
نادرًا ما تفشل مشاريع تدريب الذكاء الاصطناعي على مستوى النموذج. لكنها تواجه صعوبات عندما تكون التجارب والوثائق وتحديثات أصحاب المصلحة موزعة على العديد من الأدوات.
يرشدك هذا الدليل إلى تدريب النماذج باستخدام Databricks DBRX—وهو LLM يصل إلى ضعف كفاءة الحوسبة مقارنة بالنماذج الرائدة الأخرى—مع الحفاظ على تنظيم العمل المحيط به في ClickUp.
من الإعداد والضبط الدقيق إلى التوثيق والتحديثات بين الفرق، سترى كيف تساعد مساحة العمل الموحدة في القضاء على توسع السياق والحفاظ على تركيز فريقك على البناء، وليس البحث. 🛠
ما هو DBRX؟
DBRX هو نموذج لغوي كبير (LLM) قوي ومفتوح المصدر مصمم خصيصًا لتدريب نماذج الذكاء الاصطناعي والاستدلال في المؤسسات. نظرًا لأنه مفتوح المصدر بموجب ترخيص Databricks Open Model، يتمتع فريقك بحق الوصول الكامل إلى أوزان النموذج وبنيته، مما يتيح لك فحصه وتعديله ونشره وفقًا لشروطك الخاصة.
يتوفر في نسختين: DBRX Base للتدريب المسبق العميق و DBRX Instruct للمهام الجاهزة التي تتبع التعليمات.
بنية DBRX وتصميم مزيج الخبراء
يحل DBRX المهام باستخدام بنية Mixture-of-Experts (MoE). على عكس نماذج اللغة الكبيرة التقليدية التي تستخدم كل معلماتها التي يبلغ عددها مليارات المعلمات في كل عملية حسابية، لا يقوم DBRX بتنشيط سوى جزء بسيط من إجمالي معلماته (الخبراء الأكثر صلة) لأي مهمة معينة.
فكر في الأمر على أنه فريق من الخبراء المتخصصين؛ فبدلاً من أن يعمل الجميع على كل مشكلة، يقوم النظام بتوجيه كل مهمة بذكاء إلى المعلمات الأكثر ملاءمة.
لا يقتصر الأمر على تقليل وقت الاستجابة فحسب، بل إنه يوفر أيضًا أداءً ومخرجات من الدرجة الأولى مع تقليل تكاليف الحوسبة بشكل كبير.
فيما يلي نظرة سريعة على مواصفاته الرئيسية:
- إجمالي المعلمات: 132 مليار عبر جميع الخبراء
- المعلمات النشطة: 36 مليار لكل تمريرة أمامية
- عدد الخبراء: 16 في المجموع (توجيه MoE Top-4)، مع 4 نشطين لأي رمز معين
- نافذة السياق: 32 ألف رمز
بيانات تدريب DBRX ومواصفات الرموز المميزة
أداء LLM يعتمد بشكل كامل على جودة البيانات التي تم تدريبه عليها. تم تدريب DBRX مسبقًا على مجموعة بيانات ضخمة تضم 12 تريليون رمز تم تنظيمها بعناية من قبل فريق Databricks باستخدام أدوات معالجة البيانات المتقدمة الخاصة بهم. وهذا هو بالضبط سبب أدائه القوي في معايير الصناعة.
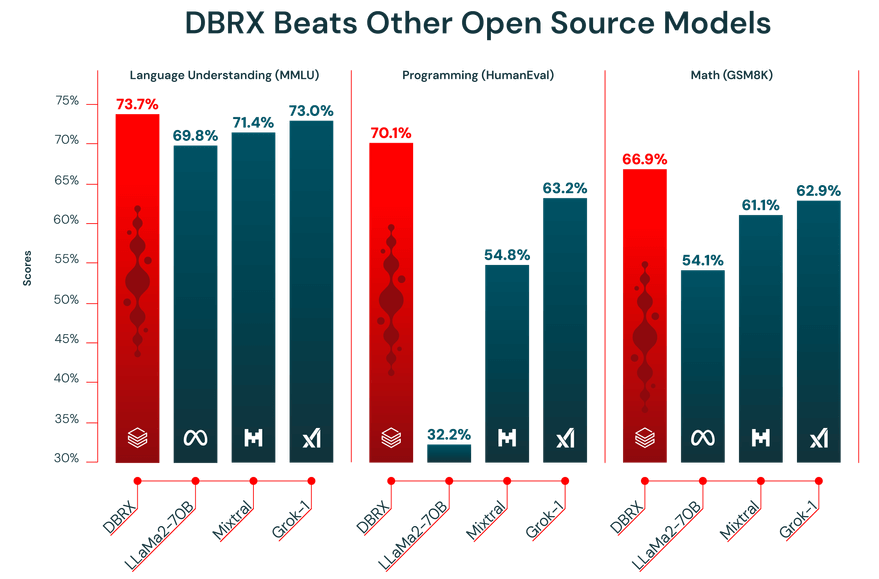
بالإضافة إلى ذلك، يتميز DBRX بنافذة سياق تضم 32000 رمز. هذا هو مقدار النص الذي يمكن للنموذج معالجته في وقت واحد. تعد نافذة السياق الكبيرة مفيدة للغاية للمهام المعقدة مثل تلخيص التقارير الطويلة، أو البحث في المستندات القانونية الطويلة، أو إنشاء أنظمة متقدمة لتوليد المعلومات المعززة بالاسترجاع (RAG)، لأنها تسمح للنموذج بالحفاظ على السياق دون اقتطاع أو نسيان المعلومات.
🎥 شاهد هذا الفيديو لترى كيف يمكن لتنسيق المشاريع المبسط أن يحول سير عمل تدريب الذكاء الاصطناعي لديك ويزيل الصعوبات الناتجة عن التبديل بين الأدوات غير المتصلة. 👇🏽
كيفية الوصول إلى DBRX وإعداده
يوفر DBRX طريقتين أساسيتين للوصول، وكلاهما يوفران وصولاً كاملاً إلى أوزان النموذج بموجب شروط تجارية متساهلة. يمكنك استخدام Hugging Face للحصول على أقصى قدر من المرونة أو الوصول إليه مباشرةً من خلال Databricks للحصول على تجربة أكثر تكاملاً.
الوصول إلى DBRX من خلال Hugging Face
بالنسبة للفرق التي تقدر المرونة وتشعر بالراحة بالفعل مع نظام Hugging Face البيئي، فإن الوصول إلى DBRX من خلال Hub هو الطريق المثالي. فهو يتيح لك دمج النموذج في سير العمل الحالي القائم على المحولات.
إليك كيفية البدء:
- قم بإنشاء حساب Hugging Face أو تسجيل الدخول إليه
- انتقل إلى بطاقة نموذج DBRX على Hub وقبول شروط الترخيص
- قم بتثبيت مكتبة المحولات مع التبعيات الضرورية مثل التسريع
- استخدم فئة AutoModelForCausalLM في برنامج Python النصي لتحميل نموذج DBRX
- قم بتكوين خط أنابيب الاستدلال الخاص بك، مع الأخذ في الاعتبار أن DBRX يتطلب ذاكرة GPU كبيرة (VRAM) للتشغيل الفعال.
📖 اقرأ المزيد: كيفية تكوين درجة حرارة LLM
الوصول إلى DBRX من خلال Databricks
إذا كان فريقك يستخدم Databricks بالفعل لهندسة البيانات أو التعلم الآلي، فإن الوصول إلى DBRX من خلال المنصة هو أسهل طريقة. فهو يقلل من صعوبات الإعداد ويوفر لك جميع الأدوات التي تحتاجها لـ MLOps في المكان الذي تعمل فيه بالفعل.
اتبع هذه الخطوات في مساحة عمل Databricks الخاصة بك للبدء:
- انتقل إلى قسم Model Garden أو Mosaic AI.
- اختر إما DBRX Base أو DBRX Instruct، حسب احتياجاتك.
- قم بتكوين نقطة نهاية خدمة للوصول إلى واجهة برمجة التطبيقات (API) أو قم بإعداد بيئة دفتر ملاحظات للاستخدام التفاعلي
- ابدأ في اختبار الاستدلال باستخدام نماذج مطالبات للتأكد من أن كل شيء يعمل بشكل صحيح قبل توسيع نطاق تدريب نموذج الذكاء الاصطناعي أو نشره.
يمنحك هذا النهج وصولاً سلسًا إلى أدوات مثل MLflow لتتبع التجارب و Unity Catalog لإدارة النماذج.
📮 ClickUp Insight: يقضي الموظف العادي أكثر من 30 دقيقة يوميًا في البحث عن المعلومات المتعلقة بالعمل، أي ما يزيد عن 120 ساعة سنويًا تضيع في البحث في رسائل البريد الإلكتروني ومحادثات Slack والملفات المتناثرة.
يمكن لمساعد الذكاء الاصطناعي الذكي المدمج في مساحة العمل الخاصة بك تغيير ذلك. أدخل ClickUp Brain.
يوفر رؤى وإجابات فورية من خلال عرض المستندات والمحادثات وتفاصيل المهام المناسبة في ثوانٍ معدودة — حتى تتمكن من التوقف عن البحث والبدء في العمل.
كيفية ضبط DBRX وتدريب نماذج الذكاء الاصطناعي المخصصة
لن تتمكن أي نموذج جاهز، مهما كان قوياً، من فهم الفروق الدقيقة الفريدة لعملك. ونظراً لأن DBRX مفتوح المصدر، يمكنك ضبطه لإنشاء نموذج مخصص يتحدث لغة شركتك أو يؤدي مهمة محددة تريده أن يتولاها.
فيما يلي ثلاث طرق شائعة للقيام بذلك:
1. ضبط DBRX باستخدام مجموعات بيانات Hugging Face
بالنسبة للفرق التي بدأت للتو أو تعمل على مهام مشتركة، تعد مجموعات البيانات العامة من Hugging Face Hub موردًا رائعًا. فهي معدة مسبقًا وسهلة التحميل، مما يعني أنك لن تضطر إلى قضاء ساعات في إعداد بياناتك.
العملية بسيطة للغاية:
- ابحث في Hub عن مجموعة بيانات تتوافق مع مهمتك (على سبيل المثال، اتباع التعليمات، التلخيص)
- قم بتحميله باستخدام مكتبة مجموعات البيانات
- تأكد من تنسيق البيانات في أزواج من التعليمات والاستجابات
- قم بتكوين برنامج التدريب الخاص بك باستخدام معلمات فائقة مثل معدل التعلم وحجم الدفعة
- ابدأ مهمة التدريب، مع التأكد من حفظ نقاط التحقق بشكل دوري.
- قم بتقييم النموذج المضبوط بدقة على مجموعة التحقق المعلقة لقياس التحسن.
2. ضبط DBRX باستخدام مجموعات البيانات المحلية
عادةً ما تحصل على أفضل النتائج من خلال الضبط الدقيق باستخدام بياناتك الخاصة. يتيح لك ذلك تعليم النموذج المصطلحات والأسلوب والمعرفة الخاصة بشركتك. فقط ضع في اعتبارك أن ذلك لا يؤتي ثماره إلا إذا كانت بياناتك نظيفة ومعدة جيدًا، ولديها حجم كافٍ.
اتبع هذه الخطوات لإعداد بياناتك الداخلية:
- جمع البيانات: اجمع أمثلة عالية الجودة من مواقع الويكي الداخلية والوثائق وقواعد البيانات الخاصة بك.
- تحويل التنسيق: قم بتنظيم بياناتك في تنسيق متسق من التعليمات والاستجابات، غالبًا في شكل أسطر JSON.
- تصفية الجودة: إزالة أي أمثلة منخفضة الجودة أو مكررة أو غير ذات صلة
- تقسيم التحقق: خصص جزءًا صغيرًا من بياناتك (عادةً 10-15٪) لتقييم أداء النموذج.
- مراجعة الخصوصية: قم بإزالة أو إخفاء أي معلومات شخصية (PII) أو بيانات حساسة
3. ضبط DBRX باستخدام StreamingDataset
إذا كانت مجموعة البيانات الخاصة بك كبيرة جدًا بحيث لا تتسع في ذاكرة جهازك، فلا تقلق، يمكنك استخدام مكتبة Streaming Dataset من Databricks. تتيح لك هذه المكتبة بث البيانات مباشرة من التخزين السحابي أثناء تدريب النموذج، بدلاً من تحميلها كلها في الذاكرة دفعة واحدة.
إليك كيفية القيام بذلك:
- إعداد البيانات: قم بتنظيف وتنظيم بيانات التدريب الخاصة بك، ثم قم بتخزينها بتنسيق قابل للبث مثل JSONL أو CSV في التخزين السحابي.
- تحويل تنسيق البث: قم بتحويل مجموعة البيانات الخاصة بك إلى تنسيق مناسب للبث، مثل Mosaic Data Shard (MDS)، بحيث يمكن قراءتها بكفاءة أثناء التدريب.
- إعداد محمل التدريب: قم بتكوين محمل التدريب الخاص بك للإشارة إلى مجموعة البيانات البعيدة وتحديد ذاكرة تخزين مؤقتة محلية لتخزين البيانات المؤقتة
- تهيئة النموذج: ابدأ عملية ضبط DBRX باستخدام إطار تدريب يدعم StreamingDataset، مثل LLM Foundry.
- التدريب القائم على البث: قم بتشغيل مهمة التدريب أثناء بث البيانات على دفعات أثناء التدريب، بدلاً من تحميلها بالكامل في الذاكرة.
- التحقق من النقاط والاستعادة: استأنف التدريب بسلاسة في حالة انقطاع التشغيل، دون تكرار البيانات أو تخطيها.
- التقييم والنشر: تحقق من أداء النموذج المُحسّن وانشره باستخدام إعداد الخدمة أو الاستدلال المفضل لديك.
💡نصيحة احترافية: بدلاً من إنشاء خطة تدريب DBRX من الصفر، ابدأ بـ قالب خارطة طريق مشاريع الذكاء الاصطناعي والتعلم الآلي من ClickUp وقم بتعديله وفقًا لاحتياجات فريقك. يوفر هذا القالب هيكلًا واضحًا لتخطيط مجموعات البيانات ومراحل التدريب والتقييم والنشر، بحيث يمكنك التركيز على تنظيم عملك بدلاً من هيكلة سير العمل.
حالات استخدام DBRX لتدريب نماذج الذكاء الاصطناعي
إن امتلاك نموذج قوي أمر مهم، ولكن معرفة المجالات التي يبرع فيها أمر آخر.
عندما لا تكون لديك صورة واضحة عن نقاط قوة النموذج، فمن السهل أن تضيع الوقت والموارد في محاولة جعله يعمل في مكان لا يناسبه. وهذا يؤدي إلى نتائج دون المستوى المطلوب وإحباط.
تجعل بنية DBRX الفريدة وبيانات التدريب الخاصة به مناسبًا بشكل استثنائي للعديد من حالات الاستخدام الرئيسية في المؤسسات. إن معرفة نقاط القوة هذه تساعدك على مواءمة النموذج مع أهداف عملك وتحقيق أقصى عائد على الاستثمار.
إنشاء النصوص وإنشاء المحتوى
تم ضبط DBRX Instruct بدقة لاتباع التعليمات وإنشاء نصوص عالية الجودة. وهذا يجعله أداة قوية لأتمتة مجموعة واسعة من المهام المتعلقة بالمحتوى. وتعد نافذة السياق الكبيرة ميزة مهمة، حيث تتيح له التعامل مع المستندات الطويلة دون فقدان الخيط.
يمكنك استخدامه من أجل:
- الوثائق الفنية: إنشاء وتحسين أدلة المنتجات ومراجع واجهة برمجة التطبيقات (API) وأدلة المستخدم
- محتوى التسويق: مسودات منشورات المدونة، والنشرات الإخبارية عبر البريد الإلكتروني، وتحديثات وسائل التواصل الاجتماعي
- إنشاء التقارير: لخص نتائج البيانات المعقدة وقم بإنشاء ملخصات تنفيذية موجزة
- الترجمة والتوطين: تكييف المحتوى الحالي مع الأسواق والجماهير الجديدة
مهام إنشاء الكود وتصحيح الأخطاء
تضمن جزء كبير من بيانات تدريب DBRX رموزًا برمجية، مما يجعله دعمًا قويًا لـ LLM للمطورين. يمكن أن يساعد في تسريع دورات التطوير من خلال أتمتة مهام الترميز المتكررة والمساعدة في حل المشكلات المعقدة.
فيما يلي بعض الطرق التي يمكن لفريق الهندسة لديك الاستفادة منها:
- إكمال الكود: إنشاء نصوص الوظائف تلقائيًا من التعليقات أو سلاسل المستندات
- اكتشاف الأخطاء: تحليل مقتطفات الكود لتحديد الأخطاء المحتملة أو العيوب المنطقية
- شرح الكود: ترجمة الخوارزميات المعقدة أو الكود القديم إلى لغة إنجليزية بسيطة
- إنشاء الاختبارات: قم بإنشاء اختبارات الوحدة بناءً على توقيع الدالة والسلوك المتوقع.
تطبيقات RAG وتطبيقات السياق الطويل
الإنشاء المعزز بالاسترجاع (RAG) هو تقنية قوية تבסس استجابات النموذج على البيانات الخاصة بشركتك. ومع ذلك، غالبًا ما تواجه أنظمة RAG صعوبات مع النماذج التي تحتوي على نوافذ سياق صغيرة، مما يفرض تقسيمًا قويًا للبيانات قد يؤدي إلى فقدان سياق مهم. نافذة السياق 32K في DBRX تجعله أساسًا ممتازًا لتطبيقات RAG القوية.
يتيح لك ذلك إنشاء أدوات داخلية قوية، مثل:
- البحث المؤسسي: أنشئ روبوت دردشة يجيب على أسئلة الموظفين باستخدام قاعدة المعرفة الداخلية الخاصة بك.
- دعم العملاء: أنشئ وكيلًا يولد استجابات الدعم استنادًا إلى وثائق منتجك
- المساعدة في البحث: تطوير أداة يمكنها تجميع المعلومات من مئات الصفحات من الأوراق البحثية
- التحقق من الامتثال: تحقق تلقائيًا من النصوص التسويقية وفقًا لإرشادات العلامة التجارية الداخلية أو الوثائق التنظيمية
كيفية دمج تدريب DBRX مع سير عمل فريقك
إن نجاح مشروع تدريب نماذج الذكاء الاصطناعي لا يقتصر على البرمجة والحوسبة فحسب. إنه جهد تعاوني يشارك فيه مهندسو التعلم الآلي وعلماء البيانات ومديرو المنتجات وأصحاب المصلحة.
عندما يكون هذا التعاون موزعًا عبر دفاتر Jupyter وقنوات Slack وأدوات إدارة المشاريع المنفصلة، فإنك تخلق تشتت السياق، وهي حالة تتشتت فيها المعلومات الهامة للمشروع عبر العديد من الأدوات.
ClickUp يحل هذه المشكلة. بدلاً من التوفيق بين عدة أدوات، تحصل على مساحة عمل واحدة متكاملة للذكاء الاصطناعي تجمع بين إدارة المشاريع والتوثيق والتواصل، بحيث تظل تجاربك متصلة من التخطيط إلى التنفيذ إلى التقييم.
لا تفقد أبدًا تتبع التجارب والتقدم المحرز
عند إجراء تجارب متعددة، فإن أصعب جزء ليس تدريب النموذج، بل تتبع التغييرات التي طرأت خلال العملية. ما هي نسخة مجموعة البيانات التي تم استخدامها، وما هو معدل التعلم الأفضل أداءً، أو أي عملية تم تنفيذها؟
ClickUp يجعل هذه العملية سهلة للغاية بالنسبة لك. يمكنك تتبع كل عملية تدريب على حدة في ClickUp Tasks، وضمن المهام، يمكنك استخدام الحقول المخصصة لتسجيل:
- إصدار مجموعة البيانات
- المعلمات الفائقة
- نوع النموذج (DBRX Base مقابل DBRX Instruct)
- حالة التدريب (في قائمة الانتظار، قيد التشغيل، قيد التقييم، قيد النشر)
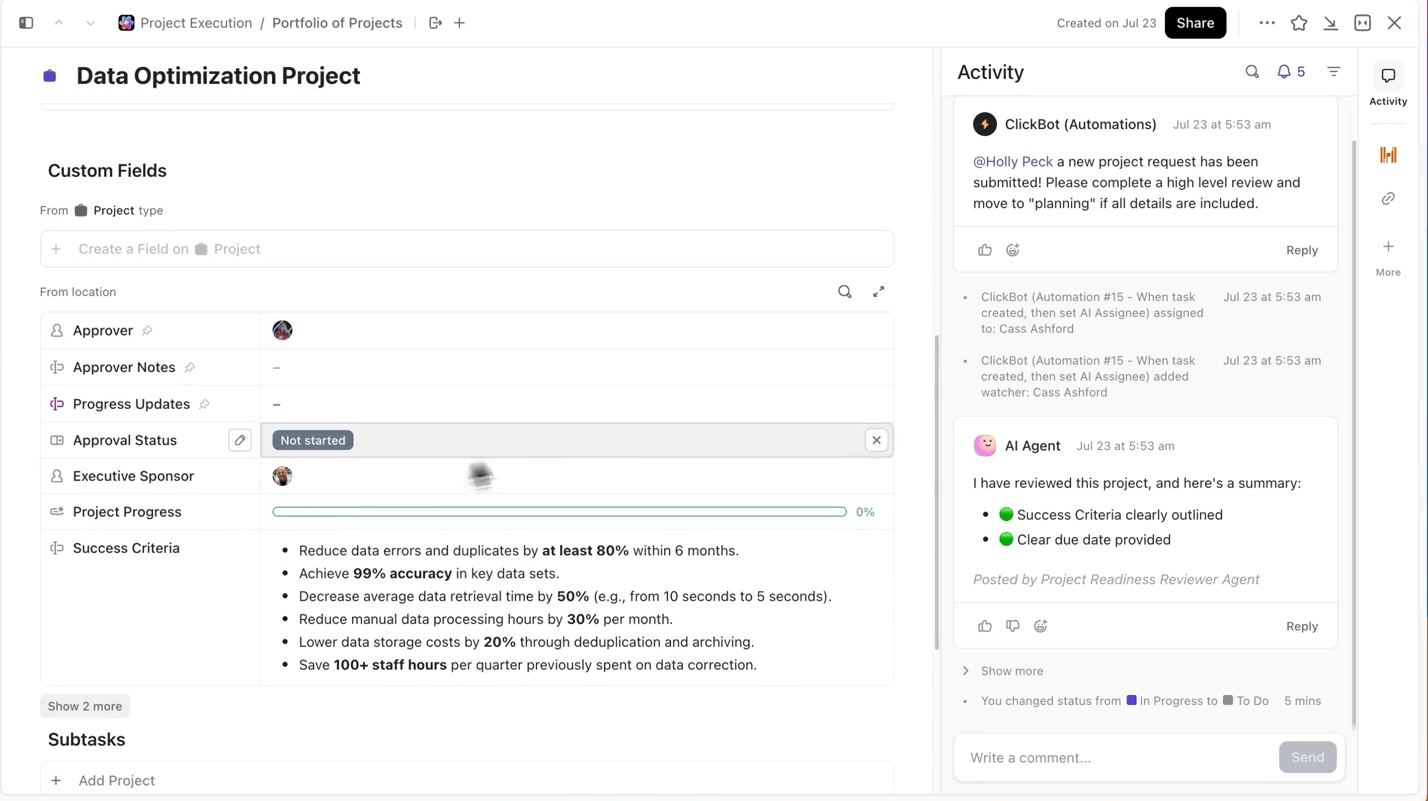
وبهذه الطريقة، يمكن البحث عن كل تجربة موثقة، ومقارنتها بسهولة مع التجارب الأخرى، وتكرارها.
حافظ على ارتباط وثائق النموذج بالعمل
لن تضطر إلى التنقل بين دفاتر Jupyter وملفات README ومواضيع Slack لفهم سياق مهمة التجربة.
باستخدام ClickUp Docs، يمكنك الحفاظ على تنظيم بنية النموذج ونصوص إعداد البيانات أو مقاييس التقييم وإتاحتها من خلال توثيقها في مستند قابل للبحث يرتبط مباشرة بمهام التجربة التي جاءت منها.

💡نصيحة احترافية: احتفظ بموجز مشروع حي في ClickUp Docs يوضح كل قرار بالتفصيل، من الهندسة إلى النشر، حتى يتمكن أعضاء الفريق الجدد من الاطلاع على تفاصيل المشروع دون الحاجة إلى البحث في المواضيع القديمة.
امنح أصحاب المصلحة رؤية في الوقت الفعلي
تعرض لوحات معلومات ClickUp تقدم التجربة وحجم عمل الفريق في الوقت الفعلي. I
بدلاً من تجميع التحديثات يدويًا أو إرسال رسائل البريد الإلكتروني، يتم تحديث لوحات المعلومات تلقائيًا بناءً على البيانات الموجودة في مهامك. لذلك يمكن لأصحاب المصلحة التحقق في أي وقت، ومعرفة الوضع الحالي، ولن يضطروا أبدًا إلى مقاطعتك بأسئلة من نوع "ما هو الوضع؟".
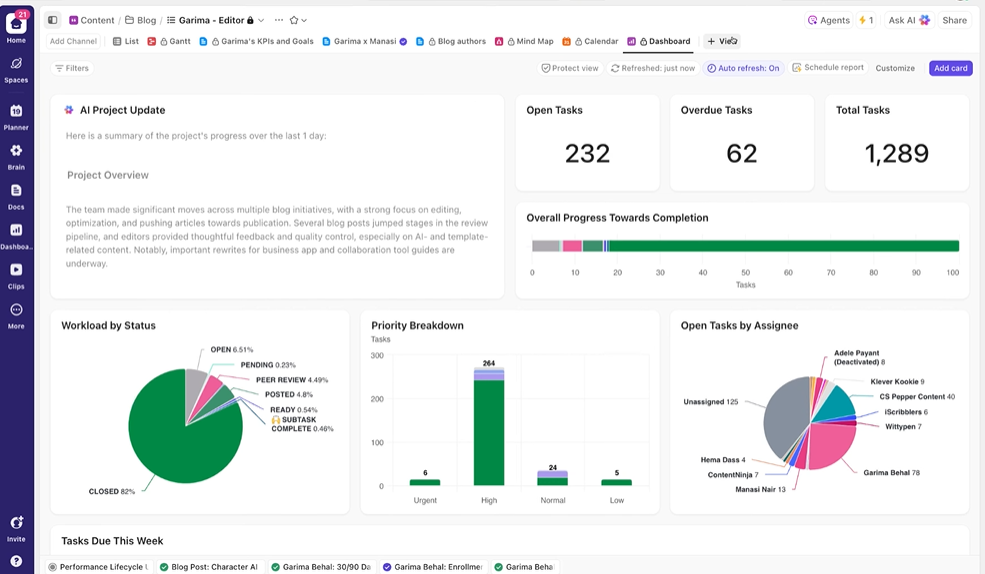
بهذه الطريقة، يمكنك التركيز على إجراء التجارب بدلاً من الاضطرار إلى الإبلاغ عنها يدويًا باستمرار.
حوّل الذكاء الاصطناعي إلى مساعدك الذكي في المشاريع
لست بحاجة إلى البحث يدويًا في أسابيع من بيانات التدريب للحصول على ملخص للتجارب حتى الآن. ما عليك سوى ذكر @Brain في أي تعليق على المهمة، وسيقدم لك ClickUp Brain المساعدة التي تحتاجها مع السياق الكامل لمشاريعك السابقة والجارية.
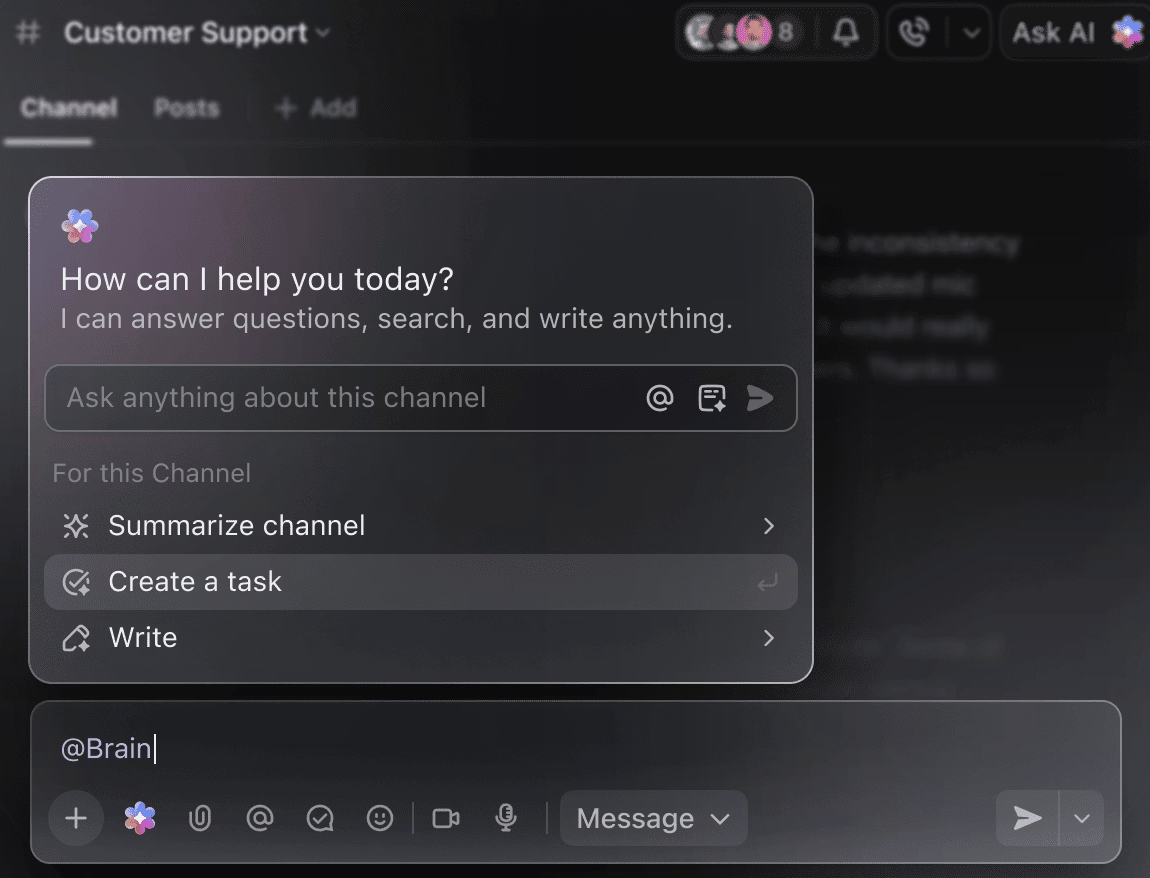
يمكنك أن تطلب من Brain "تلخيص تجارب الأسبوع الماضي في 5 نقاط" أو "صياغة مستند بأحدث نتائج المعلمات الفائقة"، وستحصل على الفور على ناتج متقن.
🧠 ميزة ClickUp: تأخذ Super Agents من ClickUp هذا الأمر إلى أبعد من ذلك — فهي قادرة على أتمتة سير العمل بالكامل بناءً على المحفزات التي تحددها، وليس مجرد الإجابة على أسئلتك. باستخدام Super Agents، يمكنك إنشاء مهمة تدريب DBRX جديدة تلقائيًا كلما تم تحميل مجموعة بيانات، وإخطار فريقك، وربط المستندات ذات الصلة عند انتهاء التدريب أو الوصول إلى نقطة فحص، وإنشاء ملخص أسبوعي للتقدم المحرز وإرساله إلى أصحاب المصلحة دون أن تلمس أي شيء.
الأخطاء الشائعة التي يجب تجنبها
الشروع في مشروع تدريب DBRX أمر مثير، ولكن هناك بعض العقبات الشائعة التي يمكن أن تعرقل تقدمك. تجنب هذه الأخطاء سيوفر لك الوقت والمال والكثير من الإحباط.
- التقليل من متطلبات الأجهزة: DBRX قوي، ولكنه كبير أيضًا. ستؤدي محاولة تشغيله على أجهزة غير ملائمة إلى حدوث أخطاء في الذاكرة وفشل مهام التدريب. ضع في اعتبارك أن DBRX (132B) يتطلب ما لا يقل عن 264 جيجابايت من ذاكرة VRAM للاستدلال 16 بت، أو ما يقرب من 70 جيجابايت إلى 80 جيجابايت عند استخدام التكمية 4 بت.
- تخطي فحوصات جودة البيانات: البيانات غير الصالحة تؤدي إلى نتائج غير صالحة. إن الضبط الدقيق لمجموعة بيانات فوضوية ومنخفضة الجودة لن يؤدي إلا إلى تعليم النموذج إنتاج مخرجات فوضوية ومنخفضة الجودة.
- تجاهل حدود طول السياق: على الرغم من أن نافذة السياق 32K في DBRX كبيرة، إلا أنها ليست لانهائية. سيؤدي إدخال مدخلات النموذج التي تتجاوز هذا الحد إلى اقتطاع صامت وأداء ضعيف.
- استخدام Base عندما يكون Instruct مناسبًا: DBRX Base هو نموذج أولي ومدرب مسبقًا مخصص للتدريب الإضافي على نطاق واسع. بالنسبة لمعظم المهام التي تتطلب اتباع التعليمات، يجب أن تبدأ بـ DBRX Instruct، الذي تم ضبطه بالفعل لهذا الغرض.
- فصل عمل التدريب عن تنسيق المشاريع: عندما يتم تتبع تجاربك في أداة واحدة وخطة مشروعك في أداة أخرى، فإنك تخلق فجوات في المعلومات. استخدم منصة متكاملة مثل ClickUp للحفاظ على تزامن عملك الفني وتنسيق المشاريع.
- إهمال التقييم قبل النشر: قد يفشل النموذج الذي يعمل بشكل جيد على بيانات التدريب الخاصة بك بشكل كبير في العالم الحقيقي. قم دائمًا بالتحقق من صحة النموذج المعدل بدقة على مجموعة اختبار محتجزة قبل نشره في الإنتاج.
- تجاهل تعقيدات الضبط الدقيق: نظرًا لأن DBRX هو نموذج مزيج من الخبراء، فقد تتطلب نصوص الضبط الدقيق القياسية مكتبات متخصصة مثل Megatron-LM أو PyTorch FSDP للتعامل مع تجزئة المعلمات عبر عدة وحدات معالجة رسومات (GPU).
DBRX مقابل منصات تدريب الذكاء الاصطناعي الأخرى
يتطلب اتخاذ قرار بشأن منصة تدريب الذكاء الاصطناعي مفاضلة أساسية: التحكم مقابل الراحة. النماذج الاحتكارية التي تعمل فقط مع واجهة برمجة التطبيقات (API) سهلة الاستخدام ولكنها تقيدك بنظام بيئي خاص بمورد معين.
توفر نماذج الأوزان المفتوحة مثل DBRX تحكمًا كاملاً ولكنها تتطلب المزيد من الخبرة الفنية والبنية التحتية. قد يجعلك هذا الاختيار تشعر بالارتباك، غير متأكد من المسار الذي يدعم أهدافك طويلة المدى بالفعل — وهو تحدٍ يواجهه العديد من الفرق أثناء اعتماد الذكاء الاصطناعي.
يوضح هذا الجدول الفروق الرئيسية لمساعدتك في اتخاذ قرار مستنير.
| الأوزان | فتح (مخصص) | ملكية خاصة | فتح (مخصص) | ملكية خاصة |
| الضبط الدقيق | تحكم كامل | قائم على واجهة برمجة التطبيقات | تحكم كامل | قائم على واجهة برمجة التطبيقات |
| الاستضافة الذاتية | نعم | لا | نعم | لا |
| الترخيص | نموذج DB المفتوح | شروط OpenAI | مجتمع Llama | مصطلحات أنثروبولوجية |
| السياق | 32 ألف | 128 ألف – مليون | 128K | 200 ألف – مليون |
يعد DBRX الخيار المناسب عندما تحتاج إلى التحكم الكامل في النموذج، أو يجب عليك الاستضافة الذاتية لأسباب تتعلق بالأمان أو الامتثال، أو تريد المرونة التي توفرها الترخيص التجاري المتساهل. إذا لم تكن لديك بنية أساسية مخصصة لوحدة معالجة الرسومات (GPU) — أو كنت تقدر السرعة في الوصول إلى السوق أكثر من التخصيص العميق — فقد تكون البدائل القائمة على واجهة برمجة التطبيقات (API) أكثر ملاءمة.
ابدأ التدريب بشكل أكثر ذكاءً مع ClickUp
يوفر لك DBRX أساسًا جاهزًا للمؤسسات لبناء تطبيقات الذكاء الاصطناعي المخصصة، مع الشفافية والتحكم اللذين لا تحصل عليهما من النماذج الاحتكارية. تعمل بنية MoE الفعالة على خفض تكاليف الاستدلال، كما أن تصميمها المفتوح يجعل الضبط الدقيق أمرًا سهلاً. لكن التكنولوجيا القوية ليست سوى نصف المعادلة.
يأتي النجاح الحقيقي من مواءمة عملك الفني مع سير عمل فريقك التعاوني. تدريب نماذج الذكاء الاصطناعي هو عمل جماعي، ومن الضروري الحفاظ على تزامن التجارب والوثائق والتواصل مع الأطراف المعنية. عندما تجمع كل شيء في مساحة عمل واحدة متقاربة وتقلل من انتشار السياق، يمكنك تقديم نماذج أفضل وبشكل أسرع.
ابدأ مجانًا مع ClickUp لتنسيق مشاريع تدريب الذكاء الاصطناعي في مساحة عمل واحدة. ✨
الأسئلة المتداولة
يمكنك مراقبة التدريب باستخدام أدوات ML القياسية مثل TensorBoard أو Weights & Biases أو MLflow. إذا كنت تقوم بالتدريب داخل نظام Databricks البيئي، فإن MLflow مدمج أصلاً لتتبع التجارب بسلاسة.
نعم، يمكن دمج DBRX في خطوط أنابيب MLOps القياسية. من خلال تحويل النموذج إلى حاوية، يمكنك نشره باستخدام منصات التنسيق مثل Kubeflow أو سير عمل CI/CD المخصص.
DBRX Base هو النموذج الأساسي المدرب مسبقًا والمخصص للفرق التي ترغب في إجراء تدريب مسبق مستمر خاص بالمجال أو ضبط دقيق للهندسة العميقة. DBRX Instruct هو إصدار مضبوط بدقة ومُحسّن لاتباع التعليمات، مما يجعله نقطة انطلاق أفضل لمعظم تطوير التطبيقات.
الفرق الرئيسي هو التحكم. يمنحك DBRX وصولاً كاملاً إلى أوزان النموذج من أجل التخصيص العميق والاستضافة الذاتية، في حين أن GPT-4 هو خدمة تعتمد على واجهة برمجة التطبيقات فقط.
تتوفر أوزان نموذج DBRX مجانًا بموجب ترخيص Databricks Open Model License. ومع ذلك، فإنك تتحمل مسؤولية تكاليف البنية التحتية الحاسوبية اللازمة لتشغيل النموذج أو ضبطه.