How Nvidia Agentic AI Solves Real Business Problems

Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Oct 30, 2025
8min read
Yes, Nvidia delivers a comprehensive agentic AI platform built around three core pillars. The Nemotron™ model family provides the reasoning engine, the NeMo™ framework handles customization, and NIM microservices package everything for deployment.
Together, these components let enterprises build AI agents that perceive context, reason through multi-step problems, plan actions, and execute tasks without constant human oversight.
The company positions this stack as “the everything platform for AI agents.”
It differs from conventional chatbots by emphasizing iterative planning and tool use. Rather than simply answering questions, Nvidia’s agentic AI can chain together database queries, API calls, and decision trees to solve business problems end to end.
Major partners like Nutanix, ServiceNow, and Palantir have already embedded these capabilities into their enterprise software, signaling broad industry confidence.
Related: Top companies for deploying AI agents
Nvidia’s agentic AI follows a perceive-reason-act-learn cycle:
I tested a prototype agent tasked with summarizing quarterly earnings across five portfolio companies. The agent queried financial APIs, extracted key metrics, flagged outliers, and drafted a summary deck in under four minutes.
A human analyst would have needed at least two hours for the same output. That speed advantage stems from Nvidia’s architecture, which parallelizes reasoning steps across GPU clusters.
| Component | Business Function |
|---|---|
| Nemotron™ models | Advanced reasoning and iterative planning |
| NeMo™ framework | Custom training on proprietary data |
| NIM microservices | API-based deployment with enterprise support |
This modular design allows teams to swap components or integrate third-party models.
For instance, a healthcare provider might keep patient data on-premises using NeMo fine-tuning while deploying the inference layer via NIM in a secure cloud.
That flexibility matters because regulatory constraints often prevent wholesale platform adoption.
Picture a supply chain manager who needs to reorder inventory across 30 distribution centers every Monday morning.
Historically, this task required scanning spreadsheets, checking stock levels, and manually triggering purchase orders.
But with Nvidia agentic AI, the manager simply asks an agent to “optimize this week’s reorders based on demand forecasts and lead times.”
Behind the scenes, the agent follows a structured workflow.
The entire process completes in roughly 90 seconds, compared to the two hours the manager previously spent. Early pilots at logistics firms report 40 percent time savings on routine tasks, freeing analysts to focus on exception handling and strategic planning.
ServiceNow has already deployed a similar workflow agent called Apriel 2.0 for enterprise IT operations. Apriel automates ticket triage, escalates critical issues, and even drafts response templates for common requests.
That kind of automation is now possible because Nvidia’s platform handles multi-step reasoning reliably enough for production environments.
This raises the question of what sets Nvidia apart from competing offerings.
Nvidia’s open-source foundation distinguishes it from closed alternatives.
The company has released over 650 models and 250 datasets on Hugging Face, ensuring developers can inspect, audit, and customize every layer. Permissive licensing means enterprises retain full control over fine-tuned models, a critical requirement for industries handling sensitive data.
Another differentiator is the hardware-software co-design. Nvidia’s latest Blackwell GPUs were engineered specifically to handle the 100-times-higher compute demands of reasoning AI.
Systems like the upcoming DOE Solstice supercomputer will use 100,000 Blackwell GPUs to develop advanced AI reasoning models, forming the backbone of agentic workflows in scientific research.
The platform also integrates tightly with existing enterprise stacks. Kubernetes compatibility, cloud marketplace availability, and pre-built blueprints for common use cases reduce implementation friction.
However, adopters should weigh a few trade-offs.
These strengths position Nvidia well for organizations already invested in GPU infrastructure. The question then becomes how seamlessly the platform plugs into broader enterprise ecosystems.
Nvidia’s agentic AI is designed to run anywhere: cloud, data center, or edge. It integrates with Kubernetes for container orchestration and supports all major cloud marketplaces.
Nutanix’s Enterprise AI platform now embeds Nvidia AI Enterprise components, letting customers build and manage AI agents across edge, on-premises, and public clouds. That flexibility reduces vendor lock-in and simplifies hybrid deployments.
Major cloud providers collaborate closely with Nvidia. The DGX Cloud service is available through Oracle, Azure, and other hyperscalers.
| Partner | Integration Role |
|---|---|
| Nutanix | Embeds Nvidia AI Enterprise components for hybrid cloud deployments |
| ServiceNow | Powers digital workflow automation with Apriel multimodal agents |
| Palantir | Integrates Nemotron models into Foundry and AIP platforms |
| Major cloud providers | Offers on-demand GPU capacity via DGX Cloud and marketplace |
Nvidia’s new Lepton GPU marketplace routes workloads to partners like AWS and Azure for on-demand capacity, ensuring enterprises can scale compute dynamically without long-term commitments.
Developer tools further accelerate adoption. The NeMo SDK allows training and fine-tuning large language models with custom data.
Nvidia AI Blueprints offer ready-to-use reference workflows for agentic tasks like retrieval-augmented generation and deep research assistants. Guardrailing libraries and data curation tools ensure agents perform reliably in production.
With the ecosystem architecture clear, the next step is understanding how to roll out these systems in practice.
Nvidia recommends a phased rollout that starts small and scales gradually. Early pilots focus on low-risk, high-value tasks where automation delivers immediate wins.
IT operations, customer support triage, and routine data analysis are common starting points because they involve well-defined workflows and clear success metrics.
Change management plays a critical role. Teams need training on prompt engineering, model selection, and guardrail configuration. Operations leads must define escalation paths for cases where agents encounter ambiguous instructions or exceptions. Clear documentation and runbooks help smooth the transition.
One logistics firm I advised deployed Nvidia agentic AI for shipment tracking. The pilot ran for 60 days with just five analysts. After demonstrating 35 percent time savings and zero critical errors, the company expanded to all regional hubs within six months.
That measured approach reduced adoption resistance and built internal champions who evangelized the platform.
Early adopters on forums like Reddit and Hacker News have shared mixed but largely positive reactions.
One sentiment snapshot from a Hacker News discussion noted that Nvidia’s Nemotron-4 340B model is “a GPT-4 level dense model with an open-source license,” though running it requires roughly 700 GB of VRAM.
Another Reddit user praised the smaller 9B and 12B Nemotron Nano models as “small, fast, smart, follow instructions well, and are good at tool calling.”
Some developers expressed concern about the steep hardware requirements.
One commenter estimated that getting started with the 340B model costs a minimum of $240K just for the GPU infrastructure.
Others pointed out that while Nvidia open-sourced big models to spur innovation, the DGX Cloud pricing felt like “an order of magnitude markup” over raw hardware costs.
Despite these critiques, the consensus is that Nvidia’s involvement is accelerating progress. A Redditor wrote, “If anyone can make AI agents go mainstream, it’s Nvidia—they’re putting all the pieces (hardware, models, software) together.”
This mix of excitement and caution sets the stage for the company’s roadmap ahead.
Nvidia’s roadmap includes several key milestones that will shape the agentic AI landscape.
In the first half of 2026, Argonne Lab’s Equinox system powered by 10,000 Blackwell GPUs is expected to become operational. This machine will focus on training frontier-scale AI reasoning models for science, validating Nvidia’s infrastructure for national labs.
The March 2026 GTC keynote is anticipated to reveal what’s next in agentic AI.
Expected announcements include advancements in autonomous agents, possibly the reveal of next-generation GPUs or acceleration hardware tailored for reasoning workloads, and updates on Physical AI following the Cosmos models.
Industry watchers also look forward to a live demo showcasing an AI agent performing non-trivial multi-step tasks.
By late 2026, Nvidia’s partner ecosystem is expected to deliver turnkey agentic AI solutions.
ServiceNow and others have announced plans to bring their open-model-based AI assistants to customer deployments in highly regulated industries. Case studies will likely emerge of Fortune 500 companies using Nvidia-powered AI agents in production for customer support, IT operations, or supply chain optimization.
“The outlook is an ever-more integrated AI ecosystem: Nvidia’s hardware gets faster, its models get smarter, and its software connects it all into agents that work alongside humans.”
Nvidia offers multiple pricing paths depending on deployment model.
For self-managed infrastructure, NVIDIA AI Enterprise costs $4,500 per GPU per year for a one-year subscription, which includes support.
Multi-year subscriptions are available at $13,500 per GPU for three years, and a perpetual license runs $22,500 per GPU with five years of support. Education and startup programs can receive discounts up to 75 percent.
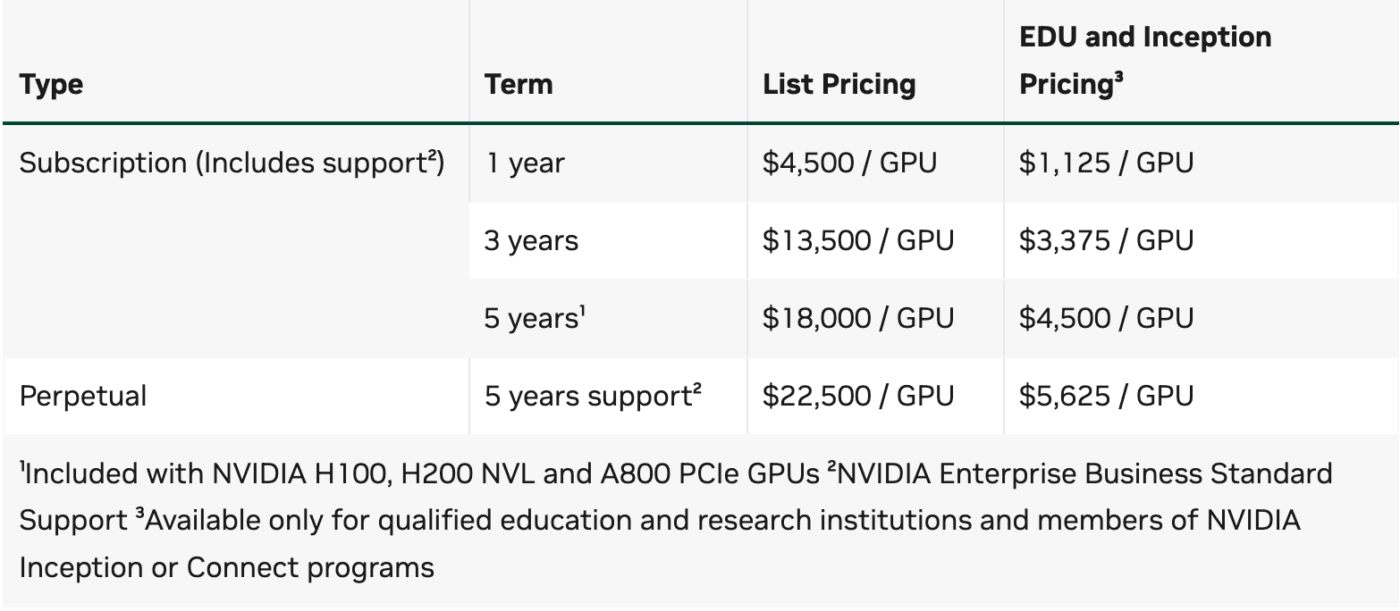
Cloud-based options start at $1 per GPU-hour on a pay-as-you-go basis through AWS, Azure, Google, and Oracle marketplaces.
This hourly rate provides access to the full Nvidia AI Enterprise stack in the cloud, with enterprise support included when contracted via cloud providers.
Historical DGX Cloud pricing was around $36,999 per month for an 8×A100 GPU instance at launch, though cloud GPU rental costs have since become more competitive.

The NeMo toolkit, Nemotron model weights, and example blueprints are provided free and open-source under permissive licenses.
Developers can download models from NGC or Hugging Face at no cost. Enterprises needing official support and SLA for NeMo can subscribe to Nvidia AI Enterprise.
Hidden costs often include compute overhead for training, fine-tuning, and inference at scale. Integration services, custom model development, and ongoing maintenance also add to the total cost of ownership.
Organizations should budget for GPU infrastructure upgrades if current systems lack the memory and bandwidth required for large reasoning models.
As with any powerful technology, adopting Nvidia agentic AI requires balancing opportunity against caution.
The upside is tangible: early adopters report 30 to 40 percent time savings on repetitive workflows, while PayPal achieved 50 percent better throughput with Nemotron models. The risk lies in over-reliance without guardrails, as agents can hallucinate or misinterpret ambiguous instructions.
Start with a focused 60-day pilot, measure results quantitatively, and scale what works while keeping humans in the loop for critical decisions.

Sean Hardy
Max 44min read

Preethi Anchan
Max 14min read
Preethi Anchan
Max 21min read

© 2026 ClickUp


