
La mayoría de los desarrolladores que crean un script de resumen de Hugging Face se topan con el mismo obstáculo: el resumen funciona perfectamente en su terminal. Pero rara vez establece conexión con el trabajo real al que se supone que debe dar soporte.
Esta guía le muestra cómo crear un resumen de texto con la biblioteca Transformers de Hugging Face y, a continuación, le explica por qué incluso una implementación impecable puede crear más problemas de los que resuelve cuando su equipo necesita resúmenes que realmente se relacionen con tareas, proyectos y decisiones.
¿Qué es el resumen de texto?
Los equipos se ahogan en información. Te enfrentas a documentos interminables, transcripciones de reuniones interminables, densos trabajos de investigación e informes trimestrales que llevan horas digerir manualmente. Esta constante sobrecarga de información ralentiza la toma de decisiones y acaba con la productividad.
El resumen de texto es el proceso de utilizar el procesamiento del lenguaje natural (NLP) para condensar este contenido en una versión breve y coherente que conserve la información más importante. Piensa en ello como un resumen ejecutivo instantáneo de cualquier documento. Esta tecnología de resumen NLP suele utilizar uno de estos dos enfoques:
Resumen extractivo: este método funciona identificando y extrayendo las frases más importantes directamente del texto original. Es como si un resaltador seleccionara automáticamente los puntos clave por ti. El resumen final es una recopilación de frases originales.
Resumen abstractivo: este método más avanzado genera frases completamente nuevas para captar el significado central del texto original. Parafrasea la información, lo que da como resultado un resumen más fluido y similar al humano, muy parecido a cómo una persona explicaría una historia larga con sus propias palabras.
Los resultados de esto se ven en todas partes. Se utiliza para condensar las notas de las reuniones en elementos de acción, destilar los comentarios de los clientes en tendencias y crear resúmenes rápidos de la documentación de los proyectos. La meta es siempre la misma: obtener la información esencial sin leer cada palabra.
📮 ClickUp Insight: El profesional medio dedica más de 30 minutos al día a buscar información relacionada con el trabajo. Eso supone más de 120 horas al año perdidas en buscar entre correos electrónicos, hilos de Slack y archivos dispersos. Un asistente de IA inteligente integrado en tu entorno de trabajo puede cambiar eso. ClickUp Brain ofrece información y respuestas instantáneas al mostrar los documentos, conversaciones y detalles de tareas adecuados en cuestión de segundos, para que puedas dejar de buscar y empezar a trabajar.
💫 Resultados reales: equipos como QubicaAMF recuperaron más de 5 horas semanales utilizando ClickUp, más de 250 horas anuales por persona, al eliminar los procesos obsoletos de gestión del conocimiento.
¿Por qué utilizar Hugging Face para resumir textos?
Crear un modelo de resumen de texto personalizado desde cero es una tarea titánica. Requiere enormes conjuntos de datos para el entrenamiento, recursos computacionales potentes y costosos, y un equipo de expertos en aprendizaje automático. Esta elevada barrera de entrada impide que la mayoría de los equipos de ingeniería y de producto se lancen a ello.
Hugging Face es la plataforma que resuelve este problema. Se trata de una comunidad de código abierto y una plataforma de ciencia de datos que te da acceso a miles de modelos preentrenados, democratizando de forma eficaz el proceso de resumir LLM para los desarrolladores. En lugar de crear desde cero, puedes empezar con un potente modelo que ya está al 99 % de su desarrollo.
He aquí por qué tantos desarrolladores recurren a Hugging Face: 🛠️
Acceso a modelos preentrenados: Hugging Face Hub es un enorme repositorio con más de 2 millones de modelos públicos entrenados por empresas como Google, Meta y OpenAI. Puedes descargar y utilizar estos puntos de control de última generación para tus propios proyectos.
API de canalización simplificada: La función de canalización es una API de alto nivel que gestiona todos los pasos complejos, como el preprocesamiento de texto, la inferencia del modelo y el formato de la salida, en solo unas pocas líneas de código.
Variedad de modelos: no estás limitado a una sola opción. Puedes elegir entre un amplio intervalo de arquitecturas como BART, T5 y Pegasus, cada una con diferentes puntos fuertes, tamaños y características de rendimiento.
Flexibilidad del marco: la biblioteca Transformers funciona a la perfección con los dos marcos de aprendizaje profundo más populares, PyTorch y TensorFlow. Puede utilizar el que su equipo ya conozca mejor.
Soporte de la comunidad: gracias a la amplia documentación, los cursos oficiales y una comunidad activa de desarrolladores, es fácil encontrar tutoriales y obtener ayuda cuando surgen problemas.
Aunque Hugging Face es increíblemente potente para los desarrolladores, es importante recordar que se trata de una solución basada en código. Requiere conocimientos técnicos para su implementación y mantenimiento. Esto no siempre es lo más adecuado para equipos sin conocimientos técnicos que solo necesitan resumir su trabajo.
🧐 ¿Sabías que...? La biblioteca Transformers de Hugging Face popularizó el uso de modelos de PLN de última generación con unas pocas líneas de código, por lo que los prototipos para resumir suelen empezar por ahí.
¿Qué son los transformadores Hugging Face?
Así que ha decidido utilizar Hugging Face, pero ¿cuál es la tecnología real que hace el trabajo? La tecnología central es una arquitectura llamada Transformer. Cuando se presentó en un artículo de 2017 titulado «Attention Is All You Need» (La atención es todo lo que necesitas), cambió por completo el campo del PLN.
Antes de Transformers, los modelos tenían dificultades para comprender el contexto de las oraciones largas. La innovación clave de Transformer es el mecanismo de atención, que permite al modelo sopesar la importancia de las diferentes palabras del texto de entrada al procesar una palabra específica. Esto le ayuda a captar las dependencias de largo alcance y a comprender el contexto, lo cual es crucial para crear resúmenes coherentes.
La biblioteca Hugging Face Transformers es un paquete de Python que te facilita enormemente el uso de estos complejos modelos. No necesitas un doctorado en aprendizaje automático. La biblioteca se encarga de todo el trabajo pesado.
Los tres componentes básicos que debes conocer
- Tokenizadores: los modelos no entienden las palabras, entienden los números. Un tokenizador toma el texto introducido y lo convierte en una secuencia de tokens numéricos, un proceso denominado tokenización, que el modelo puede procesar.
- Modelos: Son las propias redes neuronales preentrenadas. Para resumir, suelen ser modelos de secuencia a secuencia con una estructura de codificador-decodificador. El codificador lee el texto de entrada para crear una representación numérica, y el decodificador utiliza esa representación para generar el resumen.
- Pipelines: Esta es la forma más fácil de utilizar un modelo. Una pipeline agrupa un modelo preentrenado con su tokenizador correspondiente y se encarga de todos los pasos de preprocesamiento de la entrada y posprocesamiento de la salida por ti.
Dos de los modelos más populares para el resumen son BART y T5. BART (Bidirectional and Auto-Regressive Transformer) es especialmente bueno en el resumen abstractivo, ya que produce resúmenes que se leen con mucha naturalidad. T5 (Text-to-Text Transfer Transformer) es un modelo versátil que enmarca todas las tareas de PLN como un problema de texto a texto, lo que lo convierte en una potente herramienta polivalente.
🎥 Mira este vídeo para ver una comparación de los mejores resumidores de PDF con IA y descubrir qué herramientas ofrecen los resúmenes más rápidos y precisos sin perder el contexto.
Cómo crear un resumidor de texto con Hugging Face
¿Listo para crear tu propio ejemplo de resumen? Solo necesitas algunos conocimientos básicos de Python, un editor de código como VS Code y una conexión a internet. Todo el proceso consta de solo cuatro pasos. Tendrás un resumen funcional en cuestión de minutos.
Paso 1: Instala las bibliotecas necesarias.
En primer lugar, debe instalar las bibliotecas necesarias. La principal es transformers. También necesitará un marco de aprendizaje profundo como PyTorch o TensorFlow. Para este ejemplo, utilizaremos PyTorch.
Abre tu terminal o símbolo del sistema y ejecuta el siguiente comando:

Algunos modelos, como T5, también requieren la biblioteca sentencepiece para su tokenizador. Es recomendable instalarla también.

💡 Consejo profesional: Crea un entorno virtual Python antes de instalar estos paquetes. Esto mantiene aisladas las dependencias de tu proyecto y evita conflictos con otros proyectos en tu máquina.
Paso 2: Cargar el modelo y el tokenizador
La forma más fácil de empezar es utilizando la función pipeline. Esta función se encarga automáticamente de cargar el modelo y el tokenizador correctos para la tarea de resumir.
En tu script de Python, importa el pipeline e inicialízalo así:

Aquí especificamos dos cosas:
La tarea: Le indicamos al proceso que queremos realizar una «resumación».
El modelo: Elegimos un punto de control específico de un modelo preentrenado del Hugging Face Hub. facebook/bart-large-cnn es una opción popular entrenada con artículos de noticias y funciona bien para resumir contenidos de uso general. Para realizar pruebas más rápidas, puede utilizar un modelo más pequeño como t5-small.
La primera vez que ejecute este código, se descargarán los pesos del modelo desde el hub, lo que puede tardar unos minutos. Después, el modelo se almacenará en la caché de su equipo local para que se cargue al instante.
Paso 3: Crear la función de resumen
Para que tu código sea limpio y reutilizable, lo mejor es envolver la lógica de resumen en una función. Esto también facilita la experimentación con diferentes parámetros.
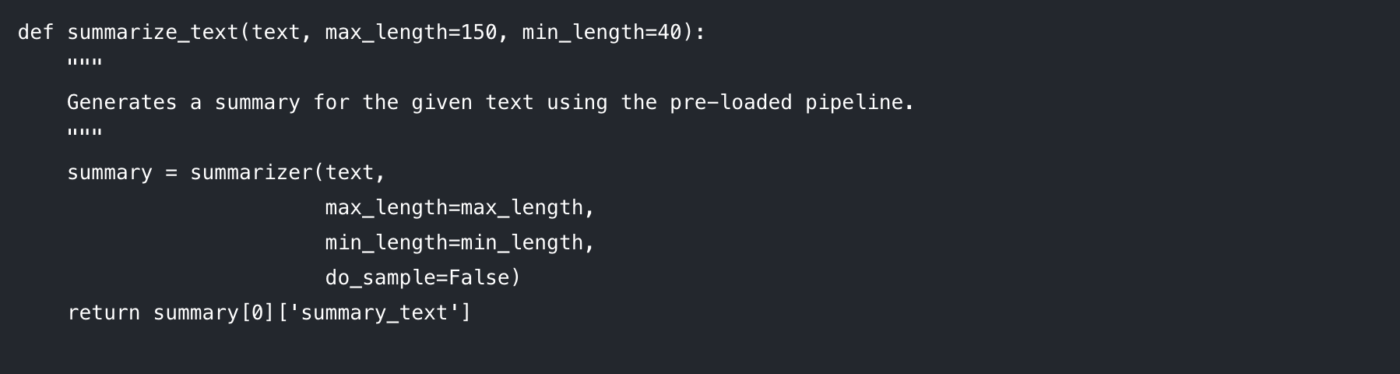
Analicemos los parámetros que puedes controlar:
max_length: Establece el número máximo de tokens (aproximadamente, palabras) para el resumen de salida.
min_length: Establece el número mínimo de tokens para evitar que el modelo genere resúmenes demasiado cortos o vacíos.
do_sample: Cuando se establece en False, el modelo utiliza un método determinista (como la búsqueda por haz) para generar el resumen más probable. Al establecerlo en True se introduce aleatoriedad, lo que puede producir resultados más creativos pero menos predecibles.
Ajustar estos parámetros es clave para obtener la calidad de salida que deseas.
Paso 4: Genere su resumen
Ahora viene la parte divertida. Pasa tu texto a la función e imprime el resultado. 🤩

Deberías ver una versión resumida del artículo impresa en tu consola. Si tienes algún problema, aquí tienes algunas soluciones rápidas:
El texto introducido es demasiado largo: el modelo puede generar un error si la entrada supera su longitud máxima (a menudo 512 o 1024 tokens). Añade truncation=True dentro de la llamada al resumidor () para cortar automáticamente las entradas largas.
El resumen es demasiado genérico: Intente aumentar el parámetro num_beams (por ejemplo, num_beams=4). Esto hace que el modelo busque más a fondo un resumen mejor, pero puede ser ligeramente más lento.
Este enfoque basado en código es fantástico para los desarrolladores que crean aplicaciones personalizadas. Pero, ¿qué ocurre cuando necesitas integrarlo en el trabajo diario de un equipo? Ahí es donde empiezan a aparecer los límites.
Limitaciones de Hugging Face para el resumen de textos
Hugging Face es una excelente opción cuando se busca flexibilidad y control. Pero una vez que se intenta utilizarlo para flujos de trabajo reales en equipo (no solo en un cuaderno de demostración), rápidamente surgen algunos retos previsibles.
Límites de tokens y dolores de cabeza con documentos largos
La mayoría de los modelos de resumen tienen una longitud máxima de entrada fija. Por ejemplo, facebook/bart-large-cnn está configurado con max_position_embeddings = 1024. Eso significa que los documentos más largos a menudo requieren truncamiento o fragmentación.
Si solo necesita una referencia rápida, puede habilitar el truncamiento en el proceso y continuar. Pero si necesita resúmenes fieles de documentos largos, normalmente terminará creando una lógica de fragmentación y luego realizando una segunda pasada, un «resumen de resúmenes», para unir los resultados. Eso supone un trabajo de ingeniería adicional y es fácil obtener resultados inconsistentes.
Riesgo de alucinación (y el impuesto de verificación)
Los modelos abstractivos pueden a veces dar lugar a alucinaciones, generando textos que parecen plausibles pero que son incorrectos desde el punto de vista factual. Para usos críticos para la empresa, esto crea un problema: cada resumen necesita una verificación manual. En ese momento, no se está ahorrando tiempo realmente, sino que se está trasladando el trabajo a otra parte del proceso.
Falta de conciencia del contexto
Un modelo Hugging Face solo conoce el texto que le proporcionas. No comprende las metas de tu proyecto, las personas involucradas o cómo se relacionan unos documentos con otros, ya que carece de la inteligencia contextual de los sistemas modernos. No puede decirte si un resumen de una llamada de un cliente contradice el documento de requisitos del proyecto, porque vive aislado.
Sobrecarga de integración (el problema de la «última milla»)
Generar un resumen suele ser la parte fácil. La verdadera dificultad está en lo que viene después.
¿A dónde va el resumen? ¿Quién lo ve? ¿Cómo se convierte en una tarea ejecutable? ¿Cómo se conecta con el trabajo que lo ha desencadenado?
Resolver esa «última milla» significa crear integraciones personalizadas y código de enlace. Eso añade trabajo previo para los desarrolladores y, a menudo, crea un flujo de trabajo torpe para todos los demás.
Barrera técnica y mantenimiento continuo
Un enfoque basado en Python es accesible principalmente para personas que saben escribir código. Esto supone una barrera práctica para los equipos de marketing, equipo de ventas y operaciones, lo que significa que su adopción sigue teniendo un límite.
También incluye mantenimiento continuo: gestión de dependencias, actualización de bibliotecas y mantenimiento de todo el sistema a medida que evolucionan las API y los modelos. Lo que comienza como una victoria rápida puede convertirse silenciosamente en otro sistema que hay que supervisar.
📮 ClickUp Insight: El 42 % de las interrupciones en el trabajo provienen de tener que hacer malabarismos con las plataformas, gestionar los correos electrónicos y saltar de una reunión a otra. ¿Y si pudieras eliminar estas costosas interrupciones? ClickUp une tus flujos de trabajo (y el chat) en una única plataforma optimizada. Inicia y gestiona tus tareas desde el chat, los documentos, las pizarras y mucho más, mientras que las funciones basadas en la IA mantienen el contexto conectado, buscable y gestionable.
El problema más grave: la proliferación del contexto
Incluso si tu script para resumir funciona perfectamente, tu equipo puede seguir perdiendo tiempo porque el resultado está desconectado del lugar donde realmente se realiza el trabajo.
Eso es la dispersión del contexto, cuando los equipos pierden horas buscando información, cambiando de una aplicación a otra y buscando archivos en plataformas desconectadas.
Aquí es donde un espacio de trabajo convergente cambia las reglas del juego. En lugar de generar resúmenes en un solo lugar e intentar «trasladarlos al trabajo» más tarde, un sistema convergente mantiene juntos los proyectos, los documentos y las conversaciones, con ClickUp Brain integrado como capa de inteligencia. Tus resúmenes permanecen conectados a las tareas y a los documentos, por lo que el siguiente paso es obvio y el traspaso es inmediato.
Resúmenes que se convierten en acciones con ClickUp
Un script de resumen puede funcionar perfectamente y, aun así, fallar a su equipo de una forma molesta: el resumen acaba quedando separado del trabajo.
Esa brecha crea una dispersión del contexto, en la que la información se encuentra dispersa en documentos, hilos de chat, tareas y «notas rápidas» en herramientas que no están conectadas entre sí. Las personas dedican más tiempo a buscar el resumen que a utilizarlo. La verdadera ventaja no es solo generar un resumen, sino mantenerlo adjunto a las decisiones, los propietarios y los siguientes pasos donde realmente se lleva a cabo el trabajo.
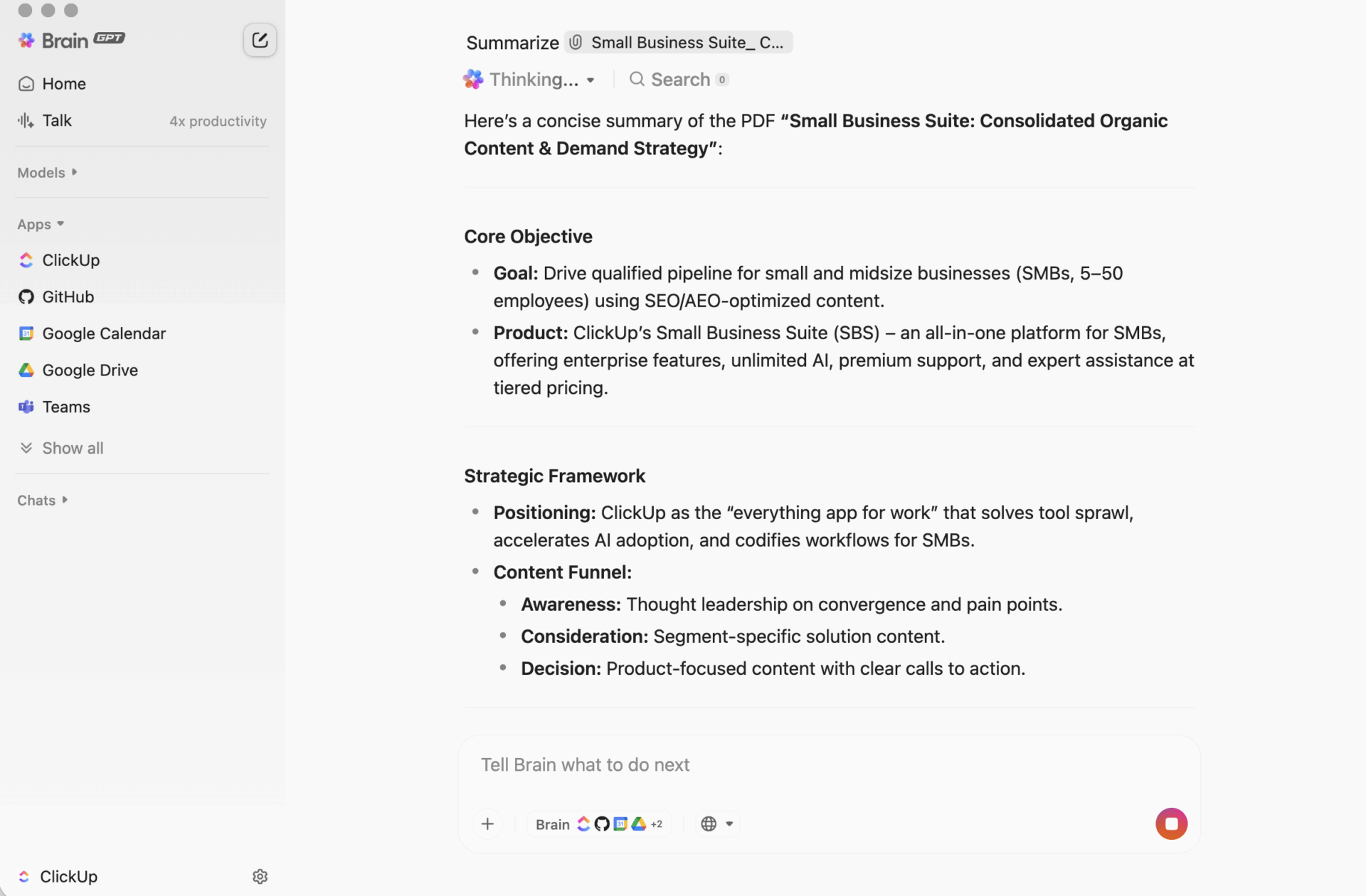
Eso es lo que hace ClickUp Brain de forma diferente. Resumir tareas, documentos y conversaciones dentro del mismo entorno de trabajo donde se encuentran tus proyectos, para que tu equipo pueda comprender algo y actuar en consecuencia sin tener que cambiar de herramienta.

ClickUp BrainGPT: interactúa con los resúmenes utilizando lenguaje natural
En el escritorio, BrainGPT es la interfaz conversacional para ClickUp Brain. En lugar de abrir scripts, cuadernos o herramientas de IA externas, su equipo puede solicitar lo que necesita en lenguaje sencillo, directamente en ClickUp.
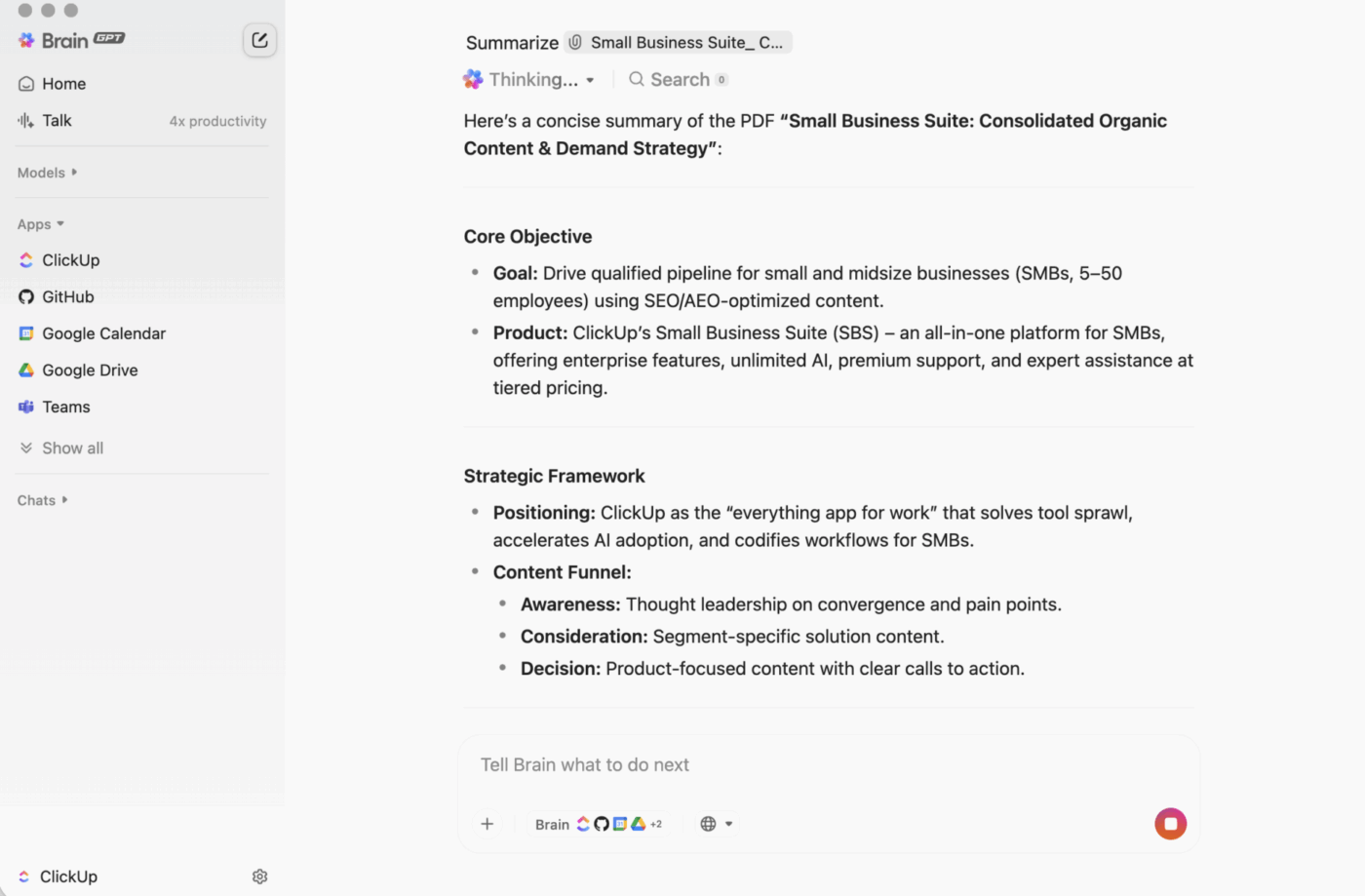
Puede escribir (o utilizar la función de voz a texto) para:
- Resumir una descripción de tarea larga, un hilo de comentarios o un documento.
- Continúa con preguntas como «¿Cuáles son los siguientes pasos?» o «¿Quién es el responsable de esto?».
- Convierte un resumen en acción creando tareas a partir de él, con propietarios y fechas límite.
Dado que ClickUp Brain funciona dentro de tu entorno de trabajo, el resultado se basa en el contexto en tiempo real: descripciones de tareas, comentarios, subtareas, documentos enlazados y estructura del proyecto. No tienes que pegar el texto en una herramienta independiente y esperar que no se pierda nada importante.
Por qué esto supera al flujo de trabajo de resumen basado en código para la mayoría de los equipos.
Un flujo de trabajo creado por desarrolladores puede generar resúmenes sólidos. La fricción aparece después, cuando alguien tiene que copiar el resultado en el lugar donde se realiza el trabajo, traducirlo en tareas y luego hacer un seguimiento.
ClickUp Brain cierra ese círculo:
No se requiere programación Cualquier miembro del equipo puede resumir un documento, un hilo de tareas o un conjunto desordenado de comentarios sin necesidad de instalar nada ni escribir código.
Resúmenes que tienen en cuenta el contextoClickUp Brain puede incluir las partes que la gente suele olvidar: decisiones ocultas en los comentarios, obstáculos mencionados en las respuestas, subtareas que cambian el significado de «terminado».
Los resúmenes viven donde vive el trabajoPuedes ponerte al día dentro de una tarea, añadir un resumen en la parte superior de ClickUp Docs o recapitular rápidamente una discusión sin crear otro «documento de resumen» que nadie consulta.
Menos proliferación de herramientas No necesitas scripts separados, cuadernos Jupyter, claves de API ni un flujo de trabajo que solo una persona entiende. Tus documentos, tareas y resúmenes permanecen en el mismo sistema.
Esta es la ventaja práctica de un entorno de trabajo convergente: se resumen los datos, se lleva a cabo la acción y se realiza la colaboración al mismo tiempo, en lugar de unirse a posteriori.
Esta es la ventaja práctica de un entorno de trabajo convergente: se resumen, ejecutan acciones y se realizan colaboraciones al mismo tiempo, en lugar de unirse a posteriori.
Cómo funciona en la vida real
Estos son algunos patrones comunes que utilizan los equipos:
- Resuma un hilo de comentarios: abra una tarea con una discusión larga, haga clic en la opción de IA y obtenga un resumen rápido de lo que ha cambiado y lo que es importante.
- Resumir un documento: abra un documento de ClickUp y utilice «Ask IA» para generar un resumen de la página, de modo que cualquiera pueda orientarse rápidamente.
- Extraiga elementos de acción: tome el resumen y convierta inmediatamente los siguientes pasos en tareas con personas asignadas y fechas límite, para que el impulso no se pierda en el traspaso.
| Capacidad | Hugging Face (basado en código) | ClickUp Brain |
|---|---|---|
| Configuración necesaria | Entorno Python, bibliotecas, código. | Ninguno, integrado |
| Conciencia del contexto | Solo texto (lo que usted introduce) | Contexto completo del entorno de trabajo (tareas, documentos, comentarios, subtareas) |
| Integración del flujo de trabajo | Exportación/importación manual | Nativo: los resúmenes pueden convertirse en tareas y actualizaciones. |
| Habilidades técnicas necesarias | Nivel de desarrollador | Cualquier miembro del equipo. |
| Mantenimiento | Mantenimiento continuo del modelo y el código. | Actualizaciones automáticas |
De los resúmenes a la ejecución con Super Agents.
Los resúmenes son útiles. Lo difícil es asegurarse de que se conviertan sistemáticamente en acciones, especialmente cuando el volumen aumenta.
Ahí es donde entran en juego los ClickUp Super Agents . Pueden utilizar la información resumida y avanzar en el trabajo basándose en desencadenantes y condiciones, dentro del mismo entorno de trabajo.
Con Super Agents, los equipos pueden:
- Resuma los cambios según un calendario (resumen semanal del proyecto, agregados diarios del estado).
- Extraiga elementos de acción y asigne propietarios automáticamente.
- Marca el trabajo estancado (tareas atascadas en revisión, hilos sin respuesta, próximos pasos vencidos).
- Mantenga alta la visibilidad del liderazgo sin la elaboración de informes manuales.
En lugar de un resumen que se queda como texto estático, los agentes ayudan a garantizar que el resumen se convierta en un plan y que el plan se convierta en progreso.
Resúmenes que viven donde se desarrolla el trabajo.
Los transformadores de Hugging Face son ideales cuando necesitas una aplicación personalizada, un proceso a medida o un control total sobre el comportamiento del modelo.
Pero para la mayoría de los equipos, el mayor problema no es «¿Podemos resumir esto?», sino «¿Podemos resumir esto y convertirlo inmediatamente en trabajo, con propietarios, plazos y visibilidad?».
Si tu meta es la productividad del equipo y la ejecución rápida, ClickUp Brain te ofrece resúmenes en contexto, justo donde se realiza el trabajo, con un camino claro desde «aquí está lo esencial» hasta «esto es lo que vamos a hacer a continuación».
¿Listo para saltarte la configuración y empezar a resumir donde realmente se desarrolla tu trabajo? Empieza gratis con ClickUp y deja que Brain se encargue del trabajo pesado.