

U bent een afdelingshoofd op zoek naar de perfecte persoon voor een bepaalde Taak. Met enorme bedrijfsgegevens is het bijna onmogelijk om de beste persoon te vinden, vooral als uw Taak tijdgevoelig is.
Bovendien, wie heeft de bandbreedte om iedereen te vragen of ze genoeg kennis hebben over een bepaald gebied?
Maar wat als je gewoon aan een systeem zou kunnen vragen, 'Wie heeft de meeste Taken gekregen?' en direct een nauwkeurig antwoord zou krijgen op basis van echte gegevens? Dat is wat Information Retrieval Systemen doen.
Deze systemen zeven door bergen gegevens om precies te vinden wat u nodig hebt.
Vergroot dat idee nu eens naar een wereldwijde database - een IR-systeem organiseert enorme hoeveelheden gegevens en helpt u binnen enkele seconden de meest relevante antwoorden te vinden. In deze gids wordt ingegaan op verschillende modellen voor het ophalen van informatie, hoe ze werken en de rol van AI-technologieën in een IR-systeem.
60-seconden samenvatting
📌 Information Retrieval (IR)-systemen helpen bij het vinden van relevante informatie uit grote gegevensverzamelingen, waarbij ze functioneren als een virtuele assistent die gegevens doorzoekt om te vinden wat u nodig hebt
iR-systemen hebben sleutelcomponenten: database, index, zoekinterface, query-processor, opvraagmodellen en rangschikkings-/scoringsmechanismen
er worden vier belangrijke IR-modellen gebruikt: Booleaans (gebruikt AND/OR/NOT operatoren), Vector Space (stelt documenten voor als vectoren), Probabilistic (gebruikt statistische benaderingen) en Term Interdependence (analyseert relaties tussen termen)
machine Learning en Natural Language Processing verbeteren IR-systemen door patroonherkenning, het rangschikken van resultaten en het begrijpen van context te verbeteren
📌 Belangrijke uitdagingen zijn privacy van gegevens, schaalbaarheid en behoud van gegevenskwaliteit bij het verwerken van grote datasets
Wat is Information Retrieval (IR)?
Information Retrieval (IR) betekent eenvoudigweg het vinden van de juiste informatie uit grote gegevensverzamelingen, zoals digitale bibliotheken, databanken of internetarchieven.
Het is alsof je een virtuele assistent hebt die door bergen gegevens heengaat om je precies te brengen wat je nodig hebt.
Aan de oppervlakte voert de gebruiker een query in, vaak met behulp van sleutelwoorden of zinnen, om naar specifieke informatie te zoeken. Achter de schermen analyseren geavanceerde technieken en algoritmen de reeksen zoekopdrachten en koppelen ze aan relevante gegevens.**
In plaats van slechts één antwoord te geven, bieden IR systemen meerdere objecten, elk met een verschillende mate van relevantie voor uw query. Bovendien worden ze overal gebruikt en hebben ze meerdere toepassingen (binnenkort meer daarover 🔔).
💡Pro Tip: Wilt u de meest bekwame persoon voor een Taak vinden? Voer specifieke termen zoals 'analyse verkooprapporten Q1 en Q2 toegewezen taken' in het informatiezoeksysteem in. Zo worden irrelevante gegevens snel uitgefilterd en wordt duidelijk wie de meeste taken heeft uitgevoerd. Pro Tip:
Toepassingen van IR in verschillende velden
Van gezondheidszorg tot e-commerce, IR-systemen worden in tal van velden gebruikt om gegevens te beheren en te categoriseren. Hier zijn een paar voorbeelden 👇
Gezondheidszorg
In de gezondheidszorg scannen IR systemen databases met medische dossiers en onderzoekspapers om artsen en onderzoekers te helpen de meest relevante informatie te vinden. Als resultaat versnellen ze de diagnose van ziekten, identificeren ze behandelingsopties en vinden ze de meest relevante onderzoeken met relevante feedback.
Klantenservice
Technieken voor het ophalen van informatie maken klantenservice sneller en nauwkeuriger. Agenten kunnen bijvoorbeeld vragen van gebruikers zoals 'restitutiebeleid' in het systeem van een bedrijf typen om direct antwoorden op te halen.
AI-chatbots en helpdesks die gebruikmaken van information retrieval gaan een stap verder en bieden realtime oplossingen zonder menselijke tussenkomst**. Daarom worden je vragen vaak binnen enkele seconden beantwoord!
E-commerce platforms
IR-systemen maken online winkelen een fluitje van een cent. Ze analyseren databases en passen klantgedrag aan om producten aan te bevelen waar u dol op zult zijn.
Instance, Amazon gebruikt IR om items voor te stellen op basis van uw zoekgeschiedenis en eerdere aankopen, zodat u precies vindt wat u nodig hebt.
Onderdelen van een Information Retrieval Systeem
Nu weten we wat information retrieval is en hoe het werkt. Laten we de sleutelblokken van een IR systeem eens uit elkaar halen. →
1. Database
Alles begint met de database. Het is een verzameling van met elkaar verbonden gegevenspunten, zoals tekstdocumenten, e-mails, webpagina's, afbeeldingen en video's. Wanneer u een gegeven query invoert, doorzoekt het IR systeem deze database matches om de meest relevante informatie voor uw behoeften op te halen.
2. Indexeerder
Voordat het systeem iets kan ophalen, organiseert de indexeerder de gegevens. Het is als het voorbereiden van een bibliotheekcatalogus om sneller te kunnen zoeken. De indexer verwerkt documenten door:
- Tokenization: Het opdelen van content in kleinere stukjes, zoals het opsplitsen van zinnen in woorden of zinsdelen (tokens genoemd)
- Stemming: Woorden vereenvoudigen tot hun basisvorm (bijv. 'running' wordt 'run')
- Verwijderen van stopwoorden: Overslaan van stopwoorden zoals 'en', 'of' en 'de' om te focussen op de primaire query
- Extractie van trefwoorden: De belangrijkste trefwoorden in de tekst identificeren
- Metadata-extractie: Extra details ophalen, zoals de auteur, publicatiedatum of titel
3. Zoekinterface
De zoekinterface is uw toegangspoort tot het IR systeem. Hier typt u uw query in met eenvoudige trefwoorden of meer gedetailleerde filters. De interface is gebruiksvriendelijk ontworpen en zorgt ervoor dat u gemakkelijk uw informatiebehoeften kenbaar kunt maken en de relevante resultaten krijgt die u zoekt.
4. Query verwerker
Zodra u op 'zoeken' drukt, neemt de query-processor het over. Deze verfijnt uw invoer door technieken toe te passen die in de indexer sectie staan. Bovendien verwerkt het ook booleaanse operatoren zoals 'AND', 'OR' en 'NOT'** om je query slimmer te maken.
5. Opvraagmodellen
Hier gebeurt de magie. Het systeem vergelijkt je opgegeven query met de geïndexeerde documenten met behulp van opvraagmodellen. Deze methoden bepalen hoe jouw query wordt vergeleken met de opgeslagen gegevens. Enkele veel voorkomende namen zijn:
- Booleaanse modellen
- Vector ruimte modellen
- Probabilistische modellen
- En meer... (later besproken)
6. Rangschikken en scoren
Zodra potentiële overeenkomsten zijn gevonden, rangschikt het systeem ze op basis van relevantie. Elk document krijgt een scoree met behulp van methoden zoals TF-IDF (Term Frequency-Inverse Document Frequency) of andere algoritmen. Dit zorgt ervoor dat het meest relevante resultaat bovenaan verschijnt.
7. Presentatie of weergave
Tot slot worden de resultaten aan u gepresenteerd. Meestal toont het systeem een gerangschikte lijst van tekstdocumenten met extra functies zoals knipsels, filters of sorteeropties. Dit maakt het gemakkelijker om het meest relevante document te kiezen. Het aantal weergegeven resultaten kan echter variëren op basis van uw voorkeuren, query of systeeminstellingen.
🔍Did you know?: Traditionele systemen voor het ophalen van informatie sterk leunden op gestructureerde databases en basis trefwoordmatching. Het resultaat? Grote problemen met relevantie en personalisatie.
Toen hebben moderne AI-technologieën het zoeken naar tekst** veranderd:
- Machine Learning (ML): Helpt IR-systemen te leren van patronen in het gedrag van gebruikers en de resultaten van zoekopdrachten te verbeteren
- Diepe neurale netwerken: Algoritmen die ongestructureerde gegevens (zoals afbeeldingen of video's) kunnen verwerken en complexe relaties kunnen blootleggen
- Natuurlijke taalverwerking (NLP): Stelt systemen in staat om de betekenis en context van query's te begrijpen om beeldherkenning en sentimentanalyse te ondersteunen, waardoor informatie toegankelijker wordt
Modellen voor het ophalen van informatie
Er zijn verschillende IR systemen die het proces van het vinden van relevante documenten stroomlijnen. Laten we eens kijken naar de meest gebruikte:
1. Set Theorie en Booleaanse modellen
Het booleaans model is een van de eenvoudigste technieken om informatie op te zoeken. Het werkt als volgt:
- AND: Vraagt documenten op die alle termen in de query bevatten. Een voorbeeld: een zoekopdracht naar 'kat EN hond' levert documenten op die beide termen vermelden op een zoekmachine
- OR: Vindt documenten die een van de termen in de query bevatten. Voor 'kat OF hond' worden documenten gevonden met vermelding van kat, hond of beide
- NOT: Sluit documenten uit die een specifieke term bevatten. Bijvoorbeeld, 'cat AND NOT dog' geeft documenten die kat vermelden maar geen hond
Dit model gebruikt een 'bag of words' concept, waarbij een 2D matrix wordt gecreëerd. In deze matrix:
- Kolommen vertegenwoordigen documenten
- Rijen vertegenwoordigen termen uit de query
Elke cel krijgt een waarde van 1 (als de term aanwezig is) of 0 (als dat niet zo is).

via AIML.nl voordelen**
- Eenvoudig te begrijpen en te implementeren
- Haalt documenten op die precies overeenkomen met de query-termen
❌ Cons
- Booleaanse modellen rangschikken documenten niet op relevantie, dus alle resultaten worden als even belangrijk behandeld
- Richt zich op exacte overeenkomsten tussen termen, dus de resultaten kunnen variëren binnen de betekenis of context van de query
2. Vectorruimtemodellen
Een Vector Space-model is een algebraïsch model dat zowel documenten als query's voorstelt als vectoren in een multidimensionale ruimte. Zo werkt het:
1. Er wordt een term-document matrix gemaakt, waarin rijen termen en kolommen documenten zijn
2. Er wordt een queryvector** gevormd op basis van de zoektermen van de gebruiker
3. Het systeem berekent een numerieke score met behulp van een maat genaamd cosinusovereenkomst, die bepaalt hoe sterk de queryvector overeenkomt met documentvectoren

via Centraal gegevenswetenschap Als een informatiezoeksysteem worden de documenten vervolgens gerangschikt op basis van deze scores, waarbij de hoogst gerangschikte het meest relevant zijn.
voordelen**
- Vindt items terug, zelfs als slechts enkele termen overeenkomen
- Variaties in termgebruik en documentlengte, geschikt voor verschillende documenttypes
Nadelen
- Grotere woordenlijsten en documentverzamelingen maken similariteitsberekeningen arbeidsintensief
3. Probabilistische modellen
Dit model gebruikt een statistische benadering, waarbij waarschijnlijkheid wordt gebruikt om in te schatten hoe relevant een document is voor de query. Het houdt rekening met:
- Frequentie van termen in het document
- Hoe vaak termen samen voorkomen (co-occurrence)
- De lengte van het document en het totale aantal termen in de query
Het systeem behandelt het opvraagproces als een probabilistische gebeurtenis en rangschikt opgeslagen documenten op basis van hun waarschijnlijkheid van relevantie. Deze benadering voegt diepgang toe door gegevensobjecten te evalueren die verder gaan dan alleen de aanwezigheid van termen.
voordelen**
- Past zich goed aan verschillende toepassingen aan, waaronder betrouwbaarheidsanalyses en beoordelingen van werkstromen
**Cons
- Is afhankelijk van aannames over relaties tussen gegevens, wat kan leiden tot misleidende resultaten
4. Modellen voor onderlinge afhankelijkheid van termen
In tegenstelling tot eenvoudiger modellen, richten Term Interdependence Models zich op relaties tussen termen in plaats van alleen hun frequentie. Deze modellen analyseren hoe woorden en zinnen zich tot elkaar verhouden om de nauwkeurigheid van de resultaten te verbeteren.
Ze gebruiken een van de volgende twee benaderingen:
- Immanente modus: Onderzoekt relaties binnen de tekst zelf
- Transcendente modus: Bekijkt externe gegevens of context om relaties af te leiden
Deze methode is vooral bruikbaar voor het vastleggen van betekenisnuances, zoals synoniemen of contextspecifieke zinnen.
voordelen
- Vangt nuances in taal door rekening te houden met relaties tussen termen
- Verbetert zoekprestaties door begrip van afhankelijkheid van termen en context
❌ Cons
- Vereist uitgebreide gegevens om termrelaties nauwkeurig te modelleren, die niet altijd beschikbaar zijn
Dat was het! Dit zijn enkele veelgebruikte information retrieval systems, met hun eigen voor- en nadelen.
➡️ Lees meer: 4 Spotlight Zoekalternatieven en Concurrenten
Information Retrieval vs. Data Querying
Hoewel beide termen bijna hetzelfde lijken, werken ze verschillend. Dus laten we IR en Data Querying eens naast elkaar leggen om te zien hoe ze zich verhouden in termen van doel, gebruikssituaties en voorbeelden:
| Information Retrieval (IR) | Data Querying | Information Retrieval (IR) | Data Retrieval (IR) | Data Querying** |
|---|---|---|---|---|
| Zie het als het stellen van een specifieke vraag aan een database in een taal die de database begrijpt (zoals SQL) | ||||
| Helpt u snel en gemakkelijk nauwkeurige en relevante informatie of bronnen te vinden op zoekmachines. Haalt exacte gegevens op zodat u ze kunt analyseren, bijwerken of nummers kunt kraken | ||||
| Wordt gebruikt voor zoekopdrachten op het web, aanbevelingen voor e-commerce, digitale bibliotheken, inzichten in de gezondheidszorg en meer. Zeer geschikt voor taken als voorraadbeheer in e-commerce, het analyseren van financiën en het optimaliseren van toeleveringsketens | ||||
| Voorbeeld: Zoeken naar 'Beste laptops tussen $800 en $1000' op Google om gerangschikte resultaten te krijgen. Een query uitvoeren op uw voorraadsysteem voor 'SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000' om te zien wat er op voorraad is |
De rol van machinaal leren en NLP bij het ophalen van informatie
IR-systemen zijn net dataschattenjagers - ze zeven door enorme hoeveelheden informatie om precies te vinden wat je zoekt. Maar wanneer ML en NLP hun krachten bundelen, worden deze systemen slimmer, sneller en veel nauwkeuriger.
Zie ML als het brein achter IR-systemen. 🧠
Het helpt het systeem om te leren, zich aan te passen en de resultaten te verbeteren wanneer u naar informatie zoekt. Zo werkt het:
- Patronen herkennen: ML bestudeert waar gebruikers op klikken, wat ze negeren en waar ze de meeste tijd aan besteden. Het gebruikt deze kennis om u de volgende keer de meest relevante resultaten te tonen
- Resultaten rangschikken: ML haalt informatie op en rangschikt deze ook. Dat betekent dat de beste en nuttigste resultaten bovenaan je zoekopdracht verschijnen
- Met de tijd aanpassen: Met elke query wordt ML beter. Het pikt trends op, verfijnt zijn begrip en verwerkt zelfs de lastigste vragen met gemak
Voorbeeld: als je vandaag zoekt naar 'beste budgetlaptops' en je krijgt specifieke resultaten, dan weet ML dat soortgelijke opties voorrang moeten krijgen als je later zoekt naar 'betaalbare notebooks'. Door AI te combineren met ML kunnen webzoekmachines zelfs voorspellen wat je de volgende keer nodig hebt.
Laten we het nu hebben over NLP. Het helpt IR-systemen te begrijpen wat je bedoelt, niet alleen de woorden die je typt. In eenvoudige woorden:
- Het begrijpt context: NLP weet dat als u 'jaguar' zegt, u het dier of de auto kunt bedoelen, en het zoekt dat uit op basis van de rest van uw query
- **Of uw query nu eenvoudig is ('goedkope vluchten') of gedetailleerd ('rechtstreekse vluchten naar Tokio onder $500'), NLP zorgt ervoor dat het systeem de juiste resultaten begrijpt en levert
Samen zorgen NLP en IR ervoor dat zoeken intuïtief aanvoelt, alsof je met iemand praat die je gewoon begrijpt. Dit betekent minder scrollen, minder frustratie en meer "wow, dit is precies wat ik nodig had!" momenten.
De rol van ClickUp bij het zoeken naar informatie ClickUp , de 'alles app voor werk', verbetert gegevensbeheer met IR-modellen.
De ingebouwde AI identificeert de resultaten op unieke wijze en stemt deze af op de query van de gebruiker, waardoor intelligente technologie naar een hoger niveau wordt getild.
En om het helemaal af te maken, ClickUp's verbonden zoekopdracht maakt het een koud kunstje om alles wat u nodig hebt 'onmiddellijk' binnen handbereik te krijgen. Dat betekent:
- Alles zoeken: Wie vindt het leuk om door e-mails te bladeren enkennisbeheersystemen om belangrijke bestanden te vinden? Vind elk bestand in een paar seconden met de optie Verbonden zoeken. Beter nog, doorzoek bestanden in al uw verbonden apps en krijg toegang tot alles op één plek
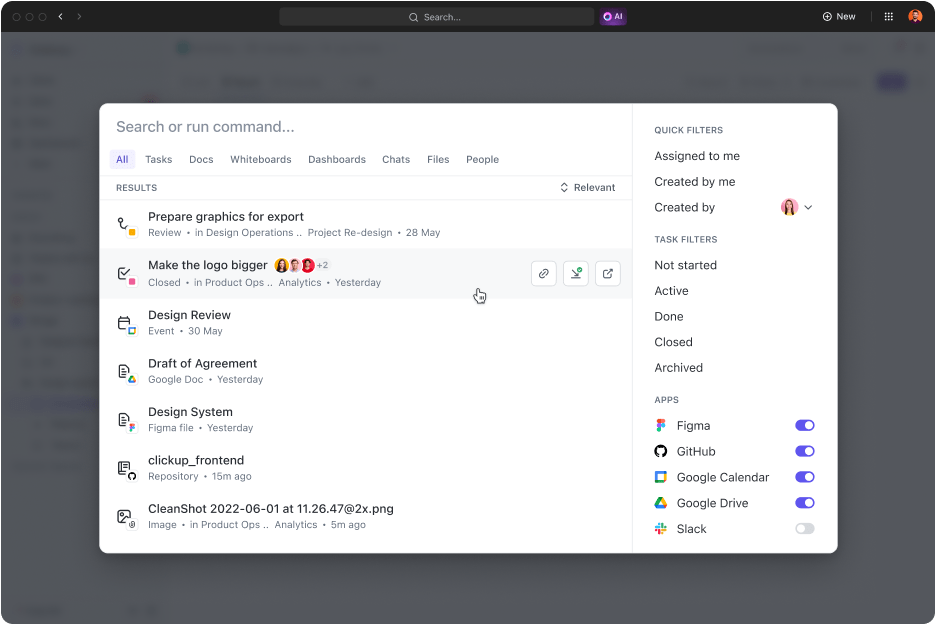
Zoek naar alles en lokaliseer elk bestand in enkele seconden met ClickUp's functie Verbonden zoeken
- Verbind uw favoriete apps:ClickUp heeft een aantal van de beste integraties die de zoekmogelijkheden uitbreiden naar apps van derden, zoals Google Drive, Dropbox, Figma en meer

Integreer je favoriete apps en krijg eenvoudig toegang tot je bestanden en beheer ze
- Raffineer resultaten: Hoe vaker u het gebruikt, hoe beter het begrijpt wat u zoekt en hoe beter het resultaten levert die speciaal op u zijn afgestemd
- Zoek op jouw manier: Krijg toegang tot Aangesloten zoeken enpDF-bestanden snel doorzoeken vanaf elke plek in uw werkruimte. U kunt bijvoorbeeld een zoekopdracht starten vanuit het commandocentrum, de Global Action Bar of uw desktop
- Creëer aangepaste zoekopdrachten: Voeg aangepaste zoekopdrachten toe zoals snelkoppelingen naar koppelingen, tekst opslaan voor later en meer om uw werkstroom te stroomlijnen
En wat als er een manier was om vervelende Taken te automatiseren, sneller te werken en meer dingen Klaar te krijgen in een mum van tijd? ClickUp Brein , de ingebouwde AI-assistent, maakt dit voor u werkelijkheid. Het is de ultieme assistent voor gegevensbeheer - slim, snel en altijd klaar om te helpen.
In een notendop 👇
- Alle-in-één kennis hub: Nooit meer vertrouwen op e-mails en berichten voor updates. Vraag alles over uw Taken, Documenten of Mensen en leun achterover terwijl ClickUp Brain de antwoorden in kaart brengt op basis van de context vanuit apps en verbonden apps

Vraag ClickUp Brain alles over uw werk en krijg onmiddellijk inzicht
- Vind sneller wat u nodig hebt: ClickUp Brain rangschikt resultaten op intelligente wijze zoals een geavanceerd IR-systeem. Het prioriteert relevante bestanden, stelt gerelateerde taken voor en helpt u zelfs verborgen werklasten in uw gegevens te ontdekken
- Taken automatiseren: Brain automatiseert het genereren van rapportages of het bijhouden van deadlines met zijnAI-tools. Het is een persoonlijke assistent die uw tijd vrijmaakt voor grotere beslissingen terwijl alles op schema blijft
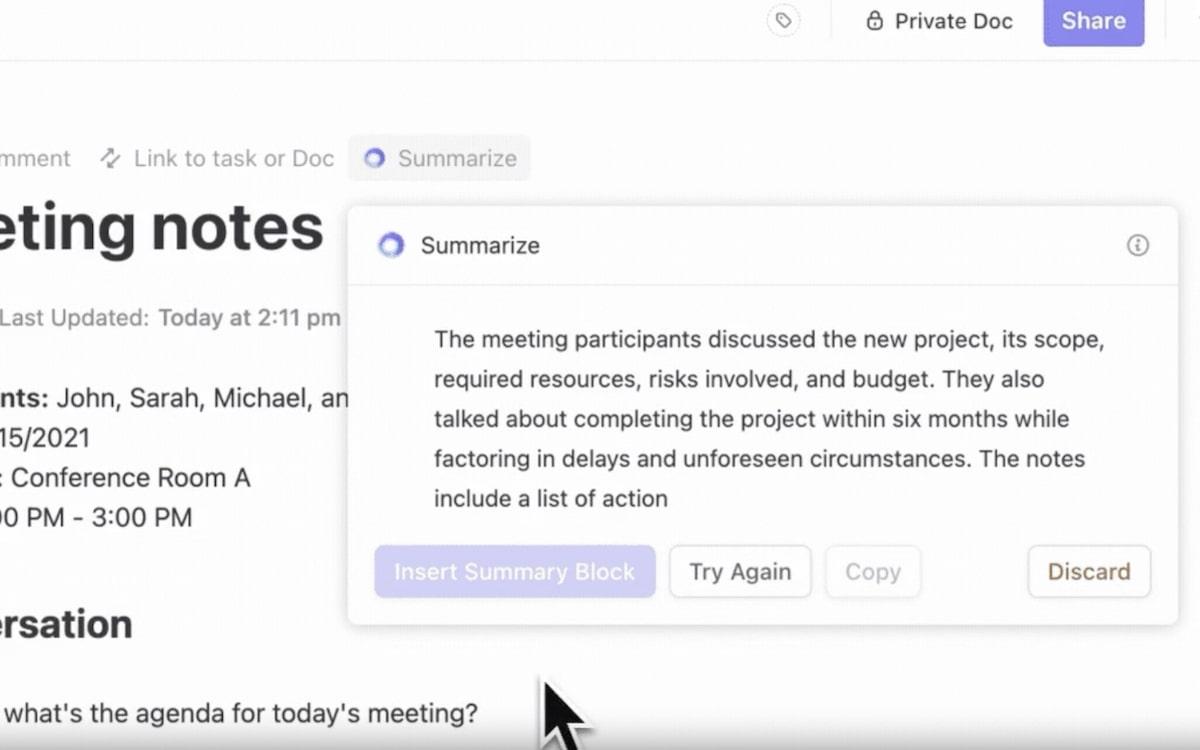
Automatiseer werkstromen, vat rapporten samen en stroomlijn taken moeiteloos met ClickUp-taak
- Contextbewust zoeken: Met NLP begrijpt ClickUp uw vraag, zelfs als uw query complex of vaag is. Bijvoorbeeld, zoeken op 'rapport over Q1 verkoop' geeft u het exacte rapport gekoppeld aan uw Taak
➡️ Lees meer: Wat is een werkmanagementsysteem en hoe implementeer je het?
Uitdagingen en toekomstige richtingen in informatie zoeken
In de wereld van information retrieval draait alles om het begrijpen van enorme hoeveelheden gegevens, maar zelfs de meest geavanceerde IR-systemen worden onderweg met een paar hobbels geconfronteerd.
Laten we eens kijken naar de gemeenschappelijke uitdagingen en de opwindende trends die vorm geven aan de toekomst van deze essentiële wetenschappelijke discipline:
- privacy en veiligheid van gegevens: Om feitelijke resultaten te kunnen leveren, heeft een IR-model vaak toegang nodig tot gevoelige gegevens. Het beschermen van gegevens van gebruikers is echter geen peulenschil voor informatiebronnen
- Schaalbaarheid en prestaties: Als gebruikers grote datasets doorzoeken, kan het verwerken van de stijgende collectie content zelfs de meest robuuste opvraagmodellen overweldigen. De uitdaging is ervoor te zorgen dat het ophalen efficiënt verloopt zonder de relevantie van de resultaten in gevaar te brengen
- Datakwaliteit en contextueel begrip: Dubbelzinnige query's of slecht georganiseerde metadata kunnen leiden tot mismatches, waardoor het voor het systeem moeilijk wordt om de intentie van de gebruiker te identificeren
Opkomende trends en ontwikkelingen in IR-technologie
Ondanks de vele hindernissen hebben recente technologische ontwikkelingen ons in staat gesteld slimmere, efficiëntere systemen te bouwen.
Moderne information retrieval systemen gebruiken nu geavanceerde methoden zoals grafiekgebaseerde analyse om de nummers en tekst en de context, metadata en relaties tussen de gegevenspunten te interpreteren.
Wat betekent dit voor gebruikers? Het maakt het mogelijk om nauwkeuriger tekst op te zoeken en gedetailleerde analyses uit te voeren, vooral in velden als onderzoek en industrieën met veel gegevens.
In combinatie met semantische webtechnologieën richt het zich op zoekreeksen en gebruikersintentie. Deze systemen kunnen verder gaan dan letterlijke overeenkomsten en zeer relevante documenten ophalen, zelfs voor gecompliceerde query's van gebruikers bij het ophalen van informatie.
Een voorbeeld: zoeken op 'voordelen van werken op afstand' kan resultaten opleveren met betrekking tot productiviteit, geestelijke gezondheid en de balans tussen werk en privé - allemaal omdat het systeem de verbindingen begrijpt.
Documenten snel ophalen met ClickUp's gegevensbeheer
Het doorspitten van eindeloze bestanden, apps en tools om dat ene belangrijke document te vinden is vermoeiend. Stelt u zich eens voor dat u als onderzoeker, student, IT-professional of gegevenswetenschapper teruggevonden documenten probeert te analyseren - dan wordt het gewoon een samenraapsel van informatieovervloed.
Maar met ClickUp verspilt u nooit meer tijd aan het zoeken naar informatie.
Het is de alles-in-één oplossing die uw werk op één plaats samenbrengt. Met functies als Connected Search en ClickUp Brain maakt het niet uit waar uw gegevens zich bevinden - ClickUp maakt het gemakkelijk om ze te vinden, te beheren en er iets mee te doen.
Waarom genoegen nemen met 'gewoon goed' als u ook 'geweldig' kunt hebben? Probeer ClickUp gratis uit en zie hoe het uw werkstroom verandert in iets gedurfds, efficiënt en ronduit onstuitbaar!