
多くのチームは、SQL生成をまるで手品のように扱っています。質問を入力するだけで、クエリが生成されるのです。
しかし、現実にはこうです。Snowflake Cortex Analystの性能は、最初に構築するセマンティックモデルの質に左右され、そのセットアップは決して簡単なものではありません。Snowflake Cortexを用いたSQL生成の方法を習得することで、データチームは自然言語を数秒で複雑かつ実行可能なクエリに変換できるようになります。
このガイドでは、YAMLセマンティックモデルの定義から自然言語を用いたデータウェアハウスへのクエリ実行に至るまで、実際の実装プロセスを順を追って解説します。これにより、開始前にその機能と前提条件の両方を理解することができます。
また、Snowflake Cortexの課題点や、SQL生成を取り巻くより広範なワークフローをClickUpがどのようにサポートできるかについても解説します。
Snowflake Cortex Analyst とは?
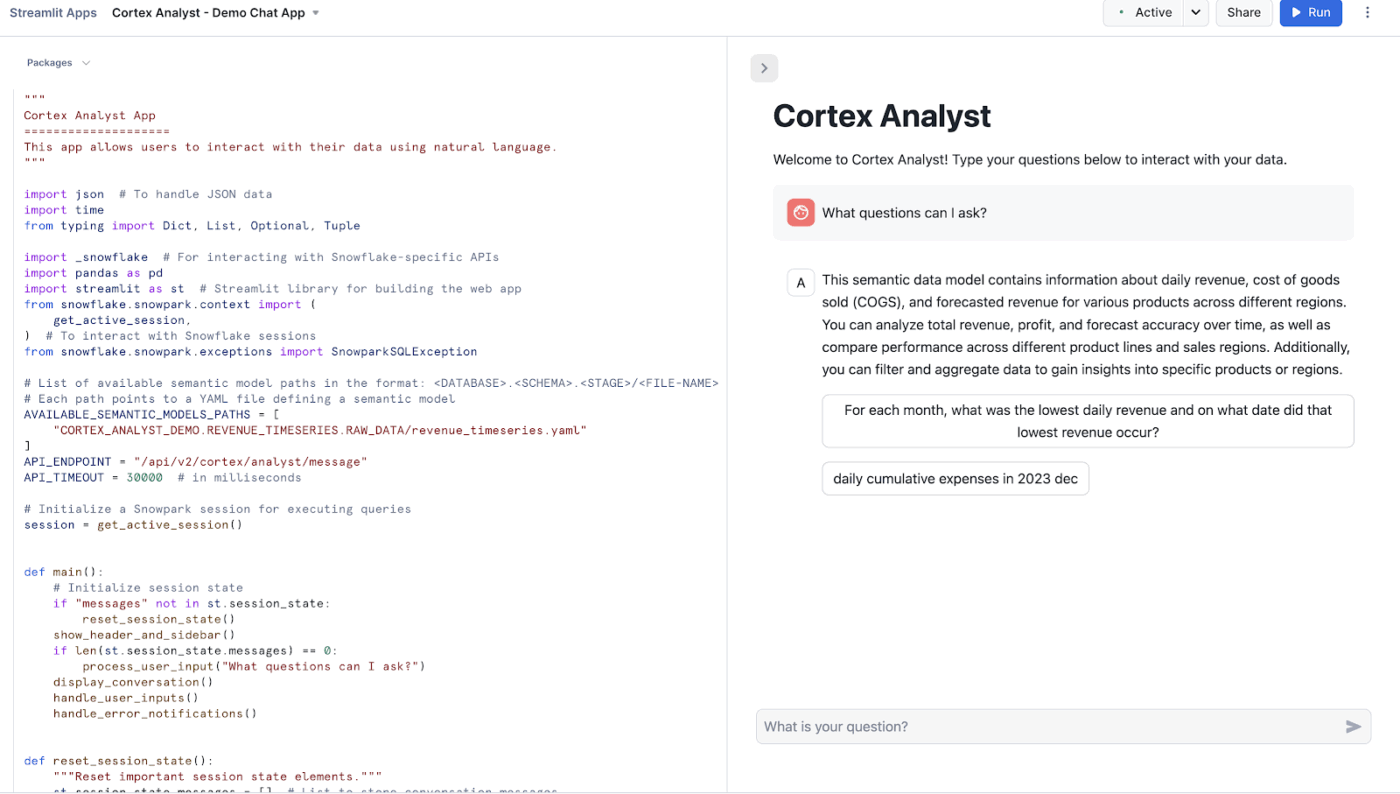
Snowflake Cortex Analystは、分析データ上で会話型アプリケーションを構築できるフルマネージドサービスです。
専用のテキストからSQLへの変換エージェントを使用して、自然言語の質問を正確で実行可能なクエリに変換します。このサービスは、複雑なデータ構造と、コードを書かずに答えを求めるビジネスユーザーとの間のギャップを埋めます。
主な機能は以下の通りです:
- 構造化データとやり取りするための高精度なインターフェースを提供します
- セマンティックモデルを活用して、お客様のビジネスロジックや用語を正確に把握します
- カスタムアプリケーションやBIツールへの容易な統合を実現するREST APIを提供しています
- Snowflakeのセキュリティ境界内でリクエストを処理することで、データのプライバシーを保護します
📮 ClickUpインサイト:アンケートの回答者の88%が個人的なタスクにAIを活用している一方で、50%以上が仕事での利用をためらっています。主な障壁は3つ。シームレスな統合の欠如、知識の不足、そしてセキュリティへの懸念です。
しかし、もしAIがワークスペースに組み込まれていて、すでにセキュリティ対策が施されているとしたらどうでしょうか? ClickUpの組み込みAIアシスタント「ClickUp Brain」なら、それが現実になります。このアシスタントは平易な言葉でのプロンプトを理解し、AI導入に関する3つの懸念事項をすべて解決すると同時に、ワークスペース全体のチャット、タスク、ドキュメント、ナレッジを接続します。
ワンクリックで答えや洞察を見つけましょう!
Snowflake Cortex SQL生成の前提条件
適切なセットアップを行わずにSnowflake Cortexを使い始めると、挫折感を抱くことになります。不正確な結果が得られたり、トラブルシューティングに時間を浪費したり、本来は基礎が不十分であるという問題なのに、誤ってツールが故障していると結論付けてしまう可能性があります。
これを回避するには、まず3つの基本要素を整える必要があります。
1. データベースとテーブルを設定する
AIの賢さは、アクセスできるデータの質に左右されます。データベースのスキーマが「cust_dat_v2_final」のような難解な列名の迷路になっていると、アナリストもAIもその意味を理解するのに苦労することになります。
このような混乱により、AIが誤った結合を生成したり、間違った列からデータを抽出したりすることになり、チームはクエリを書く前にスキーマを解読するだけで何時間も無駄にしてしまいます。
まず、 データウェアハウスソフトウェアに、Cortex Analystがクエリを実行する対象となるテーブルが含まれていることを確認してください。可能な限り、明確で説明的な列名を使用してください。たとえば、「customer_lifetime_value」という列名は、「clv_01」という名前よりも、人間にとってもAIにとってもはるかに直感的に理解しやすいものです。
セットアップを進めるには、Snowflakeの役割に以下の許可が必要です:
- 使用方法: テーブルが含まれるデータベースおよびスキーマ上で
- SELECT: Cortex Analystにクエリを実行させたいテーブル
- CREATE FEEZE: セマンティックモデルファイルをアップロードするために必要なスキーマ上で
📖 こちらもご覧ください:Snowflake Cortex を活用したビジネスインテリジェンスの実践方法
2. セマンティックモデルファイルを作成する
テキストからSQLへの変換ツールにおける最大の課題は、AIが貴社独自の用語を理解していないことです。AIは、「ARR」が「Annual Recurring Revenue(年間経常収益)」を意味することや、顧客テーブルがcustomer_idフィールドで注文テーブルと結合されることを、本来は認識していません。
この文脈がなければ、AIは技術的には有効だが論理的に誤ったSQLを生成し、一見正しいように見えても、実際には危険なほど誤解を招くような回答を返す可能性があります。
その解決策となるのがセマンティックモデルです。これは、カスタム「変換レイヤー」として機能するYAMLファイルであり、Cortex Analystにビジネスの固有の用語やロジックを教えます。このファイルの作成と保守は、 ETLツールを使用してスキーマを把握するデータエンジニアと、専門用語に精通したビジネスアナリストとの共同努力によって行われます。
セマンティックモデルファイルには、以下の主要な構成要素を含める必要があります:
| コンポーネント | 目的 |
| テーブル | 各テーブルの目的を平易な言葉で説明したリスト |
| 列 | 各列の意味的タイプ(カテゴリやメトリクスなど)を定義し、サンプル値を含めることができます |
| リレーションシップ | テーブル間の結合方法を指定することで、AIによる推測作業を不要にします |
| 検証済みクエリ | LLMの強力なガイドとなる、質問とSQLの例を提供します |
3. Cortex Search Service の設定(オプション)
必要な答えは、製品説明、サポートチケット、通話記録などの非構造化テキストの中に隠されていることがあります。標準的なSQLクエリではこうしたデータにアクセスできないため、「何が」という事実の背後にある「なぜ」を見逃してしまうことがよくあります。
必要に応じて、ここにSnowflake Cortex Search Serviceを追加することもできます。これは、 AIエージェントによるデータ分析を活用し、構造化テーブルと非構造化テキストデータの両方に同時にクエリを実行できる「 検索サービス(Search-as-a-Service)」レイヤーです。
アナリストがSQLを生成する前にテキストから文脈を抽出する必要がある質問を行う場合は、Cortex Searchを設定する必要があります。例として、まず「バッテリーの問題」というフレーズを含むすべての製品レビューを検索し、その後、それらの製品のみの販売データを集計するSQLクエリを生成することができます。
構造化されたテーブルに対する純粋なSQL生成については、このサービスは必要ありません。
🧠 豆知識:1970年代初頭、IBMの研究者ドナルド・チェンバーリンとレイモンド・ボイスは「Structured English Query Language(構造化英語クエリ言語)」を開発しました。しかし、「SEQUEL」という名称はすでに英国の航空機メーカーによって商標登録されていたため、SQLという名前に変更せざるを得ませんでした。
Cortex Analyst を使用した SQL 生成のステップガイド
準備は完了したものの、実際のワークフローが分からず、画面を前にして途方に暮れていませんか?頭の中の疑問を、実行可能なSQLクエリに変換するにはどうすればよいのでしょうか?ワークフローの管理方法が明確でない場合、新しいツールは活用されず、セットアップへの投資が無駄になってしまうことがよくあります。
その実践的なプロセスは驚くほどシンプルです。詳しく見ていきましょう!
ステップ 1: Snowflakeでデータを準備する
まず最初に、構造化データをSnowflake内に格納しておく必要があります。各Cortex Analystアプリケーションは、単一のテーブル、または1つ以上のテーブルで構成されるビューを指定します。 テーブルが作成され、データが格納されていることを確認してください。
フラットファイルからデータを読み込む場合は:
- データファイル(CSVなど)をSnowflakeフェーズにアップロードします
- COPY INTO コマンドを使用して、フェーズからテーブルにデータをロードします
- 次の手順に進む前に、データの読み込みが成功したことを確認してください
ステップ 2: セマンティックモデル(またはセマンティックビュー)を構築する
これは最も重要なセットアップステップです。Cortex Analystの真価は、大規模言語モデル(LLM)とセマンティックモデルを組み合わせた点にあります。セマンティックモデルとは、データベーススキーマと並行して配置され、ビジネスコンテキストをエンコードするYAMLファイルのことです。
Semantic Viewsは、現在SnowflakeがCortex Analyst向けに推奨する手法です。これらはビジネスメトリクス、関係、定義をSnowflake内に直接保存します。レガシーYAML形式のセマンティックモデルファイルも引き続き使用可能ですが、Snowflakeは新しい実装においてSemantic Viewsの利用を推奨しています。
セマンティックモデルまたはビューには、以下の要素を含める必要があります:
- テーブルおよび列の説明: 各フィールドの意味を平易な言葉で解説
- ビジネスメトリクス: 売上高、解約率、コンバージョン率などの計算フィールドの定義
- フィルターとシノニム: ユーザーが使用する可能性のある別の用語(例:特定のステータス値にマッピングされた「キャンセル済み」など)
- 検証済みクエリ: Snowflakeの「検証済みクエリリポジトリ」には、承認済みの質問とSQLのペアが保存されています。ユーザーの質問がこれらのエントリーのいずれかに類似している場合、Cortex AnalystはSQL生成時にそれを参照することができます。
🤝 リマインダー:Snowflakeでは、Snowsightワークフローで最適なパフォーマンスを得るために、テーブルは10個以下、選択する列は50個以下にすることを推奨しています。
ステップ 3: セマンティックモデルを Snowflake フェーズにアップロードする
YAMLベースのセマンティックモデルを使用している場合は、Cortex Analystが実行時にそれを参照できるよう、フェーズする必要があります。
- .yamlファイルをSnowflakeの内部フェーズ(例:RAW_DATA)にアップロードします。
- Snowsight UI または `LIST @stage_name` コマンドを使用して、ファイルがフェーズに表示されていることを確認してください。
- ステージのパスに注意してください。API呼び出しやアプリの設定でこれを参照することになります。
セマンティックビューを使用している場合、このステップはSnowflake内でネイティブに処理されるため、別途アップロードを行う必要はありません。
🔍 ご存知でしたか?SQLにおけるNULLは、ゼロや空を意味するものではありません。これは未知または欠落したデータを表しており、比較演算で真でも偽でもない結果が返されるなど、直感に反する動作を引き起こす原因となります。
ステップ 4: REST API 経由で自然言語の質問を送信する
ここから実際のSQL生成が始まります。REST APIは、リクエストで指定されたセマンティックモデルまたはセマンティックビューを使用して、与えられた質問に対するSQLクエリを生成します。
APIリクエストを次のように構成してください:
- メッセージ;「ユーザー」という役割を持つユーザーの質問を含む配列
- セマンティックモデルまたはセマンティックビューへの参照
- お好みのモデルを選択してください(または「自動」のままにすると、Cortexが最適なモデルを選択します)
以前のクエリに基づいて追問を行う、複数回の会話が可能な会話が可能です。
ステップ 5: API レスポンスを解析する
レスポンス内の各メッセージには、異なるタイプのコンテンツブロックが複数含まれる場合があります。現在、typeフィールドでサポートされている値は、テキスト、suggestions、SQLの3つです。
各タイプの意味は以下の通りです:
🔍 ご存知でしたか?SQLの記述順序と実行順序は一致しません。SELECTを最初に記述しても、データベースは実際にはFROMやWHEREを先に処理してから、列を選択します。この点は、初心者だけでなく経験豊富なユーザーにとっても混乱を招く原因となっています。
ステップ 6: Snowflakeで生成されたSQLを実行する
レスポンスからSQLブロックを取得したら、Snowflakeの仮想ウェアハウスで実行してください。生成されたSQLクエリはSnowflakeの仮想ウェアハウスで実行され、最終的な出力が生成されます。データはSnowflakeのガバナンス境界内に留まります。
実行時に知っておくべき重要なポイント:
- Cortex AnalystはSnowflakeの役割ベースのアクセス制御(RBAC)ポリシーと完全に統合されており、生成および実行されるSQLクエリが、確立されたすべてのアクセス制御に準拠することを保証します。
- ユーザーがテーブルへのアクセス権限を持っていない場合、手書きのSQLと同様に、クエリの実行は失敗します。
- このフェーズでは、Cortex Analyst の利用料金とは別に、ウェアハウスのコンピューティング費用が発生します。
ステップ 7: 改良と反復
最初から完璧なクエリが得られるとは限りません。以下に、時間をかけて結果を改善する方法をご紹介します:
- 繰り返し発生する質問に対しては、検証済みのクエリをセマンティックモデルに追加してください
- Cortexが用語を誤って解釈した場合、より適切な説明、同義語、フィルターを追加して、セマンティックモデルを充実させましょう
- マルチターン会話を活用して、例えば「では、それを地域で絞り込んで」といったように、前のクエリに基づいた追問を行うことができます。
- 利用状況を監視し、CORTEX_ANALYST_USAGE_HISTORY および Snowflake のクエリ履歴を活用して、失敗したクエリや不正確なクエリのパターンを特定します
🧠 豆知識:たった1つのJOIN条件の抜けが、甚大な問題を引き起こす可能性があります。JOIN条件を忘れると、デカルト積が発生し、行数が飛躍的に増加し、場合によってはシステムがクラッシュすることもあります。
SnowflakeのテキストからSQLへの変換精度に関するベストプラクティス
セマンティックモデルの品質は、生成されるクエリの精度に直結します。精度を向上させるためのベストプラクティスを紹介します。🛠️
- 検証済みのクエリをセマンティックモデルに追加する: これが最も効果的な対策です。チームが実際に質問する方法を反映した、質問とSQLのペアの例を数多く含めてください。
- わかりやすい列名とテーブル名を使用する: 列名やテーブル名が直感的に理解できるものであるほど、モデルのパフォーマンスは向上します。スキーマを変更できない場合は、意味がわかりにくい列名について、YAML ファイルに明確な説明を追加してください。
- サンプル値を含める: カテゴリ型列(ステータスや地域など)に例データを追加することで、モデルが利用可能な有効なフィルタオプションを理解しやすくなります
- エッジケースでのテスト: 開発中は、意図的に曖昧な質問や難解な質問を投げかけ、セマンティックモデルにさらなる文脈や明確化が必要な箇所を特定しましょう。
- セマンティックモデルを反復的に改善する: セマンティックモデルを「生き物」のようなドキュメントとして扱ってください。どのクエリが成功し、どのクエリが失敗するかという結果に基づいて、 反復的なプロセスを通じて継続的に更新していく必要があります。
ClickUp:Snowflake Cortexに代わる、よりシンプルなソリューション
Snowflake Cortexは、チームがSQLを生成し、構造化データに対してクエリを実行したい場合に有効です。チームはスキーマを定義し、リレーションシップをマッピングし、クエリを作成してインサイトを抽出します。このセットアップは、特にアナリストがレポート作成を担当しているような、データ量の多い環境において有効です。
しかし、多くのチームにとって、日常的な運用上の疑問に答えるために完全なSQLレイヤーは必要ありません。プロダクトマネージャー、プログラムリーダー、運用チームは、進行中の仕事に関連した迅速な回答を求めていることがよくあります。
ClickUpなら、より手軽に利用できます。チームは平易な言葉で質問し、リアルタイムのダッシュボードを確認し、SQLを記述したりセマンティックモデルを構築したりすることなく、インサイトに基づいてアクションを起こすことができます。
SQLの生成と最適化を迅速に行う
Snowflake Cortexは、ウェアハウス環境内の構造化データセットからSQLクエリを生成することに重点を置いています。これは、データがすでにSnowflake内に存在し、スキーマが定義されている場合に特に有効です。

ClickUp Brainは、より柔軟で実行重視の方法でSQL生成をサポートします。チームは、分析、議論、意思決定がすでに実施されているワークスペース内で、SQLクエリを直接生成、調整、保存することができます。
あるプロダクトアナリストが、ClickUp内で顧客維持率の分析タスクに取り組んでいるとします。クエリを書くためにツールを切り替える代わりに、そのアナリストはClickUp Brainに次のように尋ねます:
📌 次のプロンプトを試してみてください:サインアップコホートごとにグループ化されたユーザーの7日間リテンション率を計算するSQLクエリを作成してください。
ClickUp Brainは、コホートグループ化、日付フィルター、リテンションロジックを含む構造化されたクエリを生成します。アナリストは、そのクエリをSnowflakeやその他のデータウェアハウスに貼り付け、すぐに実行できます。
これにより、以下のことが可能になります:
- ユーザー、注文、イベントなど、複数のテーブルにわたる結合クエリを作成します
- 平易な英語での製品に関する質問を、実行可能なSQLロジックに変換します
- 正常に動作しないクエリをデバッグし、不適切な結合や条件の欠落などの問題を分析します
- パフォーマンスや可読性を向上させるためにクエリを書き換える
例えば、成長実験のレビュー中に、マーケティング担当者が「過去14日間の2つのランディングページのコンバージョン率を比較するSQLクエリを作成してください」と依頼したとします。
ClickUp Brainは、条件付き集計と日付フィルターを使用してクエリを生成します。チームはこれをSnowflakeで実行し、実験の結果を検証します。
📌 次のプロンプトを試してみてください:結合によって行が重複しているこのSQLクエリを修正し、問題の原因を説明してください。
ClickUp Brainは結合の問題を特定し、クエリを修正するとともに、結合条件の誤りによって重複行が発生した原因を説明します。
SQLベースのレポート作成を置き換える
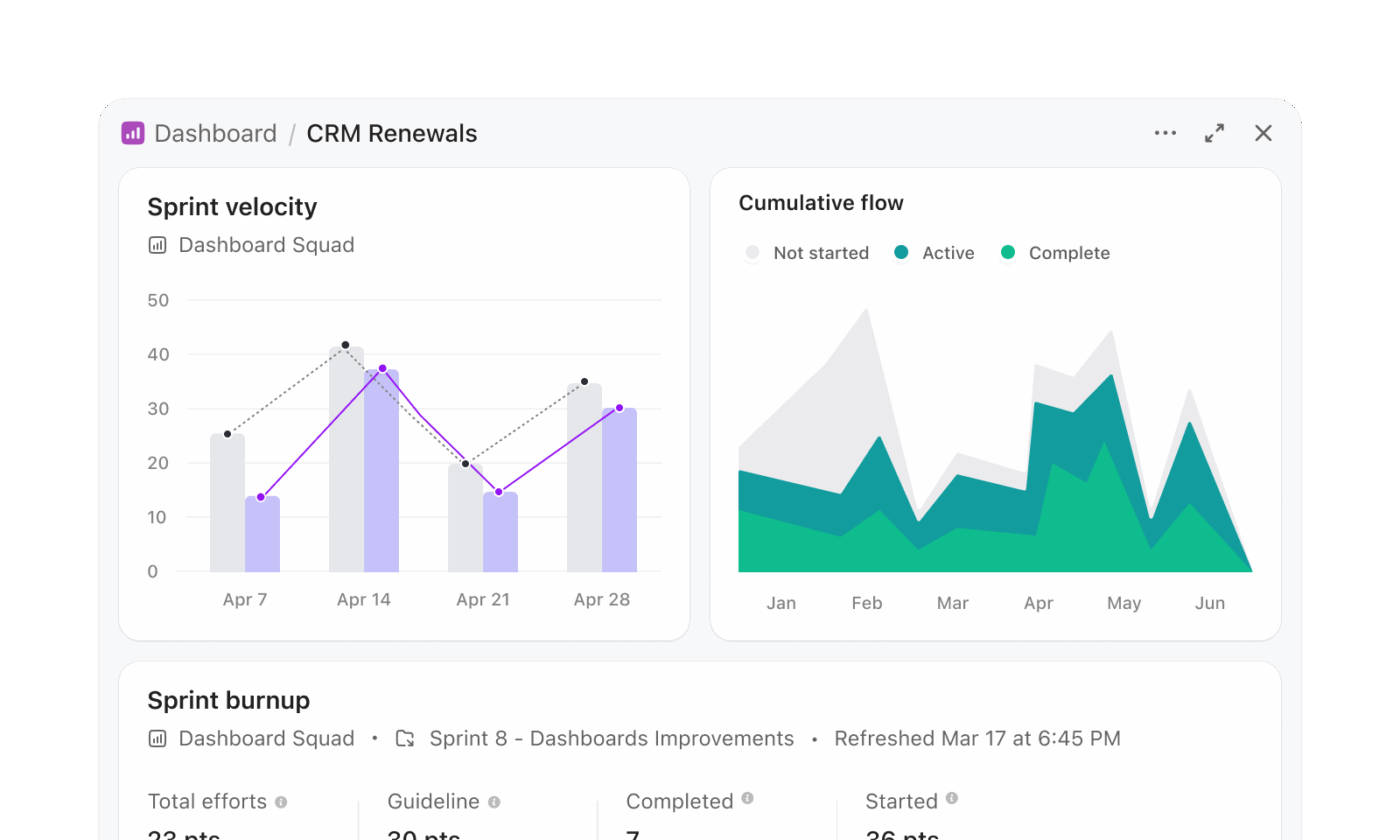
Snowflake Cortexのワークフローでは、多くの場合、SQLの生成、クエリの実行、結果の可視化が別々のレイヤーで行われます。ClickUpダッシュボードを使用すれば、その多段階のプロセスを省略し、実際の仕事から直接インサイトを提示できます。
リリースの準備状況を追跡するプログラム管理チームは、クエリを記述することなくダッシュボードを構築できます。たとえば、リリースダッシュボードには次のような内容が含まれる場合があります:
- すべてのプロダクトチームにわたる期限切れタスクを表示するようにフィルタリングされたタスクリストカード
- エンジニア間のタスク配布を示す作業負荷カード
- スプリントごとの完了タスクと保留中のタスクを比較した棒グラフ
- 平均完了時間を追跡する計算カード
リリースミーティングの前に、プログラムリーダーがこのダッシュボードを確認したとします。すると、バックエンドサービスの遅延率が高くなっていることがすぐにわかります。そこで、タスクリストのカードを開き、リスクの原因となっている具体的なタスクを確認します。
ClickUpの実際のユーザーによる共有:
ClickUpを使えば、プロジェクトを互いに素早く引き継ぐことができ、プロジェクトのステータスを簡単に確認できます。また、上司は私たちの作業量をいつでも把握できるため、作業を中断させる必要がありません。ClickUpのおかげで、少なくとも週に1日、場合によってはそれ以上の時間を節約できています。電子メールのやり取りも大幅に減りました。
ClickUpを使えば、プロジェクトを互いに素早く引き継ぐことができ、プロジェクトのステータスを簡単に確認できます。また、上司は私たちの作業負荷をいつでも把握できるため、作業を中断させる必要がありません。ClickUpの導入により、少なくとも週に1日、場合によってはそれ以上の時間を確実に節約できています。電子メールのやり取りも大幅に減りました。
パイプラインなしでインサイトを活用する
Snowflake Cortexは、データからインサイトを生成することに重点を置いています。Teamsは依然として、結果を解釈し、トリガーを実行する作業を別途行う必要があります。
ClickUp AI Super Agentsはそのギャップを埋め、インサイトを実行に移します。これらはAIチームメイトとして機能し、ワークスペースのデータを継続的に監視し、条件に基づいてアクションを実行します。
あるプログラムマネージャーが複数の製品イニシアチブを統括しているとします。スーパーエージェントには次のような機能があります:
- プロジェクト横断でタスクを監視し、期限切れのタスクが定義された閾値を超えた場合に検知します
- 同じワークフローのフェーズで繰り返し発生する遅延などのパターンを特定します
- 影響を受けるプロジェクトを要約するタスクを作成し、プログラムリーダーに割り当てます
- 期限を過ぎても未解決の重要なタスクがある場合、チーム所有者に通知する
例えば、リリースサイクル中に、スーパーエージェントが2つのチームで10件以上の高優先度タスクが期限を過ぎていることを検知しました。スーパーエージェントは「リリースリスク:期限超過」というタイトルのClickUpタスクを作成し、関連するすべてのタスクを添付した上で、プログラムマネージャーに割り当て、直ちに確認してもらいます。
チームはスーパーエージェントと直接対話することも可能です: 「すべての進行中のプロジェクトを分析し、このsprintの納期リスクを特定してください」。
スーパーエージェントは、期限、依存関係、タスクのステータスを確認し、ワークスペース内に構造化された要約を投稿します。
ClickUpで独自のスーパーエージェントを設定する方法は以下の通りです:
ClickUpでデータワークフローを一元管理
Snowflake CortexのようなテキストからSQLへの変換ツールは、データへのアクセスを容易にします。しかし、信頼性の高い結果を得るには、依然として努力が必要です。
チームは、正確な出力を維持するために、クリーンなスキーマ、強力なセマンティックモデル、そして継続的な反復作業を必要としています。適切なクエリを生成した後も、仕事はそこで終わりではありません。誰かが結果を解釈し、洞察を共有し、それを意思決定へとつなげる必要があります。
ClickUpは、これとは異なるアプローチを採用しています。分析と実行を分離するのではなく、ClickUpは両者を接続します。チームは、同じワークスペース内でSQLを生成し、インサイトを記録し、発見事項について共同作業を行い、それに基づいてアクションを起こすことができます。
ClickUp Brainはクエリの作成と改良を支援し、ダッシュボードとAIエージェントは、チームがツールを切り替えることなく成果を追跡し、仕事を進展させるのに役立ちます。
Snowflake Cortexは答えを見つけるお手伝いをします。ClickUpはその答えを活用するお手伝いをします。今すぐClickUpに登録しましょう!
よくある質問
Snowflake Cortex Analystは、Snowflake Cortex AIスイート全体の中で特化したサービスです。Cortex Analystは、セマンティックモデルを用いたテキストからSQLへの生成に特化しているのに対し、Cortex AIには、より広い範囲のLLM機能、機械学習モデルの推論、および検索機能が含まれています。
はい、Cortex Analyst では、Snowflake を通じて管理されている Apache Iceberg テーブルに対してクエリを実行できます。Snowflake 環境内でテーブルにアクセス可能であり、セマンティックモデルに適切に定義されていれば、それらのテーブルに対してクエリを生成できます。
複雑なクエリの精度は、ほぼ完全にセマンティックモデルの品質に依存します。テーブル間の関係が明確に定義され、多数の検証済みクエリと説明的なメタデータを含むモデルであれば、複数テーブルの結合や複雑な集計において、はるかに正確な結果が得られます。
Snowflake Cortex Analystの料金体系は、Snowflakeの利用量ベースのモデルに従っています。つまり、クエリ生成プロセスで使用されたコンピュートクレジットに基づいて課金されます。最新の料金については、常にSnowflakeの公式価格ドキュメントをご確認ください。