![Hoe u Gemini kunt trainen op basis van uw eigen gegevens in [jaar]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Volgens een recent onderzoek onder ondernemingen geeft 73% van de organisaties aan dat hun AI-modellen de bedrijfsspecifieke terminologie en context niet begrijpen, wat leidt tot resultaten die uitgebreid handmatig moeten worden gecorrigeerd. Dit is een van de grootste uitdagingen bij de implementatie van AI.
Grote taalmodellen zoals Google Gemini zijn al getraind op basis van enorme openbare datasets. Wat de meeste bedrijven echt nodig hebben, is niet het trainen van een nieuw model, maar Gemini uw bedrijfscontext aanleren: uw documenten, werkstroom, klanten en interne kennis.
Deze handleiding leidt u door het volledige proces van het trainen van het Gemini-model van Google op basis van uw eigen gegevens. We behandelen alles, van het voorbereiden van datasets in het juiste JSONL-format tot het uitvoeren van afstemmingsopdrachten in Google AI Studio.
We zullen ook onderzoeken of een geconvergeerde werkruimte met ingebouwde AI-context u weken aan tijd voor de installatie kan besparen.
Wat is Gemini Fine-Tuning en waarom is het belangrijk?
Gemini-afstemming is het proces waarbij het basismodel van Google wordt getraind op basis van uw eigen gegevens.
U wilt een AI die uw business begrijpt, maar kant-en-klare modellen geven generieke antwoorden die niet aansluiten bij uw situatie. Dit betekent dat u tijd verspilt met het voortdurend corrigeren van outputs, het opnieuw uitleggen van de terminologie van uw business en dat u gefrustreerd raakt wanneer de AI het gewoon niet begrijpt.
Dit voortdurende heen en weer gepraat vertraagt uw team en ondermijnt de belofte van de productiviteit van AI.
Door Gemini te finetunen, creëert u een aangepast Gemini-model dat uw specifieke patronen, toon en domeinkennis leert, waardoor het nauwkeuriger kan reageren op uw unieke gebruikssituaties. Deze aanpak werkt het beste voor consistente, herhaalbare taken waarbij het basismodel herhaaldelijk faalt.
Het verschil tussen fine-tuning en prompt engineering
Prompt engineering houdt in dat u het model elke keer dat u ermee communiceert tijdelijke, sessiegebaseerde instructies geeft. Zodra het gesprek is beëindigd, vergeet het model uw context.
Deze aanpak stuit op een plafond wanneer uw use case gespecialiseerde kennis vereist die het basismodel simpelweg niet heeft. U kunt slechts een beperkt aantal instructies geven voordat het model uw patronen daadwerkelijk moet leren.
Fine-tuning daarentegen past het gedrag van het model permanent aan door de interne gewichten te wijzigen op basis van uw trainingsvoorbeelden, zodat de wijzigingen in alle toekomstige sessies blijven bestaan.
Afstemming is geen snelle oplossing voor incidentele AI-frustraties; het is een aanzienlijke investering in tijd en gegevens. Het is vooral zinvol in specifieke scenario's waarin het basismodel consequent tekortschiet en u een permanente oplossing nodig hebt.
Overweeg fine-tuning wanneer u wilt dat de AI het volgende onder de knie krijgt:
- Gespecialiseerde terminologie: uw branche gebruikt jargon dat het model consequent verkeerd interpreteert of niet correct gebruikt.
- Consistent uitvoerformat: u hebt elke keer reacties in een zeer specifieke structuur nodig, zoals het genereren van rapporten of codefragmenten.
- Domeinexpertise: het model mist kennis over uw nicheproducten, interne processen of eigen werkstroomen.
- Merkstem: u wilt dat alle door AI gegenereerde outputs perfect aansluiten bij de exacte merkstem, stijl en persoonlijkheid van uw bedrijf.
| Aspect | Prompt engineering | Fijnafstemming |
| Wat is het? | Betere instructies opstellen in de prompt om het gedrag van het model te sturen | Het model verder trainen op basis van uw eigen voorbeelden |
| Wat verandert er? | De input die u naar het model stuurt | De interne gewichten van het model |
| Snelle implementatie | Onmiddellijk — werkt direct | Traag — vereist voorbereiding van de dataset en trainingstijd |
| Technische complexiteit | Laag — geen ML-expertise vereist | Gemiddeld tot hoog — vereist ML-pijplijnen |
| Vereiste gegevens | Een paar goede voorbeelden in de prompt | Honderden tot duizenden gelabelde voorbeelden |
| Consistentie van de output | Gemiddeld — varieert per prompt | Hoog — gedrag is in het model ingebouwd |
| Het meest geschikt voor | Eenmalige taken, experimenten, snelle iteratie | Repetitieve taken die consistente resultaten vereisen |
Prompt engineering vormt wat u tegen het model zegt. Fine-tuning vormt hoe het model denkt.
Hoewel dit artikel zich richt op Gemini, kan inzicht in alternatieve benaderingen van AI-aanpassing een waardevol perspectief bieden op verschillende methoden om vergelijkbare doelen te bereiken.
Deze video laat zien hoe u een aangepaste GPT kunt maken, een andere populaire methode om AI aan te passen aan specifieke gebruikssituaties:
📖 Lees ook: Hoe word je een prompt engineer?
Hoe u uw trainingsgegevens voor Gemini kunt voorbereiden
De meeste fine-tuningprojecten mislukken nog voordat ze van start gaan, omdat teams het proces van gegevensvoorbereiding onderschatten. Gartner voorspelt dat 60% van de AI-projecten zal worden stopgezet vanwege ontoereikende AI-ready gegevens.
U kunt wekenlang bezig zijn met het verzamelen en formatten van gegevens, om vervolgens te zien dat de training mislukt of een onbruikbaar model oplevert. Dit is vaak het meest tijdrovende onderdeel van het hele proces, maar het goed doen is de belangrijkste factor voor succes.
Het principe 'garbage in, garbage out' is hier van groot belang. De kwaliteit van uw aangepaste model is een directe weerspiegeling van de kwaliteit van de gegevens waarmee u het traint.
Vereisten voor het format van de dataset
Gemini vereist dat uw trainingsgegevens in een specifiek format zijn, namelijk JSONL, wat staat voor JSON Lines. In een JSONL-bestand is elke regel een compleet, op zichzelf staand JSON-object dat één trainingsvoorbeeld vertegenwoordigt. Dankzij deze structuur kan het systeem grote datasets gemakkelijk regel voor regel verwerken.
Elk trainingsvoorbeeld moet twee belangrijke velden bevatten:
- text_input: Dit is de prompt of vraag die u aan het model zou stellen.
- output: Dit is het ideale, perfecte antwoord dat u het model wilt leren produceren.
Voor het gemak accepteert Google AI Studio ook uploads in CSV-format en converteert deze voor u naar de vereiste JSONL-structuur.
Dit kan de eerste invoer iets vergemakkelijken als uw team meer vertrouwd is met het werken in spreadsheets.
Aanbevelingen voor de grootte van de dataset
Hoewel kwaliteit belangrijker is dan kwantiteit, hebt u toch een minimumaantal voorbeelden nodig om het model patronen te laten herkennen en leren. Als u met te weinig voorbeelden begint, heeft u als resultaat een model dat niet kan generaliseren of betrouwbaar presteren.
Hier volgen enkele algemene richtlijnen voor de grootte van datasets:
- Minimaal haalbaar: voor eenvoudige, zeer specifieke taken kunt u resultaten zien met ongeveer 100 tot 500 hoogwaardige voorbeelden.
- Betere resultaten: voor complexere of genuanceerdere outputs kunt u het beste 500 tot 1000 voorbeelden gebruiken. Dit levert een robuuster en betrouwbaarder model op.
- Afnemend rendement: op een gegeven moment zal het simpelweg toevoegen van meer repetitieve gegevens de prestaties niet significant verbeteren. Richt u op diversiteit en kwaliteit in plaats van op pure kwantiteit.
Het verzamelen van honderden hoogwaardige voorbeelden is voor de meeste teams een grote uitdaging. Plan deze fase van gegevensverzameling goed voordat u begint met het afstemmen.
📮 ClickUp Insight: De gemiddelde professional besteedt meer dan 30 minuten per dag aan het zoeken naar werkgerelateerde informatie. Dat komt neer op meer dan 120 uur per jaar die verloren gaat aan het doorzoeken van e-mails, Slack-threads en verspreide bestanden.
Een intelligente AI-assistent die in uw werkruimte is ingebouwd, kan daar verandering in brengen. Maak kennis met ClickUp Brain. Het levert direct inzichten en antwoorden door binnen enkele seconden de juiste documenten, gesprekken en taakdetails naar boven te halen, zodat u kunt stoppen met zoeken en aan de slag kunt gaan.
💫 Echte resultaten: Teams zoals QubicaAMF hebben met ClickUp meer dan 5 uur per week teruggewonnen – dat is meer dan 250 uur per jaar per persoon – door verouderde kennisbeheerprocessen te elimineren. Stel je eens voor wat je team zou kunnen bereiken met een extra week productiviteit per kwartaal!
Best practices voor datakwaliteit
Inconsistente of tegenstrijdige voorbeelden zullen het model in verwarring brengen, wat leidt tot onbetrouwbare en onvoorspelbare resultaten. Om dit te voorkomen, moeten uw trainingsgegevens zorgvuldig worden samengesteld en opgeschoond. Eén slecht voorbeeld kan het leerproces van vele goede voorbeelden tenietdoen.
Volg deze richtlijnen om een hoge gegevenskwaliteit te garanderen:
- Consistentie: Alle voorbeelden moeten hetzelfde format, stijl en toon hebben. Als u wilt dat de AI formeel is, moeten al uw uitvoervoorbeelden formeel zijn.
- Diversiteit: uw dataset moet het volledige bereik aan inputs omvatten waarmee het model in de praktijk waarschijnlijk te maken zal krijgen. Train het niet alleen op de gemakkelijke gevallen.
- Nauwkeurigheid: elk afzonderlijk uitvoervoorbeeld moet perfect zijn. Het moet precies het antwoord zijn dat u van het model verwacht, zonder fouten of typefouten.
- Netheid: Voordat u begint met trainen, moet u dubbele voorbeelden verwijderen, alle spelling- en grammaticafouten corrigeren en eventuele tegenstrijdigheden in de gegevens oplossen.
Het wordt ten zeerste aanbevolen om de trainingsvoorbeelden door meerdere personen te laten beoordelen en valideren. Een frisse blik kan vaak fouten of inconsistenties opmerken die u misschien over het hoofd hebt gezien.
Hoe u Gemini stap voor stap kunt afstemmen
Het afstemmingsproces van Gemini omvat verschillende technische stappen op de platforms van Google. Eén fout kan uren kostbare trainingstijd en rekenkracht verspillen, waardoor u opnieuw moet beginnen. Deze praktische handleiding is bedoeld om dat vallen en opstaan te verminderen en begeleidt u van begin tot eind door het proces. 🛠️
Voordat u begint, heeft u een Google Cloud-account nodig met facturering ingeschakeld en toegang tot Google AI Studio. Reserveer minimaal een paar uur voor de eerste installatie en uw eerste trainingstaak, plus extra tijd voor het testen en herhalen van uw model.
Stap 1: Google AI Studio instellen
Google AI Studio is de webgebaseerde interface waarmee u het hele afstemmingsproces kunt beheren. Het biedt een gebruiksvriendelijke manier om gegevens te uploaden, trainingen te configureren en uw aangepaste model te testen zonder code te schrijven.
Ga eerst naar ai.google.dev en log in met uw Google-account.
U moet akkoord gaan met de Servicevoorwaarden en een nieuw project aanmaken in de Google Cloud Console als u dat nog niet hebt gedaan. Zorg ervoor dat u de benodigde API's inschakelt zoals gevraagd door het platform.
Stap 2: Upload uw trainingsdataset
Zodra u klaar bent met de instelling, gaat u naar het gedeelte over afstemming in Google AI Studio. Hier begint u met het maken van uw aangepaste model.
Selecteer de optie 'Afgestemd model maken' en kies uw basismodel. Gemini 1. 5 Flash is een veelgebruikte en kosteneffectieve keuze voor fijnafstemming.
Upload vervolgens het JSONL- of CSV-bestand met uw voorbereide trainingsdataset. Het platform valideert uw bestand om te controleren of het voldoet aan de formatvereisten en markeert veelvoorkomende fouten, zoals ontbrekende velden of een onjuiste structuur.
Stap 3: Configureer uw afstemmingsinstellingen
Nadat uw gegevens zijn geüpload en gevalideerd, configureert u de trainingsparameters. Deze instellingen, ook wel hyperparameters genoemd, bepalen hoe het model leert van uw gegevens.
De belangrijkste opties die u te zien krijgt, zijn:
- Epochs: Dit bepaalt hoe vaak het model op uw volledige dataset wordt getraind. Meer epochs kunnen leiden tot beter leren, maar brengen ook het risico van overfitting met zich mee.
- Leersnelheid: hiermee bepaalt u hoe agressief het model zijn gewichten aanpast op basis van uw voorbeelden.
- Batchgrootte: hiermee stelt u in hoeveel trainingsvoorbeelden samen in één groep worden verwerkt.
Voor uw eerste poging kunt u het beste beginnen met de standaardinstellingen die worden aanbevolen door Google AI Studio. Het platform vereenvoudigt deze complexe beslissingen, waardoor het toegankelijk is, zelfs als u geen expert bent op het gebied van machine learning.
Stap 4: Voer de afstemmingsopdracht uit
Nu uw instellingen zijn geconfigureerd, kunt u beginnen met het afstemmen. De servers van Google beginnen uw gegevens te verwerken en de parameters van het model aan te passen. Dit trainingsproces kan enkele minuten tot enkele uren duren, afhankelijk van de grootte van uw dataset en het model dat u hebt geselecteerd.
U kunt de voortgang van de taak rechtstreeks volgen in het dashboard van Google AI Studio. Aangezien de taak op de servers van Google wordt uitgevoerd, kunt u uw browser veilig sluiten en later terugkomen om de status te controleren. Als een taak mislukt, is dat bijna altijd te wijten aan een probleem met de kwaliteit of format van uw trainingsgegevens.
Stap 5: Test uw aangepaste model
Zodra de training is voltooid, is uw aangepaste model klaar om te worden getest. ✨
U kunt deze gids openen via de playground-interface in Google AI Studio.
Begin met het versturen van testprompts die vergelijkbaar zijn met uw trainingsvoorbeelden om de nauwkeurigheid ervan te controleren. Test het vervolgens op randgevallen en nieuwe variaties die het nog niet eerder heeft gezien om het vermogen tot generaliseren te evalueren.
- Nauwkeurigheid: Levert het de exacte resultaten op waarvoor u het hebt getraind?
- Generalisatie: Kan het nieuwe invoergegevens die vergelijkbaar maar niet identiek zijn aan uw trainingsgegevens correct verwerken?
- Consistentie: zijn de reacties betrouwbaar en voorspelbaar bij meerdere pogingen met dezelfde prompt?
Als het resultaat niet bevredigend is, moet u waarschijnlijk teruggaan, uw trainingsgegevens verbeteren door meer voorbeelden toe te voegen of inconsistenties te corrigeren, en vervolgens het model opnieuw trainen.
Best practices voor het trainen van Gemini op aangepaste gegevens
Het simpelweg volgen van de technische stappen garandeert nog geen geweldig model. Veel teams voltooien het proces, maar zijn vervolgens teleurgesteld over de resultaten omdat ze de optimalisatiestrategieën missen die ervaren professionals gebruiken. Dit is wat een functioneel model onderscheidt van een hoogpresterend model.
Het is niet verwonderlijk dat uit het rapport State of Generative AI in the Enterprise van Deloitte blijkt dat tweederde van de bedrijven aangeeft dat 30% of minder van hun gen-AI-experimenten binnen zes maanden volledig zal worden opgeschaald.
Door deze best practices toe te passen, bespaart u tijd en behaalt u een veel beter resultaat.
- Begin klein en schaal vervolgens op: voordat u een volledige trainingsrun uitvoert, test u uw aanpak met een kleine subset van uw gegevens (bijvoorbeeld 100 voorbeelden). Zo kunt u uw format valideren en snel een idee krijgen van de prestaties zonder uren te verspillen.
- Versiebeheer van uw datasets: wanneer u trainingsvoorbeelden toevoegt, verwijdert of doorvoert bewerkingen, slaat u elke versie van uw dataset op. Zo kunt u wijzigingen bijhouden, resultaten reproduceren en terugkeren naar een vorige versie als een nieuwe versie slechter presteert.
- Test voor en na: Voordat u begint met afstemmen, stelt u een baseline vast door de prestaties van het basismodel op uw belangrijkste taken te evalueren. Zo kunt u objectief meten hoeveel verbetering uw afstemmingsinspanningen hebben opgeleverd.
- Herhaal bij fouten: Raak niet gefrustreerd als uw aangepaste model een verkeerd of slecht geformatteerd antwoord geeft. Voeg dat specifieke foutgeval toe als een nieuw, gecorrigeerd voorbeeld in uw trainingsgegevens voor de volgende iteratie.
- Documenteer uw proces: houd een logboek bij van elke trainingsrun, met aantekeningen over de gebruikte datasetversie, de hyperparameters en de resultaten. Deze documentatie is van onschatbare waarde om te begrijpen wat wel en niet werkt in de loop van de tijd.
Het beheren van deze iteraties, datasetversies en documentatie vereist robuust projectmanagement. Door dit werk te centraliseren in een platform dat is ontworpen voor gestructureerde werkstroom, kunt u voorkomen dat het proces chaotisch wordt.
Veelvoorkomende uitdagingen bij het trainen van Gemini
Teams investeren vaak veel tijd en middelen in het afstemmen van het model, maar lopen dan tegen voorspelbare obstakels aan die leiden tot verspilde moeite en frustratie. Als u deze veelvoorkomende valkuilen van tevoren kent, kunt u het proces soepeler doorlopen.
Hieronder vindt u enkele van de meest voorkomende uitdagingen en hoe u deze kunt aanpakken:
- Overfitting: Dit gebeurt wanneer het model uw trainingsvoorbeelden perfect onthoudt, maar niet in staat is om te generaliseren naar nieuwe, onbekende inputs. Om dit te verhelpen, kunt u meer diversiteit toevoegen aan uw trainingsgegevens, overwegen om het aantal epochs te verminderen of alternatieve methoden verkennen, zoals retrieval-augmented generation.
- Inconsistente resultaten: Als het model verschillende antwoorden geeft op zeer vergelijkbare vragen, komt dat waarschijnlijk doordat uw trainingsgegevens tegenstrijdige of inconsistente voorbeelden bevatten. Om deze conflicten op te lossen, is een grondige gegevensopschoning nodig.
- Formaatverschuiving: Soms volgt een model in het begin de door u gewenste outputstructuur, maar wijkt het na verloop van tijd daarvan af. De oplossing is om expliciete formaatinstructies op te nemen in de output van uw trainingsvoorbeelden, niet alleen in de content.
- Trage iteratiecyclusen: wanneer elke trainingsrun uren duurt, vertraagt dit uw vermogen om te experimenteren en verbeteringen aan te brengen aanzienlijk. Test uw ideeën eerst op kleinere datasets om sneller feedback te krijgen voordat u een volledige trainingsopdracht start.
- Knelpunt bij het verzamelen van gegevens: Vaak is het moeilijkste deel het verzamelen van voldoende hoogwaardige voorbeelden. Begin met het benutten van uw beste bestaande content, zoals supporttickets, marketingteksten of technische documenten, en breid van daaruit verder uit.
Deze uitdagingen zijn een belangrijke reden waarom veel teams uiteindelijk op zoek gaan naar alternatieven voor het handmatige afstemmingsproces.
📮ClickUp Insight: 88% van de respondenten in onze enquête gebruikt AI voor persoonlijke taken, maar meer dan 50% schuwt het gebruik ervan op het werk. De drie belangrijkste belemmeringen? Gebrek aan naadloze integratie, kennislacunes of bezorgdheid over de veiligheid. Maar wat als AI in uw werkruimte is ingebouwd en al veilig is? ClickUp Brain, de ingebouwde AI-assistent van ClickUp, maakt dit mogelijk. Het begrijpt prompts in gewone taal en lost alle drie de bezorgdheden over AI-acceptatie op, terwijl het uw chat, taken, documenten en kennis in de hele werkruimte met elkaar verbindt. Vind antwoorden en inzichten met één enkele klik!
Waarom ClickUp een slimmer alternatief is
Het afstemmen van Gemini is krachtig, maar het is ook een tijdelijke oplossing.
In dit artikel hebben we gezien dat fine-tuning uiteindelijk om één ding draait: AI leren om uw bedrijfscontext te begrijpen. Het probleem is dat fine-tuning dit indirect doet. U bereidt datasets voor, ontwikkelt voorbeelden, traint modellen opnieuw en onderhoudt pijplijnen, allemaal zodat de AI kan benaderen hoe uw team werkt.
Dat is logisch voor gespecialiseerde gebruikssituaties. Maar voor de meeste teams is het echte doel niet Gemini-personalisatie omwille van Gemini zelf. Het doel is eenvoudiger:
U wilt AI die uw werk begrijpt.
Dit is waar ClickUp een fundamenteel andere – en slimmere – aanpak hanteert.
De Converged AI-werkruimte van ClickUp biedt uw team een AI die uw werkcontext onmiddellijk begrijpt, zonder dat u daar veel moeite voor hoeft te doen. In plaats van AI te trainen om uw context later te leren, werkt u met ClickUp Brain, de geïntegreerde AI-assistent, waar uw context al aanwezig is.
Uw taken, documenten, opmerkingen, projectgeschiedenis en beslissingen zijn native met elkaar verbonden. U hoeft de AI niet te trainen op basis van uw gegevens, omdat deze al aanwezig is op de plek waar u werkt en gebruikmaakt van uw bestaande ecosysteem voor kennisbeheer.
| Aspect | Gemini-afstemming | ClickUp Brain |
|---|---|---|
| Installatietijd | Dagen tot weken aan gegevensvoorbereiding | Onmiddellijk – werkt met bestaande werkruimtegegevens |
| Contextbron | Handmatig samengestelde trainingsvoorbeelden | Automatische toegang tot al het verbonden werk |
| Onderhoud | Herhaal de training wanneer uw behoeften veranderen. | Wordt continu bijgewerkt naarmate uw werkruimte evolueert |
| Vereiste technische vaardigheden | Matig tot hoog | Geen |
Omdat ClickUp uw werksysteem is, werkt ClickUp Brain binnen uw verbonden gegevensgrafiek. Er is geen AI-wildgroei over niet-verbonden tools, geen kwetsbare trainingspijplijnen en geen risico dat het model niet meer synchroon loopt met hoe uw team daadwerkelijk werkt.
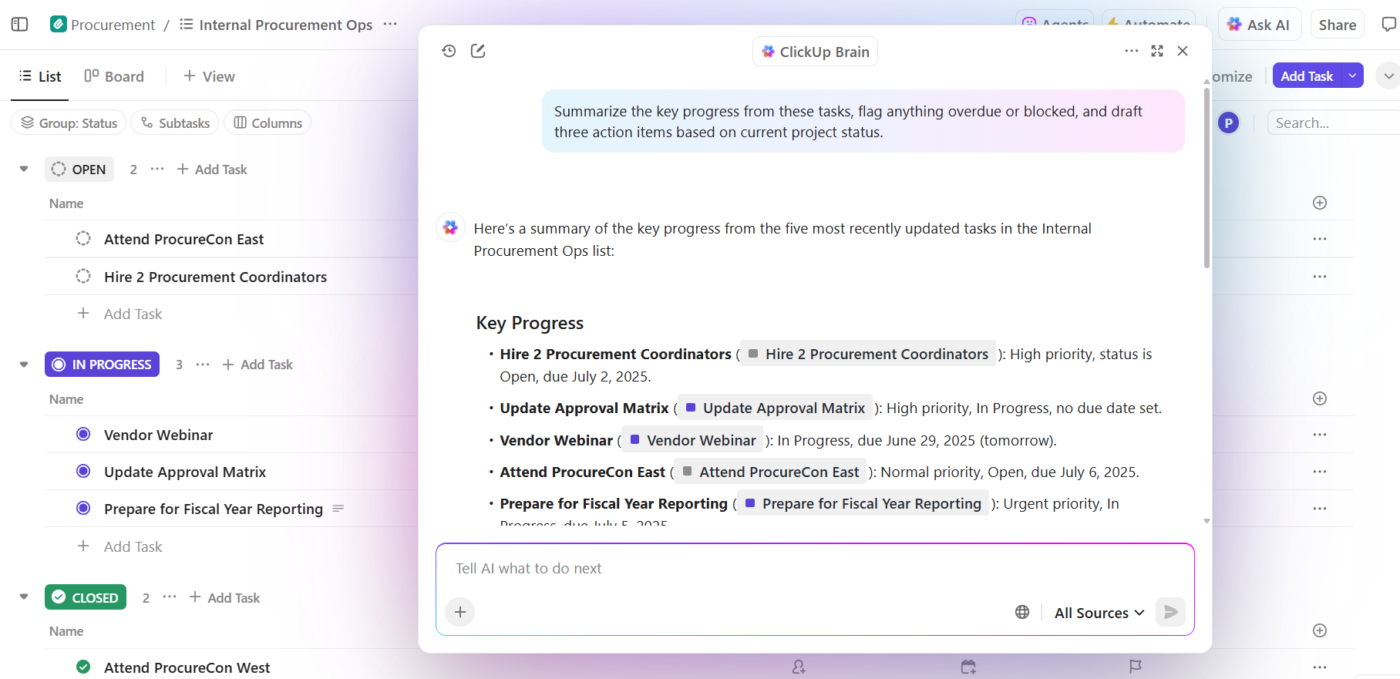
Zo ziet dat er in de praktijk uit:
- Stel vragen over uw projecten: ClickUp Brain doorzoekt de werkruimte op taken, documenten, opmerkingen en updates om vragen te beantwoorden aan de hand van uw echte projectgegevens, niet op basis van algemene trainingskennis.
- Genereer content met context: ClickUp Brain heeft al veilige toegang tot uw taken, bestanden, opmerkingen en projectgeschiedenis. Het kan documenten, samenvattingen en statusupdates maken die verwijzen naar uw daadwerkelijke werk, tijdlijnen en prioriteiten. Geen contextversnippering meer, waarbij teams uren verspillen met het zoeken naar informatie in verschillende apps en bestanden.
- Automatiseren met inzicht: met ClickUp Automations kunt u automatisering bouwen die intelligent reageert op de context van een project, zoals deadlines, eigendom en statuswijzigingen, en niet alleen op statische regels. AI kan deze zelfs voor u bouwen, zonder dat u daarvoor code nodig hebt.
💡Pro-tip: benut de ware kracht van AI in uw werkruimte met ClickUp Super Agents.
Super Agents zijn de AI-aangedreven teamgenoten van ClickUp, geconfigureerd als AI-gebruikers die samen met uw team in de werkruimte werken. Ze zijn omgevings- en contextgevoelig en kunnen worden toegewezen aan taken, vermeld in opmerkingen, geactiveerd door gebeurtenissen of schema's, of aangestuurd via chat, net als een menselijke teamgenoot.
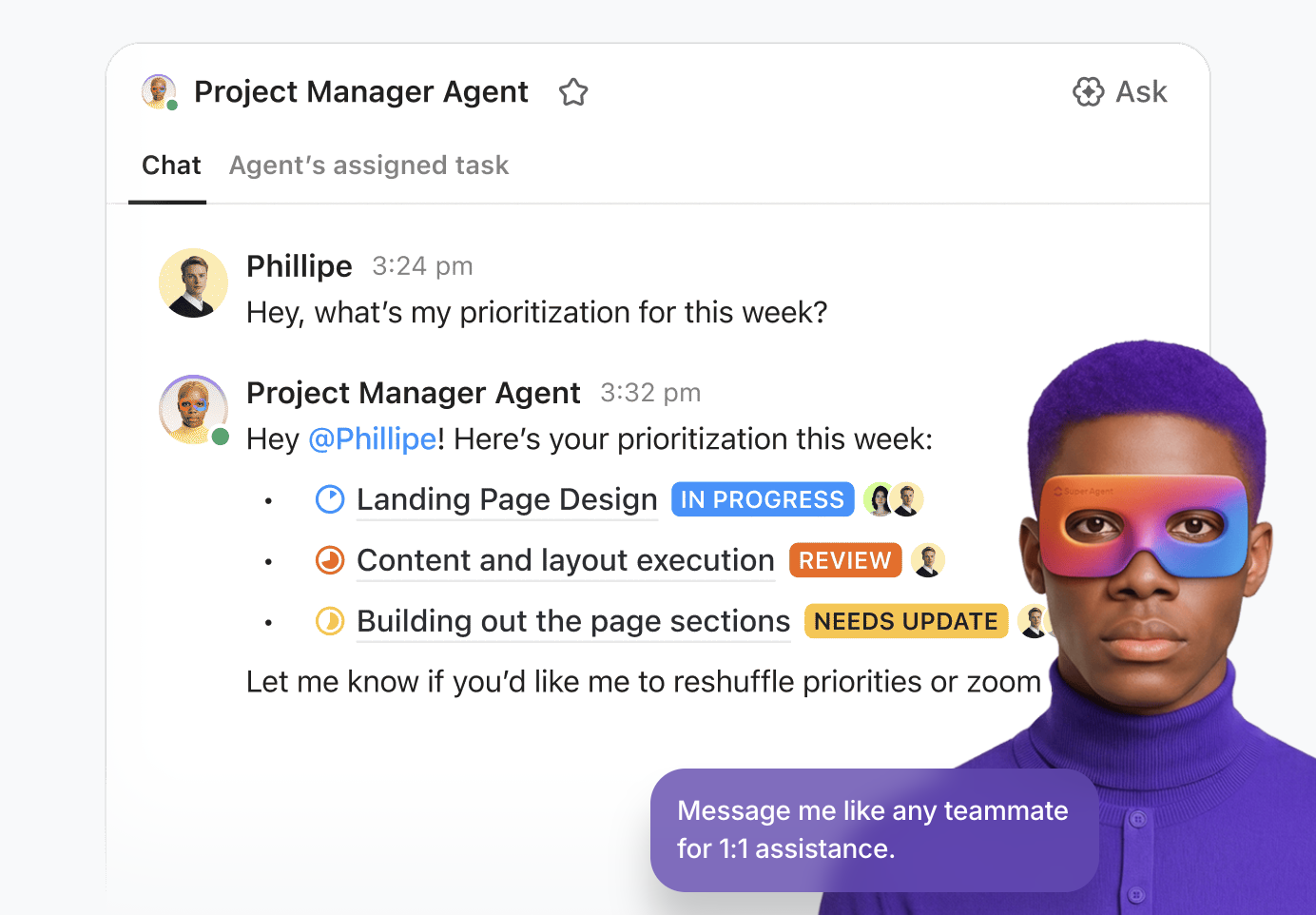
U kunt ze bouwen en implementeren met behulp van de visuele builder zonder code, waarmee u:
- Identificeer de startgebeurtenis, zoals een bericht of een verandering in de status van de Taak.
- Schets operationele regels, waaronder hoe u gegevens samenvat, werk delegeert of prioriteiten aanpast.
- Voer externe acties uit via geïntegreerde tools en extensies
- Lever ondersteunende gegevens door de agent te verbinden met relevante kennisbanken.
Bekijk de onderstaande video voor meer informatie over Super Agents.
Verfijn uw AI-strategie: schaf ClickUp aan
Fine-tuning leert een AI uw patronen aan de hand van statische voorbeelden, maar door geconvergeerde software te gebruiken in een werkruimte zoals ClickUp wordt contextversnippering voorkomen doordat uw AI live, automatische context krijgt.
Dit is de kern van een succesvolle AI-transformatie: teams die hun werk centraliseren in een verbonden platform besteden minder tijd aan het trainen van AI en meer tijd aan het benutten ervan. Naarmate uw werkruimte evolueert, evolueert uw AI automatisch – zonder dat er nieuwe trainingscycli nodig zijn.
Klaar om de training over te slaan en aan de slag te gaan met AI die uw werk al kent? Ga gratis aan de slag met ClickUp en ervaar de voordelen van een geconvergeerde werkruimte.
Veelgestelde vragen (FAQ)
Uw afgestemde model leert van uw trainingsvoorbeelden, maar het basis Gemini-model van Google bewaart uw gesprekken niet en leert standaard niet van uw gesprekken. Uw aangepaste model staat los van het basismodel dat andere gebruikers bedient.
Hoewel het trainen zelf slechts enkele uren in beslag neemt, kost het voorbereiden van hoogwaardige trainingsgegevens veel meer tijd. Deze fase van gegevensvoorbereiding kan vaak dagen of zelfs weken in beslag nemen om goed voltooid te worden.
Ja, u kunt een model afstemmen zonder code te schrijven door Google AI Studio te gebruiken. Deze tool biedt een visuele interface die de meeste technische complexiteit afhandelt, hoewel u nog steeds de vereisten voor gegevensformat moet begrijpen.
Aangepaste instructies zijn tijdelijke, sessiegebaseerde prompts die het gedrag van het model voor een enkel gesprek sturen. Bij afstemming worden de interne parameters van het model echter permanent aangepast op basis van uw trainingsvoorbeelden, waardoor blijvende veranderingen in het gedrag worden aangebracht.