

Immagina un database relazionale come un archivio ben organizzato, in cui ogni cassetto e cartella è etichettato e ordinato per facilitarne l'accesso. Senza di esso, trovare il documento giusto può diventare un incubo.
Un solido sistema di gestione di database relazionali [RDBMS] è fondamentale per qualsiasi applicazione con esito positivo. Organizzando e gestendo i dati in modo efficiente, i database relazionali rendono la gestione dei dati intuitiva e potente.
Database relazionali ben progettati:
- Adattati agli obiettivi aziendali senza interruzioni del sistema
- Consenti un facile recupero dei dati
- Non avere ridondanza dei dati
- Acquisizione di tutti i dati necessari
Ma cosa rende "relazionale" un sistema di gestione di database relazionali e perché è così essenziale? Questo post del blog esplorerà i concetti alla base di un sistema di database relazionale e ti fornirà gli strumenti necessari per crearne uno.
Comprendere i database relazionali
Un database relazionale memorizza i dati in un formato strutturato utilizzando righe e colonne. È simile a un database Excel ben organizzato, in cui i dati sono organizzati in tabelle. Ogni tabella rappresenta un tipo diverso di dati e le relazioni tra le tabelle sono stabilite tramite identificatori univoci noti come chiavi.
Ciò ti consentirà di recuperare e manipolare le informazioni in modo efficiente nello stesso database o in più database.
In passato, erano principalmente gli sviluppatori a utilizzare i database. Estraevano le informazioni dai database con SQL o Structured Query Language, un linguaggio di programmazione. Infatti, un RDMBS è anche chiamato database SQL.
Un database non relazionale, al contrario, o un database NoSQL, memorizza i dati, ma senza le tabelle, le righe o le chiavi che caratterizzano un database relazionale. I database non relazionali ottimizzano invece lo spazio di archiviazione in base al tipo di dati memorizzati.
Componenti di un database relazionale
Comprendere i componenti fondamentali di un database relazionale è necessario per gestire e utilizzare i dati in modo efficace. Insieme, questi componenti strutturano, archiviano e collegano i dati per garantire accuratezza ed efficienza.
1. Tabella
Immagina le tabelle come la base dei tuoi dati, dove ogni tabella contiene informazioni su un'entità specifica. Ad esempio, potresti avere una tabella Progetti con colonne per ID progetto, nome, data di inizio e stato. Ogni riga di questa tabella rappresenta un progetto diverso, organizzato in modo ordinato per un facile accesso.
— Crea la tabella del progetto
CREATE TABLE Progetti (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
StartDate DATE,
Stato VARCHAR(50)
);
2. Chiave primaria
Le chiavi primarie sono identificatori univoci o badge per ogni record che non possono essere lasciati vuoti. Garantiscono che una query possa identificare distintamente ogni riga di una tabella e una tabella può avere solo una chiave primaria. Ad esempio, in una tabella Attività, l'ID attività potrebbe essere la chiave primaria, distinguendo ogni attività dalle altre.
— Crea la tabella delle attività
CREATE TABLE Attività (
TaskID INT PRIMARY KEY,
TaskName VARCHAR(100),
Data di scadenza DATA
);
3. Chiave esterna
Una chiave esterna è come una connessione logica che collega una tabella a un'altra. È un campo in una tabella che crea un collegamento a un'altra tabella facendo riferimento a una chiave primaria in quella tabella. Ad esempio, supponiamo che tu voglia identificare i commenti associati a un'attività. Quindi, in una tabella Commenti, l'ID attività diventa una chiave esterna che rimanda all'ID attività nella tabella Attività [sopra], mostrando a quale attività è correlato ogni commento.
— Crea la tabella dei commenti
CREATE TABELLA Commenti (
CommentID INT PRIMARY KEY,
TaskID INT,
CommentText Testo,
FOREIGN KEY (TaskID) REFERENCES Attività(TaskID)
);
4. Indici
Gli indici migliorano le prestazioni delle query consentendo un accesso rapido alle righe in base ai valori delle colonne. Ad esempio, la creazione di un indice sulla colonna StartDate nella tabella Projects velocizza le query che filtrano in base alle date di inizio dei progetti.
— Crea un indice sulla colonna StartDate
CREATE INDEX idx_startdate ON Progetti(StartDate);
5. Viste
Le viste sono tabelle virtuali create interrogando i dati di una o più tabelle. Semplificano le query complesse presentando i dati in un formato più accessibile. Ad esempio, una vista potrebbe mostrare un riepilogo dello stato dei progetti e delle attività associate.
— Crea una vista per riassumere le attività del progetto
CREATE VIEW ProjectTaskSummary AS
SELECT p. ProjectName, t. TaskName
DA Progetti p
JOIN attività t ON p. ProjectID = t. ProjectID;
Diversi tipi di relazioni nei database relazionali
Stabilire come le diverse tabelle interagiscono nei database relazionali è fondamentale per mantenere l'integrità dei dati e ottimizzare le query. Queste interazioni sono definite attraverso varie relazioni, ciascuna delle quali ha uno scopo specifico per organizzare e collegare i dati in modo efficace.
Comprendere queste relazioni aiuta a progettare uno schema di database robusto che rifletta accuratamente le connessioni reali tra diverse entità.
1. Relazione uno a uno
Immagina uno scenario in cui ogni dipendente [uno] abbia esattamente un badge identificativo [uno]. Quindi, nei record della tabella Dipendenti, ogni record corrisponderà a un singolo record nella tabella Badge identificativi dipendenti. Si tratta di una relazione uno a uno tra le tabelle, in cui una voce corrisponde esattamente all'altra.
Ecco un codice di campione per illustrare una relazione uno a uno:
— Crea la tabella dei dipendenti
CREATE TABLE Dipendenti (
EmployeeID INT PRIMARY KEY,
Nome VARCHAR(100)
);
— Crea la tabella IDBadges
CREATE TABLE IDBadges (
BadgeID INT PRIMARY KEY,
EmployeeID INT UNIQUE,
FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID)
);
EmployeeID nella tabella IDBadges corrisponde in modo univoco [UNIQUE è un comando SQL che non consente dati duplicati o voci ripetitive nei record sotto l'attributo] a una voce nel campo EmployeeID nella tabella Employees.
2. Relazione uno-a-molti
Pensa al project manager [uno] di una grande organizzazione che supervisiona più progetti [molti].
In questo caso, la tabella Project Managers ha una relazione uno-a-molti con la tabella Projects. Il Project Manager gestisce molti progetti, ma ogni progetto appartiene a un solo Project Manager.
— Crea la tabella del project manager
CREATE TABLE ProjectManagers (
ManagerID INT PRIMARY KEY,
ManagerName VARCHAR(100)
);
— Crea la tabella del progetto
CREATE TABLE Progetti (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
ManagerID INT,
FOREIGN KEY (ManagerID) REFERENCES ProjectManagers(ManagerID)
);
Il campo ManagerID è il riferimento che collega entrambe le tabelle. Tuttavia, non è univoco nella seconda tabella, il che significa che possono esserci più record di un singolo ManagerID nella tabella, oppure un manager può avere numerosi progetti.
3. Relazione molti-a-molti
Immagina uno scenario in cui più dipendenti [molti] stanno lavorando a vari progetti [molti].
Per il monitoraggio di questo, useresti una tabella di giunzione, come Employee_Project_Assignments, che collega i dipendenti ai progetti su cui stanno lavorando. Questa tabella avrà chiavi esterne che collegano la tabella Employees e la tabella Projects.
— Crea la tabella dei dipendenti
CREATE TABLE Dipendenti (
EmployeeID INT PRIMARY KEY,
NomeImpiegato VARCHAR(100)
);
— Crea la tabella del progetto
CREATE TABLE Progetti (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100)
);
— Crea la tabella delle assegnazioni dei progetti dei dipendenti
CREATE TABLE Employee_Project_Assignments (
EmployeeID INT,
ProjectID INT,
PRIMARY KEY (EmployeeID, ProjectID),
FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID),
FOREIGN KEY (ProjectID) REFERENCES Progetti(ProjectID)
);
In questo caso, Employee_Project_Assignments è la tabella di giunzione che collega i dipendenti e i progetti.
Vantaggi dei database relazionali
I database relazionali hanno cambiato l'approccio alla gestione dei dati. I loro vantaggi li rendono una soluzione ideale per chiunque lavori con grandi set di dati interconnessi.
1. Coerenza
Immagina di cercare di dare un senso a un set di dati scollegato in cui le tabelle e i campi non seguono le regole di nomenclatura e sono sparsi ovunque: confuso, vero?
I database relazionali eccellono perché puntano sulla coerenza. Applicano regole di integrità dei dati che organizzano le informazioni per garantire che tutto sia accurato e affidabile.
Ad esempio, se stai creando un database clienti, i database relazionali assicurano che i dettagli di contatto dei clienti siano correttamente collegati ai loro ordini, evitando discrepanze o errori.
— Crea la tabella dei clienti
CREATE TABLE clienti (
customer_id INT PRIMARY KEY,
nome VARCHAR(100),
email VARCHAR(100)
);
— Crea la tabella degli ordini con un vincolo di chiave esterna
CREATE TABLE ordini (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATA,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
Questo codice impedisce che gli ordini vengano collegati a clienti inesistenti, garantendo la coerenza dei dati. Pertanto, utilizzando il modello relazionale, lavorerai sempre con dati affidabili, rendendo le tue analisi e la tua reportistica semplici e intuitive!
2. Normalizzazione
Gestire più server e fogli di calcolo e occuparsi delle informazioni duplicate sui clienti è faticoso. I database relazionali rappresentano una svolta in questo senso.
La normalizzazione organizza le strutture dei dati in tabelle ordinatamente correlate che riducono la ridondanza e ottimizzano la modalità di archiviazione dei dati utilizzando il modello relazionale.
Immagina un sistema CRM [Customer Relationship Management]. La normalizzazione ti aiuta a separare i dettagli dei clienti dalle loro interazioni e acquisti. Se un cliente aggiorna le proprie informazioni di contatto, è sufficiente aggiornare tali informazioni una sola volta.
Ecco come puoi configurarlo:
— Crea una tabella dei clienti
CREATE TABLE clienti (
customer_id INT PRIMARY KEY,
nome VARCHAR(100),
email VARCHAR(100),
telefono VARCHAR(20)
);
— Crea una tabella degli ordini
CREATE TABLE ordini (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATA,
importo_totale DECIMALE(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
— Crea una tabella delle interazioni con i clienti:
CREATE TABLE customer_interactions (
interaction_id INT PRIMARY KEY,
customer_id INT,
interaction_date DATE,
interaction_type VARCHAR(50),
nota TESTO,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
Con questa configurazione, aggiornare l'indirizzo e-mail di un cliente è un gioco da ragazzi: basta apportare la modifica nella tabella Clienti e ciò non influirà sulle query o su altre tabelle. Ciò rende la gestione, l'interrogazione e l'archiviazione dei dati più efficiente e meno soggetta a errori.
3. Scalabilità
Man mano che la tua attività cresce, cresceranno anche il database dei dipendenti e quello dei clienti. Gli sviluppatori di sistemi software per database relazionali progettano database relazionali in grado di gestire grandi volumi di dati.
Che tu stia gestendo i registri commerciali di una startup o i numerosi utenti di un gigante tecnologico, i database relazionali si adattano facilmente alla crescita della tua attività. Essi indicizzano il modello di dati e ottimizzano i set di dati per mantenere prestazioni fluide man mano che i tuoi dati crescono.
Ad esempio, per migliorare le prestazioni delle query su una tabella di ordini di grandi dimensioni, puoi creare un indice sulla colonna order_date:
— Crea un indice sulla colonna order_date
CREATE INDEX idx_order_date ON orders(order_date);
Questo indice crea un set di dati separato che memorizza la posizione della colonna order_date e può essere consultato rapidamente.
La creazione di un indice velocizza l'esecuzione delle query quando si esegue un filtro o un ordinamento per data_ordine, rendendo più veloci le transazioni del database relazionale.
Aiuta anche i tuoi sistemi di gestione di database relazionali a scalare man mano che gli ordini crescono.
4. Flessibilità
La flessibilità è fondamentale quando si lavora con esigenze di dati in continua evoluzione, e i database relazionali offrono proprio questo.
Hai bisogno di aggiungere nuovi campi o tabelle? Fallo!
Ad esempio, se hai bisogno di effettuare il monitoraggio dei punti fedeltà dei clienti nella tabella clienti del tuo database CRM (Customer Resource Management), puoi aggiungere una nuova colonna:
— Aggiungi una nuova colonna per i punti fedeltà
ALTER TABLE customers ADD loyalty_points INT per impostazione predefinita 0;
Questa adattabilità garantisce che il tuo modello di gestione del database relazionale possa crescere e cambiare insieme alle esigenze del tuo progetto senza influire sul modello di dati relazionali esistente, sulle strutture di spazio di archiviazione fisica, sul modello di spazio di archiviazione fisica dei dati o sulle operazioni del database.
Mentre esploriamo i sistemi di database relazionali, ClickUp si distingue come uno strumento versatile per il project management che offre potenti funzionalità CRM e di database relazionale.

Il software di project management CRM di ClickUp trasforma il modo in cui gestisci le relazioni con i clienti e ottimizza i processi commerciali. Puoi personalizzare il modello di database relazionale dei clienti in base alle tue esigenze collegando attività, documenti e accordi e utilizzare l'automazione e i moduli per ottimizzare i flussi di lavoro, automatizzare l'assegnazione delle attività e trigger gli aggiornamenti dello stato.
Puoi esplorare le informazioni sui tuoi clienti con dashboard delle prestazioni per visualizzare metriche critiche come il valore del ciclo di vita del cliente e l'importo medio delle transazioni.
Inoltre, ClickUp CRM può aiutarti a semplificare la gestione degli account, organizzare i clienti, gestire le pipeline, effettuare il monitoraggio degli ordini e persino aggiungere dati geografici: tutto progettato per potenziare l'efficienza e la produttività del tuo CRM.
5. Potenti funzionalità di query
Per ottenere informazioni approfondite dal tuo database relazionale, puoi utilizzare SQL per eseguire ricerche complesse, unire più tabelle e aggregare dati.
Ad esempio, supponiamo che tu stia analizzando le prestazioni di vendita individuando il numero totale di ordini e il loro valore per cliente. Questa query unisce le tabelle dei clienti e degli ordini per fornire un riepilogo/riassunto delle prestazioni di vendita per cliente.
Una procedura memorizzata è come una scorciatoia in un database. Le procedure memorizzate sono blocchi di codice SQL precompilati che puoi eseguire ogni volta che devi eseguire query complesse, effettuare automazioni o gestire processi ripetitivi.
Utilizzando le procedure memorizzate, puoi semplificare le operazioni, aumentare l'efficienza e garantire che le azioni del database siano coerenti e veloci. Le procedure memorizzate sono perfette per la convalida dei dati e l'aggiornamento dei record.
SQL consente di raccogliere dati da diverse tabelle per creare report e visualizzazioni dettagliati. Questa capacità di generare informazioni significative rende i database relazionali uno strumento fondamentale per amministratori di database, analisti di dati o sviluppatori di dati.
Passaggi per creare un database relazionale
Ora che abbiamo esplorato e compreso i componenti e i diversi tipi di relazioni nei database relazionali, è il momento di applicare ciò che abbiamo imparato. Ecco una guida passo passo alla creazione di un database relazionale. Per comprendere meglio, creeremo un database per la gestione dei progetti di project management.
Passaggio 1: Definire lo scopo
Inizia chiarendo quali saranno le cose da fare con il tuo sistema di database relazionale.
Nel nostro esempio, stiamo costruendo un modello di database relazionale per il monitoraggio delle proprietà della gestione dei progetti, come attività, membri del team e scadenze.
Vuoi che il database relazionale:
- Gestisci più progetti contemporaneamente
- Assegna attività ai membri del team e effettua il monitoraggio dello stato delle attività
- Monitora le scadenze delle attività e lo stato di completamento
- Genera report sullo stato di avanzamento del progetto e sulle prestazioni del team.
Passaggio 2: Progettare lo schema
Successivamente, abbozza la struttura del tuo database relazionale.
Identifica le entità chiave [tabelle], i loro attributi di dati [colonne] e come interagiscono. Questo passaggio comporta il piano per come i tuoi dati strutturati saranno organizzati e correlati.
Entità per il project management:
- Progetti: contiene dettagli su ciascun progetto
- Attività: include informazioni sulle singole attività
- Membri del team: memorizza i dettagli relativi al team
- Assegnazione delle attività: collega le attività ai membri del team
Ecco uno schema di campione:
| Nome tabella | Attributi | Descrizione |
| Progetti | project_id (INT, PK)project_name (VARCHAR(100))start_date (DATE)end_date (DATE) | La tabella memorizza le informazioni relative a ciascun progetto. |
| Attività | task_id (INT, PK)project_id (INT, FK)task_name (VARCHAR(100))stato (VARCHAR(50))due_date (DATE) | La tabella contiene i dettagli delle attività associate ai progetti. |
| Membri del team | member_id (INT, PK)name (VARCHAR(100))ruolo (VARCHAR(50)) | La tabella contiene informazioni sui membri del team. |
| Compiti assegnati | task_id (INT, FK)member_id (INT, FK)assignment_date (DATE) | La tabella collega le attività ai membri del team con le date di assegnazione. |
Le relazioni tra queste strutture logiche di dati e le tabelle di dati possono talvolta creare confusione, poiché la maggior parte dei sistemi di gestione di database relazionali diventano sempre più complessi.
Molti preferiscono una rappresentazione visiva delle relazioni, solitamente attraverso mappe mentali e strumenti di progettazione di database relazionali .
Più avanti nell'articolo parleremo delle mappe mentali e degli strumenti di progettazione di database relazionali.
Passaggio 3: Stabilire relazioni
Abbiamo già discusso in precedenza i tipi di relazioni e lo schema delle tabelle aiuta a definire le relazioni tra le tabelle.
La chiave esterna è fondamentale per garantire la coerenza dei dati e consentire query complesse.
Essi collegano i punti dati correlati tra le tabelle e mantengono l'integrità dei dati referenziali in tutto il database, assicurando che ogni record sia collegato correttamente agli altri.
Ma è necessario effettuare la condivisione per facilitarne la consultazione, come nell'esempio riportato di seguito:
- Le attività sono correlate ai progetti tramite project_id
- Gli incarichi collegano le attività e i membri del team utilizzando task_id e member_id.
Passaggio 4: Creare tabelle
Abbiamo già discusso in modo approfondito il processo di creazione delle tabelle, definendo le chiavi primarie e esterne. Puoi fare riferimento a quelle sezioni se necessario. Tuttavia, puoi trovare le query SQL qui sotto per creare un piccolo database relazionale per il project management come parte della guida.
— Crea una tabella Progetti
CREATE TABLE Progetti (
project_id INT PRIMARY KEY,
project_name VARCHAR(100),
start_date DATE,
end_date DATA
);
— Crea una tabella Attività
CREATE TABLE Attività (
task_id INT PRIMARY KEY,
project_id INT,
task_name VARCHAR(100),
stato VARCHAR(50),
due_date DATE,
FOREIGN KEY (project_id) REFERENCES Progetti(project_id)
);
— Crea una tabella dei membri del team
CREATE TABLE TeamMembers (
member_id INT PRIMARY KEY,
nome VARCHAR(100),
ruolo VARCHAR(50)
);
— Crea tabella Assegnazioni attività
CREATE TABLE TaskAssignments (
task_id INT,
member_id INT,
assignment_date DATE,
FOREIGN KEY (task_id) REFERENCES Tasks(task_id),
FOREIGN KEY (member_id) REFERENCES TeamMembers(member_id),
PRIMARY KEY (task_id, member_id)
);
Passaggio 5: Inserimento dei dati
Aggiungi alcuni dati reali alle tue tabelle per vedere come funziona tutto.
Questo passaggio prevede il test della configurazione per garantire che i database relazionali funzionino come previsto. Ciò include l'inserimento dei dettagli del progetto, delle descrizioni delle attività, dei membri del team e degli incarichi nel database SQL.
Esempio di codice SQL
— Inserisci nella tabella Progetti
INSERT INTO Progetti (id_progetto, nome_progetto, data_inizio, data_fine) VALORI
(1, "Riprogettazione del sito web", "2024-01-01", "2024-06-30"),
(2, "Sviluppo di app mobili", "2024-03-01", "2024-12-31");
— Inserisci nella tabella Attività
INSERT INTO Attività (task_id, project_id, task_name, stato, due_date) VALUES
(1, 1, "Modelli di progettazione", "In corso", "2024-02-15"),
(2, 1, "Sviluppo front-end", "Non iniziato", "30-04-2024");
— Inserisci nella tabella Membri del team
INSERT INTO TeamMembers (member_id, name, ruolo) VALUES
(1, "Alice Johnson", "Designer"),
(2, "Bob Smith", "Sviluppatore");
— Inserisci nella tabella Assegnazioni attività
INSERT INTO TaskAssignments (task_id, member_id, assignment_date) VALUES
(1, 1, '2024-01-10'),
(2, 2, '2024-03-01');
Passaggio 6: Query dei dati
Infine, una volta che i dati sono stati memorizzati nel tuo database relazionale, utilizza le query SQL per recuperarli e analizzarli. Le query possono aiutarti a effettuare il monitoraggio dello stato dei progetti, controllare l'assegnazione delle attività e generare report preziosi.
Esempio di query SQL
— Query per trovare tutte le attività relative a un progetto specifico
SELECT t. nome_attività, t. stato, t. data_scadenza, tm. nome
DALLE attività t
JOIN TaskAssignments ta ON t. task_id = ta. task_id
UNISCITI A TeamMembers tm SU ta. member_id = tm. member_id
WHERE t. project_id = 1;
Creazione di sistemi di gestione di database relazionali con la vista Tabella di ClickUp
ClickUp eccelle nella creazione di database relazionali e fogli di calcolo puliti, organizzati e collaborativi utilizzando la sua vista Tabella.
La vista Tabella di ClickUp supporta oltre 15 tipi di dati, dalle formule e dallo stato di avanzamento delle attività ai costi e alle valutazioni, e consente di allegare documenti e link direttamente alle tabelle. Offre un modo visivo e intuitivo per gestire il database relazionale e la struttura dei dati relazionali all'interno dei progetti.

Una guida passo passo alla creazione di un sistema di gestione di database relazionali utilizzando la vista Tabella di ClickUp.
Passaggio 1: Definire il database
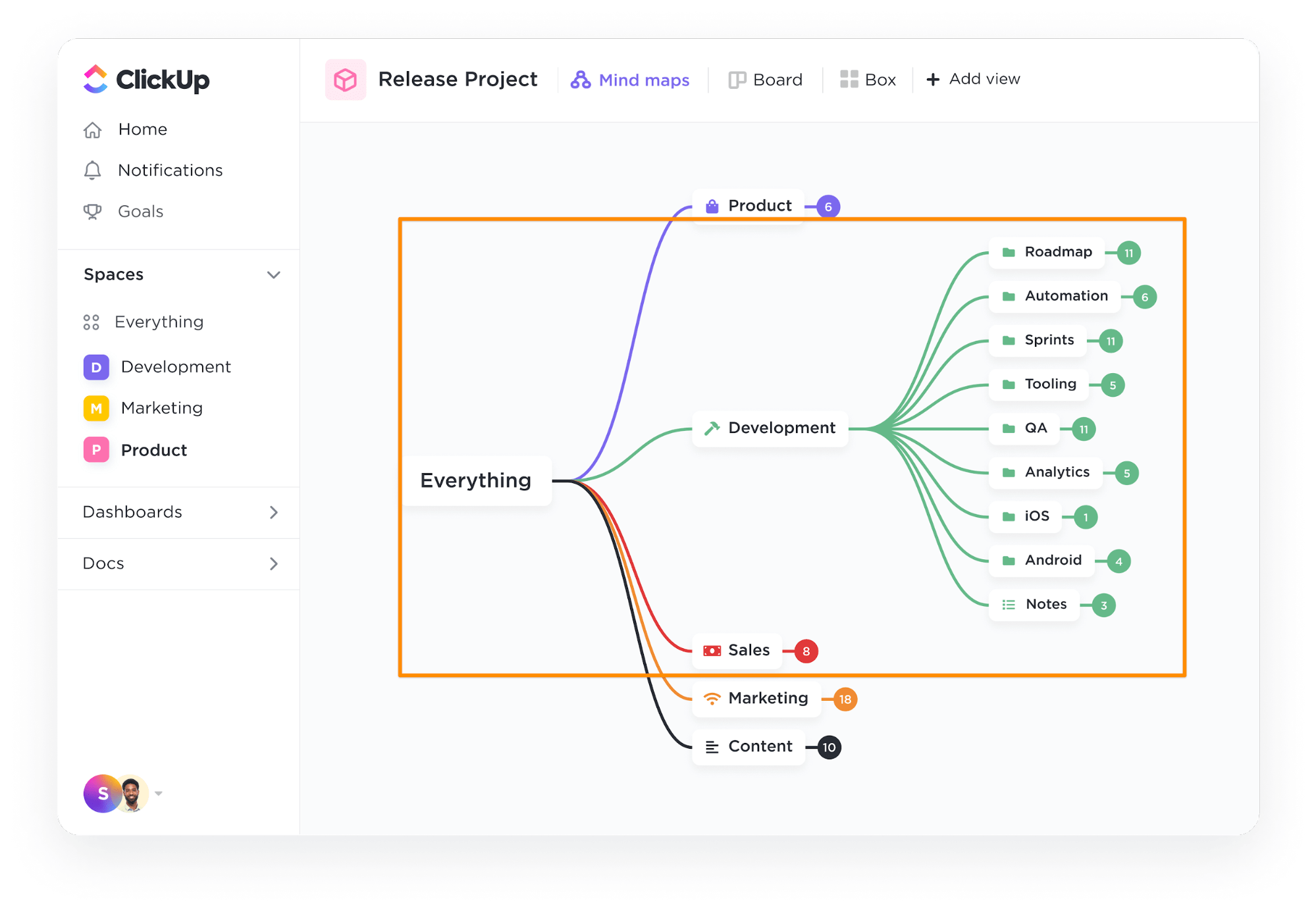
Utilizza lo strumento ClickUp Mappe mentali per compilare e definire lo schema del tuo database, ovvero quali tabelle creare e le loro relazioni reciproche.
Passaggio 2: imposta una vista Tabella
Passa al progetto o all'area di lavoro desiderata in ClickUp.

Aggiungi una nuova vista e seleziona Vista Tabella.
Passaggio 3: Creare tabelle
Utilizza attività e campi personalizzati per rappresentare tabelle e colonne.

Organizza i punti dati chiave nella vista Tabella.
Passaggio 4: Stabilire relazioni
Utilizza i campi personalizzati per collegare attività correlate [ad esempio, utilizzando gli elenchi a discesa per fare riferimento ad altre attività].

Mantieni l'integrità dei dati assicurandoti che i collegamenti siano accurati.
Passaggio 5: Gestione dei dati
Aggiungi, modifica ed elimina voci di dati direttamente nella vista Tabella.

Utilizza filtri e opzioni di ordinamento per gestire e analizzare i dati.
Passaggio 6: Query e reportistica
Utilizza le funzionalità avanzate di filtraggio e reportistica di ClickUp per generare approfondimenti dai tuoi dati relazionali.

I modelli di database gratis e pronti all'uso di ClickUp possono velocizzare il processo di creazione del tuo database relazionale e semplificare le cose.

Il modello di foglio di calcolo ClickUp raccoglie informazioni cruciali sui clienti per la tua attività. Si tratta di un modello a livello di elenco che utilizza un database flat-file.
Basta aggiungere il modello al tuo spazio e utilizzarlo direttamente.
Questi modelli di foglio di calcolo ti aiutano a raccogliere e gestire in modo efficiente i dati essenziali dei clienti. Puoi archiviare i dati in modo sicuro e creare database relazionali altamente efficienti che possono aiutare il personale commerciale della tua organizzazione.
Il modello di foglio di calcolo modificabile di ClickUp è il modello più facilmente personalizzabile per la gestione di dati finanziari complessi. Questo modello semplifica il monitoraggio del budget e la pianificazione dei progetti.
Funzionalità quali importazione automatica dei dati, formule finanziarie personalizzate, grafici intuitivi per il monitoraggio dei progressi e stati, campi e visualizzazioni personalizzati per organizzare e gestire in modo efficiente i dati finanziari lo rendono ideale per esperti e manager nel campo dei dati finanziari.
Con ClickUp, puoi automatizzare le attività, impostare aggiornamenti ricorrenti e rivedere la struttura dei tuoi dati senza soluzione di continuità, garantendo accuratezza e coerenza in tutti i tuoi documenti.
La creazione di contenuti può diventare rapidamente opprimente a causa della quantità di contenuti generati. Per gestire questo aspetto, un database di contenuti aiuta a organizzare e effettuare il monitoraggio dei contenuti in modo efficiente, rendendo più facile la scalabilità man mano che le tue esigenze crescono. Consolida tutte le informazioni relative ai contenuti, come lo stato e le metriche, in un sistema standardizzato, risparmiando tempo ed evitando la duplicazione del lavoro richiesto.
Il modello di database per blog di ClickUp è lo strumento ideale per gestire in modo efficiente i contenuti del blog. A differenza di altri fogli di calcolo Excel per la project management, è altamente intuitivo e può aiutarti a organizzare i post, semplificare la creazione e effettuare il monitoraggio dallo stato della bozza alla pubblicazione.

Puoi utilizzare questo modello per:
- Categorizza e suddividi in sottocategorie i post del blog per facilitarne l'accesso e il recupero.
- Monitora lo stato di ogni post dall'ideazione alla pubblicazione con stati personalizzati.
- Utilizza più visualizzazioni come Tabella, Monitoraggio stato e Hub database per visualizzare i dati.
- Utilizza liste di controllo e campi precompilati per semplificare il processo di creazione dei post del blog.
- Analizza le prestazioni del blog e gestisci le analisi per ottimizzare la strategia dei contenuti.
Grazie alle funzioni integrate di monitoraggio del tempo, tag e avvisi di dipendenza, gestire i contenuti del tuo blog non è mai stato così facile.
Costruisci una solida base con i database relazionali
Un sistema di gestione di database relazionali è molto più di un semplice strumento per un amministratore di database: è la spina dorsale di una gestione dei dati scalabile ed efficiente. Padroneggiare le complessità delle tabelle, delle chiavi primarie e esterne e delle relazioni tra database ti consentirà di progettare sistemi robusti e flessibili.
Sfruttando questi principi e ClickUp, puoi migliorare l'integrità dei dati, semplificare l'accesso e promuovere soluzioni innovative.
Sei pronto a migliorare la gestione dei tuoi dati? Iscriviti oggi stesso a ClickUp e scopri come può trasformare la gestione del tuo database relazionale e la tua produttività!