
KI-Projekte scheitern selten auf Modellebene. Sie geraten jedoch ins Stocken, wenn Experimente, Dokumentationen und Updates für Stakeholder auf zu viele Tools verteilt sind.
Dieser Leitfaden führt Sie durch das Trainieren von Modellen mit Databricks DBRX – einem LLM, das bis zu doppelt so recheneffizient ist wie andere führende Modelle – und dabei die damit verbundenen Arbeiten in ClickUp organisiert.
Von der Einrichtung und Feinabstimmung bis hin zur Dokumentation und teamübergreifenden Updates sehen Sie, wie ein einziger, konvergierter Workspace dazu beiträgt, Kontextverwirrung zu vermeiden und Ihr Team auf die Entwicklung statt auf die Suche zu konzentrieren. 🛠
Was ist DBRX?
DBRX ist ein leistungsstarkes Open-Source-Sprachmodell (LLM), das speziell für das Training und die Inferenz von KI-Modellen in Unternehmen entwickelt wurde. Da es unter der Databricks Open Model License als Open Source verfügbar ist, hat Ihr Team vollen Zugriff auf die Gewichte und die Architektur des Modells, sodass Sie es nach Ihren eigenen Vorstellungen überprüfen, modifizieren und einsetzen können.
Es gibt zwei Varianten: DBRX Base für tiefgreifendes Vortraining und DBRX Instruct für sofort einsatzbereite Aufgaben zur Befolgung von Anweisungen.
DBRX-Architektur und Mix-of-Experts-Design
DBRX löst Aufgaben mithilfe einer Mixture-of-Experts (MoE)-Architektur. Im Gegensatz zu herkömmlichen großen Sprachmodellen, die alle ihre Milliarden von Parametern für jede einzelne Berechnung verwenden, aktiviert DBRX nur einen Bruchteil seiner Gesamtparameter (die relevantesten Experten) für eine bestimmte Aufgabe.
Stellen Sie sich das wie ein Team aus spezialisierten Experten vor: Anstatt dass jeder an jedem Problem arbeitet, leitet das System jede Aufgabe intelligent an die am besten geeigneten Parameter weiter.
Dies verkürzt nicht nur die Reaktionszeit, sondern liefert auch erstklassige Leistung und Ergebnisse bei gleichzeitig deutlich reduzierten Rechenkosten.
Hier ein kurzer Überblick über die wichtigsten Spezifikationen:
- Gesamtparameter: 132 Milliarden über alle Experten hinweg
- Aktive Parameter: 36B pro Vorwärtsdurchlauf
- Anzahl der Experten: insgesamt 16 (MoE Top-4-Routing), davon 4 aktiv für jedes beliebige Token
- Kontextfenster: 32K-Token
DBRX-Trainingsdaten und Token-Spezifikationen
Die Leistung eines LLM hängt direkt von den Daten ab, mit denen es trainiert wurde. DBRX wurde mit einem riesigen Datensatz von 12 Billionen Tokens vortrainiert, der vom Databricks-Team mit seinen fortschrittlichen Datenverarbeitungs-Tools sorgfältig zusammengestellt wurde. Genau deshalb hat es bei Branchen-Benchmarks so gut abgeschnitten.
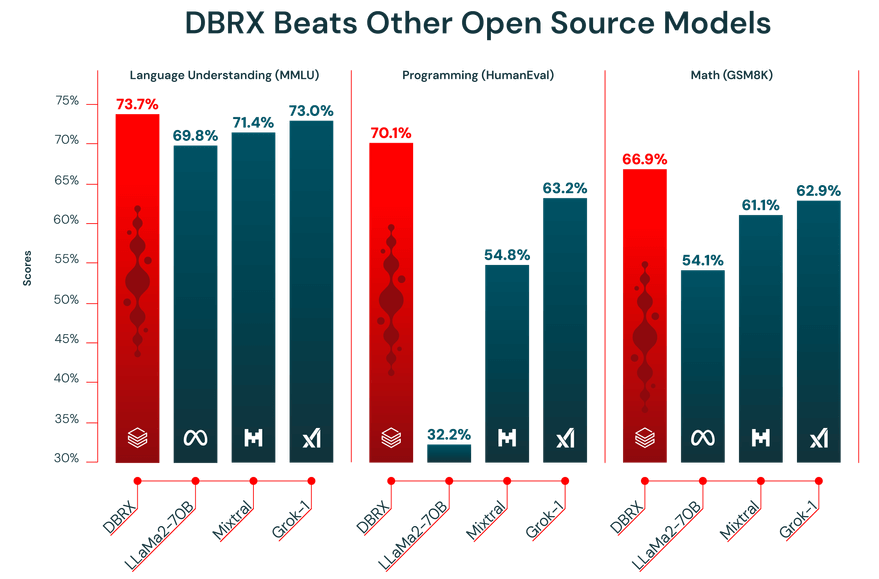
Darüber hinaus verfügt DBRX über ein Kontextfenster mit 32.000 Token. Dies ist die Textmenge, die das Modell gleichzeitig berücksichtigen kann. Ein großes Kontextfenster ist sehr hilfreich für komplexe Aufgaben wie das Zusammenfassen langer Berichte, das Durchsuchen umfangreicher Rechtsdokumente oder den Aufbau fortschrittlicher RAG-Systeme (Retrieval-Augmented Generation), da es dem Modell ermöglicht, den Kontext beizubehalten, ohne Informationen zu kürzen oder zu vergessen.
🎥 Sehen Sie sich dieses Video an, um zu erfahren, wie eine optimierte Projektkoordination Ihren KI-Trainings-Workflow verändern und die Reibungsverluste beim Wechsel zwischen unverbundenen tools beseitigen kann. 👇🏽
So greifen Sie auf DBRX zu und richten es ein
DBRX bietet zwei primäre Zugriffsmöglichkeiten, die beide uneingeschränkten Zugriff auf die Modellgewichte zu günstigen kommerziellen Bedingungen bieten. Sie können Hugging Face für maximale Flexibilität nutzen oder direkt über Databricks darauf zugreifen, um eine besser integrierte Erfahrung zu erhalten.
Greifen Sie über Hugging Face auf DBRX zu.
Für Teams, die Wert auf Flexibilität legen und bereits mit dem Hugging Face-Ökosystem vertraut sind, ist der Zugriff auf DBRX über den Hub der ideale Weg. So können Sie das Modell in Ihre bestehenden transformatorbasierten Workflows integrieren.
So fangen Sie an:
- Erstellen Sie ein Hugging Face-Konto oder melden Sie sich an.
- Navigieren Sie zur DBRX-Modellkarte im Hub und akzeptieren Sie die Lizenzbedingungen.
- Installieren Sie die Transformers-Bibliothek zusammen mit den erforderlichen Abhängigkeiten wie Accelerate.
- Verwenden Sie die Klasse „AutoModelForCausalLM” in Ihrem Python-Skript, um das DBRX-Modell zu laden.
- Konfigurieren Sie Ihre Inferenz-Pipeline und beachten Sie dabei, dass DBRX für einen effektiven Betrieb viel GPU-Speicher (VRAM) benötigt.
📖 Weiterlesen: So konfigurieren Sie die LLM-Temperatur
Greifen Sie über Databricks auf DBRX zu.
Wenn Ihr Team bereits Databricks für Data Engineering oder maschinelles Lernen verwendet, ist der Zugriff auf DBRX über die Plattform der einfachste Weg. Das erspart Ihnen mühsame Arbeiten beim Setup und bietet Ihnen alle Tools, die Sie für MLOps benötigen, direkt dort, wo Sie bereits arbeiten.
Befolgen Sie diese Schritte in Ihrer Databricks-Workspace, um loszulegen:
- Navigieren Sie zum Abschnitt „Model Garden“ oder „Mosaic KI“.
- Wählen Sie je nach Ihren Anforderungen entweder DBRX Base oder DBRX Instruct aus.
- Konfigurieren Sie einen Serving-Endpunkt für den API-Zugriff oder richten Sie eine Notebook-Umgebung für die interaktive Nutzung ein.
- Beginnen Sie mit dem Testen der Inferenz anhand von Beispielprompts, um sicherzustellen, dass alles korrekt funktioniert, bevor Sie das Training oder die Bereitstellung Ihres KI-Modells skalieren.
Dieser Ansatz bietet Ihnen nahtlosen Zugriff auf Tools wie MLflow für die Nachverfolgung von Experimenten und den Unity Catalog für die Modellverwaltung.
📮 ClickUp Insight: Der durchschnittliche Berufstätige verbringt täglich mehr als 30 Minuten mit der Suche nach Informationen zur Arbeit – das sind über 120 Stunden pro Jahr, die durch das Durchsuchen von E-Mails, Slack-Threads und verstreuten Dateien verloren gehen.
Ein intelligenter KI-Assistent, der in Ihren Workspace eingebettet ist, kann das ändern. Hier kommt ClickUp Brain ins Spiel.
Es liefert sofortige Einblicke und Antworten, indem es innerhalb von Sekunden die richtigen Dokumente, Unterhaltungen und Details zu Aufgaben anzeigt – so können Sie mit der Suche aufhören und mit der Arbeit beginnen.
So optimieren Sie DBRX und trainieren benutzerdefinierte KI-Modelle
Ein Standardmodell, egal wie leistungsfähig es auch sein mag, wird niemals die einzigartigen Nuancen Ihres Geschäfts verstehen. Da DBRX Open Source ist, können Sie es feinabstimmen, um ein benutzerdefiniertes Modell zu erstellen, das die Sprache Ihres Geschäfts spricht oder eine bestimmte Aufgabe ausführt, die Sie ihm übertragen möchten.
Hier sind drei gängige Möglichkeiten, wie Sie dies zu erledigen haben:
1. Optimieren Sie DBRX mit Hugging Face-Datensätzen
Für Teams, die gerade erst anfangen oder an allgemeinen Aufgaben arbeiten, sind öffentliche Datensätze von Hugging Face Hub eine großartige Ressource. Sie sind vorformatiert und leicht zu laden, sodass Sie keine Stunden mit der Vorbereitung Ihrer Daten verbringen müssen.
Der Prozess ist ziemlich einfach:
- Finden Sie im Hub einen Datensatz, der zu Ihrer Aufgabe passt (z. B. Befehlsausführung, Zusammenfassung).
- Laden Sie es mithilfe der Datensatzbibliothek.
- Stellen Sie sicher, dass die Daten in einem Format von Befehl-Antwort-Paaren formatiert sind.
- Konfigurieren Sie Ihr Trainingsskript mit Hyperparametern wie Lernrate und Batchgröße.
- Starten Sie den Trainingsauftrag und achten Sie darauf, während eines Zeitraums regelmäßig Checkpoints zu speichern.
- Bewerten Sie das fein abgestimmte Modell anhand eines zurückbehaltenen Validierungssatzes, um die Verbesserung zu messen.
2. DBRX mit lokalen Datensätzen feinabstimmen
Die besten Ergebnisse erzielen Sie in der Regel durch Feinabstimmung mit Ihren eigenen proprietären Daten. Auf diese Weise können Sie dem Modell die spezifische Terminologie, den Stil und das Fachwissen Ihres Unternehmens beibringen. Beachten Sie jedoch, dass sich dies nur lohnt, wenn Ihre Daten sauber und gut aufbereitet sind und über ein ausreichendes Volumen verfügen.
Befolgen Sie diese Schritte, um Ihre internen Daten vorzubereiten:
- Datenerfassung: Sammeln Sie hochwertige Beispiele aus Ihren internen Wikis, Dokumenten und Datenbanken.
- Formatkonvertierung: Strukturieren Sie Ihre Daten in einem einheitlichen Befehl-Antwort-Format, häufig als JSON-Zeilen.
- Qualitätsfilterung: Entfernen Sie alle Beispiele von geringer Qualität, Duplikate oder irrelevante Beispiele.
- Validierungssplit: Legen Sie einen kleinen Teil Ihrer Daten (in der Regel 10–15 %) beiseite, um die Leistung des Modells zu bewerten.
- Datenschutzprüfung: Entfernen oder maskieren Sie alle personenbezogenen Daten (PII) oder sensiblen Daten.
3. Feinabstimmung von DBRX mit StreamingDataset
Wenn Ihr Datensatz zu groß ist, um in den Speicher Ihres Computers zu passen, können Sie die Streaming-Datensatzbibliothek von Databricks verwenden. Damit können Sie Daten während des Trainings des Modells direkt aus dem Cloud-Speicher streamen, anstatt sie alle auf einmal in den Speicher zu laden.
So geht's:
- Datenaufbereitung: Bereinigen und strukturieren Sie Ihre Trainingsdaten und speichern Sie sie anschließend in einem streambaren Format wie JSONL oder CSV in einem Cloud-Speicher.
- Konvertierung des Streaming-Formats: Konvertieren Sie Ihren Datensatz in ein streamingfreundliches Format wie Mosaic Data Shard (MDS), damit er während des Trainings effizient gelesen werden kann.
- Setup des Trainingsloaders: Konfigurieren Sie Ihren Trainingsloader so, dass er auf den Remote-Datensatz verweist, und definieren Sie einen lokalen Cache für den temporären Speicher.
- Modellinitialisierung: Starten Sie den DBRX-Feinabstimmungsprozess mit einem Trainingsframework, das StreamingDataset unterstützt, z. B. LLM Foundry.
- Streaming-basiertes Training: Führen Sie den Trainingsjob aus, während die Daten während des Trainings in Stapeln gestreamt werden, anstatt sie vollständig in den Speicher zu laden.
- Checkpointing und Wiederherstellung: Setzen Sie das Training nahtlos fort, wenn ein Durchlauf unterbrochen wird, ohne Daten zu duplizieren oder zu überspringen.
- Bewertung und Bereitstellung: Validieren Sie die Leistung des fein abgestimmten Modells und stellen Sie es mit Ihrem bevorzugten Serving- oder Inferenz-Setup bereit.
💡Profi-Tipp: Anstatt einen DBRX-Trainingsplan von Grund auf neu zu erstellen, beginnen Sie mit der Vorlage für KI- und Machine-Learning-Projekte von ClickUp und passen Sie diese an die Bedürfnisse Ihres Teams an. Sie bietet eine klare Struktur für die Planung von Datensätzen, Trainingsphasen, Evaluierung und Bereitstellung, sodass Sie sich auf die Organisation Ihrer Arbeit konzentrieren können, anstatt einen Workflow zu strukturieren.
Anwendungsfälle von DBRX für das Training von KI-Modellen
Ein leistungsstarkes Modell zu haben ist eine Sache, aber genau zu wissen, wo es seine Stärken hat, ist eine andere.
Wenn Sie sich über die Stärken eines Modells nicht im Klaren sind, kann es leicht passieren, dass Sie Zeit und Ressourcen darauf verwenden, es dort einzusetzen, wo es einfach nicht passt. Dies führt zu unterdurchschnittlichen Ergebnissen und Frustration.
Die einzigartige Architektur und die Trainingsdaten von DBRX eignen sich hervorragend für mehrere Schlüssel-Anwendungsfälle in Unternehmen. Wenn Sie diese Stärken kennen, können Sie das Modell an Ihren Geschäftszielen ausrichten und Ihre Kapitalrendite maximieren.
Textgenerierung und Erstellung von Inhalten
DBRX Instruct ist genau darauf abgestimmt, Anweisungen zu befolgen und hochwertige Texte zu generieren. Das macht es zu einem leistungsstarken tool für die Automatisierung eines breiten Bereichs von inhaltsbezogenen Aufgaben. Sein großes Kontextfenster ist ein bedeutender Vorteil, da es so lange Dokumente verarbeiten kann, ohne den Thread zu verlieren.
Sie können es für folgende Zwecke verwenden:
- Technische Dokumentation: Erstellen und verfeinern Sie Produkthandbücher, API-Referenzen und Benutzerhandbücher.
- Marketing-Inhalte: Entwürfe für Blogbeiträge, E-Mail-Newsletter und Social-Media-Updates
- Berichterstellung: Fassen Sie komplexe Datenergebnisse zusammen und erstellen Sie prägnante Zusammenfassungen für Führungskräfte.
- Übersetzung und Lokalisierung: Passen Sie bestehende Inhalte für neue Märkte und Zielgruppen an.
Code-Generierung und Debugging-Aufgaben
Ein erheblicher Teil der Trainingsdaten von DBRX umfasste Code, wodurch es zu einer leistungsfähigen LLM-Unterstützung für Entwickler wurde. Es kann dazu beitragen, Entwicklungszyklen zu beschleunigen, indem es wiederholende Codierungsaufgaben automatisiert und bei der Lösung komplexer Probleme hilft.
Hier sind einige Möglichkeiten, wie Ihr Engineering-Team davon profitieren kann:
- Code-Vervollständigung: Generieren Sie automatisch Funktionskörper aus Kommentaren oder Docstrings.
- Fehlererkennung: Analysieren Sie Code-Schnipsel, um potenzielle Fehler oder logische Mängel zu identifizieren.
- Code-Erklärung: Übersetzen Sie komplexe Algorithmen oder Legacy-Code in einfaches Englisch.
- Testgenerierung: Erstellen Sie Unit-Tests basierend auf der Signatur einer Funktion und dem erwarteten Verhalten.
RAG und Anwendungen mit langem Kontext
Retrieval-Augmented Generation (RAG) ist eine leistungsstarke Technik, die die Antworten eines Modells auf die privaten Daten Ihres Unternehmens basiert. RAG-Systeme haben jedoch oft Schwierigkeiten mit Modellen, die kleine Kontextfenster haben, was zu einer aggressiven Datenaufteilung führt, bei der wichtige Kontexte verloren gehen können. Das 32K-Kontextfenster von DBRX bildet eine hervorragende Grundlage für robuste RAG-Anwendungen.
Auf diese Weise können Sie leistungsstarke interne tools erstellen, wie zum Beispiel:
- Enterprise-Suche: Erstellen Sie einen Chatbot, der Fragen von Mitarbeitern mithilfe Ihrer internen Wissensdatenbank beantwortet.
- Kundensupport: Erstellen Sie einen Agenten, der Support-Antworten auf der Grundlage Ihrer Produktdokumentation generiert.
- Forschungsassistenz: Entwickeln Sie ein tool, das Informationen aus Hunderten von Seiten Forschungsarbeiten zusammenfassen kann.
- Compliance-Prüfung: Überprüfen Sie Marketingtexte automatisch anhand interner Markenrichtlinien oder regulatorischer Dokumente.
So integrieren Sie DBRX-Schulungen in den Workflow Ihres Teams
Ein erfolgreiches KI-Modelltrainingsprojekt umfasst mehr als nur Code und Rechenleistung. Es ist eine gemeinschaftliche Anstrengung, an der ML-Ingenieure, Datenwissenschaftler, Produktmanager und Stakeholder beteiligt sind.
Wenn diese Zusammenarbeit über Jupyter-Notebooks, Slack-Kanäle und separate Tools für das Projektmanagement verstreut ist, entsteht eine Situation, in der wichtige Info über zu viele Tools verstreut ist.
ClickUp löst dieses Problem. Anstatt mehrere Tools zu jonglieren, erhalten Sie einen konvergierten KI-Workspace, in dem Projektmanagement, Dokumentation und Kommunikation zusammenkommen – so bleiben Ihre Experimente von der Planung über die Durchführung bis zur Auswertung miteinander verbunden.
Behalten Sie den Überblick über Experimente und Fortschritte
Bei der Durchführung mehrerer Experimente ist nicht das Trainieren des Modells der schwierigste Teil, sondern die Nachverfolgung der während des Prozesses vorgenommenen Änderungen. Welche Version des Datensatzes wurde verwendet, welche Lernrate hat am besten funktioniert oder welcher Durchlauf wurde ausgeliefert?
ClickUp macht diesen Prozess für Sie ganz einfach. Sie können jeden Trainingslauf separat in ClickUp Aufgaben verfolgen und innerhalb der Aufgaben benutzerdefinierte Felder verwenden, um Folgendes zu protokollieren:
- Datensatz-Version
- Hyperparameter
- Modellvariante (DBRX Base vs. DBRX Instruct)
- Trainingsstatus (In Warteschlange, Wird ausgeführt, Wird ausgewertet, Bereitgestellt)
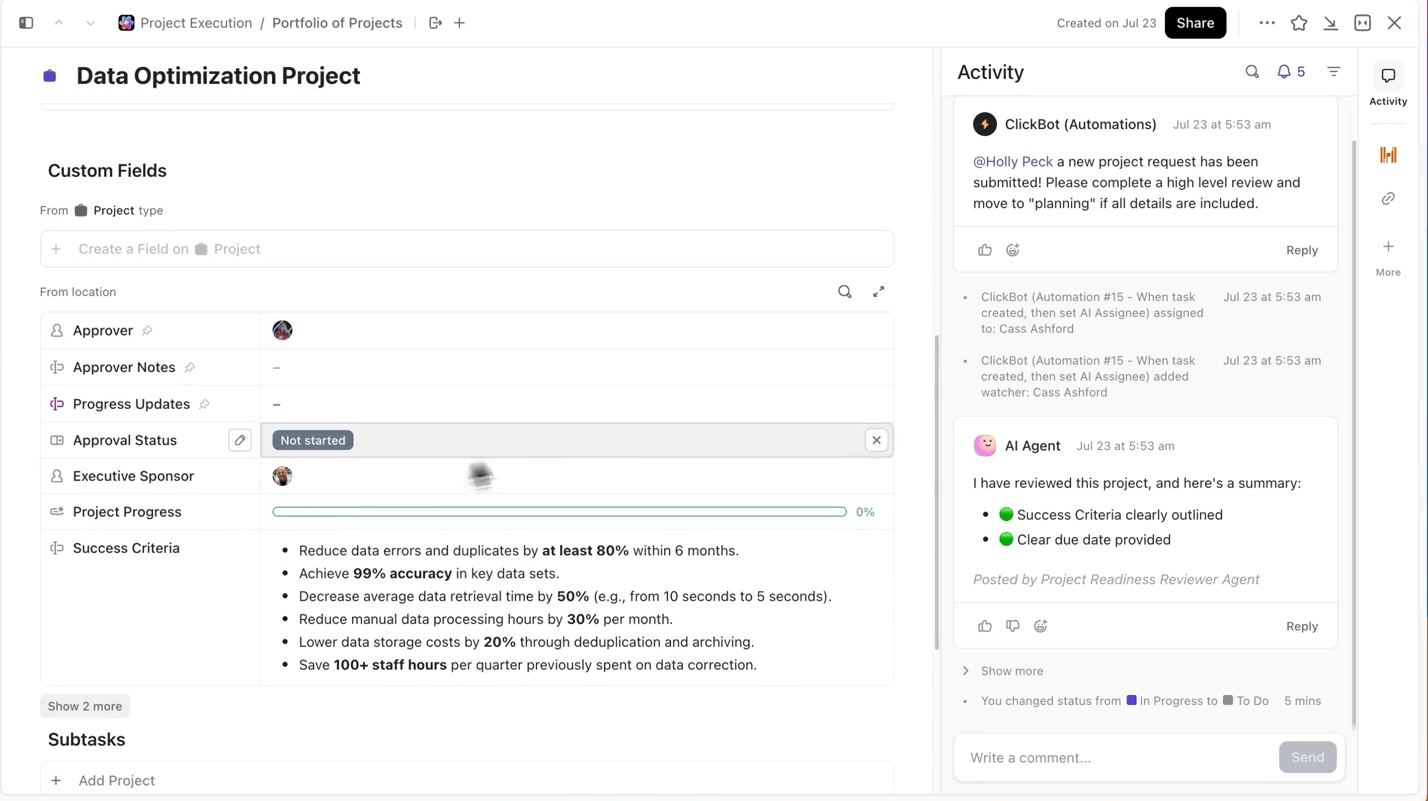
Auf diese Weise ist jedes dokumentierte Experiment durchsuchbar, leicht mit anderen zu vergleichen und reproduzierbar.
Halten Sie die Modelldokumentation mit der Arbeit verknüpft
Sie müssen nicht zwischen Jupyter-Notebooks, README-Dateien oder Slack-Threads hin- und herspringen, um den Kontext einer Experiment-Aufgabe zu verstehen.
Mit ClickUp Docs können Sie Ihre Modellarchitektur, Datenvorbereitungsskripte oder Bewertungsmetriken organisieren und zugänglich halten , indem Sie sie in einem durchsuchbaren Dokument dokumentieren, das direkt mit den Experimentaufgaben verknüpft ist, aus denen sie stammen.

💡Profi-Tipp: Führen Sie in ClickUp Docs ein aktuelles Projektbriefing, in dem alle Entscheidungen von der Architektur bis zur Bereitstellung detailliert beschrieben sind, damit neue Mitglieder des Teams sich jederzeit über die Projektdetails informieren können, ohne alte Threads durchforsten zu müssen.
Geben Sie Stakeholdern Echtzeit-Sichtbarkeit
ClickUp-Dashboards zeigen den Fortschritt des Experiments und die Workload des Teams in Echtzeit an. I
Anstatt Updates manuell zusammenzustellen oder E-Mails zu versenden, werden Dashboards automatisch auf der Grundlage der Daten in Ihren Aufgaben aktualisiert. So können Stakeholder jederzeit nachsehen, wie der Status der Dinge ist, und müssen Sie nie mit Fragen nach dem aktuellen Status unterbrechen.
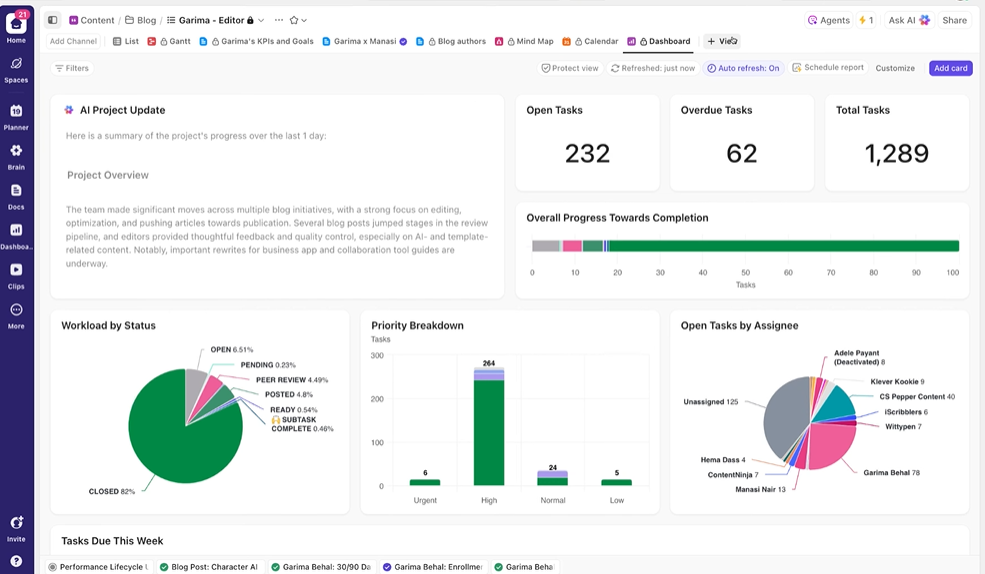
Auf diese Weise können Sie sich auf die Durchführung von Experimenten konzentrieren, anstatt ständig manuell für die Berichterstellung verantwortlich zu sein.
Machen Sie KI zu Ihrem intelligenten Projektassistenten.
Sie müssen nicht mehr wochenlang manuell Trainingsdaten durchforsten, um eine Zusammenfassung der bisherigen Experimente zu erhalten. Erwähnen Sie einfach @Brain in einem beliebigen Kommentar zu einer Aufgabe, und ClickUp Brain gibt Ihnen die benötigte Hilfe mit dem vollständigen Kontext zu Ihren vergangenen und laufenden Projekten.
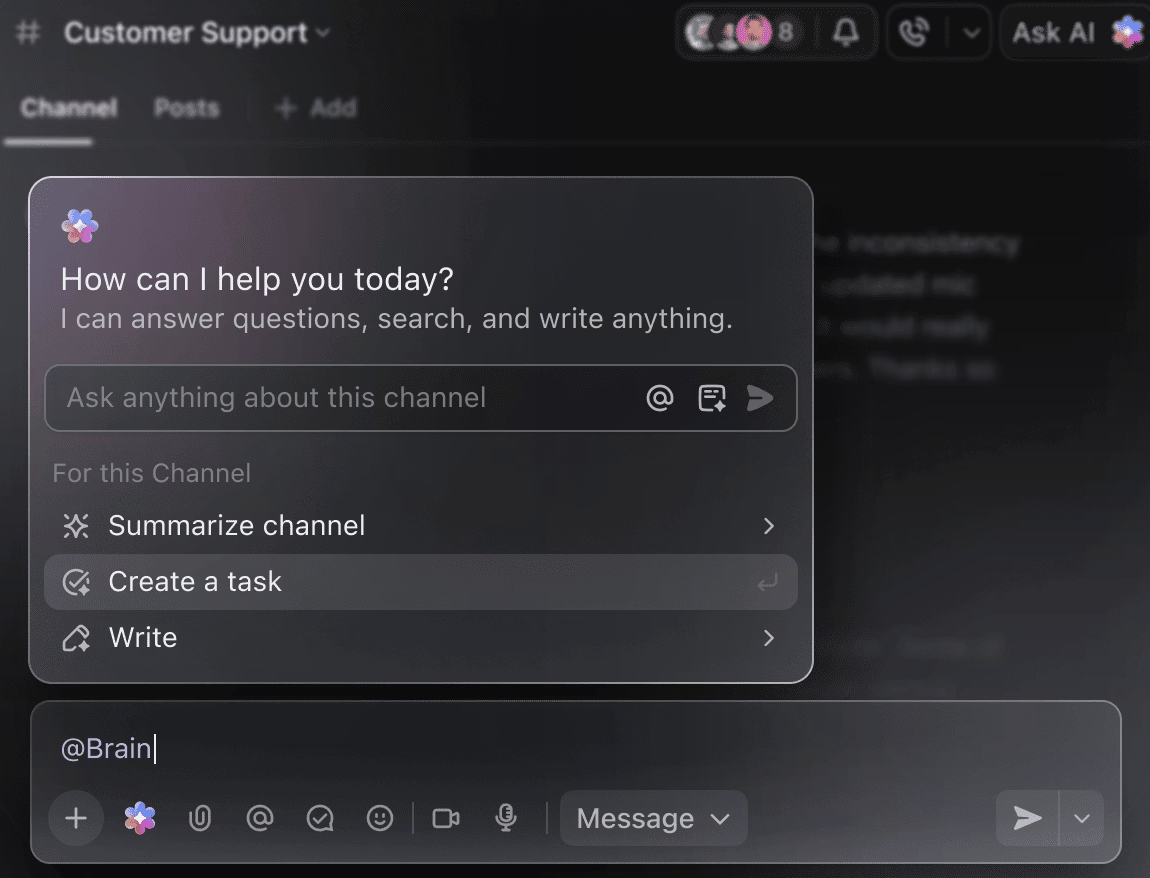
Sie können Brain bitten, „die Experimente der letzten Woche in 5 Stichpunkten zusammenzufassen” oder „ein Dokument mit den neuesten Hyperparameter-Ergebnissen zu erstellen”, und erhalten sofort ein ausgefeiltes Ergebnis.
🧠 Der Vorteil von ClickUp: Die Super Agents von ClickUp gehen noch einen Schritt weiter – sie können ganze Workflows basierend auf von Ihnen definierten Auslösern automatisieren und nicht nur Ihre Fragen beantworten. Mit Super Agents können Sie automatisch eine neue DBRX-Trainingsaufgabe erstellen, sobald ein Datensatz hochgeladen wird, Ihr Team benachrichtigen und relevante Dokumente verknüpfen, wenn der Trainingslauf beendet ist oder einen Checkpoint erreicht hat, sowie eine wöchentliche Zusammenfassung des Fortschritts erstellen und an die Stakeholder senden, ohne dass Sie selbst etwas tun müssen.
Häufige Fehler, die es zu vermeiden gilt
Ein DBRX-Trainingsprojekt zu starten ist spannend, aber einige häufige Fallstricke können Ihren Fortschritt behindern. Wenn Sie diese Fehler vermeiden, sparen Sie Zeit, Geld und viel Frust.
- Unterschätzung der Hardwareanforderungen: DBRX ist leistungsstark, aber auch groß. Der Versuch, es auf unzureichender Hardware auszuführen, führt zu Fehlern im Speicher und fehlgeschlagenen Trainingsaufträgen. Beachten Sie, dass DBRX (132B) mindestens 264 GB VRAM für 16-Bit-Inferenz oder etwa 70 GB bis 80 GB bei Verwendung von 4-Bit-Quantisierung benötigt.
- Überspringen von Datenqualitätsprüfungen: Garbage in, garbage out. Die Feinabstimmung eines unordentlichen, qualitativ minderwertigen Datensatzes führt nur dazu, dass das Modell unordentliche, qualitativ minderwertige Ergebnisse liefert.
- Ignorieren von Kontextlängen-Limiten: Das 32K-Kontextfenster von DBRX ist zwar großzügig bemessen, aber nicht unbegrenzt. Das Ergebnis, wenn Sie dem Modell Eingaben zuführen, die dieses Limit überschreiten, ist eine stille Kürzung und schlechte Leistung.
- Verwendung von Base, wenn Instruct geeignet ist: DBRX Base ist ein rohes, vortrainiertes Modell, das für weiteres, groß angelegtes Training vorgesehen ist. Für die meisten Aufgaben, bei denen Anweisungen befolgt werden müssen, sollten Sie mit DBRX Instruct beginnen, das bereits für diesen Zweck optimiert wurde.
- Trennung der Trainingsarbeit von der Projektkoordination: Wenn Ihre Nachverfolgung der Experimente in einem Tool und Ihr Projektplan in einem anderen Tool gespeichert sind, entstehen Informationssilos. Verwenden Sie eine integrierte Plattform wie ClickUp, um Ihre technische Arbeit und Ihre Projektkoordination in einer Synchronisierung zu halten.
- Vernachlässigung der Bewertung vor der Bereitstellung: Ein Modell, das mit Ihren Trainingsdaten gut funktioniert, kann in der Praxis spektakulär versagen. Validieren Sie Ihr fein abgestimmtes Modell immer anhand eines zurückbehaltenen Testsatzes, bevor Sie es in der Produktion einsetzen.
- Übersehen der Komplexität der Feinabstimmung: Da DBRX ein Mixture-of-Experts-Modell ist, erfordern Standard-Feinabstimmungsskripte möglicherweise spezielle Bibliotheken wie Megatron-LM oder PyTorch FSDP, um die Aufteilung der Parameter über mehrere GPUs hinweg zu verarbeiten.
DBRX im Vergleich zu anderen KI-Trainingsplattformen
Die Entscheidung für eine KI-Trainingsplattform ist mit einem grundlegenden Kompromiss verbunden: Kontrolle vs. Komfort. Proprietäre, API-only-Modelle sind einfach zu verwenden, binden Sie jedoch an das Ökosystem eines Anbieters.
Offene Gewichtsmodelle wie DBRX bieten vollständige Kontrolle, erfordern jedoch mehr technisches Fachwissen und Infrastruktur. Diese Wahl kann dazu führen, dass Sie sich festgefahren fühlen und unsicher sind, welcher Weg tatsächlich Ihre langfristigen Ziele unterstützt – eine Herausforderung, mit der viele Teams bei der Einführung von KI konfrontiert sind.
Diese Tabelle zeigt die wichtigsten Unterschiede auf, damit Sie eine fundierte Entscheidung treffen können.
| Gewichte | Öffnen (Benutzerdefiniert) | Proprietär | Öffnen (Benutzerdefiniert) | Proprietär |
| Feinabstimmung | Volle Kontrolle | API-basiert | Volle Kontrolle | API-basiert |
| Selbsthosting | Ja | Nein | Ja | Nein |
| Lizenz | DB Open Model | OpenAI-Bedingungen | Llama-Community | Anthropic-Begriffe |
| Kontext | 32K | 128K – 1M | 128K | 200.000 – 1 Million |
DBRX ist die richtige Wahl, wenn Sie die vollständige Kontrolle über das Modell benötigen, aus Gründen der Sicherheit oder Compliance selbst hosten müssen oder die Flexibilität einer freizügigen kommerziellen Lizenz wünschen. Wenn Sie keine dedizierte GPU-Infrastruktur haben oder dem Wert der Markteinführungsgeschwindigkeit mehr Wert beimaßen als einer benutzerdefinierten Anpassung, sind API-basierte Alternativen möglicherweise besser geeignet.
Beginnen Sie mit ClickUp intelligenter zu trainieren
DBRX bietet Ihnen eine Enterprise-gerechte Grundlage für die Erstellung benutzerdefinierter KI-Anwendungen mit einer Transparenz und Kontrolle, die Sie bei proprietären Modellen nicht finden. Die effiziente MoE-Architektur hält die Inferenzkosten niedrig, und das offene Design erleichtert die Feinabstimmung. Aber starke Technologie ist nur die halbe Miete.
Wahrer Erfolg entsteht, wenn Sie Ihre technische Arbeit auf den kollaborativen Workflow Ihres Teams abstimmen. Das Trainieren von KI-Modellen ist eine Teamleistung, bei der die Synchronisierung von Experimenten, Dokumentation und Kommunikation mit den Beteiligten entscheidend ist. Wenn Sie alles in einem einzigen konvergierten Workspace zusammenführen und die Kontextstreuung reduzieren, können Sie bessere Modelle schneller bereitstellen.
Starten Sie kostenlos mit ClickUp, um Ihre KI-Trainingsprojekte in einem Workspace zu koordinieren. ✨
Häufig gestellte Fragen
Sie können das Training mit Standard-ML-Tools wie TensorBoard, Weights & Biases oder MLflow überwachen. Wenn Sie innerhalb des Databricks-Ökosystems trainieren, ist MLflow nativ integriert, um eine nahtlose Nachverfolgung der Experimente zu ermöglichen.
Ja, DBRX kann in Standard-MLOps-Pipelines integriert werden. Durch die Containerisierung des Modells können Sie es mithilfe von Orchestrierungsplattformen wie Kubeflow oder benutzerdefinierten CI/CD-Workflows bereitstellen.
DBRX Base ist das grundlegende vortrainierte Modell für Teams, die domänenspezifisches kontinuierliches Vortraining oder eine tiefgreifende Feinabstimmung der Architektur durchführen möchten. DBRX Instruct ist eine fein abgestimmte Version, die für die Befolgung von Anweisungen optimiert ist und somit einen besseren Ausgangspunkt für die meisten Anwendungsentwicklungen darstellt.
Der Hauptunterschied liegt in der Kontrolle. DBRX bietet Ihnen vollen Zugriff auf die Modellgewichte für eine benutzerdefinierte Anpassung und Selbsthosting, während GPT-4 ein reiner API-Dienst ist.
Die DBRX-Modellgewichte sind unter der Databricks Open Model License kostenlos verfügbar. Sie sind jedoch für die Kosten der Recheninfrastruktur verantwortlich, die für die Ausführung oder Feinabstimmung des Modells erforderlich ist.