

Sind Sie von Daten überflutet? Selbst die erfahrensten Datenexperten haben Mühe, mit der Flut von Daten Schritt zu halten, die in einer digitalisierten Welt generiert werden – ganz zu schweigen von dem Versuch, Prozesse effizienter zu gestalten. Von Webanalysen über Kundendaten bis hin zu Metriken sind Sie dafür verantwortlich, diese Daten so genau und aktuell wie möglich zu halten. ✨
Ein solides Datenbankdesign ist für die Erstellung und Pflege einer Datenbank für Ihr Unternehmen unerlässlich, aber selbst dann müssen Sie wissen, wie Sie Ihre Arbeit frei von Kreuzkontaminationen und Datenredundanzen halten können. Abhängigkeiten definieren die Beziehung zwischen Datenattributen, was Ihnen in allen Bereichen hilft, von der Datengenauigkeit bis hin zu erweiterten Erkenntnissen.
Der Clou? Es gibt so viele Arten von Abhängigkeiten zur Auswahl. Aber funktionale Abhängigkeiten sind ein Muss, wenn Sie darauf brennen, eine Datenbank zu erstellen.
In diesem Leitfaden erklären wir Ihnen, was eine funktionale Abhängigkeit ist, geben Ihnen einige Beispiele für alle funktionalen Abhängigkeiten und bieten Ihnen hilfreiche Tipps zur Optimierung Ihrer relationalen Datenbank.
Was ist eine funktionale Abhängigkeit?
Eine funktionale Abhängigkeit ist eine Art von Abhängigkeit, bei der eine Beziehung zwischen zwei Variablen besteht. Auf der linken Seite befindet sich das determinierende Attribut, auch Primärschlüssel genannt, und auf der rechten Seite das abhängige Attribut, auch Nicht-Schlüssel-Attribut genannt. Die Funktion oder das Ergebnis ändert sich je nach der Beziehung zwischen den beiden Variablen.
Wir wissen, dass das etwas kompliziert klingt, daher hier eine Erklärung, wie funktionale Abhängigkeiten funktionieren:
- Angenommen, Sie verwenden eine Kundendatenbank-Software zur Nachverfolgung der Geburtstage Ihrer Kunden. Sie möchten Ihren Kunden an ihrem Geburtstag eine benutzerdefinierte E-Mail senden, um die Kundenbindung zu stärken.
- Sie müssen eine funktionale Abhängigkeit verwenden, um jedem Benutzer an seinem Geburtstag eine E-Mail zu senden – schließlich würde eine irrelevante „Happy Birthday“-Nachricht an 300 Personen doch etwas seltsam wirken, oder?
- In diesem Fall besteht die Funktion zum Versenden einer E-Mail aus einer Abhängigkeit von der Variablen „Geburtstag des Kunden”.
- Wenn Sie diese Art von Beziehung in Ihrer Datenbank wünschen, müssen Sie eine funktionale Abhängigkeit zwischen dem Geburtstag des Kunden und der Funktion einrichten, die die E-Mail an seinem Geburtstag versendet.
Funktionale Abhängigkeiten sind für die Normalisierung von Datenbanken von grundlegender Bedeutung. Durch die Normalisierung organisieren Sie eine Datenbank – ähnlich wie beim Aufräumen eines Raums –, um Daten so anzuordnen, dass Wiederholungen vermieden werden.
Die Regeln funktionaler Abhängigkeiten in Datenbankmanagementsystemen
Funktionale Abhängigkeiten folgen mehreren Inferenzregeln, die auch als Armstrongs Axiome bezeichnet werden.
Es gibt drei wichtige Regeln für funktionale Abhängigkeiten:
- Reflexivität: Die Reflexivitätsregel besagt, dass wenn Attribut A mit Attribut X in Beziehung steht, dann steht Attribut X auch mit Attribut A in Beziehung. Als Beispiel: A ist der Vorname einer Person und X ist der Nachname einer Person. Diese beiden Attribute stehen immer in Beziehung zueinander.
- Erweiterung: Die Erweiterungsregel besagt, dass Sie, wenn Sie einer Variablen Daten hinzufügen (auch als Erweiterung bezeichnet), diese Erweiterung zum Attributsatz hinzufügen müssen. Wenn Sie also das Feld „Vorname” um einen Spitznamen erweitern, bezieht sich dieses Feld nun auch auf das Feld „Nachname”.
- Transitivität: Die Transitivitätsregel besagt, dass, wenn Attribut A mit Attribut C in Beziehung steht, durch Assoziation auch Attribut B gleich Attribut C ist. Lassen Sie sich davon nicht verwirren – transitive Abhängigkeit bedeutet, dass manchmal eine Sache eine andere bestimmt, die wiederum eine dritte Sache bestimmt. Wenn Sie beispielsweise in Ihrer CRM-Plattform Barcodes für Kunden auf der Grundlage ihres Vor- und Nachnamens generieren, bestimmt der Name die Position des Kunden in einer alphabetischen Liste.
Funktionale Abhängigkeiten verwandeln Ihre Datenmodelle mithilfe von SQL in ein tatsächliches Beziehungsschema, wodurch die Integrität Ihrer Daten gewahrt bleibt. In der Praxis können Sie funktionale Abhängigkeiten in Ihrem Datenbankmanagementsystem (DBMS) verwenden, um Datenredundanzen und „Hoppla“-Momente zu vermeiden, die Datenbanken beschädigen können. 👀
Vollständige funktionale Abhängigkeit versus teilweise funktionale Abhängigkeit
Bevor wir uns die verschiedenen Arten funktionaler Abhängigkeiten ansehen, ist es wichtig, zwischen partiellen und vollständigen funktionalen Abhängigkeiten zu unterscheiden.
Angenommen, Sie geben Ihre Organigrammdaten in eine Datenbank ein. Bei einer vollständigen funktionalen Abhängigkeit hängt ein Attribut von einem anderen Attributsatz ab, jedoch nicht von einer Teilmenge dieses Attributs. Nehmen wir also an, wir haben eine Kombination aus „Mitarbeitername“ und „Mitarbeiter-ID“, die einen „Speicherort“ bestimmt.
Wenn Sie den „Namen des Mitarbeiters” und die „Mitarbeiter-ID” kennen, können Sie den „Speicherort” bestimmen. Allerdings können Sie diese beiden Variablen nicht einzeln betrachten, um den „Speicherort” zu bestimmen. In diesem Fall besteht eine vollständige Abhängigkeit zwischen dem „Speicherort” und der Kombination aus „Name des Mitarbeiters” und „Mitarbeiter-ID”.
Eine partielle funktionale Abhängigkeit liegt vor, wenn ein Attribut nur von einem Teil des Primärschlüssels statt des zusammengesetzten Primärschlüssels abhängt. Wenn Sie beispielsweise das Feld „Arbeitsjahre” mit „Mitarbeiter-ID” ermitteln können, liegt eine partielle Abhängigkeit vor, da „Arbeitsjahre” nicht von „Standort” abhängt.
Das mag nach einem kleinen Unterschied klingen, hat jedoch große Auswirkungen auf die Datennormalisierung. Partielle funktionale Abhängigkeiten können zu Redundanzen in Ihrer Datenbank führen, was bedeutet, dass Sie diese im zweiten Normalform-Schritt des Normalisierungsprozesses (2NF) beheben müssen. Das ist zwar kein Weltuntergang, aber definitiv etwas, das Sie später beheben müssen. 🛠️
Erste, zweite und dritte Normalform in SQL
Das Ziel der Datennormalisierung ist es, alle Anomalien beim Einfügen, Aktualisieren oder Löschen in Ihrer Datenbank zu beseitigen, die zu Chaos führen können. Die Normalisierung mit funktionalen Abhängigkeiten erfolgt in drei Schritten.
Erste Normalform
Betrachten Sie die erste Normalform als Grundlage für den Aufbau eines Systems, in dem Sie funktionale Abhängigkeiten verwenden können. Sie bildet die Grundlage für die Identifizierung von Abhängigkeiten in der zweiten und dritten Normalform. Technisch gesehen enthält 1NF Attribute, die nur atomare Werte enthalten, wodurch sichergestellt wird, dass sich keine Gruppen wiederholen.
Zweite Normalform
Nachdem Sie die Daten durch 1NF geschickt haben, erhalten Sie eine Tabelle, in der alle Nicht-Schlüsselattribute vollständig funktional vom Primärschlüssel abhängig sind. In 2NF entfernen Sie partielle Abhängigkeiten, indem Sie Tabellen aufteilen, um sicherzustellen, dass jedes Nicht-Schlüsselattribut vollständig vom Primärschlüssel abhängig ist.
Dritte Normalform
Nachdem eine Datentabelle in 2NF ist, geht sie zu 3NF über, sobald alle Attribute nur funktional vom Primärschlüssel abhängig sind und von nichts anderem. In 3ND entfernen Sie in dieser Phase alle transitiven Abhängigkeiten durch weitere Tabellenteilung.
1NF bildet die Grundlage für funktionale Abhängigkeiten, während 2NF und 3NF die Organisation dieser Daten durch die Umstrukturierung der funktionalen Abhängigkeiten verfeinern. Dadurch wird sichergestellt, dass Sie jedes Datenfragment an der logischsten Stelle speichern, wodurch Redundanzen reduziert und die Datenintegrität verbessert werden.
Arten funktionaler Abhängigkeiten mit Beispielen
Wenn Sie bereit sind, funktionale Abhängigkeiten zu verwenden, stehen Ihnen vier Optionen zur Auswahl.
Trivial
Eine triviale Abhängigkeit ist eine grundlegende Art der funktionalen Abhängigkeit, bei der ein Attribut oder eine Reihe von Attributen sich selbst bestimmt. Jede einzelne Abhängigkeit ist hier eine Teilmenge Ihrer Determinante. Mit anderen Worten: Wenn C eine Teilmenge von A ist, ist die funktionale Beziehung trivial.
Es mag etwas offensichtlich klingen, aber ein Beispiel wäre die Identifizierung des Titels eines Buches, wenn Sie sowohl den Titel als auch den Verfasser kennen. Die Beziehung zwischen diesen beiden Attributen ist ziemlich leicht zu erkennen, weshalb triviale funktionale Abhängigkeiten am einfachsten zu verstehen sind.
Nicht trivial
Hier wird es interessant. Bei einer nicht trivialen funktionalen Abhängigkeit kann ein Attribut ein anderes eindeutiges Attribut bestimmen. In diesem Fall ist A eine Sammlung von Attributen, ebenso wie B, aber B ist keine Teilmenge von A. Wenn B keine Teilmenge von A ist, haben sie eine nicht triviale Beziehung.
Sie haben eine nicht triviale Beziehung, wenn Sie eine Datenbank mit Büchern erstellen, jedem Buch einen eindeutigen Code zuweisen und den Titel des Buches nachschlagen können, wenn Sie den dem Buch zugewiesenen Code kennen.
Mehrwertig
Bei einer mehrwertigen Abhängigkeit ist ein Attribut mit mehreren anderen Attributen verbunden. Die Attribute in Ihrer Gruppe von Abhängigkeiten sind nicht voneinander abhängig. Wenn also die Attribute A und C keine funktionale Abhängigkeit aufweisen, ist die Beziehung zwischen B, A und C mehrwertig.
Um bei der Buchanalogie zu bleiben: Das ist wie bei einem Verfasser, der viele Bücher geschrieben hat. Wenn Sie seinen Namen kennen, können Sie eine Liste aller Bücher erstellen, die er geschrieben hat. Bei einer mehrwertigen funktionalen Abhängigkeit sind mit dem Namen eines Verfassers mehrere Bücher verknüpft.
Transitiv
Eine transitive funktionale Abhängigkeit liegt vor, wenn ein Attribut ein anderes und dann ein weiteres bestimmt. Das ist so etwas wie eine Kettenreaktion. Wenn Ihnen das bekannt vorkommt, dann liegt das daran, dass diese Art der funktionalen Abhängigkeit der Regel der Transitivität folgt.
In diesem Fall muss A gleich C sein, wenn A gleich B und B gleich C ist. Nehmen wir an, Sie erstellen eine Buchdatenbank, und Ihre eindeutigen Buchcodes bestimmen die Verlage und deren Genres. Wenn Sie den Buchcode kennen, können Sie herausfinden, wer der Verlag ist und zu welchem Genre das Buch gehört.
Verwendung funktionaler Abhängigkeiten für die Datenbankverwaltung
Möchten Sie funktionale Abhängigkeiten nutzen? Sie können funktionale Abhängigkeiten nach Belieben einsetzen, aber wenn Sie smarter und mit weniger Aufwand arbeiten möchten, entscheiden Sie sich für ClickUp.
Hier finden Sie eine kurze Übersicht darüber, wie Sie in ClickUp eine Datenbank erstellen und funktionale Abhängigkeiten einbinden können:
Zunächst müssen Sie eine Datenbank in ClickUp einrichten. Sie können Datenblätter aus Excel importieren oder eigene Datenblätter von Grund auf neu erstellen.
Die Tabelle von ClickUp ermöglicht die Massenbearbeitung und andere benutzerdefinierte Ansichten zur Nachverfolgung von Daten nahezu für alles. ClickUp visualisiert außerdem Daten, damit Sie Ihre Datenbank in Rekordzeit abschließen können.
Die gute Nachricht ist, dass Sie hier nicht bei Null anfangen müssen. Mit den Datenbankvorlagen von ClickUp ist die Erstellung von Datenbanken ein Kinderspiel.
Die ClickUp-Blog-Datenbankvorlage ist äußerst hilfreich für die Inhaltsplanung, und die ClickUp-Mitarbeiterverzeichnisvorlage eignet sich perfekt für die schnelle Erstellung einer Datenbank mit Kontaktinformationen für Kollegen. Auch hierbei handelt es sich um eine No-Code-Datenbank. Wenn Sie also eine Datenbank erstellen möchten, ohne SQL zu lernen, sind Sie bei uns genau richtig.
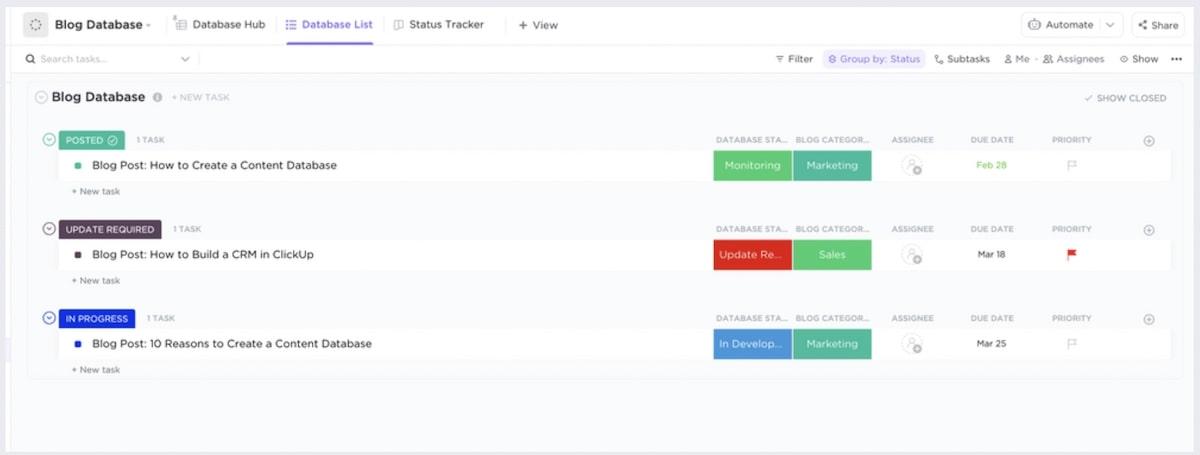
Funktionale Abhängigkeiten in ClickUp integrieren
Normalerweise müssten Sie sich intensiv mit SQL auseinandersetzen, um funktionale Abhängigkeiten in einer Datenbank zu erstellen. Glücklicherweise macht die Drag-and-Drop-Oberfläche von ClickUp das Erstellen von Beziehungen zwischen Aufgaben und Dokumenten zum Kinderspiel. Es schadet auch nicht, dass die KI-Tools in ClickUp die Datenbankverwaltung zum Kinderspiel machen – selbst wenn Sie selbst kein Datenbankprofi sind.
So erstellen Sie eine Abhängigkeit in Ihrer ClickUp-Datenbank.
Klicken Sie zunächst auf die Aufgabe, mit der Sie arbeiten möchten.
Gehen Sie zu „Beziehungen“ > „Abhängigkeit“. Wählen Sie zwischen „Warten auf“, „Blockieren“ und „Aufgaben“, um die Beziehung benutzerdefiniert anzupassen.

In diesem Fall wählen wir Warten auf und suchen nach einer anderen Aufgabe, die mit der aktuellen Aufgabe in Zusammenhang steht.
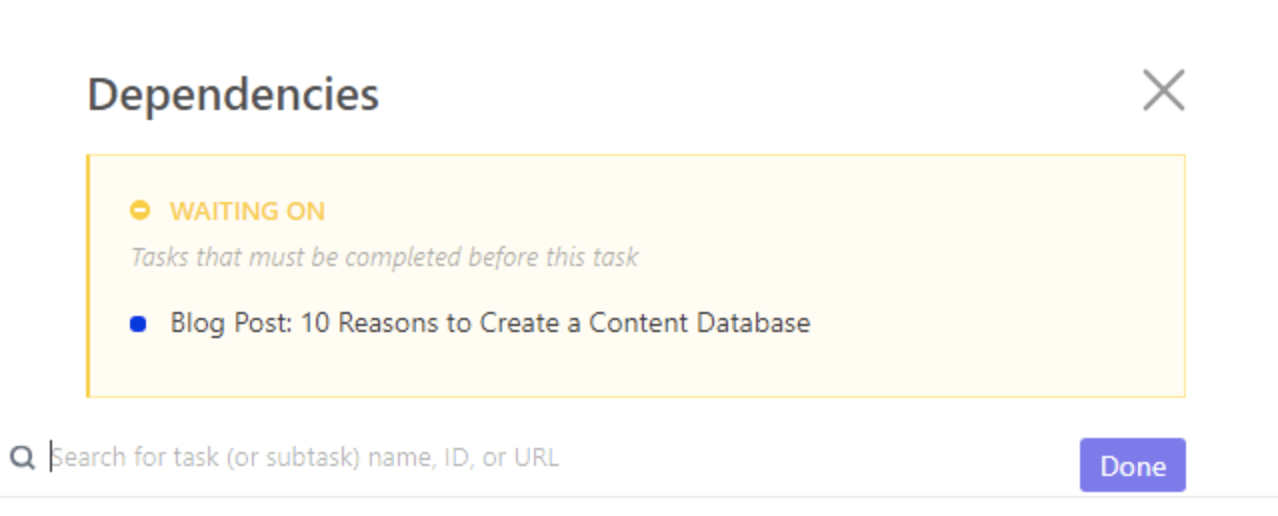
Klicken Sie auf „Erledigt“ und schon ist es erledigt! 🙌
Vereinfachen Sie Abhängigkeiten mit ClickUp
Wer sagt, dass Datenbankverwaltung kompliziert sein muss? Solange Sie die Abhängigkeiten zwischen den Funktionen genau verstehen, können Sie eine schnelle und präzise Datenbank entwerfen, die Ihr Unternehmen voranbringt.
Sie müssen das auch nicht alleine erledigen. ClickUp ist ein solides Datenbankmanagementsystem, das Daten mit Vorlagen, Projekten, Aufgaben, Zielen und allem dazwischen kombiniert.
Sparen Sie mehr Zeit und konzentrieren Sie sich auf hochwertige Aufgaben, indem Sie auf die echte All-in-One-Plattform von ClickUp umsteigen.
Probieren Sie es selbst aus: Erstellen Sie ein kostenloses ClickUp-Konto, um eine bessere Datenbank aufzubauen!