![Cómo entrenar Gemini con tus propios datos en [año]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Según un estudio de corporación reciente, el 73 % de las organizaciones afirman que sus modelos de IA no comprenden la terminología y el contexto específicos de la corporación, lo que da lugar a resultados que requieren una amplia corrección manual. Esto se convierte en uno de los mayores retos de la adopción de la IA.
Los grandes modelos lingüísticos como Google Gemini ya están entrenados con enormes conjuntos de datos públicos. Lo que la mayoría de las empresas realmente necesitan no es entrenar un nuevo modelo, sino enseñar a Gemini el contexto de su negocio: sus documentos, flujos de trabajo, clientes y conocimientos internos.
Esta guía le guiará a través del proceso completo de entrenamiento del modelo Gemini de Google con sus propios datos. Cubriremos todo, desde la preparación de conjuntos de datos en el formato JSONL correcto hasta la ejecución de tareas de ajuste en Google AI Studio.
También exploraremos si un entorno de trabajo convergente con contexto de IA integrado podría ahorrarte semanas de tiempo de configuración.
¿Qué es el ajuste de Gemini y por qué es importante?
El ajuste de Gemini es el proceso de entrenamiento del modelo base de Google con tus propios datos.
Usted quiere una IA que comprenda su empresa, pero los modelos listos para usar dan respuestas genéricas que no dan en el blanco. Esto significa que pierde tiempo corrigiendo constantemente los resultados, volviendo a explicar la terminología de su empresa y frustrándose cuando la IA simplemente no lo entiende.
Este constante ir y venir ralentiza a tu equipo y socava la promesa de productividad de la IA.
El ajuste fino de Gemini crea un modelo Gemini personalizado que aprende tus patrones específicos, tu tono y tus conocimientos del dominio, lo que le permite responder con mayor precisión a tus casos de uso únicos. Este enfoque funciona mejor para tareas consistentes y repetibles en las que el modelo base falla repetidamente.
En qué se diferencia el ajuste fino de la ingeniería de indicaciones
La ingeniería de indicaciones consiste en dar al modelo instrucciones temporales basadas en la sesión cada vez que interactúas con él. Una vez que termina la conversación, el modelo olvida tu contexto.
Este enfoque alcanza su límite cuando su caso de uso requiere conocimientos especializados que el modelo base simplemente no tiene. Solo puede dar un número limitado de instrucciones antes de que el modelo tenga que aprender realmente sus patrones.
Por el contrario, el ajuste fino modifica de forma permanente el comportamiento del modelo modificando sus pesos internos en función de sus ejemplos de entrenamiento, de modo que los cambios persisten en todas las sesiones futuras.
El ajuste no es una solución rápida para las frustraciones ocasionales de la IA, sino una inversión significativa de tiempo y datos. Tiene más sentido en escenarios específicos en los que el modelo base se queda corto de forma sistemática y se necesita una solución permanente.
Considera la posibilidad de realizar ajustes cuando necesites que la IA domine:
- Terminología especializada: su sector utiliza jerga que el modelo interpreta erróneamente de forma sistemática o no utiliza correctamente.
- Formato de salida coherente: necesitas respuestas con una estructura muy específica en todo momento, como la generación de informes o fragmentos de código.
- Conocimiento del sector: el modelo carece de conocimientos sobre sus productos especializados, procesos internos o flujos de trabajo propios.
- Voz de marca: quieres que todos los resultados generados por la IA coincidan perfectamente con la voz, el estilo y la personalidad exactos de la marca de tu empresa.
| Aspecto | Ingeniería de indicaciones | Ajuste fino |
| Qué es | Elaborar mejores indicaciones en la indicación para guiar el comportamiento del modelo. | Entrenar el modelo aún más con tus propios ejemplos |
| ¿Qué cambios? | La entrada que envías al modelo | Las ponderaciones internas del modelo |
| Rapidez de implementación | Inmediato: funciona al instante. | Lento: requiere tiempo para preparar el conjunto de datos y entrenar el modelo. |
| Complejidad técnica | Bajo: no se necesitan conocimientos de ML. | Medio-alto: requiere canalizaciones de ML. |
| Datos necesarios | Algunos buenos ejemplos dentro de la indicación | Cientos o miles de ejemplos etiquetados con rótulos |
| Consistencia de los resultados | Medio: varía según las indicaciones. | Alto: el comportamiento está integrado en el modelo. |
| Ideal para | Tareas puntuales, experimentos, iteración rápida. | Tareas repetitivas que requieren resultados consistentes |
La ingeniería de indicaciones da forma a lo que le dices al modelo. El ajuste fino da forma a cómo piensa el modelo.
Aunque este artículo se centra en Gemini, comprender otros enfoques alternativos para la personalización de la IA puede proporcionar una perspectiva valiosa sobre diferentes métodos para alcanzar metas similares.
Este vídeo muestra cómo crear un GPT personalizado, otro enfoque popular para adaptar la IA a casos de uso específicos:
📖 Lea también: Cómo convertirse en ingeniero de indicaciones
Cómo preparar tus datos de entrenamiento para Gemini
La mayoría de los proyectos de ajuste fino fracasan antes incluso de empezar porque los equipos subestiman el proceso de preparación de datos. Gartner prevé que el 60 % de los proyectos de IA se abandonarán debido a la insuficiencia de datos preparados para la IA.
Puede pasar semanas recopilando y formateando datos de forma incorrecta, solo para que el trabajo de entrenamiento falle o produzca un modelo inútil. A menudo, esta es la parte más laboriosa de todo el proceso, pero hacerlo bien es el factor más importante para un intento correcto.
El principio de «si entra basura, sale basura» se aplica en gran medida aquí. La calidad de su modelo personalizado será un reflejo directo de la calidad de los datos con los que lo entrene.
Requisitos de formato del conjunto de datos
Gemini requiere que tus datos de entrenamiento estén en un formato específico llamado JSONL, que significa JSON Lines. En un archivo JSONL, cada línea es un objeto JSON completo e independiente que representa un ejemplo de entrenamiento. Esta estructura facilita al sistema el procesamiento de grandes conjuntos de datos línea por línea.
Cada ejemplo de entrenamiento debe contener dos campos clave:
- text_input: Esta es la indicación o pregunta que le harías al modelo.
- Salida: esta es la respuesta ideal y perfecta que quieres que el modelo aprenda a producir.
Para mayor comodidad, Google AI Studio también acepta cargas en formato CSV y las convertirá a la estructura JSONL requerida por usted.
Esto puede facilitar un poco la entrada inicial de datos si tu equipo se siente más cómodo trabajando con hojas de cálculo.
Recomendaciones sobre el tamaño del conjunto de datos
Aunque la calidad es más importante que la cantidad, necesitas un número mínimo de ejemplos para que el modelo reconozca y aprenda patrones. Si empiezas con muy pocos ejemplos, el modelo no podrá generalizar ni funcionar de forma fiable.
A continuación, se incluyen algunas pautas generales sobre el tamaño de los conjuntos de datos:
- Mínimo viable: para tareas sencillas y muy específicas, puedes empezar a ver resultados con entre 100 y 500 ejemplos de alta calidad.
- Mejores resultados: para obtener resultados más complejos o matizados, si se aspiran a entre 500 y 1000 ejemplos, se obtendrá un modelo más robusto y fiable.
- Rendimientos decrecientes: en cierto momento, el simple hecho de añadir más datos repetitivos no mejorará significativamente el rendimiento. Céntrate en la diversidad y la calidad por encima del volumen.
Recopilar cientos de ejemplos de alta calidad supone un reto importante para la mayoría de los equipos. Planifica adecuadamente esta fase de recopilación de datos antes de comprometerte con el proceso de ajuste.
📮 ClickUp Insight: El profesional medio dedica más de 30 minutos al día a buscar información relacionada con el trabajo, lo que supone más de 120 horas al año perdidas en buscar entre correos electrónicos, hilos de Slack y archivos dispersos.
Un asistente inteligente de IA integrado en tu entorno de trabajo puede cambiar eso. Te presentamos ClickUp Brain. Ofrece información y respuestas instantáneas al mostrar los documentos, conversaciones y detalles de tareas adecuados en cuestión de segundos, para que puedas dejar de buscar y empezar a trabajar.
💫 Resultados reales: equipos como QubicaAMF recuperaron más de 5 horas semanales utilizando ClickUp, lo que supone más de 250 horas anuales por persona, al eliminar procesos obsoletos de gestión del conocimiento. ¡Imagina lo que tu equipo podría crear con una semana extra de productividad cada trimestre!
Buenas prácticas para la calidad de los datos
Los ejemplos incoherentes o contradictorios confundirán al modelo, lo que dará lugar a resultados poco fiables e impredecibles. Para evitarlo, los datos de entrenamiento deben seleccionarse y limpiarse meticulosamente. Un solo ejemplo erróneo puede echar por tierra el aprendizaje de muchos ejemplos correctos.
Sigue estas directrices para garantizar una alta calidad de los datos:
- Coherencia: todos los ejemplos deben seguir el mismo formato, estilo y tono. Si quieres que la IA sea formal, todos tus ejemplos de salida deben ser formales.
- Diversidad: tu conjunto de datos debe abarcar el intervalo completo de entradas que el modelo probablemente encontrará en el uso real. No lo entrenes solo con los casos fáciles.
- Precisión: cada ejemplo de salida debe ser perfecto. Debe ser la respuesta exacta que usted desea que produzca el modelo, sin errores ni faltas ortográficas.
- Limpieza: antes de entrenar, debes eliminar los ejemplos duplicados, corregir todos los errores ortográficos y gramaticales, y resolver cualquier contradicción en los datos.
Es muy recomendable que varias personas revisen y validen los ejemplos de entrenamiento. A menudo, una mirada nueva puede detectar errores o inconsistencias que tú podrías haber pasado por alto.
Cómo ajustar Gemini paso a paso
El proceso de ajuste de Gemini implica varios pasos técnicos en las plataformas de Google. Un solo error de configuración puede hacerte perder horas de valioso tiempo de entrenamiento y recursos informáticos, obligándote a empezar de nuevo. Esta guía práctica está diseñada para reducir ese proceso de prueba y error, guiándote a través del proceso de principio a fin. 🛠️
Antes de empezar, necesitará una cuenta de Google Cloud con la facturación habilitada y acceso a Google AI Studio. Reserve al menos unas horas para la configuración inicial y su primer trabajo de entrenamiento, además de tiempo adicional para probar y repetir su modelo.
Paso 1: Configurar Google AI Studio
Google AI Studio es la interfaz web desde la que gestionarás todo el proceso de ajuste. Ofrece una forma sencilla de cargar datos, configurar el entrenamiento y probar tu modelo personalizado sin necesidad de escribir código.
En primer lugar, acceda a ai.google.dev e inicie sesión con su cuenta de Google.
Deberá aceptar las condiciones de servicio y crear un nuevo proyecto en Google Cloud Console si aún no tiene uno. Asegúrese de habilitar las API necesarias según las indicaciones de la plataforma.
Paso 2: Cargue su conjunto de datos de entrenamiento
Una vez que haya completado el ajuste, vaya a la sección de ajuste dentro de Google AI Studio. Aquí, comenzará el proceso de creación de su modelo personalizado.
Seleccione la opción «Crear modelo ajustado» y elija su modelo base. Gemini 1. 5 Flash es una opción común y rentable para el ajuste fino.
A continuación, carga el archivo JSONL o CSV que contiene tu conjunto de datos de entrenamiento preparado. La plataforma validará tu archivo para asegurarse de que cumple con los requisitos de formato, señalando cualquier error común, como campos faltantes o estructura incorrecta.
Paso 3: Configure los ajustes de optimización
Una vez que hayas subido y validado tus datos, podrás configurar los parámetros de entrenamiento. Estos ajustes, conocidos como hiperparámetros, controlan cómo el modelo aprende de tus datos.
Las opciones clave que verás son:
- Épocas: Determinan cuántas veces se entrenará el modelo con todo tu conjunto de datos. Un mayor número de épocas puede conducir a un mejor aprendizaje, pero también conlleva el riesgo de sobreajuste.
- Tasa de aprendizaje: controla la agresividad con la que el modelo ajusta sus pesos basándose en tus ejemplos.
- Tamaño del lote: establece cuántos ejemplos de entrenamiento se procesan juntos en un solo grupo.
Para tu primer intento, lo mejor es empezar con los ajustes predeterminados recomendados por Google AI Studio. La plataforma simplifica estas decisiones complejas, haciéndolas accesibles incluso si no eres un experto en aprendizaje automático.
Paso 4: Ejecuta la tarea de ajuste.
Una vez configurados los ajustes, ya puede iniciar el trabajo de ajuste. Los servidores de Google comenzarán a procesar sus datos y a ajustar los parámetros del modelo. Este proceso de entrenamiento puede durar entre unos minutos y varias horas, dependiendo del tamaño de su conjunto de datos y del modelo que haya seleccionado.
Puedes supervisar el progreso del trabajo directamente en el panel de control de Google AI Studio. Dado que el trabajo se ejecuta en los servidores de Google, puedes cerrar el navegador con total seguridad y volver más tarde para comprobar el estado. Si un trabajo falla, casi siempre se debe a un problema con la calidad o el formato de tus datos de entrenamiento.
Paso 5: Prueba tu modelo personalizado
Una vez completada la tarea de entrenamiento, tu modelo personalizado estará listo para ser probado. ✨
Puede acceder a ella a través de la interfaz del entorno de pruebas en Google IA Studio.
Comience enviándole indicaciones de prueba similares a sus ejemplos de entrenamiento para verificar su precisión. A continuación, pruébelo en casos extremos y nuevas variaciones que no haya visto antes para evaluar su capacidad de generalización.
- Precisión: ¿Produce los resultados exactos para los que lo has entrenado?
- Generalización: ¿Maneja correctamente las nuevas entradas que son similares pero no idénticas a tus datos de entrenamiento?
- Consistencia: ¿Son sus respuestas fiables y predecibles en múltiples intentos con la misma indicación?
Si los resultados no son satisfactorios, es probable que tengas que volver atrás, mejorar tus datos de entrenamiento añadiendo más ejemplos o corrigiendo inconsistencias, y luego volver a entrenar el modelo.
Buenas prácticas para entrenar Gemini con datos personalizados
El simple hecho de seguir los pasos técnicos no garantiza un modelo excelente. Muchos equipos completan el proceso solo para acabar decepcionados con los resultados, ya que no aplican las estrategias de optimización que utilizan los profesionales con experiencia. Esto es lo que diferencia un modelo funcional de uno de alto rendimiento.
No es de extrañar que el informe «State of Generative AI in the Enterprise» (Estado de la IA generativa en la empresa) de Deloitte revele que dos tercios de las empresas afirman que el 30 % o menos de sus experimentos con IA generativa se ampliarán por completo en un plazo de seis meses.
La adopción de estas buenas prácticas le ahorrará tiempo y le proporcionará resultados mucho mejores.
- Empieza poco a poco y luego amplía: antes de confirmar un entrenamiento completo, prueba tu enfoque con un pequeño subconjunto de tus datos (por ejemplo, 100 ejemplos). Esto te permitirá validar el formato de tus datos y hacerte una idea rápida del rendimiento sin perder horas.
- Versión de sus conjuntos de datos: a medida que añada, elimine o realice ediciones en los ejemplos de entrenamiento, guarde cada versión de su conjunto de datos. Esto le permitirá realizar el seguimiento de los cambios, reproducir los resultados y volver a una versión anterior si la nueva funciona peor.
- Prueba antes y después: antes de empezar con el ajuste, establece una referencia evaluando el rendimiento del modelo base en tus tareas clave. Esto te permitirá medir de forma objetiva la mejora que has conseguido con tus esfuerzos de ajuste.
- Repite los errores: cuando tu modelo personalizado genere una respuesta incorrecta o con un formato inadecuado, no te frustres. Añade ese caso de error específico como un nuevo ejemplo corregido en tus datos de entrenamiento para la próxima iteración.
- Documenta tu proceso: lleva un registro de cada sesión de entrenamiento, anotando la versión del conjunto de datos utilizada, los hiperparámetros y los resultados. Esta documentación es muy valiosa para comprender qué funciona y qué no a lo largo del tiempo.
La gestión de estas iteraciones, versiones de conjuntos de datos y documentación requiere una sólida gestión de proyectos. Centralizar este trabajo en una plataforma diseñada para flujos de trabajo estructurados puede evitar que el proceso se vuelva caótico.
Retos comunes durante el entrenamiento de Gemini
Los equipos suelen invertir mucho tiempo y recursos en el ajuste, solo para encontrarse con obstáculos previsibles que provocan una pérdida de esfuerzo y frustración. Conocer de antemano estos errores comunes puede ayudarte a navegar por el proceso con mayor fluidez.
Estos son algunos de los retos más frecuentes y cómo abordarlos:
- Sobreajuste: esto ocurre cuando el modelo memoriza perfectamente tus ejemplos de entrenamiento, pero no logra generalizar a entradas nuevas y desconocidas. Para solucionarlo, puedes añadir más diversidad a tus datos de entrenamiento, considerar reducir el número de épocas o explorar métodos alternativos como la generación aumentada por recuperación.
- Resultados inconsistentes: si el modelo da respuestas diferentes a preguntas muy similares, es probable que sea porque tus datos de entrenamiento contienen ejemplos contradictorios o inconsistentes. Es necesario realizar una limpieza exhaustiva de los datos para resolver estos conflictos.
- Desviación de formato: a veces, un modelo comienza siguiendo la estructura de salida deseada, pero luego se «desvía» de ella con el tiempo. La solución es incluir instrucciones de formato explícitas en la salida de sus ejemplos de entrenamiento, no solo el contenido.
- Ciclos de iteración lentos: cuando cada ciclo de entrenamiento dura horas, se ralentiza drásticamente su capacidad para experimentar y mejorar. Pruebe primero sus ideas en conjuntos de datos más pequeños para obtener una respuesta más rápida antes de lanzar un trabajo de entrenamiento completo.
- Cuello de botella en la recopilación de datos: A menudo, la parte más difícil es el cuello de botella en la recopilación de datos, es decir, simplemente reunir suficientes ejemplos de alta calidad. Empieza por aprovechar tu mejor contenido existente, como tickets de soporte, textos de marketing o documentos técnicos, y amplía a partir de ahí.
Estos retos son una de las razones clave por las que muchos equipos acaban buscando alternativas al proceso de ajuste manual.
📮ClickUp Insight: El 88 % de los encuestados utiliza la IA para sus tareas personales, pero más del 50 % evita utilizarla en el trabajo. ¿Las tres barreras principales? La falta de integración fluida, las lagunas de conocimiento o las preocupaciones en materia de seguridad. Pero, ¿y si la IA estuviera integrada en tu entorno de trabajo y ya fuera segura? ClickUp Brain, el asistente de IA integrado de ClickUp, lo hace realidad. Entiende las indicaciones en lenguaje sencillo, resolviendo las tres preocupaciones relacionadas con la adopción de la IA, al tiempo que conecta tu chat, tus tareas, tus documentos y tus conocimientos en todo el entorno de trabajo. ¡Encuentra respuestas e información con un solo clic!
Por qué ClickUp es una alternativa más inteligente
El ajuste fino de Gemini es muy potente, pero también es una solución alternativa.
A lo largo de este artículo, hemos visto que el ajuste fino se reduce, en última instancia, a una cosa: enseñar a la IA a comprender el contexto de su empresa. El problema es que el ajuste fino lo hace de forma indirecta. Usted prepara conjuntos de datos, diseña ejemplos, vuelve a entrenar modelos y mantiene canalizaciones, todo ello para que la IA pueda aproximarse al funcionamiento de su equipo.
Esto tiene sentido para casos de uso especializados. Pero para la mayoría de los equipos, la meta real no es la personalización de Gemini por sí misma. La meta es más sencilla:
Quieres una IA que comprenda tu trabajo.
Aquí es donde ClickUp adopta un enfoque fundamentalmente diferente y más inteligente.
El entorno de trabajo de IA convergente de ClickUp proporciona a tu equipo una IA que comprende tu contexto de trabajo al instante, sin necesidad de realizar grandes esfuerzos. En lugar de entrenar a la IA para que aprenda tu contexto más adelante, trabajas con ClickUp Brain, el asistente de IA integrado, donde tu contexto ya está presente.
Tus tareas, documentos, comentarios, historial de proyectos y decisiones están conectados de forma nativa. No es necesario entrenar la IA con tus datos, ya que esta ya se encuentra donde se desarrolla tu trabajo, aprovechando tu ecosistema de gestión del conocimiento existente.
| Aspecto | Ajuste de Gemini | ClickUp Brain |
|---|---|---|
| Tiempo de configuración de la configuración | Días o semanas de preparación de datos | Inmediato: funciona con los datos existentes del entorno de trabajo. |
| Fuente de contexto | Ejemplos de entrenamiento seleccionados manualmente | Acceso automático a todo el trabajo conectado |
| Mantenimiento | Vuelva a entrenarlo cuando cambien sus necesidades. | Actualización continua a medida que evoluciona tu entorno de trabajo. |
| Habilidades técnicas necesarias | Moderado a alto | Ninguno |
Dado que ClickUp es tu sistema de trabajo, ClickUp Brain opera dentro de tu gráfico de datos conectados. No hay expansión de IA entre herramientas desconectadas, ni procesos de entrenamiento frágiles, ni riesgo de que el modelo se desincronice con la forma en que tu equipo trabaja realmente.
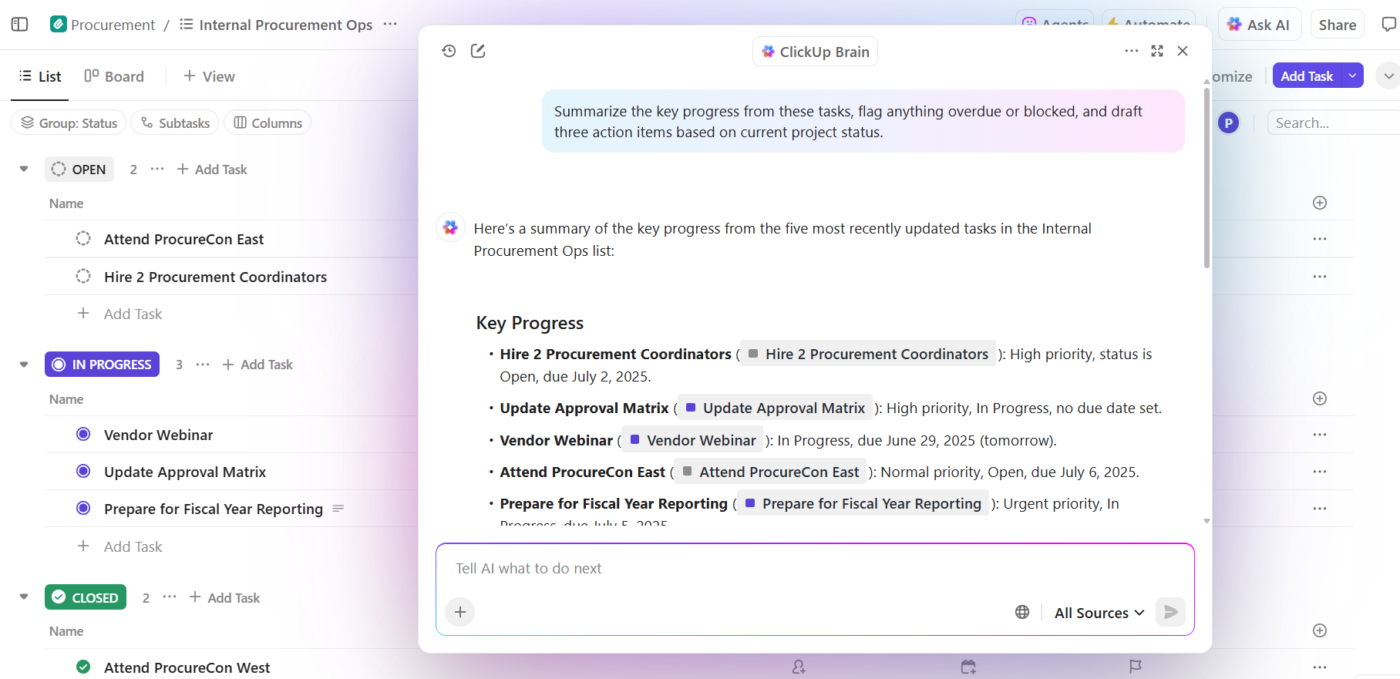
Así es como se ve en la práctica:
- Haz preguntas sobre tus proyectos: ClickUp Brain realiza búsquedas en el entorno de trabajo entre tareas, documentos, comentarios y actualizaciones para responder a preguntas utilizando los datos reales de tu proyecto, no conocimientos genéricos de entrenamiento.
- Genera contenido con contexto: ClickUp Brain ya tiene acceso seguro a tus tareas, archivos, comentarios e historial de proyectos. Puede crear documentos, resúmenes y actualizaciones de estado que hagan referencia a tu trabajo real, cronogramas y prioridades. Se acabó la dispersión de contexto, en la que los equipos pierden horas buscando información en diferentes aplicaciones y archivos.
- Automatiza con comprensión: con ClickUp Automations, puedes crear automatizaciones que reaccionen de forma inteligente al contexto del proyecto, como plazos, propiedad y cambios de estado, y no solo a reglas estáticas. La IA puede incluso crearlas por ti, sin necesidad de código.
💡Consejo profesional: Aprovecha todo el potencial de la IA en tu entorno de trabajo de ClickUp con ClickUp Super Agents.
Los Super Agents son compañeros de equipo de ClickUp impulsados por IA, configurados como «usuarios» de IA que trabajan junto a tu equipo dentro del entorno de trabajo. Son ambientales y contextuales, y se les pueden asignar tareas, hacer menciones en comentarios, desencadenarlos a través de eventos o programaciones, o dirigirlos a través del chat, igual que a un compañero de equipo humano.
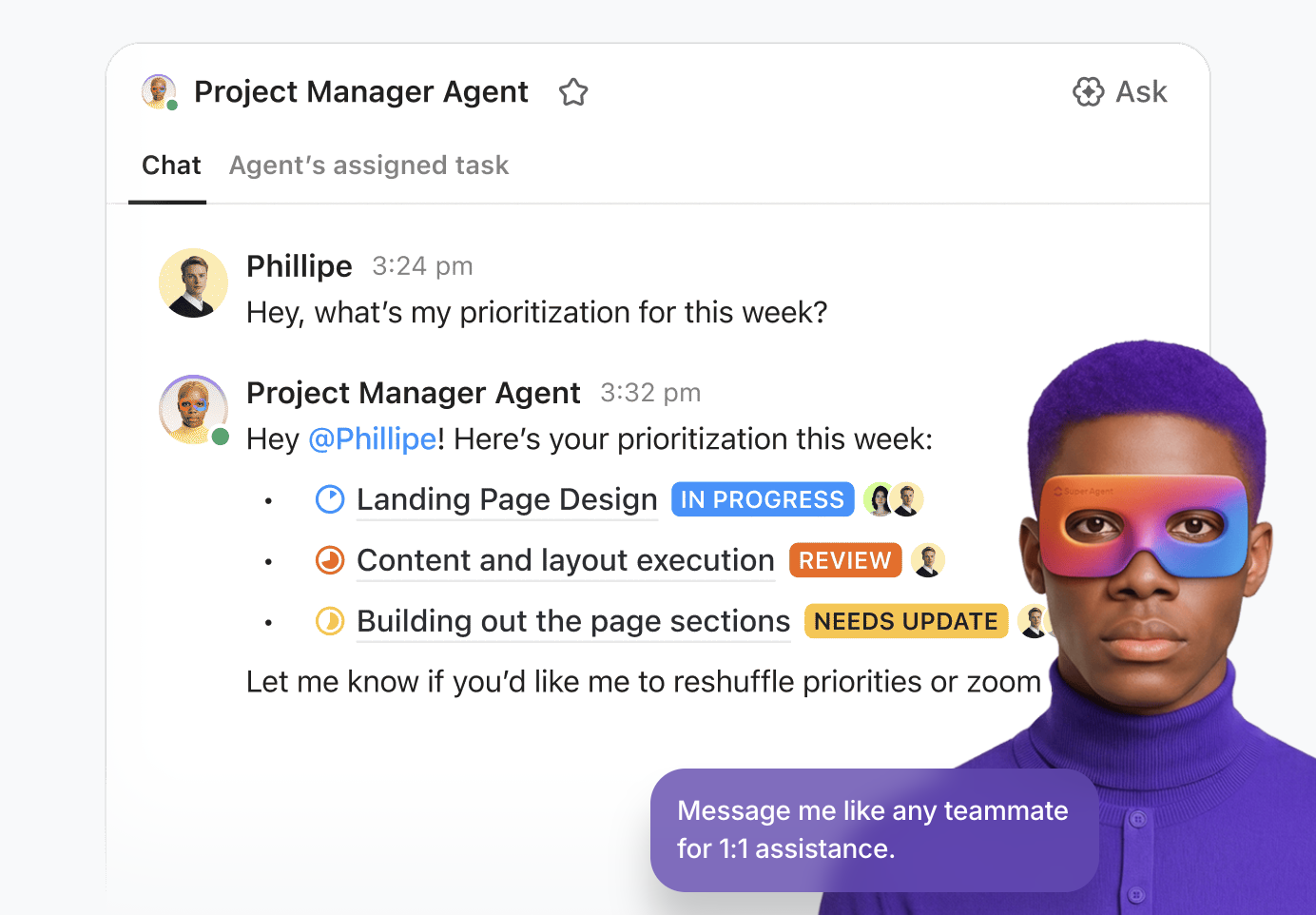
Puede crearlos e implementarlos utilizando el generador visual sin código que le permite:
- Identifica el evento inicial, como un mensaje o un cambio en el estado de una tarea.
- Esboza las reglas operativas, incluyendo cómo resumir datos, delegar trabajo o ajustar prioridades.
- Ejecute acciones externas a través de herramientas y extensiones integradas.
- Proporcione datos de soporte conectando el agente a las bases de conocimiento pertinentes.
Obtenga más información sobre los superagentes en el siguiente vídeo.
Ajusta tu estrategia de IA: obtén ClickUp
El ajuste fino enseña a una IA tus patrones a través de ejemplos estáticos, pero el uso de software convergente en un entorno de trabajo como ClickUp elimina la dispersión del contexto al proporcionar a tu IA un contexto automático y en tiempo real.
Esta es la clave para una transformación exitosa de la IA: los equipos que centralizan su trabajo en una plataforma conectada dedican menos tiempo a entrenar la IA y más tiempo a beneficiarse de ella. A medida que tu entorno de trabajo evoluciona, tu IA evoluciona automáticamente, sin necesidad de ciclos de reentrenamiento.
¿Estás listo para saltarte el entrenamiento y empezar con una IA que ya conoce tu trabajo? Empieza gratis con ClickUp y disfruta de las ventajas de un entorno de trabajo convergente.
Preguntas frecuentes (FAQ)
Tu modelo ajustado aprende de tus ejemplos de entrenamiento, pero el modelo Gemini básico de Google no conserva ni aprende de tus datos de conversación de forma predeterminada, por defecto. Tu modelo personalizado es independiente del modelo básico que se ofrece a otros usuarios.
Aunque el trabajo de entrenamiento en sí mismo solo lleva unas horas, la mayor inversión de tiempo se dedica a preparar datos de entrenamiento de alta calidad. Esta fase de preparación de datos a menudo puede llevar días o incluso semanas para completarse correctamente.
Sí, puede ajustar un modelo sin escribir código utilizando Google AI Studio. Proporciona una interfaz visual que se encarga de la mayor parte de la complejidad técnica, aunque seguirá siendo necesario comprender los requisitos de formato de los datos.
Las indicaciones personalizadas son indicaciones temporales basadas en sesiones que guían el comportamiento del modelo durante una sola conversación. Sin embargo, el ajuste fino modifica de forma permanente los parámetros internos del modelo en función de sus ejemplos de entrenamiento, lo que genera cambios duraderos en su comportamiento.