

AI heeft veranderd wat ingenieurs zelf moeten documenteren. GitHub Copilot, Cursor en Mintlify kunnen eerste versies van documentatie genereren: parameterbeschrijvingen, functieoverzichten en README-sjablonen. Wat ze niet kunnen schrijven is de Intent Layer: de genomen beslissing, de geaccepteerde afweging, de beperking die van belang was en de optie die het team heeft afgewezen.
Code toont gedrag. De onderliggende reden wordt zelden vastgelegd. Die reden staat meestal in een Slack-thread, een opmerking bij een ticket, een incidentrapport of in iemands geheugen.
Uit de Developer Survey 2024 van Stack Overflow bleek dat 61% van de professionele ontwikkelaars meer dan 30 minuten per dag besteedt aan het zoeken naar antwoorden op het werk, waarbij een op de vier er meer dan een uur aan besteedt. Natuurlijk is zoeken soms onvermijdelijk. Maar de echte verspilling is de Sprint-context die nooit in een document terecht is gekomen.
Deze gids laat zien wat engineers zelf moeten schrijven, waar AI kan helpen en hoe je codedocumenten bruikbaar houdt nadat de Sprint is afgelopen.
TL;DR
AI kan de mechanische laag van de documentatie opstellen: docstrings, parameters, functieoverzichten en README-sjablonen. Ingenieurs moeten nog steeds de intentielaag schrijven: de beslissingen, afwegingen, beperkingen en afgewezen opties achter de code.
Ingenieurs moeten dat nog steeds zelf schrijven, in Architecture Decision Records, PR-beschrijvingen en 'why'-opmerkingen die samen met de code worden vastgelegd. De intentielaag voorkomt dat de volgende ontwikkelaar beslissingen moet achterhalen aan de hand van variabelenamen, commitberichten en oude PR's. AI kan nu de routinematige onderdelen opstellen: parametertypen, retourbeschrijvingen en basisoverzichten van functies.
Wat moet codedocumentatie eigenlijk uitleggen?
Code-documentatie moet de volgende ontwikkelaar helpen begrijpen wat de code doet, hoe deze veilig te gebruiken is en waarom deze op die manier is gebouwd. Deze komt op twee plaatsen voor: binnen bronbestanden als opmerkingen en docstrings, en buiten bronbestanden als README's, API-referenties, runbooks en architectuuraantekeningen.
De meeste codebases worden moeilijk te lezen zodra de context van de beslissing verdwijnt. De oorspronkelijke ontwikkelaar heeft misschien een slimme afweging gemaakt. De volgende ontwikkelaar ziet alleen het resultaat, niet de redenering.
Het resultaat: elk nieuw teamlid moet de intentie achterhalen uit variabelenamen, commitberichten en oude PR's. Dat vertraagt de inwerking, reviews, het opsporen van fouten en toekomstige wijzigingen in datzelfde gebied.
Goede documentatie geeft antwoord op vier vragen:
- Voor wie is deze code bedoeld? Interne ontwikkelaars, open-sourcebijdragers, externe API-gebruikers of eindgebruikers
- Welk probleem lost het op? De zakelijke of technische behoefte achter de module
- Waarom is voor deze aanpak gekozen? De overwogen alternatieven en de geaccepteerde afwegingen
- Waar zijn de gerelateerde onderdelen? Modules met afhankelijkheid, upstream-services, architectuurbeslissingen, tickets en runbooks
De 'waarom'-vraag verdient de meeste aandacht van de mens.
Zoeken is ook buiten de engineering al een grote belasting voor kenniswerk. Uit het kennisbeheeronderzoek van ClickUp bleek dat 57% van de werknemers tijd verspilt met het zoeken naar werkgerelateerde informatie in interne documenten of kennisbanken. Als ze niet kunnen vinden wat ze nodig hebben, neemt 1 op de 6 zijn toevlucht tot persoonlijke noodoplossingen: het doorzoeken van oude e-mails, aantekeningen of schermafbeeldingen.
Code-documentatie faalt op dezelfde manier: als ontwikkelaars de uitleg niet kunnen vinden, kan de uitleg net zo goed niet bestaan.
De kosten van een fout zijn hoog. Een commentator op r/AskProgramming beschreef een RPA-werkstroom waarbij een niet-gedocumenteerde knop bijna automatische bankkosten en brieven aan klanten triggerde.
Zoeken is ook buiten de engineering al een grote belasting voor kenniswerk. Uit het kennisbeheeronderzoek van ClickUp bleek dat 57% van de werknemers tijd verspilt met het zoeken naar werkgerelateerde informatie in interne documenten of kennisbanken. Als ze niet kunnen vinden wat ze nodig hebben, neemt 1 op de 6 zijn toevlucht tot persoonlijke noodoplossingen: het doorzoeken van oude e-mails, aantekeningen of schermafbeeldingen.
Code-documentatie faalt op dezelfde manier: als ontwikkelaars de uitleg niet kunnen vinden, kan de uitleg net zo goed niet bestaan.
De kosten van een fout zijn hoog. Een commentator op r/AskProgramming beschreef een RPA-werkstroom waarbij een niet-gedocumenteerde knop bijna automatische kosten voor de bank en brieven aan klanten triggerde.
Wat zijn de belangrijkste soorten code-documentatie?
De vijf belangrijkste soorten zijn inline-opmerkingen, docstrings, README-bestanden, interne wiki's en externe API-documentatie. Elk type is bedoeld voor een andere lezer op een ander moment. Als je ze door elkaar haalt, wordt het moeilijker om documentatie te schrijven en te gebruiken. Een README die leest als een docstring schrikt nieuwe bijdragers af. Een docstring die leest als een wikipagina wordt ballast binnen bronbestanden.
Inline-opmerkingen en docstrings
Inline-opmerkingen moeten niet-voor de hand liggende redeneringen uitleggen. Een opmerking die x = x + 1 herformuleert als "x verhogen" voegt niets toe. Een opmerking die zegt "offset voor API-respons met index vanaf nul" verdient zijn plaats omdat de code die externe beperking niet kan weergeven. Gebruik inline-opmerkingen alleen voor niet-voor de hand liggende logica binnen de body van een functie.
Docstrings zijn gestructureerde beschrijvingen die aan functies, klassen of modules zijn gekoppeld. Ze omvatten parameters, retourwaarden, uitzonderingen en voorbeelden van gebruik. Elke taal heeft zijn eigen conventies. Volg de conventie die uw taal al verwacht: PEP 257 voor Python-docstrings, Javadoc voor Java en JSDoc voor JavaScript en TypeScript.
Vergelijk deze twee:
Zwakke docstring:
Sterke docstring:
De tweede geeft de functie een duidelijke naam, documenteert de parameters ervan en legt een aanname bloot: de werkstroom hanteert een belastingtarief van 8,25%.
README's, wiki's en externe documenten
Een README moet vijf vragen in volgorde beantwoorden: Wat doet dit project? Hoe installeer ik het? Hoe gebruik ik het? Hoe kan ik bijdragen? Waar kan ik hulp krijgen? Als een nieuwe bijdrager niet snel het installatiepad kan vinden, is de README ofwel overladen of slecht gestructureerd.
Wiki's en kennisbanken werken het beste voor content die meerdere opslagplaatsen of services omvat: architectuurbeslissingen, onboardinggidsen en runbooks. Een wiki waar niemand vanuit de code naar gekoppeld is, wordt een tweede zoekprobleem.
Externe documentatie omvat API-referenties, SDK-handleidingen en documentatie voor gebruikers. Deze is bedoeld voor de gebruikers van uw code, niet voor de bijdragers. Externe documentatie vereist meer details over de installatie, duidelijkere stappen voor verificatie en een referentiestijl, omdat de lezer mogelijk helemaal niet bekend is met uw codebase.
Als het team nog geen structuur heeft, begin dan met een sjabloon voor technische documentatie voor architectuur en aantekeningen over de installatie, of een sjabloon voor projectdocumentatie voor doelen, eigenaars, mijlpalen en beslissingen. Pas de secties aan in plaats van een geheel nieuw format te bedenken.
| Type | Voornaamste doelgroep | Frequentie van updates | Typische locatie |
|---|---|---|---|
| Inline-opmerkingen | Ontwikkelaars die een specifiek codepad lezen | Wanneer het gedrag van code verandert | Bronbestanden |
| Docstrings | Ontwikkelaars die een functie, klasse of module aanroepen | Wanneer de interface verandert | Bronbestanden |
| README | Nieuwe bijdragers en beoordelaars | Per grote release of projectwijziging | Hoofdmap van de opslagplaats |
| Wiki of kennisbank | Interne teams en belanghebbenden uit verschillende teams | Naarmate beslissingen of processen veranderen | Repository-wiki van de gedeelde kennisbank |
| Externe API-documentatie | API-gebruikers en eindgebruikers | Per release van de API-versie | Documentatieplatform |
Hoe schrijf je tegenwoordig eigenlijk documentatie?
Gebruik AI voor de onderdelen die het kan opstellen. Besteed menselijke tijd aan beslissingen, beperkingen en afwegingen.
AI kan nu een groot deel van het routinematige werk opstellen: parametertypen, beschrijvingen van retourwaarden en basisoverzichten van functies. Het documentatiewerk door mensen valt uiteen in twee categorieën.
Schrijf eerst zelfdocumenterende code
De beste documentatie is code die nauwelijks nodig heeft. Beschrijvende namen, functies met één doel en consistente conventies verminderen de documentatielast nog voordat je ook maar één opmerking schrijft.
Zelfdocumenterende code maakt het gedrag makkelijker te lezen. Het legt zelden de redenering achter dat gedrag uit. Namen helpen ontwikkelaars te identificeren wat iets doet. Documentatie moet de redenering uitleggen die naamgeving niet kan overbrengen.
Vraag jezelf, voordat je een opmerking toevoegt, af of het hernoemen van een variabele of het extraheren van een functie de opmerking overbodig zou maken. Als het antwoord ja is, voer dan eerst een refactor uit. Een duidelijke naam maakt opmerkingen overbodig die alleen maar slechte naamgeving verduidelijken.
Voorheen:
Na:
De geherstructureerde versie brengt dezelfde informatie over via de naamgeving alleen. De enige nuttige opmerking zou nu zijn waarom bepaalde rollen zijn uitgesloten, wat een beleidsbeslissing is die de code zelf niet kan uitdrukken.
Schrijf de intentielaag (het deel dat AI niet kan)
De implementatie is zichtbaar in de code. De intentie verdwijnt tenzij iemand deze opschrijft. Code legt zelden vast waarom er een afweging is gemaakt, welke beperking aanleiding gaf tot een ontwerp, of welk alternatief is afgewezen.
Een veelgebruikte regel onder ontwikkelaars vat dit goed samen: documenteer het waarom, niet het wat. Een veelgelikete reactie op r/coding:
Ik zie dat deze voorwaardelijke vertakking plaatsvindt tussen rode en blauwe gebruikers. Vertel me waarom gebruikers op die manier worden ingedeeld en waarom we tussen hen vertakken.
Ik zie dat deze voorwaardelijke vertakking plaatsvindt tussen rode en blauwe gebruikers. Vertel me waarom gebruikers op die manier worden ingedeeld en waarom we tussen hen vertakken.
Een commitbericht kan helpen tijdens de review, maar het is op de lange termijn geen geschikte plek voor ontwerpbegronden, omdat toekomstige lezers het zelden vinden op het moment dat ze het nodig hebben.
Will Larson, voormalig CTO van Calm en auteur van An Elegant Puzzle, heeft geschreven over de waarde van Architecture Decision Records omdat ze de technische onderbouwing buiten de codebase bewaren.
ADR's zijn nuttig omdat ze de ontwerpredenering een vaste plek geven. Als je team geen vast format heeft, gebruik dan een eenvoudig ADR-sjabloon: beslissing, context, overwogen opties, afwegingen en gevolgen.
Richt uw documentatie op de volgende categorieën:
- Ontwerpbeslissingen en alternatieven: “We hebben hier gekozen voor een write-through-cache in plaats van een write-back-cache, omdat dataconsistentie voor deze werkstroom belangrijker is dan schrijflatentie”
- Bekende limieten: Technische schuld, schaalbaarheidslimieten, tijdelijke noodoplossingen of gebieden die in de toekomst moeten worden opgeschoond
- Aannames: Verwachte invoerformaten, omgevingsvereisten of upstream-afhankelijkheden die de code niet afdwingt
- Referenties: Links naar relevante tickets, RFC's of Architecture Decision Records (ADR's) die de bredere context toelichten
Verschillende contexten vragen om verschillende plaatsen. Docstrings leggen de intentie op functieniveau vast. Code-commentaren behandelen de redenering op regelniveau. PR-beschrijvingen bieden context op wijzigingsniveau. ADR's behandelen beslissingen op systeemniveau. Commitberichten helpen ook, maar ze mogen niet de enige vastlegging van een belangrijke beslissing zijn.
Een veelvoorkomend anti-patroon: het sorteringsalgoritme regel voor regel documenteren. De echte vraag is waarom er voor een aangepaste sortering is gekozen in plaats van de standaardbibliotheek. Documenteer bij aangepaste codepaden de beslissing achter de implementatie.
Wat zijn de belangrijkste best practices voor documentatie?
Vijf werkwijzen zorgen ervoor dat documentatie na afloop van de Sprint waarschijnlijk nuttig blijft. Bij de meeste andere adviezen over documentatie is er een afhankelijkheid van het feit dat deze werkwijzen al in praktijk worden gebracht.
- Documenteer terwijl je codeert, niet daarna. De context vervaagt snel. Tegen de volgende Sprint ben je vergeten welk alternatief je hebt afgewezen en waarom. Schrijf de 'waarom'-opmerking in dezelfde toewijzing als de code, anders schrijf je hem helemaal niet
- Gebruik een consistente stijlgids. Kies één docstring-format, zoals Google-stijl, NumPy-stijl, Javadoc of JSDoc, en handhaaf dit bij codereview of linting. Consistentie is belangrijker dan welk format je kiest. Een gedeelde stijlgids maakt een einde aan de vraag “hoe moet ik dit opmaken?” en maakt geautomatiseerde linting mogelijk
- Beschouw documentatie als onderdeel van de codereview. Voeg documentatiecontroles toe aan je PR-checklist. Als een PR het gedrag wijzigt, moet de reviewer controleren of de documentatie de wijziging weerspiegelt. In de documentatie over engineeringpraktijken van Google wordt reviewers gevraagd te controleren of de code goed gedocumenteerd is. Pas dezelfde regel intern toe: als een PR het gedrag wijzigt, moeten reviewers controleren of opmerkingen, docstrings, README's en runbooks nog steeds overeenkomen
- Verwijder verouderde documentatie. Verouderde documentatie kan echte schade aanrichten omdat het lezers naar de verkeerde implementatie, API of het verkeerde proces leidt. Evalueer documentatie elk kwartaal of vóór elke grote release. Geef eigendom toe, zodat documentatie niet ieders verantwoordelijkheid is en dus van niemand.
- Zorg dat voorbeelden uitvoerbaar blijven. Code-voorbeelden moeten gemakkelijk te kopiëren, uit te voeren en te testen zijn. Dat is de veiligste manier om afwijkingen op te sporen voordat gebruikers dat doen
Welke tools moet u gebruiken om code-documentatie te genereren?
Documentatietools vallen uiteen in twee groepen: traditionele generators en AI-assistenten. Ze vervullen verschillende taken.
Traditionele generators analyseren gestructureerde opmerkingen in uw broncode en genereren doorbladerbare referenties. Welke generator het meest geschikt is, hangt meestal af van de taal die u gebruikt.
| Tool | Taal/ecosysteem | Wat het genereert |
|---|---|---|
| Javadoc | Java | API-referentie op basis van opmerkingen in documenten |
| JSDoc | JavaScript/TypeScript | API-referentie op basis van geannoteerde opmerkingen |
| Sphinx | Python (ondersteunt andere talen via plug-ins) | Volledige documentatiesites vanuit reStructuredText of Markdown |
| Doxygen | C, C++, Java, Python en andere | Taaloverschrijdende referentiedocumentatie |
| Godoc | Ga | Pakketdocumentatie op basis van broncodecommentaar |
De kwaliteit van de output hangt volledig af van uw docstrings. Deze geven vorm aan en publiceren wat u hebt geschreven. Ze vullen ontbrekende bedoelingen niet aan.
AI-aangedreven assistenten voegen een tweede laag toe. GitHub Copilot, Cursor en Windsurf kunnen opmerkingen en docstrings opstellen binnen de editor. Mintlify kan helpen bij het genereren en onderhouden van ontwikkelaarsdocumentatie op basis van code en bestaande documentatie. Swimm richt zich op het koppelen van interne documentatie aan codewijzigingen. ReadMe en GitBook helpen teams bij het publiceren van API-referenties en documentatie voor ontwikkelaars, vaak met AI-ondersteunde zoek- of schrijffuncties.
Uit het onderzoek van Stack Overflow bleek dat documentatie de meest gevraagde categorie voor AI-automatisering was, genoemd in ongeveer 33,9% van de open antwoorden van ontwikkelaars. Deze tools zijn het meest effectief wanneer de code het gedrag al duidelijk weergeeft.
AI wordt zwakker wanneer de uitleg afhankelijk is van beslissingen die buiten de codebase zijn genomen: een Slack-thread, een planningsvergadering, een ticket of een incidentbeoordeling. Het kan de functie samenvatten. Het kan niet weten welke beperking onderhandelbaar was, welke optie werd afgewezen of waarom de afweging werd geaccepteerd.
Praktische werkstroom:
- Laat AI het raamwerk opstellen: functieoverzicht, parameters, retourwaarden en veelvoorkomende uitzonderingen
- Vergelijk het met het daadwerkelijke gedrag van de code
- Voeg het 'waarom' toe: de beslissing, beperking, aanname of afgewezen alternatief
- Schrijf een ADR voor beslissingen op systeemniveau
- Publiceer geen door AI gegenereerde documenten zonder deze te controleren
Waar ClickUp wel en niet past
ClickUp is geen generator voor documentatie op codeniveau. Het vervangt Javadoc, Sphinx, JSDoc of Godoc niet. Het helpt bij de documentatie rondom de code: README's, runbooks, onboardinggidsen, ADR's en beslissingslogboeken die gekoppeld moeten blijven aan de taken, tickets en sprints die ze hebben voortgebracht.
Met ClickUp Docs kun je dit naast je technische werk opstellen, en ClickUp Brain kan een document opstellen op basis van de context van een taak of project, waarna ontwikkelaars de redenen voor de beslissing, beperkingen en afwegingen kunnen toevoegen.
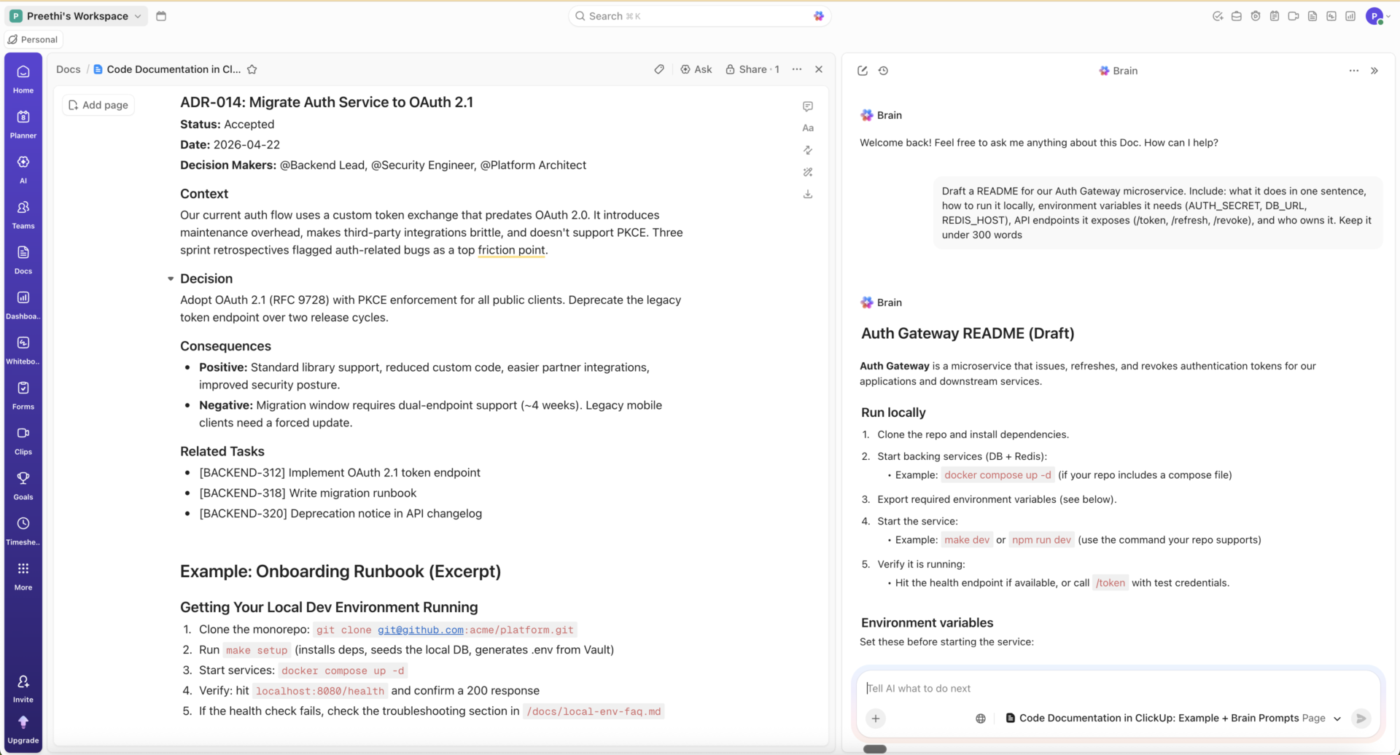
Voor engineeringteams betekent dit dat ze minder tijd kwijt zijn aan het doorzoeken van verspreide documenten, chats en tickets, en meer tijd hebben om de beslissingen vast te leggen die door die tools doorgaans verborgen blijven.
Als uw probleem is: "onze documenten zijn technisch gezien compleet, maar niemand kan ze vinden", dan is dat een vindbaarheidsprobleem. Een verbonden werkruimte kan daarbij helpen.
Als uw probleem is dat "onze API-referentie verouderd is", dan is dat een probleem met de generator en de beoordeling. Sphinx, Javadoc, JSDoc of Godoc zullen u meer helpen dan een werkruimte-tool. Verwar deze twee niet met elkaar.
Wat verandert er als AI het grootste deel van de documentatie schrijft?
Er is een terugkerende grap in de threads van r/developersIndia, r/webdev en r/AskProgramming over technische documentatie. Als iemand vraagt hoe het team met documentatie omgaat, is het meest gegeven antwoord meestal een versie van: “Ik ben de documentatie.”
Het is grappig omdat het waar is. Jarenlang was de oplossing voor ontbrekende documentatie de engineer die het toevallig nog wist.
AI verandert de norm. Het kan routinematige documentatie snel opstellen, waardoor ongedocumenteerde beslissingen moeilijker te rechtvaardigen zijn. Wanneer AI de mechanische onderdelen van uw documenten binnen enkele seconden kan opbouwen, is 'ik onthoud het wel' niet langer acceptabel als het officiële verslag.
Dat verschuift de focus van de engineer naar intentie, beslissingen en afwegingen: de aspecten die de syntaxis alleen niet kan verklaren.
Veel van het oude advies over documentatie is geschreven voor een pre-AI-werkstroom. Het richt zich sterk op parameterbeschrijvingen, functiesignaturen en uitgebreide aantekeningen over de installatie.
AI kan nu een groot deel van dat werk opstellen. Als ingenieurs het grootste deel van hun documentatietijd besteden aan mechanische samenvattingen, besteden ze menselijke aandacht aan de laag met de laagste waarde.
Besteed de tijd aan de intentie: waarom de functie bestaat, welke optie je hebt afgewezen en op welke aanname de code is gebaseerd. Dat zijn de aantekeningen die je toekomstige team, AI-codeeragenten en de engineer die de codebase in 2027 overneemt, nodig zullen hebben.
Als je documentatieprobleem bestaat uit een versnipperde context, kan ClickUp helpen om de beslissingsgeschiedenis dichter bij de taken, documenten en projecten te houden die eraan ten grondslag liggen.
Veelgestelde vragen over code-documentatie
Wat is een README?
Een README slaagt voor zijn eerste test als een bijdrager snel vijf dingen kan vinden: wat het project doet, hoe het te installeren, hoe het te gebruiken, hoe bij te dragen en waar hulp te vinden is. Als de installatie verborgen ligt onder badges, architectuurnotities of changelog-details, is de README slecht gestructureerd.
Wat is het verschil tussen code-commentaar en documentatie?
Codecommentaar staat in de broncodebestanden en geeft uitleg over specifieke regels of blokken. Documentatie staat meestal buiten de broncodebestanden, in README's, wiki's, gegenereerde referentiesites of API-documentatie. Commentaar helpt de volgende ontwikkelaar die uw functie leest. Documentatie helpt de volgende persoon die uw project probeert te gebruiken, uit te voeren of eraan bij te dragen.
Wat is de intentielaag in code-documentatie?
De Intent Layer is het deel van de codedocumentatie dat vastlegt waarom de code bestaat, niet wat deze doet: de genomen beslissing, de geaccepteerde afweging, de beperking die het ontwerp heeft bepaald en de optie die het team heeft afgewezen. Code toont gedrag; de Intent Layer bewaart de onderliggende redenering. AI-tools zoals GitHub Copilot en Mintlify kunnen de mechanische laag (parametertypen, functieoverzichten) opstellen, maar kunnen de Intent Layer niet afleiden uit de syntaxis. Deze is meestal te vinden in Architecture Decision Records, PR-beschrijvingen of opmerkingen die waarom uitleggen in plaats van wat.
Hoe vaak moet code-documentatie worden bijgewerkt?
Werk de documentatie bij in dezelfde pull-aanvraag die het onderliggende gedrag wijzigt. Als een functie-signatuur verandert, verandert de docstring in die PR. Controleer README's en architectuurdocumenten minstens één keer per release of elk kwartaal. Verouderde documentatie is gevaarlijk omdat deze lezers verkeerd gedrag, een verkeerde API of een verkeerd proces bijbrengt.
Wat zijn de vier soorten documentatie?
Het veelgebruikte Diátaxis-raamwerk verdeelt documentatie in vier soorten: tutorials (leergericht, voor beginners), handleidingen (Taakgericht, voor gebruikers die een specifiek probleem oplossen), naslagwerken (informatiegericht, voor gebruikers die details opzoeken) en uitleg (begripsgericht, voor gebruikers die context willen). Door deze te mengen ontstaat documentatie die niemand kan gebruiken. Een README die een volledige tutorial probeert te zijn, kan het installatiepad verbergen. Een referentiepagina die als een essay is geschreven, kan de API-aanroep verbergen.
Hoe documenteer je code met AI?
Gebruik AI voor de mechanische laag en schrijf de intentielaag zelf. Tools zoals GitHub Copilot, Cursor en Mintlify kunnen docstrings, parameterbeschrijvingen, retourwaarden en functieoverzichten rechtstreeks in je editor opstellen. Toets het concept aan het daadwerkelijke gedrag van de code en voeg vervolgens de onderdelen toe die AI niet kan afleiden: de reden voor de beslissing, de beperking die eraan ten grondslag lag, de optie die je hebt afgewezen en elke aanname waarop de code berust. Schrijf voor beslissingen op systeemniveau een Architecture Decision Record. Publiceer nooit door AI gegenereerde documenten zonder dat deze door een mens zijn gecontroleerd.
Is door AI gegenereerde documentatie betrouwbaar?
Door AI gegenereerde documentatie is handig voor mechanisch werk zoals parameterbeschrijvingen, retourwaarden en basisoverzichten van functies, maar het moet nog steeds door mensen worden gecontroleerd. Tools zoals GitHub Copilot, Cursor, Codeium en Mintlify kunnen dit goed aan. AI kan niet afleiden waarom er een afweging is gemaakt, welke alternatieven zijn afgewezen of welke product-, bedrijfs- of infrastructuurbeperkingen de vorm van het ontwerp hebben bepaald. Gebruik AI voor het eerste concept. Voeg zelf de intentie en context toe.
Heeft elke functie een docstring nodig?
Nee. Openbare API's en elke functie die een andere ontwikkelaar zal aanroepen, hebben docstrings nodig. Privé-helpers die in één bestand worden gebruikt, hebben dat meestal niet nodig, tenzij de logica niet voor de hand ligt. Het overmatig documenteren van triviale code zorgt voor een onderhoudslast zonder dat dit duidelijkheid toevoegt. Stem de diepgang van de documentatie af op de doelgroep van de functie.
Wat is de beste tool voor het genereren van code-documentatie?
De juiste tool hangt af van uw taal. Java-teams gebruiken Javadoc, JavaScript- en TypeScript-teams gebruiken JSDoc, Python-teams gebruiken Sphinx, Go-teams gebruiken Godoc en Doxygen ondersteunt C, C++ en diverse andere talen. AI-ondersteunde tools zoals Mintlify, Swimm, Copilot en Cursor kunnen helpen bij het opstellen of onderhouden van documentatie in verschillende delen van de werkstroom, maar ze vervangen geen taal-specifieke generators.
Hoe lang moet een README zijn?
Lang genoeg om snel de basis te behandelen: wat het project doet, hoe het te installeren, hoe het te gebruiken, hoe bij te dragen en waar hulp te vinden is. Zet meer gedetailleerde informatie over de installatie, architectuur en API in gekoppelde documenten of submappen.