
Você tem certeza de que o documento existe. Você o viu na semana passada.
Mas depois de tentar todas as combinações de palavras-chave que você pode imaginar — “resultados de marketing do terceiro trimestre”, “desempenho do terceiro trimestre”, “relatório de marketing de outubro” — a barra de pesquisa da sua empresa não apresenta nenhum resultado. Essa busca frustrante por informações é um sinal clássico de uma pesquisa por palavras-chave desatualizada.
Esses sistemas encontram apenas correspondências exatas de palavras e não entendem o que você realmente quer dizer. O Cohere resolve esse problema de forma eficaz, fornecendo uma camada de pesquisa inteligente que conecta seus sistemas.
Portanto, se você está tentando descobrir “Como usar o Cohere para pesquisa empresarial”, nós temos a solução. Este guia explica tudo.
O que é o Cohere AI e por que ele é importante para a pesquisa empresarial?
O Cohere é uma plataforma de IA que cria grandes modelos de linguagem (LLMs) especificamente para uso empresarial. Para a pesquisa interna, isso significa ir além da pesquisa baseada em palavras-chave para uma pesquisa semântica e inteligente que compreende a intenção, o contexto e o significado.
A maioria das ferramentas de pesquisa empresarial ainda depende da correspondência literal de palavras-chave. Se as palavras exatas não aparecerem no título ou no corpo de um documento, o resultado muitas vezes é perdido. O Cohere muda isso, permitindo que os sistemas de pesquisa entendam o que o usuário realmente está procurando, e não apenas o que digitou.
As equipes que tentam criar uma pesquisa baseada em IA por conta própria geralmente passam meses montando bancos de dados vetoriais, pipelines de embeddings e modelos de reclassificação. Mesmo depois de todo esse trabalho, a pesquisa muitas vezes tem um desempenho abaixo do esperado porque fica em um sistema separado de onde o trabalho realmente acontece, desconectada de tarefas, documentos e fluxos de trabalho.
Uma ferramenta de pesquisa empresarial poderosa como o Cohere usa geração aumentada por recuperação (RAG) para combinar pesquisa inteligente com IA. Essa abordagem transforma seu conhecimento interno em um recurso acessível instantaneamente.
No caso do Cohere, a ferramenta converte documentos em embeddings, representações numéricas de significado. Quando alguém pesquisa por “relatório de receita trimestral”, o sistema recupera documentos conceitualmente relevantes, como “Resultados financeiros do quarto trimestre” ou “Resumo de ganhos”, mesmo que essas palavras-chave exatas não estejam presentes.
É por isso que o Cohere é importante para a pesquisa empresarial. Ele reduz a complexidade da implementação, melhora a precisão dos resultados e permite uma pesquisa que funciona da maneira como os funcionários realmente pensam e fazem perguntas nos sistemas de trabalho modernos.
📮ClickUp Insight: Mais da metade de todos os funcionários (57%) perde tempo pesquisando em documentos internos ou na base de conhecimento da empresa para encontrar informações relacionadas ao trabalho.
E quando isso não é possível? 1 em cada 6 recorre a soluções alternativas pessoais, vasculhando e-mails antigos, notas ou capturas de tela apenas para juntar as peças.
O ClickUp Brain elimina a necessidade de pesquisa, fornecendo respostas instantâneas baseadas em IA, extraídas de todo o seu espaço de trabalho e aplicativos integrados de terceiros, para que você obtenha o que precisa sem complicações.
Principais recursos do Cohere para pesquisa empresarial
Ao avaliar soluções de pesquisa com IA, o hype do marketing pode tornar difícil identificar quais recursos realmente resolvem seus problemas. Promessas genéricas de “pesquisa mais inteligente” não ajudam suas equipes de engenharia e de produto a tomar decisões informadas.
A realidade é que um sistema de pesquisa confiável depende de um conjunto de modelos distintos de IA trabalhando em conjunto.
O Cohere oferece vários modelos que você pode usar de forma independente ou combinar para construir uma arquitetura de pesquisa sofisticada. Compreender esses recursos essenciais é o primeiro passo para projetar um sistema que atenda às necessidades específicas da sua equipe.
Incorpore para pesquisa vetorial semântica
A maior frustração com os sistemas de pesquisa antigos é a incapacidade de encontrar informações conceitualmente relacionadas. Você pesquisa “guia de integração de funcionários” e não encontra o documento intitulado “Lista de verificação para o primeiro dia do novo contratado”. Isso acontece porque o sistema está comparando palavras, não significados.
O modelo Embed, com pesquisa neural, resolve isso convertendo o texto em vetores — longas listas de números que capturam o significado semântico. Esse processo, chamado de embedding, permite que o sistema identifique documentos que são conceitualmente semelhantes, mesmo que não compartilhem palavras-chave em comum. Essencialmente, sua ferramenta de pesquisa entende automaticamente sinônimos e ideias relacionadas.
Aqui estão os principais aspectos do modelo Embed do Cohere:
- Suporte multimodal: a versão mais recente, Embed 4, pode processar texto e imagens, permitindo que você pesquise em diferentes tipos de conteúdo ao mesmo tempo.
- Recursos multilíngues: você pode pesquisar informações em documentos em diferentes idiomas sem precisar traduzi-los primeiro.
- Opções de dimensionalidade: você pode escolher o tamanho dos seus vetores. Dimensões mais altas capturam mais nuances, mas exigem mais espaço de armazenamento e poder de processamento.
📖 Leia mais: Casos de uso de pesquisa empresarial com IA
Reorganize para melhorar a relevância dos resultados.
Às vezes, uma pesquisa retorna uma lista de documentos relevantes, mas o mais importante está escondido na segunda página. Isso obriga os usuários a vasculhar os resultados, desperdiçando tempo e fazendo com que percam a confiança no sistema de pesquisa.
Este é um problema de classificação. O sistema encontrou as informações corretas, mas não conseguiu priorizá-las corretamente.
O modelo Rerank do Cohere resolve isso com um processo de duas etapas. Primeiro, você usa um método de recuperação rápida (como pesquisa semântica) para reunir um grande conjunto de documentos potencialmente relevantes. Em seguida, você passa essa lista para o modelo Rerank, que usa uma arquitetura de codificador cruzado mais intensiva em termos computacionais para analisar cada documento em relação à sua consulta específica e reordená-los para obter a máxima relevância.
Isso é especialmente útil em situações de alto risco, nas quais a precisão é fundamental, como quando um agente de suporte encontra a resposta certa para um cliente ou um membro da equipe procura uma seção específica em um documento. Embora isso aumente um pouco o tempo de processamento, a melhoria na qualidade dos resultados geralmente compensa.
Casos de uso do Enterprise Search para equipes
Os recursos de IA abstrata são interessantes, mas só se tornam úteis quando aplicados para resolver problemas comerciais do mundo real. Uma implementação bem-sucedida de pesquisa empresarial começa com a identificação desses pontos específicos. 👀
Aqui estão alguns cenários práticos em que as equipes podem aplicar a pesquisa com tecnologia Cohere:
- Pesquisa na base de conhecimento: ajude os funcionários a encontrar respostas na documentação interna, wikis, base de conhecimento do atendimento ao cliente e procedimentos operacionais padrão (SOPs) .
- Suporte ao cliente: permita que os agentes localizem rapidamente artigos de ajuda relevantes e resoluções de tickets anteriores durante uma ligação com um cliente — a análise da McKinsey mostra ganhos de produtividade de 30 a 45% quando a IA generativa é aplicada aos fluxos de trabalho de atendimento ao cliente.
- Legal e conformidade: pesquise milhões de contratos, políticas e documentos regulatórios com compreensão semântica para encontrar cláusulas ou precedentes específicos.
- Pesquisa e desenvolvimento: permita que os engenheiros encontrem trabalhos anteriores, patentes e documentação técnica relevantes para evitar a duplicação de esforços.
- RH e integração: apresente políticas relevantes, materiais de treinamento, exemplos de fluxo de trabalho e procedimentos para novos funcionários, para que eles possam encontrar respostas por conta própria.
- Capacitação de vendas: ajude os representantes de vendas a encontrar os estudos de caso, informações competitivas e informações sobre produtos certos para fechar negócios mais rapidamente.
O ponto em comum é que uma pesquisa empresarial eficaz deve ser integrada ao gerenciamento de fluxo de trabalho existente. Uma barra de pesquisa independente não é suficiente. Sua equipe precisa ser capaz de encontrar informações e agir imediatamente sem precisar trocar de ferramenta.
🛠️ Kit de ferramentas: crie um hub interno que sua equipe realmente utilizará. O modelo de base de conhecimento do ClickUp mantém tudo — desde instruções até procedimentos operacionais padrão — organizado e fácil de pesquisar, para que ninguém fique sem saber onde encontrar as informações.

Como configurar o Cohere para pesquisa empresarial
Passar da avaliação da pesquisa por IA para sua implementação real pode parecer assustador. Especialmente se sua equipe não tem experiência com modelos de linguagem de grande porte.
Embora a complexidade da sua configuração dependa da sua escala e da pilha de tecnologia existente, as etapas principais para construir um sistema de pesquisa com tecnologia Cohere são consistentes. Esta seção fornece um guia prático para orientar sua equipe técnica.
Pré-requisitos e acesso à API
Antes de escrever qualquer código, você precisa organizar suas ferramentas e acessos. Essa configuração inicial ajuda a evitar problemas de segurança e obstáculos mais tarde.
Veja o que você precisa para começar:
- Conta da API Cohere: inscreva-se no site da Cohere para obter suas chaves de API.
- Ambiente de desenvolvimento: a maioria das equipes usa Python, mas SDKs estão disponíveis para outras linguagens.
- Banco de dados vetorial: você precisará de um local para armazenar suas incorporações de documentos, como Pinecone, Weaviate, Qdrant ou um serviço gerenciado como o Amazon OpenSearch.
- Corpus de documentos: reúna o conteúdo que você deseja tornar pesquisável (por exemplo, PDFs, arquivos de texto, registros de banco de dados).
Você também pode acessar os modelos do Cohere por meio do Amazon Bedrock, o que pode simplificar o faturamento e a segurança se sua empresa já trabalha dentro do ecossistema AWS.
Gere embeddings com o Cohere Embed
A próxima etapa é converter seus documentos em vetores pesquisáveis. Esse processo envolve preparar seu conteúdo e, em seguida, executá-lo no modelo Cohere Embed.
A maneira como você prepara seus documentos, especialmente como os divide em partes menores, tem um grande impacto na qualidade da pesquisa. Isso é chamado de estratégia de fragmentação.
As estratégias comuns de fragmentação incluem:
- Pedaços de tamanho fixo: o método mais simples, mas pode dividir frases ou ideias de forma inadequada no meio.
- Chunking semântico: um método mais avançado que respeita a estrutura do documento, como quebras no final de parágrafos ou seções.
- Trechos sobrepostos: essa abordagem inclui uma pequena quantidade de texto repetido entre os trechos para ajudar a preservar o contexto entre as fronteiras.
Depois que seus documentos forem divididos em blocos, envie-os para a API Embed em lotes para gerar as representações vetoriais. Normalmente, esse é um processo único para seus documentos existentes, com documentos novos ou atualizados sendo incorporados à medida que são criados.
📖 Leia mais: O que é um mecanismo de pesquisa interno? As melhores ferramentas e como elas funcionam
Armazene e consulte vetores
Seus vetores recém-criados precisam de um local para serem armazenados. Um banco de dados vetorial é um banco de dados especializado projetado para armazenar e consultar embeddings com base em sua similaridade.
O processo de consulta funciona assim:
- Um usuário digita uma consulta de pesquisa
- Seu aplicativo envia essa consulta para o mesmo modelo Cohere Embed para convertê-la em um vetor.
- Esse vetor de consulta é enviado ao banco de dados, que encontra os vetores de documentos mais semelhantes.
- O banco de dados retorna os documentos correspondentes, que você pode exibir ao usuário.
Ao escolher um banco de dados vetorial, você também deve considerar qual métrica de similaridade usar. A similaridade coseno é a mais comum para pesquisas baseadas em texto, mas existem outras opções para diferentes casos de uso.
| Métrica de similaridade | Ideal para |
|---|---|
| Similaridade coseno | Pesquisa de texto para fins gerais |
| Produto escalar | Quando a magnitude dos vetores é importante |
| Distância euclidiana | Dados espaciais ou geográficos |
Implemente a reclassificação para obter melhores resultados.
Para muitas aplicações, os resultados do seu banco de dados vetorial são bons o suficiente. Mas quando você precisa do melhor resultado absoluto no topo, é inteligente adicionar uma etapa de reclassificação.
Isso é especialmente importante quando sua pesquisa alimenta um sistema RAG, já que a qualidade da resposta gerada depende muito da qualidade do contexto recuperado.
O pipeline de reclassificação é simples:
- Recupere um conjunto maior de candidatos iniciais do seu banco de dados vetorial (por exemplo, os 50 melhores resultados).
- Passe a consulta original do usuário e esta lista de candidatos para a API Cohere Rerank.
- A API retorna a mesma lista de documentos, mas reordenada com base em uma pontuação de relevância mais precisa.
- Exiba os principais resultados da lista reclassificada para o usuário.
Para medir o impacto da reclassificação, você pode acompanhar métricas de avaliação offline, como nDCG (ganho cumulativo normalizado descontado) e MRR (classificação recíproca média).
💫 Para uma visão geral visual da implementação de recursos de pesquisa empresarial, assista a este tutorial que demonstra os principais conceitos e considerações práticas:
Melhores práticas para pesquisa empresarial com tecnologia Cohere
Construir um sistema de pesquisa é apenas o primeiro passo. Manter e melhorar sua qualidade ao longo do tempo é o que separa um projeto bem-sucedido de um fracassado. Se os usuários tiverem algumas experiências ruins, perderão a confiança e deixarão de usar a ferramenta. 🛠️
Aqui estão algumas lições aprendidas com implementações bem-sucedidas de pesquisa empresarial:
- Comece com a pesquisa híbrida: não confie apenas na pesquisa semântica. Combine-a com um algoritmo tradicional de pesquisa por palavra-chave, como o BM25. Isso oferece o melhor dos dois mundos: a pesquisa semântica encontra itens conceitualmente relacionados, enquanto a pesquisa por palavra-chave garante que você ainda possa encontrar correspondências exatas para códigos de produtos ou nomes específicos.
- Invista na higiene e na qualidade dos dados: seus resultados de pesquisa só podem ser tão bons quanto seus dados. Documentos limpos e bem estruturados, com títulos e parágrafos claros, produzem embeddings muito melhores.
- Divida cuidadosamente: a forma como você divide seus documentos em partes é fundamental. Em vez de usar limites arbitrários de caracteres, tente alinhar as partes com a estrutura lógica dos seus documentos, como parágrafos ou seções.
- Adicione filtragem de metadados: a pesquisa semântica é poderosa, mas às vezes os usuários já sabem o que estão procurando. Permita que eles filtrem os resultados por metadados como data, departamento ou tipo de documento antes que a pesquisa semântica seja iniciada.
- Monitore e itere: preste muita atenção ao que seus usuários estão pesquisando, em quais resultados eles clicam e quais consultas não retornam resultados. Esses dados são valiosos para identificar lacunas de conteúdo e melhorar seu sistema.
- Lide com falhas com elegância: nenhum sistema de pesquisa é perfeito. Quando uma pesquisa retornar resultados insatisfatórios, forneça alternativas úteis, como sugerir consultas alternativas ou oferecer notificação a um especialista humano.
Limitações do Cohere para Pesquisa Empresarial
Embora o Cohere forneça modelos de IA poderosos, ele não é uma solução plug-and-play (não exatamente).
A criação de uma solução de pesquisa empresarial pronta para produção traz desafios significativos que as equipes muitas vezes subestimam. Compreender essas limitações é fundamental para tomar uma decisão informada e evitar surpresas desagradáveis no futuro.
A maior questão é que você está adquirindo um conjunto de ferramentas, não um produto acabado. Isso deixa sua equipe responsável por construir e manter toda a infraestrutura envolvida em torno da pesquisa como um serviço.
Aqui estão algumas das principais limitações a serem consideradas:
| Desafio | Por que isso se torna um problema |
|---|---|
| Requer conhecimento especializado | Você precisa de engenheiros de IA e dados experientes para construir, operar e manter o sistema. Isso não é algo que a maioria das equipes pode configurar ou possuir casualmente. |
| Integrações personalizadas necessárias | Os modelos não se conectam automaticamente às suas ferramentas existentes. Cada fonte de dados precisa ser conectada e mantida manualmente. |
| Alta manutenção contínua | Os índices de pesquisa devem ser constantemente atualizados à medida que o conteúdo muda ou os modelos são atualizados, adicionando trabalho operacional contínuo. |
| Não conectado ao seu espaço de trabalho | A IA entende a linguagem, mas não está presente onde sua equipe realmente trabalha, criando uma desconexão entre a pesquisa e a execução. |
| A mudança de contexto é inevitável | As pessoas encontram informações em um lugar e, em seguida, trocam de ferramenta para agir sobre elas, o que prejudica a produtividade e a adoção. |
Como usar o ClickUp como alternativa à pesquisa empresarial
A esta altura, a vantagem deve estar clara.
A pesquisa empresarial é poderosa, mas criá-la por conta própria significa possuir pipelines de ingestão, estratégias de fragmentação, atualizações de embeddings, lógica de reclassificação e manutenção contínua. Trata-se de um compromisso de infraestrutura de longo prazo, não do lançamento de um recurso.
Como o primeiro espaço de trabalho de IA convergente do mundo, o ClickUp elimina toda essa camada, tornando a pesquisa alimentada por IA nativa do próprio espaço de trabalho.
Isso é importante porque a maioria dos problemas de pesquisa não são realmente problemas de pesquisa. São problemas de dispersão do trabalho. Quando o trabalho está espalhado por ferramentas desconectadas, as equipes são forçadas a procurar constantemente pelo contexto. O resultado é perda de tempo, esforço duplicado e decisões tomadas sem visibilidade total.
O ClickUp resolve esse problema na origem, reunindo trabalho, contexto e inteligência em um único espaço de trabalho. Vamos analisar como isso funciona na prática.
Obtenha respostas contextuais em todo o espaço de trabalho com o ClickUp Brain.
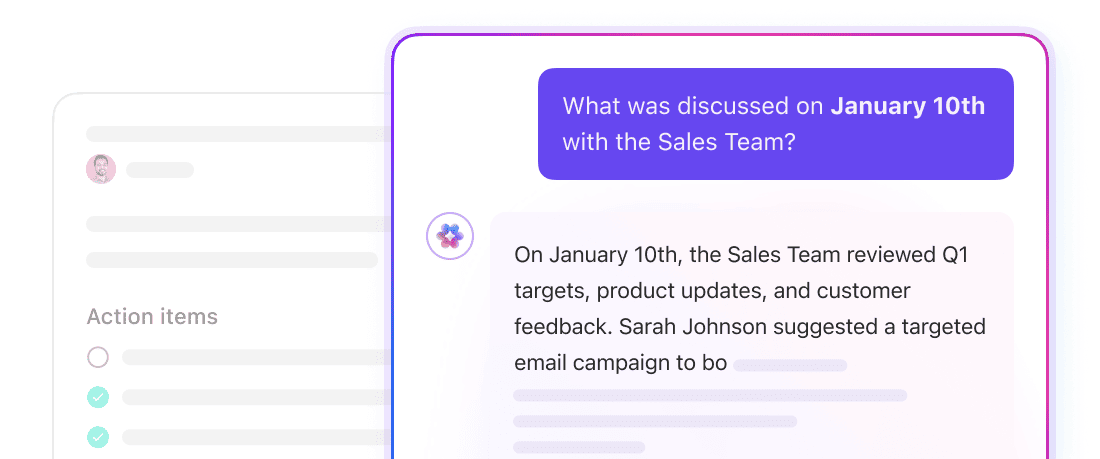
O ClickUp Brain é uma camada de IA contextual que opera em todo o seu espaço de trabalho. Ele pode responder a perguntas, resumir informações e exibir trabalhos relevantes, pois já tem acesso à estrutura subjacente do seu espaço de trabalho: ClickUp Tasks, ClickUp Docs, ClickUp Comments e muito mais.
Não há necessidade de definir tamanhos de blocos ou gerenciar embeddings aqui. O Brain usa o modelo de dados nativo do ClickUp para entender como as informações estão conectadas. Faça uma pergunta como “O que está impedindo o lançamento do quarto trimestre?” e o Brain pode extrair o contexto de tarefas, comentários e documentos vinculados a essa iniciativa.
O ClickUp Brain também oferece suporte a vários modelos de IA, permitindo que você aproveite diferentes solicitações para o modelo mais adequado para raciocínio, resumo ou geração. Isso evita limitar seus fluxos de trabalho aos pontos fortes ou às limitações de um único modelo.
Quando você precisar de contexto externo, o Brain pode realizar pesquisas na web diretamente do espaço de trabalho, retornando resultados resumidos sem que você precise sair do ClickUp ou abrir uma guia separada no navegador.
Pesquise, navegue e execute com o ClickUp Enterprise Search.
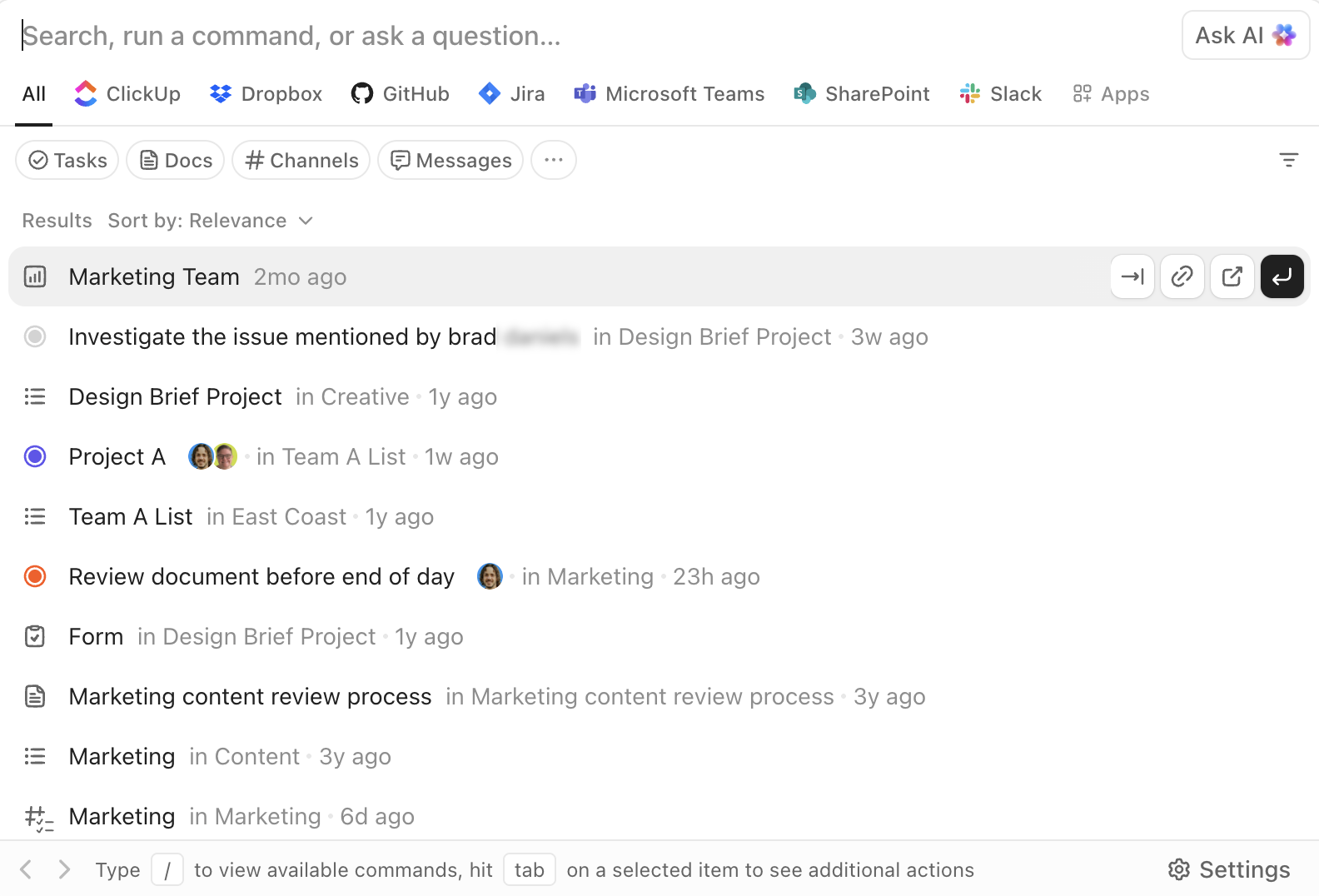
A Pesquisa Empresarial do ClickUp pode ser acessada de qualquer lugar no espaço de trabalho. Ela permite pesquisar tarefas, documentos, comentários e anexos, bem como aplicativos de terceiros conectados, como Google Drive, Slack, GitHub e outros, dependendo de suas integrações.
A barra de comando de IA transforma a pesquisa em uma camada de execução. Você pode acessar itens, criar tarefas, alterar status, atribuir proprietários ou abrir visualizações específicas diretamente da mesma interface. Não se trata apenas de “encontrar e ler”, mas de “encontrar e agir”.
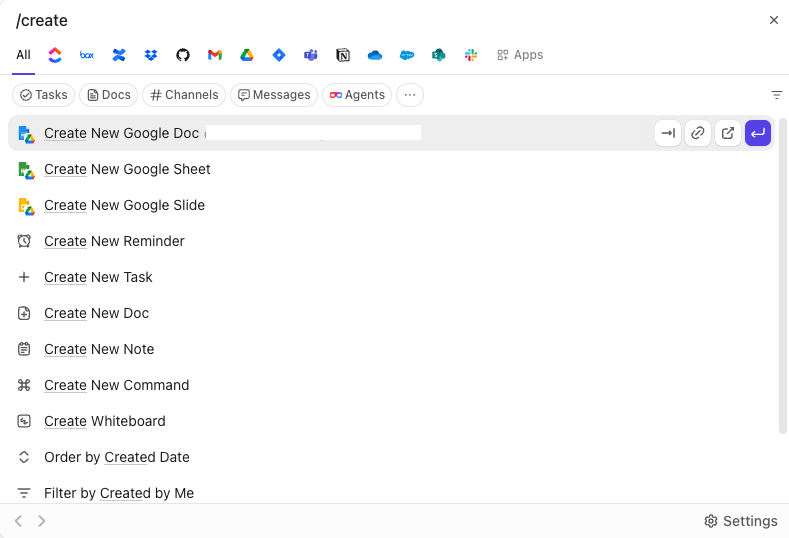
Como a pesquisa está incorporada à interface do usuário do espaço de trabalho, os resultados são sempre acionáveis. Você não recupera informações isoladamente e depois troca de ferramenta para usá-las. O fluxo de trabalho continua no mesmo lugar.
Reduza a proliferação de ferramentas com o ClickUp BrainGPT.
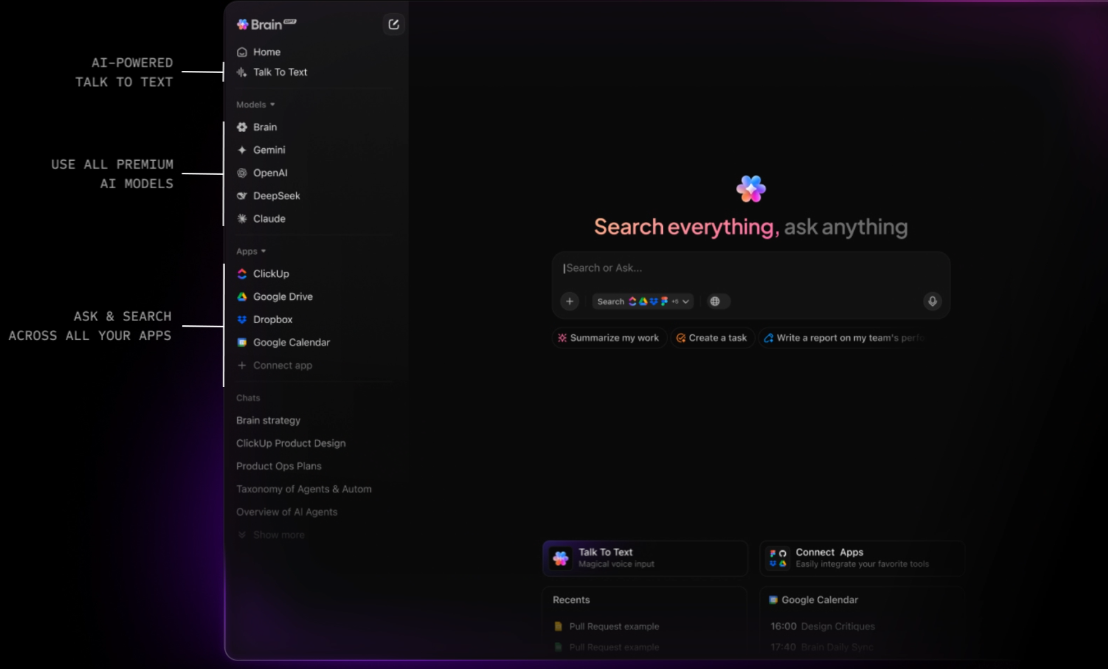
O ClickUp BrainGPT amplia os recursos de pesquisa além do navegador, oferecendo um aplicativo independente para desktop e uma extensão para o Chrome. Ele se conecta diretamente ao seu espaço de trabalho e exibe a mesma inteligência contextual sem exigir que você abra primeiro o ClickUp ou qualquer um dos seus aplicativos conectados.
A partir de uma única interface, você pode pesquisar tarefas, documentos, comentários e ferramentas conectadas, incluindo Gmail e outras integrações. O recurso Talk-to-Text baseado em voz permite que você faça pesquisas ou capture perguntas instantaneamente, o que é especialmente útil para pesquisas rápidas ou trabalho em trânsito.
Em vez de adicionar outro produto de pesquisa de IA para gerenciar, o Brain GPT consolida a descoberta em uma única interface que já compreende o seu trabalho.
Essa é a verdadeira mudança. O ClickUp não pede que você crie uma pesquisa empresarial. Esse espaço de trabalho convergente o incorpora diretamente ao sistema onde o trabalho é realizado, eliminando a sobrecarga da infraestrutura e preservando o poder, a precisão e a velocidade.
Bônus: comparação estratégica entre IA personalizada e IA nativa do espaço de trabalho
| Valor fundamental | Flexibilidade máxima; controle proprietário | Pronto para execução; sensível ao contexto por padrão |
| Implementação | Meses: Requer equipes de engenharia para construir pipelines | Minutos: alternância com um clique para todo o espaço de trabalho |
| Ingestão de dados | Manual: você deve criar e manter ETL e banco de dados vetorial. | Automático: acesso em tempo real a tarefas, documentos e bate-papos |
| Lógica de permissão | Deve ser codificado manualmente (alto risco de vazamento de dados) | Herdado nativamente da sua hierarquia do ClickUp. |
| Profundidade contextual | Semântico (baseado no significado) | Operacional (sabe quem está designado para o quê) |
| Interface do usuário | Você deve projetar e construir a barra de pesquisa/chat. | Integrado (barra de pesquisa, visualizações de documentos e tarefas) |
| Ação do fluxo de trabalho | Nenhuma: o usuário encontra as informações e, em seguida, muda de ferramenta para trabalhar. | Alto: encontre informações e converta instantaneamente em uma tarefa |
| Ideal para | Empresas de alta tecnologia que desenvolvem software proprietário | Equipes que desejam eliminar a “proliferação de ferramentas” e agir rapidamente |
A pesquisa não deve atrasar você!
A pesquisa semântica não é mais um diferencial. É um requisito básico.
O custo real da pesquisa empresarial aparece em todos os outros aspectos: o tempo de engenharia para criá-la e mantê-la, a infraestrutura necessária para mantê-la precisa e o atrito criado quando a pesquisa fica fora das ferramentas onde o trabalho realmente acontece. Encontrar o documento certo não importa muito se, para agir com base nele, ainda for necessário mudar de sistema.
É por isso que o problema não é apenas “uma pesquisa melhor”. É eliminar a lacuna entre a informação e a execução.
Quando a pesquisa é incorporada diretamente ao espaço de trabalho, o contexto é preservado por padrão. As respostas não são apenas recuperadas, elas são imediatamente utilizáveis. As tarefas podem ser atualizadas, as decisões podem ser documentadas e o trabalho pode avançar sem a necessidade de mais uma transferência.
Para equipes que não querem passar meses construindo e mantendo uma infraestrutura de pesquisa personalizada, trabalhar em um espaço de trabalho de IA convergente muda completamente a equação. O ClickUp oferece pesquisa de nível empresarial com tecnologia de IA como parte do sistema que sua equipe já usa para planejar, colaborar e executar.
✅ Comece a usar o ClickUp gratuitamente.
Perguntas frequentes
O Cohere se concentra especificamente em casos de uso corporativo, como pesquisa, oferecendo modelos como Embed e Rerank, que são desenvolvidos especificamente para tarefas de recuperação. A OpenAI fornece modelos mais amplos e de uso geral que podem ser adaptados para pesquisa, mas podem exigir mais ajustes.
Sim, o Cohere fornece APIs que permitem a integração com outras ferramentas; no entanto, isso requer desenvolvimento personalizado e recursos de engenharia. Uma alternativa como o ClickUp oferece pesquisa nativa de IA que funciona imediatamente, eliminando a necessidade de qualquer trabalho de integração.
Setores com grandes repositórios de documentos não estruturados, como os setores jurídico, de saúde, de serviços financeiros e de tecnologia, são os que mais se beneficiam da pesquisa semântica. Qualquer organização que tenha dificuldades com o gerenciamento do conhecimento pode obter melhorias significativas.