
Die meisten Teams, die sich mit Open-Source-KI-Modellen beschäftigen, stellen fest, dass Meta's LLaMA eine seltene Kombination aus Leistung und Flexibilität bietet, aber das Setup kann sich wie das Zusammenbauen von Möbeln ohne Anleitung anfühlen.
Dieser Leitfaden führt Sie durch die Erstellung eines funktionsfähigen LLaMA-Chatbots von Grund auf und behandelt Alles von den Hardwareanforderungen und dem Modellzugriff bis hin zu Prompt-Engineering und Bereitstellungsstrategien.
Legen wir los!
Was ist LLaMA und warum sollte man es für Chatbots verwenden?
Wenn Sie einen Chatbot mit proprietären APIs erstellen, haben Sie oft das Gefühl, an das System eines anderen Anbieters gebunden zu sein, mit unvorhersehbaren Kosten und Fragen zum Datenschutz konfrontiert zu sein. Diese Bindung an einen Anbieter bedeutet, dass Sie das Modell nicht wirklich benutzerdefiniert an die individuellen Bedürfnisse Ihres Teams anpassen können, was zu generischen Antworten und potenziellen Compliance-Problemen führt.
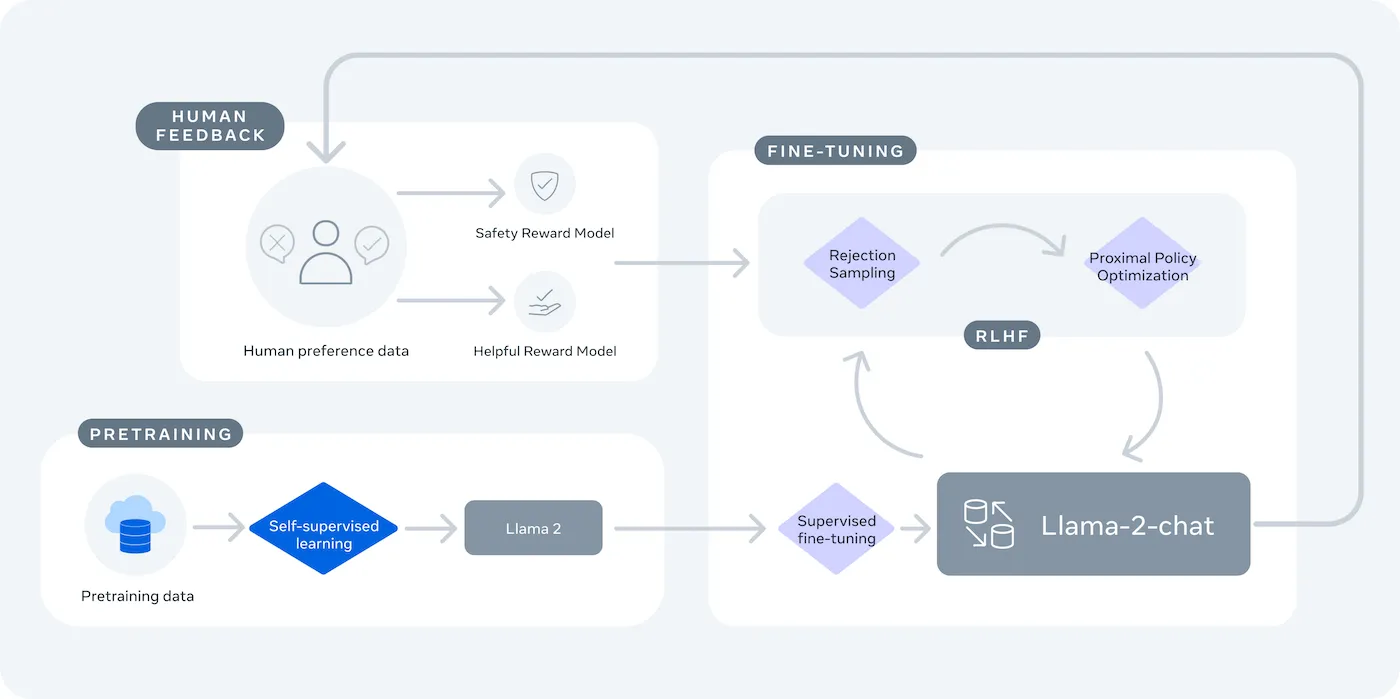
LLaMA (Large Language Model Meta /AI) ist die Familie der offenen Sprachmodelle von Meta und bietet eine leistungsstarke Alternative. Es wurde sowohl für Forschungszwecke als auch für den kommerziellen Einsatz entwickelt und gibt Ihnen die Kontrolle, die Ihnen geschlossene Closed-Source-Modelle nicht bieten.
LLaMA-Modelle gibt es in verschiedenen Größen, gemessen in Parametern (z. B. 7B, 13B, 70B). Stellen Sie sich Parameter als Maß für die Komplexität und Leistungsfähigkeit des Modells vor – größere Modelle sind leistungsfähiger, benötigen aber auch mehr Rechenressourcen.
Hier sind einige Gründe, warum Sie einen LLaMA-Chatbot verwenden könnten:
- Datenschutz: Wenn Sie ein Modell auf Ihrer eigenen Infrastruktur ausführen, verlassen Ihre Daten der Unterhaltung niemals Ihre Umgebung. Dies ist für Teams, die mit sensiblen Informationen umgehen, von entscheidender Bedeutung.
- Benutzerdefinierte Anpassung: Sie können ein LLaMA-Modell anhand der internen Dokumente oder Daten Ihres Unternehmens feinabstimmen. Dadurch kann es Ihren spezifischen Kontext besser verstehen und wesentlich relevantere Antworten liefern.
- Kostenvorhersagbarkeit: Nach dem anfänglichen Hardware-Setup müssen Sie sich keine Gedanken mehr über API-Gebühren pro Token machen. Ihre Kosten sind fest und vorhersehbar.
- Keine Ratenlimits: Die Kapazität Ihres Chatbots wird durch Ihre eigene Hardware begrenzt, nicht durch die Kontingente eines Anbieters. Sie können nach Bedarf skalieren.
Der wichtigste Kompromiss ist die Bequemlichkeit zugunsten der Kontrolle. LLaMA erfordert mehr technisches Setup als eine Plug-and-Play-API. Für Chatbots in der Produktion verwenden Teams in der Regel LLaMA 2 oder das neuere LLaMA 3, das eine verbesserte Argumentation bietet und mehr Text auf einmal verarbeiten kann.
Was Sie vor dem Erstellen eines LLaMA-Chatbots benötigen
Sich ohne die richtigen tools in ein Entwicklungsprojekt zu stürzen, ist ein Garant für Frustration. Sie kommen bis zur Hälfte, nur um dann festzustellen, dass Ihnen ein wichtiger Teil der Hardware oder Software fehlt, was Ihren Fortschritt zum Erliegen bringt und Ihnen Stunden Ihrer Zeit kostet.
Um dies zu vermeiden, sollten Sie im Voraus alles Notwendige zusammenstellen. Hier ist eine Checkliste, die einen reibungslosen Start gewährleistet. 🛠️
Hardware-Anforderungen
| Modellgröße | Minimale VRAM | Alternative Option |
|---|---|---|
| 7 Milliarden Parameter | 8 GB | Cloud-GPU-Instanz |
| 13 Milliarden Parameter | 16 GB | Cloud-GPU-Instanz |
| 70 Milliarden Parameter | Mehrere GPUs | Quantisierung oder Cloud |
Wenn Ihr lokaler Rechner nicht über eine ausreichend leistungsfähige Grafikprozessoreinheit (GPU) verfügt, können Sie Cloud-Dienste wie AWS oder GCP nutzen. Inferenzplattformen wie Baseten und Replicate bieten ebenfalls Pay-as-you-go-Zugriff auf GPUs.
Softwareanforderungen
- Python 3. 8+: Dies ist die Standardprogrammiersprache für Projekte im Bereich maschinelles Lernen.
- Paketmanager: Sie benötigen pip oder Conda, um die für Ihr Projekt erforderlichen Bibliotheken zu installieren.
- Virtuelle Umgebung: Dies ist eine Best Practice, mit der die Abhängigkeiten Ihres Projekts von anderen Python-Projekten auf Ihrem Rechner isoliert bleiben.
Zugangsvoraussetzungen
- Hugging Face-Konto: Sie benötigen ein Konto, um die LLaMA-Modellgewichte herunterzuladen.
- Meta-Genehmigung: Sie müssen die Lizenzvereinbarung von Meta akzeptieren, um Zugriff auf LLaMA-Modelle zu erhalten. Die Genehmigung erfolgt in der Regel innerhalb weniger Stunden.
- API-Schlüssel: Diese sind nur erforderlich, wenn Sie sich dafür entscheiden, einen gehosteten Inferenz-Endpunkt zu verwenden, anstatt das Modell lokal auszuführen.
Für diese Anleitung verwenden wir das LangChain-Framework. Es vereinfacht viele der komplexen Aspekte der Erstellung eines Chatbots, wie z. B. die Verwaltung von Eingabeaufforderungen und Unterhaltungen.
{kind=link}
So erstellen Sie Schritt für Schritt einen Chatbot mit LLaMA
Die Verbindung aller technischen Komponenten eines Chatbots – das Modell, die Eingabeaufforderung, der Speicher – kann überwältigend sein. Man kann sich leicht im Code verlieren, was zu Fehlern und einem Chatbot führt, der nicht wie erwartet funktioniert. Diese Schritt-für-Schritt-Anleitung unterteilt den Prozess in einfache, überschaubare Teile.
Dieser Ansatz funktioniert unabhängig davon, ob Sie das Modell auf Ihrem eigenen Rechner ausführen oder einen gehosteten Dienst nutzen.
Schritt 1: Installieren Sie die erforderlichen Pakete.
Zunächst müssen Sie die wichtigsten Python-Bibliotheken installieren. Öffnen Sie Ihr Terminal und führen Sie diesen Befehl aus:
pip install langchain transformers accelerate torch
Wenn Sie einen gehosteten Dienst wie Baseten für die Inferenz verwenden, müssen Sie auch dessen spezifisches Software Development Kit (SDK) installieren:
pip install baseten
Hier erfahren Sie, was jedes dieser Pakete zu erledigen hat:
- Langchain: Ein Framework, das beim Erstellen von Anwendungen mit großen Sprachmodellen hilft, einschließlich der Verwaltung von Ketten der Unterhaltung und des Speichers.
- Transformers: Die Hugging Face-Bibliothek zum Laden und Ausführen des LLaMA-Modells
- Accelerate: Eine Bibliothek, die dabei hilft, das Laden des Modells auf Ihre CPU und GPU zu optimieren.
- Torch: Die PyTorch-Bibliothek, die die Backend-Leistung für die Berechnungen des Modells bereitstellt.
Wenn Sie das Modell lokal auf einem Rechner mit einer NVIDIA-GPU ausführen, stellen Sie sicher, dass CUDA installiert und korrekt konfiguriert ist. Dadurch kann das Modell die GPU für eine deutlich schnellere Leistung nutzen.
Schritt 2: Erhalten Sie Zugriff auf LLaMA-Modelle
Bevor Sie das Modell herunterladen können, müssen Sie über Hugging Face einen offiziellen Zugang von Meta erhalten.
- Erstellen Sie ein Konto auf huggingface.co
- Gehen Sie zur Seite des Modells, zum Beispiel meta-llama/Llama-2-7b-chat-hf.
- Klicken Sie auf „Auf Repository zugreifen“ und stimmen Sie den Lizenzbedingungen von Meta zu.
- Generieren Sie in Ihren Hugging Face-Konto-Einstellungen einen neuen Token.
- Führen Sie in Ihrem Terminal „huggingface-cli login“ aus und fügen Sie Ihren Token ein, um die Authentifizierung Ihres Geräts durchzuführen.
Die Genehmigung erfolgt in der Regel schnell. Achten Sie darauf, eine Modellvariante mit „Chat” im Namen zu wählen, da diese speziell für Aufgaben der Unterhaltung trainiert wurden.
Schritt 3: Laden Sie das LLaMA-Modell
Jetzt können Sie das Modell in Ihren Code laden. Je nach Ihrer Hardware haben Sie zwei Hauptoptionen.
Wenn Sie über eine ausreichend leistungsstarke GPU verfügen, können Sie das Modell lokal laden:
Wenn Ihre Hardware einen Limit hat, können Sie einen gehosteten Inferenzdienst verwenden:
Der Befehl device_map="auto" weist die Transformers-Bibliothek an, das Modell automatisch auf alle verfügbaren GPUs zu verteilen.
Wenn Ihnen immer noch der Speicherplatz ausgeht, können Sie eine Technik namens Quantisierung verwenden, um die Größe des Modells zu verringern, was jedoch zu einer leichten Verringerung der Leistung führen kann.
Schritt 4: Erstellen Sie eine Prompt-Vorlage
LLaMA-Chat-Modelle sind darauf trainiert, ein bestimmtes Format für Eingabeaufforderungen zu erwarten. Eine EingabeaufforderungsVorlage stellt sicher, dass Ihre Eingabe korrekt strukturiert ist.
Schauen wir uns dieses Format einmal genauer an:
- <
>: Dieser Abschnitt enthält die Systemaufforderung, die dem Modell seine Kernanweisungen gibt und seine Persönlichkeit definiert. - [INST]: Dies markiert den Beginn der Frage oder Anweisung des Benutzers.
- [/INST]: Dies signalisiert dem Modell, dass es Zeit ist, eine Antwort zu generieren.
Beachten Sie, dass verschiedene Versionen von LLaMA möglicherweise leicht unterschiedliche Vorlagen verwenden. Überprüfen Sie immer die Dokumentation des Modells auf Hugging Face, um das richtige Format zu ermitteln.
Schritt 5: Richten Sie die Chatbot-Kette ein
Als Nächstes erstellen Sie eine Verbindung zwischen Ihrem Modell und Ihrer Prompt-Vorlage mithilfe von LangChain zu einer Konversationskette. Diese Kette umfasst auch einen Speicher für die Nachverfolgung der Unterhaltung.
LangChain bietet verschiedene Arten von Speicher:
- ConversationBufferMemory: Dies ist die einfachste Option. Sie speichert den gesamten Verlauf der Unterhaltung.
- ConversationSummaryMemory: Um Space zu sparen, fasst diese Option in einem bestimmten Zeitraum ältere Teile der Unterhaltung zusammen.
- ConversationBufferWindowMemory: Hiermit werden nur die letzten paar Nachrichten im Speicher behalten, was nützlich ist, um zu verhindern, dass der Kontext zu lang wird.
Zum Testen ist ConversationBufferMemory ein guter Ausgangspunkt.
Schritt 6: Führen Sie die Chatbot-Schleife aus.
Schließlich können Sie eine einfache Schleife erstellen, um über das Terminal mit Ihrem Chatbot zu interagieren.
In einer realen Anwendung würden Sie diese Schleife durch einen API-Endpunkt ersetzen, indem Sie ein Framework wie FastAPI oder Flask verwenden. Sie können auch die Antwort des Modells an den Benutzer zurückstreamen, wodurch sich der Chatbot viel schneller anfühlt.
Sie können auch Parameter wie die Temperatur anpassen, um die Zufälligkeit der Antworten zu steuern. Eine niedrige Temperatur (z. B. 0,2) macht die Ausgabe deterministischer und sachlicher, während eine höhere Temperatur (z. B. 0,8) mehr Kreativität fördert.
📚 Lesen Sie auch: KI-Agent vs. Chatbot: Die wichtigsten Unterschiede und welches Modell das richtige für Sie ist.
So testen Sie Ihren LLaMA-Chatbot
Sie haben einen Chatbot entwickelt, der Antworten gibt, aber ist er auch bereit für echte Benutzer? Die Bereitstellung eines ungetesteten Bots kann zu peinlichen Fehlern führen, wie z. B. der Bereitstellung falscher Informationen oder der Generierung unangemessener Inhalte, was dem Ruf Ihres Unternehmens schaden kann.
Ein systematischer Plan für Tests ist die Lösung für diese Unsicherheit. Er stellt sicher, dass Ihr Chatbot robust, zuverlässig und sicher ist.
Funktionstests:
- Randfälle: Testen Sie, wie der Bot mit leeren Eingaben, sehr langen Nachrichten und Sonderzeichen umgeht.
- Speicherüberprüfung: Stellen Sie sicher, dass sich der Chatbot den Kontext über mehrere Runden der Unterhaltung merkt.
- Anweisungen befolgen: Überprüfen Sie, ob der Bot die Regeln einhält, die Sie in der Systemaufforderung festgelegt haben.
Qualitätsbewertung:
- Relevanz: Beantwortet die Antwort tatsächlich die Frage des Benutzers?
- Genauigkeit: Sind die von den Anbietern bereitgestellten Informationen korrekt?
- Kohärenz: Verläuft die Unterhaltung logisch?
- Sicherheit: Weigert sich der Bot, unangemessene oder schädliche Anfragen zu beantworten?
Leistungstests:
- Latenz: Messen Sie, wie lange es dauert, bis der Bot mit der Antwort beginnt und seine Antwort beendet.
- Ressourcennutzung: Überwachen Sie, wie viel GPU-Speicher das Modell während der Inferenz verwendet.
- Parallelität: Testen Sie, wie sich das System verhält, wenn mehrere Benutzer gleichzeitig damit interagieren.
Achten Sie auch auf häufige LLM-Probleme wie Halluzinationen (selbstbewusste Angabe falscher Informationen), Kontextdrift (Verlust des Themas in einer langen Unterhaltung) und Wiederholungen. Das Protokollieren aller Testunterhaltungen ist eine gute Möglichkeit, Muster zu erkennen und Probleme zu beheben, bevor sie Ihre Benutzer erreichen.
📚 Lesen Sie auch: Der Unterschied zwischen funktionalen Tests und nicht-funktionalen Tests
LLaMA-Chatbot-Anwendungsfälle für Teams
Sobald Sie die Feinabstimmung und Bereitstellung hinter sich haben, entfaltet LLaMA seinen größten Nutzen, wenn es auf alltägliche Probleme im Team angewendet wird – nicht auf abstrakte KI-Demos. Teams benötigen in der Regel keinen „Chatbot“, sondern einen schnelleren Zugriff auf Wissen, weniger manuelle Übergaben und weniger repetitive Arbeit.
Interner Wissensassistent
Durch die Feinabstimmung von LLaMA anhand interner Dokumentationen, Wikis und FAQs – oder durch die Kombination mit einer RAG-basierten Wissensdatenbank – können Teams Fragen in natürlicher Sprache stellen und präzise, kontextbezogene Antworten erhalten. Dadurch entfällt die mühsame Suche in verstreuten tools, während sensible Daten vollständig intern bleiben und nicht an APIs von Drittanbietern gesendet werden.
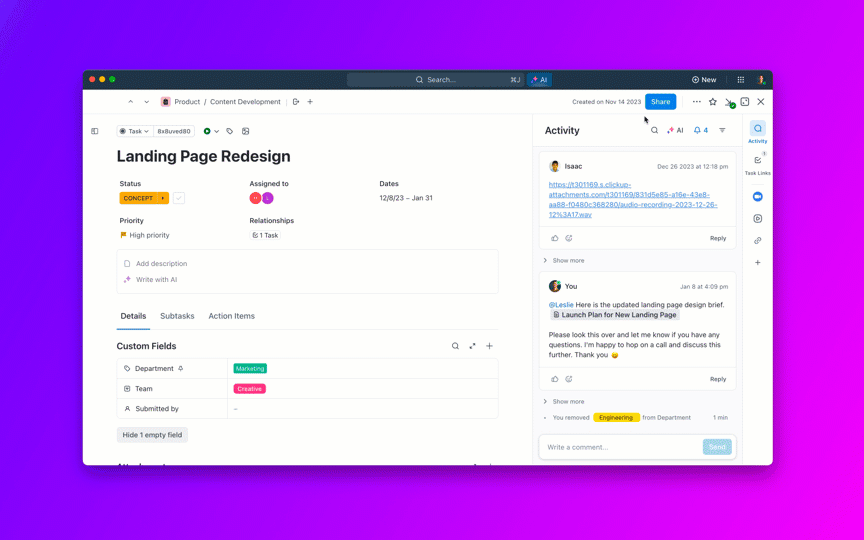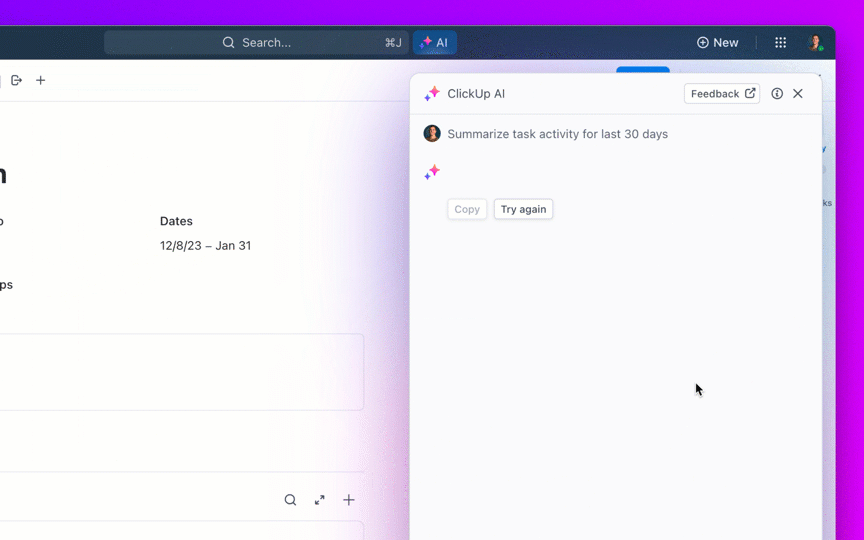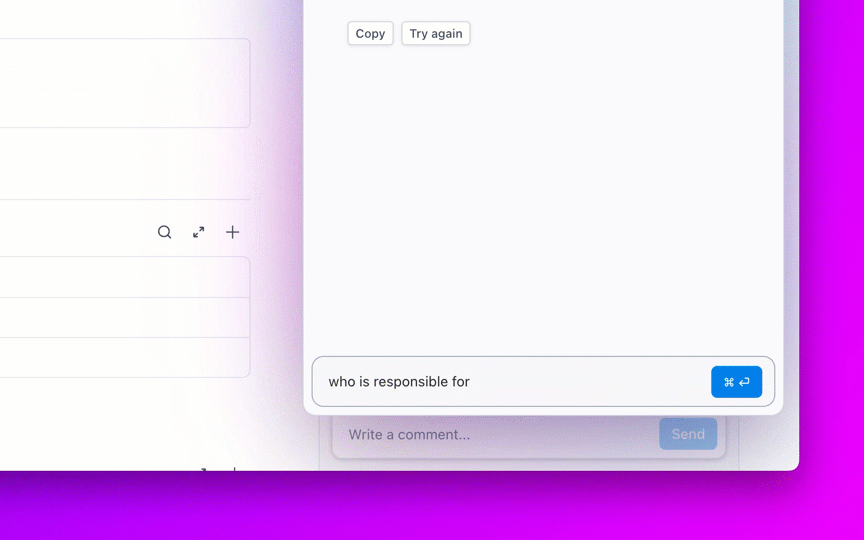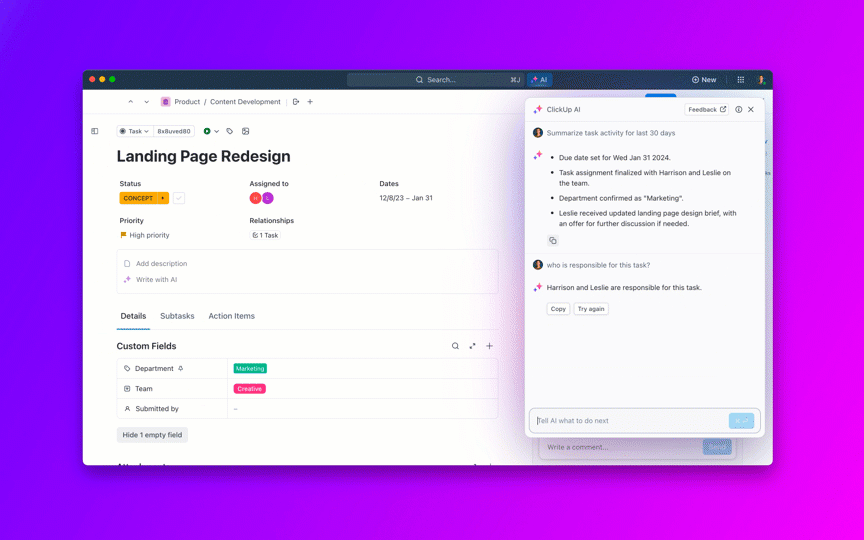
🌟 Die Enterprise-Suche in ClickUp und der vorgefertigte Agent „Ambient Answers“ liefern detaillierte kontextbezogene Antworten auf Ihre Fragen, indem sie das Wissen in Ihrem ClickUp-Workspace nutzen.
Code-Review-Assistent
Wenn LLaMA anhand Ihrer eigenen Codebasis und Stilrichtlinien trainiert wird, kann es als kontextbezogener Code-Review-Assistent fungieren. Anstelle generischer Best Practices erhalten Entwickler Vorschläge, die mit den Konventionen des Teams, architektonischen Entscheidungen und historischen Mustern übereinstimmen.
🌟 Ein LLaMA-basierter Code-Review-Helfer kann Probleme aufdecken, Verbesserungen vorschlagen oder unbekannte Codes erklären. Codegen von ClickUp geht noch einen Schritt weiter, indem es innerhalb des EntwicklungsWorkflows agiert – es erstellt Pull Requests, wendet Refactors an oder aktualisiert Dateien direkt als Reaktion auf diese Erkenntnisse. Das Ergebnis ist weniger Kopieren und Einfügen und weniger fehlerhafte Übergaben zwischen „Denken” und „Tun”.
Triage im Kundensupport
LLaMA kann für die Absichtsklassifizierung trainiert werden, um eingehende Kundenabfragen zu verstehen und sie an das richtige Team oder den richtigen Workflow weiterzuleiten. Häufige Fragen können automatisch bearbeitet werden, während Sonderfälle mit dem entsprechenden Kontext an menschliche Agenten weitergeleitet werden, wodurch die Antwortzeiten ohne Qualitätseinbußen verkürzt werden.
Sie können auch einfach einen Triage-Superagenten mit natürlicher Sprache in Ihrem ClickUp-Workspace erstellen. Weitere Informationen
Zusammenfassung von Meetings und Nachverfolgung
Anhand von Besprechungsprotokollen als Eingabe kann LLaMA Entscheidungen, Aktionspunkte und wichtige Diskussionspunkte extrahieren. Der wahre Wert zeigt sich, wenn diese Ergebnisse direkt in Aufgabenmanagement-Tools einfließen und so Unterhaltungen in nachverfolgbare Aufgaben umgewandelt werden.
🌟 Der KI-Meeting-Notizbuchhalter von ClickUp erstellt nicht nur Meeting-Notizen, sondern entwirft auch Zusammenfassungen, generiert Aktionspunkte und verknüpft Meeting-Notizen mit Ihren Dokumenten und Aufgaben.
Erstellung und Überarbeitung von Dokumenten
Teams können LLaMA verwenden, um erste Entwürfe von Berichten, Angeboten oder Dokumentationen auf der Grundlage bestehender Vorlagen und früherer Beispiele zu erstellen. Dadurch verlagert sich der Aufwand von der Erstellung einer leeren Seite hin zur Überprüfung und Verfeinerung, was die Lieferung beschleunigt, ohne die Standards zu senken.
🌟 ClickUp Brain kann schnell Entwürfe für Dokumentationen erstellen und dabei Ihr gesamtes Wissen am Arbeitsplatz im Kontext behalten. Probieren Sie es noch heute aus.
LLaMA-basierte Chatbots sind am effektivsten, wenn sie in bestehende Workflows – Dokumentation, Projektmanagement und Teamkommunikation – eingebettet sind, anstatt als eigenständige Tools zu fungieren.
Hier macht die direkte Integration von KI in Ihren Workspace den entscheidenden Unterschied. Anstatt ein separates Tool zu entwickeln, können Sie dialogorientierte KI dort einsetzen, wo Ihr Team bereits arbeitet.
Sie können beispielsweise einen benutzerdefinierten LLaMA-Bot erstellen, der als Wissensassistent fungiert. Befindet sich dieser jedoch außerhalb Ihres Projektmanagement-Tools, muss Ihr Team den Kontext wechseln, um ihm eine Frage zu stellen. Dies führt zu Reibungsverlusten und verlangsamt die Arbeit aller Beteiligten.
Vermeiden Sie diesen Kontextwechsel, indem Sie eine KI verwenden, die bereits Teil Ihres Workflows ist.
Stellen Sie Fragen zu Ihren Projekten, Aufgaben und Dokumenten, ohne ClickUp jemals verlassen zu müssen, indem Sie ClickUp Brain verwenden. Geben Sie einfach @brain in einen beliebigen Aufgabenkommentar oder ClickUp-Chat ein, um sofort eine kontextbezogene Antwort zu erhalten. Es ist, als hätten Sie ein Mitglied des Teams, das Ihren gesamten Workspace perfekt kennt. 🤩
Dadurch wird der Chatbot von einer Neuheit zu einem zentralen Bestandteil der Maschine für die Produktivität Ihres Teams.
Einschränkungen bei der Verwendung von LLaMA zum Erstellen von Chatbots
Die Erstellung eines LLaMA-Chatbots kann sehr motivierend sein, aber Teams werden oft von versteckten Komplexitäten überrascht. Das „kostenlose“ Open-Source-Modell kann am Ende teurer und schwieriger zu verwalten sein als erwartet, was zu einer schlechten Benutzererfahrung und einem ständigen, ressourcenintensiven Wartungszyklus führt.
Es ist wichtig, die Limite zu verstehen, bevor Sie sich festlegen.
- Technische Komplexität: Die Einrichtung und Wartung eines LLaMA-Modells erfordert Kenntnisse über Machine-Learning-Infrastrukturen.
- Hardwareanforderungen: Die Ausführung der größeren, leistungsfähigeren Modelle erfordert teure GPU-Hardware, und die Cloud-Kosten können schnell steigen.
- Einschränkungen des Kontextfensters: LLaMA-Modelle verfügen über einen Limit an Speicher ( 4K-Token für LLaMA 2 ). Die Verarbeitung langer Dokumente oder Unterhaltungen erfordert komplexe Chunking-Strategien.
- Keine integrierten Sicherheitsvorkehrungen: Sie sind selbst für die Implementierung Ihrer eigenen Inhaltsfilterung und Sicherheitsmaßnahmen verantwortlich.
- Laufende Wartung: Wenn neue Modelle veröffentlicht werden, müssen Sie Ihre Systeme aktualisieren, und fein abgestimmte Modelle müssen möglicherweise neu trainiert werden.
Selbst gehostete Modelle weisen in der Regel auch eine höhere Latenz auf als hochoptimierte kommerzielle APIs. All dies sind operative Belastungen, die Managed Solutions für Sie übernimmt.
📮ClickUp Insight: 88 % unserer Umfrageteilnehmer nutzen KI für ihre persönlichen Aufgaben, doch über 50 % scheuen sich, sie bei der Arbeit einzusetzen. Die drei größten Hindernisse? Mangelnde nahtlose Integration, Wissenslücken oder Bedenken hinsichtlich der Sicherheit.
Was aber, wenn KI in Ihren Arbeitsbereich integriert und bereits sicher ist? ClickUp Brain, der integrierte KI-Assistent von ClickUp, macht dies möglich. Er versteht Eingabeaufforderungen in einfacher Sprache und löst damit alle drei Bedenken hinsichtlich der Einführung von KI, während er Ihren Chat, Ihre Aufgaben, Dokumente und Ihr Wissen im gesamten Workspace miteinander verbindet. Finden Sie Antworten und Erkenntnisse mit einem einzigen Klick!
Alternativen zu LLaMA für die Erstellung von Chatbots
LLaMA ist nur eine Option unter vielen KI-Modellen, und es kann überwältigend sein, herauszufinden, welches das richtige für Sie ist.
Hier sehen Sie eine Übersicht über die verschiedenen Alternativen.
Andere Open-Source-Modelle:
- Mistral: Bekannt für seine starke Leistung auch bei kleineren Größen der Modelle, was es effizient macht.
- Falcon: Mit einer sehr großzügigen Lizenz, die eine große Berechtigung für kommerzielle Anwendungen bietet.
- MPT: Optimiert für die Verarbeitung langer Dokumente und Unterhaltungen
Kommerzielle APIs:
- OpenAI (GPT-4, GPT-3. 5): Diese Modelle gelten allgemein als die leistungsfähigsten großen Sprachmodelle und lassen sich sehr einfach integrieren.
- Anthropic (Claude): Bekannt für starke Sicherheits-Features und sehr große Kontextfenster.
- Google (Gemini): Bietet leistungsstarke multimodale Funktionen, mit denen Text, Bilder und Audio verstanden werden können.
Sie können ihn selbst mit einem Open-Source-Modell erstellen, für eine kommerzielle API bezahlen oder einen konvergenten KI-Workspace nutzen, der eine vorintegrierte Lösung mit verschiedenen Arten von KI-Agenten bietet.
📚 Lesen Sie auch: So nutzen Sie einen Chatbot für Ihr Geschäft
Erstellen Sie kontextbezogene KI-Assistenten mit ClickUp
Wenn Sie einen Chatbot mit LLaMA erstellen, haben Sie eine unglaubliche Kontrolle über Ihre Daten, Kosten und benutzerdefinierte Anpassungen. Diese Kontrolle geht jedoch mit der Verantwortung für Infrastruktur, Wartung und Sicherheit einher – alles Dinge, die verwaltete APIs für Sie übernehmen. Das Ziel ist nicht nur, einen Bot zu erstellen, sondern Ihr Team produktiver zu machen, und ein komplexes Engineering-Projekt kann manchmal davon ablenken.
Die richtige Wahl hängt von den Ressourcen und Prioritäten Ihres Teams ab. Wenn Sie über ML-Fachwissen verfügen und strenge Anforderungen an den Datenschutz haben, ist LLaMA eine fantastische Option. Wenn Sie Geschwindigkeit und Einfachheit als Priorität betrachten, ist ein integriertes Tool möglicherweise besser geeignet.
Mit ClickUp erhalten Sie einen konvergenten KI-Arbeitsbereich, in dem alle Ihre Aufgaben, Dokumente und Unterhaltungen an einem Ort zusammengefasst sind und der durch integrierte KI unterstützt wird. Er reduziert die Kontextverteilung und hilft Teams, schneller und effektiver zu arbeiten, da sie durch anpassbare Super Agents und kontextbezogene KI jederzeit auf die richtigen Informationen zugreifen können.
Verschwenden Sie keine Zeit mehr mit der Infrastruktur und profitieren Sie noch heute von den Vorteilen eines kontextbezogenen KI-Assistenten, ohne alles von Grund auf neu aufbauen zu müssen. Starten Sie kostenlos mit ClickUp.
Häufig gestellte Fragen (FAQ)
Die Kosten hängen vollständig von Ihrer Bereitstellungsmethode ab und können mithilfe von Projektprognosen geschätzt werden. Wenn Sie Ihre eigene Hardware verwenden, fallen Vorabkosten für die GPU an, jedoch keine laufenden Gebühren pro Abfrage. Cloud-Anbieter berechnen einen Stundensatz basierend auf der GPU und der Größe des Modells.
Ja, die Lizenzen für LLaMA 2 und LLaMA 3 erlauben die kommerzielle Nutzung. Sie müssen jedoch den Nutzungsbedingungen von Meta zustimmen und die erforderliche Quellenangabe in Ihrem Produkt angeben.
LLaMA 3 ist das neuere und leistungsfähigere Modell, das bessere Schlussfolgerungsfähigkeiten und ein größeres Kontextfenster (8K-Token gegenüber 4K bei LLaMA 2) bietet. Das bedeutet, dass es längere Unterhaltungen und Dokumente verarbeiten kann, aber auch mehr Rechenressourcen für den Betrieb benötigt.
Python ist aufgrund seiner umfangreichen Bibliotheken zwar die gängigste Sprache für maschinelles Lernen, aber nicht zwingend erforderlich. Einige Plattformen bieten mittlerweile No-Code- oder Low-Code-Lösungen an, mit denen Sie einen LLaMA-Chatbot mit grafischer Benutzeroberfläche bereitstellen können. /