
Les projets de formation à l'IA échouent rarement au niveau du modèle. Ils rencontrent des difficultés lorsque les expériences, la documentation et les mises à jour des parties prenantes sont dispersées entre trop d'outils.
Ce guide vous explique comment former des modèles avec Databricks DBRX, un LLM jusqu'à deux fois plus efficace en termes de calcul que les autres modèles leaders, tout en organisant le travail qui l'entoure dans ClickUp.
De l'installation et du réglage fin à la documentation et aux mises à jour inter-équipes, vous verrez comment un environnement de travail unique et convergent permet d'éliminer la dispersion contextuelle et permet à votre équipe de se concentrer sur la création plutôt que sur la recherche. 🛠
Qu'est-ce que DBRX ?
DBRX est un puissant modèle linguistique open source (LLM) spécialement conçu pour l'entraînement et l'inférence des modèles d'IA d'entreprise. Comme il s'agit d'un modèle open source sous licence Databricks Open Model License, votre équipe a un accès complet aux poids et à l'architecture du modèle, ce qui vous permet de l'inspecter, de le modifier et de le déployer selon vos propres conditions.
Il existe en deux versions : DBRX Base pour le pré-entraînement approfondi et DBRX Instruct pour les tâches prêtes à l'emploi qui suivent des instructions.
Architecture DBRX et conception de mélange d'experts
DBRX résout les tâches à l'aide d'une architecture Mixture-of-Experts (MoE). Contrairement aux grands modèles linguistiques traditionnels qui utilisent tous leurs milliards de paramètres pour chaque calcul, DBRX n'active qu'une fraction de ses paramètres totaux (les experts les plus pertinents) pour une tâche donnée.
Considérez-le comme une équipe d'experts spécialisés : au lieu que tout le monde travaille sur tous les problèmes, le système attribue intelligemment chaque tâche aux paramètres correspondants les plus qualifiés.
Cela permet non seulement de réduire le temps de réponse, mais aussi d'obtenir des performances et des résultats de premier ordre tout en réduisant considérablement les coûts de calcul.
Voici un aperçu rapide de ses principales spécifications :
- Nombre total de paramètres : 132 milliards pour tous les experts
- Paramètres actifs : 36 milliards par passe avant
- Nombre d'experts : 16 au total (routage MoE Top-4), dont 4 actifs pour un jeton donné.
- Fenêtre de contexte : 32 000 jetons
Données d'entraînement DBRX et spécifications des jetons
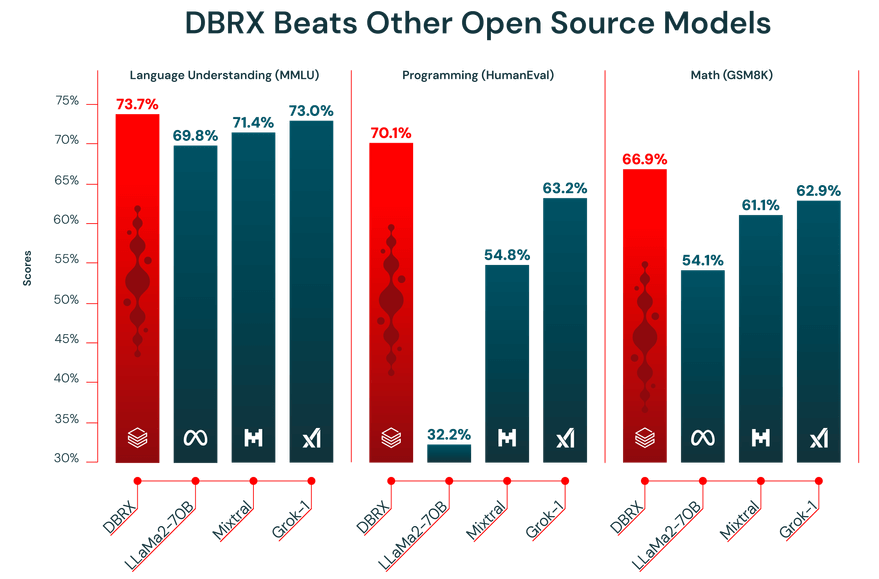
Les performances d'un LLM dépendent de la qualité des données sur lesquelles il est formé. DBRX a été préformé sur un ensemble de données massif de 12 000 milliards de tokens, soigneusement sélectionné par l'équipe Databricks à l'aide de ses outils avancés de traitement des données. C'est précisément pour cette raison qu'il a obtenu d'excellents résultats lors des tests de performance de l'industrie.
De plus, DBRX dispose d'une fonctionnalité permettant d'afficher une fenêtre contextuelle de 32 000 tokens. Il s'agit de la quantité de texte que le modèle peut prendre en compte à la fois. Une grande fenêtre contextuelle est très utile pour des tâches complexes telles que le résumé de longs rapports, l'analyse de documents juridiques volumineux ou la création de systèmes avancés de génération augmentée par la recherche (RAG), car elle permet au modèle de conserver le contexte sans tronquer ni oublier d'informations.
🎥 Regardez cette vidéo pour découvrir comment une coordination de projet rationalisée peut transformer votre flux de travail de formation en IA et éliminer les frictions liées au passage d'un outil à l'autre. 👇🏽
Comment accéder à DBRX et le configurer
DBRX propose deux modes d'accès principaux, qui offrent tous deux un accès complet aux poids des modèles à des conditions commerciales avantageuses. Vous pouvez utiliser Hugging Face pour une flexibilité maximale ou y accéder directement via Databricks pour une expérience plus intégrée.
Accédez à DBRX via Hugging Face.
Pour les équipes qui apprécient la flexibilité et sont déjà à l'aise avec l'écosystème Hugging Face, l'accès à DBRX via le hub est la solution idéale. Il vous permet d'intégrer le modèle dans vos flux de travail existants basés sur des transformateurs.
Voici comment commencer :
- Créez ou connectez-vous à votre compte Hugging Face.
- Accédez à la carte du modèle DBRX sur le hub et acceptez les conditions de licence.
- Installez la bibliothèque transformers ainsi que les dépendances nécessaires telles que accelerate.
- Utilisez la classe AutoModelForCausalLM dans votre script Python pour charger le modèle DBRX.
- Configurez votre pipeline d'inférence en gardant à l'esprit que DBRX nécessite une mémoire GPU (VRAM) importante pour fonctionner efficacement.
📖 En savoir plus : Comment configurer la température LLM
Accédez à DBRX via Databricks.
Si votre équipe utilise déjà Databricks pour l'ingénierie des données ou l'apprentissage automatique, l'accès à DBRX via la plateforme est la solution la plus simple. Cela élimine les frictions liées à l'installation et vous fournit tous les outils dont vous avez besoin pour le MLOps directement là où vous travaillez déjà.
Suivez ces étapes dans votre environnement de travail Databricks pour commencer :
- Accédez à la section Model Garden ou Mosaic IA.
- Sélectionnez DBRX Base ou DBRX Instruct, selon vos besoins.
- Configurez un point de terminaison de service pour l'accès à l'API ou configurez un environnement de notebook pour une utilisation interactive.
- Commencez à tester l'inférence à l'aide d'échantillons d'invites pour vous assurer que tout fonctionne correctement avant de passer à l'échelle supérieure dans la formation ou le déploiement de votre modèle d'IA.
Cette approche vous offre un accès transparent à des outils tels que MLflow pour le suivi des expériences et Unity Catalog pour la gouvernance des modèles.
📮 ClickUp Insight : En moyenne, un professionnel passe plus de 30 minutes par jour à rechercher des informations liées à son travail, soit plus de 120 heures par an perdues à fouiller dans ses e-mails, ses fils de discussion Slack et ses fichiers éparpillés.
Un assistant IA intelligent intégré à votre environnement de travail peut changer cela. Découvrez ClickUp Brain.
Il fournit des informations et des réponses instantanées en faisant apparaître les bons documents, discussions et détails de tâches en quelques secondes, afin que vous puissiez arrêter de chercher et commencer à travailler.
Comment affiner DBRX et former des modèles d'IA personnalisés
Un modèle prêt à l'emploi, aussi puissant soit-il, ne comprendra jamais les nuances propres à votre entreprise. DBRX étant open source, vous pouvez l'ajuster pour créer un modèle personnalisé qui parle le langage de votre entreprise ou effectue une tâche spécifique que vous souhaitez lui confier.
Voici trois méthodes courantes à faire :
1. Affinez DBRX avec les ensembles de données Hugging Face
Pour les équipes qui débutent ou qui travaillent sur des tâches courantes, les ensembles de données publics de Hugging Face Hub constituent une excellente ressource. Ils sont préformatés et faciles à charger, ce qui vous évite de passer des heures à préparer vos données.
Le processus est assez simple :
- Trouvez un ensemble de données sur le hub qui correspond à votre tâche (par exemple, suivi d'instructions, résumé).
- Chargez-le à l'aide de la bibliothèque de jeux de données.
- Assurez-vous que les données sont mises en forme en paires instruction-réponse.
- Configurez votre script d'entraînement avec des hyperparamètres tels que le taux d'apprentissage et la taille des lots.
- Lancez la tâche d'entraînement, en veillant à enregistrer régulièrement les points de contrôle au cours d'une période donnée.
- Évaluez le modèle affiné sur un ensemble de validation réservé afin de mesurer les améliorations apportées.
2. Affinez DBRX à l'aide d'ensembles de données locaux
Vous obtiendrez généralement les meilleurs résultats en affinant votre modèle à l'aide de vos propres données propriétaires. Cela vous permet d'enseigner au modèle la terminologie, le style et les connaissances spécifiques à votre entreprise. N'oubliez pas que cela n'est rentable que si vos données sont propres, bien préparées et suffisamment volumineuses.
Suivez ces étapes pour préparer vos données internes :
- Collecte de données : rassemblez des exemples de haute qualité à partir de vos wikis, documents et bases de données internes.
- Conversion de format : structurez vos données dans un format cohérent d'instructions-réponses, souvent sous forme de lignes JSON.
- Filtrage de qualité : supprimez tous les exemples de mauvaise qualité, en double ou non pertinents.
- Répartition de validation : réservez une petite partie de vos données (généralement 10 à 15 %) pour évaluer les performances du modèle.
- Contrôle de confidentialité : supprimez ou masquez toute information personnelle identifiable (PII) ou donnée sensible.
3. Affinez DBRX avec StreamingDataset
Si votre ensemble de données s'avère trop volumineux pour tenir dans la mémoire de votre machine, pas d'inquiétude, vous pouvez utiliser la bibliothèque Streaming Dataset de Databricks. Elle vous permet de diffuser les données directement depuis le stockage cloud pendant que le modèle est en cours de formation, plutôt que de les charger toutes en mémoire en une seule fois.
Voici comment faire :
- Préparation des données : nettoyez et structurez vos données d'entraînement, puis stockez-les dans un format diffusable tel que JSONL ou CSV dans un stockage cloud.
- Conversion du format de streaming : convertissez votre ensemble de données dans un format adapté au streaming, tel que Mosaic Data Shard (MDS), afin qu'il puisse être lu efficacement pendant l'entraînement.
- Installation du chargeur d'entraînement : configurez votre chargeur d'entraînement pour qu'il pointe vers l'ensemble de données distant et définissez un cache local pour le stockage temporaire des données.
- Initialisation du modèle : lancez le processus de réglage fin DBRX à l'aide d'un cadre de formation prenant en charge StreamingDataset, tel que LLM Foundry.
- Formation basée sur le streaming : exécutez la tâche de formation pendant que les données sont diffusées par lots pendant la formation, plutôt que d'être entièrement chargées en mémoire.
- Point de contrôle et récupération : reprenez l'entraînement de manière transparente si une exécution est interrompue, sans dupliquer ni ignorer des données.
- Évaluation et déploiement : validez les performances du modèle optimisé et déployez-le à l'aide de votre installation de service ou d'inférence préférée.
💡Conseil de pro : au lieu de créer un plan de formation DBRX à partir de zéro, commencez par utiliser le modèle de feuille de route pour les projets d'IA et d'apprentissage automatique de ClickUp et adaptez-le aux besoins de votre équipe. Il fournit une structure claire pour la planification des ensembles de données, les phases de formation, l'évaluation et le déploiement, afin que vous puissiez vous concentrer sur l'organisation de votre travail plutôt que sur la structuration d'un flux de travail.
Cas d'utilisation de DBRX pour l'entraînement de modèles IA
C'est une chose d'avoir un modèle puissant, mais c'en est une autre de savoir exactement où il excelle.
Lorsque vous n'avez pas une idée claire des points forts d'un modèle, il est facile de consacrer du temps et des ressources à essayer de le faire fonctionner là où il n'est tout simplement pas adapté. Cela conduit à des résultats médiocres et à de la frustration.
L'architecture unique et les données d'entraînement de DBRX le rendent particulièrement adapté à plusieurs cas d'utilisation clés en entreprise. Connaître ces atouts vous aide à aligner le modèle sur vos objectifs commerciaux et à maximiser votre retour sur investissement.
Génération de texte et création de contenu
DBRX Instruct est finement réglé pour suivre les instructions et générer du texte de haute qualité. Cela en fait un outil puissant pour automatiser un large éventail de tâches liées au contenu. Sa grande fenêtre contextuelle est un avantage significatif, lui permettant de traiter de longs documents sans perdre le fil.
Vous pouvez l'utiliser pour :
- Documentation technique : générez et affinez les manuels de produits, les références API et les guides d'utilisation pour les utilisateurs.
- Contenu marketing : rédigez des articles de blog, des newsletters par e-mail et des mises à jour sur les réseaux sociaux.
- Génération de rapports : résumez les résultats de données complexes et créez des résumés exécutifs concis.
- Traduction et localisation : adaptez le contenu existant à de nouveaux marchés et publics.
Tâches de génération de code et de débogage
Une partie importante des données d'entraînement de DBRX comprenait du code, ce qui en fait un support LLM performant pour les développeurs. Il peut contribuer à accélérer les cycles de développement en effectuant l'automatisation des tâches de codage répétitives et en aidant à résoudre des problèmes complexes.
Voici quelques façons dont votre équipe d'ingénieurs peut en tirer parti :
- Complétion de code : générez automatiquement des corps de fonction à partir de commentaires ou de chaînes de documentation.
- Détection des bugs : analysez des extraits de code pour identifier les erreurs potentielles ou les failles logiques.
- Explication du code : traduisez des algorithmes complexes ou du code hérité en anglais simple.
- Génération de tests : créez des tests unitaires basés sur la signature d'une fonction et le comportement attendu.
RAG et applications à contexte long
La génération augmentée par la récupération (RAG) est une technique puissante qui fonde les réponses d'un modèle sur les données privées de votre entreprise. Cependant, les systèmes RAG ont souvent du mal avec les modèles qui ont des fenêtres contextuelles petites, ce qui oblige à un découpage agressif des données qui peut faire perdre des éléments contextuels importants. La fenêtre contextuelle 32K de DBRX en fait une excellente base pour des applications RAG robustes.
Cela vous permet de créer des outils internes puissants, tels que :
- Recherche d'entreprise : créez un chatbot qui répond aux questions des employés à l'aide de votre base de connaissances interne.
- Service client : créez un agent qui génère des réponses d'assistance basées sur la documentation de votre produit.
- Assistance à la recherche : développez un outil capable de synthétiser les informations contenues dans des centaines de pages d'articles de recherche.
- Vérification de la conformité : vérifiez automatiquement les textes marketing par rapport aux directives internes de la marque ou aux documents réglementaires.
Comment intégrer la formation DBRX au flux de travail de votre équipe
La réussite d'un projet d'entraînement de modèles d'IA ne se limite pas au code et au calcul. Il s'agit d'un effort collaboratif impliquant des ingénieurs en apprentissage automatique, des scientifiques des données, des chefs de produit et des parties prenantes.
Lorsque cette collaboration est dispersée entre les notebooks Jupyter, les canaux Slack et les différents outils de gestion de projet, vous créez une « prolifération contextuelle », une situation dans laquelle les informations critiques du projet sont dispersées entre trop d'outils.
ClickUp résout ce problème. Au lieu de jongler avec plusieurs outils, vous disposez d'un environnement de travail IA convergé où la gestion de projet, la documentation et la communication cohabitent, afin que vos expériences restent connectées de la planification à l'exécution et à l'évaluation.
Ne perdez jamais le suivi de vos expériences et de votre progression.
Lorsque vous menez plusieurs expériences, le plus difficile n'est pas de former le modèle, mais le suivi des changements intervenus au cours du processus. Quelle version de l'ensemble de données a été utilisée, quel taux d'apprentissage a donné les meilleurs résultats, ou quelle exécution a été livrée ?
ClickUp vous facilite grandement ce processus. Vous pouvez suivre chaque cycle de formation séparément dans les tâches ClickUp, et dans les tâches, vous pouvez utiliser les champs personnalisés pour enregistrer :
- Version du jeu de données
- Hyperparamètres
- Variante du modèle (DBRX Base vs DBRX Instruct)
- Statut de l'entraînement (en attente, en cours, en évaluation, déployé)
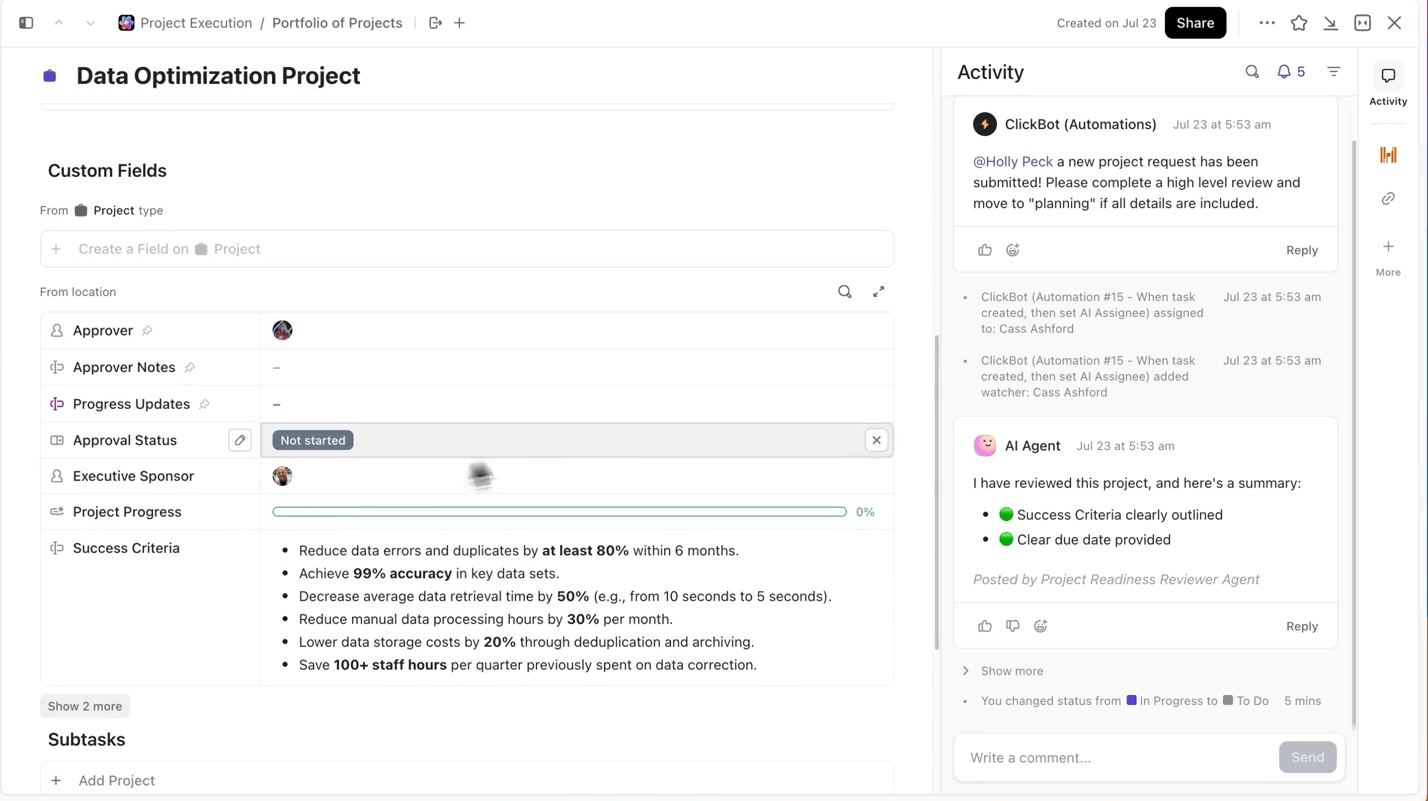
Ainsi, chaque expérience documentée est consultable, facile à comparer avec d'autres et reproductible.
Conservez la documentation des modèles liée au travail
Vous n'avez plus besoin de passer des notebooks Jupyter aux fichiers README ou aux fils de discussion Slack pour comprendre le contexte d'une tâche expérimentale.
Avec ClickUp Docs, vous pouvez organiser et rendre accessibles votre architecture de modèle, vos scripts de préparation des données ou vos indicateurs d'évaluation en les documentant dans un document consultable qui est lié aux tâches d'expérimentation dont ils sont issus.
💡Conseil de pro : conservez un brief de projet évolutif dans ClickUp Docs qui détaille chaque décision, de l'architecture au déploiement, afin que les nouveaux membres de l'équipe puissent toujours se mettre à jour sur les détails du projet sans avoir à fouiller dans d'anciens fils de discussion.
Offrez aux parties prenantes une visibilité en temps réel
Les tableaux de bord ClickUp affichent en temps réel la progression des expériences et la charge de travail de l'équipe. I
Au lieu de compiler manuellement les mises à jour ou d'envoyer des e-mails, les tableaux de bord se mettent à jour automatiquement en fonction des données de vos tâches. Ainsi, les parties prenantes peuvent vérifier à tout moment où en sont les choses et n'ont plus besoin de vous interrompre avec des questions du type « quel est le statut ? ».
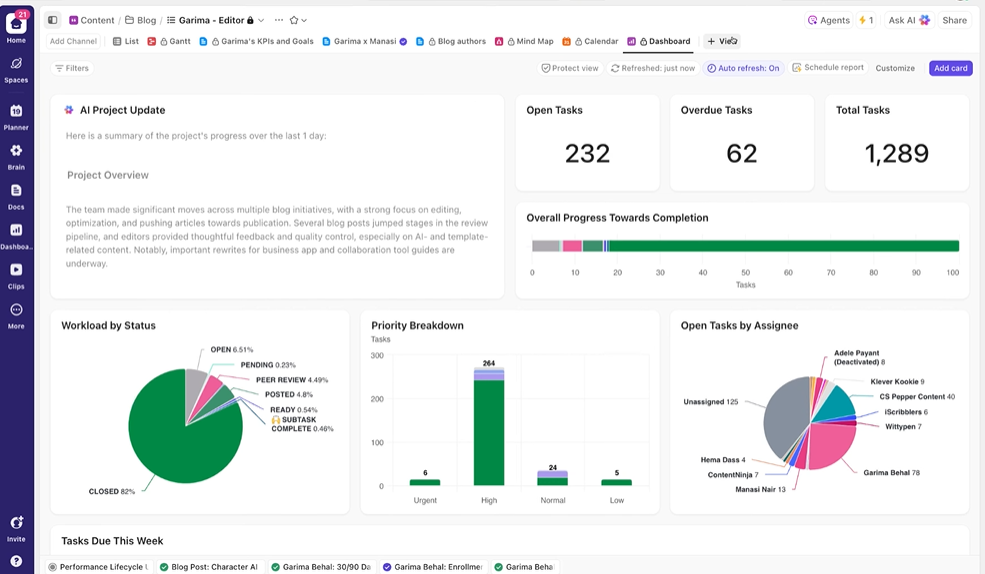
Ainsi, vous pouvez vous concentrer sur la réalisation des expériences plutôt que de devoir constamment produire des rapports manuellement.
Faites de l'IA votre assistant de projet intelligent.
Vous n'avez plus besoin de passer manuellement en revue des semaines de données d'entraînement pour obtenir un résumé des expériences menées jusqu'à présent. Il vous suffit de mentionner @Brain dans n'importe quel commentaire de tâche, et ClickUp Brain vous fournira l'aide dont vous avez besoin avec le contexte complet de vos projets passés et en cours.
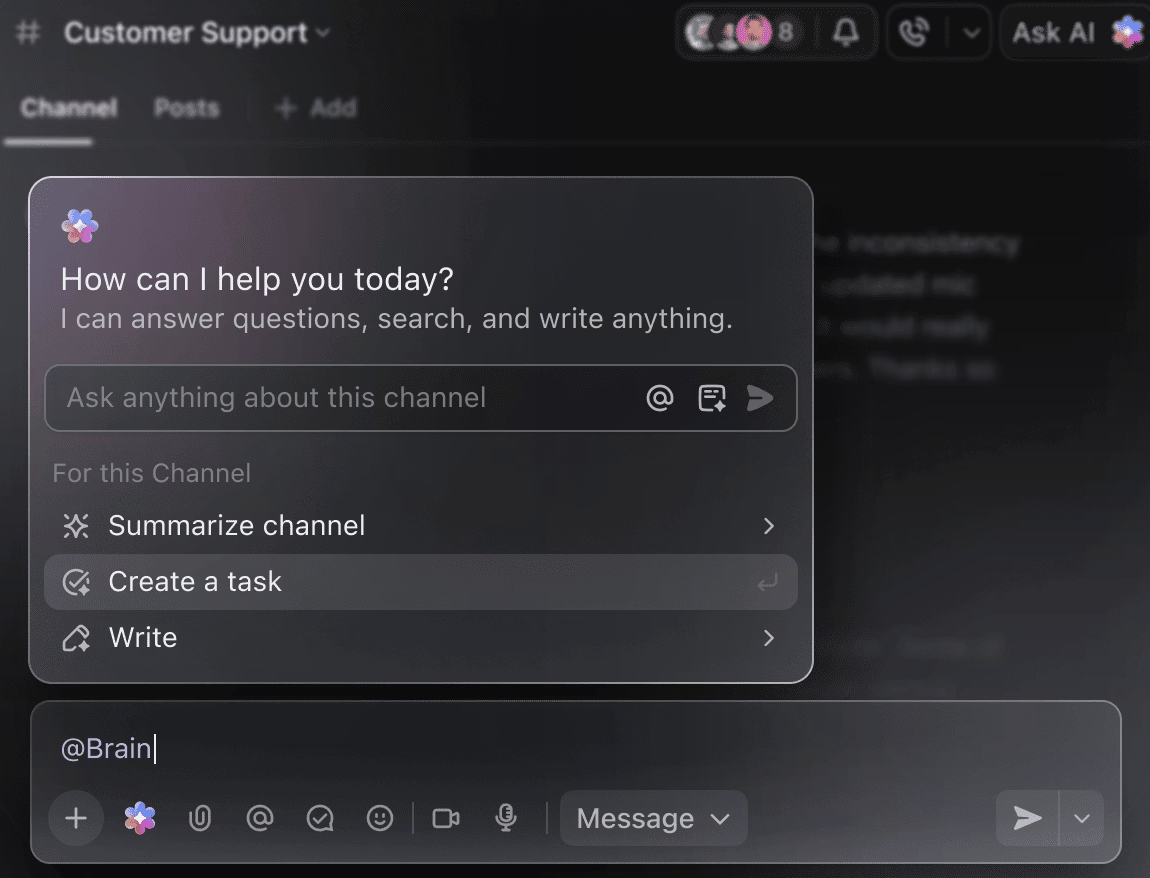
Vous pouvez demander à Brain de « résumer les expériences de la semaine dernière en 5 points » ou de « rédiger un document avec les derniers résultats des hyperparamètres », et obtenir instantanément un résultat soigné.
🧠 L'avantage ClickUp : les super agents de ClickUp vont encore plus loin : ils peuvent automatiser l'ensemble des flux de travail en fonction des déclencheurs que vous définissez, et pas seulement répondre à vos questions. Grâce aux super agents, vous pouvez créer automatiquement une nouvelle tâche de formation DBRX chaque fois qu'un ensemble de données est téléchargé, informer votre équipe et lier les documents pertinents lorsque la formation est terminée ou atteint un point de contrôle, puis générer un résumé hebdomadaire de la progression et le transmettre aux parties prenantes sans que vous ayez à intervenir.
Erreurs courantes à éviter
Se lancer dans un projet de formation DBRX est passionnant, mais quelques pièges courants peuvent compromettre votre progression. Éviter ces erreurs vous permettra d'économiser du temps, de l'argent et beaucoup de frustration.
- Sous-estimer les exigences matérielles : DBRX est puissant, mais il est également volumineux. Tenter de l'exécuter sur un matériel inadéquat entraînera des erreurs de mémoire insuffisante et l'échec des tâches d'entraînement. Gardez à l'esprit que DBRX (132B) nécessite au moins 264 Go de VRAM pour une inférence 16 bits, soit environ 70 à 80 Go lors de l'utilisation d'une quantification 4 bits.
- Ignorer les contrôles de qualité des données : si les données d'entrée sont erronées, les résultats le seront aussi. Le réglage fin d'un ensemble de données désordonné et de mauvaise qualité ne fera qu'apprendre au modèle à produire des résultats désordonnés et de mauvaise qualité.
- Ignorer les limites de longueur du contexte : bien que la fenêtre de contexte de 32 Ko de DBRX soit généreuse, elle n'est pas infinie. L'alimentation du modèle avec des entrées dépassant cette limite entraînera un résultat de troncature silencieuse et des performances médiocres.
- Utilisation de Base lorsque Instruct est approprié : DBRX Base est un modèle brut pré-entraîné destiné à un entraînement supplémentaire à grande échelle. Pour la plupart des tâches de suivi d'instructions, vous devez commencer par DBRX Instruct, qui a déjà été optimisé à cette fin.
- Séparation du travail de formation et de la coordination de projet : lorsque le suivi de vos expériences se fait dans un outil et que votre plan de projet se trouve dans un autre, vous créez des silos d'informations. Utilisez une plateforme intégrée comme ClickUp pour synchroniser votre travail technique et la coordination de vos projets.
- Négliger l'évaluation avant le déploiement : un modèle qui fonctionne bien sur vos données d'entraînement peut échouer de manière spectaculaire dans le monde réel. Validez toujours votre modèle affiné sur un ensemble de tests réservé avant de le déployer en production.
- Négliger la complexité du réglage fin : DBRX étant un modèle Mixture-of-Experts, les scripts de réglage fin standard peuvent nécessiter des bibliothèques spécialisées telles que Megatron-LM ou PyTorch FSDP pour gérer le partitionnement des paramètres sur plusieurs GPU.
DBRX par rapport aux autres plateformes de formation à l'IA
Le choix d'une plateforme de formation à l'IA implique un compromis fondamental : contrôle ou commodité. Les modèles propriétaires, accessibles uniquement via API, sont faciles à utiliser, mais vous enferment dans l'écosystème d'un fournisseur.
Les modèles ouverts tels que DBRX offrent un contrôle total, mais nécessitent davantage d'expertise technique et d'infrastructure. Ce choix peut vous laisser perplexe, ne sachant pas quelle voie correspond réellement à vos objectifs à long terme, un défi auquel de nombreuses équipes sont confrontées lors de l'adoption de l'IA.
Ce tableau présente les principales différences afin de vous aider à prendre une décision éclairée.
| Poids | Ouvrir (Personnalisé) | Propriétaire | Ouvrir (Personnalisé) | Propriétaire |
| Réglage fin | Contrôle total | Basé sur une API | Contrôle total | Basé sur une API |
| Auto-hébergement | Oui | Non | Oui | Non |
| Licence | Modèle ouvert DB | Conditions générales d'OpenAI | Communauté Llama | Termes anthropiques |
| Contexte | 32K | 128K – 1M | 128K | 200 000 – 1 million |
DBRX est le choix idéal lorsque vous avez besoin d'un contrôle total sur le modèle, que vous devez l'héberger vous-même pour des raisons de sécurité ou de conformité, ou que vous souhaitez bénéficier de la flexibilité d'une licence commerciale permissive. Si vous ne disposez pas d'une infrastructure GPU dédiée ou si vous privilégiez la rapidité de mise sur le marché à une personnalisation approfondie, les alternatives basées sur des API peuvent être plus adaptées.
Commencez à vous former plus intelligemment avec ClickUp
DBRX vous offre une base prête à l'emploi pour créer des applications IA personnalisées, avec une transparence et un contrôle que vous n'obtenez pas avec les modèles propriétaires. Son architecture MoE efficace réduit les coûts d'inférence et sa conception ouverte facilite le réglage fin. Mais une technologie performante n'est qu'une partie de l'équation.
La véritable réussite vient de l'alignement de votre travail technique avec le flux de travail collaboratif de votre équipe. L'entraînement des modèles IA est un travail d'équipe, et il est essentiel de synchroniser les expériences, la documentation et la communication avec les parties prenantes. Lorsque vous rassemblez tout dans un seul environnement de travail convergent et que vous réduisez la dispersion du contexte, vous pouvez livrer de meilleurs modèles, plus rapidement.
Commencez gratuitement avec ClickUp pour coordonner vos projets de formation en IA dans un seul environnement de travail. ✨
Foire aux questions
Vous pouvez surveiller l'entraînement à l'aide d'outils ML standard tels que TensorBoard, Weights & Biases ou MLflow. Si vous effectuez l'entraînement dans l'écosystème Databricks, MLflow est intégré en natif pour un suivi transparent des expériences.
Oui, DBRX peut être intégré dans des pipelines MLOps standard. En conteneurisant le modèle, vous pouvez le déployer à l'aide de plateformes d'orchestration telles que Kubeflow ou de flux de travail CI/CD personnalisés.
DBRX Base est le modèle pré-entraîné de base destiné aux équipes qui souhaitent effectuer un pré-entraînement continu spécifique à un domaine ou un réglage fin de l'architecture. DBRX Instruct est une version optimisée pour suivre des instructions, ce qui en fait un meilleur point de départ pour la plupart des développements d'applications.
La principale différence réside dans le contrôle. DBRX vous donne un accès complet aux poids du modèle pour une personnalisation approfondie et un auto-hébergement, tandis que GPT-4 est un service uniquement basé sur une API.
Les pondérations du modèle DBRX sont disponibles gratuitement sous la licence Databricks Open Model License. Cependant, vous êtes responsable des coûts liés à l'infrastructure informatique nécessaire pour exécuter ou affiner le modèle.