
La plupart des équipes qui explorent les modèles d'IA open source découvrent que LLaMA de Meta offre une combinaison rare de puissance et de flexibilité, mais l'installation technique peut s'apparenter à l'assemblage d'un meuble sans notice.
Ce guide vous explique comment créer un chatbot LLaMA fonctionnel à partir de zéro, en couvrant tout, des exigences matérielles et de l'accès au modèle à l'ingénierie des invites et aux stratégies de déploiement.
C'est parti !
Qu'est-ce que LLaMA et pourquoi l'utiliser pour les chatbots ?
Créer un chatbot avec des API propriétaires donne souvent l'impression d'être prisonnier du système de quelqu'un d'autre, confronté à des coûts imprévisibles et à des questions de confidentialité des données. Cette dépendance vis-à-vis d'un fournisseur signifie que vous ne pouvez pas vraiment personnaliser le modèle en fonction des besoins spécifiques de votre équipe, ce qui conduit à des réponses génériques et à d'éventuels problèmes de conformité.
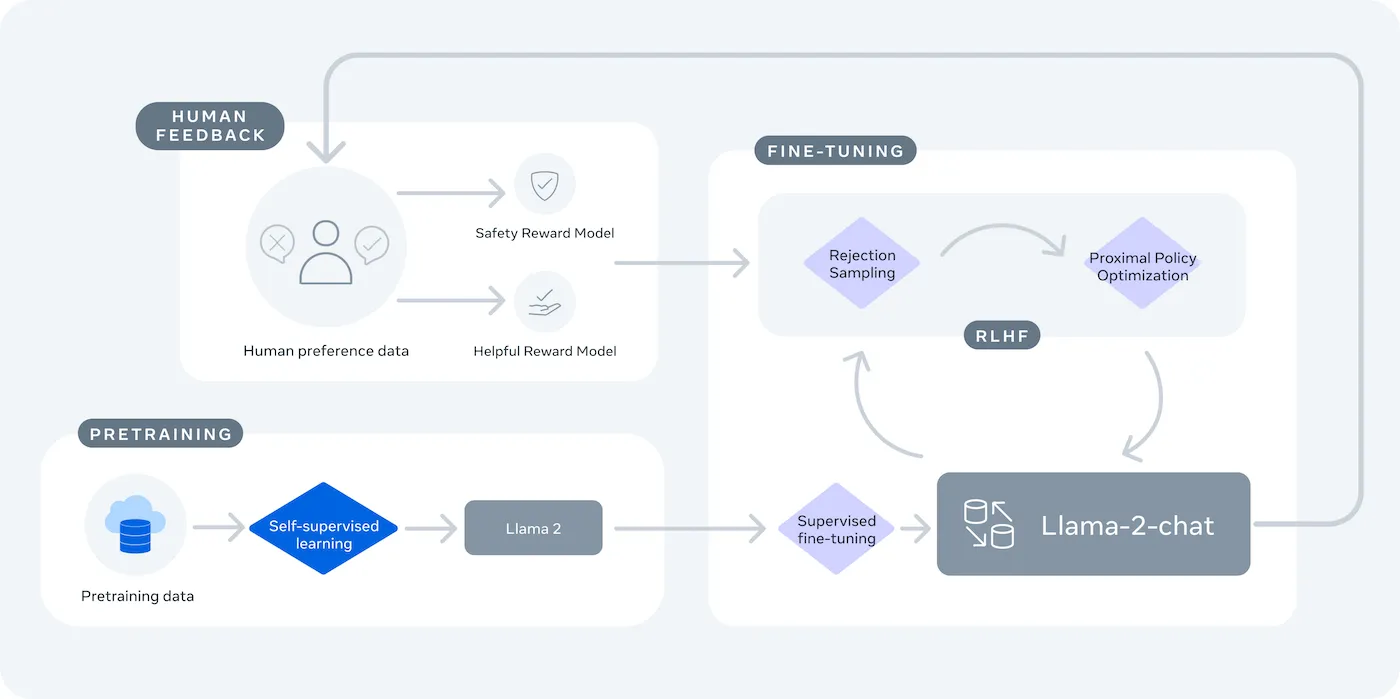
LLaMA (Large Language Model Meta IA) est la famille de modèles linguistiques ouverts de Meta, qui offre une alternative puissante. Conçue à la fois pour la recherche et l'utilisation commerciale, elle vous offre un contrôle que les modèles à code source fermé ne vous permettent pas.
Les modèles LLaMA sont disponibles en différentes tailles, mesurées en paramètres (par exemple, 7B, 13B, 70B). Considérez les paramètres comme une mesure de la complexité et de la puissance du modèle : les modèles plus grands sont plus performants, mais nécessitent davantage de ressources informatiques.
Voici pourquoi vous pourriez utiliser un chatbot LLaMA :
- Confidentialité des données : lorsque vous exécutez un modèle sur votre propre infrastructure, vos données de discussion ne quittent jamais votre environnement. Ceci est essentiel pour les équipes qui traitent des informations sensibles.
- Personnalisation: vous pouvez affiner un modèle LLaMA à partir des documents ou des données internes de votre entreprise. Cela lui permet de comprendre votre contexte spécifique et de fournir des réponses beaucoup plus pertinentes.
- Prévisibilité des coûts : après l'installation initiale du matériel, vous n'avez plus à vous soucier des frais d'API par jeton. Vos coûts deviennent fixes et prévisibles.
- Aucune limite de fréquence : la capacité de votre chatbot est limitée par votre propre matériel, et non par les quotas d'un fournisseur. Vous pouvez l'adapter selon vos besoins.
Le principal compromis est la commodité au profit du contrôle. LLaMA nécessite une installation plus technique qu'une API plug-and-play. Pour les chatbots de production, les équipes utilisent généralement LLaMA 2 ou la nouvelle version LLaMA 3, qui offre un raisonnement amélioré et peut traiter plus de texte à la fois.
Ce dont vous avez besoin avant de créer un chatbot LLaMA
Se lancer dans un projet de développement sans les outils adéquats est la recette idéale pour se frustrer. Vous arrivez à mi-chemin et vous vous rendez compte qu'il vous manque un élément clé du matériel ou de l'accès au logiciel, ce qui fait dérailler votre progression et vous fait perdre des heures de votre temps.
Pour éviter cela, rassemblez tout ce dont vous avez besoin à l'avance. Voici une checklist pour vous assurer un démarrage en douceur. 🛠️
Configuration matérielle requise
| Taille du modèle | VRAM minimale | Option alternative |
|---|---|---|
| 7 milliards de paramètres | 8 Go | Instance GPU cloud |
| 13 milliards de paramètres | 16 Go | Instance GPU cloud |
| 70 milliards de paramètres | Plusieurs GPU | Quantification ou cloud |
Si votre ordinateur local ne dispose pas d'un processeur graphique (GPU) suffisamment puissant, vous pouvez utiliser des services cloud tels que AWS ou GCP. Les plateformes d'inférence telles que Baseten et Replicate offrent également un accès GPU à la carte.
Configuration logicielle requise
- Python 3. 8+ : il s'agit du langage de programmation standard pour les projets d'apprentissage automatique.
- Gestionnaire de paquets : vous aurez besoin de pip ou de Conda pour installer les bibliothèques nécessaires à votre projet.
- Environnement virtuel : il s'agit d'une bonne pratique qui permet d'isoler les dépendances de votre projet des autres projets Python sur votre machine.
Conditions d'accès
- Compte Hugging Face : vous aurez besoin d'un compte pour télécharger les poids du modèle LLaMA.
- Approbation Meta : vous devez accepter le contrat de licence de Meta pour accéder aux modèles LLaMA, qui est généralement approuvé en quelques heures.
- Clés API : elles ne sont nécessaires que si vous décidez d'utiliser un point de terminaison d'inférence hébergé au lieu d'exécuter le modèle localement.
Pour ce guide, nous utiliserons le framework LangChain. Il simplifie de nombreux aspects complexes de la création d'un chatbot, tels que la gestion des invites et de l'historique des discussions.
{kind=link}
Comment créer un chatbot avec LLaMA étape par étape
Relier tous les éléments techniques d'un chatbot (le modèle, l'invite, la mémoire) peut sembler fastidieux. Il est facile de se perdre dans le code, ce qui entraîne des bugs et un chatbot qui ne fonctionne pas comme prévu. Ce guide étape par étape décompose le processus en parties simples et gérables.
Cette approche fonctionne que vous exécutiez le modèle sur votre propre machine ou que vous utilisiez un service hébergé.
Étape 1 : Installez les paquets requis
Vous devez d'abord installer les bibliothèques Python de base. Ouvrez votre terminal et exécutez cette commande :
pip install langchain transformers accelerate torch
Si vous utilisez un service hébergé tel que Baseten pour l'inférence, vous devrez également installer son kit de développement logiciel (SDK) spécifique :
pip install baseten
Voici ce que chacun de ces forfaits propose à faire :
- Langchain : un framework qui aide à créer des applications avec des modèles linguistiques volumineux, notamment la gestion des chaînes de discussion et de la mémoire.
- Transformers : la bibliothèque Hugging Face pour charger et exécuter le modèle LLaMA.
- Accelerate : une bibliothèque qui aide à optimiser le chargement du modèle sur votre CPU et votre GPU.
- Torch : la bibliothèque PyTorch, qui fournit la puissance backend nécessaire aux calculs du modèle.
Si vous exécutez le modèle localement sur une machine équipée d'un GPU NVIDIA, assurez-vous que CUDA est correctement installé et configuré. Cela permet au modèle d'utiliser le GPU pour des performances beaucoup plus rapides.
Étape 2 : Accédez aux modèles LLaMA
Avant de pouvoir télécharger le modèle, vous devez obtenir un accès officiel auprès de Meta via Hugging Face.
- Créez un compte sur huggingface.co
- Accédez à la page du modèle, par exemple meta-llama/Llama-2-7b-chat-hf.
- Cliquez sur « Accéder au référentiel » et acceptez les conditions de licence de Meta.
- Dans les paramètres de votre compte Hugging Face, générez un nouveau jeton d'accès.
- Dans votre terminal, exécutez huggingface-cli login et collez votre jeton pour effectuer l'authentification de votre machine.
L'approbation est généralement rapide. Veillez à choisir une variante de modèle dont le nom comporte le mot « chat », car celles-ci ont été spécialement formées pour les tâches de discussion.
Étape 3 : Chargez le modèle LLaMA
Vous pouvez désormais charger le modèle dans votre code. Vous disposez de deux options principales en fonction de votre matériel.
Si vous disposez d'un GPU suffisamment puissant, vous pouvez charger le modèle localement :
Si votre matériel est limité, vous pouvez utiliser un service d'inférence hébergé :
La commande device_map="auto" indique à la bibliothèque transformers de réaliser automatiquement la distribution du modèle sur tous les GPU disponibles.
Si vous manquez toujours de mémoire, vous pouvez utiliser une technique appelée quantification pour réduire la taille du modèle, même si cela peut légèrement réduire ses performances.
Étape 4 : Créez un modèle de message
Les modèles de chat LLaMA sont entraînés à attendre un format spécifique pour les invites. Un modèle d'invite garantit que votre saisie est correctement structurée.
Décomposons ce format :
- <
> : cette section contient l'invite système, qui donne au modèle ses instructions de base et définit sa personnalité. - [INST] : marque le début de la question ou de l'instruction de l'utilisateur.
- [/INST] : cela indique au modèle qu'il est temps de générer une réponse.
N'oubliez pas que les différentes versions de LLaMA peuvent utiliser des modèles légèrement différents. Vérifiez toujours la documentation du modèle sur Hugging Face pour connaître le format correct.
Étape 5 : Configurez la chaîne de chatbots
Ensuite, vous effectuerez la connexion entre votre modèle et votre modèle de prompt à une chaîne conversationnelle à l'aide de LangChain. Cette chaîne comprendra également une mémoire pour assurer le suivi de la discussion.
LangChain propose plusieurs types de mémoire :
- ConversationBufferMemory : Il s'agit de l'option la plus simple. Elle stocke l'historique complet des discussions.
- ConversationSummaryMemory : pour gagner de l'espace, cette option résume périodiquement les parties les plus anciennes de la discussion.
- ConversationBufferWindowMemory : cette fonctionnalité ne conserve que les derniers échanges en mémoire, ce qui est utile pour éviter que le contexte ne devienne trop long.
Pour les tests, ConversationBufferMemory est un excellent point de départ.
Étape 6 : Exécutez la boucle du chatbot
Enfin, vous pouvez créer une boucle simple pour interagir avec votre chatbot depuis le terminal.
Dans une application réelle, vous remplaceriez cette boucle par un point de terminaison API à l'aide d'un framework tel que FastAPI ou Flask. Vous pouvez également renvoyer la réponse du modèle à l'utilisateur, ce qui rend le chatbot beaucoup plus rapide.
Vous pouvez également ajuster des paramètres tels que la température pour contrôler le caractère aléatoire des réponses. Une température basse (par exemple 0,2) rend le résultat plus déterministe et factuel, tandis qu'une température plus élevée (par exemple 0,8) favorise davantage la créativité.
📚 À lire également : Agent IA ou chatbot : principales différences et lequel vous convient le mieux ?
Comment tester votre chatbot LLaMA
Vous avez créé un chatbot qui fournit des réponses, mais est-il prêt pour les utilisateurs réels ? Le déploiement d'un bot non testé peut entraîner des échecs embarrassants, comme la fourniture d'informations incorrectes ou la génération de contenu inapproprié, ce qui peut nuire à la réputation de votre entreprise.
Un plan de test systématique est la solution à cette incertitude. Il garantit la robustesse, la fiabilité et la sécurité de votre chatbot.
Tests fonctionnels :
- Cas limites : testez la manière dont le bot gère les entrées vides, les messages très longs et les caractères spéciaux.
- Vérification de la mémoire : assurez-vous que le chatbot mémorise le contexte tout au long d'une discussion comportant plusieurs tours de parole.
- Suivi des instructions : vérifiez si le bot respecte les règles que vous avez définies dans l'invite du système.
Évaluation de la qualité :
- Pertinence : la réponse répond-elle réellement à la question de l'utilisateur ?
- Précision : les informations fournies sont-elles correctes ?
- Cohérence : la discussion se déroule-t-elle de manière logique ?
- Sécurité : le bot refuse-t-il de répondre aux demandes inappropriées ou nuisibles ?
Tests de performance :
- Latence: mesurez le temps nécessaire au bot pour commencer à répondre et terminer sa réponse.
- Utilisation des ressources: surveillez la quantité de mémoire GPU utilisée par le modèle pendant l'inférence.
- Concurrence : testez les performances du système lorsque plusieurs utilisateurs interagissent simultanément avec lui.
Faites également attention aux problèmes courants liés aux LLM, tels que les hallucinations (affirmation avec certitude d'informations fausses), la dérive contextuelle (perte de fil conducteur dans une longue discussion) et les répétitions. L'enregistrement de toutes les discussions testées est un excellent moyen de repérer les schémas récurrents et de corriger les problèmes avant qu'ils n'atteignent vos utilisateurs.
📚 À lire également : La différence entre les tests fonctionnels et les tests non fonctionnels
Cas d'utilisation du chatbot LLaMA pour les équipes
Une fois que vous avez dépassé les aspects techniques du réglage et du déploiement, LLaMA devient particulièrement utile lorsqu'il est appliqué aux problèmes quotidiens des équipes, et non à des démonstrations abstraites d'IA. En général, les équipes n'ont pas besoin d'un « chatbot », mais d'un accès plus rapide aux connaissances, de moins de transferts manuels et de moins de travail répétitif.
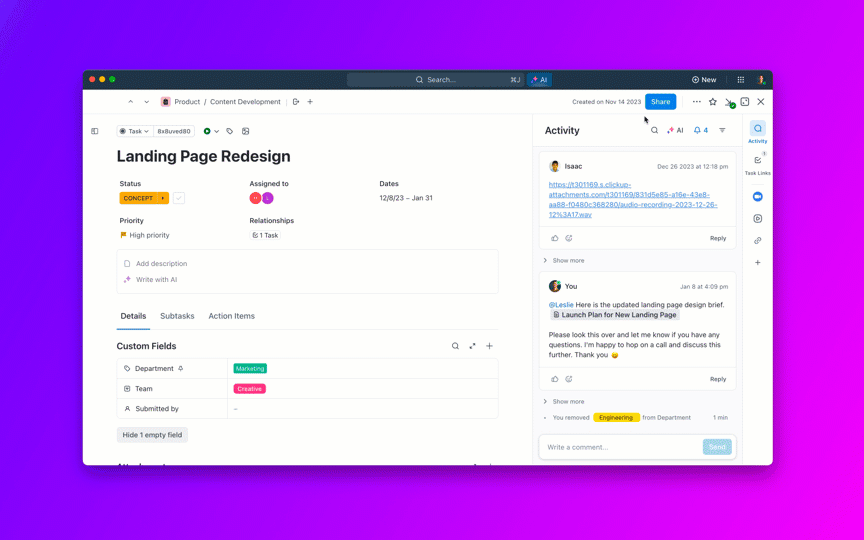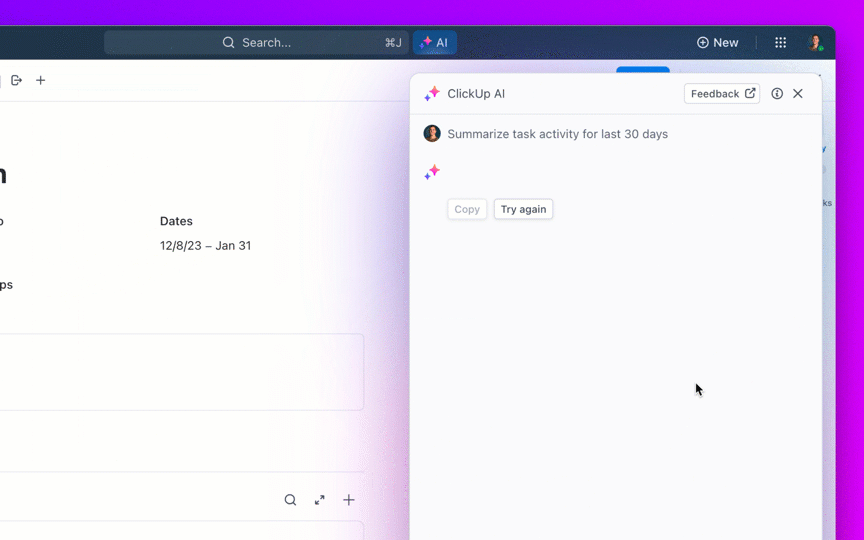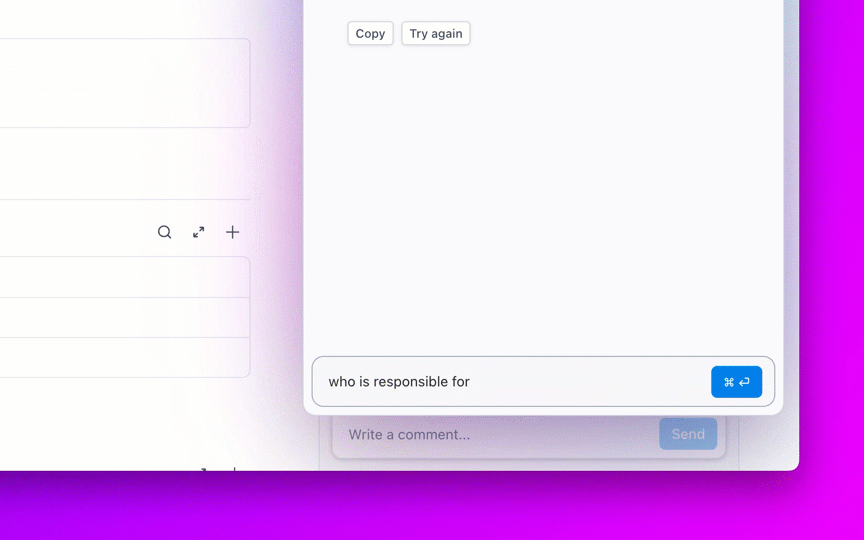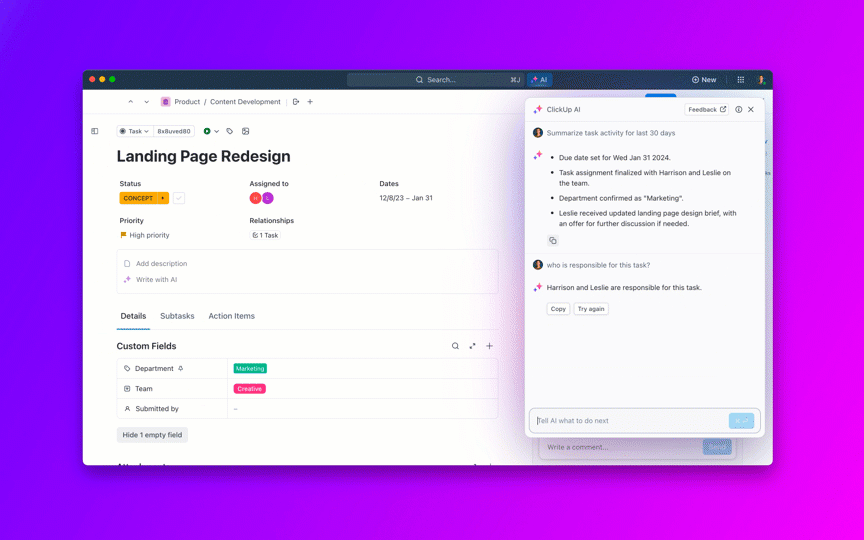
Assistant de connaissances interne
En affinant LLaMA à partir de la documentation interne, des wikis et des FAQ, ou en l'associant à une base de connaissances basée sur RAG, les équipes peuvent poser des questions en langage naturel et obtenir des réponses précises et adaptées au contexte. Cela élimine les frictions liées à la recherche dans des outils dispersés tout en conservant les données sensibles en interne, plutôt que de les envoyer à des API tierces.
🌟 La recherche d'entreprise dans ClickUp et l'agent Ambient Answers préconfiguré fournissent des réponses contextuelles détaillées à vos questions en utilisant les connaissances disponibles dans votre environnement de travail ClickUp.
Assistant de révision de code
Une fois formé à partir de votre propre base de code et de vos guides de style, LLaMA peut agir comme un assistant de révision de code contextuel. Au lieu de bonnes pratiques génériques, les développeurs obtiennent des suggestions qui correspondent aux conventions de l'équipe, aux décisions architecturales et aux modèles historiques.
🌟 Un assistant de révision de code basé sur LLaMA peut mettre en évidence des problèmes, suggérer des améliorations ou expliquer du code inconnu. Codegen de ClickUp va encore plus loin en agissant au sein même du flux de travail de développement : il crée des demandes de tirage, applique des refactorisations ou met à jour des fichiers directement en réponse à ces informations. Le résultat est moins de copier-coller et moins de ruptures entre la « réflexion » et « l'action ».
Triage du service client d'assistance
LLaMA peut être formé à la classification des intentions afin de comprendre les requêtes des clients et de les acheminer vers la bonne équipe ou le bon flux de travail. Les questions courantes peuvent être traitées automatiquement, tandis que les cas particuliers sont transmis à des agents humains avec le contexte joint, ce qui réduit les temps de réponse sans sacrifier la qualité.
Vous pouvez également créer un super agent de triage à l'aide du langage naturel dans votre environnement de travail ClickUp. En savoir plus
Résumé des réunions et suivi
À partir des transcriptions de réunions, LLaMA peut extraire les décisions, les éléments d’action et les points clés de la discussion. La véritable valeur ajoutée apparaît lorsque ces résultats sont directement intégrés dans des outils de gestion des tâches, transformant ainsi les discussions en travail suivi.
🌟 L'assistant de prise de notes IA de ClickUp ne se contente pas de prendre des notes pendant les réunions ; il rédige des résumés, génère des actions à entreprendre et lie les notes de réunion à vos documents et tâches.
Rédaction et itération de documents
Les équipes peuvent utiliser LLaMA pour générer des premières ébauches de rapports, de propositions ou de documentation à partir de modèles existants et d'exemples passés. Cela permet de passer de la création d'une page blanche à la révision et au perfectionnement, ce qui accélère la livraison sans réduire les normes.
🌟 ClickUp Brain peut rapidement générer des brouillons de documentation, en conservant toutes vos connaissances professionnelles dans leur contexte. Essayez-le dès aujourd'hui.
Les chatbots alimentés par LLaMA sont plus efficaces lorsqu'ils sont intégrés dans des flux de travail existants (documentation, gestion de projet et communication d'équipe) plutôt que lorsqu'ils fonctionnent comme des outils autonomes.
C'est là que l'intégration directe de l'IA dans votre environnement de travail fait toute la différence. Au lieu de créer un outil distinct, vous pouvez intégrer l'IA conversationnelle à l'environnement dans lequel votre équipe travaille déjà.
Par exemple, vous pouvez créer un bot LLaMA personnalisé qui servira d'assistant de connaissances. Mais s'il ne fait pas partie de votre outil de gestion de projet, votre équipe devra changer de contexte pour lui poser une question. Cela crée des frictions et ralentit tout le monde.
Éliminez ce changement de contexte en utilisant une IA qui fait déjà partie de votre flux de travail.
Posez des questions sur vos projets, tâches et documents sans jamais quitter ClickUp grâce à ClickUp Brain. Il vous suffit de taper @brain dans n'importe quel commentaire de tâche ou dans ClickUp Chat pour obtenir une réponse instantanée et contextuelle. C'est comme avoir un membre de l'équipe qui connaît parfaitement tout votre environnement de travail. 🤩
Le chatbot, qui n'était au départ qu'une nouveauté, devient ainsi un élément central de la productivité de votre équipe.
Limites de l'utilisation de LLaMA pour la création de chatbots
La création d'un chatbot LLaMA peut être très enrichissante, mais les équipes sont souvent prises au dépourvu par des complexités cachées. Le modèle open source « gratuit » peut s'avérer plus coûteux et difficile à gérer que prévu, ce qui se traduit par une mauvaise expérience pour les utilisateurs et un cycle de maintenance constant et gourmand en ressources.
Il est important de comprendre les limites avant la validation.
- Complexité technique : la configuration et la maintenance d'un modèle LLaMA nécessitent des connaissances en infrastructure d'apprentissage automatique.
- Configuration matérielle requise : l'exécution de modèles plus volumineux et plus performants nécessite du matériel GPU coûteux, et les coûts liés au cloud peuvent rapidement s'accumuler.
- Contraintes de la fenêtre contextuelle: les modèles LLaMA ont une mémoire limitée ( 4 Ko de jetons pour LLaMA 2 ). Le traitement de documents ou de discussions longues nécessite des stratégies de segmentation complexes.
- Aucune protection intégrée : vous êtes responsable de la mise en œuvre de vos propres mesures de filtrage de contenu et de sécurité.
- Maintenance continue : à mesure que de nouveaux modèles sont lancés, vous devrez mettre à jour vos systèmes, et les modèles affinés peuvent nécessiter un nouveau apprentissage.
Les modèles auto-hébergés ont également généralement une latence plus élevée que les API commerciales hautement optimisées. Ce sont là autant de contraintes opérationnelles que les solutions gérées prennent en charge pour vous.
📮ClickUp Insight : 88 % des personnes interrogées dans le cadre de notre sondage utilisent l'IA pour leurs tâches personnelles, mais plus de 50 % hésitent à l'utiliser au travail. Les trois principaux obstacles ? Le manque d'intégration transparente, les lacunes en matière de connaissances ou les préoccupations liées à la sécurité.
Mais que se passe-t-il si l'IA est intégrée à votre environnement de travail et est déjà sécurisée ? ClickUp Brain, l'assistant IA intégré à ClickUp, rend cela possible. Il comprend les invites en langage naturel, résolvant ainsi les trois problèmes liés à l'adoption de l'IA tout en effectuant la connexion entre votre chat, vos tâches, vos documents et vos connaissances dans tout l'environnement de travail. Trouvez des réponses et des informations en un seul clic !
Alternatives à LLaMA pour créer des chatbots
LLaMA n'est qu'une option parmi une multitude de modèles /IA, et il peut être difficile de déterminer lequel vous convient le mieux.
Voici comment se présente le paysage des alternatives.
Autres modèles open source :
- Mistral: réputé pour ses performances élevées même avec des modèles de petite taille, ce qui le rend très efficace.
- Falcon : Livré avec une licence très permissive, idéale pour les applications commerciales.
- MPT : optimisé pour traiter les documents et les discussions longues.
API commerciales :
- OpenAI (GPT-4, GPT-3. 5) : généralement considérés comme les modèles linguistiques les plus performants, ils sont très faciles à intégrer.
- Anthropic (Claude) : réputé pour ses fonctionnalités de sécurité robustes et ses fenêtres contextuelles très larges.
- Google (Gemini) : offre de puissantes capacités multimodales, lui permettant de comprendre le texte, les images et l'audio.
Vous pouvez le créer vous-même à l'aide d'un modèle open source, payer pour une API commerciale ou utiliser un environnement de travail IA convergent qui offre une solution préintégrée avec différents types d'agents IA.
📚 À lire également : Comment utiliser un chatbot pour votre entreprise
Créez des assistants IA contextuels avec ClickUp
La création d'un chatbot avec LLaMA vous offre un contrôle incroyable sur vos données, vos coûts et vos personnalisations. Mais ce contrôle s'accompagne d'une responsabilité en matière d'infrastructure, de maintenance et de sécurité, autant d'aspects pris en charge par les API gérées. L'objectif n'est pas seulement de créer un bot, mais aussi d'améliorer la productivité de votre équipe, et un projet d'ingénierie complexe peut parfois vous détourner de cet objectif.
Le choix approprié dépend des ressources et des priorités de votre équipe. Si vous disposez d'une expertise en apprentissage automatique et avez des exigences strictes en matière de confidentialité, LLaMA est une option fantastique. Si vous privilégiez la rapidité et la simplicité, un outil intégré pourrait être plus adapté.
Avec ClickUp, vous bénéficiez d'un environnement de travail IA convergent qui regroupe toutes vos tâches, tous vos documents et toutes vos discussions en un seul endroit, grâce à une IA intégrée. Il réduit la dispersion du contexte et aide les équipes à travailler plus rapidement et plus efficacement, en mettant à leur disposition les informations pertinentes grâce à des super agents personnalisables et à une IA contextuelle.
Ne perdez plus de temps sur l'infrastructure et profitez dès aujourd'hui des avantages d'un assistant IA contextuel sans avoir à tout créer de zéro. Commencez gratuitement avec ClickUp.
Foire aux questions (FAQ)
Le coût dépend entièrement de votre méthode de déploiement, et les prévisions du projet peuvent vous aider à l'estimer. Si vous utilisez votre propre matériel, vous devrez supporter un coût initial pour le GPU, mais vous n'aurez pas à payer de frais supplémentaires par requête. Les fournisseurs de cloud facturent un tarif horaire basé sur la taille du GPU et du modèle.
Oui, les licences pour LLaMA 2 et LLaMA 3 autorisent une utilisation commerciale. Cependant, vous devez accepter les conditions d'utilisation de Meta et fournir les mentions requises dans votre produit.
LLaMA 3 est le modèle le plus récent et le plus performant, offrant de meilleures capacités de raisonnement et une fenêtre contextuelle plus large (8 000 jetons contre 4 000 pour LLaMA 2). Cela signifie qu'il peut traiter des discussions et des documents plus longs, mais qu'il nécessite également davantage de ressources informatiques pour fonctionner.
Bien que Python soit le langage le plus couramment utilisé pour l'apprentissage automatique en raison de ses bibliothèques étendues, il n'est pas strictement nécessaire. Certaines plateformes commencent à proposer des solutions sans code ou à faible code qui vous permettent de déployer un chatbot LLaMA avec une interface graphique. /