
Os projetos de treinamento de IA raramente falham no nível do modelo. Eles enfrentam dificuldades quando os experimentos, a documentação e as atualizações das partes interessadas estão espalhados por muitas ferramentas.
Este guia orienta você no treinamento de modelos com o Databricks DBRX — um LLM que é até duas vezes mais eficiente em termos de computação do que outros modelos líderes —, mantendo o trabalho organizado no ClickUp.
Da configuração e ajuste fino à documentação e atualizações entre equipes, você verá como um único espaço de trabalho convergente ajuda a eliminar a dispersão de contexto e mantém sua equipe focada na construção, não na pesquisa. 🛠
O que é o DBRX?
O DBRX é um modelo de linguagem grande (LLM) poderoso e de código aberto, projetado especificamente para treinamento e inferência de modelos de IA empresarial. Por ser de código aberto sob a Databricks Open Model License, sua equipe tem acesso total aos pesos e à arquitetura do modelo, permitindo que você o inspecione, modifique e implante de acordo com suas necessidades.
Ele vem em duas variantes: DBRX Base para pré-treinamento profundo e DBRX Instruct para tarefas prontas para uso que seguem instruções.
Arquitetura DBRX e design de mistura de especialistas
O DBRX resolve tarefas usando uma arquitetura Mixture-of-Experts (MoE). Ao contrário dos modelos de linguagem tradicionais, que usam todos os seus bilhões de parâmetros para cada cálculo, o DBRX ativa apenas uma fração de seus parâmetros totais (os especialistas mais relevantes) para qualquer tarefa específica.
Pense nisso como uma equipe de especialistas; em vez de todos trabalharem em todos os problemas, o sistema encaminha cada tarefa de forma inteligente para os parâmetros mais qualificados.
Isso não apenas reduz o tempo de resposta, mas também oferece desempenho e resultados de alto nível, ao mesmo tempo em que reduz significativamente os custos computacionais.
Aqui está uma rápida visão geral das principais especificações:
- Parâmetros totais: 132 bilhões em todos os especialistas
- Parâmetros ativos: 36B por passagem para a frente
- Contagem de especialistas: 16 no total (MoE Top-4 routing), com 4 ativos para qualquer token específico
- Janela de contexto: 32 mil tokens
Especificações dos dados de treinamento e tokens do DBRX
O desempenho de um LLM é tão bom quanto os dados com os quais ele é treinado. O DBRX foi pré-treinado em um enorme conjunto de dados de 12 trilhões de tokens cuidadosamente selecionado pela equipe da Databricks usando suas ferramentas avançadas de processamento de dados. É exatamente por isso que ele teve um ótimo desempenho nos benchmarks do setor.
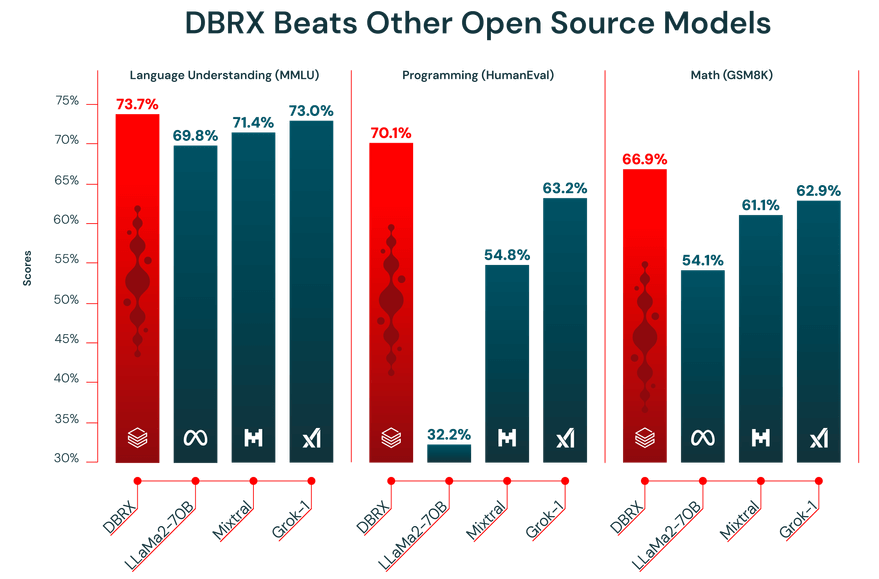
Além disso, o DBRX possui uma janela de contexto de 32.000 tokens. Essa é a quantidade de texto que o modelo pode considerar de uma só vez. Uma janela de contexto grande é muito útil para tarefas complexas, como resumir relatórios longos, pesquisar documentos jurídicos extensos ou construir sistemas avançados de geração aumentada por recuperação (RAG), pois permite que o modelo mantenha o contexto sem truncar ou esquecer informações.
🎥 Assista a este vídeo para ver como a coordenação simplificada de projetos pode transformar seu fluxo de trabalho de treinamento de IA e eliminar o atrito de alternar entre ferramentas desconectadas. 👇🏽
Como acessar e configurar o DBRX
O DBRX oferece duas rotas de acesso principais, ambas com acesso total aos pesos do modelo sob termos comerciais permissivos. Você pode usar o Hugging Face para obter flexibilidade máxima ou acessá-lo diretamente pelo Databricks para uma experiência mais integrada.
Acesse o DBRX através do Hugging Face
Para equipes que valorizam a flexibilidade e já estão familiarizadas com o ecossistema Hugging Face, acessar o DBRX através do Hub é o caminho ideal. Ele permite integrar o modelo aos seus fluxos de trabalho existentes baseados em transformadores.
Veja como começar:
- Crie ou faça login na sua conta Hugging Face
- Navegue até o cartão do modelo DBRX no Hub e aceite os termos da licença.
- Instale a biblioteca transformers junto com as dependências necessárias, como accelerate.
- Use a classe AutoModelForCausalLM em seu script Python para carregar o modelo DBRX.
- Configure seu pipeline de inferência, lembrando que o DBRX requer uma quantidade significativa de memória GPU (VRAM) para funcionar de maneira eficaz.
📖 Leia mais: Como configurar a temperatura do LLM
Acesse o DBRX através do Databricks
Se sua equipe já usa o Databricks para engenharia de dados ou aprendizado de máquina, acessar o DBRX por meio da plataforma é a maneira mais fácil. Isso elimina o atrito da configuração e oferece todas as ferramentas necessárias para MLOps exatamente onde você já está trabalhando.
Siga estas etapas em seu espaço de trabalho Databricks para começar:
- Navegue até a seção Model Garden ou Mosaic AI.
- Selecione DBRX Base ou DBRX Instruct, dependendo de suas necessidades.
- Configure um endpoint de serviço para acesso à API ou configure um ambiente de notebook para uso interativo.
- Comece a testar a inferência com prompts de amostra para garantir que tudo esteja funcionando corretamente antes de ampliar o treinamento ou a implantação do seu modelo de IA.
Essa abordagem oferece acesso contínuo a ferramentas como o MLflow para rastreamento de experimentos e o Unity Catalog para governança de modelos.
📮 ClickUp Insight: O profissional médio passa mais de 30 minutos por dia procurando informações relacionadas ao trabalho — isso significa mais de 120 horas por ano perdidas vasculhando e-mails, threads do Slack e arquivos espalhados.
Um assistente de IA inteligente integrado ao seu espaço de trabalho pode mudar isso. Conheça o ClickUp Brain.
Ele fornece insights e respostas instantâneas, exibindo os documentos, conversas e detalhes de tarefas certos em segundos — para que você possa parar de pesquisar e começar a trabalhar.
Como ajustar o DBRX e treinar modelos de IA personalizados
Um modelo pronto para uso, por mais poderoso que seja, nunca entenderá as nuances exclusivas do seu negócio. Como o DBRX é de código aberto, você pode ajustá-lo para criar um modelo personalizado que fale a linguagem da sua empresa ou execute uma tarefa específica que você gostaria que ele realizasse.
Aqui estão três maneiras comuns de fazer isso:
1. Ajuste o DBRX com conjuntos de dados Hugging Face
Para equipes que estão começando ou trabalhando em tarefas comuns, os conjuntos de dados públicos do Hugging Face Hub são um ótimo recurso. Eles são pré-formatados e fáceis de carregar, o que significa que você não precisa passar horas preparando seus dados.
O processo é bastante simples:
- Encontre um conjunto de dados no Hub que corresponda à sua tarefa (por exemplo, seguir instruções, resumir).
- Carregue-o usando a biblioteca de conjuntos de dados
- Certifique-se de que os dados estejam formatados em pares de instrução-resposta.
- Configure seu script de treinamento com hiperparâmetros como taxa de aprendizagem e tamanho do lote.
- Inicie o trabalho de treinamento, certificando-se de salvar pontos de verificação periodicamente.
- Avalie o modelo ajustado em um conjunto de validação retido para medir a melhoria.
2. Ajuste o DBRX com conjuntos de dados locais
Normalmente, você obterá os melhores resultados fazendo ajustes finos com seus próprios dados proprietários. Isso permite que você ensine ao modelo a terminologia, o estilo e o conhecimento específico da sua empresa. Lembre-se de que isso só vale a pena se seus dados estiverem limpos, bem preparados e tiverem volume suficiente.
Siga estas etapas para preparar seus dados internos:
- Coleta de dados: reúna exemplos de alta qualidade de seus wikis, documentos e bancos de dados internos.
- Conversão de formato: estruture seus dados em um formato consistente de instrução-resposta, geralmente como linhas JSON.
- Filtragem de qualidade: remova quaisquer exemplos de baixa qualidade, duplicados ou irrelevantes.
- Divisão de validação: reserve uma pequena parte dos seus dados (normalmente 10-15%) para avaliar o desempenho do modelo.
- Revisão de privacidade: remova ou oculte qualquer informação de identificação pessoal (PII) ou dados confidenciais.
3. Ajuste o DBRX com o StreamingDataset
Se o seu conjunto de dados acabar sendo grande demais para caber na memória da sua máquina, não se preocupe, você pode usar a biblioteca Streaming Dataset da Databricks. Ela permite que você transmita dados diretamente do armazenamento em nuvem enquanto o modelo está sendo treinado, em vez de carregar tudo na memória de uma só vez.
Veja como você pode fazer isso:
- Preparação de dados: limpe e estruture seus dados de treinamento e, em seguida, armazene-os em um formato transmissível, como JSONL ou CSV, em um armazenamento em nuvem.
- Conversão de formato de streaming: converta seu conjunto de dados em um formato compatível com streaming, como Mosaic Data Shard (MDS), para que ele possa ser lido com eficiência durante o treinamento.
- Configuração do carregador de treinamento: configure seu carregador de treinamento para apontar para o conjunto de dados remoto e defina um cache local para armazenamento temporário de dados.
- Inicialização do modelo: Inicie o processo de ajuste fino do DBRX usando uma estrutura de treinamento compatível com StreamingDataset, como LLM Foundry.
- Treinamento baseado em streaming: execute a tarefa de treinamento enquanto os dados são transmitidos em lotes durante o treinamento, em vez de carregados inteiramente na memória.
- Verificação e recuperação: retome o treinamento sem interrupções se uma execução for interrompida, sem duplicar ou pular dados.
- Avaliação e implantação: valide o desempenho do modelo ajustado e implante-o usando sua configuração preferida de serviço ou inferência.
💡Dica profissional: em vez de criar um plano de treinamento DBRX do zero, comece com o Modelo de Roteiro de Projetos de IA e Aprendizado de Máquina do ClickUp e ajuste-o às necessidades da sua equipe. Ele fornece uma estrutura clara para planejar conjuntos de dados, fases de treinamento, avaliação e implantação, para que você possa se concentrar em organizar seu trabalho em vez de estruturar um fluxo de trabalho.
Casos de uso do DBRX para treinamento de modelos de IA
Uma coisa é ter um modelo poderoso, mas outra é saber exatamente onde ele se destaca.
Quando você não tem uma visão clara dos pontos fortes de um modelo, é fácil gastar tempo e recursos tentando fazê-lo funcionar onde ele simplesmente não se encaixa. Isso leva a resultados abaixo da média e frustração.
A arquitetura exclusiva e os dados de treinamento do DBRX o tornam excepcionalmente adequado para vários casos de uso empresariais importantes. Conhecer esses pontos fortes ajuda você a alinhar o modelo com seus objetivos de negócios e maximizar o retorno sobre o investimento.
Geração de texto e criação de conteúdo
O DBRX Instruct é perfeitamente ajustado para seguir instruções e gerar textos de alta qualidade. Isso o torna uma ferramenta poderosa para automatizar uma ampla gama de tarefas relacionadas a conteúdo. Sua grande janela de contexto é uma vantagem significativa, permitindo que ele lide com documentos longos sem perder o fio da meada.
Você pode usá-lo para:
- Documentação técnica: gere e refine manuais de produtos, referências de API e guias do usuário.
- Conteúdo de marketing: rascunhos de posts de blog, boletins informativos por e-mail e atualizações nas redes sociais
- Geração de relatórios: resuma descobertas de dados complexos e crie resumos executivos concisos.
- Tradução e localização: adapte o conteúdo existente para novos mercados e públicos
Tarefas de geração de código e depuração
Uma parte significativa dos dados de treinamento do DBRX incluía código, tornando-o um suporte LLM capaz para desenvolvedores. Ele pode ajudar a acelerar os ciclos de desenvolvimento, automatizando tarefas repetitivas de codificação e auxiliando na resolução de problemas complexos.
Aqui estão algumas maneiras pelas quais sua equipe de engenharia pode aproveitá-lo:
- Conclusão de código: gere automaticamente corpos de funções a partir de comentários ou docstrings
- Detecção de bugs: analise trechos de código para identificar possíveis erros ou falhas lógicas.
- Explicação do código: traduza algoritmos complexos ou códigos legados para uma linguagem simples.
- Geração de testes: crie testes unitários com base na assinatura de uma função e no comportamento esperado.
RAG e aplicações de contexto longo
A geração aumentada por recuperação (RAG) é uma técnica poderosa que baseia as respostas de um modelo nos dados privados da sua empresa. No entanto, os sistemas RAG muitas vezes enfrentam dificuldades com modelos que têm janelas de contexto pequenas, forçando um fragmentação agressiva dos dados que pode perder contextos importantes. A janela de contexto de 32K do DBRX torna-o uma excelente base para aplicações RAG robustas.
Isso permite que você crie ferramentas internas poderosas, como:
- Pesquisa empresarial: crie um chatbot que responda às perguntas dos funcionários usando sua base de conhecimento interna.
- Suporte ao cliente: crie um agente que gere respostas de suporte baseadas na documentação do seu produto.
- Assistência à pesquisa: desenvolva uma ferramenta capaz de sintetizar informações de centenas de páginas de artigos de pesquisa.
- Verificação de conformidade: verifique automaticamente o texto de marketing em relação às diretrizes internas da marca ou documentos regulatórios.
Como integrar o treinamento DBRX ao fluxo de trabalho da sua equipe
Um projeto bem-sucedido de treinamento de modelos de IA envolve mais do que apenas código e computação. É um esforço colaborativo que envolve engenheiros de ML, cientistas de dados, gerentes de produto e partes interessadas.
Quando essa colaboração está espalhada por notebooks Jupyter, canais Slack e ferramentas de gerenciamento de projetos separadas, você cria uma dispersão de contexto, uma situação em que informações críticas do projeto estão espalhadas por muitas ferramentas.
O ClickUp resolve isso. Em vez de lidar com várias ferramentas, você tem um espaço de trabalho de IA convergente onde o gerenciamento de projetos, a documentação e a comunicação coexistem — para que seus experimentos permaneçam conectados, desde o planejamento até a execução e a avaliação.
Nunca perca o controle das experiências e do progresso
Ao executar vários experimentos, a parte mais difícil não é treinar o modelo, mas acompanhar o que mudou durante o processo. Qual versão do conjunto de dados foi usada, qual taxa de aprendizagem teve melhor desempenho ou qual execução foi enviada?
O ClickUp torna esse processo super fácil para você. Você pode acompanhar cada execução de treinamento separadamente nas Tarefas do ClickUp e, dentro das tarefas, pode usar Campos Personalizados para registrar:
- Versão do conjunto de dados
- Hiperparâmetros
- Variante do modelo (DBRX Base vs DBRX Instruct)
- Status do treinamento (Em fila, Em execução, Em avaliação, Implantado)
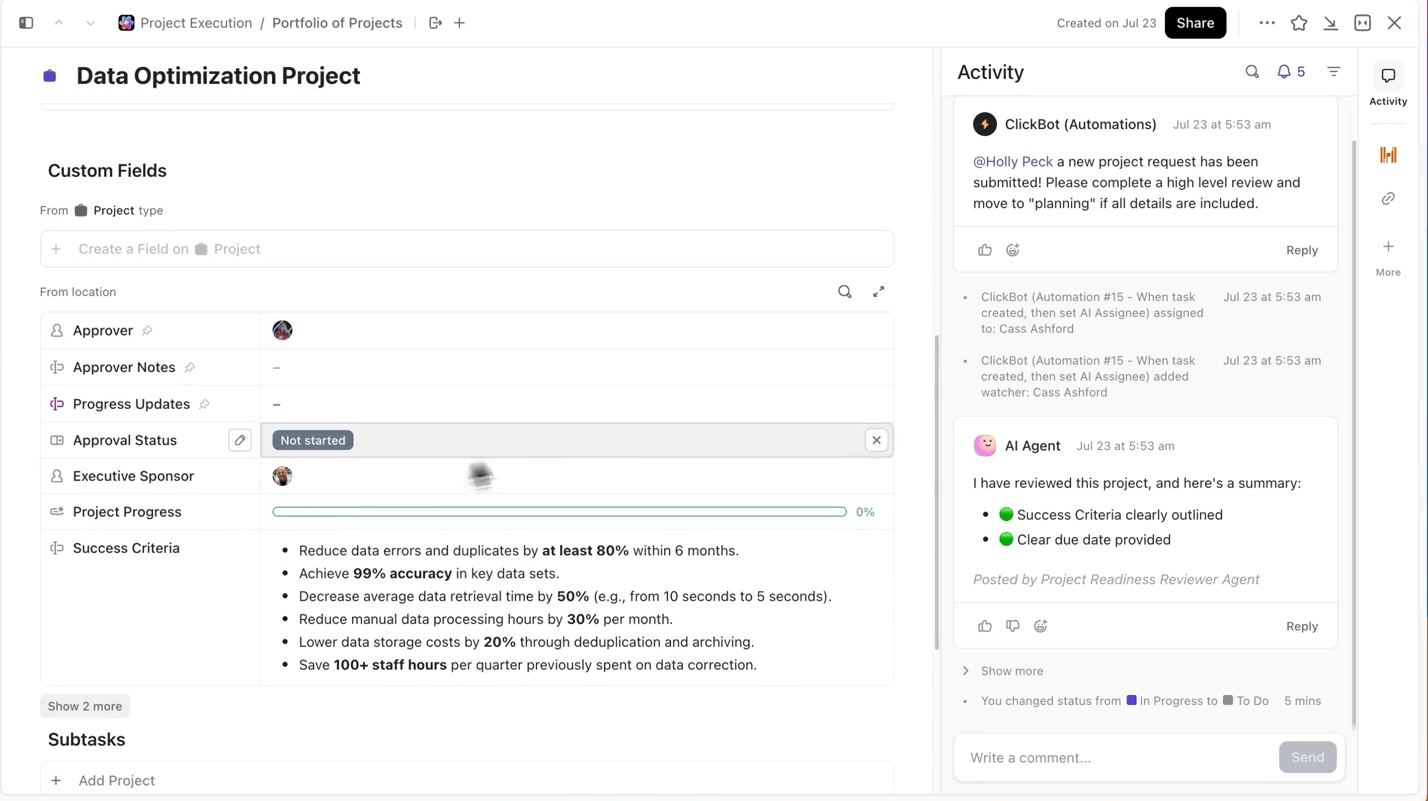
Dessa forma, todos os experimentos documentados podem ser pesquisados, são fáceis de comparar com outros e são reproduzíveis.
Mantenha a documentação do modelo vinculada ao trabalho
Você não precisa alternar entre notebooks Jupyter, arquivos README ou threads do Slack para entender o contexto da tarefa de um experimento.
Com o ClickUp Docs, você pode manter sua arquitetura de modelo, scripts de preparação de dados ou métricas de avaliação organizados e acessíveis, documentando-os em um documento pesquisável que se vincula diretamente às tarefas de experimento das quais eles se originaram.

💡Dica profissional: mantenha um resumo do projeto atualizado no ClickUp Docs que detalhe todas as decisões, desde a arquitetura até a implantação, para que os novos membros da equipe possam sempre se atualizar sobre os detalhes do projeto sem precisar vasculhar tópicos antigos.
Dê visibilidade em tempo real às partes interessadas
Os painéis do ClickUp mostram o progresso da experiência e a carga de trabalho da equipe em tempo real.
Em vez de compilar atualizações manualmente ou enviar e-mails, os painéis são atualizados automaticamente com base nos dados das suas tarefas. Assim, as partes interessadas podem verificar a qualquer momento, ver como estão as coisas e nunca precisam interromper você com perguntas do tipo “qual é o status?”.
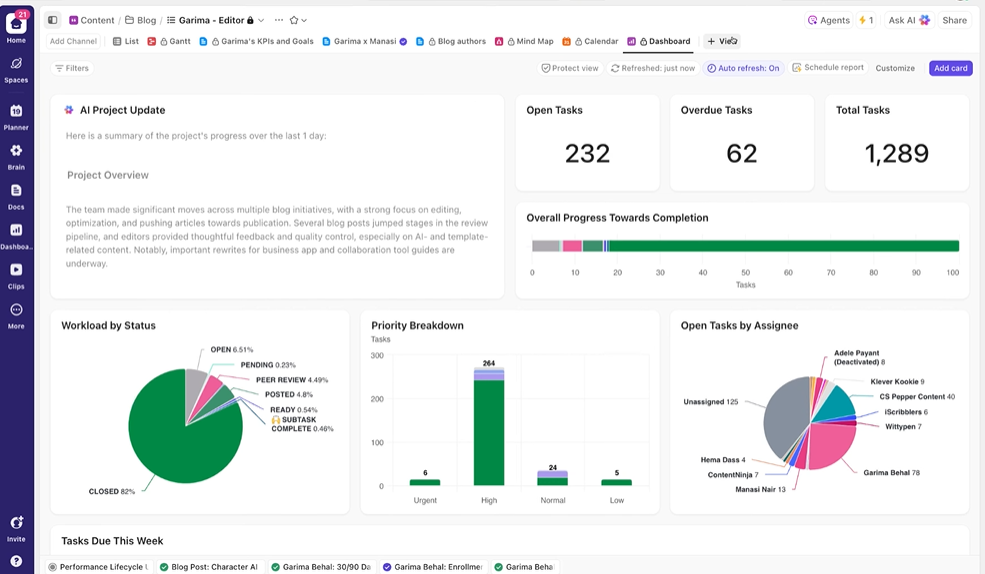
Dessa forma, você se concentra em executar experimentos, em vez de ter que relatar manualmente sobre eles constantemente.
Transforme a IA em sua parceira inteligente de projetos
Você não precisa vasculhar manualmente semanas de dados de treinamento para obter um resumo das experiências realizadas até o momento. Basta mencionar @Brain em qualquer comentário de tarefa, e o ClickUp Brain lhe dará a ajuda necessária com todo o contexto de seus projetos anteriores e em andamento.
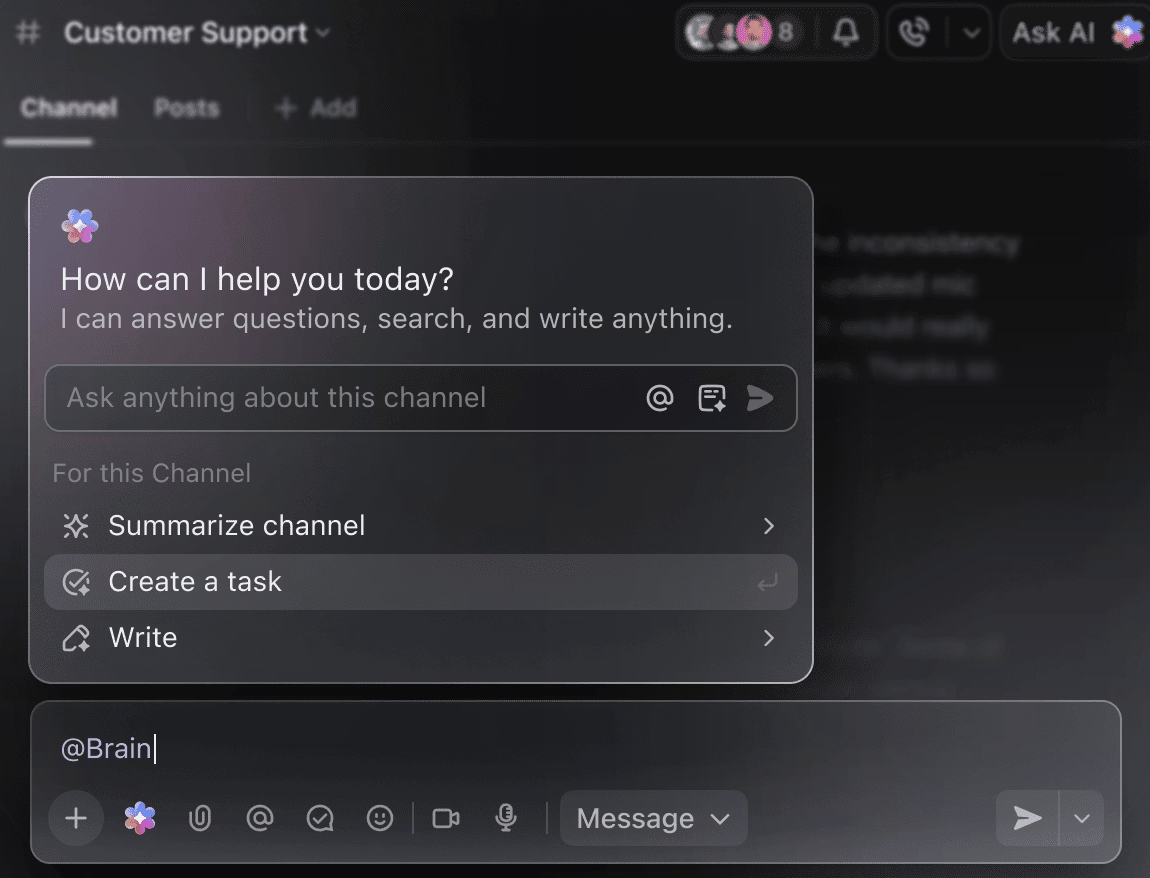
Você pode pedir ao Brain para “Resumir as experiências da semana passada em 5 pontos” ou “Redigir um documento com os resultados mais recentes dos hiperparâmetros” e obter instantaneamente um resultado refinado.
🧠 A vantagem do ClickUp: os Super Agentes do ClickUp vão muito além — eles podem automatizar fluxos de trabalho inteiros com base em gatilhos definidos por você, não apenas responder às suas perguntas. Com os superagentes, você pode criar automaticamente uma nova tarefa de treinamento DBRX sempre que um conjunto de dados for carregado, notificar sua equipe e vincular documentos relevantes quando o treinamento terminar ou atingir um ponto de verificação, além de gerar um resumo semanal do progresso e enviá-lo às partes interessadas sem que você precise fazer nada.
Erros comuns a evitar
Embarcar em um projeto de treinamento DBRX é empolgante, mas algumas armadilhas comuns podem atrapalhar seu progresso. Evitar esses erros economizará tempo, dinheiro e muita frustração.
- Subestimar os requisitos de hardware: o DBRX é poderoso, mas também é grande. Tentar executá-lo em hardware inadequado levará a erros de memória insuficiente e falhas nas tarefas de treinamento. Lembre-se de que o DBRX (132B) requer pelo menos 264 GB de VRAM para inferência de 16 bits, ou aproximadamente 70 GB a 80 GB ao usar quantização de 4 bits.
- Ignorar as verificações de qualidade dos dados: lixo entra, lixo sai. O ajuste fino em um conjunto de dados desorganizado e de baixa qualidade só ensinará o modelo a produzir resultados desorganizados e de baixa qualidade.
- Ignorando os limites de comprimento do contexto: Embora a janela de contexto de 32K do DBRX seja generosa, ela não é infinita. Alimentar o modelo com entradas que excedam esse limite resultará em truncamento silencioso e baixo desempenho.
- Usando o Base quando o Instruct for apropriado: O DBRX Base é um modelo bruto e pré-treinado destinado a treinamentos adicionais em grande escala. Para a maioria das tarefas que seguem instruções, você deve começar com o DBRX Instruct, que já foi ajustado para essa finalidade.
- Separando o trabalho de treinamento da coordenação do projeto: quando o acompanhamento do experimento fica em uma ferramenta e o plano do projeto em outra, você cria silos de informação. Use uma plataforma integrada como o ClickUp para manter seu trabalho técnico e a coordenação do projeto em sincronia.
- Negligenciar a avaliação antes da implantação: um modelo que tem um bom desempenho nos seus dados de treinamento pode falhar espetacularmente no mundo real. Sempre valide seu modelo ajustado em um conjunto de testes retido antes de implantá-lo na produção.
- Ignorando a complexidade do ajuste fino: como o DBRX é um modelo de mistura de especialistas, os scripts de ajuste fino padrão podem exigir bibliotecas especializadas, como Megatron-LM ou PyTorch FSDP, para lidar com o particionamento de parâmetros em várias GPUs.
DBRX x outras plataformas de treinamento de IA
A escolha de uma plataforma de treinamento de IA envolve uma escolha fundamental: controle versus conveniência. Modelos proprietários, apenas com API, são fáceis de usar, mas prendem você ao ecossistema de um fornecedor.
Modelos de pesos abertos como o DBRX oferecem controle total, mas exigem mais conhecimento técnico e infraestrutura. Essa escolha pode deixar você confuso, sem saber qual caminho realmente apoia seus objetivos de longo prazo — um desafio que muitas equipes enfrentam durante a adoção da IA.
Esta tabela detalha as principais diferenças para ajudá-lo a tomar uma decisão informada.
| Ponderações | Abrir (Personalizado) | Proprietário | Abrir (Personalizado) | Proprietário |
| Ajustes finos | Controle total | Baseado em API | Controle total | Baseado em API |
| Auto-hospedagem | Sim | Não | Sim | Não |
| Licença | Modelo aberto DB | Termos da OpenAI | Comunidade Llama | Termos antropológicos |
| Contexto | 32K | 128K – 1M | 128K | 200 mil – 1 milhão |
O DBRX é a escolha certa quando você precisa de controle total sobre o modelo, deve hospedar você mesmo por motivos de segurança ou conformidade ou deseja a flexibilidade de uma licença comercial permissiva. Se você não tem uma infraestrutura de GPU dedicada — ou valoriza mais a velocidade de comercialização do que a personalização profunda — alternativas baseadas em API podem ser mais adequadas.
Comece a treinar de forma mais inteligente com o ClickUp
O DBRX oferece uma base pronta para uso corporativo para a criação de aplicativos de IA personalizados, com a transparência e o controle que você não obtém em modelos proprietários. Sua arquitetura MoE eficiente mantém os custos de inferência baixos, e seu design aberto facilita o ajuste fino. Mas uma tecnologia robusta é apenas metade da equação.
O verdadeiro sucesso vem do alinhamento do seu trabalho técnico com o fluxo de trabalho colaborativo da sua equipe. O treinamento de modelos de IA é um trabalho em equipe, e manter as experiências, a documentação e a comunicação com as partes interessadas em sincronia é fundamental. Ao reunir tudo em um único espaço de trabalho convergente e reduzir a dispersão de contexto, você pode entregar modelos melhores e mais rápidos.
Comece gratuitamente com o ClickUp para coordenar seus projetos de treinamento de IA em um único espaço de trabalho. ✨
Perguntas frequentes
Você pode monitorar o treinamento usando ferramentas padrão de ML, como TensorBoard, Weights & Biases ou MLflow. Se você estiver treinando dentro do ecossistema Databricks, o MLflow é integrado nativamente para um rastreamento contínuo dos experimentos.
Sim, o DBRX pode ser integrado a pipelines MLOps padrão. Ao conteinerizar o modelo, você pode implantá-lo usando plataformas de orquestração como Kubeflow ou fluxos de trabalho CI/CD personalizados.
O DBRX Base é o modelo pré-treinado fundamental destinado a equipes que desejam realizar pré-treinamento contínuo específico para o domínio ou ajuste fino da arquitetura profunda. O DBRX Instruct é uma versão ajustada otimizada para seguir instruções, tornando-o um ponto de partida melhor para a maioria dos desenvolvimentos de aplicativos.
A principal diferença é o controle. O DBRX oferece acesso total aos pesos do modelo para personalização profunda e hospedagem própria, enquanto o GPT-4 é um serviço apenas de API.
Os pesos do modelo DBRX estão disponíveis gratuitamente sob a Licença de Modelo Aberto da Databricks. No entanto, você é responsável pelos custos da infraestrutura de computação necessária para executar ou ajustar o modelo.