
その文書が存在するはずだと確信しています。先週見たばかりです。
しかし「第3四半期のマーケティング結果」「第3四半期の業績」「10月のマーケティングレポート」など、考えられるあらゆるキーワードの組み合わせを試しても、会社の検索バーは空っぽのまま。この苛立たしい情報探しは、時代遅れのキーワード検索の典型的な兆候です。
従来のシステムは完全一致の単語しか見つけられず、真意を見逃します。Cohereはシステムを接続するインテリジェントな検索レイヤーを提供し、この課題を効果的に解決します。
「Cohereを企業検索に活用する方法」をお探しなら、当ガイドがすべてを解説します。
Cohere AIとは何か?なぜ企業検索にとって重要なのか?
Cohere は、企業利用に特化した大規模言語モデル(LLM)を構築するAIプラットフォームです。社内検索においては、キーワードベースの検索を超え、意図・文脈・意味を理解する意味論的インテリジェント検索を実現します。
多くの企業検索ツールは依然として文字通りのキーワード一致に依存しています。文書タイトルや本文に完全一致する単語が含まれない場合、結果から漏れることが多々あります。Cohereは、ユーザーが入力した文字列だけでなく、実際に求めている内容を検索システムが理解できるようにすることで、この状況を変えます。
自社でAI搭載検索を構築しようとするチームは、通常、ベクトルデータベース、埋め込みパイプライン、再ランク付けモデルの構築に数か月を費やします。それほどの労力をかけた後も、検索は実際の業務が行われるシステムとは別の場所に存在し、タスクや文書、ワークフローから切り離されているため、パフォーマンスが低下することが多いのです。
Cohereのような強力な企業検索ツールは、検索拡張生成(RAG)技術を用いてスマート検索とAIを融合させます。このアプローチにより、社内知識が即座にアクセス可能なリソースへと変貌します。
Cohereの場合、このツールは文書を意味の数値表現である埋め込み表現に変換します。ユーザーが「四半期収益報告書」を検索すると、システムは「第4四半期決算結果」や「収益要約」など、概念的に関連する文書を抽出します。たとえそれらのキーワードが正確に含まれていなくてもです。
Cohereが企業検索において重要な理由です。導入の複雑さを軽減し、結果の精度を向上させ、現代のワークシステム内で従業員が実際に考える方法や質問の仕方に基づいた検索を実現します。
📮ClickUpインサイト: 従業員の半数以上(57%)が、仕事に関連する情報を探すために社内ドキュメントやナレッジベースを検索する時間を無駄にしています。
では、それができない場合は?6人に1人が個人的な回避策に頼っています——古い電子メールやメモ、スクリーンショットを掘り起こして、情報を寄せ集めるためだけに。
ClickUp Brainは、ワークスペース全体と統合されたサードパーティアプリからAI駆動の即時回答を提供することで検索を不要にし、煩わしさなく必要な情報を得られます。
企業検索向けCohereの主要機能
AI検索ソリューションを評価する際、マーケティングの誇大宣伝により、どの機能が実際に課題を解決するのか判断が困難になる場合があります。「よりスマートな検索」といった一般的な約束事は、エンジニアリングチームやプロダクトチームが情報に基づいた意思決定を行う助けにはなりません。
現実には、信頼性の高い検索システムは、複数の異なるAIモデルが連携して動作するパイプラインに依存しています。
Cohereは複数のモデルを提供しており、単独で使用したり組み合わせて高度な検索アーキテクチャを構築できます。これらのコア機能を理解することが、チームの特定のニーズを満たすシステム設計の第一ステップです。
セマンティックベクトル検索のための埋め込み生成
従来の検索システムにおける最大の不満点は、概念的に関連する情報を見つけられないことです。「従業員オンボーディングガイド」を検索しても、「新入社員初日チェックリスト」というタイトルの文書を見逃してしまいます。これはシステムが意味ではなく単語を照合しているためです。
ニューラル検索を備えたEmbedモデルは、テキストをベクトル(意味的な意味を捉えた長い数値リスト)に変換することでこの課題を解決します。この「埋め込み」と呼ばれるプロセスにより、共通キーワードを共有していなくても概念的に類似した文書を識別可能になります。つまり、検索ツールが自動的に同義語や関連概念を理解する仕組みです。
CohereのEmbedモデルの主な特徴は以下の通りです:
- マルチモーダルサポート:最新バージョン「Embed 4」はテキストと画像の両方を処理可能。異なる種類のコンテンツを同時に検索できます
- 多言語対応機能: 翻訳を必要とせずに、異なる言語の文書を横断して情報を検索できます
- 次元数の選択肢: ベクトルのサイズを選択できます。高次元ほどニュアンスを捉えられますが、より多くのストレージと処理能力を必要とします
📖 詳細はこちら:AI企業検索の活用事例
結果の関連性を高めるための再ランク付け
検索で関連文書のリストが表示されても、最も重要な文書が2ページ目に埋もれていることがあります。これによりユーザーは結果を丹念に確認せざるを得ず、時間の浪費と検索システムへの信頼喪失を招きます。
これはランキングの問題です。システムは正しい情報を見つけましたが、優先順位付けを正しく行えませんでした。
CohereのRerankモデルは、2つのフェーズでこの課題を解決します。まず、高速な検索手法(セマンティック検索など)を用いて、関連性のある可能性が高い大量の文書を収集します。次に、そのリストをRerankモデルに渡し、より計算負荷の高いクロスエンコーダーアーキテクチャを用いて、各文書を特定のクエリに対して分析し、関連性を最大化するよう再順序付けします。
これは特に、サポート担当者が顧客に適切な回答を見つける場合や、チームメンバーが文書内の特定セクションを検索する場合など、精度が極めて重要なハイステークスな状況で有用です。処理時間にわずかな追加が発生しますが、結果の品質向上は多くの場合、そのトレードオフに見合う価値があります。
📖 詳細はこちら:ワークフロー自動化の例とユースケース
企業向けエンタープライズ検索のユースケース
抽象的なAI機能は興味深いものの、現実のビジネス課題解決に応用して初めて真価を発揮します。成功する企業検索の導入は、こうした具体的な課題点の特定から始まります。👀
Cohereを活用した検索をチームが適用できる実用的なシナリオをいくつかご紹介します:
- ナレッジベース検索: 従業員が社内文書、wiki、カスタマーサービスナレッジベース、標準業務手順書(SOP)から回答を見つけられるよう支援します。
- カスタマーサポート:エージェントが顧客との通話中に、関連するヘルプ記事や過去のチケット解決事例を迅速に検索できるようにします。マッキンゼーの分析によれば、カスタマーケアワークフローに生成AIを適用することで30~45%の生産性向上が見込まれます。
- 法務・コンプライアンス: 数百万件の契約書、ポリシー、規制文書を意味理解で検索し、特定の条項や判例を見つけ出します
- 研究開発: エンジニアが関連する先行研究、特許、技術文書を効率的に検索できるようにし、重複する努力を回避します
- 人事とオンボーディング:新入社員が自ら回答を見つけられるよう、関連するポリシー、研修資料、ワークフローの例、手順を提示します。
- 営業支援: 営業担当者が適切な事例研究、競合情報、製品情報を見つけ、取引を迅速に成立させるための支援を提供します
効果的な企業検索には、既存のワークフロー管理への統合が不可欠です。単体の検索バーだけでは不十分です。チームはツールを切り替えることなく、情報を見つけ、即座にアクションを起こせる必要があります。
🛠️ ツールキット: チームが実際に活用する社内hubを構築しましょう。ClickUpのナレッジベーステンプレートは、ハウツーから標準業務手順書(SOP)まで、すべての情報を整理し検索しやすくします。これにより、情報の所在を推測する必要がなくなります。

Cohere for 企業検索の設定方法
AI検索の評価から実際の導入へ進むのは、特に大規模言語モデルに不慣れなチームにとっては困難に感じられるかもしれません。
セットアップの複雑さは規模や既存の技術スタックによって異なりますが、Cohereを活用した検索システム構築の核心的なステップは共通しています。本セクションでは技術チームを導く実践的なステップを解説します。
前提条件とAPIアクセス
コードを書く前に、ツールとアクセス権限を整える必要があります。この初期セットアップにより、後々のセキュリティ問題や障害を未然に防げます。
開始に必要なものは以下の通りです:
- Cohere APIアカウント: Cohereウェブサイトでサインアップし、APIキーを取得してください
- 開発環境: 多くのチームはPythonを使用していますが、他の言語用のSDKも利用可能です
- ベクトルデータベース: ドキュメントの埋め込みを保存する場所が必要です。Pinecone、Weaviate、Qdrant、またはAmazon OpenSearchのようなマネージドサービスなどが該当します。
- 文書コーパス: 検索対象とするコンテンツ(例: PDF、テキストファイル、データベースレコード)を収集します。
Amazon Bedrock経由でCohereのモデルを利用することも可能です。AWSエコシステム内で既に業務を行っている企業の場合、これにより課金とセキュリティ管理が簡素化されます。
Cohere Embedで埋め込み生成
次のステップは、文書を検索可能なベクトルに変換することです。このプロセスでは、コンテンツを準備した後、Cohere Embedモデルで処理します。
文書をどのように準備するか、特に小さな単位に分割する方法は、検索品質に多大な影響を与えます。これをチャンキング戦略と呼びます。
一般的なチャンキング戦略には以下が含まれます:
- 固定サイズチャンク: 最もシンプルな方法ですが、文や考えを不自然に途切れさせる可能性があります
- セマンティックチャンキング: 段落やセクションの終わりで分割するなど、文書構造を尊重するより高度な手法
- 重複チャンク: この手法では、チャンク間の境界を越えて文脈を維持するため、チャンク間に少量の重複テキストを含めます。
文書をチャンク処理したら、Embed APIにバッチ処理で送信しベクトル表現を生成します。既存文書では通常この処理は1回限りで、新規または更新された文書は作成時に即時埋め込み処理されます。
📖 詳細はこちら:内部検索エンジンとは? 主要ツールとその仕組み
ベクトルの保存とクエリ
新しく作成したベクトルには保存場所が必要です。ベクトルデータベースは、類似性に基づいて埋め込みを保存・クエリするために設計された特殊なデータベースです。
クエリ処理は次のように機能します:
- ユーザーが検索クエリを入力します
- アプリケーションはそのクエリを同じCohere Embedモデルに送信し、ベクトルに変換します
- そのクエリベクトルはデータベースに送信され、最も類似したドキュメントベクトルを検索します
- データベースは一致する文書を返します。それらをユーザーに表示できます
ベクトルデータベースを選択する際には、使用する類似度メトリクスの選択も検討事項となります。コサイン類似度はテキストベースの検索で最も一般的ですが、異なるユースケース向けに他の選択肢も存在します。
| 類似度メトリクス | 最適: |
|---|---|
| コサイン類似度 | 汎用テキスト検索 |
| 内積 | ベクトルの大きさが重要な場合 |
| ユークリッド距離 | 空間データまたは地理データ |
より良い結果を得るための再ランク付けを実装する
多くのアプリケーションでは、ベクトルデータベースの結果で十分です。しかし、最上位に絶対的な最高の結果を必要とする場合、再ランク付けステップを追加するのが賢明です。
特にRAGシステムを駆動する検索では、生成される回答の品質は取得される文脈の品質に大きく依存するため、この手法が極めて重要です。
再ランク付けのパイプラインはシンプルです:
- ベクトルデータベースからより大規模な初期候補セット(例:上位50件の結果)を取得します
- ユーザーの元のクエリと候補リストをCohere Rerank APIに渡します
- APIは同じドキュメントリストを返しますが、より精度の高い関連性スコアに基づいて再順序付けされます
- 再ランク付けされたリストの上位結果をユーザーに表示します
再ランク付けの効果を測定するには、nDCG(正規化割引累積利得)やMRR(平均逆順位)などのオフライン評価メトリクスを追跡できます。
💫 企業検索機能の実装の概要を視覚的に把握するには、主要な概念と実践的な考慮事項を説明するこのウォークスルーをご覧ください:
Cohereを活用した企業検索のベストプラクティス
検索システムの構築は最初のステップに過ぎません。長期的に品質を維持・向上させることが、成功と失敗を分ける鍵です。ユーザーが数回の悪い体験をすると、信頼を失いツールの使用を中止します。🛠️
成功した企業検索導入事例から得られた教訓を以下に示します:
- ハイブリッド検索から始める: 意味検索だけに頼らないでください。BM25などの従来のキーワード検索アルゴリズムと組み合わせてください。これにより両方の長所を活かせます——意味検索は概念的に関連するアイテムを見つけ、キーワード検索は製品コードや固有名詞の完全一致を確実に検索できます。
- データ品質と衛生管理への投資:検索結果の精度はデータの質に依存します。明確な見出しと段落構成を備えたクリーンで構造化された文書は、はるかに優れた埋め込みベクトルを生成します
- 慎重にチャンク分割:文書をチャンクに分割する方法は極めて重要です。任意の文字リミットを用いる代わりに、段落やセクションなど文書の論理構造に沿ってチャンクを分割してください。
- メタデータによるフィルタリングを追加: 意味検索は強力ですが、ユーザーが既に探しているものを知っている場合もあります。意味検索が開始される前に、日付、部署、文書タイプなどのメタデータで結果をフィルタリングできるようにします。
- 監視と改善:ユーザーが何を検索しているか、どの結果をクリックしているか、どのクエリが結果を返さないかに細心の注意を払ってください。このデータはコンテンツの不足箇所を特定し、システムを改善するための貴重な情報源です。
- エラーを適切に処理する: 完璧な検索システムは存在しません。検索結果が不十分な場合、代替クエリの提案や専門家への通知提供など、有用な代替手段を提供します。
📖 詳細はこちら:パーソナライズド検索:職場の生産性と体験を向上させる
Cohere for 企業検索の制限事項
Cohereは強力なAIモデルを提供しますが、プラグアンドプレイのソリューションではありません(厳密には)。
本番環境対応の企業検索ソリューション構築には、チームがしばしば過小評価しがちな重大な課題が伴います。これらの制約を理解することは、情報に基づいた意思決定を行い、将来的な高額な予期せぬ問題を防ぐために極めて重要です。
最大の問題点は、完成品ではなくツール群を提供されることです。これにより、検索サービスとしての基盤となる周辺インフラ全体の構築と保守が、すべて御社のチームに委ねられることになります。
考慮すべき主なリミットは以下の通りです:
| 課題 | なぜ問題となるのか |
|---|---|
| 専門的な知識が必要です | システムを構築・運用・保守するには、経験豊富なAIエンジニアとデータエンジニアが必要です。これは多くのチームが気軽に設定したり所有したりできるものではありません。 |
| カスタム統合が必要です | モデルは既存ツールに自動接続されません。各データソースは手動で接続・保守する必要があります。 |
| 継続的なメンテナンスが必要 | コンテンツの変更やモデルの更新に伴い、検索インデックスは常に更新されなければならず、継続的な仕事が発生します。 |
| ワークスペースに接続されていません | AIは言語を理解しますが、実際の業務現場には存在しないため、検索と実行の間に断絶が生じています。 |
| コンテキストの切り替えは避けられない | ユーザーは一箇所で情報を見つけ、それを活用するために別のツールに切り替えるため、生産性と導入率が低下します。 |
📖 詳細はこちら:Word & ClickUp対応 Free ナレッジベーステンプレート
ClickUpを企業検索の代替手段として活用する方法
今となっては、そのトレードオフは明らかであるはずです。
企業検索は強力ですが、自社開発にはデータ取り込みパイプライン、チャンキング戦略、埋め込み更新、再ランク付けロジック、継続的なメンテナンスの所有が伴います。これは機能リリースではなく、長期的なインフラ投資です。
世界初の統合型AIワークスペースであるClickUpは、AI搭載検索機能をワークスペース自体にネイティブに組み込むことで、その層全体を排除します。
これが重要なのは、ほとんどの検索課題は本質的に検索問題ではないからです。それらは仕事の分散化問題です。仕事が連携しないツールに分散すると、チームは常に文脈を探し回らざるを得ません。その結果、時間の浪費、努力の重複、そして完全な可視性のない意思決定が生じます。
ClickUpは、仕事・コンテキスト・インテリジェンスを単一のワークスペースに統合することで、この問題を根本から解決します。実際の仕組みを詳しく見ていきましょう。
ClickUp Brainでワークスペース全体から文脈を認識した回答を取得
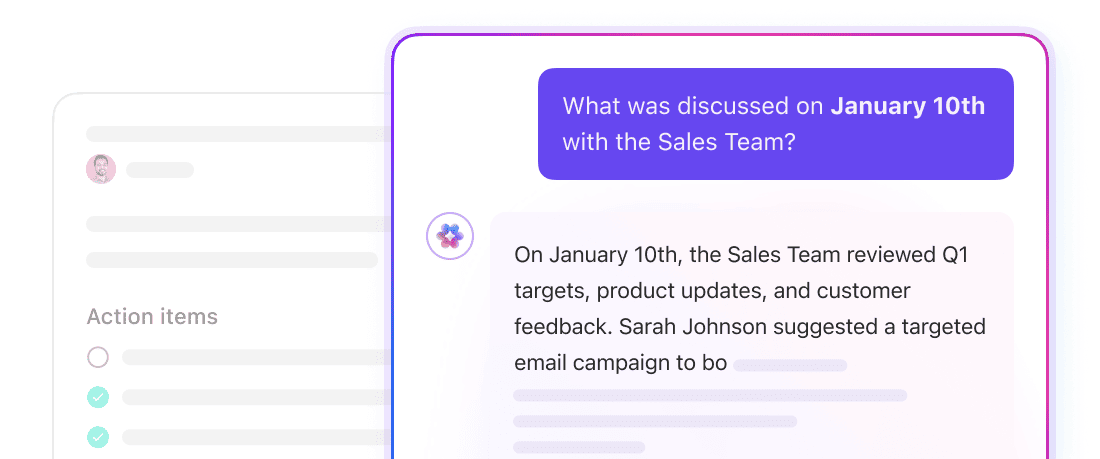
ClickUp Brainは、ワークスペース全体で動作する文脈認識AIレイヤーです。ClickUpタスク、ClickUpドキュメント、ClickUpコメントなど、ワークスペースの基盤構造にアクセスできるため、質問への回答、情報の要約、関連する作業の抽出が可能です。
チャンクサイズの定義や埋め込みデータの管理は不要です。BrainはClickUpのネイティブデータモデルを活用し、情報の接続を理解します。「第4四半期のローンチを阻害している要因は?」といった質問に対し、Brainは当該イニシアチブに関連するタスク、コメント、ドキュメントから文脈を抽出します。
ClickUp Brainは内部で複数のAIモデルをサポートしており、推論・要約・生成など目的に応じて最適なモデルへリクエストを振り分けられます。これにより、ワークフローを単一モデルの制約に縛られることがありません。
外部コンテキストが必要な場合、Brainはワークスペースから直接ウェブ検索を実行し、ClickUpを離れる必要もなく、別のブラウザタブを開く必要もなく、要約された結果を返します。
ClickUp Enterprise Searchで検索、ナビゲーション、実行を
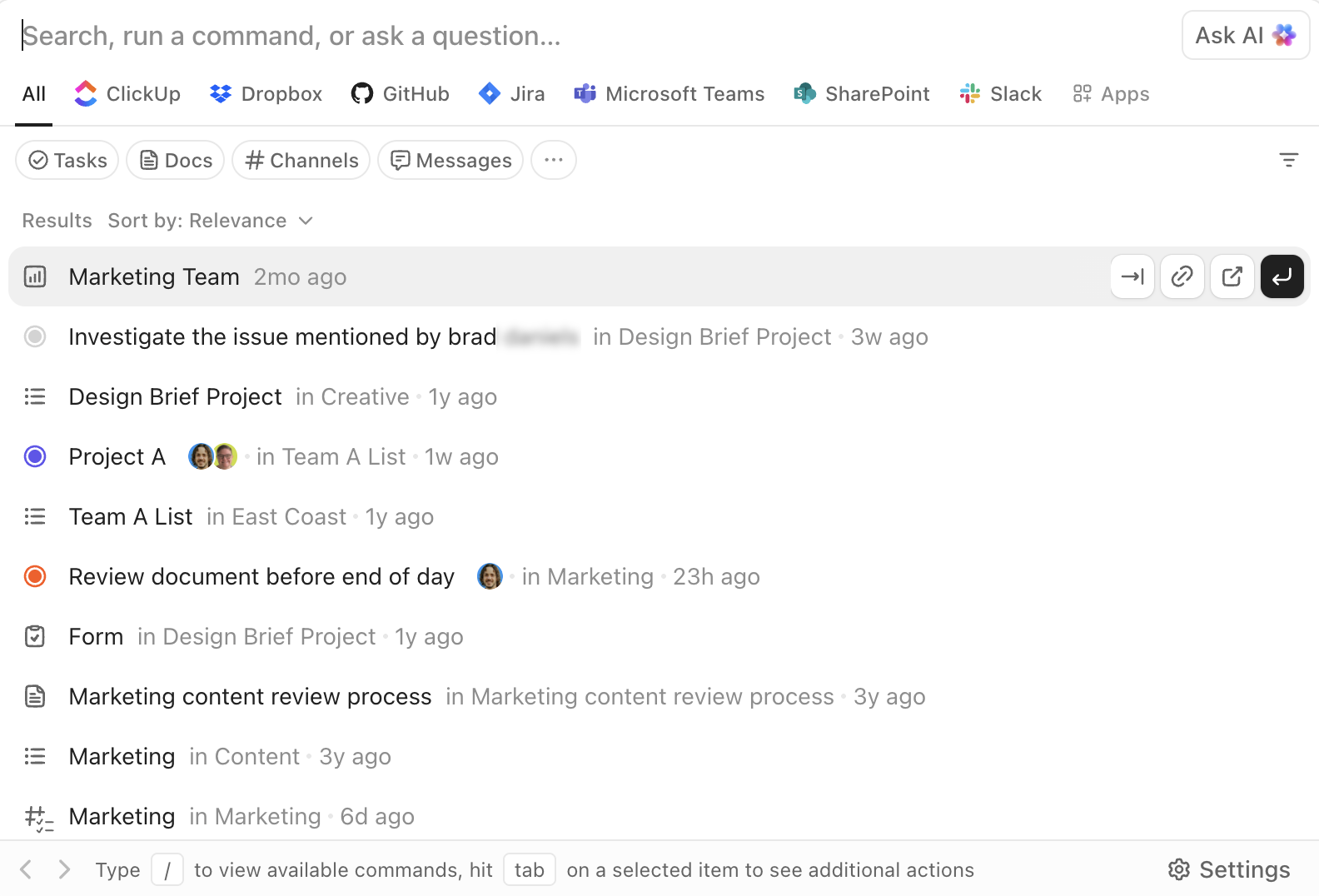
ClickUpのエンタープライズ検索はワークスペース内のどこからでも利用可能です。タスク、ドキュメント、コメント、添付ファイルに加え、Google Drive、Slack、GitHubなど接続済みのサードパーティアプリ(統合状況による)を横断検索できます。
AIコマンドバーは検索を実行レイヤーに変えます。同じインターフェースから直接、アイテムへの移動、タスク作成、ステータス変更、所有者割り当て、特定ビューの表示が可能です。これは単なる「検索して読む」ではなく、「検索して行動する」を実現します。
検索機能がワークスペースUIに組み込まれているため、結果は常にアクション可能な状態です。情報を単独で取得し、別のツールに切り替えて利用する必要はありません。ワークフローはその場で継続します。
ClickUp BrainGPTでツールの乱立を削減
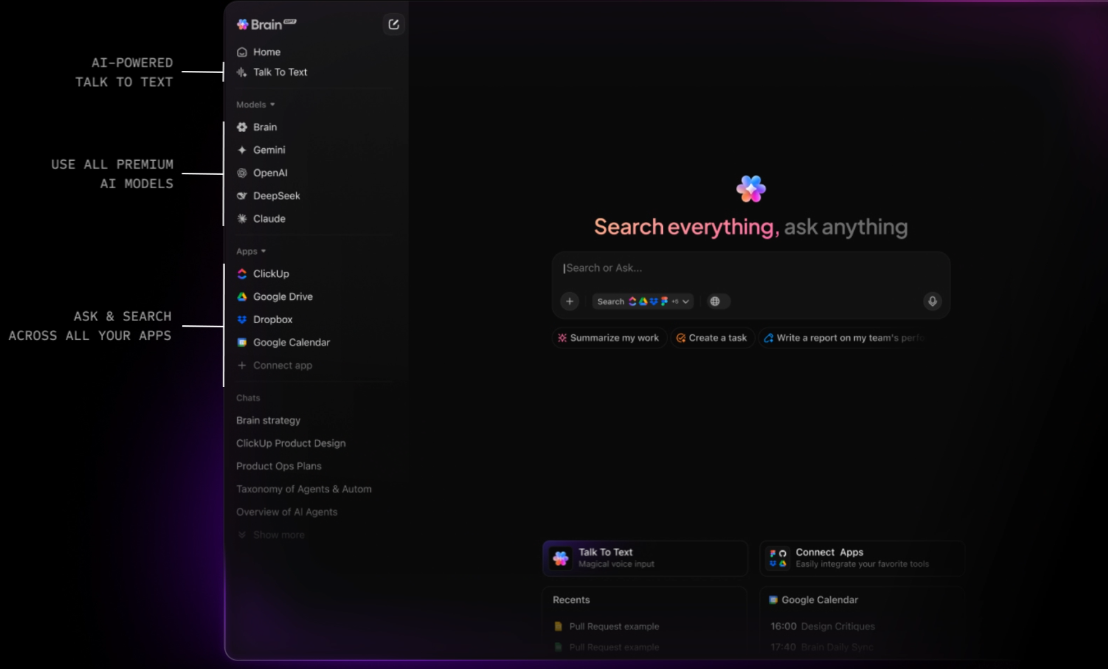
ClickUp BrainGPTは検索機能をブラウザの枠を超えて拡張し、スタンドアロンのデスクトップアプリとChrome拡張機能を提供します。ワークスペースに直接接続し、ClickUpや連携アプリを事前に開く必要なく、同じ文脈理解型インテリジェンスを提示します。
単一のインターフェースから、タスク、ドキュメント、コメント、Gmailやその他の連携ツールを含む接続済みツールを検索できます。音声入力による「Talk-to-Text」機能で、検索の実行や質問の即時記録が可能。特に素早い参照や移動中の仕事に便利です。
管理すべきAI検索製品をさらに追加する代わりに、Brain GPTは既存の仕事環境を理解した単一のインターフェースに検索機能を統合します。
これが真の変革です。ClickUpは企業検索の構築を求めません。この統合ワークスペースは、仕事が行われるシステムに直接組み込むことで、インフラのオーバーヘッドを排除しつつ、パワー、精度、スピードを維持します。
📖 詳細はこちら:主要ナレッジマネジメントシステムの例
特典:カスタム構築とネイティブワークスペースAIの戦略的比較
| 中核の価値 | 最大限の柔軟性;独自の制御 | 実行準備完了;デフォルトでコンテキスト認識機能を搭載 |
| 実装 | 数か月: エンジニアリングチームによるパイプライン構築が必要 | 分単位: ワークスペース全体のワンクリック切り替え |
| データ取り込み | マニュアル:ETLとベクトルデータベースの構築・保守が必要です | 自動化:タスク、ドキュメント、チャットへのリアルタイムアクセス |
| 許可ロジック | 手動でのコード入力が必要(データ漏洩のリスクが高い) | ClickUpの階層をネイティブに継承 |
| 文脈の深さ | セマンティック(意味ベース) | 運用管理(担当者を把握) |
| ユーザーインターフェース | 検索バー/チャットの設計と構築が必要です | 組み込み機能(検索バー、ドキュメント、タスクビュー) |
| ワークフローアクション | なし: ユーザーが情報を見つけ、仕事のためにツールを切り替える | 高:情報を見つけ、即座にタスクに変換する |
| 最適な用途 | 独自ソフトウェアを開発する技術集約型企業 | Teams looking to eliminate “tool sprawl” and act fast |
検索が足かせになるべきではありません!
セマンティック検索はもはや差別化要因ではありません。基本中の基本です。
企業検索の真のコストは他のあらゆる場所に現れます:構築・維持に必要なエンジニアリング時間、精度を維持するためのインフラ、そして検索が実際の仕事が行われるツールの外に存在することで生じる摩擦です。適切な文書を見つけることは、それに対して行動を起こすためにシステムを切り替える必要があるなら、あまり意味がありません。
だからこそ課題は単なる「検索の改善」ではありません。情報と実行の間の隔たりを解消することなのです。
検索機能がワークスペースに直接組み込まれると、文脈はデフォルトで保持されます。回答は単に取得されるだけでなく、即座に活用可能です。タスクの更新、意思決定の記録、仕事の進捗管理が、新たな引き継ぎ作業を発生させることなく行えます。
カスタム検索インフラの構築・維持に数ヶ月を費やしたくないチームにとって、統合型AIワークスペースでの作業は状況を一変させます。ClickUpは、チームが既に計画・協業・実行に使用しているシステムの一部として、エンタープライズグレードのAI搭載検索機能を提供します。
よくある質問
Cohereは検索などの企業ユースケースに特化し、検索タスク向けに設計されたEmbedやRerankといったモデルを提供します。OpenAIはより広範な汎用モデルを提供しており、検索に適応可能ですが、より多くの調整が必要となる場合があります。
はい、Cohereは他のツールとの連携を可能にするAPIを提供しています。ただし、これにはカスタム開発とエンジニアリングリソースが必要です。ClickUpのような代替ツールは、箱から出してすぐに使えるネイティブAI検索を提供し、いかなる連携作業も不要にします。
大規模な非構造化リポジトリを保有する業界(法務、医療、金融サービス、テクノロジー分野など)は、セマンティック検索の恩恵を最も大きく受けます。知識管理に課題を抱えるあらゆる組織で大幅な改善が期待できます。