
Die meisten Entwickler, die ein Hugging Face-Zusammenfassungsskript erstellen, stoßen auf dasselbe Problem: Die Zusammenfassung funktioniert in ihrem Terminal einwandfrei. Aber sie kann nur selten eine Verbindung zu der eigentlichen Arbeit herstellen, die sie unterstützen soll.
Dieser Leitfaden führt Sie durch die Erstellung eines Text-Summarizers mit der Transformers-Bibliothek von Hugging Face und zeigt Ihnen dann, warum selbst eine fehlerfreie Implementierung mehr Probleme schaffen als lösen kann, wenn Ihr Team Zusammenfassungen benötigt, die tatsächlich mit Aufgaben, Projekten und Entscheidungen in Verbindung stehen.
Was ist Textzusammenfassung?
Teams versinken in Informationen. Sie sehen sich mit langwierigen Dokumenten, endlosen Protokollen von Meetings, komplexen Forschungsarbeiten und Quartalsberichten konfrontiert, deren manuelle Auswertung Stunden in Anspruch nimmt. Diese ständige Informationsüberflutung verlangsamt die Entscheidungsfindung und beeinträchtigt die Produktivität.
Bei der Textzusammenfassung wird mithilfe von Natural Language Processing (NLP) der Inhalt zu einer kurzen, zusammenhängenden Version verdichtet, die die wichtigsten Informationen enthält. Stellen Sie sich das als eine Art Instant-Zusammenfassung für jedes Dokument vor. Diese NLP-Zusammenfassungstechnologie verwendet in der Regel einen von zwei Ansätzen:
Extraktive Zusammenfassung: Bei dieser Methode werden die wichtigsten Sätze direkt aus dem Quelltext identifiziert und extrahiert. Das ist so, als würde ein Textmarker automatisch die Schlüsselpunkte für Sie herausgreifen. Die endgültige Zusammenfassung ist eine Sammlung von Original-Sätzen.
Abstrakte Zusammenfassung: Diese fortgeschrittenere Methode generiert völlig neue Sätze, um die Kernaussage des Ausgangstextes zu erfassen. Sie paraphrasiert die Informationen, was als Ergebnis eine flüssigere und menschenähnlichere Zusammenfassung ergibt, ähnlich wie eine Person eine lange Geschichte mit ihren eigenen Worten erklären würde.
Die Ergebnisse davon sehen Sie überall. Es wird verwendet, um Meeting-Notizen zu Aktionspunkten zu verdichten, Kundenfeedback zu Trends zu destillieren und schnelle Übersichten über Projektdokumentationen zu erstellen. Das Ziel ist immer dasselbe: die wesentlichen Informationen zu erhalten, ohne jedes einzelne Wort lesen zu müssen.
📮 ClickUp Insight: Der durchschnittliche Berufstätige verbringt täglich mehr als 30 Minuten mit der Suche nach arbeitsbezogenen Informationen. Das sind über 120 Stunden pro Jahr, die für das Durchsuchen von E-Mails, Slack-Threads und verstreuten Dateien verloren gehen. Ein intelligenter KI-Assistent, der in Ihrem Workspace eingebettet ist, kann das ändern. ClickUp Brain liefert sofortige Einblicke und Antworten, indem es in Sekundenschnelle die richtigen Dokumente, Unterhaltungen und Aufgaben-Details anzeigt, sodass Sie mit der Suche aufhören und mit der Arbeit beginnen können.
💫 Echte Ergebnisse: Teams wie QubicaAMF haben durch den Einsatz von ClickUp mehr als 5 Stunden pro Woche und über 250 Stunden pro Jahr und Person eingespart, indem sie veraltete Wissensmanagementprozesse abgeschafft haben.
Warum Hugging Face für die Zusammenfassung von Texten verwenden?
Ein benutzerdefiniertes Textzusammenfassungsmodell von Grund auf neu zu erstellen, ist ein gewaltiges Unterfangen. Es erfordert enorme Datensätze für das Training, leistungsstarke und teure Rechenressourcen sowie ein Team von Experten für maschinelles Lernen. Diese hohe Einstiegsbarriere hält die meisten Engineering- und Produktteams davon ab, jemals damit anzufangen.
Hugging Face ist die Plattform, die dieses Problem löst. Es handelt sich um eine Open-Source-Community und Datenwissenschaftsplattform, die Ihnen Zugriff auf Tausende von vortrainierten Modellen bietet und damit die LLM-Zusammenfassung für Entwickler effektiv demokratisiert. Anstatt von Grund auf neu zu entwickeln, können Sie mit einem leistungsstarken Modell beginnen, das bereits zu 99 % fertig ist.
Hier erfahren Sie, warum so viele Entwickler auf Hugging Face setzen: 🛠️
Zugriff auf vortrainierte Modelle: Der Hugging Face Hub ist ein riesiges Repository mit über 2 Millionen öffentlichen Modellen, die von Unternehmen wie Google, Meta und OpenAI trainiert wurden. Sie können diese hochmodernen Checkpoints für Ihre eigenen Projekte herunterladen und verwenden.
Vereinfachte Pipeline-API: Die Pipeline-Funktion ist eine hochentwickelte API, die alle komplexen Schritte wie Textvorverarbeitung, Modellinferenz und Ausgabeformatierung mit nur wenigen Zeilen Code erledigt.
Modellvielfalt: Sie sind nicht auf eine Option festgelegt. Sie können aus einem breiten Bereich von Architekturen wie BART, T5 und Pegasus wählen, die jeweils unterschiedliche Stärken, Größen und Leistungsmerkmale aufweisen.
Flexibilität des Frameworks: Die Transformers-Bibliothek funktioniert nahtlos mit den beiden beliebtesten Deep-Learning-Frameworks, PyTorch und TensorFlow. Sie können das Framework verwenden, mit dem Ihr Team bereits vertraut ist.
Community-Support: Dank umfangreicher Dokumentation, offiziellen Kursen und einer aktiven Entwickler-Community finden Sie leicht Tutorials und erhalten Hilfe, wenn Sie auf Probleme stoßen.
Hugging Face ist zwar für Entwickler unglaublich leistungsstark, aber man darf nicht vergessen, dass es sich um eine code-basierte Lösung handelt. Die Implementierung und Wartung erfordert technisches Fachwissen. Dies ist nicht immer die richtige Lösung für nicht-technische Teams, die lediglich ihre Arbeit zusammenfassen möchten.
🧐 Wussten Sie schon? Die Transformers-Bibliothek von Hugging Face hat es möglich gemacht, modernste NLP-Modelle mit wenigen Zeilen Code zu verwenden, weshalb Zusammenfassungsprototypen oft dort beginnen.
Was sind Hugging Face Transformers?
Sie haben sich also für Hugging Face entschieden, aber wie funktioniert die Technologie eigentlich? Die Kerntechnologie ist eine Architektur namens Transformer. Als sie 2017 in einem Artikel mit dem Titel „Attention Is All You Need“ vorgestellt wurde, hat sie das Feld der natürlichen Sprachverarbeitung (NLP) komplett verändert.
Vor Transformers hatten Modelle Schwierigkeiten, den Kontext langer Sätze zu verstehen. Die Schlüsselinnovation von Transformer ist der Aufmerksamkeitsmechanismus, der es dem Modell ermöglicht, bei der Verarbeitung eines bestimmten Wortes die Bedeutung verschiedener Wörter im Text zu gewichten. Dies hilft ihm, in einem breiten Bereich von Abhängigkeiten zu erfassen und den Kontext zu verstehen, was für die Erstellung kohärenter Zusammenfassungen entscheidend ist.
Die Hugging Face Transformers-Bibliothek ist ein Python-Paket, mit dem Sie diese komplexen Modelle unglaublich einfach verwenden können. Sie benötigen keinen Doktortitel in maschinellem Lernen. Die Bibliothek übernimmt die schwierigen Aufgaben für Sie.
Die drei Kernkomponenten, die Sie kennen müssen
- Tokenizer: Modelle verstehen keine Wörter, sondern Zahlen. Ein Tokenizer nimmt Ihren Text und wandelt ihn in eine Folge von numerischen Tokens um – ein Prozess, der als Tokenisierung bezeichnet wird – den das Modell verarbeiten kann.
- Modelle: Dies sind die vortrainierten neuronalen Netze selbst. Für die Zusammenfassung handelt es sich in der Regel um Sequenz-zu-Sequenz-Modelle mit einer Encoder-Decoder-Struktur. Der Encoder liest den Text, um eine numerische Darstellung zu erstellen, und der Decoder verwendet diese Darstellung, um die Zusammenfassung zu generieren.
- Pipelines: Dies ist die einfachste Art, ein Modell zu verwenden. Eine Pipeline bündelt ein vortrainiertes Modell mit dem entsprechenden Token-Tokenizer und übernimmt für Sie alle Schritte der Vorverarbeitung der Eingabe und der Nachverarbeitung der Ausgabe.
Zwei der beliebtesten Modelle für Zusammenfassungen sind BART und T5. BART (Bidirectional and Auto-Regressive Transformer) eignet sich besonders gut für abstrakte Zusammenfassungen und erzeugt Zusammenfassungen, die sich sehr natürlich lesen. T5 (Text-to-Text Transfer Transformer) ist ein vielseitiges Modell, das jede NLP-Aufgabe als Text-zu-Text-Problem formuliert und es so zu einem leistungsstarken Allrounder macht.
🎥 Sehen Sie sich dieses Video an, um die besten KI-PDF-Summarizer im Vergleich zu sehen – und erfahren Sie, welche Tools die schnellsten und genauesten Zusammenfassungen liefern, ohne den Kontext zu verlieren.
So erstellen Sie einen Text-Summarizer mit Hugging Face
Sind Sie bereit, Ihr eigenes Summarizer-Beispiel zu erstellen? Sie benötigen lediglich einige grundlegende Python-Kenntnisse, einen Editor wie VS Code und eine Internetverbindung. Der gesamte Vorgang umfasst nur vier Schritte. In wenigen Minuten haben Sie einen funktionierenden Summarizer.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Zunächst müssen Sie die erforderlichen Bibliotheken installieren. Die wichtigste davon ist „transformers“. Außerdem benötigen Sie ein Deep-Learning-Framework wie PyTorch oder TensorFlow. In diesem Beispiel verwenden wir PyTorch.
Öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung und führen Sie den folgenden Befehl aus:

Einige Modelle, wie T5, benötigen für ihren Token auch die sentencepiece-Bibliothek. Es empfiehlt sich, diese ebenfalls zu installieren.

💡 Profi-Tipp: Erstellen Sie eine virtuelle Python-Umgebung, bevor Sie diese Pakete installieren. Dadurch bleiben die Abhängigkeiten Ihres Projekts isoliert und Konflikte mit anderen Projekten auf Ihrem Rechner werden vermieden.
Schritt 2: Laden Sie das Modell und den Tokenizer.
Am einfachsten beginnen Sie mit der Pipeline-Funktion. Diese übernimmt automatisch das Laden des richtigen Modells und Token für die Zusammenfassungsaufgabe.
Importieren Sie in Ihrem Python-Skript die Pipeline und initialisieren Sie sie wie folgt:

Hier legen wir zwei Dinge fest:
Die Aufgabe: Wir teilen der Pipeline mit, dass wir eine „Zusammenfassung” durchführen möchten.
Das Modell: Wir wählen einen bestimmten vortrainierten Modell-Checkpoint aus dem Hugging Face hub aus. facebook/bart-large-cnn ist eine beliebte Wahl, die auf Nachrichtenartikeln trainiert wurde und sich gut für allgemeine Zusammenfassungen eignet. Für schnellere Tests können Sie ein kleineres Modell wie t5-small verwenden.
Wenn Sie diesen Code zum ersten Mal ausführen, werden die Modellgewichte aus dem hub heruntergeladen, was einige Minuten dauern kann. Danach wird das Modell auf Ihrem lokalen Rechner zwischengespeichert, sodass es sofort geladen werden kann.
Schritt 3: Erstellen Sie die Zusammenfassungsfunktion
Um Ihren Code übersichtlich und wiederverwendbar zu gestalten, sollten Sie die Zusammenfassungslogik am besten in eine Funktion einbinden. Dies erleichtert auch das Experimentieren mit verschiedenen Parametern.
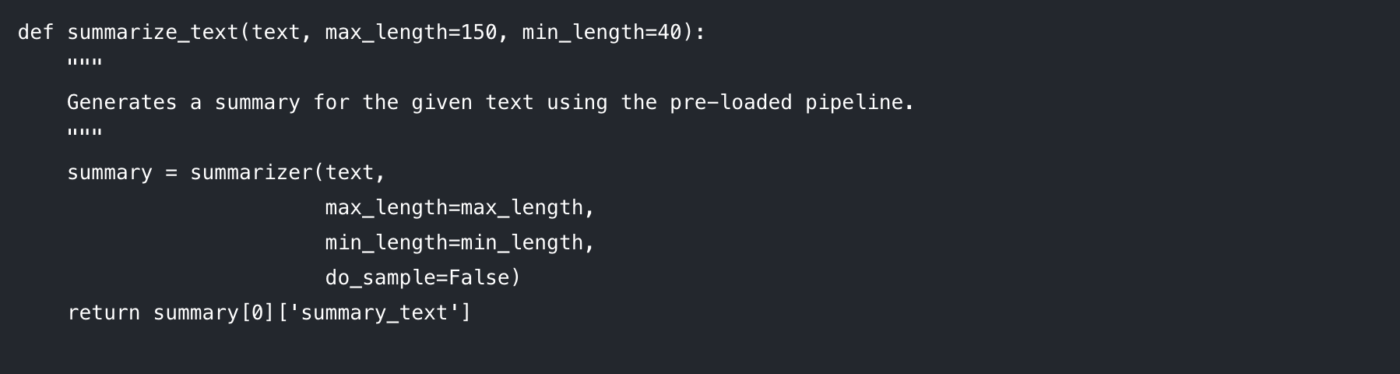
Schauen wir uns die Parameter an, die Sie steuern können:
max_length: Hiermit wird die maximale Anzahl von Tokens (grob gesagt: Wörtern) für die ausgegebene Zusammenfassung festgelegt.
min_length: Hiermit wird die Mindestanzahl an Tokens festgelegt, um zu verhindern, dass das Modell zu kurze oder leere Zusammenfassungen generiert.
do_sample: Wenn diese Option auf „False” eingestellt ist, verwendet das Modell eine deterministische Methode (wie Beam Search), um die wahrscheinlichste Zusammenfassung zu generieren. Wenn sie auf „True” eingestellt ist, wird Zufälligkeit eingeführt, was zu kreativeren, aber weniger vorhersehbaren Ergebnissen führen kann.
Die Anpassung dieser Parameter ist der Schlüssel, um die gewünschte Ausgabequalität zu erzielen.
Schritt 4: Erstellen Sie Ihre Zusammenfassung
Jetzt kommt der spaßige Teil. Übergeben Sie Ihren Text an die Funktion und drucken Sie das Ergebnis aus. 🤩

Sie sollten eine gekürzte Version des Artikels auf Ihrer Konsole sehen. Wenn Sie auf Probleme stoßen, finden Sie hier einige schnelle Lösungen:
Der eingegebene Text ist zu lang: Das Modell gibt möglicherweise eine Fehlermeldung aus, wenn Ihre Eingabe die maximale Länge überschreitet (oft 512 oder 1024 Tokens). Fügen Sie truncation=True innerhalb des summarizer()-Aufrufs hinzu, um lange Eingaben automatisch zu kürzen.
Die Zusammenfassung ist zu allgemein: Versuchen Sie, den Parameter num_beams zu erhöhen (z. B. num_beams=4). Dadurch sucht das Modell gründlicher nach einer besseren Zusammenfassung, kann jedoch etwas langsamer sein.
Dieser code-basierte Ansatz ist fantastisch für Entwickler, die benutzerdefinierte Apps erstellen. Aber was passiert, wenn Sie dies in die tägliche Arbeit eines Teams integrieren müssen? Hier zeigen sich die Grenzen.
Einschränkungen von Hugging Face für die Textzusammenfassung
Hugging Face ist eine großartige Option, wenn Sie Flexibilität und Kontrolle wünschen. Sobald Sie jedoch versuchen, es für echte Team-Workflows (und nicht nur für ein Demo-Notebook) zu verwenden, treten schnell einige vorhersehbare Herausforderungen auf.
Token-Limits und Probleme mit langen Dokumenten
Die meisten Zusammenfassungsmodelle haben eine feste maximale Eingabelänge. Beispielsweise ist facebook/bart-large-cnn mit max_position_embeddings = 1024 konfiguriert. Das bedeutet, dass längere Dokumente oft gekürzt oder in Abschnitte unterteilt werden müssen.
Wenn Sie nur eine schnelle Basis benötigen, können Sie die Trunkierung in der Pipeline aktivieren und fortfahren. Wenn Sie jedoch originalgetreue Zusammenfassungen langer Dokumente benötigen, müssen Sie in der Regel eine Chunking-Logik erstellen und dann einen zweiten Durchgang erledigen, eine „Zusammenfassung der Zusammenfassungen“, um die Ergebnisse miteinander zu verknüpfen. Das ist zusätzlicher Entwicklungsaufwand, und es kann leicht zu inkonsistenten Ergebnissen kommen.
Halluzinationsrisiko (und die Überprüfungssteuer)
Abstraktive Modelle können manchmal halluzinieren und Texte generieren, die plausibel klingen, aber sachlich falsch sind. Für geschäftskritische Anwendungen ist das ein Problem: Jede Zusammenfassung muss manuell überprüft werden. An diesem Punkt sparen Sie nicht wirklich Zeit, sondern verlagern die Arbeit nur auf einen anderen Teil des Prozesses.
Mangelnde Kontextwahrnehmung
Ein Hugging Face-Modell kennt nur den Text, den Sie ihm zuführen. Es hat kein Verständnis für die Ziele Ihres Projekts, die beteiligten Personen oder die Zusammenhänge zwischen den einzelnen Dokumenten, da ihm die kontextbezogene Intelligenz moderner Systeme fehlt. Es kann Ihnen nicht sagen, ob eine Zusammenfassung eines Kundengesprächs im Widerspruch zum Projektanforderungsdokument steht, da es isoliert arbeitet.
Integrationsaufwand (das „Last Mile“-Problem)
Das Erstellen einer Zusammenfassung ist in der Regel der einfache Teil. Die eigentliche Herausforderung kommt danach.
Wohin geht die Zusammenfassung? Wer sieht sie? Wie wird sie zu einer umsetzbaren Aufgabe? Wie erstellen Sie die Verbindung zwischen ihr und der Arbeit, die ihren Auslöser darstellt?
Um diese „letzte Hürde” zu überwinden, müssen benutzerdefinierte Integrationen und Glue-Code erstellt werden. Das bedeutet zusätzlichen Aufwand für die Entwickler und führt oft zu einem umständlichen Workflow für alle anderen.
Technische Hürden und laufende Wartung
Ein Python-basierter Ansatz ist vor allem für Personen zugänglich, die Code schreiben können. Das stellt eine praktische Hürde für Marketing-, Vertriebs- und Betriebsteams dar, was bedeutet, dass die Akzeptanz begrenzt bleibt.
Dazu gehört auch die laufende Wartung: Verwalten von Abhängigkeiten, Aktualisieren von Bibliotheken und Sicherstellen, dass Alles weiterhin funktioniert, während sich APIs und Modelle weiterentwickeln. Was als schneller Erfolg beginnt, kann sich still und leise zu einem weiteren System entwickeln, das betreut werden muss.
📮 ClickUp Insight: 42 % der Unterbrechungen bei der Arbeit entstehen durch das Jonglieren mit verschiedenen Plattformen, das Verwalten von E-Mails und das Hin- und Herspringen zwischen Meetings. Was wäre, wenn Sie diese kostspieligen Unterbrechungen eliminieren könnten? ClickUp vereint Ihre Workflows (und Chats) unter einer einzigen, optimierten Plattform. Starten und verwalten Sie Ihre Aufgaben über Chats, Dokumente, Whiteboards und mehr, während KI-gestützte Features den Kontext verbunden, durchsuchbar und verwaltbar halten.
Das größere Problem: Kontextverwirrung
Selbst wenn Ihr Zusammenfassungsskript perfekt funktioniert, kann Ihr Team dennoch Zeit verlieren, da die Ausgabe keinen Bezug zu dem Ort hat, an dem die Arbeit tatsächlich stattfindet.
Das ist Kontextzerstreuung, wenn Teams Stunden damit verschwenden, nach Informationen zu suchen, zwischen Apps zu wechseln und Dateien auf unverbundenen Plattformen zu suchen.
Hier kommt ein konvergierter Arbeitsbereich ins Spiel. Anstatt Zusammenfassungen an einem Ort zu erstellen und später zu versuchen, sie „in die Arbeit zu integrieren”, hält ein konvergiertes System Projekte, Dokumente und Unterhaltungen zusammen, wobei ClickUp Brain als Intelligenzschicht eingebettet ist. Ihre Zusammenfassungen bleiben mit Aufgaben und Dokumenten verbunden, sodass der nächste Schritt offensichtlich ist und die Übergabe sofort erfolgt.
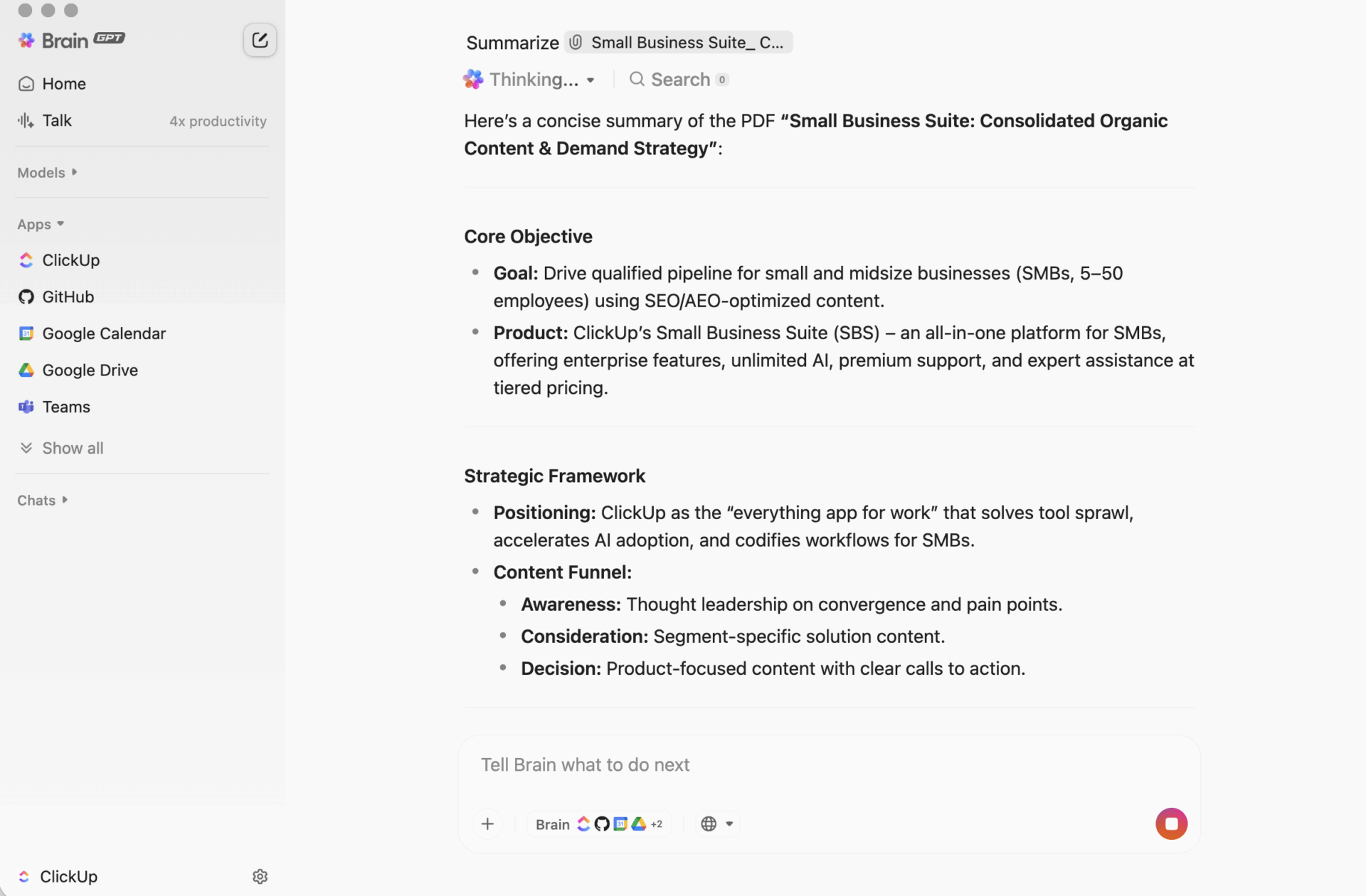
Zusammenfassungen, die mit ClickUp in Maßnahmen umgesetzt werden
Ein Zusammenfassungsskript kann perfekt funktionieren und dennoch Ihr Team in einer ärgerlichen Weise im Stich lassen: Die Zusammenfassung landet irgendwo außerhalb der Arbeit.
Diese Lücke führt zu einer Kontextzerstreuung, bei der Informationen über Dokumente, Chat-Threads, Aufgaben und „Schnellnotizen” in tools verstreut sind, die nicht miteinander verbunden sind. Die Menschen verbringen mehr Zeit damit, die Zusammenfassung zu finden, als sie zu nutzen. Der eigentliche Gewinn besteht nicht nur darin, eine Zusammenfassung zu erstellen. Es geht darum, diese Zusammenfassung mit Entscheidungen, Eigentümern und nächsten Schritten zu verknüpfen, wo die Arbeit tatsächlich stattfindet.
Das ist es, was ClickUp Brain anders macht. Es fasst Aufgaben, Dokumente und Unterhaltungen innerhalb desselben Workspaces, in dem sich Ihre Projekte befinden, zusammen, sodass Ihr Team etwas verstehen und darauf reagieren kann, ohne zwischen verschiedenen Tools hin- und herspringen zu müssen.

ClickUp BrainGPT: Interagieren Sie mit Zusammenfassungen in natürlicher Sprache
Auf dem Desktop ist BrainGPT die Konversationsschnittstelle für ClickUp Brain. Anstatt Skripte, Notizbücher oder externe KI-Tools zu öffnen, kann Ihr Team direkt in ClickUp in einfacher Sprache nach dem fragen, was es benötigt.
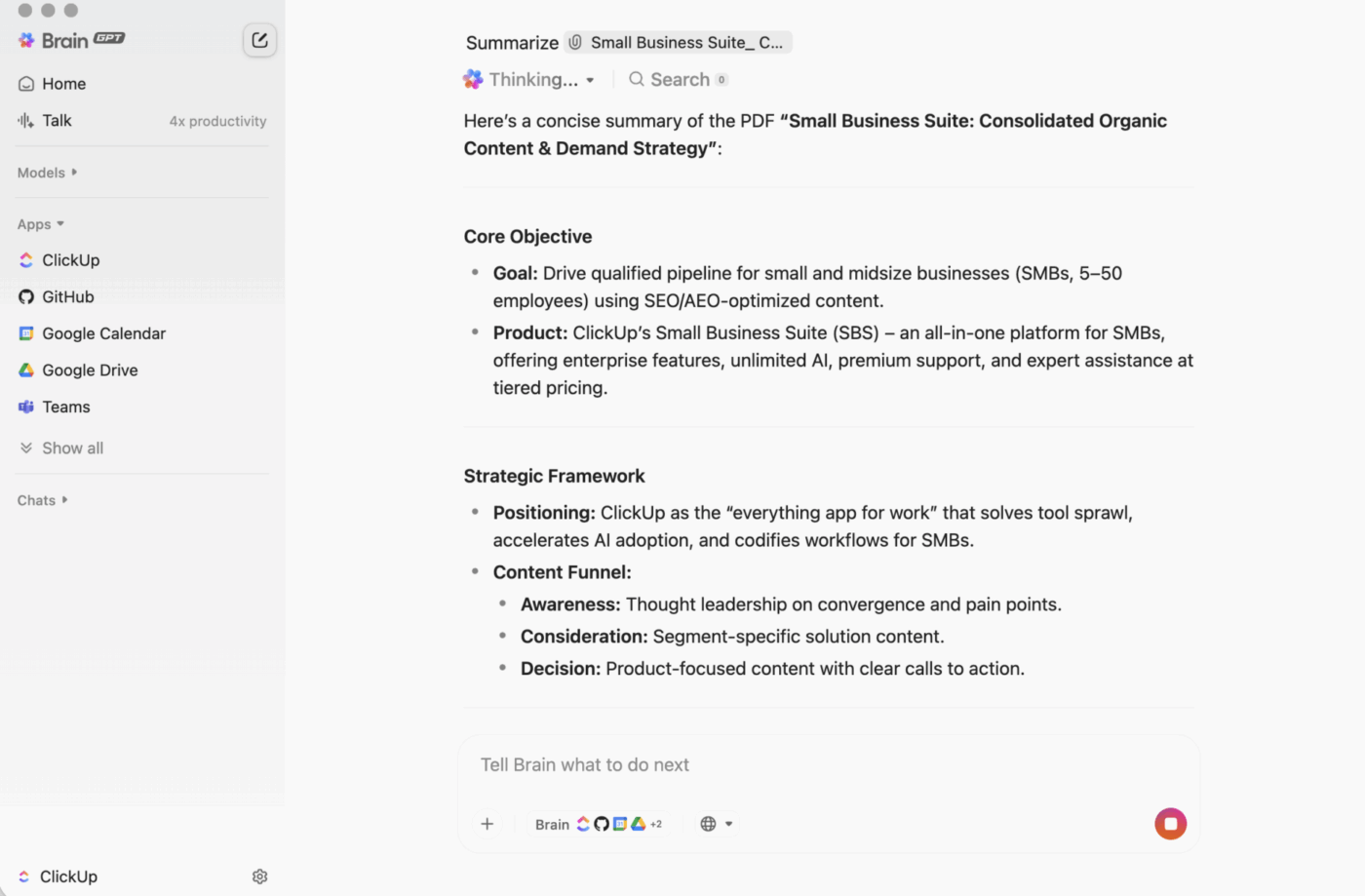
Sie können Folgendes eingeben (oder die Sprach-zu-Text-Funktion verwenden):
- Fassen Sie eine lange Beschreibung der Aufgabe, einen Kommentar-Thread oder ein Dokument zusammen.
- Fragen Sie nach mit Fragen wie „Was sind die nächsten Schritte?“ oder „Wer ist dafür verantwortlich?“
- Verwandeln Sie eine Zusammenfassung in eine Maßnahme, indem Sie daraus Aufgaben mit Eigentümern und Fälligkeitsdaten erstellen.
Da ClickUp Brain in Ihrem Workspace funktioniert, basiert die Ausgabe auf dem Live-Kontext: Aufgabenbeschreibungen, Kommentare, Unteraufgaben, verknüpfte Dokumente und Projektstruktur. Sie fügen keinen Text in ein separates Tool ein und hoffen, dass nichts Wichtiges übersehen wird.
Warum dies für die meisten Teams besser ist als ein code-basierter Zusammenfassungs-Workflow
Ein von Entwicklern erstellter Workflow kann aussagekräftige Zusammenfassungen generieren. Die Reibung entsteht danach, wenn jemand die Ausgabe an den Ort kopieren muss, an dem die Arbeit stattfindet, sie dann in Aufgaben übersetzen und anschließend die Umsetzung verfolgen muss.
ClickUp Brain schließt diese Lücke:
Keine Programmierkenntnisse erforderlichJeder im Team kann ein Dokument, einen Thread für Aufgaben oder eine unübersichtliche Reihe von Kommentaren zusammenfassen, ohne etwas installieren oder Code schreiben zu müssen.
Kontextbezogene ZusammenfassungenClickUp Brain kann die Teile einbeziehen, die Menschen normalerweise vergessen: Entscheidungen, die in Kommentaren verborgen sind, Hindernisse, die in Antworten erwähnt werden, Unteraufgaben, die die Bedeutung von „erledigt” verändern.
Zusammenfassungen befinden sich dort, wo die Arbeit stattfindet Sie können sich innerhalb einer Aufgabe auf den neuesten Stand bringen, eine Zusammenfassung oben in ClickUp Docs hinzufügen oder eine Diskussion schnell zusammenfassen, ohne ein weiteres „Zusammenfassungsdokument” zu erstellen, das niemand liest.
Weniger Tools Sie benötigen keine separaten Skripte, Jupyter-Notebooks, API-Schlüssel oder einen Workflow, den nur eine Person versteht. Ihre Dokumente, Aufgaben und Zusammenfassungen bleiben alle im selben System.
Das ist der praktische Vorteil eines konvergenten Workspaces: Zusammenfassung, Aktion und Zusammenarbeit finden gemeinsam statt, anstatt nachträglich zusammengefügt zu werden.
Das ist der praktische Vorteil eines konvergenten Workspaces: Zusammenfassung, Aktion und Zusammenarbeit finden gemeinsam statt, anstatt nachträglich zusammengefügt zu werden.
So funktioniert es in der Praxis
Hier sind einige gängige Muster, die Teams verwenden:
- Fassen Sie einen Kommentar-Thread zusammen: Öffnen Sie eine Aufgabe mit einer langen Diskussion, klicken Sie auf die /AI-Option und erhalten Sie eine kurze Zusammenfassung der Änderungen und wichtigen Punkte.
- Dokument zusammenfassen: Öffnen Sie ein ClickUp-Dokument und verwenden Sie „Ask KI“, um eine Zusammenfassung der Seite zu erstellen, damit sich jeder schnell orientieren kann.
- Maßnahmen extrahieren: Nehmen Sie die Zusammenfassung und wandeln Sie die nächsten Schritte sofort in Aufgaben mit Mitarbeitern und Fälligkeitsdaten um, damit die Dynamik bei der Übergabe nicht verloren geht.
| Fähigkeit | Hugging Face (code-basiert) | ClickUp Brain |
|---|---|---|
| Erforderliches Setup | Python-Umgebung, Bibliotheken, Code | Keine, integriert |
| Kontextbewusstsein | Nur Text (was Sie eingeben) | Vollständiger Workspace-Kontext (Aufgaben, Dokumente, Kommentare, Unteraufgaben) |
| Workflow-Integration | Manueller Export/Import | Native: Zusammenfassungen können zu Aufgaben und Aktualisierungen werden. |
| Erforderliche technische Kenntnisse | Entwickler-Level | Jeder im Team |
| Wartung | Laufende Modell- und Code-Pflege | Automatische Updates |
Von Zusammenfassungen zur Umsetzung mit Super Agents
Zusammenfassungen sind nützlich. Die Schwierigkeit besteht darin, sicherzustellen, dass sie konsequent in Folgemaßnahmen umgesetzt werden, insbesondere wenn das Volumen zunimmt.
Hier kommen die ClickUp Super Agents ins Spiel. Sie können zusammengefasste Informationen nutzen und die Arbeit auf der Grundlage von Auslösern und Bedingungen innerhalb desselben Workspaces vorantreiben.
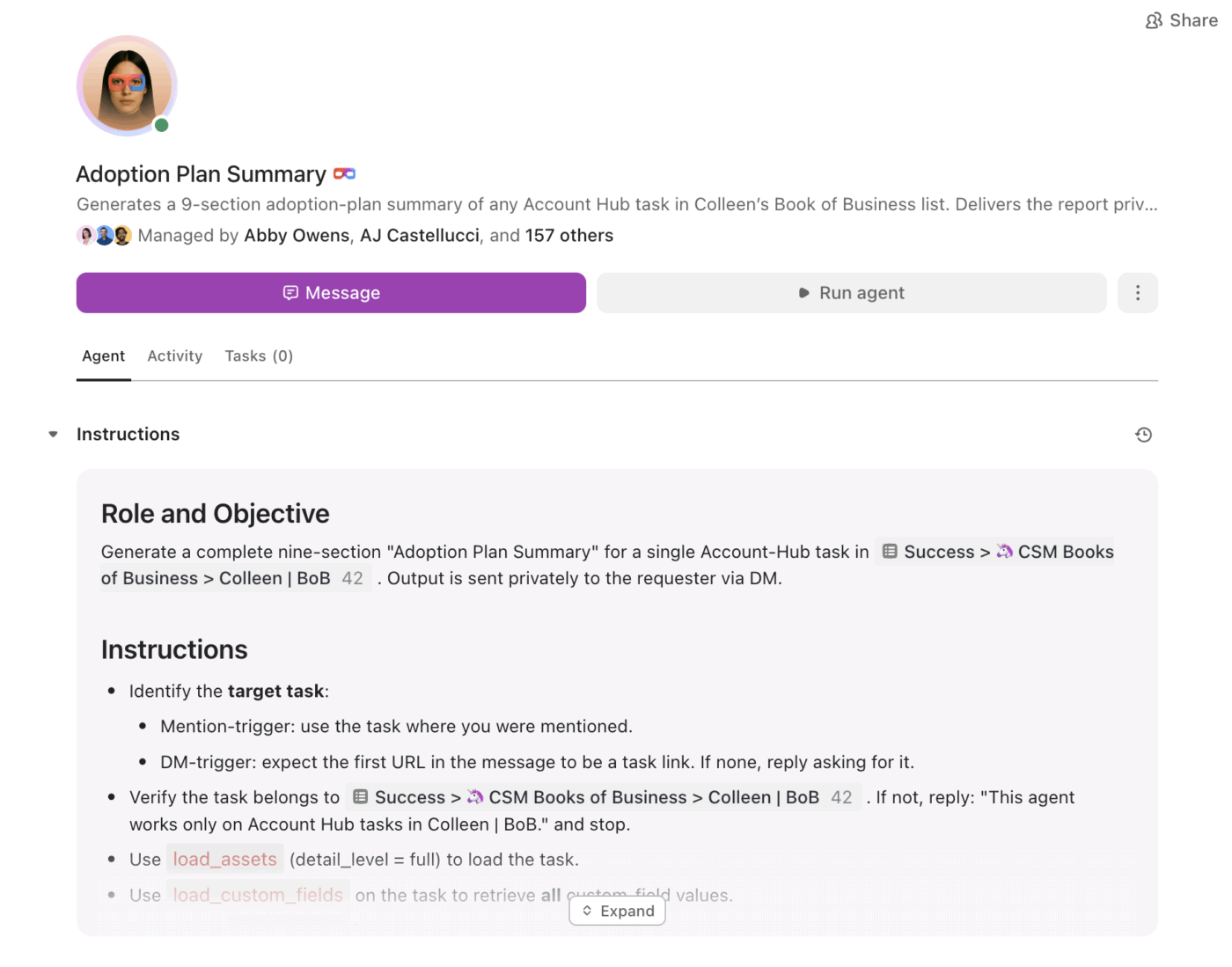
Mit Super Agents können Teams:
- Fassen Sie Änderungen nach einem Zeitplan zusammen (wöchentliche Zusammenfassung des Projekts, tägliche Zusammenfassung des Status)
- Extrahieren Sie Elemente und weisen Sie ihnen automatisch Eigentümer zu.
- Markieren Sie ins Stocken geratene Arbeiten (Aufgaben, die in der Überprüfung stecken geblieben sind, unbeantwortete Threads, überfällige nächste Schritte)
- Sorgen Sie für eine hohe Sichtbarkeit der Führungskräfte ohne manuelle Berichterstellung.
Anstatt eine Zusammenfassung als statischen Text zu hinterlegen, helfen Agenten dabei, sicherzustellen, dass die Zusammenfassung zu einem Plan wird und der Plan zu Fortschritt.
Zusammenfassungen, die dort entstehen, wo gearbeitet wird
Hugging Face Transformers sind ideal, wenn Sie eine benutzerdefinierte App, eine maßgeschneiderte Pipeline oder die vollständige Kontrolle über das Modellverhalten benötigen.
Für die meisten Teams ist jedoch nicht die Frage „Können wir dies zusammenfassen?“ das größere Problem, sondern „Können wir dies zusammenfassen und sofort in Arbeit umsetzen, mit Eigentümern, Fristen und Sichtbarkeit?“
Wenn Ihr Ziel Teamproduktivität und schnelle Umsetzung ist, bietet Ihnen ClickUp Brain Zusammenfassungen im Kontext, genau dort, wo die Arbeit stattfindet, mit einem klaren Weg von „Hier ist das Wesentliche“ zu „Hier ist, was wir als Nächstes tun“.
Sind Sie bereit, das Setup zu überspringen und mit der Zusammenfassung dort zu beginnen, wo Ihre Arbeit tatsächlich stattfindet? Starten Sie kostenlos mit ClickUp und überlassen Sie Brain die Schwerarbeit.