
Anda merilis pembaruan perangkat lunak terbaru, dan laporan mulai berdatangan.
Tiba-tiba, satu metrik mengendalikan segalanya, mulai dari CSAT/NPS hingga keterlambatan roadmap: waktu penyelesaian bug.
Pimpinan melihatnya sebagai metrik yang menjamin komitmen—apakah kita bisa meluncurkan produk, belajar, dan melindungi pendapatan tepat waktu? Praktisi merasakan tantangan di lapangan—tiket yang tumpang tindih, tanggung jawab yang tidak jelas, eskalasi yang berisik, dan konteks yang tersebar di Slack, spreadsheet, dan alat terpisah.
Fragmentasi tersebut memperpanjang siklus, menyembunyikan akar masalah, dan mengubah prioritas menjadi tebak-tebakan.
Hasilnya? Proses pembelajaran yang lambat, komitmen yang tidak terpenuhi, dan tumpukan pekerjaan yang secara diam-diam membebani setiap sprint.
Panduan ini adalah panduan lengkap Anda untuk mengukur, membandingkan, dan mengurangi waktu penyelesaian bug, serta menunjukkan secara konkret bagaimana AI mengubah alur kerja dibandingkan dengan proses manual tradisional.
Apa itu Waktu Penyelesaian Bug?
Waktu penyelesaian bug adalah waktu yang dibutuhkan untuk memperbaiki bug, diukur mulai dari saat bug dilaporkan hingga sepenuhnya diselesaikan.
Dalam praktiknya, waktu mulai dihitung saat masalah dilaporkan atau terdeteksi (melalui pengguna, QA, atau pemantauan) dan berhenti saat perbaikan diterapkan dan digabungkan, siap untuk verifikasi atau rilis—tergantung pada bagaimana tim Anda mendefinisikan "selesai."
Contoh: Sebuah crash P1 dilaporkan pada pukul 10:00 pagi hari Senin, dengan perbaikan yang digabungkan pada pukul 3:00 sore hari Selasa, memiliki waktu penyelesaian sekitar 29 jam.
Ini berbeda dengan waktu deteksi bug. Waktu deteksi mengukur seberapa cepat Anda mengenali suatu cacat setelah terjadi (peringatan berbunyi, alat pengujian QA menemukannya, pelanggan melaporkannya).
Waktu penyelesaian mengukur seberapa cepat Anda berpindah dari kesadaran akan masalah hingga penyelesaian—triage, reproduksi, diagnosis, implementasi, tinjauan, pengujian, dan persiapan untuk rilis. Bayangkan deteksi sebagai “kami tahu ada masalah,” dan penyelesaian sebagai “masalah telah diperbaiki dan siap.”
Tim menggunakan batas yang sedikit berbeda; pilih salah satu dan konsisten agar tren Anda akurat:
- Dilaporkan → Selesai: Berakhir saat perbaikan kode telah digabungkan dan siap untuk QA. Baik untuk throughput engineering
- Dilaporkan → Ditutup: Termasuk validasi QA dan rilis. Ideal untuk SLA yang berdampak pada pelanggan
- Detected → Resolved: Dimulai saat pemantauan/QA mendeteksi masalah, bahkan sebelum tiket dibuat. Berguna untuk tim yang banyak menangani produksi
🧠 Fakta Menarik: Sebuah bug yang unik dan lucu dalam Final Fantasy XIV mendapat pujian karena begitu spesifik sehingga pembaca menjulukinya sebagai "Perbaikan Bug Paling Spesifik dalam MMO 2025." Bug ini muncul saat pemain menetapkan harga item antara tepat 44.442 gil dan 49.087 gil di zona acara tertentu—menyebabkan disconnect akibat kemungkinan glitch overflow bilangan bulat.
Mengapa hal ini penting?
Waktu penyelesaian adalah faktor penentu dalam siklus rilis. Waktu yang lama atau tidak terduga memaksa pemotongan ruang lingkup, hotfixes, dan penundaan rilis; hal ini menciptakan utang perencanaan karena ekor panjang (outliers) lebih sering mengganggu sprint daripada yang ditunjukkan oleh rata-rata.
Hal ini juga langsung terkait dengan kepuasan pelanggan. Pelanggan akan toleran terhadap masalah jika masalah tersebut diakui dengan cepat dan diselesaikan secara prediktif. Perbaikan yang lambat—atau lebih buruk lagi, perbaikan yang tidak konsisten—akan memicu eskalasi, menurunkan CSAT/NPS, dan mengancam perpanjangan langganan.
Singkatnya, jika Anda mengukur waktu penyelesaian bug secara bersih dan sistematis, serta menguranginya, roadmap dan hubungan Anda akan membaik.
📖 Baca Lebih Lanjut: Cara Memrioritaskan Bug untuk Penyelesaian Masalah yang Efisien
Bagaimana Cara Mengukur Waktu Penyelesaian Bug?
Pertama, tentukan di mana waktu Anda dimulai dan berakhir.
Sebagian besar tim memilih salah satu dari dua opsi: Dilaporkan → Selesai (perbaikan telah digabungkan dan siap untuk verifikasi) atau Dilaporkan → Ditutup (QA telah memvalidasi dan perubahan telah dirilis atau ditutup dengan alasan lain).
Pilih satu definisi dan gunakan secara konsisten agar tren Anda memiliki makna.
Sekarang Anda membutuhkan beberapa metrik yang dapat diukur. Mari kita uraikan:
Metrik pelacakan bug penting yang perlu diperhatikan:
| 📊 Metrik | 📌 Apa yang dimaksud dengan ini | 💡 Bagaimana hal ini membantu | 🧮 Rumus (Jika Berlaku) |
|---|---|---|---|
| Jumlah Bug 🐞 | Jumlah total bug yang dilaporkan | Memberikan gambaran menyeluruh tentang kesehatan sistem. Angka tinggi? Saatnya untuk menyelidiki. | Total Bugs = Semua bug yang tercatat di sistem {Terbuka + Tertutup} |
| Bug Terbuka 🚧 | Bug yang belum diperbaiki | Menampilkan beban kerja saat ini. Membantu dalam prioritas. | Bug Terbuka = Total Bug - Bug yang Telah Ditutup |
| Bug yang Telah Ditutup ✅ | Bug yang telah diselesaikan dan diverifikasi | Melacak kemajuan dan pekerjaan yang telah dilakukan. | Bug Tertutup = Jumlah bug dengan status "Tertutup" atau "Terselesaikan" |
| Severitas Bug 🔥 | Kritisnya bug (misalnya, kritis, mayor, minor) | Membantu melakukan triase berdasarkan dampak. | Dicatat sebagai bidang kategorikal, tanpa rumus. Gunakan filter/pengelompokan. |
| Prioritas Bug 📅 | Seberapa mendesak suatu bug perlu diperbaiki | Membantu dalam perencanaan sprint dan rilis. | Juga merupakan bidang kategorikal, biasanya diurutkan (misalnya, P0, P1, P2). |
| Waktu Penyelesaian ⏱️ | Waktu dari pelaporan bug hingga perbaikan | Mengukur responsivitas. | Waktu Penyelesaian = Tanggal Ditutup - Tanggal Dilaporkan |
| Tingkat Pembukaan Kembali 🔄 | persentase bug yang dibuka kembali setelah ditutup | Mencerminkan kualitas perbaikan atau masalah regresi. | Tingkat Pembukaan Kembali (%) = {Jumlah Bug yang Dibuka Kembali ÷ Total Bug yang Ditutup} × 100 |
| Kebocoran Bug 🕳️ | Bug yang lolos ke produksi | Menunjukkan efektivitas QA /pengujian perangkat lunak. | Tingkat Kebocoran (%) = {Bug Produksi ÷ Total Bug} × 100 |
| Kepadatan Bug 🧮 | Jumlah bug per unit ukuran kode | Menyoroti area kode yang rentan terhadap risiko. | Kepadatan Bug = Jumlah Bug ÷ KLOC {Kilo Baris Kode} |
| Bug yang Ditugaskan vs Belum Ditugaskan 👥 | Distribusi bug berdasarkan kepemilikan | Pastikan tidak ada yang terlewat. | Gunakan filter: Belum Ditetapkan = Bug di mana "Ditetapkan Kepada" kosong |
| Usia Bug yang Belum Ditangani 🧓 | Berapa lama bug tetap tidak terselesaikan | Mengidentifikasi stagnasi dan risiko penumpukan pekerjaan. | Usia Bug = Tanggal Saat Ini - Tanggal Dilaporkan |
| Bug Ganda 🧬 | Jumlah laporan duplikat | Menyoroti kesalahan dalam proses penerimaan. | Tingkat Duplikat = Duplikat ÷ Total Bug × 100 |
| MTTD (Waktu Rata-Rata untuk Mendeteksi) 🔎 | Waktu rata-rata yang dibutuhkan untuk mendeteksi bug atau insiden | Mengukur efisiensi pemantauan dan kesadaran. | MTTD = Σ(Waktu Deteksi - Waktu Perkenalan) ÷ Jumlah Bug |
| MTTR (Waktu Rata-Rata untuk Penyelesaian) 🔧 | Waktu rata-rata untuk memperbaiki bug secara penuh setelah terdeteksi | Memantau responsivitas tim engineering dan waktu perbaikan. | MTTR = Σ(Waktu Penyelesaian - Waktu Deteksi) ÷ Jumlah Bug yang Diselesaikan |
| MTTA (Waktu Rata-Rata untuk Mengakui) 📬 | Waktu dari deteksi hingga saat seseorang mulai bekerja pada bug | Menampilkan responsivitas tim dan respons terhadap peringatan. | MTTA = Σ(Waktu Diterima - Waktu Terdeteksi) ÷ Jumlah Bug |
| MTBF (Waktu Rata-Rata Antara Gangguan) 🔁 | Waktu antara satu kegagalan yang telah diselesaikan dan kegagalan berikutnya yang terjadi | Menunjukkan stabilitas seiring waktu. | MTBF = Waktu Operasional Total ÷ Jumlah Gangguan |
⚡️ Arsip Template: 15 Template Laporan Bug Gratis & Formulir untuk Pelacakan Bug
Faktor-faktor yang Mempengaruhi Waktu Penyelesaian Bug
Waktu penyelesaian seringkali dianggap sama dengan “seberapa cepat insinyur menulis kode.”
Namun, itu hanyalah salah satu bagian dari proses.
Waktu penyelesaian bug merupakan gabungan dari kualitas saat penerimaan, efisiensi alur melalui sistem Anda, dan risiko ketergantungan. Jika salah satu dari elemen tersebut mengalami kendala, waktu siklus akan memanjang, prediktabilitas menurun, dan eskalasi semakin sering terjadi.
Kualitas penerimaan menentukan arah
Laporan yang masuk tanpa langkah reproduksi yang jelas, detail lingkungan, log, atau informasi versi/build memaksa komunikasi bolak-balik tambahan. Laporan duplikat dari berbagai saluran (dukungan, QA, pemantauan, Slack) menambah kebisingan dan memecah tanggung jawab.
Semakin cepat Anda menangkap konteks yang tepat—dan menghilangkan duplikat—semakin sedikit handoff dan permintaan klarifikasi yang Anda butuhkan di kemudian hari.
Prioritas dan rute menentukan siapa yang menangani bug dan kapan
Label tingkat keparahan yang tidak sesuai dengan dampak pelanggan/bisnis (atau yang berubah seiring waktu) menyebabkan perputaran antrean: tiket dengan suara paling keras melompat ke depan sementara bug berdampak tinggi terabaikan.
Aturan rute yang jelas berdasarkan komponen/pemilik, dan antrean tunggal yang akurat memastikan pekerjaan P0/P1 tidak tersembunyi di bawah "baru dan ramai."
Kepemilikan dan serah terima adalah pembunuh diam-diam
Jika tidak jelas apakah bug termasuk ke dalam kategori mobile, backend auth, atau tim platform, bug tersebut akan terkirim ulang. Setiap kali terkirim ulang, konteksnya akan direset.
Perbedaan zona waktu memperparah masalah ini: bug yang dilaporkan pada akhir hari tanpa penanggung jawab yang jelas dapat kehilangan 12–24 jam sebelum seseorang mulai mereproduksi masalah tersebut. Definisi yang jelas tentang "siapa yang bertanggung jawab atas apa," dengan penanggung jawab piket atau DRI mingguan, menghilangkan ketidakpastian tersebut.
Reproduksibilitas bergantung pada observabilitas
Catatan log yang tidak lengkap, ID korelasi yang hilang, atau kurangnya jejak crash membuat diagnosis menjadi tebak-tebakan. Bug yang hanya muncul dengan bendera tertentu, tenant, atau bentuk data tertentu sulit untuk direproduksi di lingkungan pengembangan.
Jika insinyur tidak dapat mengakses data produksi yang disanitasi dengan aman, mereka akhirnya harus melakukan instrumentasi, redeploy, dan menunggu—berhari-hari alih-alih berjam-jam.
Keselarasan lingkungan dan data memastikan keakuratan data
“Berfungsi di mesin saya” biasanya berarti “data produksi berbeda.” Semakin jauh lingkungan pengembangan/staging Anda dari produksi (konfigurasi, layanan, versi pihak ketiga), semakin lama Anda akan menghabiskan waktu untuk mengejar masalah yang tidak terdeteksi. Snapshot data yang aman, skrip seeding, dan pemeriksaan kesesuaian dapat mengurangi kesenjangan tersebut.
Pekerjaan yang sedang berjalan (WIP) dan fokus meningkatkan throughput aktual
Tim yang kelebihan beban menarik terlalu banyak bug sekaligus, memecah perhatian mereka, dan bolak-balik antara tugas dan rapat. Perpindahan konteks menambah jam kerja yang tidak terlihat.
Batasan WIP yang terlihat dan kecenderungan untuk menyelesaikan pekerjaan yang sudah dimulai sebelum mengambil pekerjaan baru akan menurunkan median lebih cepat daripada upaya heroik tunggal.
Code review, CI, dan kecepatan QA adalah hambatan klasik
Waktu pembangunan yang lambat, tes yang tidak stabil, dan SLA tinjauan yang tidak jelas menghambat perbaikan yang seharusnya cepat. Sebuah patch yang seharusnya selesai dalam 10 menit bisa menghabiskan dua hari menunggu peninjau atau terjebak dalam pipeline yang memakan waktu berjam-jam.
Demikian pula, antrean QA yang melakukan pengujian batch atau bergantung pada pengujian manual dapat menambah waktu hingga satu hari pada tahap “Dilaporkan → Ditutup”, meskipun tahap “Dilaporkan → Diselesaikan” berjalan cepat.
Ketergantungan memperluas antrian
Perubahan lintas tim (perubahan skema, migrasi platform, pembaruan SDK), bug vendor, atau ulasan toko aplikasi (mobile) dapat menyebabkan penundaan. Tanpa pelacakan eksplisit "Diblokir/Ditunda", penundaan tersebut secara tidak terlihat meningkatkan rata-rata waktu penyelesaian dan menyembunyikan di mana bottleneck sebenarnya berada.
Model rilis dan strategi rollback sangat penting
Jika Anda melakukan rilis dalam batch besar dengan gerbang manual, bahkan bug yang sudah diselesaikan tetap menunggu hingga batch berikutnya diluncurkan. Fitur bendera fitur, rilis canary, dan jalur hotfix memperpendek waktu penyelesaian—terutama untuk insiden P0/P1—dengan memungkinkan Anda memisahkan deployment perbaikan dari siklus rilis penuh.
Arsitektur dan utang teknis menentukan batas atas Anda
Ketergantungan yang erat, kurangnya titik uji, dan modul warisan yang tidak transparan membuat perbaikan sederhana menjadi berisiko. Tim mengatasinya dengan pengujian tambahan dan tinjauan yang lebih lama, yang memperpanjang siklus. Sebaliknya, kode modular dengan uji kontrak yang baik memungkinkan Anda bergerak cepat tanpa merusak sistem yang berdekatan.
Komunikasi dan kebersihan status memengaruhi prediktabilitas
Pembaruan yang tidak jelas ("sedang ditangani") menyebabkan pekerjaan ulang saat pemangku kepentingan menanyakan perkiraan waktu penyelesaian (ETA), tim dukungan membuka kembali tiket, atau tim produk menaikkan prioritas. Transisi status yang jelas, catatan tentang reproduksi dan penyebab akar masalah, serta ETA yang dipublikasikan mengurangi churn dan melindungi fokus tim engineering Anda.
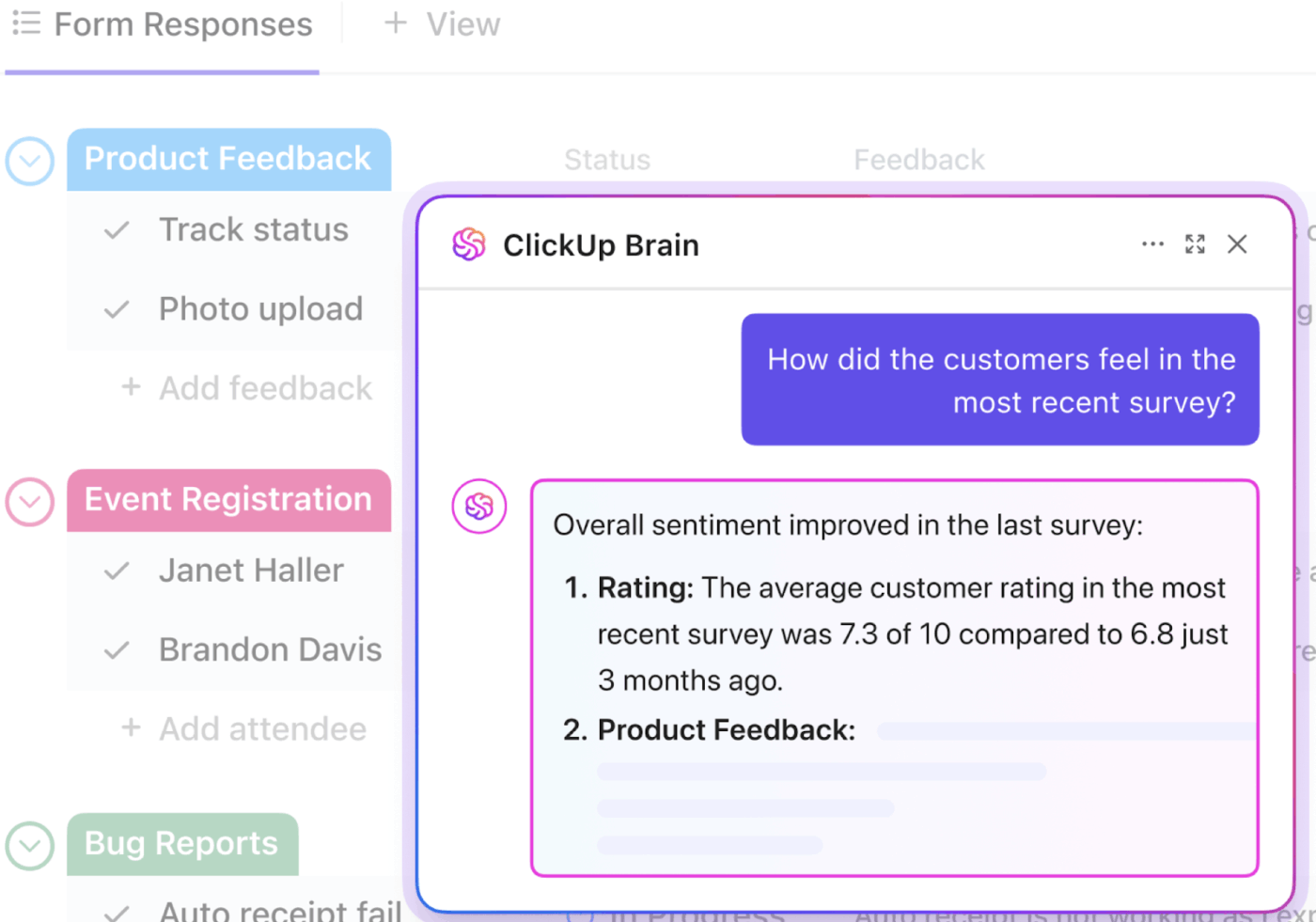
📮ClickUp Insight: Seorang profesional rata-rata menghabiskan lebih dari 30 menit setiap hari untuk mencari informasi terkait pekerjaan—itu berarti lebih dari 120 jam per tahun terbuang untuk menggali email, obrolan Slack, dan file yang tersebar.
Asisten AI cerdas yang terintegrasi dalam ruang kerja Anda dapat mengubah hal itu. Kenalkan ClickUp Brain. Ia memberikan wawasan dan jawaban instan dengan menampilkan dokumen, percakapan, dan detail tugas yang relevan dalam hitungan detik—sehingga Anda dapat berhenti mencari dan mulai bekerja.
💫 Hasil Nyata: Tim seperti QubicaAMF menghemat 5+ jam per minggu menggunakan ClickUp—itu setara dengan lebih dari 250 jam per tahun per orang—dengan menghilangkan proses manajemen pengetahuan yang usang. Bayangkan apa yang dapat tim Anda ciptakan dengan tambahan satu minggu produktivitas setiap kuartal!
Indikator utama bahwa waktu penyelesaian Anda akan molor
❗️Waktu untuk mengakui masalah meningkat dan banyak tiket tanpa pemilik selama lebih dari 12 jam
❗️Peningkatan "Waktu dalam Review/CI" dan kegagalan tes yang sering terjadi
❗️Tingkat duplikasi yang tinggi pada tahap penerimaan dan label tingkat keparahan yang tidak konsisten di antara tim
❗️Beberapa bug masih berada di status "Blocked" tanpa ketergantungan eksternal yang ditentukan
❗️Tingkat pembukaan ulang meningkat (perbaikan tidak dapat direproduksi atau definisi penyelesaian tidak jelas)
Organisasi yang berbeda merasakan faktor-faktor ini secara berbeda. Pimpinan eksekutif mengalaminya sebagai siklus pembelajaran yang terlewatkan dan keterlambatan dalam mencapai target pendapatan; sementara operator merasakannya sebagai kebisingan dalam proses triase dan ketidakjelasan tanggung jawab.
Menyesuaikan proses penerimaan, alur kerja, dan ketergantungan adalah cara untuk menurunkan seluruh kurva—median dan P90.
Ingin tahu lebih banyak tentang cara menulis laporan bug yang lebih baik? Mulai di sini. 👇🏼
📖 Baca Lebih Lanjut: Siklus Hidup Pengujian Perangkat Lunak (STLC): Gambaran Umum dan Fase-fase
Standar Industri untuk Waktu Penyelesaian Bug
Tolok ukur penyelesaian bug berubah sesuai dengan toleransi risiko, model rilis, dan seberapa cepat Anda dapat menerapkan perubahan.
Di sini Anda dapat menggunakan median (P50) untuk memahami alur kerja tipikal dan P90 untuk menetapkan janji dan SLA—berdasarkan tingkat keparahan dan sumber (pelanggan, QA, pemantauan).
Mari kita bahas apa artinya:
| 🔑 Istilah | 📝 Deskripsi | 💡 Mengapa hal ini penting |
|---|---|---|
| P50 (Median) | Nilai tengah—50% perbaikan bug lebih cepat dari ini, dan 50% lebih lambat | 👉 Mencerminkan waktu penyelesaian yang tipikal atau paling umum. Baik untuk memahami kinerja normal |
| P90 (Persentil ke-90) | 90% bug diselesaikan dalam waktu ini. Hanya 10% yang membutuhkan waktu lebih lama | 👉 Menunjukkan batas kasus terburuk (tetapi masih realistis). Berguna untuk menetapkan janji eksternal |
| SLAs (Perjanjian Tingkat Layanan) | Komitmen yang Anda buat—baik secara internal maupun kepada pelanggan—tentang seberapa cepat masalah akan ditangani | 👉 Contoh: “Kami menyelesaikan bug P1 dalam 48 jam, 90% dari waktu.” Membantu membangun kepercayaan dan akuntabilitas |
| Berdasarkan Tingkat Keparahan dan Sumber | Segmentasikan metrik Anda berdasarkan dua dimensi kunci: • Severity (misalnya, P0, P1, P2)• Sumber (misalnya, Pelanggan, QA, Pemantauan) | 👉 Memungkinkan pelacakan dan prioritas yang lebih akurat, sehingga bug kritis mendapatkan perhatian lebih cepat |
Di bawah ini adalah rentang acuan berdasarkan industri yang sering menjadi target tim yang sudah matang; gunakan sebagai titik awal, lalu sesuaikan dengan konteks Anda.
SaaS
Selalu aktif dan kompatibel dengan CI/CD, sehingga hotfixes sering dilakukan. Masalah kritis (P0/P1) sering ditargetkan untuk median di bawah satu hari kerja, dengan P90 dalam 24–48 jam. Masalah non-kritis (P2+) umumnya diselesaikan dalam median 3–7 hari, dengan P90 dalam 10–14 hari. Tim dengan fitur flag yang kuat dan uji otomatis cenderung mencapai waktu penyelesaian yang lebih cepat.
Platform e-commerce
Karena konversi dan alur keranjang belanja sangat kritis bagi pendapatan, standar yang diterapkan lebih tinggi. Masalah P0/P1 biasanya diatasi dalam hitungan jam (rollback, penandaan, atau konfigurasi) dan diselesaikan sepenuhnya pada hari yang sama; P90 biasanya diselesaikan pada akhir hari atau kurang dari 12 jam pada musim sibuk. Masalah P2+ biasanya diselesaikan dalam 2–5 hari, dengan P90 dalam 10 hari.
Perangkat lunak perusahaan
Validasi yang lebih ketat dan jendela perubahan pelanggan memperlambat ritme kerja. Untuk P0/P1, tim menargetkan solusi sementara dalam 4–24 jam dan perbaikan dalam 1–3 hari kerja; P90 dalam 5 hari kerja. Item P2+ sering digabungkan ke dalam rilis bertahap, dengan median 2–4 minggu tergantung pada jadwal implementasi pelanggan.
Aplikasi game dan seluler
Backend layanan langsung berperilaku seperti SaaS (bendera dan rollback dalam hitungan menit hingga jam; P90 pada hari yang sama). Pembaruan klien dibatasi oleh ulasan toko: P0/P1 sering menggunakan lever server-side secara langsung dan merilis patch klien dalam 1–3 hari; P90 dalam seminggu dengan ulasan dipercepat. Perbaikan P2+ umumnya dijadwalkan ke sprint berikutnya atau rilis konten.
Perbankan/Fintech
Gerbang risiko dan kepatuhan mendorong pola "mitigasi cepat, perubahan hati-hati". P0/P1 ditangani dengan cepat (pemberitahuan, rollback, pengalihan lalu lintas dalam hitungan menit hingga jam) dan diperbaiki sepenuhnya dalam 1–3 hari; P90 dalam seminggu, termasuk pengendalian perubahan. P2+ sering memakan waktu 2–6 minggu untuk melewati tinjauan keamanan, audit, dan CAB.
Jika angka-angka Anda berada di luar rentang ini, periksa kualitas penerimaan, rute/kepemilikan, tinjauan kode, dan throughput QA, serta persetujuan dependensi sebelum mengasumsikan "kecepatan engineering" adalah masalah utama.
🌼 Tahukah Anda: Menurut survei Stack Overflow tahun 2024, para pengembang semakin sering menggunakan AI sebagai asisten andalan mereka sepanjang perjalanan pengembangan kode. Sebanyak 82% menggunakan AI untuk menulis kode—sungguh kolaborator kreatif! Saat terjebak atau mencari solusi, 67,5% mengandalkan AI untuk mencari jawaban, dan lebih dari setengah (56,7%) mengandalkan AI untuk debugging dan mendapatkan bantuan.
Bagi sebagian orang, alat AI juga terbukti berguna untuk mendokumentasikan proyek (40,1%) dan bahkan menghasilkan data sintetis atau konten (34,8%). Penasaran dengan basis kode baru? Hampir sepertiga (30,9%) menggunakan AI untuk mempercepat proses adaptasi. Pengujian kode masih menjadi tugas manual bagi banyak orang, tetapi 27,2% telah mengadopsi AI di bidang ini. Area lain seperti tinjauan kode, perencanaan proyek, dan analitik prediktif memiliki tingkat adopsi AI yang lebih rendah, tetapi jelas bahwa AI secara bertahap terintegrasi ke setiap tahap pengembangan perangkat lunak.
📖 Baca Lebih Lanjut: Cara Menggunakan AI untuk Jaminan Kualitas
Cara Mengurangi Waktu Penyelesaian Bug
Kecepatan dalam penyelesaian bug bergantung pada pengurangan hambatan di setiap tahap serah terima, mulai dari penerimaan hingga rilis.
Keuntungan terbesar diperoleh dengan membuat 30 menit pertama lebih efisien (penerimaan yang bersih, penugasan yang tepat, prioritas yang benar), lalu mempercepat siklus yang mengikuti (reproduksi, tinjauan, verifikasi).
Berikut adalah sembilan strategi yang bekerja bersama sebagai satu sistem. AI mempercepat setiap langkah, dan alur kerja berjalan dengan rapi di satu tempat, sehingga eksekutif mendapatkan kepastian dan praktisi mendapatkan alur kerja yang lancar.
1. Sentralisasikan penerimaan dan tangkap konteks langsung dari sumbernya
Waktu penyelesaian bug menjadi lebih lama saat Anda harus merekonstruksi konteks dari obrolan Slack, tiket dukungan, dan spreadsheet. Salurkan semua laporan—dukungan, QA, pemantauan—ke dalam antrean tunggal dengan templat terstruktur yang mengumpulkan komponen, tingkat keparahan, lingkungan, versi/build aplikasi, langkah-langkah untuk mereproduksi, hasil yang diharapkan vs aktual, dan lampiran (log/HAR/screenshot).
AI dapat secara otomatis merangkum laporan panjang, mengekstrak langkah reproduksi dan detail lingkungan dari lampiran, serta menandai duplikat yang kemungkinan terjadi sehingga proses triase dimulai dengan catatan yang koheren dan terperinci.
Metrik yang perlu dipantau: MTTA (pengakuan dalam hitungan menit, bukan jam), tingkat duplikasi, waktu "Membutuhkan Informasi".

📖 Baca Lebih Lanjut: Kekuatan Formulir ClickUp: Memperlancar Pekerjaan Tim Perangkat Lunak
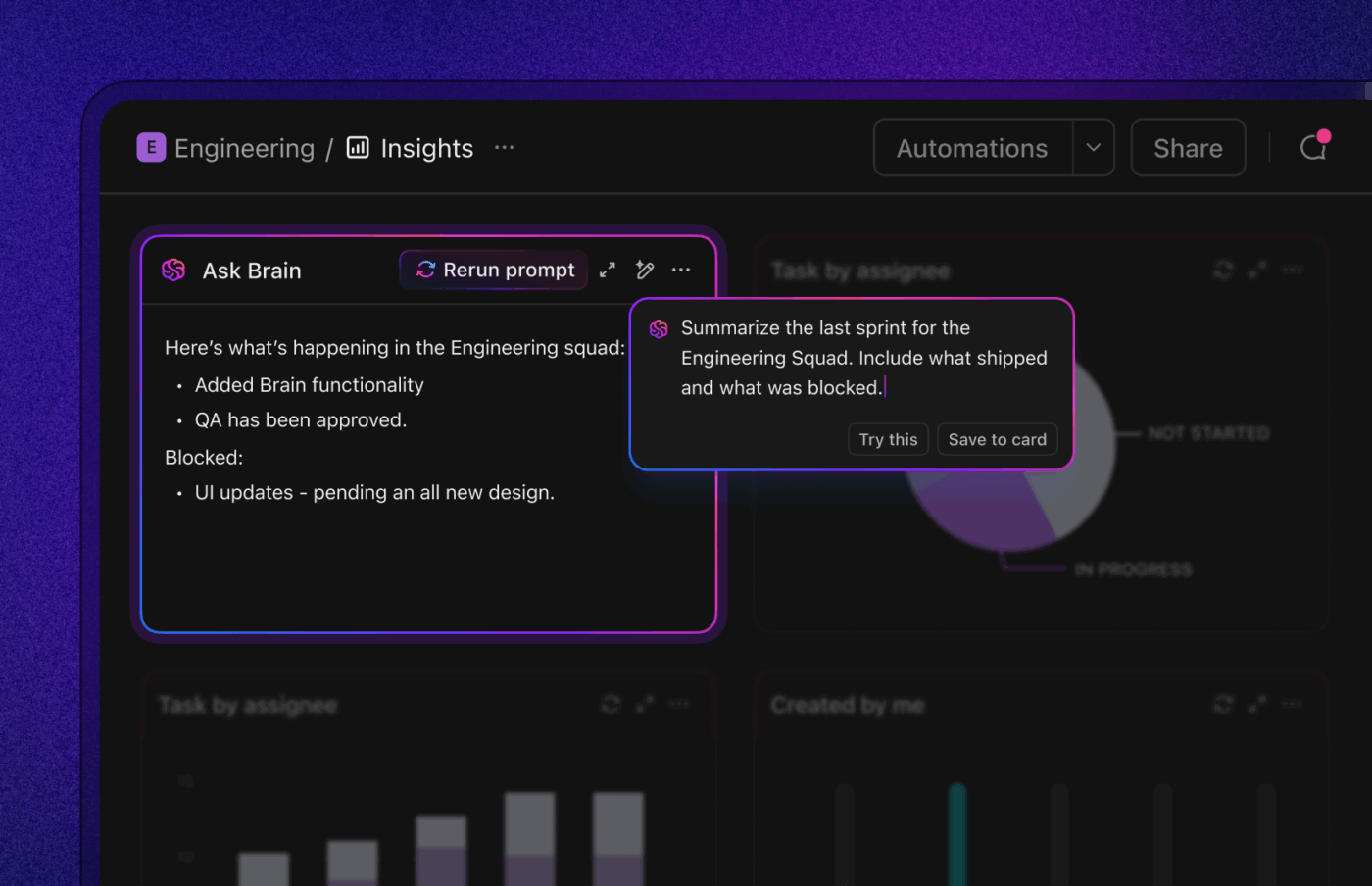
2. Triage dan pengalihan yang didukung AI untuk mengurangi MTTA
Perbaikan tercepat adalah yang langsung sampai ke meja yang tepat.
Gunakan aturan sederhana ditambah AI untuk mengklasifikasikan tingkat keparahan, mengidentifikasi pemilik yang kemungkinan bertanggung jawab berdasarkan komponen/area kode, dan otomatis menugaskan dengan jam SLA. Tetapkan jalur kerja yang jelas untuk P0/P1 versus yang lainnya dan pastikan "siapa yang bertanggung jawab" tidak ambigu.
Otomatisasi dapat menetapkan prioritas berdasarkan bidang, mengalihkan ke tim berdasarkan komponen, memulai timer SLA, dan memberitahu insinyur piket; AI dapat mengusulkan tingkat keparahan dan pemilik berdasarkan pola sebelumnya. Ketika triase menjadi proses 2–5 menit alih-alih debat 30 menit, MTTA Anda turun dan MTTR mengikuti.
Metrik yang perlu dipantau: MTTA, kualitas respons pertama (apakah komentar pertama meminta informasi yang tepat?), jumlah serah terima per bug.
Inilah gambaran praktisnya:
3. Prioritaskan berdasarkan dampak bisnis dengan tingkatan SLA yang jelas
“Suara paling keras yang menang” membuat antrean tidak dapat diprediksi dan merusak kepercayaan dengan eksekutif yang memantau CSAT/NPS dan perpanjangan langganan.
Ganti itu dengan skor yang menggabungkan tingkat keparahan, frekuensi, ARR yang terpengaruh, kritisitas fitur, dan kedekatan dengan perpanjangan/peluncuran—dan dukung dengan tingkatan SLA (misalnya, P0: mitigasi dalam 1–2 jam, penyelesaian dalam sehari; P1: pada hari yang sama; P2: dalam satu sprint).
Jaga jalur P0/P1 tetap terlihat dengan batasan WIP agar tidak ada yang terabaikan.
Metrik yang perlu dipantau: Tingkat penyelesaian P50/P90 per tingkatan, tingkat pelanggaran SLA, korelasi dengan CSAT/NPS.
💡Tips Pro: Fitur Prioritas Tugas, Bidang Kustom, dan Ketergantungan di ClickUp memungkinkan Anda menghitung skor dampak dan menghubungkan bug dengan akun, umpan balik, atau item roadmap; Selain itu, Tujuan di ClickUp membantu Anda menghubungkan kepatuhan SLA dengan tujuan perusahaan, yang secara langsung menjawab kekhawatiran eksekutif tentang keselarasan.
4. Jadikan reproduksi dan diagnosis sebagai aktivitas satu langkah
Setiap langkah tambahan dengan pertanyaan "Bisakah Anda mengirimkan log?" akan memperpanjang waktu penyelesaian.
Standarkan apa yang dimaksud dengan "baik": bidang yang wajib diisi untuk build/commit, lingkungan, langkah reproduksi, perbandingan antara yang diharapkan dan yang sebenarnya, serta lampiran untuk log, crash dump, dan file HAR. Pasang alat pemantauan telemetri klien/server agar ID crash dan ID permintaan dapat dihubungkan dengan jejak.
Gunakan Sentry (atau alat serupa) untuk melacak tumpukan (stack traces) dan hubungkan masalah tersebut langsung ke bug. AI dapat membaca log dan tumpukan untuk mengusulkan domain kesalahan yang kemungkinan besar dan menghasilkan reproduksi minimal, mengubah waktu yang dibutuhkan untuk menganalisis masalah menjadi beberapa menit kerja yang terfokus.
Simpan panduan langkah demi langkah (runbooks) untuk kategori bug umum agar insinyur tidak perlu memulai dari awal.
Metrik yang perlu diperhatikan: Waktu yang dihabiskan dalam status "Menunggu Informasi," persentase kasus yang dapat direproduksi pada percobaan pertama, dan tingkat pembukaan ulang yang terkait dengan ketidakmampuan mereproduksi kasus.
📖 Pelajari Lebih Lanjut: Cara Menggunakan AI dalam Pengembangan Perangkat Lunak (Kasus Penggunaan & Alat)
5. Perpendek siklus tinjauan kode dan pengujian
Pembaruan besar (Big PRs) sering terhambat. Fokus pada perbaikan yang tepat sasaran, pengembangan berbasis trunk, dan fitur flag agar perbaikan dapat dirilis dengan aman. Tetapkan reviewer secara otomatis berdasarkan kepemilikan kode untuk menghindari waktu idle, dan gunakan daftar periksa (tes diperbarui, telemetri ditambahkan, flag di belakang kill switch) agar kualitas terintegrasi sejak awal.
Otomatisasi harus memindahkan bug ke status "Dalam Peninjauan" saat pull request dibuka dan ke "Terselesaikan" saat merge; AI dapat menyarankan unit test atau menyoroti perbedaan kode yang berisiko untuk difokuskan dalam peninjauan.
Metrik yang perlu diperhatikan: Waktu di "In Review," tingkat kegagalan perubahan untuk pull request perbaikan bug, dan latensi ulasan P90.
Anda dapat menggunakan integrasi GitHub/GitLab di ClickUp untuk menjaga status penyelesaian tetap sinkron; Otomatisasi dapat memastikan penerapan "definisi selesai."
📖 Baca Lebih Lanjut: Cara Menggunakan AI untuk Otomatisasi Tugas
6. Paralelkan verifikasi dan jadikan kesetaraan lingkungan QA menjadi kenyataan
Verifikasi tidak boleh dimulai berhari-hari kemudian atau di lingkungan yang tidak digunakan oleh pelanggan Anda.
Jaga agar "siap untuk QA" tetap ketat: perbaikan darurat yang didorong oleh bendera diverifikasi di lingkungan yang mirip produksi dengan data sampel yang sesuai dengan kasus yang dilaporkan.
Jika memungkinkan, buat lingkungan sementara dari cabang bug agar QA dapat memvalidasi secara langsung; AI kemudian dapat menghasilkan kasus uji dari deskripsi bug dan regresi sebelumnya.
Metrik yang perlu diperhatikan: Waktu di "QA/Verifikasi," tingkat bounce dari QA kembali ke dev, waktu median untuk menutup setelah merge.

📖 Baca Lebih Lanjut: Cara Menulis Kasus Uji yang Efektif
7. Komunikasikan status dengan jelas untuk mengurangi beban koordinasi
Pembaruan yang baik mencegah tiga pemberitahuan status dan satu eskalasi.
Tangani pembaruan seperti produk: singkat, spesifik, dan disesuaikan dengan audiens (tim dukungan, eksekutif, pelanggan). Tetapkan jadwal untuk P0/P1 (misalnya, setiap jam hingga masalah teratasi, lalu setiap empat jam), dan jaga satu sumber kebenaran.
AI dapat menyusun pembaruan yang aman untuk pelanggan dan ringkasan internal dari riwayat tugas, termasuk status real-time berdasarkan tingkat keparahan dan tim. Bagi eksekutif seperti Direktur Produk Anda, naikkan bug ke inisiatif agar mereka dapat melihat apakah pekerjaan kualitas kritis mengancam janji pengiriman.
Metrik yang perlu dipantau: Waktu antara pembaruan status pada P0/P1, kepuasan pelanggan (CSAT) pemangku kepentingan terhadap komunikasi.
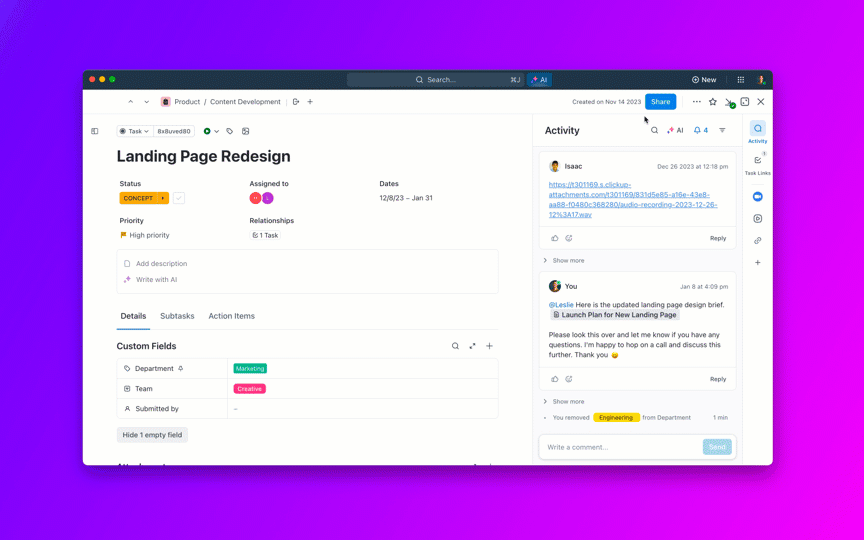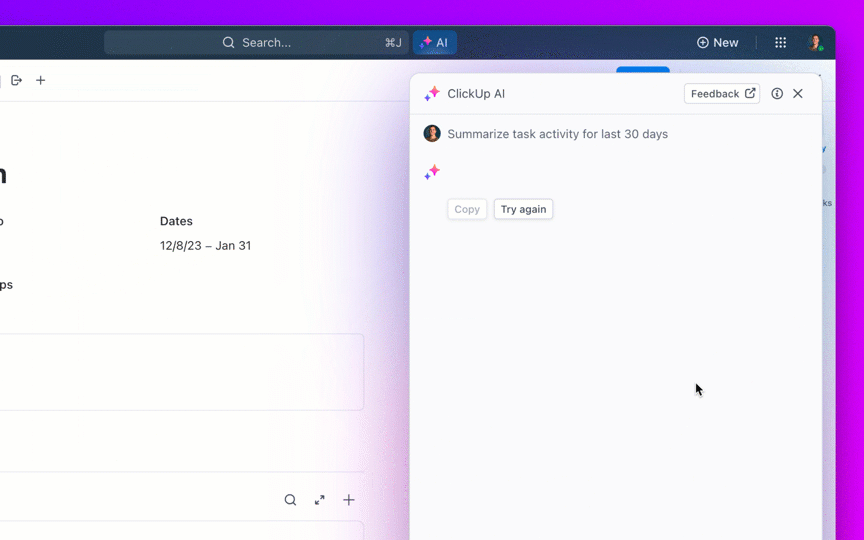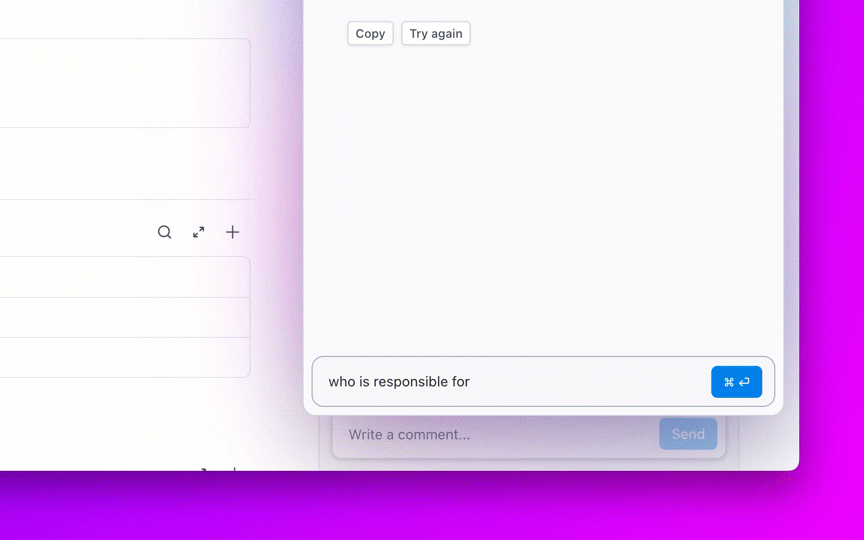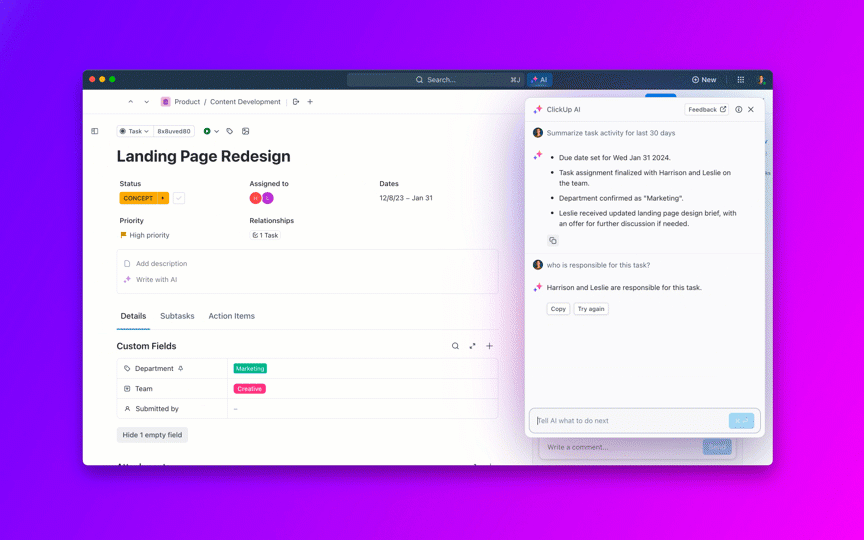
8. Kendalikan penumpukan tugas yang menumpuk dan hindari tugas yang "selalu terbuka"
Backlog yang terus bertambah dan menumpuk secara diam-diam membebani setiap sprint.
Tetapkan kebijakan penuaan (misalnya, P2 > 30 hari memicu tinjauan, P3 > 90 hari memerlukan justifikasi) dan jadwalkan triase penuaan mingguan untuk menggabungkan duplikat, menutup laporan yang sudah tidak relevan, dan mengubah bug bernilai rendah menjadi item backlog produk.
Gunakan AI untuk mengelompokkan backlog berdasarkan tema (misalnya, “kadaluwarsa token otentikasi,” “masalah unggah gambar yang tidak stabil”) sehingga Anda dapat menjadwalkan minggu perbaikan tematik dan menghilangkan kelas bug tertentu sekaligus.
Metrik yang perlu dipantau: jumlah backlog berdasarkan kategori usia, % masalah yang ditutup sebagai duplikat/usang, kecepatan penurunan tematik.
9. Tutup lingkaran dengan identifikasi akar masalah dan pencegahan
Jika jenis bug yang sama terus muncul kembali, perbaikan MTTR Anda mungkin menyembunyikan masalah yang lebih besar.
Lakukan analisis akar penyebab yang cepat dan tanpa menyalahkan pada P0/P1 dan P2 berfrekuensi tinggi; tandai akar penyebab (kekurangan spesifikasi, kekurangan pengujian, kekurangan alat, ketidakstabilan integrasi), hubungkan dengan komponen yang terpengaruh dan insiden, serta lacak tugas tindak lanjut (pengaman, pengujian, aturan lint) hingga selesai.
AI dapat menyusun ringkasan RCA dan mengusulkan tes pencegahan atau aturan lint berdasarkan riwayat perubahan. Dan begitulah cara Anda beralih dari pemadaman kebakaran ke lebih sedikit kebakaran.
Metrik yang perlu dipantau: Tingkat pembukaan ulang, tingkat regresi, waktu antara kejadian berulang, dan persentase RCAs dengan tindakan pencegahan yang telah diselesaikan.

Secara keseluruhan, perubahan ini memperpendek jalur end-to-end: pengakuan yang lebih cepat, triase yang lebih bersih, prioritas yang lebih cerdas, hambatan yang lebih sedikit dalam tinjauan dan QA, serta komunikasi yang lebih jelas. Pimpinan eksekutif mendapatkan kepastian yang terikat dengan CSAT/NPS dan pendapatan; praktisi mendapatkan antrean yang lebih tenang dengan perpindahan konteks yang lebih sedikit.
📖 Baca Lebih Lanjut: Cara Melakukan Analisis Penyebab Utama
Alat AI yang Membantu Mengurangi Waktu Penyelesaian Bug
AI dapat memangkas waktu penyelesaian di setiap tahap—penerimaan, triase, pengalihan, perbaikan, dan verifikasi.
Namun, manfaat sebenarnya baru terasa ketika alat-alat tersebut memahami konteks dan terus memajukan pekerjaan tanpa perlu intervensi manual.
Cari sistem yang secara otomatis memperkaya laporan (langkah reproduksi, lingkungan, duplikat), memprioritaskan berdasarkan dampak, mengalihkan ke pemilik yang tepat, menyusun pembaruan yang jelas, dan terintegrasi erat dengan kode, CI, dan observabilitas Anda.
Yang terbaik di antaranya juga mendukung alur kerja seperti agen: bot yang memantau SLA, mengingatkan reviewer, menaikkan prioritas item yang macet, dan merangkum hasil untuk pemangku kepentingan. Berikut ini adalah kumpulan alat AI kami untuk penyelesaian bug yang lebih baik:
1. ClickUp (Terbaik untuk AI kontekstual, otomatisasi, dan alur kerja agen)
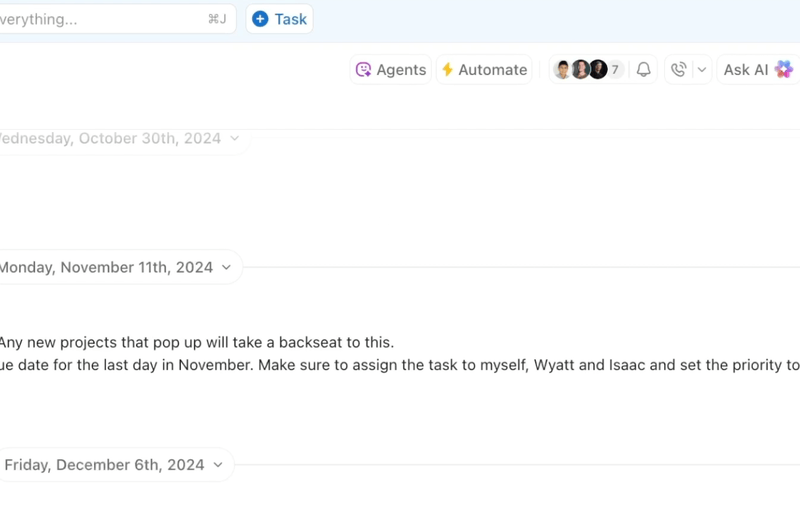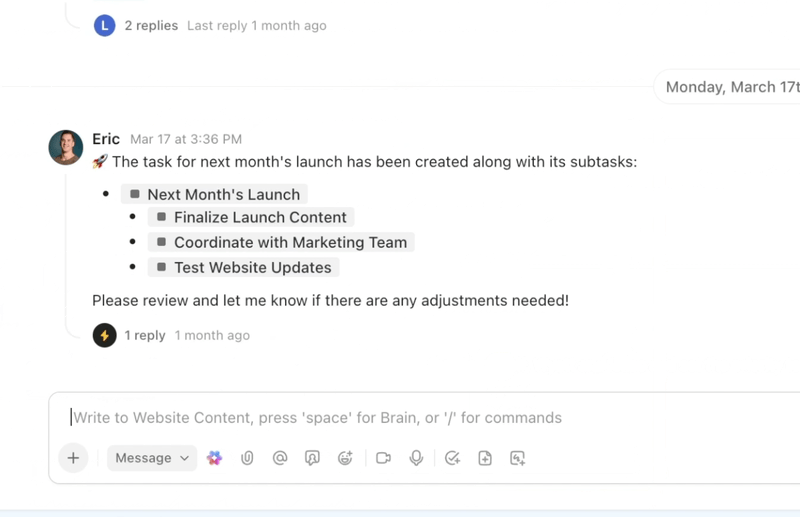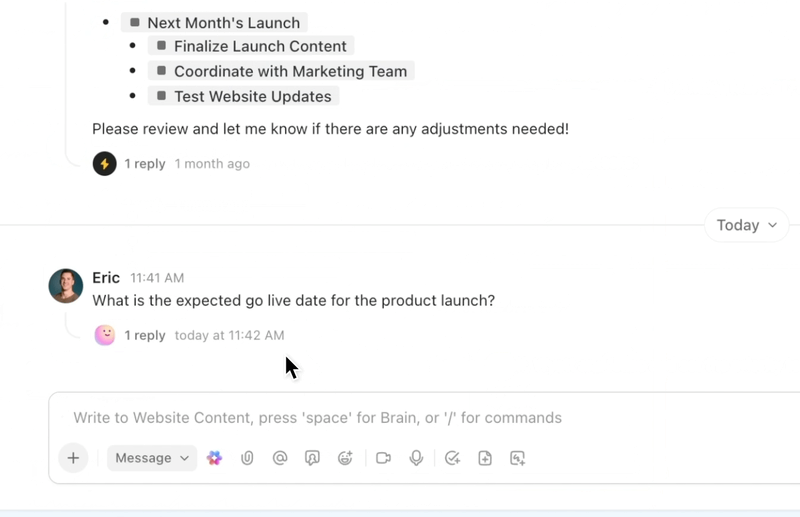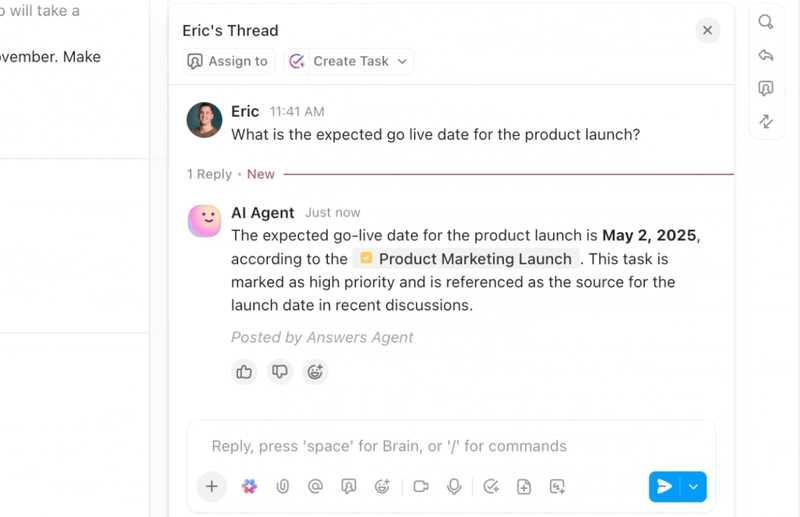
Jika Anda ingin alur kerja penyelesaian bug yang efisien dan cerdas, ClickUp, aplikasi serba bisa untuk kerja, menggabungkan AI, otomatisasi, dan bantuan alur kerja yang fleksibel dalam satu platform.
ClickUp Brain menampilkan konteks yang tepat secara instan—merangkum thread bug yang panjang, mengekstrak langkah-langkah untuk mereproduksi bug dan detail lingkungan dari lampiran, menandai duplikat yang kemungkinan besar, dan menyarankan tindakan selanjutnya. Alih-alih harus menelusuri Slack, tiket, dan log, tim mendapatkan catatan yang bersih dan terperinci yang dapat langsung ditindaklanjuti.
Otomatisasi dan Agen Autopilot di ClickUp memastikan pekerjaan terus berjalan tanpa perlu pengawasan terus-menerus. Bug secara otomatis diarahkan ke tim yang tepat, pemilik tugas ditugaskan, SLA dan tenggat waktu ditetapkan, status diperbarui seiring kemajuan pekerjaan, dan pemangku kepentingan menerima notifikasi tepat waktu.

Agen-agen ini bahkan dapat melakukan triase dan mengkategorikan masalah, mengelompokkan laporan serupa, merujuk pada perbaikan historis untuk menyarankan langkah-langkah yang mungkin, dan menaikkan prioritas item mendesak—sehingga MTTA dan MTTR tetap rendah bahkan saat volume meningkat.
🛠️ Ingin alat siap pakai? Template Pelacakan Bug dan Masalah ClickUp adalah solusi kuat dari ClickUp untuk Perangkat Lunak yang dirancang untuk membantu tim Dukungan, Teknik, dan Produk mengelola bug dan masalah perangkat lunak dengan mudah. Dengan tampilan yang dapat disesuaikan seperti Daftar, Papan, Beban Kerja, Formulir, dan Garis Waktu, tim dapat memvisualisasikan dan mengelola proses pelacakan bug sesuai dengan kebutuhan mereka.
Template ini dilengkapi dengan 20 Status Kustom dan 7 Bidang Kustom, memungkinkan alur kerja yang disesuaikan, memastikan setiap masalah dilacak dari penemuan hingga penyelesaian. Otomatisasi bawaan menangani tugas-tugas berulang, menghemat waktu berharga dan mengurangi upaya manual.
💟 Bonus: Brain MAX adalah asisten desktop bertenaga AI yang dirancang untuk mempercepat penyelesaian bug dengan fitur-fitur cerdas dan praktis.
Saat Anda menemui bug, cukup gunakan fitur talk-to-text Brain MAX untuk mendiktekan masalah—catatan suara Anda akan langsung ditranskrip dan dapat dilampirkan ke tiket bug baru atau yang sudah ada. Fitur Enterprise Search-nya akan mencari melalui semua alat terhubung Anda—seperti ClickUp, GitHub, Google Drive, dan Slack—untuk menampilkan laporan bug terkait, log kesalahan, potongan kode, dan dokumentasi, sehingga Anda memiliki semua konteks yang dibutuhkan tanpa perlu beralih aplikasi.
Perlu mengkoordinasikan perbaikan? Brain MAX memungkinkan Anda menugaskan bug ke pengembang yang tepat, mengatur pengingat otomatis untuk pembaruan status, dan melacak kemajuan—semua dari desktop Anda!
2. Sentry (Terbaik untuk menangkap kesalahan)
Sentry mengurangi MTTD dan waktu reproduksi dengan menangkap kesalahan, jejak, dan sesi pengguna di satu tempat. Pengelompokan masalah berbasis AI mengurangi kebisingan; aturan "Suspect Commit" dan kepemilikan mengidentifikasi pemilik kode yang kemungkinan besar, sehingga pengalihan menjadi instan. Session Replay memberikan insinyur jalur pengguna yang tepat dan detail konsol/jaringan untuk mereproduksi tanpa perlu bolak-balik berulang kali.
Fitur AI Sentry dapat merangkum konteks masalah dan, pada beberapa stack, mengusulkan tambalan Autofix yang merujuk pada kode yang bermasalah. Dampak praktisnya: lebih sedikit tiket duplikat, penugasan yang lebih cepat, dan jalur yang lebih singkat dari laporan hingga tambalan yang berfungsi.
3. GitHub Copilot (Terbaik untuk meninjau kode lebih cepat)
Copilot mempercepat siklus perbaikan di dalam editor. Ia menjelaskan tumpukan kesalahan, menyarankan tambalan yang tepat, menulis uji unit untuk mengunci perbaikan, dan membuat skrip reproduksi.
Copilot Chat dapat menganalisis kode yang bermasalah, mengusulkan refaktorisasi yang lebih aman, dan menghasilkan komentar atau deskripsi pull request yang mempercepat proses tinjauan kode. Dengan integrasi tinjauan wajib dan CI, hal ini menghemat waktu dari "diagnosis → implementasi → pengujian," terutama untuk bug yang terdefinisi dengan jelas dan memiliki reproduksi yang mudah.
4. Snyk by DeepCode AI (Terbaik untuk mengidentifikasi pola)
DeepCode’s AI-powered static analysis mendeteksi cacat dan pola yang tidak aman saat Anda mengode dan dalam PR. Ia menyoroti alur yang bermasalah, menjelaskan mengapa hal itu terjadi, dan mengusulkan perbaikan aman yang sesuai dengan gaya pemrograman kode Anda.
Dengan mendeteksi regresi sebelum penggabungan dan mengarahkan pengembang ke pola yang lebih aman, Anda dapat mengurangi tingkat kedatangan bug baru dan mempercepat perbaikan kesalahan logika yang sulit terdeteksi dalam tinjauan. Integrasi IDE dan PR memastikan proses ini tetap dekat dengan tempat kerja.
5. Datadog’s Watchdog dan AIOps (Terbaik untuk analisis log)
Datadog’s Watchdog menggunakan ML untuk mengidentifikasi anomali di seluruh log, metrik, jejak, dan pemantauan pengguna nyata. Ia mengkorelasikan lonjakan dengan penanda deployment, perubahan infrastruktur, dan topologi untuk menyarankan penyebab akar yang kemungkinan besar.
Untuk bug yang berdampak pada pelanggan, hal ini berarti deteksi dalam hitungan menit, pengelompokan otomatis untuk mengurangi kebisingan notifikasi, dan petunjuk konkret tentang di mana harus mencari. Waktu triase berkurang karena Anda mulai dengan "deploy ini mempengaruhi layanan ini dan tingkat kesalahan meningkat di endpoint ini" daripada memulai dari nol.
⚡️ Arsip Template: Template Pelacakan Masalah & Log Gratis dalam Excel & ClickUp
6. New Relic AI (Terbaik untuk mengidentifikasi dan merangkum tren)
New Relic’s Errors Inbox mengelompokkan kesalahan serupa di seluruh layanan dan versi, sementara asisten AI-nya merangkum dampak, menyoroti penyebab kemungkinan, dan menghubungkan ke jejak/transaksi yang terlibat.
Korelasi deployment dan kecerdasan perubahan entitas membuatnya jelas kapan rilis terbaru menjadi penyebabnya. Untuk sistem terdistribusi, konteks ini menghemat jam-jam komunikasi antar tim dan memastikan bug sampai ke pemilik yang tepat dengan hipotesis yang sudah terbentuk.
7. Rollbar (Terbaik untuk alur kerja otomatis)
Rollbar spesialis dalam pemantauan kesalahan real-time dengan pemindaian sidik jari cerdas untuk mengelompokkan duplikat dan melacak tren kemunculan. Ringkasan berbasis AI dan petunjuk akar masalahnya membantu tim memahami cakupan (pengguna yang terpengaruh, versi yang terdampak), sementara data telemetri dan jejak tumpukan memberikan petunjuk reproduksi cepat.
Aturan alur kerja Rollbar dapat secara otomatis membuat tugas, menandai tingkat keparahan, dan mengalihkan ke pemilik yang bertanggung jawab, mengubah aliran kesalahan yang berisik menjadi antrean prioritas dengan konteks yang terhubung.
8. PagerDuty AIOps dan otomatisasi runbook (Pilihan terbaik untuk diagnostik dengan intervensi minimal)
PagerDuty menggunakan korelasi peristiwa dan pengurangan kebisingan berbasis ML untuk menggabungkan badai peringatan menjadi insiden yang dapat ditindaklanjuti.
Routing dinamis memastikan masalah langsung diteruskan ke tim yang bertugas, sementara otomatisasi runbook dapat memicu diagnostik atau mitigasi (me-restart layanan, roll back deployment, atau mengaktifkan/menonaktifkan fitur) sebelum intervensi manusia. Untuk waktu penyelesaian bug, hal ini berarti MTTA yang lebih singkat, mitigasi lebih cepat untuk P0, dan lebih sedikit waktu yang terbuang akibat kelelahan akibat notifikasi.
Inti dari pendekatan ini adalah otomatisasi dan AI di setiap langkah. Anda mendeteksi masalah lebih awal, mengalihkan tugas dengan lebih cerdas, mencapai kode lebih cepat, dan berkomunikasi tentang status tanpa menghambat para insinyur—semua hal ini berkontribusi pada pengurangan waktu penyelesaian bug yang signifikan.
📖 Baca Lebih Lanjut: Cara Menggunakan AI dalam DevOps
Contoh Nyata Penggunaan AI dalam Penyelesaian Bug
Jadi, AI kini resmi keluar dari laboratorium. AI sedang mengurangi waktu penyelesaian bug di dunia nyata.
Mari kita lihat caranya!
| Domain / Organisasi | Bagaimana AI digunakan | Dampak / Manfaat |
|---|---|---|
| Ubisoft | Mengembangkan Commit Assistant, alat AI yang dilatih menggunakan data kode internal selama satu dekade, yang memprediksi dan mencegah bug pada tahap pengkodean. | Tujuan utamanya adalah untuk secara drastis mengurangi waktu dan biaya—hingga 70% dari biaya pengembangan game secara tradisional dihabiskan untuk perbaikan bug. |
| Razer (Platform Wyvrn) | Diluncurkan AI-powered QA Copilot (terintegrasi dengan Unreal dan Unity) untuk mengotomatisasi deteksi bug dan menghasilkan laporan QA. | Meningkatkan deteksi bug hingga 25% dan memangkas waktu QA menjadi setengah. |
| Google / DeepMind & Project Zero | Perkenalkan Big Sleep, alat AI yang secara otomatis mendeteksi kerentanan keamanan dalam perangkat lunak open-source seperti FFmpeg dan ImageMagick. | Telah diidentifikasi 20 bug, semuanya diverifikasi oleh ahli manusia dan dijadwalkan untuk diperbaiki. |
| Peneliti UC Berkeley | Menggunakan benchmark bernama CyberGym, model AI menganalisis 188 proyek open-source, mengidentifikasi 17 kerentanan—termasuk 15 kerentanan "zero-day" yang belum diketahui—dan menghasilkan eksploit proof-of-concept. | Menunjukkan kemampuan AI yang terus berkembang dalam deteksi kerentanan dan pengujian otomatis terhadap eksploitasi. |
| Spur (Startup Yale) | Mengembangkan agen AI yang menerjemahkan deskripsi kasus uji dalam bahasa biasa menjadi rutinitas pengujian situs web otomatis — secara efektif merupakan alur kerja QA yang menulis sendiri. | Memungkinkan pengujian otomatis dengan input manusia minimal |
| Laporan Bug Android yang Dapat Direproduksi Secara Otomatis | Menggunakan NLP (Pemrosesan Bahasa Alami) dan reinforcement learning untuk menginterpretasikan bahasa laporan bug dan menghasilkan langkah-langkah untuk mereproduksi bug Android. | Mencapai akurasi 67%, recall 77%, dan mereproduksi 74% laporan bug, melebihi metode tradisional. |
Kesalahan Umum dalam Mengukur Waktu Penyelesaian Bug
Jika pengukuran Anda tidak akurat, rencana perbaikan Anda juga akan tidak akurat.
Sebagian besar "angka buruk" dalam alur kerja penyelesaian bug berasal dari definisi yang tidak jelas, alur kerja yang tidak konsisten, dan analisis yang dangkal.
Mulailah dengan dasar-dasarnya terlebih dahulu—apa yang dianggap sebagai awal/akhir, bagaimana Anda menangani penundaan dan pembukaan ulang—lalu baca data sebagaimana pelanggan Anda mengalaminya. Hal ini termasuk:
❌ Batasan yang tidak jelas: Campur aduk antara "Dilaporkan → Selesai" dan "Dilaporkan → Ditutup" dalam dasbor yang sama (atau berganti bulan setiap bulan) membuat tren menjadi tidak berarti. Pilih satu batasan, dokumentasikan, dan terapkan secara konsisten di seluruh tim. Jika Anda membutuhkan keduanya, publikasikan sebagai metrik terpisah dengan label yang jelas.
❌ Pendekatan berbasis rata-rata: Mengandalkan rata-rata menyembunyikan kenyataan antrian dengan beberapa kasus yang memakan waktu lama. Gunakan median (P50) untuk waktu "tipikal", P90 untuk prediktabilitas/SLAs, dan simpan rata-rata untuk perencanaan kapasitas. Selalu perhatikan distribusi, bukan hanya angka tunggal.
❌ Tidak ada segmentasi: Menggabungkan semua bug bersama-sama mencampurkan insiden P0 dengan bug kosmetik P3. Segmentasikan berdasarkan tingkat keparahan, sumber (pelanggan vs. QA vs. pemantauan), komponen/tim, dan "baru vs. regresi". P0/P1 P90 adalah apa yang dirasakan oleh pemangku kepentingan; median P2+ adalah apa yang direncanakan oleh tim teknik.
❌ Mengabaikan waktu "terhenti": Menunggu log pelanggan, vendor eksternal, atau jendela rilis? Jika Anda tidak melacak status "Terblokir/Terhenti" sebagai status utama, waktu penyelesaian Anda akan menjadi bahan perdebatan. Laporkan baik waktu kalender maupun waktu aktif agar bottleneck terlihat dan perdebatan berhenti.
❌ Kesenjangan normalisasi waktu: Campur aduk zona waktu atau beralih antara jam kerja dan jam kalender di tengah proses akan merusak perbandingan. Normalisasikan cap waktu ke satu zona (atau UTC) dan tentukan sekali apakah SLA diukur dalam jam kerja atau jam kalender; terapkan secara konsisten.
❌ Intake yang tidak rapi dan duplikat: Informasi lingkungan/build yang hilang dan tiket duplikat memperpanjang waktu penyelesaian dan membingungkan penanggung jawab. Standarkan bidang yang diperlukan saat intake, perbarui secara otomatis (log, versi, perangkat), dan hapus duplikat tanpa mereset waktu—tutup duplikat sebagai tiket tertaut, bukan "tiket baru".
❌ Model status yang tidak konsisten: Status kustom (“QA Ready-ish,” “Pending Review 2”) menyembunyikan waktu yang dihabiskan dalam status dan membuat transisi status tidak dapat diandalkan. Tetapkan alur kerja standar (Baru → Ditriage → Dalam Proses → Dalam Review → Selesai → Ditutup) dan audit untuk status yang tidak sesuai alur.
❌ Tidak mengetahui waktu dalam status: Angka "waktu total" tunggal tidak dapat menunjukkan di mana pekerjaan terhenti. Catat dan tinjau waktu yang dihabiskan dalam status Triaged, In Review, Blocked, dan QA. Jika P90 tinjauan kode jauh lebih besar daripada implementasi, perbaikan Anda bukan "menulis kode lebih cepat"—melainkan membebaskan kapasitas tinjauan.
🧠 Fakta Menarik: Tantangan AI Cyber terbaru DARPA menampilkan lompatan signifikan dalam otomatisasi keamanan siber. Kompetisi ini menampilkan sistem AI yang dirancang untuk secara otomatis mendeteksi, mengeksploitasi, dan memperbaiki kerentanan dalam perangkat lunak—tanpa campur tangan manusia. Tim pemenang, “Team Atlanta,” berhasil mengidentifikasi 77% dari bug yang disuntikkan dan memperbaiki 61% di antaranya, menunjukkan kekuatan AI tidak hanya dalam menemukan kelemahan tetapi juga memperbaikinya secara aktif.
❌ Kebutaan terhadap pembukaan ulang: Menganggap pembukaan ulang sebagai bug baru akan mereset waktu dan membuat MTTR terlihat lebih baik. Pantau Tingkat Pembukaan Ulang dan "waktu hingga penutupan stabil" (dari laporan pertama hingga penutupan akhir di semua siklus). Peningkatan pembukaan ulang biasanya menandakan reproduksi yang lemah, celah dalam pengujian, atau definisi "selesai" yang tidak jelas.
❌ Tidak ada MTTA: Tim terlalu fokus pada MTTR dan mengabaikan MTTA (waktu pengakuan/penanganan). MTTA yang tinggi merupakan tanda peringatan dini untuk penyelesaian yang lama. Ukur MTTA, tetapkan SLAs berdasarkan tingkat keparahan, dan otomatiskan rute/eskalasi untuk menjaga MTTA tetap rendah.
❌ AI/otomatisasi tanpa batasan: Membiarkan AI menentukan tingkat keparahan atau menutup duplikat tanpa tinjauan dapat menyebabkan klasifikasi yang salah pada kasus tepi dan secara diam-diam memengaruhi metrik. Gunakan AI untuk saran, wajibkan konfirmasi manusia pada P0/P1, dan audit kinerja model setiap bulan agar data tetap dapat diandalkan.
Perketat area-area ini, dan grafik waktu penyelesaian Anda akhirnya akan mencerminkan kenyataan. Dari sana, perbaikan akan berlipat ganda: penerimaan yang lebih baik mengurangi MTTA, status yang lebih bersih mengungkap bottleneck yang sebenarnya, dan P90 yang terpisah memberikan janji kepada pemimpin yang dapat Anda penuhi.
⚡️ Arsip Template: 10 Template Kasus Uji untuk Pengujian Perangkat Lunak
Praktik Terbaik untuk Penyelesaian Bug yang Lebih Baik
Untuk ringkasannya, berikut adalah poin-poin penting yang perlu diingat!
| 🧩 Praktik terbaik | 💡 Apa artinya | 🚀 Mengapa hal ini penting |
| Gunakan sistem pelacakan bug yang andal | Lacak semua bug yang dilaporkan menggunakan sistem pelacakan bug terpusat. | Memastikan tidak ada bug yang terlewat dan memungkinkan visibilitas status bug di seluruh tim. |
| Tulis laporan bug yang detail | Sertakan konteks visual, informasi sistem operasi, langkah-langkah untuk mereproduksi, dan tingkat keparahan. | Membantu pengembang memperbaiki bug lebih cepat dengan semua informasi penting yang tersedia di awal. |
| Klasifikasikan & prioritaskan bug | Gunakan matriks prioritas untuk mengurutkan bug berdasarkan urgensi dan dampak. | Memfokuskan tim pada bug kritis dan masalah mendesak terlebih dahulu. |
| Manfaatkan pengujian otomatis | Jalankan tes secara otomatis dalam pipeline CI/CD Anda. | Mendukung deteksi dini dan mencegah regresi. |
| Tentukan pedoman pelaporan yang jelas | Sediakan templat dan pelatihan tentang cara melaporkan bug. | Menghasilkan informasi yang akurat dan komunikasi yang lebih lancar. |
| Pantau metrik kunci | Ukur waktu penyelesaian, waktu yang telah berlalu, dan waktu respons. | Memungkinkan pelacakan dan peningkatan kinerja menggunakan data historis. |
| Gunakan pendekatan proaktif | Jangan tunggu pengguna mengeluh—lakukan pengujian secara proaktif. | Meningkatkan kepuasan pelanggan dan mengurangi beban dukungan. |
| Manfaatkan alat cerdas & ML | Gunakan machine learning untuk memprediksi bug dan menyarankan perbaikan. | Meningkatkan efisiensi dalam mengidentifikasi akar masalah dan memperbaiki bug. |
| Sesuaikan dengan SLAs | Penuhi perjanjian tingkat layanan (SLA) yang telah disepakati untuk penyelesaian. | Membangun kepercayaan dan memenuhi harapan klien secara tepat waktu. |
| Review dan tingkatkan secara berkelanjutan | Analisis bug yang dibuka kembali, kumpulkan umpan balik, dan sesuaikan proses. | Mendorong peningkatan berkelanjutan dalam proses pengembangan dan manajemen bug Anda. |
Penyelesaian Bug yang Sederhana dengan AI Kontekstual
Tim penyelesaian bug tercepat tidak mengandalkan tindakan heroik. Mereka merancang sistem: definisi awal/akhir yang jelas, proses penerimaan yang bersih, prioritas berdasarkan dampak bisnis, tanggung jawab yang jelas, dan umpan balik yang cepat di seluruh tim dukungan, QA, engineering, dan rilis.
ClickUp dapat menjadi pusat komando bertenaga AI untuk sistem penyelesaian bug Anda. Sentralisasikan semua laporan ke dalam satu antrean, standarkan konteks dengan bidang terstruktur, dan biarkan AI ClickUp melakukan triase, ringkasan, dan prioritaskan sementara otomatisasi menegakkan SLAs, menaikkan tingkat prioritas saat tenggat waktu terlewat, dan menjaga semua pemangku kepentingan tetap selaras. Hubungkan bug dengan pelanggan, kode, dan rilis sehingga eksekutif dapat melihat dampak dan praktisi tetap fokus pada tugas.
Jika Anda siap untuk mengurangi waktu penyelesaian bug dan membuat roadmap Anda lebih dapat diprediksi, daftar ke ClickUp dan mulailah mengukur peningkatan dalam hitungan hari—bukan kuartal.
Pertanyaan yang Sering Diajukan
Apa yang dimaksud dengan waktu penyelesaian bug yang baik?
Tidak ada angka "baik" yang tunggal—hal ini bergantung pada tingkat keparahan, model rilis, dan toleransi risiko. Gunakan median (P50) untuk kinerja "tipikal" dan P90 untuk janji/SLA, serta segmentasi berdasarkan tingkat keparahan dan sumber.
Apa perbedaan antara penyelesaian bug dan penutupan bug?
Resolusi terjadi ketika perbaikan diterapkan (misalnya, kode digabungkan, konfigurasi diterapkan) dan tim menganggap bug telah ditangani. Penutupan terjadi ketika masalah diverifikasi dan secara resmi diselesaikan (misalnya, QA diverifikasi di lingkungan target, dirilis, atau ditandai sebagai "tidak akan diperbaiki/duplikat" dengan alasan). Banyak tim mengukur keduanya: Dilaporkan→Diselesaikan mencerminkan kecepatan engineering; Dilaporkan→Ditutup mencerminkan alur kualitas end-to-end. Gunakan definisi yang konsisten agar dashboard tidak mencampurkan tahap-tahap.
Apa perbedaan antara waktu penyelesaian bug dan waktu deteksi bug?
Waktu deteksi (MTTD) adalah waktu yang dibutuhkan untuk menemukan bug setelah terjadi atau dirilis—melalui pemantauan, QA, atau pengguna. Waktu penyelesaian adalah waktu yang dibutuhkan untuk beralih dari deteksi/laporan hingga perbaikan diterapkan (dan, jika diinginkan, diverifikasi/dirilis). Bersama-sama, keduanya mendefinisikan jendela dampak pelanggan: deteksi cepat, akui cepat, selesaikan cepat, dan rilis dengan aman. Anda juga dapat melacak MTTA (waktu untuk mengakui/menugaskan) untuk mengidentifikasi penundaan triase yang sering kali menandakan waktu penyelesaian yang lebih lama.
Bagaimana AI membantu dalam penyelesaian bug?
AI mempercepat proses yang biasanya memakan waktu: penerimaan, triase, diagnosis, perbaikan, dan verifikasi.
- Penerimaan dan triase: Otomatis merangkum laporan panjang, mengekstrak langkah reproduksi/lingkungan, menandai duplikat, dan menyarankan tingkat keparahan/prioritas sehingga insinyur dapat memulai dengan konteks yang jelas (misalnya, ClickUp AI, Sentry AI).
- Routing dan SLAs: Memprediksi komponen/pemilik yang paling mungkin, menetapkan timer, dan menaikkan tingkat prioritas saat MTTA atau waktu tunggu ulasan melebihi batas—mengurangi waktu idle "waktu dalam status" (ClickUp Automations dan alur kerja seperti agen).
- Diagnosis: Mengelompokkan kesalahan serupa, mengkorelasikan lonjakan dengan commit/rilis terbaru, dan menunjuk ke penyebab akar yang kemungkinan besar dengan jejak tumpukan dan konteks kode (Sentry AI dan sejenisnya).
- Implementasi: Menyarankan perubahan kode dan pengujian berdasarkan pola dari repositori Anda, mempercepat siklus "tulis/perbaiki" (GitHub Copilot; Snyk Code AI oleh DeepCode).
- Verifikasi dan komunikasi: menulis kasus uji dari langkah reproduksi, menyusun catatan rilis dan pembaruan untuk pemangku kepentingan, serta merangkum status untuk eksekutif dan pelanggan (ClickUp AI). Digunakan bersama-sama—ClickUp sebagai pusat komando dengan Sentry/Copilot/DeepCode dalam stack—tim dapat mengurangi waktu MTTA/P90 tanpa mengandalkan tindakan heroik.