

São 3 da manhã.
Um alarme estridente o acorda com um sobressalto.
Você se levanta rapidamente, atraído pelo brilho da tela do computador. Um sistema crítico está fora do ar. O pânico se instala. Esta não é uma cena de um thriller de ficção científica; é um cenário de pesadelo para todos os profissionais de TI.
Mas isso também é uma realidade. Quando o mundo digital para, a pressão é imensa.
É aqui que o gerenciamento de incidentes se torna uma tábua de salvação.
O gerenciamento de incidentes é fundamental para lidar e resolver rapidamente as interrupções do projeto. Ao gerenciar essas interrupções com eficiência, você pode se concentrar mais em entregar resultados e concluir seu projeto com eficácia.
Neste artigo, exploraremos o processo de gerenciamento de incidentes e compartilharemos as melhores práticas para ajudá-lo a implementar um plano de contingência robusto. Isso garantirá que você possa lidar de forma eficaz com quaisquer incidentes futuros no projeto.
Entendendo o gerenciamento de incidentes
Incidentes são interrupções ou ameaças potenciais que afetam a qualidade do serviço. Por exemplo, um aplicativo comercial que trava ou um servidor web lento, causando problemas de produtividade, são considerados incidentes. Esses eventos podem variar de pequenas falhas que afetam alguns usuários a grandes interrupções que afetam serviços globais.
O gerenciamento de incidentes é o processo de identificar, priorizar e resolver problemas de TI para minimizar interrupções nas operações comerciais, ao mesmo tempo em que implementa medidas para evitar ocorrências futuras. Esse processo de prevenção proativa de incidentes é vital para qualquer organização, pois interrupções no serviço podem levar a perdas comerciais significativas. O gerenciamento eficiente de incidentes permite que as equipes priorizem e resolvam problemas rapidamente, garantindo uma melhor continuidade do serviço.
Ao lidar com incidentes, as equipes precisam de um plano bem definido que as ajude a:
- Responda prontamente para minimizar o tempo de inatividade
- Comunique-se de forma eficaz com clientes, partes interessadas, proprietários de serviços e outras partes relevantes.
- Colabore de forma integrada para acelerar a resolução de problemas e eliminar obstáculos à resolução.
- Melhore continuamente aprendendo com os incidentes e aplicando essas lições para aprimorar a qualidade do serviço e refinar os processos.
Saber como redigir um relatório de incidentes também é essencial neste contexto. Relatórios detalhados de incidentes facilitam uma análise completa, identificam as causas principais e desenvolvem estratégias preventivas.
A relação entre gerenciamento de incidentes, ITSM e DevOps
O gerenciamento de incidentes é um componente essencial do Gerenciamento de Serviços de TI (ITSM), garantindo que os serviços de TI permaneçam disponíveis e confiáveis. Enquanto isso, o DevOps integra equipes de desenvolvimento e operações para melhorar a colaboração e a eficiência.
Alinhar o gerenciamento de incidentes com os princípios de gerenciamento de projetos DevOps pode ajudar as organizações a responder a incidentes de forma rápida e eficaz. Esse alinhamento promove melhorias contínuas, recuperação mais rápida de incidentes e prestação de serviços aprimorada.
Entendendo os processos de gerenciamento de incidentes
Um processo eficaz de gerenciamento de incidentes permite que as equipes de TI investiguem, documentem e resolvam interrupções ou falhas no serviço com eficiência.
Diferentes empresas costumam adotar vários tipos de processos de gerenciamento de incidentes adaptados às suas necessidades específicas. Como não existe uma abordagem única que sirva para todos, você encontrará diversas metodologias nas organizações.
Algumas equipes seguem os processos tradicionais de gerenciamento de incidentes de TI, como os detalhados nas certificações da Information Technology Infrastructure Library (ITIL). Outras preferem uma abordagem mais orientada para a Engenharia de Confiabilidade do Site (SRE) ou DevOps.
O fluxo de trabalho de gerenciamento de incidentes ITIL concentra-se em reduzir o tempo de inatividade e mitigar o impacto dos incidentes na produtividade dos funcionários. Usando modelos de relatórios de incidentes, as equipes podem estabelecer um fluxo de trabalho repetível para registrar, diagnosticar e resolver incidentes, mantendo registros abrangentes de suas atividades.
A estrutura ITIL é predominantemente usada por equipes de TI que gerenciam serviços dentro das empresas. Essas equipes geralmente personalizam a ampla cobertura de incidentes e processos da ITIL para atender às suas necessidades.
O ITIL é particularmente benéfico para criar uma cultura de resolução proativa de problemas. Seus processos estruturados ajudam as equipes a acompanhar consistentemente os incidentes e as ações, aprimorando os relatórios e as análises, o que acaba levando a serviços mais robustos e equipes mais eficazes.
IA e aprendizado de máquina no gerenciamento de incidentes
A integração da IA e do aprendizado de máquina no gerenciamento de incidentes transforma a forma como as equipes lidam com incidentes. As ferramentas baseadas em IA podem analisar grandes quantidades de dados para prever possíveis incidentes antes que eles ocorram, permitindo medidas preventivas.
Os algoritmos de aprendizado de máquina podem identificar padrões e anomalias que os analistas humanos podem deixar passar, fornecendo insights mais profundos sobre as causas principais e possíveis soluções. Essas tecnologias também podem automatizar tarefas rotineiras, como registro de incidentes e diagnósticos iniciais, liberando recursos humanos para a resolução de problemas mais complexos.
Alta disponibilidade e tempo de inatividade na gestão de incidentes
Minimizar o tempo de inatividade é fundamental para um gerenciamento eficaz de incidentes. A alta disponibilidade garante que os sistemas estejam operacionais e acessíveis em todos os momentos, minimizando o risco de interrupções no serviço. Redundância, mecanismos de failover e balanceamento de carga são empregados para alcançar alta disponibilidade.
Reduzir o tempo de inatividade é fundamental para manter a produtividade e a satisfação do cliente. Os processos de gerenciamento de incidentes devem incluir planos robustos para resposta e recuperação rápidas, a fim de minimizar a duração e o impacto das interrupções.
Processo de gerenciamento de incidentes de TI em detalhes
O gerenciamento de incidentes envolve identificar, registrar, categorizar, priorizar e resolver incidentes de maneira eficiente.
Compreender essas etapas ajuda a garantir uma abordagem sistemática para gerenciar incidentes, minimizar o tempo de inatividade e prevenir ocorrências futuras.
Etapas do processo de gerenciamento de incidentes de TI
1. Identifique e registre o incidente
Os incidentes podem ter várias origens, incluindo funcionários, clientes, fornecedores ou sistemas de monitoramento. A etapa inicial envolve identificar e registrar o incidente. Esses registros, geralmente chamados de tickets de incidente, normalmente incluem:
- O nome da pessoa que reportou o incidente
- A data e a hora em que o incidente foi relatado
- Uma descrição do incidente detalhando o que está com defeito ou fora de serviço
- Um número de identificação exclusivo é atribuído para fins de rastreamento.
2. Categorize o incidente
É fundamental atribuir a cada incidente uma categoria lógica e intuitiva (e subcategoria, se necessário). Essa categorização ajuda a analisar dados para identificar tendências e padrões, o que é essencial para o gerenciamento eficaz de problemas e a prevenção de incidentes futuros.
3. Priorize o incidente
Cada incidente deve ser priorizado com base em seu impacto nos negócios, no número de indivíduos afetados, nos SLAs relevantes e nas possíveis implicações financeiras, de segurança e de conformidade.
As equipes responsáveis determinam sua prioridade relativa comparando-o com outros incidentes em aberto. Determinar os níveis de gravidade e prioridade com antecedência é uma prática recomendada, permitindo que os gerentes de incidentes avaliem a prioridade rapidamente.
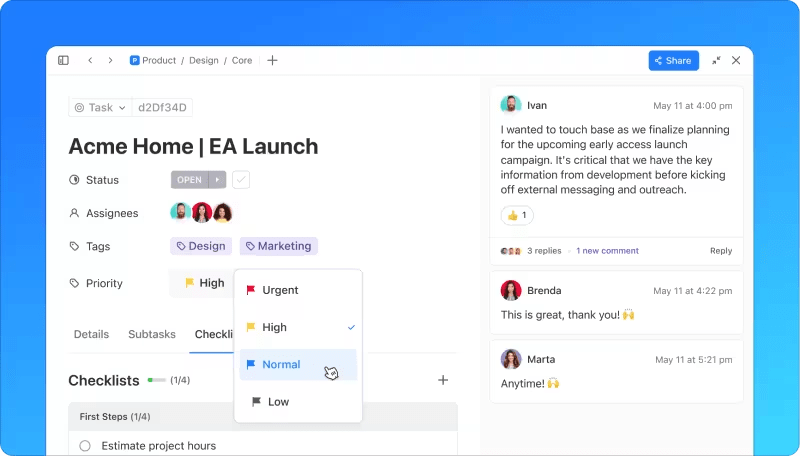
4. Responda ao incidente
A fase de resposta envolve várias ações importantes:
- Diagnóstico inicial: idealmente, a equipe de suporte de primeira linha diagnostica e resolve o incidente. Se não for possível, ela registra todas as informações pertinentes e encaminha o caso para a equipe de nível superior.
- Escalonamento: a equipe seguinte continua o processo de diagnóstico. Se não for possível resolver o incidente, ele é escalonado.
- Comunicação: atualizações regulares são compartilhadas com as partes interessadas internas e externas afetadas.
- Investigação e diagnóstico: essa fase continua até que a natureza do incidente seja identificada. As equipes podem trazer recursos externos ou membros de outros departamentos para ajudar na resolução.
- Resolução e recuperação: após o diagnóstico, a equipe executa as etapas necessárias para resolver o incidente. A recuperação envolve o tempo necessário para que as operações sejam totalmente restauradas, pois algumas correções, como patches de bugs, podem precisar de testes e implantação mesmo após a resolução.
- Encerramento: se o incidente foi escalado, ele é devolvido ao service desk para encerramento. Somente os funcionários do service desk podem encerrar incidentes, garantindo a qualidade e a satisfação do cliente.
Gerenciamento de incidentes para equipes de DevOps e SRE
As abordagens DevOps e SRE ganharam imensa popularidade, especialmente com o surgimento de serviços em nuvem sempre ativos, aplicativos da Web acessíveis globalmente, microsserviços e soluções de software como serviço (SaaS).
Os softwares modernos, essenciais para uso pessoal e profissional, raramente são hospedados em um servidor local. Em vez disso, esses aplicativos são normalmente implantados em data centers, atendendo a milhares ou milhões de usuários em todo o mundo. Agilidade e velocidade são cruciais para as equipes responsáveis pela manutenção desses serviços. Qualquer tempo de inatividade pode ter consequências de longo alcance, afetando várias organizações simultaneamente.
A filosofia “você constrói, você opera” oferece às equipes ágeis a flexibilidade necessária. Mas também pode confundir as linhas de responsabilidade. Embora as equipes de DevOps possam prosperar com processos de desenvolvimento menos rígidos, é essencial padronizar as práticas essenciais de gerenciamento de incidentes:
Responsabilidades compartilhadas de plantão
Ao contrário dos modelos tradicionais, nos quais membros específicos da equipe são designados como especialistas de plantão, as equipes de DevOps geralmente adotam um cronograma de plantão rotativo. Essa abordagem garante que todos os membros da equipe sejam responsáveis por responder a incidentes, incluindo aqueles que podem ocorrer fora do horário normal de trabalho.
A familiaridade leva à resolução
No centro da filosofia DevOps está a crença de que os engenheiros que desenvolveram um serviço estão em melhor posição para resolver os problemas quando eles surgem. Esse princípio destaca a mentalidade “você constrói, você opera”, em que aqueles que estão mais familiarizados com a arquitetura e as complexidades do serviço lidam com interrupções e perturbações.
Rapidez e responsabilidade
As equipes de DevOps devem criar e implantar software rapidamente. Mas essa velocidade vem acompanhada de uma camada adicional de responsabilidade. Saber que terão que resolver incidentes motiva os engenheiros a produzir códigos confiáveis e de alta qualidade.
A análise da causa raiz (RCA) também é essencial no gerenciamento de incidentes DevOps. A RCA envolve identificar as razões subjacentes aos incidentes, permitindo que as equipes implementem soluções práticas e evitem a recorrência.
Trata-se de uma abordagem proativa que aborda problemas imediatos e fortalece o sistema como um todo, reduzindo a probabilidade de incidentes graves no futuro e aumentando a resiliência dos serviços.
Ao manter um fluxo contínuo e coeso nas práticas de gerenciamento de incidentes, as equipes de DevOps podem equilibrar flexibilidade e estrutura. Isso garante que elas estejam bem preparadas para lidar com incidentes de forma rápida e eficaz, levando a serviços de software mais confiáveis e robustos.
Funções na gestão de incidentes
Embora as organizações possam adaptar suas funções e responsabilidades com base em suas necessidades específicas, a seguir estão algumas das funções mais comuns em equipes de gerenciamento de incidentes de TI:
- Usuário final/solicitante: essa pessoa é normalmente aquela que está enfrentando uma interrupção no serviço e é responsável por iniciar o processo de gerenciamento de incidentes, enviando um ticket de incidente.
- Central de atendimento de nível 1: A central de atendimento de nível 1 é o ponto de contato inicial para os solicitantes. Os técnicos lidam com problemas e solicitações básicas. Sua experiência abrange problemas comuns, como redefinição de senhas e problemas de conectividade, como problemas de Wi-Fi.
- Central de atendimento de nível 2: os técnicos desse nível possuem habilidades e conhecimentos mais avançados do que os do nível 1. Eles lidam com questões mais complexas e escalam os incidentes do nível 1. Sua função envolve resolver problemas técnicos complexos e garantir a resolução eficaz dos incidentes.
- Central de atendimento de nível 3 e superior: este nível é composto por especialistas com profundo conhecimento em áreas específicas da infraestrutura de TI, como manutenção de hardware ou suporte a servidores.
- Gerente de incidentes: o gerente de incidentes supervisiona o processo de gerenciamento de incidentes, avaliando sua eficácia, sugerindo melhorias e garantindo o cumprimento dos procedimentos estabelecidos.
- Responsável pelo processo: O responsável pelo processo supervisiona e refina o processo de gerenciamento de incidentes. Ele analisa, ajusta e aprimora o processo para garantir que ele esteja alinhado com os objetivos organizacionais e ofereça suporte ideal aos esforços de gerenciamento de incidentes.
Essas funções contribuem coletivamente para um processo de identificação e gerenciamento de incidentes bem estruturado e eficiente, garantindo a resolução rápida e eficaz dos incidentes, ao mesmo tempo em que aprimora continuamente a abordagem.
Ferramentas e recursos para um gerenciamento eficaz de incidentes
Aproveitar as ferramentas e os recursos certos de gerenciamento de incidentes pode aumentar significativamente a eficiência e a eficácia do processo de gerenciamento de incidentes.
Os navegadores da web, especialmente o Google Chrome, são fundamentais no gerenciamento de incidentes. A versatilidade e compatibilidade do Chrome com vários softwares de gerenciamento de incidentes baseados na web o tornam uma ferramenta indispensável para equipes de TI. Sua extensa biblioteca de extensões, como ferramentas de desenvolvimento, rastreadores de bugs e monitores de desempenho, permite diagnósticos e solução de problemas em tempo real.
Além disso, recuperar artefatos como dados de cache, histórico, downloads etc. por meio da análise forense do navegador ajuda as equipes a identificar possíveis fontes de ataques de vírus e códigos maliciosos.
O Chrome também se integra perfeitamente ao ClickUp, um software de produtividade e gerenciamento de incidentes altamente conceituado, usado por equipes em pequenas e grandes empresas.
Aqui estão alguns dos benefícios significativos de usar o ClickUp para gerenciamento de incidentes:
1. Rastreamento centralizado de incidentes
O ClickUp consolida todas as informações relacionadas a incidentes em uma única plataforma. Essa abordagem centralizada garante que todos os relatórios, atualizações e resoluções de incidentes estejam acessíveis em um único lugar, reduzindo o risco de perda de informações e garantindo que os membros da equipe tenham os dados mais atualizados ao seu alcance.
2. Colaboração em tempo real
Os recursos de colaboração do ClickUp facilitam a comunicação entre os membros da equipe. Os usuários podem comentar diretamente nas tarefas, compartilhar arquivos e atualizar o status dos incidentes em tempo real com a visualização do ClickUp Chat. Esse recurso beneficia equipes que trabalham em diferentes locais ou fusos horários, garantindo que todos fiquem informados e alinhados.

3. Gerenciamento automatizado do fluxo de trabalho
O ClickUp Automations ajuda a criar fluxos de trabalho automatizados que acionam ações específicas com base em condições predefinidas. Por exemplo, quando um incidente é relatado, notificações automatizadas podem ser enviadas aos membros relevantes da equipe e as tarefas podem ser atribuídas com base no tipo de incidente. Isso reduz o esforço manual e acelera a resolução do incidente.
4. Relatórios e análises integrados
A plataforma oferece ferramentas robustas de relatórios e análises que ajudam a monitorar tendências de incidentes e métricas de desempenho. As equipes podem gerar relatórios detalhados sobre priorização de incidentes, tempos de resolução de incidentes, taxas de recorrência e outros indicadores-chave de desempenho. Essa abordagem baseada em dados ajuda a identificar padrões, avaliar a eficácia das estratégias de resposta e tomar decisões informadas para melhorar os processos de gerenciamento de incidentes.
5. Painéis personalizáveis
A plataforma permite que você crie painéis personalizados que exibem métricas e KPIs críticos de gerenciamento de incidentes. Os painéis do ClickUp fornecem uma visão geral visual dos incidentes em andamento, tarefas pendentes e desempenho da equipe, permitindo que os gerentes avaliem rapidamente o estado atual do gerenciamento de incidentes e resolvam quaisquer problemas.
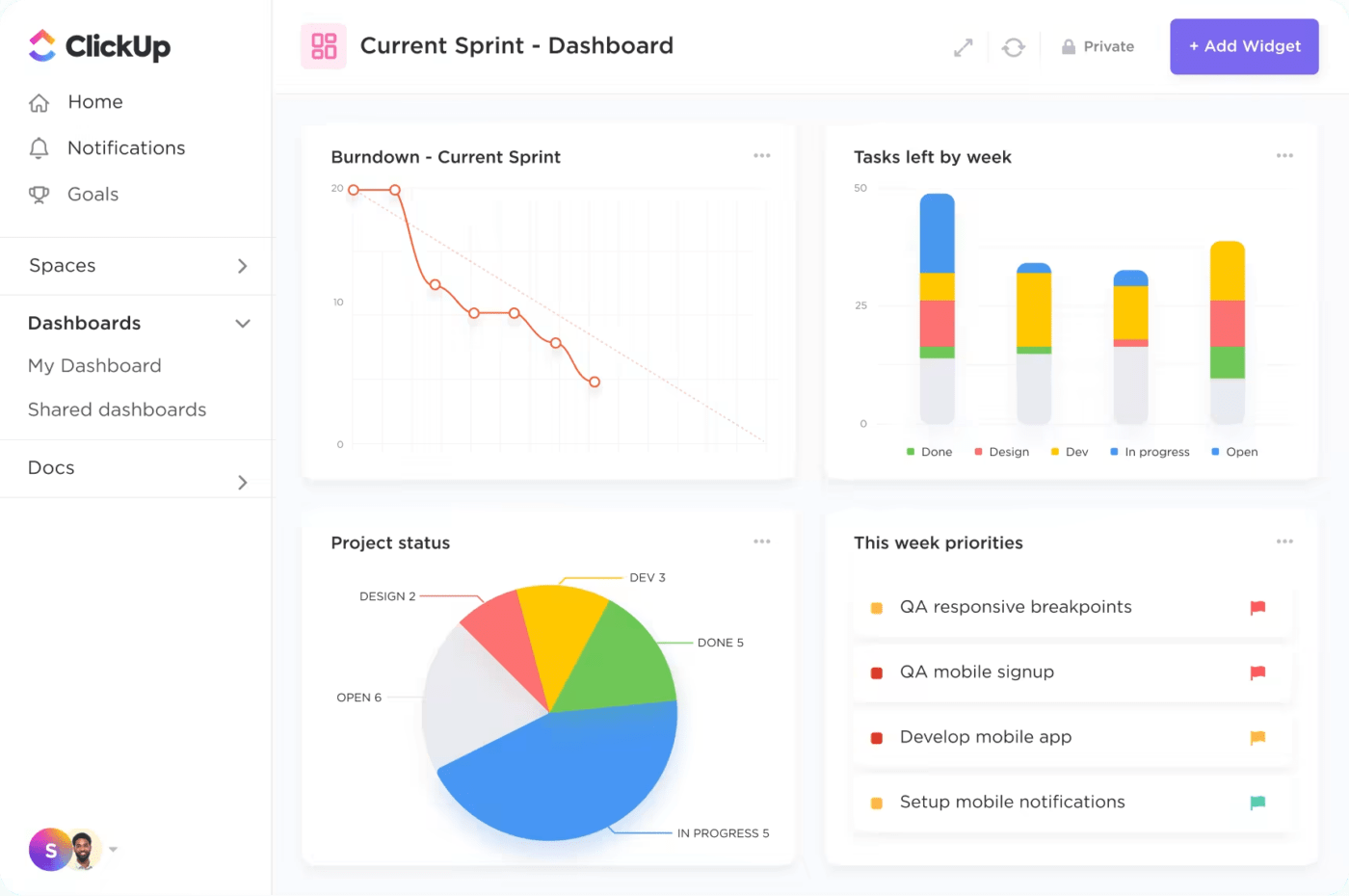
6. Modelos pré-criados
O ClickUp oferece uma variedade de modelos de TI personalizáveis , projetados para o gerenciamento de incidentes. Esses modelos também ajudam os usuários a documentar bugs.
Por exemplo, o Modelo de Relatório de Incidentes de TI do ClickUp permite que as equipes de TI documentem, rastreiem e resolvam incidentes de forma rápida e eficiente. Isso não apenas melhora a velocidade do serviço, mas também ajuda as empresas a identificar tendências de longo prazo que podem ser abordadas para melhorar sua infraestrutura geral de TI.
Este modelo facilita:
- Documente e relate os incidentes com precisão
- Acompanhe o progresso da resolução de problemas em tempo real
- Identifique padrões nas questões relatadas para resolver problemas de forma proativa.
Ele inclui componentes essenciais, como uma descrição detalhada, uma lista de verificação, subtarefas e campos personalizáveis. Essa flexibilidade garante que o modelo possa ser adaptado aos processos e procedimentos da sua organização, criando um relatório abrangente de incidentes de TI.
Você também pode usar o modelo de plano de ação para incidentes do ClickUp, que simplifica o desenvolvimento de planos de ação para incidentes (IAPs) abrangentes para empresas.
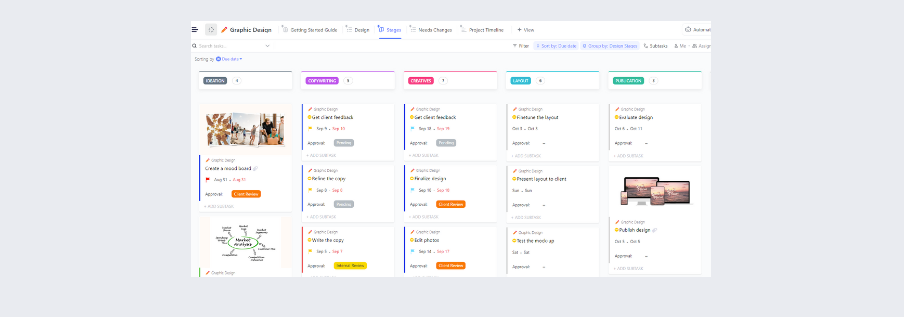
Este modelo inclui sistematicamente todas as informações cruciais, ajudando você a estabelecer registros confiáveis das atividades relacionadas a incidentes e a implementar estratégias de resposta eficazes.
O modelo apresenta seções codificadas por cores para uma documentação organizada:
- Resumo da situação: fornece uma visão geral concisa do incidente e do plano de ação geral.
- Plano de execução: detalha os objetivos e estratégias para gerenciar o incidente.
- Informações de contato da equipe de incidentes: lista os métodos de contato das pessoas envolvidas na resposta
- Lista de organização de incidentes: descreve as funções e responsabilidades das equipes de operações, planejamento, logística e finanças.
- Lista de atribuição de incidentes: atribui tarefas específicas a supervisores e membros da equipe.
- Mapa/resumo da situação: inclui representações gráficas do local ou região do incidente.
- Aprovação do plano de incidentes: captura detalhes como o nome da pessoa que enviou o plano, a data de envio e as assinaturas necessárias.
Ao utilizar este modelo, as empresas podem compilar de forma eficiente todos os detalhes necessários para a aprovação do IAP e implementar uma resposta a incidentes bem coordenada e completa.
Melhores práticas de gerenciamento de incidentes
O gerenciamento eficaz de incidentes depende das melhores práticas que garantem uma resolução rápida e eficaz.
Defina expectativas claras com SLAs
Os Acordos de Nível de Serviço (SLAs) desempenham um papel significativo ao definir expectativas claras sobre a rapidez com que as equipes devem lidar com incidentes com base na gravidade.
Os SLAs definem tempos específicos de resposta e resolução, o que ajuda a priorizar incidentes e orientar as equipes no gerenciamento eficiente de sua carga de trabalho. Essa abordagem estruturada ajuda você a concentrar os recursos onde eles são mais necessários, para que possa alinhar a resolução de incidentes com as prioridades de negócios e minimizar o tempo de inatividade.
Aplique patches regularmente para evitar incidentes
Outra prática essencial é a aplicação regular de patches, que ajuda a prevenir incidentes ao corrigir vulnerabilidades antes que elas possam ser exploradas. É um processo contínuo que corrige falhas de segurança em softwares e sistemas, tornando mais difícil para os invasores explorarem pontos fracos conhecidos.
Essa prática é parte fundamental de uma estrutura de gerenciamento de riscos de segurança cibernética, pois protege a infraestrutura de TI contra ameaças emergentes e reduz o risco de violações. Sem patches oportunos, as vulnerabilidades permanecem abertas e podem levar a problemas de segurança significativos.
Priorize o monitoramento dos data centers
O gerenciamento do data center também desempenha um papel vital no gerenciamento de incidentes. O gerenciamento adequado garante que tanto os aspectos físicos quanto os virtuais do data center sejam bem mantidos. Isso inclui supervisionar os controles ambientais, as fontes de alimentação e a segurança física.
Os sistemas de monitoramento em tempo real são essenciais nesse sentido, pois ajudam a detectar e resolver problemas antes que eles se agravem. O gerenciamento eficaz do data center, quando combinado com uma estrutura de gerenciamento de riscos de segurança cibernética bem implementada, permite a detecção precoce de problemas, ajudando a evitar grandes interrupções e a manter a estabilidade das operações de TI.
Benefícios e desafios do gerenciamento de incidentes
Os incidentes podem retardar o andamento do projeto e esgotar recursos valiosos, muitas vezes causando interrupções operacionais significativas e perda potencial de dados críticos. Isso destaca a importância vital de um gerenciamento eficaz de incidentes.
Os principais benefícios do gerenciamento de incidentes incluem:
1. Deflexão aprimorada de incidentes
A prevenção de incidentes envolve identificar e mitigar proativamente possíveis problemas antes que eles se transformem em problemas significativos. Sistemas eficazes de gerenciamento de incidentes permitem que as organizações implementem medidas preventivas e monitorem continuamente o desempenho do sistema, reduzindo assim a frequência e a gravidade dos incidentes.
2. Processo de mudança otimizado
Um processo de mudança bem gerenciado garante que os funcionários implementem atualizações e modificações de forma sistemática, seguindo os procedimentos estabelecidos. Aproveitar os procedimentos operacionais padrão (SOP) para o gerenciamento de mudanças ajuda a padronizar os procedimentos, garantindo consistência e reduzindo o risco de erros.
3. Resolução e encerramento eficazes de incidentes
Um processo de resolução claramente definido garante que as equipes tratem os incidentes prontamente e tomem todas as medidas necessárias para resolver o problema. Uma vez resolvidos, os incidentes são formalmente encerrados com documentação completa e ações de acompanhamento. Essa abordagem estruturada melhora a eficiência operacional e fornece um registro valioso para análise pós-incidente e melhoria contínua, ajudando a refinar as estratégias de gerenciamento de incidentes ao longo do tempo.
Desafios do gerenciamento de incidentes
Apesar dos benefícios, vários desafios costumam surgir no gerenciamento de incidentes.
1. Dificuldade em identificar as causas principais
Um desafio significativo é identificar a causa raiz de um incidente, principalmente ao lidar com questões complexas que envolvem vários componentes do sistema e interdependências.
O diagnóstico preciso da causa subjacente requer uma investigação minuciosa e, muitas vezes, envolve colaboração entre diferentes funções. Os procedimentos operacionais padrão (SOP) podem ajudar na criação de procedimentos padronizados para a análise da causa raiz, mas a implementação eficaz desses procedimentos requer ferramentas e metodologias avançadas.
A Stanley Security enfrentou um desafio semelhante ao gerenciar seus processos de resposta a incidentes. Como líder global em soluções de segurança, a Stanley Security lida com vários incidentes em diversos sistemas e regiões.
Anteriormente, as equipes de marketing da empresa dependiam de ferramentas como Excel e e-mail para comunicação interna e gerenciamento de tarefas. A demanda da pandemia da COVID-19 por ferramentas de gerenciamento de projetos mais integradas e escaláveis destacou a necessidade de quebrar silos e aumentar a produtividade.
O ClickUp forneceu um espaço de trabalho unificado para equipes globais, facilitando a comunicação e organizando documentos, bem como SOPs, em um banco de dados mundial. Esse alinhamento permitiu que as equipes colaborassem de forma mais eficaz e compartilhassem as melhores práticas. Como resultado, a Stanley Security alcançou um aumento de 80% na melhoria do trabalho em equipe, economizando mais de 8 horas semanais em reuniões e atualizações. Eles também observaram uma redução de 50% no tempo gasto na criação e compartilhamento de relatórios.
2. Recorrência de incidentes
Outro desafio é evitar que os incidentes se repitam. Isso requer um profundo entendimento das questões subjacentes e a implementação de medidas preventivas eficazes. Identificar padrões e tendências de incidentes passados é essencial para desenvolver estratégias para mitigar riscos futuros.
O ClickUp aborda esse desafio fornecendo ferramentas integradas de relatórios e análises que oferecem insights sobre métricas de incidentes e tendências de desempenho. Essa abordagem baseada em dados facilita a identificação de problemas recorrentes e ajuda a desenvolver estratégias de prevenção direcionadas.

A solução de TI e PMO da ClickUp pode ajudar nesse sentido:
- Crie status personalizados (por exemplo, “Encerrado”, “Em espera”, “Em andamento”) e campos (por exemplo, “Solicitante”, “Departamento”) para categorizar e gerenciar incidentes de maneira eficaz.
- Acompanhe e monitore incidentes em tempo real, garantindo atualizações rápidas e verificações de status.
- Anexe documentos relevantes, capturas de tela ou registros aos incidentes para análise. Crie uma base de conhecimento para uma solução comum de incidentes.
- Gere relatórios sobre a frequência dos incidentes, o tempo de resolução e as causas principais para identificar tendências e melhorar a resposta.
- Conecte o ClickUp a outras ferramentas de TI para ter uma visão holística dos incidentes.
Dominando o gerenciamento de incidentes para o sucesso ideal do projeto
Dominar o gerenciamento de incidentes não significa apenas reagir aos problemas, mas criar um ambiente resiliente e ágil, no qual as interrupções são gerenciadas rapidamente e as metas do projeto são alcançadas com o mínimo de impacto.
A adoção dessas estratégias ajudará sua equipe a evitar possíveis problemas e garantirá que seus projetos sejam executados com sucesso e sem contratempos.
Com o ClickUp, você ganha a vantagem de uma plataforma completa que integra o gerenciamento de incidentes com o gerenciamento de projetos e operações de TI. O rastreamento em tempo real, os fluxos de trabalho automatizados e as ferramentas colaborativas do ClickUp permitem que sua equipe resolva problemas rapidamente, mantendo seus projetos em dia. Seja gerenciando operações diárias ou lidando com requisitos complexos de projetos, o ClickUp oferece a visibilidade e o controle necessários para resultados excepcionais.
Pronto para melhorar sua gestão de incidentes e o sucesso dos projetos? Inscreva-se hoje mesmo no ClickUp e transforme sua gestão de incidentes!