
A maioria das equipes que exploram modelos de IA de código aberto descobre que o LLaMA da Meta oferece uma combinação rara de potência e flexibilidade, mas a configuração técnica pode parecer como montar móveis sem instruções.
Este guia orienta você na criação de um chatbot LLaMA funcional a partir do zero, cobrindo tudo, desde requisitos de hardware e acesso ao modelo até engenharia de prompts e estratégias de implantação.
Vamos começar!
O que é LLaMA e por que usá-lo para chatbots?
Criar um chatbot com APIs proprietárias muitas vezes dá a sensação de que você está preso ao sistema de outra pessoa, enfrentando custos imprevisíveis e questões de privacidade de dados. Essa dependência do fornecedor significa que você não pode personalizar verdadeiramente o modelo para as necessidades exclusivas da sua equipe, levando a respostas genéricas e possíveis dores de cabeça com conformidade.
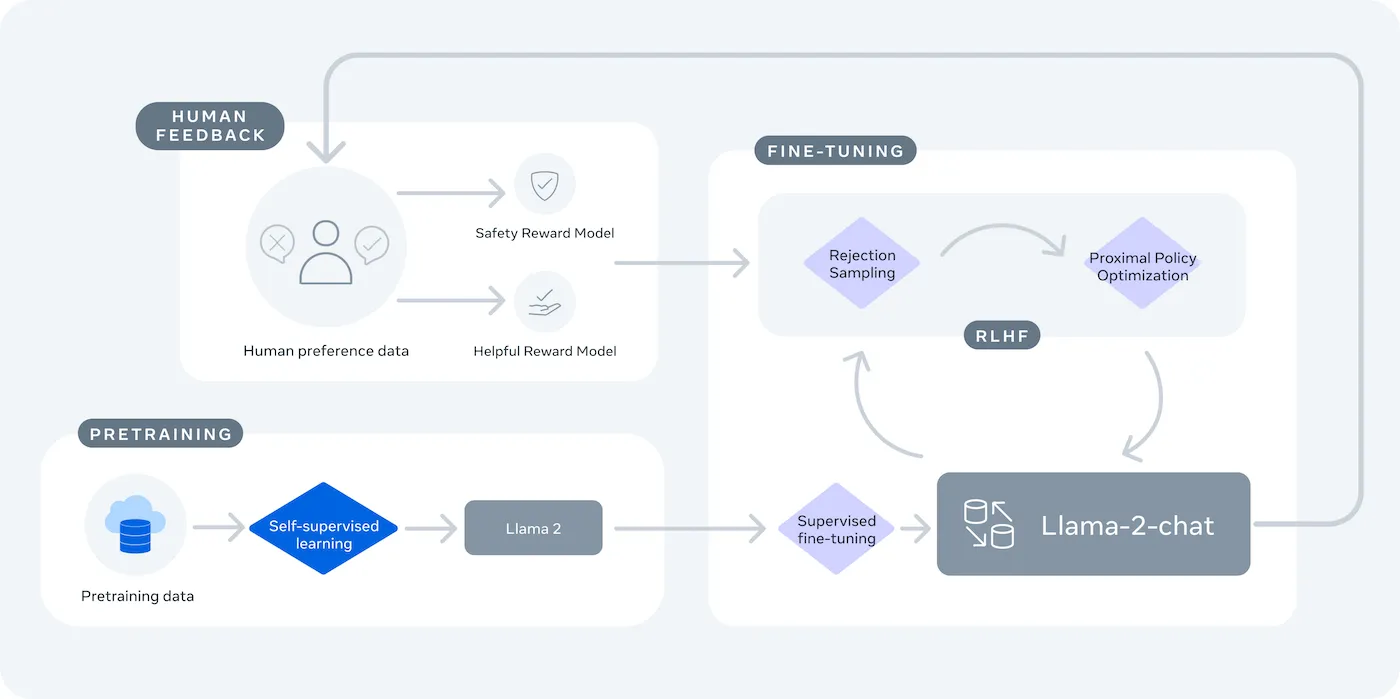
LLaMA (Large Language Model Meta AI) é a família de modelos de linguagem de peso aberto da Meta e oferece uma alternativa poderosa. Ele foi projetado para uso comercial e de pesquisa, oferecendo o controle que os modelos de código fechado não oferecem.
Os modelos LLaMA vêm em tamanhos diferentes, medidos em parâmetros (por exemplo, 7B, 13B, 70B). Pense nos parâmetros como uma medida da complexidade e do poder do modelo — modelos maiores são mais capazes, mas exigem mais recursos computacionais.
Veja por que você pode usar um chatbot LLaMA:
- Privacidade de dados: quando você executa um modelo em sua própria infraestrutura, seus dados de conversação nunca saem do seu ambiente. Isso é fundamental para equipes que lidam com informações confidenciais.
- Personalização: você pode ajustar um modelo LLaMA com base nos documentos ou dados internos da sua empresa. Isso ajuda o modelo a entender seu contexto específico e fornecer respostas muito mais relevantes.
- Previsibilidade de custos: após a configuração inicial do hardware, você não precisa se preocupar com cobranças de API por token. Seus custos se tornam fixos e previsíveis.
- Sem limites de taxa: a capacidade do seu chatbot é limitada pelo seu próprio hardware, não pelas cotas de um fornecedor. Você pode dimensionar conforme necessário.
A principal desvantagem é a conveniência em troca do controle. O LLaMA requer uma configuração mais técnica do que uma API plug-and-play. Para chatbots de produção, as equipes normalmente usam o LLaMA 2 ou o mais recente LLaMA 3, que oferece raciocínio aprimorado e pode lidar com mais texto de uma só vez.
O que você precisa antes de criar um chatbot LLaMA
Começar um projeto de desenvolvimento sem as ferramentas certas é uma receita para a frustração. Você chega na metade do caminho e percebe que está faltando um componente essencial de hardware ou software, atrapalhando seu progresso e desperdiçando horas do seu tempo.
Para evitar isso, reúna tudo o que você precisa com antecedência. Aqui está uma lista de verificação para garantir um início tranquilo. 🛠️
Requisitos de hardware
| Tamanho do modelo | VRAM mínima | Opção alternativa |
|---|---|---|
| 7 bilhões de parâmetros | 8 GB | Instância de GPU na nuvem |
| 13 bilhões de parâmetros | 16 GB | Instância de GPU na nuvem |
| 70 bilhões de parâmetros | Várias GPUs | Quantização ou nuvem |
Se o seu computador local não tiver uma unidade de processamento gráfico (GPU) potente o suficiente, você pode usar serviços em nuvem como AWS ou GCP. Plataformas de inferência como Baseten e Replicate também oferecem acesso à GPU com pagamento conforme o uso.
Requisitos de software
- Python 3.8+: esta é a linguagem de programação padrão para projetos de aprendizado de máquina.
- Gerenciador de pacotes: você precisará do pip ou do Conda para instalar as bibliotecas necessárias para o seu projeto.
- Ambiente virtual: esta é uma prática recomendada que mantém as dependências do seu projeto isoladas de outros projetos Python na sua máquina.
Requisitos de acesso
- Conta Hugging Face: você precisará de uma conta para baixar os pesos do modelo LLaMA.
- Aprovação da Meta: você deve aceitar o contrato de licença da Meta para ter acesso aos modelos LLaMA, que geralmente são aprovados em poucas horas.
- Chaves API: elas só são necessárias se você decidir usar um endpoint de inferência hospedado em vez de executar o modelo localmente.
Para este guia, usaremos a estrutura LangChain. Ela simplifica muitas das partes complexas da criação de um chatbot, como o gerenciamento de prompts e o histórico de conversas.
{kind=link}
Como criar um chatbot com o LLaMA passo a passo
Conectar todas as peças técnicas de um chatbot — o modelo, o prompt, a memória — pode parecer uma tarefa difícil. É fácil se perder no código, o que leva a bugs e a um chatbot que não funciona como esperado. Este guia passo a passo divide o processo em partes simples e gerenciáveis.
Essa abordagem funciona independentemente de você estar executando o modelo em sua própria máquina ou usando um serviço hospedado.
Etapa 1: Instale os pacotes necessários
Primeiro, você precisa instalar as bibliotecas Python principais. Abra seu terminal e execute este comando:
pip install langchain transformers accelerate torch
Se você estiver usando um serviço hospedado como o Baseten para inferência, também precisará instalar seu kit de desenvolvimento de software (SDK) específico:
pip install baseten
Veja o que cada um desses pacotes oferece:
- Langchain: uma estrutura que ajuda a criar aplicativos com grandes modelos de linguagem, incluindo gerenciamento de cadeias de conversação e memória.
- Transformers: a biblioteca Hugging Face para carregar e executar o modelo LLaMA.
- Accelerate: uma biblioteca que ajuda a otimizar a forma como o modelo é carregado na sua CPU e GPU.
- Torch: a biblioteca PyTorch, que fornece o poder de back-end para os cálculos do modelo.
Se você estiver executando o modelo localmente em uma máquina com uma GPU NVIDIA, certifique-se de ter o CUDA instalado e configurado corretamente. Isso permite que o modelo use a GPU para um desempenho muito mais rápido.
Etapa 2: Obtenha acesso aos modelos LLaMA
Antes de baixar o modelo, você precisa obter acesso oficial da Meta através do Hugging Face.
- Crie uma conta em huggingface.co
- Acesse a página do modelo, por exemplo, meta-llama/Llama-2-7b-chat-hf
- Clique em “Acessar repositório” e concorde com os termos de licença da Meta.
- Nas configurações da sua conta Hugging Face, gere um novo token de acesso.
- No seu terminal, execute huggingface-cli login e cole seu token para autenticar sua máquina.
A aprovação geralmente é rápida. Certifique-se de escolher uma variante do modelo com “chat” no nome, pois elas foram treinadas especificamente para tarefas de conversação.
Etapa 3: Carregue o modelo LLaMA
Agora você pode carregar o modelo em seu código. Você tem duas opções principais, dependendo do seu hardware.
Se você tiver uma GPU potente o suficiente, poderá carregar o modelo localmente:
Se o seu hardware for limitado, você pode usar um serviço de inferência hospedado:
O comando device_map="auto" instrui a biblioteca transformers a distribuir automaticamente o modelo por todas as GPUs disponíveis.
Se você ainda estiver com falta de memória, pode usar uma técnica chamada quantização para reduzir o tamanho do modelo, embora isso possa reduzir um pouco o desempenho.
Etapa 4: crie um modelo de prompt
Os modelos de chat LLaMA são treinados para esperar um formato específico para prompts. Um modelo de prompt garante que sua entrada esteja estruturada corretamente.
Vamos detalhar esse formato:
- <
>: Esta seção contém o prompt do sistema, que fornece ao modelo suas instruções principais e define sua personalidade. - [INST]: Isso marca o início da pergunta ou instrução do usuário.
- [/INST]: Isso sinaliza ao modelo que é hora de gerar uma resposta.
Lembre-se de que versões diferentes do LLaMA podem usar modelos ligeiramente diferentes. Sempre verifique a documentação do modelo no Hugging Face para obter o formato correto.
Etapa 5: Configure a cadeia do chatbot
Em seguida, você conectará seu modelo e modelo de prompt a uma cadeia de conversação usando o LangChain. Essa cadeia também incluirá memória para acompanhar a conversa.
O LangChain oferece vários tipos de memória:
- ConversationBufferMemory: Esta é a opção mais simples. Ela armazena todo o histórico de conversas.
- Memória de resumo da conversa: para economizar espaço, essa opção resume periodicamente as partes mais antigas da conversa.
- ConversationBufferWindowMemory: mantém apenas as últimas trocas na memória, o que é útil para evitar que o contexto fique muito longo.
Para testes, o ConversationBufferMemory é um ótimo ponto de partida.
Etapa 6: Execute o loop do chatbot
Por fim, você pode criar um loop simples para interagir com seu chatbot a partir do terminal.
Em uma aplicação no mundo real, você substituiria esse loop por um endpoint de API usando uma estrutura como FastAPI ou Flask. Você também pode transmitir a resposta do modelo de volta ao usuário, o que torna o chatbot muito mais rápido.
Você também pode ajustar parâmetros como temperatura para controlar a aleatoriedade das respostas. Uma temperatura baixa (por exemplo, 0,2) torna a saída mais determinística e factual, enquanto uma temperatura mais alta (por exemplo, 0,8) incentiva mais criatividade.
Como testar seu chatbot LLaMA
Você criou um chatbot que fornece respostas, mas ele está pronto para usuários reais? Implantar um bot não testado pode levar a falhas embaraçosas, como fornecer informações incorretas ou gerar conteúdo inadequado, o que pode prejudicar a reputação da sua empresa.
Um plano de testes sistemático é a solução para essa incerteza. Ele garante que seu chatbot seja robusto, confiável e seguro.
Teste funcional:
- Casos extremos: teste como o bot lida com entradas vazias, mensagens muito longas e caracteres especiais.
- Verificação de memória: garanta que o chatbot se lembre do contexto ao longo de várias rodadas de uma conversa.
- Instruções a seguir: Verifique se o bot segue as regras definidas no prompt do sistema.
Avaliação de qualidade:
- Relevância: A resposta realmente responde à pergunta do usuário?
- Precisão: as informações fornecidas estão corretas?
- Coerência: A conversa flui de maneira lógica?
- Segurança: O bot se recusa a responder a solicitações inadequadas ou prejudiciais?
Teste de desempenho:
- Latência: meça quanto tempo leva para o bot começar a responder e concluir sua resposta.
- Uso de recursos: monitore a quantidade de memória GPU que o modelo usa durante a inferência.
- Concorrência: teste o desempenho do sistema quando vários usuários estão interagindo com ele ao mesmo tempo.
Além disso, fique atento a problemas comuns de LLM, como alucinações (afirmar informações falsas com confiança), desvio de contexto (perder o foco do assunto em uma conversa longa) e repetição. Registrar todas as conversas de teste é uma ótima maneira de identificar padrões e corrigir problemas antes que eles cheguem aos usuários.
📚 Leia também: A diferença entre testes funcionais e testes não funcionais
Casos de uso do LLaMA Chatbot para equipes
Depois de passar pela mecânica de ajuste fino e implantação, o LLaMA se torna mais valioso quando aplicado a problemas cotidianos da equipe, e não a demonstrações abstratas de IA. As equipes normalmente não precisam de um “chatbot”; elas precisam de acesso mais rápido ao conhecimento, menos transferências manuais e menos trabalho repetitivo.
Assistente de conhecimento interno
Ao ajustar o LLaMA em documentação interna, wikis e perguntas frequentes — ou combiná-lo com uma base de conhecimento baseada em RAG — as equipes podem fazer perguntas em linguagem natural e obter respostas precisas e contextuais. Isso elimina o atrito de pesquisar em ferramentas dispersas, mantendo os dados confidenciais totalmente internos, em vez de enviá-los para APIs de terceiros.
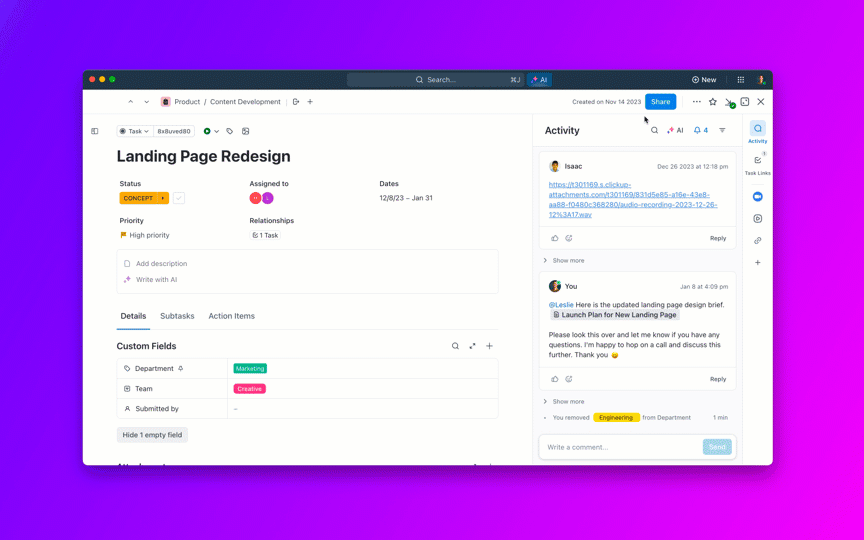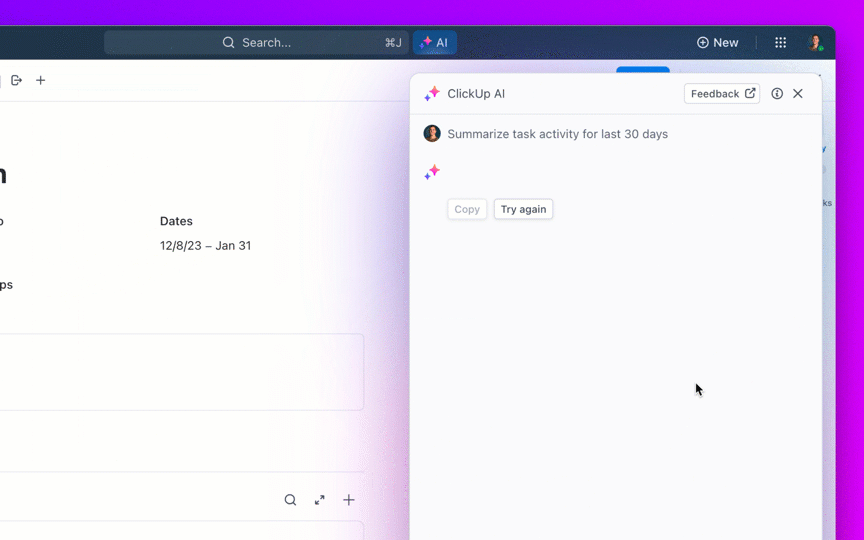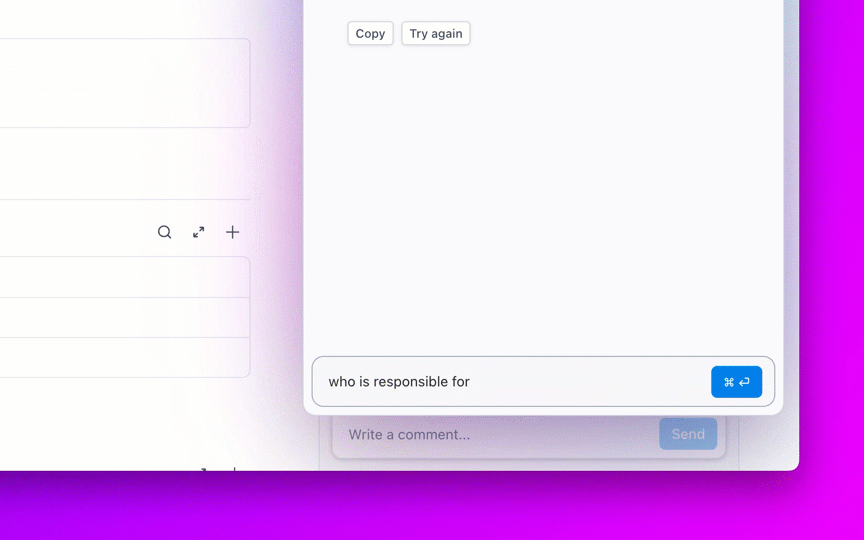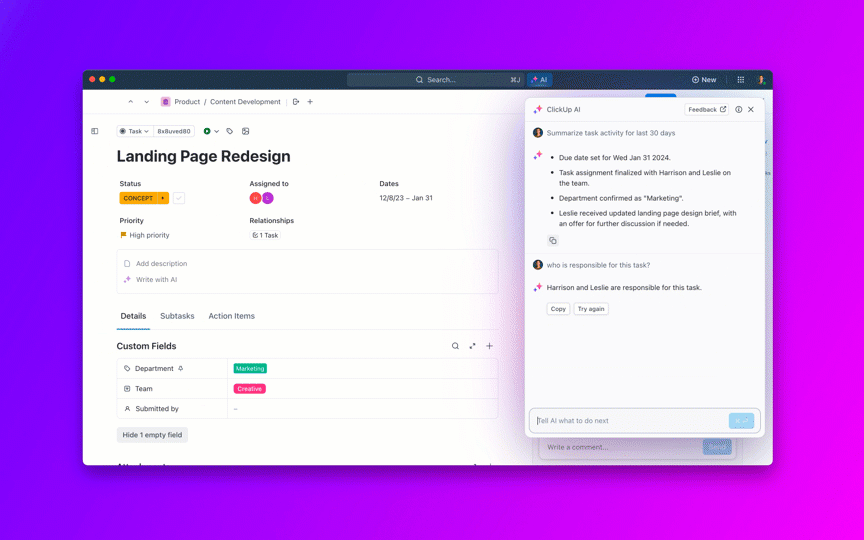
🌟 A Pesquisa Empresarial no ClickUp e o agente pré-construído Ambient Answers fornecem respostas contextuais detalhadas às suas perguntas usando o conhecimento dentro do seu espaço de trabalho ClickUp.
Auxiliar de revisão de código
Quando treinado com sua própria base de código e guias de estilo, o LLaMA pode atuar como um assistente de revisão de código contextual. Em vez de práticas recomendadas genéricas, os desenvolvedores recebem sugestões alinhadas com as convenções da equipe, decisões arquitetônicas e padrões históricos.
🌟 Um auxiliar de revisão de código baseado em LLaMA pode revelar problemas, sugerir melhorias ou explicar códigos desconhecidos. O Codegen da ClickUp vai um passo além, atuando dentro do fluxo de trabalho de desenvolvimento — criando solicitações de pull, aplicando refatorações ou atualizando arquivos diretamente em resposta a essas informações. O resultado é menos copiar e colar e menos falhas na transição entre “pensar” e “fazer”.
Triagem do suporte ao cliente
O LLaMA pode ser treinado para classificação de intenções, a fim de entender as consultas recebidas dos clientes e encaminhá-las para a equipe ou fluxo de trabalho certo. Perguntas comuns podem ser tratadas automaticamente, enquanto casos extremos são encaminhados para agentes humanos com o contexto anexado, reduzindo os tempos de resposta sem sacrificar a qualidade.
Você também pode criar um Super Agente de Triagem usando linguagem natural dentro do seu espaço de trabalho ClickUp. Saiba mais
Resumo de reuniões e acompanhamento
Usando transcrições de reuniões como entrada, o LLaMA pode extrair decisões, itens de ação e pontos-chave de discussão. O valor real surge quando esses resultados fluem diretamente para ferramentas de gerenciamento de tarefas, transformando conversas em trabalho rastreado.
🌟 O AI Meeting Notetaker da ClickUp não se limita a tomar notas de reuniões; ele redige resumos, gera itens de ação e vincula notas de reuniões aos seus documentos e tarefas.
Elaboração e iteração de documentos
As equipes podem usar o LLaMA para gerar rascunhos de relatórios, propostas ou documentação com base em modelos existentes e exemplos anteriores. Isso muda o foco da criação de uma página em branco para a revisão e o refinamento, acelerando a entrega sem reduzir os padrões.
🌟 O ClickUp Brain pode gerar rapidamente rascunhos para documentação, mantendo todo o conhecimento do seu local de trabalho em contexto. Experimente hoje mesmo.
Os chatbots com tecnologia LLaMA são mais eficazes quando incorporados aos fluxos de trabalho existentes — documentação, gerenciamento de projetos e comunicação em equipe — em vez de operarem como ferramentas independentes.
É aqui que integrar a IA diretamente ao seu espaço de trabalho faz toda a diferença. Em vez de criar uma ferramenta separada, você pode levar a IA conversacional para onde sua equipe já opera.
Por exemplo, você pode criar um bot LLaMA personalizado para atuar como um assistente de conhecimento. Mas se ele estiver fora da sua ferramenta de gerenciamento de projetos, sua equipe terá que mudar de contexto para fazer uma pergunta. Isso cria atrito e atrasa todo mundo.
Elimine essa mudança de contexto usando uma IA que já faz parte do seu fluxo de trabalho.
Faça perguntas sobre seus projetos, tarefas e documentos sem sair do ClickUp usando o ClickUp Brain. Basta digitar @brain em qualquer comentário de tarefa ou no ClickUp Chat para obter uma resposta instantânea e contextualizada. É como ter um membro da equipe que conhece perfeitamente todo o seu espaço de trabalho. 🤩
Isso transforma o chatbot de uma novidade em uma parte essencial do mecanismo de produtividade da sua equipe.
Limitações do uso do LLaMA para a criação de chatbots
Criar um chatbot LLaMA pode ser empoderador, mas as equipes muitas vezes são pegas de surpresa por complexidades ocultas. O modelo de código aberto “gratuito” pode acabar sendo mais caro e difícil de gerenciar do que o esperado, levando a uma experiência ruim para o usuário e a um ciclo de manutenção constante que consome recursos.
É importante entender as limitações antes de se comprometer.
- Complexidade técnica: a configuração e manutenção de um modelo LLaMA requer conhecimento de infraestrutura de aprendizado de máquina.
- Requisitos de hardware: Executar modelos maiores e mais capazes exige hardware GPU caro, e os custos de nuvem podem aumentar rapidamente.
- Restrições da janela de contexto: os modelos LLaMA têm memória limitada ( 4K tokens para LLaMA 2 ). O manuseio de documentos ou conversas longas requer estratégias complexas de fragmentação.
- Sem proteções de segurança integradas: você é responsável por implementar suas próprias medidas de filtragem de conteúdo e segurança.
- Manutenção contínua: à medida que novos modelos são lançados, você precisará atualizar seus sistemas, e modelos ajustados podem exigir um novo treinamento.
Modelos auto-hospedados também costumam ter latência mais alta do que APIs comerciais altamente otimizadas. Todas essas são cargas operacionais que as soluções gerenciadas lidam para você.
📮ClickUp Insight: 88% dos participantes da nossa pesquisa usam IA para suas tarefas pessoais, mas mais de 50% evitam usá-la no trabalho. As três principais barreiras? Falta de integração perfeita, lacunas de conhecimento ou preocupações com segurança.
Mas e se a IA estiver integrada ao seu espaço de trabalho e já for segura? O ClickUp Brain, assistente de IA integrado do ClickUp, torna isso realidade. Ele entende comandos em linguagem simples, resolvendo todas as três preocupações relacionadas à adoção da IA, ao mesmo tempo em que conecta seu chat, tarefas, documentos e conhecimento em todo o espaço de trabalho. Encontre respostas e insights com um único clique!
Alternativas ao LLaMA para a criação de chatbots
O LLaMA é apenas uma opção entre uma infinidade de modelos de IA, e pode ser difícil descobrir qual é o mais adequado para você.
Veja como se divide o panorama das alternativas.
Outros modelos de código aberto:
- Mistral: Conhecido por seu forte desempenho mesmo com modelos menores, tornando-o eficiente.
- Falcon: Vem com uma licença muito permissiva, o que é ótimo para aplicações comerciais.
- MPT: Otimizado para lidar com documentos e conversas longas.
APIs comerciais:
- OpenAI (GPT-4, GPT-3.5): Geralmente considerados os modelos de linguagem de grande porte mais capazes, eles são muito fáceis de integrar.
- Anthropic (Claude): Conhecido por seus recursos de segurança robustos e janelas de contexto muito grandes.
- Google (Gemini): Oferece recursos multimodais poderosos, permitindo que ele entenda texto, imagens e áudio.
Você pode criá-lo sozinho com um modelo de código aberto, pagar por uma API comercial ou usar um espaço de trabalho de IA convergente que oferece uma solução pré-integrada com diferentes tipos de agentes de IA.
📚 Leia também: Como usar um chatbot para o seu negócio
Crie assistentes de IA sensíveis ao contexto com o ClickUp
Criar um chatbot com o LLaMA oferece um controle incrível sobre seus dados, custos e personalização. Mas esse controle vem acompanhado da responsabilidade pela infraestrutura, manutenção e segurança — tudo o que as APIs gerenciadas cuidam para você. O objetivo não é apenas criar um bot, mas tornar sua equipe mais produtiva, e um projeto de engenharia complexo às vezes pode distrair você disso.
A escolha certa depende dos recursos e das prioridades da sua equipe. Se você tem experiência em ML e necessidades rigorosas de privacidade, o LLaMA é uma opção fantástica. Se você prioriza velocidade e simplicidade, uma ferramenta integrada pode ser mais adequada.
Com o ClickUp, você obtém um espaço de trabalho de IA convergente com todas as suas tarefas, documentos e conversas em um só lugar, alimentado por IA integrada. Ele reduz a dispersão de contexto e ajuda as equipes a trabalhar de forma mais rápida e eficaz, com as informações certas ao alcance dos dedos por meio de Super Agentes personalizáveis e IA contextual.
Pare de perder tempo com infraestrutura e aproveite hoje mesmo os benefícios de um assistente de IA sensível ao contexto, sem precisar criar nada do zero. Comece gratuitamente com o ClickUp.
Perguntas frequentes (FAQ)
O custo depende inteiramente do seu método de implantação, e a previsão do projeto pode ajudar a estimá-lo. Se você usar seu próprio hardware, terá um custo inicial para a GPU, mas não haverá taxas contínuas por consulta. Os provedores de nuvem cobram uma taxa por hora com base no tamanho da GPU e do modelo.
Sim, as licenças para LLaMA 2 e LLaMA 3 permitem o uso comercial. No entanto, você deve concordar com os termos de uso da Meta e fornecer a atribuição necessária em seu produto.
O LLaMA 3 é o modelo mais novo e mais capaz, oferecendo melhores habilidades de raciocínio e uma janela de contexto maior (8K tokens contra 4K para o LLaMA 2). Isso significa que ele pode lidar com conversas e documentos mais longos, mas também requer mais recursos computacionais para funcionar.
Embora Python seja a linguagem mais comum para aprendizado de máquina devido às suas extensas bibliotecas, ela não é estritamente necessária. Algumas plataformas estão começando a oferecer soluções sem código ou com pouco código que permitem implantar um chatbot LLaMA com uma interface gráfica. /