

ニューラル検索は、現代のチームの仕事のやり方に追いつけない時代遅れのキーワードベースのシステムを急速に置き換えています。データの規模が拡大し、質問が複雑になるにつれ、チームは単語だけでなく意図を理解する検索を必要としています。
では、ニューラル検索とは具体的にどのようなもので、なぜそれが企業チームの情報検索方法を変化させているのでしょうか?
⏰ 60秒でわかるまとめ
文書に埋もれてしまったり、ツール間で正しい情報を探し出すのに苦労していませんか? ニューラル検索が企業チームのゲームをどのように変えているかをご紹介します。
適切な検索ツールを試して、インテリジェントな検索をあなたのワークスペースに取り入れ、時間をかけずに仕事を効率化しましょう。
ニューラルサーチとは?
ニューラル検索は、完璧な表現でなくても質問内容を理解するAI主導の情報検索アプローチです。正確なキーワードを一致させるのではなく、意味を解釈し、文脈に基づいて結果を返します。
これは、人間の言語処理方法と同様に、人工ニューラルネットワークとベクトル検索を使用して検索クエリを処理します。
- 同義語や関連語を自動的に認識
- 単語そのものではなく、その背後にある意図を解釈します。
- ユーザーとのやり取りから学習し、今後の検索結果を改善する
つまり、あなたやあなたのチームは、文書を見つけるために「正しい」キーワードを推測する必要がなくなります。ニューラル検索は、実際の話し方や考え方に適応するため、複雑な非構造化環境において、はるかに効果的です。
従来のキーワードベースの検索との違い
従来のキーワード検索は、正確な用語の一致を探すことで仕事をしていました。 高速ですが、文字通りのものです。 一方、ニューラル検索は、たとえ言葉が正確に一致していなくても、ユーザーが何を伝えようとしているかを理解します。
2つの比較は次の通りです。
| 機能* | キーワードベースの検索 | ニューラル検索 |
| クエリマッチング | 正確なキーワードの一致 | 意図と意味を理解する |
| 同義語の処理 | リミットがあり、多くの場合、手動での設定が必要 | 同義語や関連語を自動的に認識 |
| 言語理解 | 文字どおりおよび構文依存関係 | 文脈を認識し、言語に適応する |
| あいまいなクエリへの応答 | キーワードが明確でない場合、精度が低い | あいまいな表現でも関連性の高い結果を返します。 |
| 検索適応性 | 静的なルール、ハードコードされた関連性 | ユーザーとのやり取りから学習し、時間をかけて改善 |
| 非構造化データへのサポート | リミットがあり、一貫性のない | ドキュメント、メモ、メッセージなどの非構造化データに最適化 |
| テクノロジーベース | ストリングマッチングアルゴリズム | ディープラーニングとベクトルベースのモデル |
| ユーザー体験 | しばしば不完全で、不満の残るもの | 直感的で、人間の思考や検索方法により適合した |
もし貴社のチームがまだキーワードベースの検索に頼っているのであれば、おそらくリミットにぶつかっているでしょう。ニューラル検索は、文字通りの意味を超えて、それらの問題を解決します。
検索におけるディープラーニングとニューラルネットワークの役割
ニューラル検索は単に推測するだけではなく、より優れた学習を行います。その背景には、膨大な量の人間言語で訓練されたディープラーニングモデルがあります。これらのモデルは、キーワードベースのシステムでは再現できない方法で、パターン、リレーションシップ、コンテクストを検出します。
検索システムを向上させる方法をご紹介します。
- 人工ニューラルネットワークは、脳の情報処理方法をシミュレートします。すなわち、言葉、概念、フレーズ間の関係をマップします。
- ディープニューラルネットワークは複数の層で構成され、生データから高度な意味論的な意味を抽出します。
- 機械学習モデルは、ユーザーとのやり取りや進化するクエリからのフィードバックを使用して、これらのネットワークを時間をかけて微調整します。
何千もの文書にまたがる仕事をしている企業チームにとっては、より迅速な発見、ユーザーの意図とのより良い一致、そして無駄な作業の削減を意味します。
たとえ2人のユーザーがまったく異なる方法で同じ質問をしたとしても、ディープラーニングで訓練されたニューラル検索エンジンは、関連性の高い結果を提供することができます。
📌 鍵となる事実:キーワード検索とは異なり、ベクトルベースの類似性により、ニューラル検索では、元の検索用語が文書に含まれていない場合でも、関連する結果を見つけることができます。
ニューラル検索の仕組み
ニューラル検索はユーザーにとっては魔法のように感じられるかもしれませんが、その裏側では、AIモデル、ベクトル埋め込み、インデックス構造のレイヤーによって支えられた、綿密に設計されたプロセスが動いています。
ニューラル検索エンジンがクエリを処理する方法を簡単に説明すると、次のようになります。
- *ユーザーが自然言語クエリを入力します。「新入社員の受け入れに最適なツール」のような漠然としたものから、「契約承認ワークフローテンプレート」のような具体的なものまで、さまざまなクエリが考えられます。
- クエリはベクトル埋め込みに変換されます。クエリをプレーンテキストとして処理するのではなく、システムは事前学習モデルまたは言語モデルを使用して数値ベクトル形式に変換します。これらの埋め込みは、クエリの意味的意味を捉えます。
- 検索エンジンはベクトルとインデックスされたデータを比較します。システム内のすべての文書、メモ、サポートチケットは、取り込み時にすでにベクトルに変換されています。エンジンは、インデックス内のクエリベクトルとドキュメントベクトルの類似性を計算します。
- このモデルは、最も意味的に関連性の高い結果を返します。キーワードに一致するドキュメントを検索するのではなく、意図に沿ったコンテンツを検索します。たとえキーワードが完全に一致していなくても、です。
- ユーザーとのやりとりにより結果が改善されます。 導入されたモデルは、クリック、滞在時間、スキップされた結果などのフィードバックから継続的に学習し、時間の経過とともに将来的な検索結果を改善します。
このプロセス全体はミリ秒単位で完了します。
裏側にあるもの:ニューラル検索を支えるテクノロジー
ニューラル検索を可能にするために、いくつかの先進的なテクノロジーが組み合わさっています。
- ベクトル検索:クエリベクトルとドキュメントベクトルの間の高速な類似度マッチングを可能にする
- テキスト埋め込みモデル:自然言語を緻密なベクトル表現に変換する
- ディープラーニングと機械学習:より正確な結果を得るためにモデルを訓練し、微調整するために使用
- モデルインデックスおよびインジェストパイプライン:リアルタイム検索の準備のために、受信データのインデックス処理を行います。
- 検索システムアーキテクチャ:大量のクエリを低レイテンシでサポートするスケーラブルなレイヤー
ニューラル検索システムは、従来のキーワード検索と意味検索を組み合わせたハイブリッドモデルもサポートしています。これは、精度と再現率が同程度に重要である場合に最適です。
数千件におよぶカスタマーチケット、社内ナレッジベース、クラウド文書など、どのような検索でも、ニューラル検索は結果の質、スピード、関連性を劇的に向上させます。
ニューラルサーチのメリット
チームが適切な文書、ダッシュボード、洞察を見つけられない場合、仕事は滞ってしまいます。ニューラル検索は、大規模で非構造化されたシステムであっても、情報を即座にアクセスできるようにすることで、このボトルネックを解消します。
以下は、それが大規模でロック解除するものです。
- 雑多なデータの高速な検出:サポートチケット、電子メール、製品ドキュメントなど、どのようなものを検索する場合でも、ニューラル検索は、ユーザーが入力した内容だけでなく、ユーザーが何を意味しているのかを理解することで、ノイズを排除します。
- 検索結果の関連性を向上*: 「オンボーディング」という語を含むすべてのドキュメントを呼び出すのではなく、問題を解決するドキュメントを提示
- 自然言語クエリへのサポート*: チームはファイル名や専門用語を覚えておく必要はありません。話し言葉で検索できます。
- ユーザーの行動から継続的に学習:各ユーザーのクエリ、クリック、およびインタラクションがモデルを微調整し、時間の経過とともに結果がより賢明になります。
- チーム全体の生産性向上:エンジニア、アナリスト、法務チームなど、基本的に誰もが、より速く、より少ないやり取りで必要なものを見つけることができます。
また、クロスプラットフォームの検索体験も向上します。APIまたはデータコネクタを介して統合されたシステムでは、ニューラル検索が統一レイヤーとして機能し、クラウドドライブ、CRM、ナレッジベースなどから関連性の高い結果を返します。
検索ボリュームが多い、またはデータソースが膨大であるという課題をお持ちの組織にとって、このアップグレードは非常に重要です。
- 検索時間の短縮
- 洞察の取りこぼしが減少
- より多くの情報を得て、より迅速な意思決定が可能に
ニューラル検索は情報検索を最適化し、組織全体の情報活用方法を改善します。
📖 こちらもご覧ください:検索強化型生成の活用例
ニューラルサーチのユースケース
ニューラル検索はニッチな機能ではなく、業界全体の情報検索、管理、適用方法を再構築するものです。大規模な非構造化データセットを持つシステム全体に導入すると、レガシー検索エンジンがもたらす摩擦が解消されます。
企業レベルの環境における実際の仕事の流れは次の通りです。
Eコマースと製品検索
製品の発見は、その背後にあるシステムによって左右されます。検索エンジンがキーワードに頼っている場合、顧客は、たとえカタログに記載されている場合でも、探しているものを見逃すことがよくあります。
ニューラル検索エンジンは、これを次のように解決します。*
- 「アーチサポート付きの環境にやさしいランニングシューズ」のようなあいまいな意図を含むクエリを解釈し、その属性を持つアイテムを提示します。たとえ正確な用語が製品タイトルに含まれていなくてもです。
- 過去の検索クエリとユーザーのやり取りを活用し、よりパーソナライズされた結果をリアルタイムで返す
- 製品データ、ユーザーレビュー、仕様、メタデータをベクトル埋め込みに自動的にインデックス化し、より高速な意味フィルタリングを実現
これにより、製品化までの時間が短縮され、コンバージョン率が向上します。また、グローバルにスケールアップし、多言語クエリを処理し、手動によるルール更新なしで変化する在庫に適応します。
複数の市場やプラットフォームにわたって製品カタログを管理するチームにとって、ニューラル検索は、常に手動で調整を行う必要性を排除します。
企業知識管理
企業環境では、重要な文書が至る所に存在しています。プロジェクトフォルダ、チケット、社内wiki、PDF、アーカイブされた受信トレイなどです。そして、そのほとんどが構造化されていません。
ニューラル検索を使用した場合:
- チームは、分散したツールから情報を抽出することができます。たとえソースシステムを覚えていなくても。
- 「クライアント固有のSLA例外」のような検索クエリは、ストリングマッチではなく、意味的な関係に基づいて埋もれたドキュメントを浮上させます。
- テキスト埋め込みモデルは、Google DriveやSharePointなどのプラットフォーム上で、長文データを検索可能なベクトルに変換します。
ITリーダーにとっては、これは部族知識への依存関係が低くなり、「どこに…があるか」という社内サポートチケットが減ることを意味します。
その結果、ドキュメントの増加に伴って進化する、検索可能な生きた組織の脳が生まれます。
AI搭載のチャットボットとバーチャルアシスタント
企業向けバーチャルアシスタントは、自然な会話形式の入力に対しては、しばしば機能不全に陥ります。ニューラル検索は、ボットによるデータの解釈と取得方法を変更することで、これを変えます。
その方法とは:
- チャットボットのバックエンドにコンテクスト認識検索機能を直接組み込みます。
- CRM、社内ヘルプデスク、コンプライアンスドキュメントなどのライブデータソースにアシスタントを接続
- 正確な回答を返すために、ニューラルクエリ理解レイヤーを使用します。あらかじめプログラムされた返答ではありません。
固定パスに頼るのではなく、ニューラルネットワークを搭載したボットはリアルタイムで適応します。例えば、「契約締結後にアクセスを更新できますか?」というユーザーからの問い合わせは、たとえそのフレーズがどこにも存在していなくても、正しいポリシー・ドキュメントにルーティングされます。
これによりセルフサービスがより効果的になり、サポートチームへの負担が軽減されます。
ヘルスケアと研究
医療分野における検索は必須であり、むしろ極めて重要です。医師、研究者、アナリストは、臨床メモ、学術研究、患者記録など、さまざまな情報源から迅速かつ正確な情報を取得する必要があります。
*ニューラル検索は、以下によってこれをサポートします。
- ディープニューラルネットワークを使用して、一見明白でない用語間の関係(例えば、「適応外使用」と「代替治療」)を検出する
- 臨床メモ、画像レポート、EHRなどの大量の非構造化データを、統一されたベクトルベースの検索システムにインデックス化する
- 厳密なフォーマットや専門用語を必要とせずに、研究論文、ケーススタディ、データレイク全体で自然言語検索を可能にします。
これにより、診断の精度が向上し、治療プランの策定が加速し、文献レビューに費やす時間を数時間単位で節約できます。研究の設定では、過去の仕事やデータセットの意味的な調査を可能にすることで、発見を促進します。
📖 Read More: AIナレッジベースの構築と最適化方法
ビジネスへのニューラルサーチの導入
キーワードベースの検索からニューラル検索への移行は、組織が情報を取得、接続、活性化する方法における戦略的な転換です。
プラットフォームを評価する場合、既存のシステムにAIを組み込む場合、あるいは企業全体に拡張する場合、関連するツール、統合、トレードオフを理解することが不可欠です。
詳しく見ていきましょう。
人気のAI搭載検索ツールとプラットフォーム
現在、複数の主要プラットフォームがニューラル検索のビルトインサポートを提供しており、それぞれが異なる企業のニーズに合わせて最適化されています。
- Elasticsearch + kNN:人気の検索エンジンにベクトル検索機能を追加し、従来のキーワードと意味的関連性を組み合わせたハイブリッドモデルに役立つ
- ニューラルプラグイン付きOpenSearch:オープンソースでモジュール式、PyTorch/Hugging Faceとの統合をサポートし、カスタムニューラル検索パイプラインを実現
- Pinecone:リアルタイムのパフォーマンスで大規模な意味検索インデックスを処理する管理ベクトルデータベース
- Weaviate:テキストと画像の埋め込みをネイティブサポートするオープンソースエンジン。設定が迅速で、生産環境でも柔軟性が高い。
- Vespa: リアルタイム検索およびレコメンデーションシステム向けに構築され、大規模なクエリ処理とパーソナライゼーションをサポート
これらのプラットフォームは、ベクトル検索、インデックス作成、意味マッチング、ハイブリッドクエリ処理などのビルディングブロックを提供していますが、専用のインフラセットアップと継続的なMLオペレーションのサポートが必要になることがよくあります。
ClickUpのニューラル検索における役割
ClickUpは、職場におけるニューラル検索のあり方を再定義します。バックエンドツールとして機能するのではなく、インテリジェント検索をワークフローに直接組み込みます。AIを搭載し、プラットフォーム間の接続を可能にし、チームの動きをより速く、摩擦を少なくします。
ClickUpがこれをどのように実現しているのか、その方法をご紹介します。
AIによる理解と検索
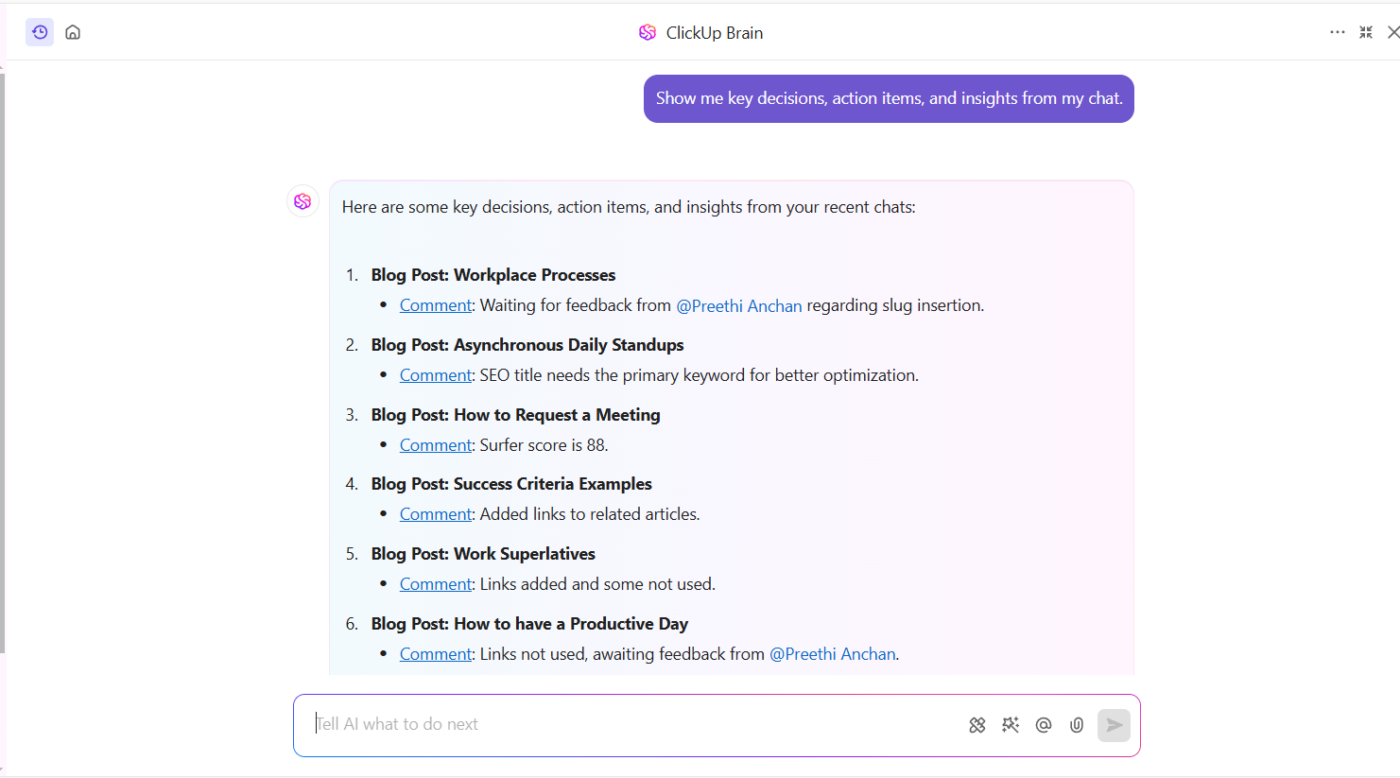
ClickUp Brainは、高度なニューラル検索技術を使用して自然言語入力を理解し、正確なキーワードに頼らずに、文脈を考慮した正確な結果を返します。
「四半期ごとのプランニングタイムライン」や「オンボーディングドキュメントの更新」など、誰かが入力すると、ClickUp Brainが意図を解釈し、タスク、ドキュメント、会話の中から最も関連性の高いコンテンツを提示します。
ユーザーとのやり取りから継続的に学習するため、結果は時間の経過とともに賢くなり、お客様のチームのコミュニケーション方法に適応します。
クロスプラットフォームのセマンティック検索
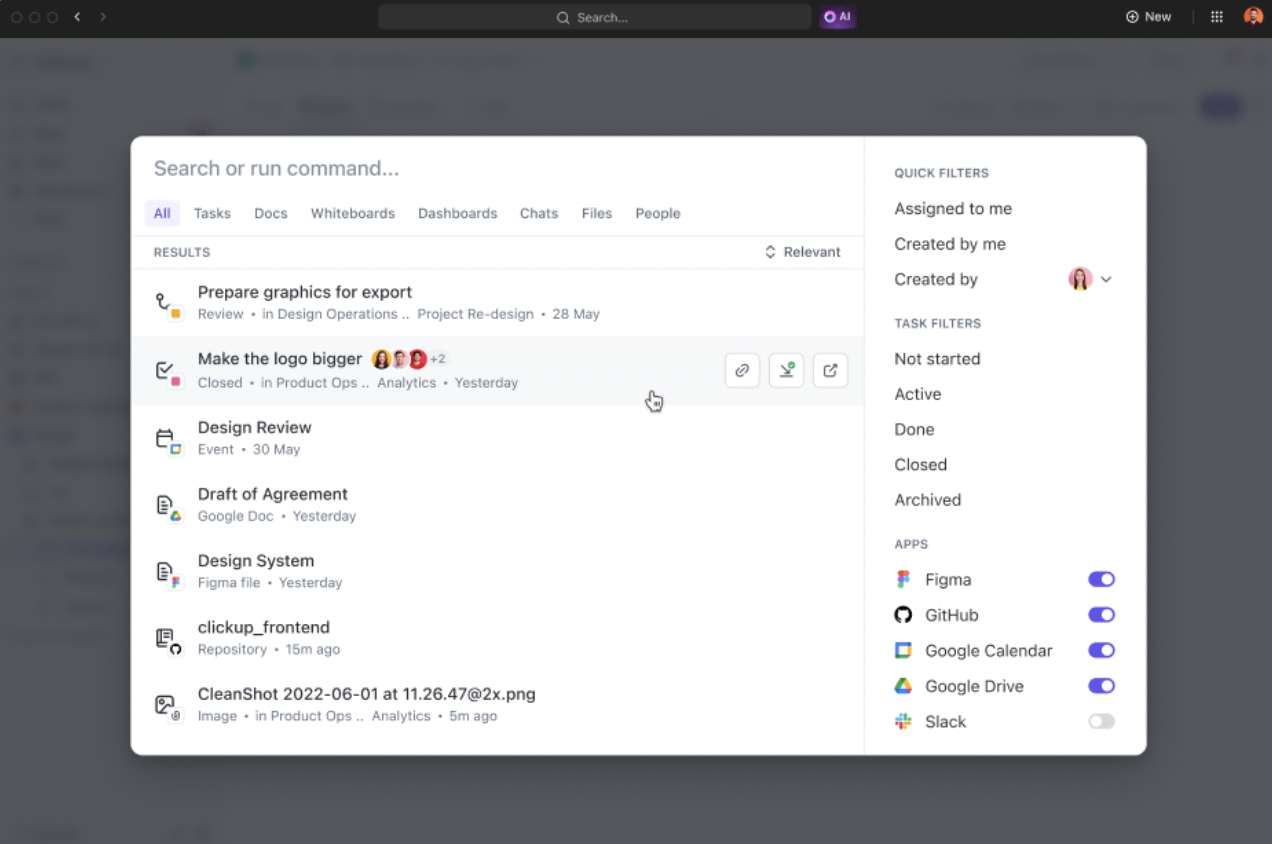
ClickUp 接続検索を使用すると、Google Drive や Dropbox などの複数のプラットフォームを単一の統合インターフェースから横断的に検索できます。 裏側では、ニューラル検索モデルが意味を分析し、表現が保存されているものと異なっていても、適切なファイル、メモ、またはチケットを提供します。
これにより、Connected Searchは真の生産性向上ツールとなります。
- タブやツールを切り替える必要はもうありません。
- ファイル名やフォルダパスを覚えておく必要はありません。
- すべてが1か所で、高速に検索できます。
これは、ニューラル検索を強力にするだけでなく、すべてのチームが利用できるようにするというClickUpの革新的なステップです。
企業向けツールとのシームレスな統合
企業環境は多数のプラットフォームによって支えられており、ニューラル検索は全体像にアクセスできる場合にのみ機能します。ClickUpの統合機能は、CRM、プロジェクトツール、クラウドドライブ、サポートシステムからのコンテンツをClickUpワークスペースに直接同期することで、これを可能にします。
これにより、以下が可能になります。
- 企業向けツールのリアルタイムインデックス
- 一貫したアクセス制御とデータの完全性
- これまでサイロ化されていたシステム全体における真実の単一ソース
ニューラル検索を最上位に重ねることで、チームは手動での同期を必要とせずに、組織全体からコンテンツをミリ秒単位で取得することができます。
📮ClickUp Insight:92%のナレッジワーカーが、チャット、電子メール、スプレッドシートに散在する重要な意思決定を失うリスクにさらされています。意思決定を記録し追跡するための統一されたシステムがなければ、重要なビジネス上の洞察はデジタルノイズの中に埋もれてしまいます。
ClickUpのタスク管理機能を使えば、そんな心配は無用です。チャット、タスクのコメント、ドキュメント、電子メールから、ワンクリックでタスクを作成できます!
洞察をアクションに変える
検索がワークフローの終わりであってはなりません。ClickUpの自動化機能は、ニューラル検索の結果を即座にインテリジェントなアクションに接続します。
例えば:
- ユーザーが検索している内容に基づいてタスクに自動的にタグ付け
- AIが意図を検出した結果に基づいて、チケットやリクエストを適切なチームに振り分ける
- アクティブな仕事中に関連アイテムを表示し、より迅速なコンテクストの切り替えを実現
チームは余計なステップを踏むことなく、「見つけた」から「すでに処理済み」へと進むことができます。ClickUpは、情報を探しやすくするだけでなく、より使いやすく、行動しやすく、そこから学べるようにします。
📖 Read More: Top AI Workflow Automation Tools
ニューラル検索を既存のシステムに統合する方法
ニューラル検索を採用するためにインフラを全面的に見直す必要はありません。ほとんどのチームは、既存のシステムに最小限の混乱で重ね合わせています。鍵となるのは、インテリジェンスをどこに挿入するか、そしてそれを裏でどのようにサポートするかを知ることです。
今後の進むべき現実的な道筋は次の通りです。
- 既存の検索フローを監査する:ユーザーが現在どのように検索しているか、どのようなツールを使用しているか、キーワードベースの検索がどこで不十分になるかを地図に表す
- 解釈のためのニューラルレイヤーを追加する:インデックスされたコンテンツと照合する前に、クエリを言語モデルまたは埋め込みエンジンに通します。
- ベクトルデータベースを選択する:FAISS、Pinecone、Weaviateなどのツールを使用して、埋め込みを保存および取得します。規模とレイテンシ要件に応じて選択してください。
- インデックス化が重要な非構造化データ:PDF、チャット、チケット、ドキュメントを埋め込みパイプラインに取り込みます。これらは通常、最も価値が活用されていないものです。
- 従来のロジックとの融合:精度が重要なユースケースでは、ハイブリッドモデル(意味 + キーワード)が、再現率と制御のバランスを最適化します。
- 監視と適応:検索品質、クエリパフォーマンス、システムフィードバックを追跡し、しきい値を微調整し、時間をかけてモデルを再トレーニングする
ニューラル検索は、既存のアーキテクチャに適合する場合に最も効果を発揮し、既存のアーキテクチャを置き換えようとする場合には効果を発揮しません。
📖 もっと読む:ニューラルネットワークソフトウェアの総合ガイド
導入にあたっての課題と考慮事項
ニューラル検索は、よりスマートで高速な情報へのアクセスをロック解除しますが、導入は単に新しいモデルを接続するだけではありません。新しい技術的、運用上、組織上の考慮事項が導入されるため、綿密なプランニングが必要です。
企業チームが考慮すべき事項は以下の通りです。
データの準備は自動的には行われません。
ニューラルモデルは、その背後にあるデータに依存します。データに一貫性がなかったり、断片化されていたり、許可制でロックされていたりすると、意味的な正確性が損なわれます。
- クリーンで構造化されたデータは埋め込み品質を向上させます。
- 構造化されていないコンテンツは、文脈を失うことなくインデックス化できるようにしなければなりません。
- システムとチーム全体でアクセス制御を尊重する必要があります。
データの整合性がなければ、どんなに優れたモデルでもノイズを返すことになります。
モデルの選択はすべてに影響する
誤ったモデルを選択したり、過剰なエンジニアリングを行ったりすると、導入が失敗する可能性があります。
- 事前学習済みのモデルは一般的な用途には適しているが、分野特有のニュアンスを捉え損なう可能性がある。
- 微調整されたモデルは精度を提供するが、より多くのデータと努力が必要となる。
- コンテンツや用語の変更を反映させるために、継続的なモデル更新が必要になる場合があります。
これは一度きりの設定ではなく、チューニングが必要な生きたシステムです。
インフラは成功とともに拡張を求められる
利用が増えるにつれ、コンピューティング、ストレージ、レイテンシの需要も増大します。
- ベクトルデータベースは、大規模かつ低レイテンシのクエリを処理できなければなりません。
- 組み込みパイプラインは、リアルタイムで最新の状態に保つ必要があります。
- ユーザーの増加に伴い、クエリ量が予測不能に急増する可能性があります。
チームは、部門や地域をまたいで拡張する際に、パフォーマンスとコストのバランスを取る必要があります。
期待値と説明可能性
ニューラル検索は、すべてのユーザー(または利害関係者)が対応できるレベルの抽象化を導入しています。
- 関連性は向上するかもしれませんが、結果の背後にある「理由」は常に明白であるとは限りません。
- ハイブリッドモデル(意味 + キーワード)は、必要に応じてより優れた説明能力を提供します。
- コンプライアンスや法務など、一部のユースケースでは、結果のロジックを透明化する必要がある場合があります。
特に、リスクの高い環境や規制の厳しい環境では、事前に適切な期待値を設定することが鍵となります。
ニューラル検索は、すぐに使える解決策ではありません。しかし、基盤に投資する意欲のあるチームにとっては、その見返りは非常に大きなものとなります。より賢いシステム、より迅速な発見、そして人々と彼らが頼りにするデータ間のより良い連携が実現します。
📖 続きを読む:情報検索システムでデータ管理を強化
ニューラル検索の未来
ニューラル検索はもはやイノベーションのレイヤーではなく、企業インテリジェンスの中核となるインフラになりつつあります。次に起こるのは機能ではなく、戦略的な活用です。
企業ITリーダーが注目し、構築すべきものは次のとおりです。
- 検索はより先を見越したものになります:誰かがクエリを入力しなくても、役割、タスク、タイミングに基づいて結果が提示されます。
- 検索結果は意思決定システムにフィードされます:ニューラル検索は文書を単に引き出すだけではなく、洞察をダッシュボード、チケット、レポート作成に直接反映します。
- 綿密に調整されたモデルが成功を定義する:社内データでモデルを訓練するチームは、汎用APIに依存するチームよりも優れた成果を上げることができるでしょう。
- 知識はストレージよりもアクセスを優先します:サイロ化された文書は、保存場所に関係なく検索可能になります。
- 検索は情報を提供するだけでなく、行動を起こします。* 検索結果は自動化のトリガーとなり、次のステップの提案、タスクの割り当て、または障害の特定をリアルタイムで行います。
- インフラは参照からインテリジェンスへとシフトする:ニューラル検索は、拡張性のある接続された意思決定の基盤となる
未来は、より良い検索を追求することではありません。正しい情報が常に手に入るため、検索が目に見えなくなるようなシステムを構築することなのです。
📚 おもしろ読み:AIを日常的なタスクに活用するには?
チームの情報検索方法を見直してみませんか?
Neural searchは、チームの仕事、意思決定、コラボレーションの方法を大きく変えます。データポイント間の関係を理解するベクトル検索を促進します。キーワードマッチングに基づく従来の検索方法よりもはるかに優れています。
データが増大し、ワークフローが複雑になるにつれ、文脈に沿った適切な情報を引き出す能力は、真の競争優位性となります。最も賢いチームは、単に検索を改善するだけでなく、検索そのものを不要にします。
ClickUpは、AIによる検索結果をワークフローに直接組み込むことで、ニューラル検索を最適化し、チームがプラットフォームを問わず関連情報に迅速にアクセスできるようにします。 企業向けツールとのシームレスな統合により、生産性がさらに向上し、重要な洞察が簡単に実行可能なタスクに変換されるようになります。
今すぐClickUpを試して、インテリジェント検索が本当に何ができるか見てみましょう。