
A maioria dos desenvolvedores que criam um script de resumo Hugging Face se depara com o mesmo problema: o resumo funciona perfeitamente em seu terminal. Mas raramente se conecta ao trabalho real que deveria apoiar.
Este guia orienta você na criação de um resumidor de texto com a biblioteca Transformers do Hugging Face e, em seguida, mostra por que mesmo uma implementação perfeita pode criar mais problemas do que resolver quando sua equipe precisa de resumos que realmente se conectem a tarefas, projetos e decisões.
O que é resumo de texto?
As equipes estão afogadas em informações. Você enfrenta documentos longos, transcrições intermináveis de reuniões, trabalhos de pesquisa densos e relatórios trimestrais que levam horas para serem digeridos manualmente. Essa sobrecarga constante de informações retarda a tomada de decisões e mata a produtividade.
A resumização de texto é o processo de usar o Processamento de Linguagem Natural (NLP) para condensar esse conteúdo em uma versão curta e coerente que preserva as informações mais importantes. Pense nisso como um resumo executivo instantâneo para qualquer documento. Essa tecnologia de resumização NLP geralmente usa uma das duas abordagens:
Resumo extrativo: esse método funciona identificando e extraindo as frases mais importantes diretamente do texto original. É como ter um marcador que seleciona automaticamente os pontos-chave para você. O resumo final é uma coleção de frases originais.
Resumo abstrativo: esse método mais avançado gera frases totalmente novas para capturar o significado central do texto original. Ele parafraseia as informações, resultando em um resumo mais fluido e semelhante ao humano, muito parecido com a forma como uma pessoa explicaria uma longa história com suas próprias palavras.
Você vê os resultados disso em todos os lugares. Ele é usado para condensar notas de reuniões em itens de ação, destilar o feedback dos clientes em tendências e criar visões gerais rápidas da documentação do projeto. O objetivo é sempre o mesmo: obter as informações essenciais sem ler cada palavra.
📮 ClickUp Insight: O profissional médio passa mais de 30 minutos por dia procurando informações relacionadas ao trabalho. Isso significa mais de 120 horas por ano perdidas vasculhando e-mails, threads do Slack e arquivos espalhados. Um assistente de IA inteligente integrado ao seu espaço de trabalho pode mudar isso. O ClickUp Brain fornece insights e respostas instantâneas, exibindo os documentos, conversas e detalhes de tarefas certos em segundos, para que você possa parar de procurar e começar a trabalhar.
💫 Resultados reais: equipes como a QubicaAMF recuperaram mais de 5 horas semanais usando o ClickUp, mais de 250 horas anuais por pessoa, eliminando processos desatualizados de gerenciamento de conhecimento.
Por que usar o Hugging Face para resumir textos?
Criar um modelo personalizado de resumo de texto do zero é uma tarefa gigantesca. Requer enormes conjuntos de dados para treinamento, recursos computacionais poderosos e caros e uma equipe de especialistas em aprendizado de máquina. Essa alta barreira de entrada impede a maioria das equipes de engenharia e de produtos de sequer começar.
O Hugging Face é a plataforma que resolve esse problema. É uma comunidade de código aberto e uma plataforma de ciência de dados que dá acesso a milhares de modelos pré-treinados, democratizando efetivamente a resumização LLM para desenvolvedores. Em vez de construir do zero, você pode começar com um modelo poderoso que já está 99% pronto.
Veja por que tantos desenvolvedores recorrem ao Hugging Face: 🛠️
Acesso a modelos pré-treinados: O Hugging Face Hub é um enorme repositório com mais de 2 milhões de modelos públicos treinados por empresas como Google, Meta e OpenAI. Você pode baixar e usar esses checkpoints de última geração em seus próprios projetos.
API de pipeline simplificada: a função de pipeline é uma API de alto nível que lida com todas as etapas complexas, como pré-processamento de texto, inferência de modelo e formatação de saída, em apenas algumas linhas de código.
Variedade de modelos: você não está limitado a uma única opção. Você pode escolher entre uma ampla variedade de arquiteturas, como BART, T5 e Pegasus, cada uma com diferentes pontos fortes, tamanhos e características de desempenho.
Flexibilidade da estrutura: a biblioteca Transformers funciona perfeitamente com as duas estruturas de deep learning mais populares, PyTorch e TensorFlow. Você pode usar aquela com a qual sua equipe já está familiarizada.
Suporte da comunidade: com documentação abrangente, cursos oficiais e uma comunidade ativa de desenvolvedores, é fácil encontrar tutoriais e obter ajuda quando você encontrar problemas.
Embora o Hugging Face seja incrivelmente poderoso para desenvolvedores, é importante lembrar que se trata de uma solução baseada em código. Ela requer conhecimento técnico para ser implementada e mantida. Isso nem sempre é adequado para equipes não técnicas que precisam apenas resumir seu trabalho.
🧐 Você sabia? A biblioteca Transformers da Hugging Face tornou comum o uso de modelos de PNL de última geração com poucas linhas de código, e é por isso que os protótipos de resumo geralmente começam por aí.
O que são transformadores Hugging Face?
Então você decidiu usar o Hugging Face, mas qual é a tecnologia real por trás disso? A tecnologia central é uma arquitetura chamada Transformer. Quando foi apresentada em um artigo de 2017 intitulado “Attention Is All You Need” (Atenção é tudo o que você precisa), ela mudou completamente o campo da NLP.
Antes do Transformers, os modelos tinham dificuldade para entender o contexto de frases longas. A principal inovação do Transformer é o mecanismo de atenção, que permite ao modelo ponderar a importância de diferentes palavras no texto de entrada ao processar uma palavra específica. Isso ajuda a capturar dependências de longo alcance e entender o contexto, o que é crucial para criar resumos coerentes.
A biblioteca Hugging Face Transformers é um pacote Python que torna incrivelmente fácil usar esses modelos complexos. Você não precisa de um doutorado em aprendizado de máquina. A biblioteca abstrai o trabalho pesado.
Os três componentes principais que você precisa conhecer
- Tokenizadores: os modelos não entendem palavras; eles entendem números. Um tokenizador pega seu texto de entrada e o converte em uma sequência de tokens numéricos — um processo chamado tokenização — que o modelo pode processar.
- Modelos: são as próprias redes neurais pré-treinadas. Para resumos, geralmente são modelos sequência a sequência com uma estrutura codificador-decodificador. O codificador lê o texto inserido para criar uma representação numérica, e o decodificador usa essa representação para gerar o resumo.
- Pipelines: Esta é a maneira mais fácil de usar um modelo. Um pipeline agrupa um modelo pré-treinado com seu tokenizador correspondente e lida com todas as etapas de pré-processamento da entrada e pós-processamento da saída para você.
Dois dos modelos mais populares para resumos são o BART e o T5. O BART (Bidirectional and Auto-Regressive Transformer) é particularmente bom em resumos abstratos, produzindo resumos que parecem muito naturais. O T5 (Text-to-Text Transfer Transformer) é um modelo versátil que enquadra todas as tarefas de NLP como um problema de texto para texto, tornando-o um poderoso multifuncional.
🎥 Assista a este vídeo para ver uma comparação entre os melhores resumidores de PDF com IA e saber quais ferramentas oferecem os resumos mais rápidos e precisos sem perder o contexto.
Como criar um resumidor de texto com o Hugging Face
Pronto para criar seu próprio exemplo de resumidor? Tudo o que você precisa é de alguns conhecimentos básicos de Python, um editor de código como o VS Code e uma conexão com a internet. Todo o processo leva apenas quatro etapas. Você terá um resumidor funcional em poucos minutos.
Etapa 1: instale as bibliotecas necessárias
Primeiro, você precisa instalar as bibliotecas necessárias. A principal delas é a transformers. Você também precisará de uma estrutura de aprendizado profundo, como PyTorch ou TensorFlow. Usaremos o PyTorch para este exemplo.
Abra seu terminal ou prompt de comando e execute o seguinte comando:

Alguns modelos, como o T5, também exigem a biblioteca sentencepiece para seu tokenizador. É uma boa ideia instalá-la também.

💡 Dica profissional: crie um ambiente virtual Python antes de instalar esses pacotes. Isso mantém as dependências do seu projeto isoladas e evita conflitos com outros projetos na sua máquina.
Etapa 2: Carregue o modelo e o tokenizador
A maneira mais fácil de começar é usando a função pipeline. Ela lida automaticamente com o carregamento do modelo e tokenizador corretos para a tarefa de resumo.
Em seu script Python, importe o pipeline e inicialize-o assim:

Aqui, estamos especificando duas coisas:
A tarefa: informamos ao pipeline que queremos realizar uma “resenha”.
O modelo: escolhemos um checkpoint de modelo pré-treinado específico do Hugging Face Hub. O facebook/bart-large-cnn é uma escolha popular, treinada em artigos de notícias e funciona bem para resumos de uso geral. Para testes mais rápidos, você pode usar um modelo menor, como o t5-small.
Na primeira vez que você executar este código, ele baixará os pesos do modelo do Hub, o que pode levar alguns minutos. Depois disso, o modelo será armazenado em cache em sua máquina local para carregamento instantâneo.
Etapa 3: Crie a função de resumo
Para tornar seu código limpo e reutilizável, é melhor envolver a lógica de resumo em uma função. Isso também facilita a experimentação com diferentes parâmetros.
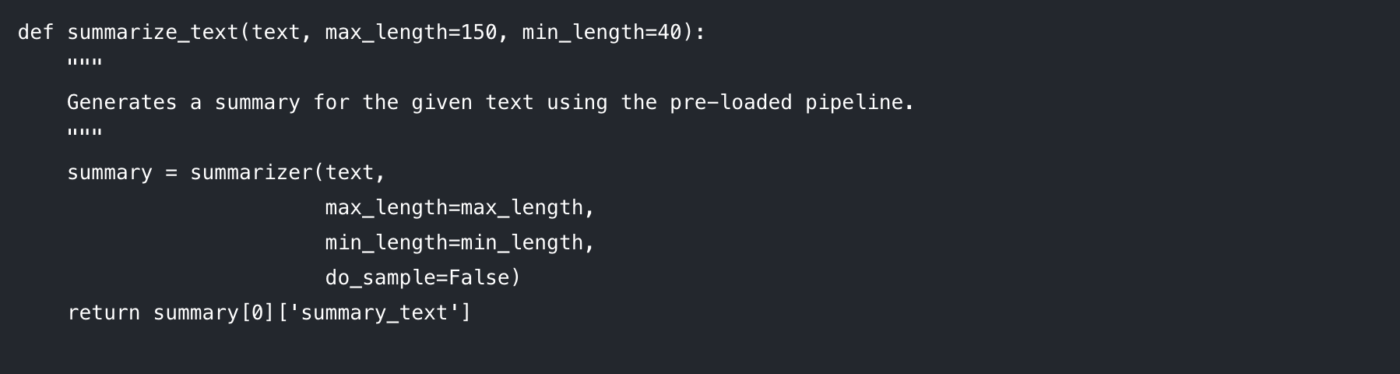
Vamos detalhar os parâmetros que você pode controlar:
max_length: Define o número máximo de tokens (aproximadamente, palavras) para o resumo de saída.
min_length: Define o número mínimo de tokens para evitar que o modelo gere resumos excessivamente curtos ou vazios.
do_sample: Quando definido como False, o modelo usa um método determinístico (como a pesquisa de feixe) para gerar o resumo mais provável. Definir como True introduz aleatoriedade, o que pode produzir resultados mais criativos, mas menos previsíveis.
Ajustar esses parâmetros é fundamental para obter a qualidade de saída desejada.
Etapa 4: Gere seu resumo
Agora vem a parte divertida. Passe seu texto para a função e imprima o resultado. 🤩

Você deverá ver uma versão resumida do artigo impressa no seu console. Se você encontrar problemas, aqui estão algumas soluções rápidas:
O texto inserido é muito longo: o modelo pode apresentar um erro se sua inserção exceder o comprimento máximo (geralmente 512 ou 1024 tokens). Adicione truncation=True dentro da chamada do resumidor() para cortar automaticamente inserções longas.
O resumo é muito genérico: tente aumentar o parâmetro num_beams (por exemplo, num_beams=4). Isso faz com que o modelo pesquise mais minuciosamente por um resumo melhor, mas pode ser um pouco mais lento.
Essa abordagem baseada em código é fantástica para desenvolvedores que criam aplicativos personalizados. Mas o que acontece quando você precisa integrar isso ao trabalho diário de uma equipe? É aí que as limitações começam a aparecer.
Limitações do Hugging Face para resumos de texto
O Hugging Face é uma ótima opção quando você deseja flexibilidade e controle. Mas, assim que você tenta usá-lo em fluxos de trabalho reais em equipe (não apenas em um notebook de demonstração), alguns desafios previsíveis surgem rapidamente.
Limites de tokens e dores de cabeça com documentos longos
A maioria dos modelos de resumo tem um comprimento máximo de entrada fixo. Por exemplo, o facebook/bart-large-cnn está configurado com max_position_embeddings = 1024. Isso significa que documentos mais longos geralmente exigem truncamento ou fragmentação.
Se você precisar apenas de uma base rápida, pode ativar o truncamento no pipeline e seguir em frente. Mas se precisar de resumos fiéis de documentos longos, normalmente acaba criando uma lógica de fragmentação e, em seguida, fazendo uma segunda passagem, um “resumo dos resumos”, para unir os resultados. Isso é engenharia extra e é fácil obter resultados inconsistentes.
Risco de alucinação (e o custo da verificação)
Modelos abstrativos podem, às vezes, gerar alucinações, produzindo textos que parecem plausíveis, mas são factualmente incorretos. Para usos críticos nos negócios, isso cria um problema: cada resumo precisa de verificação manual. Nesse ponto, você não está realmente economizando tempo, apenas transferindo o trabalho para uma parte diferente do processo.
Falta de consciência do contexto
Um modelo Hugging Face só conhece o texto que você insere nele. Ele não tem compreensão dos objetivos do seu projeto, das pessoas envolvidas ou de como um documento se relaciona com outro, carecendo da inteligência contextual dos sistemas modernos. Ele não pode dizer se um resumo de uma ligação de um cliente contradiz o documento de requisitos do projeto, porque vive isolado.
Sobrecarga de integração (o problema da “última milha”)
Gerar um resumo geralmente é a parte fácil. O verdadeiro desafio é o que vem a seguir.
Para onde vai o resumo? Quem o vê? Como ele se transforma em uma tarefa acionável? Como você o conecta ao trabalho que o desencadeou?
Resolver essa “última etapa” significa criar integrações personalizadas e código de ligação. Isso aumenta o trabalho inicial do desenvolvedor e, muitas vezes, cria um fluxo de trabalho complicado para todos os outros.
Barreira técnica e manutenção contínua
Uma abordagem baseada em Python é mais acessível para pessoas que sabem programar. Isso cria uma barreira prática para as equipes de marketing, vendas e operações, o que significa que a adoção permanece limitada.
Ele também vem com manutenção contínua: gerenciamento de dependências, atualização de bibliotecas e manutenção de tudo funcionando à medida que as APIs e os modelos evoluem. O que começa como uma vitória rápida pode silenciosamente se tornar outro sistema para cuidar.
📮 ClickUp Insight: 42% das interrupções no trabalho vêm da necessidade de alternar entre plataformas, gerenciar e-mails e pular entre reuniões. E se você pudesse eliminar essas interrupções dispendiosas? O ClickUp une seus fluxos de trabalho (e bate-papos) em uma única plataforma simplificada. Inicie e gerencie suas tarefas em bate-papos, documentos, quadros brancos e muito mais, enquanto recursos alimentados por IA mantêm o contexto conectado, pesquisável e gerenciável.
A questão mais importante: expansão do contexto
Mesmo que seu script de resumo funcione perfeitamente, sua equipe ainda pode perder tempo porque o resultado está desconectado de onde o trabalho realmente acontece.
Isso é dispersão de contexto, quando as equipes perdem horas procurando informações, alternando entre aplicativos e procurando arquivos em plataformas desconectadas.
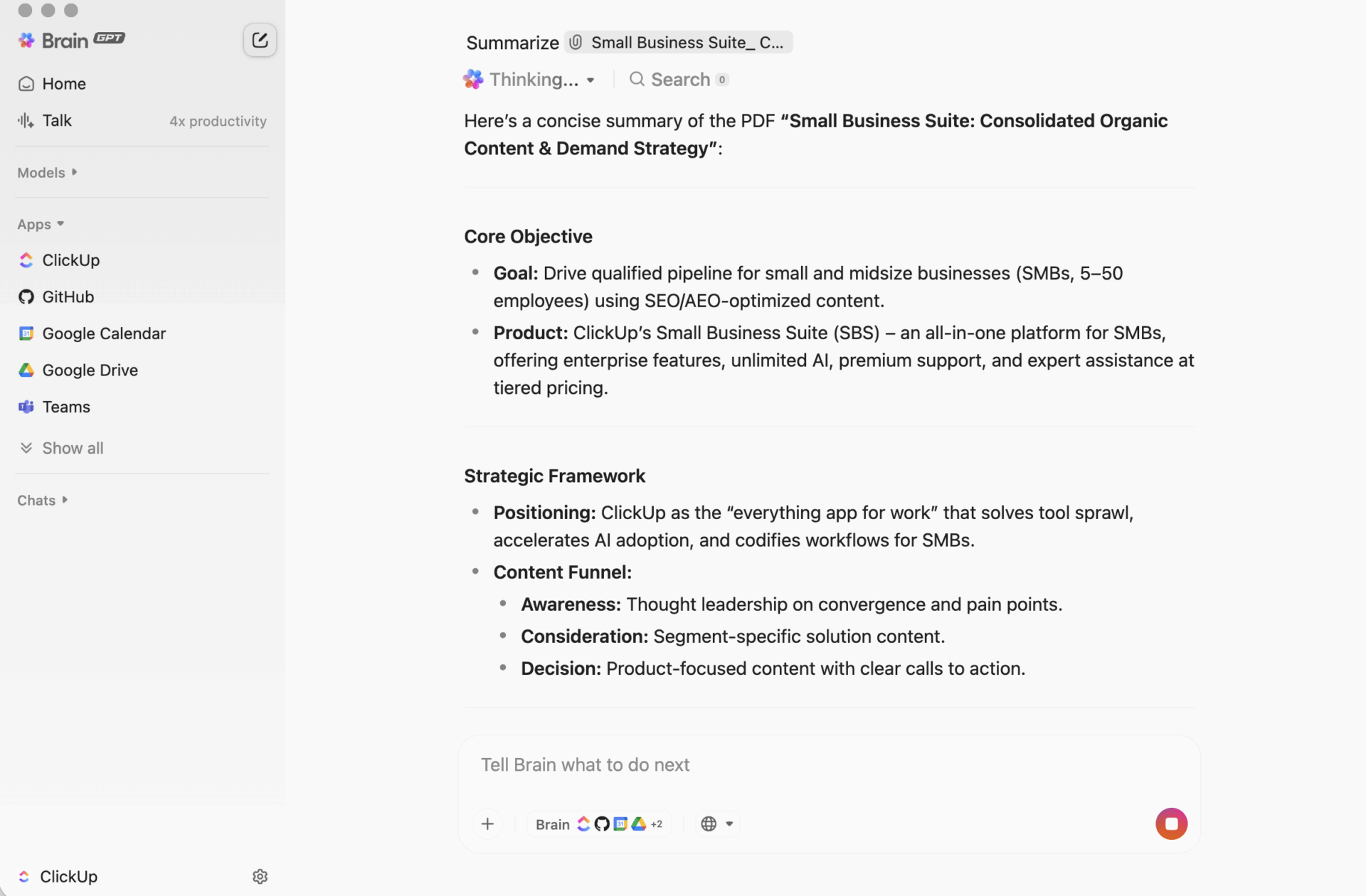
É aqui que um espaço de trabalho convergente muda o jogo. Em vez de gerar resumos em um único lugar e tentar “movê-los para o trabalho” mais tarde, um sistema convergente mantém projetos, documentos e conversas juntos, com o ClickUp Brain incorporado como camada de inteligência. Seus resumos permanecem conectados a tarefas e documentos, de modo que o próximo passo é óbvio e a transferência é imediata.
Resumo que se transforma em ação com o ClickUp
Um script de resumo pode funcionar perfeitamente e ainda assim prejudicar sua equipe de uma maneira irritante: o resumo acaba ficando em algum lugar separado do trabalho.
Essa lacuna cria uma dispersão de contexto, em que as informações ficam espalhadas por documentos, conversas de chat, tarefas e “notas rápidas” em ferramentas que não se conectam. As pessoas gastam mais tempo procurando o resumo do que usando-o. A verdadeira vitória não é apenas gerar um resumo. É manter esse resumo vinculado às decisões, aos responsáveis e às próximas etapas, onde o trabalho realmente acontece.
É isso que o ClickUp Brain faz de diferente. Ele resume tarefas, documentos e conversas dentro do mesmo espaço de trabalho onde seus projetos estão, para que sua equipe possa entender algo e agir sem precisar mudar de ferramenta.

ClickUp BrainGPT: interaja com resumos usando linguagem natural
No desktop, o BrainGPT é a interface conversacional do ClickUp Brain. Em vez de abrir scripts, notebooks ou ferramentas externas de IA, sua equipe pode solicitar o que precisa em linguagem simples, diretamente no ClickUp.
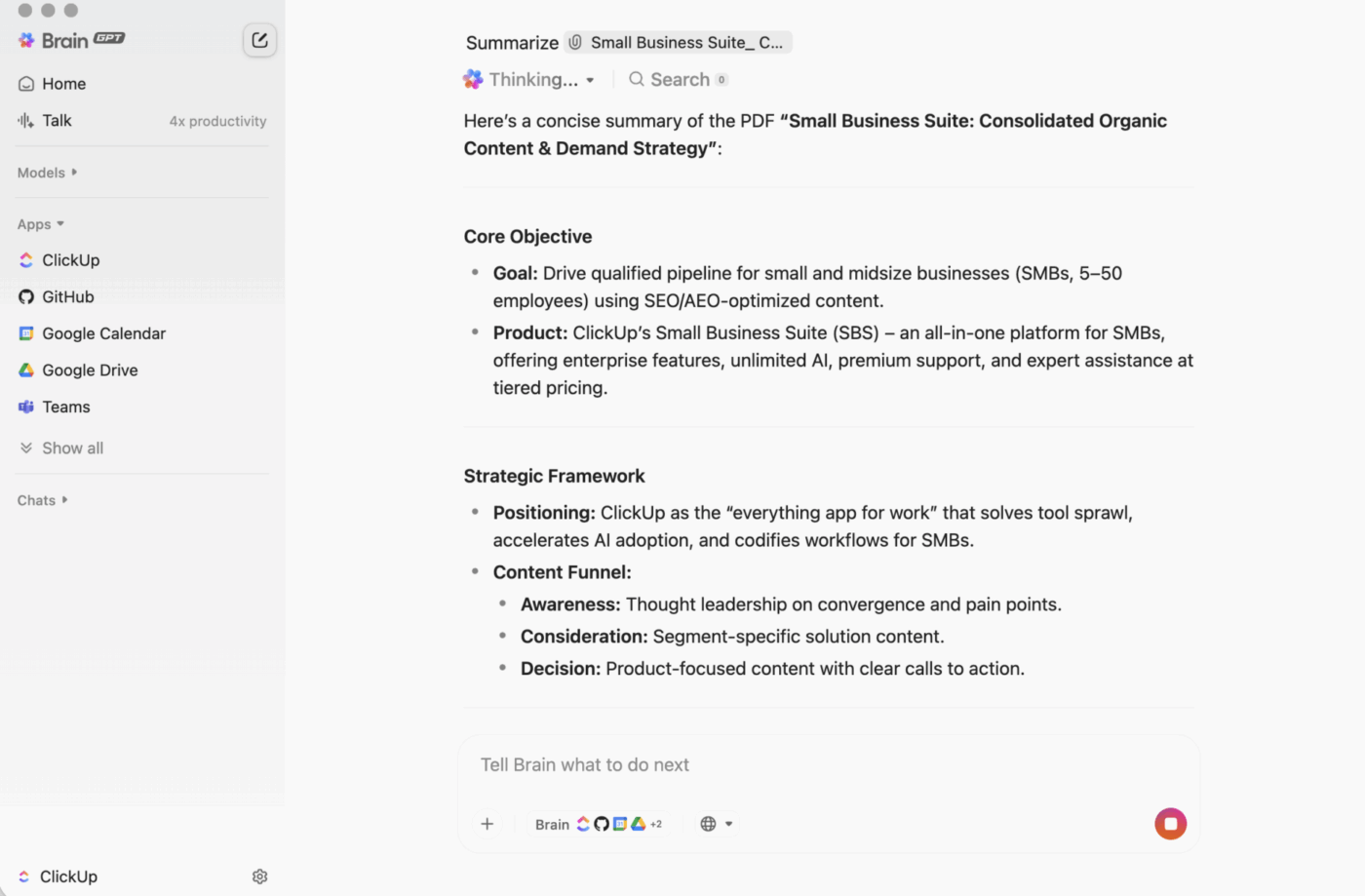
Você pode digitar (ou usar o recurso de conversão de voz em texto) para:
- Resuma uma longa descrição de tarefa, sequência de comentários ou documento.
- Dê continuidade com perguntas como “Quais são os próximos passos?” ou “Quem é o responsável por isso?”
- Transforme um resumo em ação criando tarefas a partir dele, com responsáveis e prazos.
Como o ClickUp Brain funciona dentro do seu espaço de trabalho, o resultado é baseado no contexto ao vivo: descrições de tarefas, comentários, subtarefas, documentos vinculados e estrutura do projeto. Você não está colando texto em uma ferramenta separada e torcendo para que nada importante seja perdido.
Por que isso supera um fluxo de trabalho de resumo baseado em código para a maioria das equipes
Um fluxo de trabalho criado por desenvolvedores pode gerar resumos sólidos. O atrito surge depois disso, quando alguém precisa copiar o resultado para o local onde o trabalho é realizado, traduzi-lo em tarefas e, em seguida, acompanhar o andamento.
O ClickUp Brain fecha esse ciclo:
Não é necessário saber programarQualquer membro da equipe pode resumir um documento, uma sequência de tarefas ou um conjunto confuso de comentários sem instalar nada ou escrever código.
Resumos sensíveis ao contexto O ClickUp Brain pode incluir as partes que as pessoas geralmente esquecem: decisões ocultas nos comentários, bloqueadores mencionados nas respostas, subtarefas que alteram o significado de “concluído”.
Os resumos ficam onde o trabalho ficaVocê pode acompanhar o andamento de uma tarefa, adicionar um resumo na parte superior do ClickUp Docs ou recapitular rapidamente uma discussão sem criar outro “documento de resumo” que ninguém vai ler.
Menos ferramentas Você não precisa de scripts separados, notebooks Jupyter, chaves API ou um fluxo de trabalho que apenas uma pessoa entende. Seus documentos, tarefas e resumos ficam todos no mesmo sistema.
Essa é a vantagem prática de um espaço de trabalho convergente: resumo, ação e colaboração acontecem juntos, em vez de serem unidos após o fato.
Essa é a vantagem prática de um espaço de trabalho convergente: resumo, ação e colaboração acontecem juntos, em vez de serem unidos após o fato.
Como isso funciona na vida real
Aqui estão alguns padrões comuns que as equipes utilizam:
- Resuma uma sequência de comentários: abra uma tarefa com uma longa discussão, clique na opção IA e obtenha um resumo rápido do que mudou e do que é importante.
- Resuma um documento: abra um documento do ClickUp e use “Ask AI” para gerar um resumo da página para que qualquer pessoa possa se orientar rapidamente.
- Extraia itens de ação: pegue o resumo e converta imediatamente as próximas etapas em tarefas com responsáveis e prazos, para que o impulso não se perca na transferência.
| Capacidade | Hugging Face (baseado em código) | ClickUp Brain |
|---|---|---|
| Configuração necessária | Ambiente Python, bibliotecas, codificação | Nenhum, integrado |
| Consciência do contexto | Apenas texto (o que você passa) | Contexto completo do espaço de trabalho (tarefas, documentos, comentários, subtarefas) |
| Integração do fluxo de trabalho | Exportação/importação manual | Nativo: resumos podem se tornar tarefas e atualizações |
| Habilidades técnicas necessárias | Nível de desenvolvedor | Qualquer pessoa da equipe |
| Manutenção | Manutenção contínua do modelo e do código | Atualizações automáticas |
De resumos à execução com Super Agents
Os resumos são úteis. O difícil é garantir que eles se transformem consistentemente em ações, especialmente quando o volume aumenta.
É aí que entram os Super Agentes do ClickUp . Eles podem usar informações resumidas e levar o trabalho adiante com base em gatilhos e condições, dentro do mesmo espaço de trabalho.
Com o Super Agents, as equipes podem:
- Resuma as mudanças em uma programação (recapitulação semanal do projeto, relatórios diários de status)
- Extraia itens de ação e atribua responsáveis automaticamente
- Sinalize trabalhos paralisados (tarefas presas em revisão, tópicos sem resposta, próximas etapas atrasadas)
- Mantenha a visibilidade da liderança elevada sem relatórios manuais
Em vez de um resumo ficar como texto estático, os agentes ajudam a garantir que o resumo se torne um plano e que o plano se torne progresso.
Resumos que vivem onde o trabalho acontece
Os Hugging Face Transformers são ótimos quando você precisa de um aplicativo personalizado, um pipeline sob medida ou controle total sobre o comportamento do modelo.
Mas, para a maioria das equipes, o maior problema não é “Podemos resumir isso?”, e sim “Podemos resumir isso e imediatamente transformá-lo em trabalho, com responsáveis, prazos e visibilidade?”.
Se o seu objetivo é produtividade da equipe e execução rápida, o ClickUp Brain oferece resumos contextualizados, exatamente onde o trabalho acontece, com um caminho claro desde “aqui está o essencial” até “aqui está o que faremos a seguir”.
Pronto para pular a configuração e começar a resumir onde seu trabalho realmente acontece? Comece gratuitamente com o ClickUp e deixe o Brain cuidar do trabalho pesado.