

Eres el jefe de un departamento y buscas a la persona perfecta para realizar una tarea concreta. Con la gran cantidad de datos de la empresa, encontrar al candidato ideal es casi imposible, especialmente si la tarea es urgente.
Además, ¿quién tiene tiempo para preguntar a todo el mundo si tiene suficientes conocimientos sobre un área específica?
Pero, ¿y si simplemente pudiera preguntarle a un sistema: «¿A quién se le ha asignado más [tarea]?» y obtener una respuesta instantánea y precisa basada en datos reales? Eso es lo que hacen los sistemas de recuperación de información.
Estos sistemas examinan grandes cantidades de datos para encontrar exactamente lo que necesita.
Ahora, amplíe esa idea a una base de datos global: un sistema de IR organiza grandes cantidades de datos, lo que le ayuda a encontrar las respuestas más relevantes en cuestión de segundos. En esta guía se exploran diferentes modelos de recuperación de información, cómo funcionan y el rol de las tecnologías de IA en un sistema de IR.
⏰ Resumen de 60 segundos
📌 Los sistemas de recuperación de información (IR) ayudan a encontrar información relevante en grandes colecciones de datos, funcionando como un asistente virtual que examina los datos para encontrar lo que necesitas.
📌 Los sistemas IR tienen componentes clave: base de datos, índice, interfaz de búsqueda, procesador de consultas, modelos de recuperación y mecanismos de clasificación/puntuación.
📌 Se utilizan cuatro modelos principales de IR: booleano (utiliza operadores AND/OR/NOT), espacio vectorial (representa los documentos como vectores), probabilístico (utiliza enfoques estadísticos) e interdependencia de términos (analiza las relaciones entre los términos).
📌 El aprendizaje automático y el procesamiento del lenguaje natural mejoran los sistemas de IR al optimizar el reconocimiento de patrones, la clasificación de resultados y la comprensión del contexto.
📌 Los principales retos incluyen la privacidad de los datos, la escalabilidad y el mantenimiento de la calidad de los datos durante el procesamiento de grandes conjuntos de datos.
¿Qué es la recuperación de información (IR)?
La recuperación de información (IR) significa simplemente encontrar la información adecuada en grandes colecciones de datos, como bibliotecas digitales, bases de datos o archivos de Internet.
Es como tener un asistente virtual que revisa montones de datos para ofrecerte exactamente lo que necesitas.
A simple vista, el usuario introduce una consulta, a menudo utilizando palabras clave o frases, para buscar información específica. Entre bastidores, técnicas y algoritmos avanzados analizan las cadenas de búsqueda y las comparan con los datos relevantes.
En lugar de identificar una única respuesta, los sistemas de IR proporcionan varios objetos, cada uno con diferentes grados de relevancia para su consulta. Además, se utilizan en todas partes y tienen múltiples aplicaciones (más información al respecto próximamente 🔔).
💡Consejo profesional: ¿Necesitas encontrar a la persona más cualificada para una tarea? Introduce términos específicos como «análisis de informes de ventas del primer y segundo trimestre tareas asignadas a» en el sistema de recuperación de información. De esta forma, se filtran rápidamente los datos irrelevantes y se identifica quién los ha gestionado más.
Aplicaciones de la IR en diferentes campos.
Desde la asistencia sanitaria hasta el comercio electrónico, los sistemas de IR se utilizan en numerosos campos para gestionar y categorizar datos. Aquí tienes algunos ejemplos 👇
Atención sanitaria
En el ámbito sanitario, los sistemas de IR escanean bases de datos de historiales médicos y artículos de investigación para ayudar a médicos e investigadores a encontrar la información más relevante. Como resultado, agilizan el diagnóstico de enfermedades, identifican opciones de tratamiento y encuentran los estudios más relevantes utilizando comentarios pertinentes.
Servicio de atención al cliente personalizado
Las técnicas de recuperación de información hacen que el soporte al cliente sea más rápido y preciso. Por ejemplo, los agentes pueden escribir consultas de los usuarios como «política de reembolso» en el sistema de la empresa para capturar respuestas instantáneas.
Los chatbots con IA y los servicios de asistencia técnica basados en la recuperación de información van un paso más allá, ofreciendo soluciones en tiempo real sin intervención humana. ¡Por eso sus preguntas suelen responderse en cuestión de segundos!
Plataformas de comercio electrónico
Los sistemas de IR facilitan las compras en línea. Analizan las bases de datos y comparan el comportamiento de los clientes para recomendar productos que le encantarán.
Por ejemplo, Amazon utiliza la IR para sugerir elementos basados en su historial de búsqueda y compras anteriores, lo que le ayuda a encontrar exactamente lo que necesita.
Componentes de un sistema de recuperación de información
Ahora sabemos qué es la recuperación de información y cómo funciona. Analicemos los componentes clave de un sistema de IR. →
1. Base de datos
Todo comienza con la base de datos. Se trata de una recopilación de puntos de datos interrelacionados, como documentos de texto, correos electrónicos, páginas web, imágenes y vídeos. Cuando introduces una consulta determinada, el sistema de IR busca entre estas coincidencias de la base de datos para recuperar la información más relevante para tus necesidades.
2. Índice
Antes de que el sistema pueda recuperar cualquier cosa, el índice organiza los datos. Es como preparar un índice de biblioteca para agilizar las búsquedas. El índice procesa los documentos mediante:
- Tokenización: Dividir el contenido en fragmentos más pequeños, como dividir oraciones en palabras o frases (denominadas tokens).
- Derivación: simplificar las palabras a su forma básica (por ejemplo, «running» se convierte en «run»).
- Eliminación de palabras innecesarias: omita palabras de relleno como «y», «o» y «el» para centrarse en la consulta principal.
- Extracción de palabras clave: Identificar las palabras clave principales del texto.
- Extracción de metadatos: Obtenga detalles adicionales como el autor, la fecha de publicación o el título.
3. Interfaz de búsqueda
La interfaz de búsqueda actúa como puerta de acceso al sistema IR. Aquí es donde se escribe la consulta utilizando palabras clave sencillas o filtros más detallados. Diseñada para ser fácil de usar, garantiza que pueda comunicar fácilmente sus necesidades de acceso a la información y obtener los resultados relevantes que busca.
4. Procesador de consultas
Una vez que pulsas «buscar», el procesador de consultas se encarga del resto. Refina tu entrada aplicando las técnicas enumeradas en la sección del índice. Además, también maneja operadores booleanos como «AND», «OR» y «NOT» para que tu consulta sea más inteligente.
5. Modelos de recuperación
Aquí es donde ocurre la magia. El sistema compara su consulta con los documentos del índice utilizando modelos de recuperación. Estos métodos deciden cómo hacer coincidir su consulta con los datos almacenados. Algunos de los nombres más comunes son:
- Modelos booleanos
- Modelos de espacio vectorial
- Modelos probabilísticos
- Y mucho más... (se tratará más adelante).
6. Clasificación y puntuación
Una vez encontradas las posibles coincidencias, el sistema las clasifica según su relevancia. Cada documento obtiene una puntuación utilizando métodos como TF-IDF (frecuencia de término-frecuencia inversa de documento) u otros algoritmos. Esto garantiza que el resultado más relevante aparezca en la parte superior.
7. Presentación o visualización
Por último, se le presentan los resultados. Normalmente, el sistema muestra una lista clasificada de documentos de texto con funciones adicionales como fragmentos, filtros u opciones de clasificación. Esto facilita la selección del documento más relevante. Sin embargo, el número de resultados mostrados puede variar en función de sus preferencias, la consulta o los ajustes del sistema.
🔍¿Sabías que...? Los sistemas tradicionales de recuperación de información dependían en gran medida de bases de datos estructuradas y de la coincidencia básica de palabras clave. ¿El resultado? Importantes problemas de relevancia y personalización.
Fue entonces cuando las modernas tecnologías de IA transformaron la recuperación de texto a través de:
- Aprendizaje automático (ML): ayuda a los sistemas de IR a aprender de los patrones de comportamiento de los usuarios y a mejorar los resultados de búsqueda con el tiempo.
- Redes neuronales profundas: algoritmos que pueden procesar datos no estructurados (como imágenes o vídeos) y descubrir relaciones complejas.
- Procesamiento del lenguaje natural (NLP): permite a los sistemas comprender el significado y el contexto de las consultas para facilitar el reconocimiento de imágenes y el análisis de sentimientos, lo que hace que el acceso a la información sea más versátil.
Modelos de recuperación de información
Existen diferentes sistemas de IR que agilizan el proceso de búsqueda de documentos relevantes. Veamos los más utilizados:
1. Teoría de conjuntos y modelos booleanos
El modelo booleano es una de las técnicas de recuperación de información más sencillas. Así es como funciona:
- Y: Recupera documentos que contienen todos los términos de la consulta. Por ejemplo, una búsqueda de «gato Y perro» devolverá documentos que tengan menciones de ambos términos en un motor de búsqueda.
- O: Encuentra documentos que contengan cualquiera de los términos de la consulta. Para «gato O perro», recupera documentos que tengan menciones de gato, perro o ambos.
- NO: Excluye los documentos que contienen un término específico. Por ejemplo, «gato Y NO perro» devuelve documentos que tienen menciones de gato pero no de perro.
Este modelo utiliza el concepto de «bolsa de palabras», en el que se crea una matriz 2D. En esta matriz:
- Las columnas representan documentos.
- Las filas representan términos de la consulta.
A cada celda se le asigna un valor de 1 (si el término está presente) o 0 (si no lo está).

✅ Ventajas
- Fácil de entender y de implementar.
- Recupera documentos que coinciden exactamente con los términos de la consulta.
❌ Contras
- Los modelos booleanos no clasifican los documentos por relevancia, por lo que todos los resultados se tratan como igualmente importantes.
- Se centra en coincidencias exactas de términos, por lo que los resultados pueden variar según el significado o el contexto de la consulta.
2. Modelos de espacio vectorial
Un modelo de espacio vectorial es un modelo algebraico que representa tanto los documentos como las consultas como vectores en un espacio multidimensional. Así es como funciona:
1. Se crea una matriz término-documento, en la que las filas son términos y las columnas son documentos.
2. Se formula un vector de consulta basado en los términos de búsqueda del usuario.
3. El sistema calcula una puntuación numérica utilizando una medida denominada similitud coseno, que determina el grado de coincidencia entre el vector de consulta y los vectores de los documentos.

Como sistema de recuperación de información, los documentos se clasifican en función de estas puntuaciones, siendo los mejor clasificados los más relevantes.
✅ Ventajas
- Recupera elementos incluso si solo coinciden algunos términos.
- Variaciones en el uso de términos y la longitud de los documentos, adaptándose a diversos tipos de documentos.
❌ Contras
- Los vocabularios y colecciones de documentos más grandes hacen que los cálculos de similitud requieran muchos recursos.
3. Modelos probabilísticos
Este modelo adopta un enfoque estadístico y utiliza la probabilidad para estimar la relevancia de un documento para la consulta. Tiene en cuenta:
- Frecuencia de los términos en el documento
- ¿Con qué frecuencia se repiten juntos los términos (coocurrencia)?
- Longitud del documento y número total de términos de consulta.
El sistema trata el proceso de recuperación como un evento probabilístico, clasificando los documentos almacenados en función de su probabilidad de relevancia. Este enfoque añade profundidad al evaluar los objetos de datos más allá de la presencia básica de términos.
✅ Ventajas
- Se adapta bien a diversas aplicaciones, incluyendo análisis de fiabilidad y evaluaciones del flujo de carga.
❌ Contras
- Se basa en suposiciones sobre las relaciones entre los datos, lo que puede dar lugar a resultados engañosos.
4. Modelos de interdependencia de términos
A diferencia de los modelos más simples, los modelos de interdependencia de términos se centran en las relaciones entre los términos, en lugar de solo en su frecuencia. Estos modelos analizan cómo se relacionan entre sí las palabras y las frases para mejorar la precisión de los resultados.
Utilizan uno de estos dos enfoques:
- Modo inmanente: explora las relaciones dentro del propio texto.
- Modo trascendente: tiene en cuenta datos externos o el contexto para inferir relaciones.
Este método es especialmente útil para captar matices en el significado, como sinónimos o frases específicas del contexto.
✅ Ventajas
- Captura los matices del lenguaje teniendo en cuenta las relaciones entre términos.
- Mejora el rendimiento de la recuperación mediante la comprensión de las dependencias de los términos y el contexto.
❌ Contras
- Requiere una gran cantidad de datos para modelar con precisión las relaciones entre términos, lo que puede no estar siempre disponible.
¡Eso es todo! Estos son algunos de los sistemas de recuperación de información más utilizados, con sus propias ventajas e inconvenientes.
➡️ Más información: 4 alternativas y competidores de Spotlight Search
Recuperación de información frente a consulta de datos
Aunque ambos términos parecen casi iguales, funcionan de manera diferente. Así que compararemos la IR y la consulta de datos para ver cómo se comparan en términos de finalidad, casos de uso y ejemplos:
| Aspecto | Recuperación de información (IR) | Consultas de datos |
| Definición | Funciona como un motor de búsqueda que rastrea toneladas de datos para ofrecerte los resultados más relevantes. | Piensa en ello como si le hicieras una pregunta específica a una base de datos en un lenguaje que entiende (como SQL). |
| Meta/Propósito | Le ayuda a encontrar información o recursos precisos y relevantes en los motores de búsqueda, de forma rápida y sencilla. | Extrae números exactos para que puedas analizar, actualizar o procesar números. |
| Casos de uso | Se utiliza para búsquedas en la web, recomendaciones de comercio electrónico, bibliotecas digitales, información sobre atención sanitaria y mucho más. | Ideal para tareas como la gestión de existencias en el comercio electrónico, el análisis de las finanzas y la optimización de las cadenas de suministro. |
| Ejemplo | Buscar «Las mejores computadoras portátiles entre 800 y 1000 dólares» en Google para obtener resultados clasificados. | Consulte su sistema de inventario con la consulta «SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000» para ver qué hay en stock. |
El rol del aprendizaje automático y el procesamiento del lenguaje natural en la recuperación de información
Los sistemas de IR son como cazadores de tesoros de datos: examinan grandes cantidades de información para encontrar exactamente lo que estás buscando. Pero cuando ML y NLP unen fuerzas, estos sistemas se vuelven más inteligentes, más rápidos y mucho más precisos.
Piensa en el aprendizaje automático como el cerebro detrás de los sistemas de IR. 🧠
Ayuda al sistema a aprender, adaptarse y mejorar los resultados cada vez que buscas información. Así es como funciona:
- Detección de patrones: el aprendizaje automático estudia en qué hacen clic los usuarios, qué ignoran y qué es lo que más tiempo dedican a leer. A continuación, utiliza este conocimiento para mostrarte los resultados más relevantes la próxima vez.
- Resultados de clasificación: el aprendizaje automático recupera información y también la clasifica. Eso significa que los mejores y más útiles resultados aparecen en la parte superior de tu búsqueda.
- Adaptación con el tiempo: con cada consulta, el aprendizaje automático mejora. Detecta tendencias, perfecciona su comprensión y maneja con facilidad incluso las preguntas más difíciles.
Por ejemplo, si hoy busca «los mejores portátiles económicos» e interactúa con resultados específicos, el aprendizaje automático sabrá dar prioridad a opciones similares cuando más adelante busque «portátiles asequibles». Al combinar la IA con el aprendizaje automático, los motores de búsqueda web pueden incluso predecir lo que podría necesitar a continuación.
Ahora hablemos del PLN. Ayuda a los sistemas de IR a comprender lo que quieres decir, no solo las palabras que escribes. En pocas palabras:
- Entiende el contexto: el PLN sabe que cuando dices «jaguar», puedes referirte al animal o al coche, y lo deduce basándose en el resto de tu consulta.
- Gestiona lenguaje complejo: tanto si su consulta es sencilla («vuelos baratos») como detallada («vuelos directos a Tokio por menos de 500 $»), el PLN se asegura de que el sistema comprenda y ofrezca los resultados adecuados.
Juntos, el NLP y el IR hacen que la búsqueda resulte intuitiva, como hablar con alguien que simplemente te entiende. Esto significa menos desplazamientos, menos frustración y más momentos del tipo «¡Vaya, esto es justo lo que necesitaba!».
El rol de ClickUp en la recuperación de información
ClickUp, la «aplicación para todo el trabajo», mejora la gestión de datos con modelos de IR.
Su IA integrada identifica y compara de forma única los resultados con la consulta del usuario, llevando la tecnología inteligente al siguiente nivel.
Y para endulzar el trato, la búsqueda conectada de ClickUp hace que sea muy fácil tener todo lo que necesitas «inmediatamente» al alcance de la mano. Eso significa:
- Busca cualquier cosa: ¿A quién le gusta rebuscar entre correos electrónicos y sistemas de gestión del conocimiento para localizar archivos importantes? Encuentra cualquier archivo en segundos utilizando la opción de búsqueda conectada. Mejor aún, busca archivos en todas tus aplicaciones conectadas y accede a todo en un solo lugar.
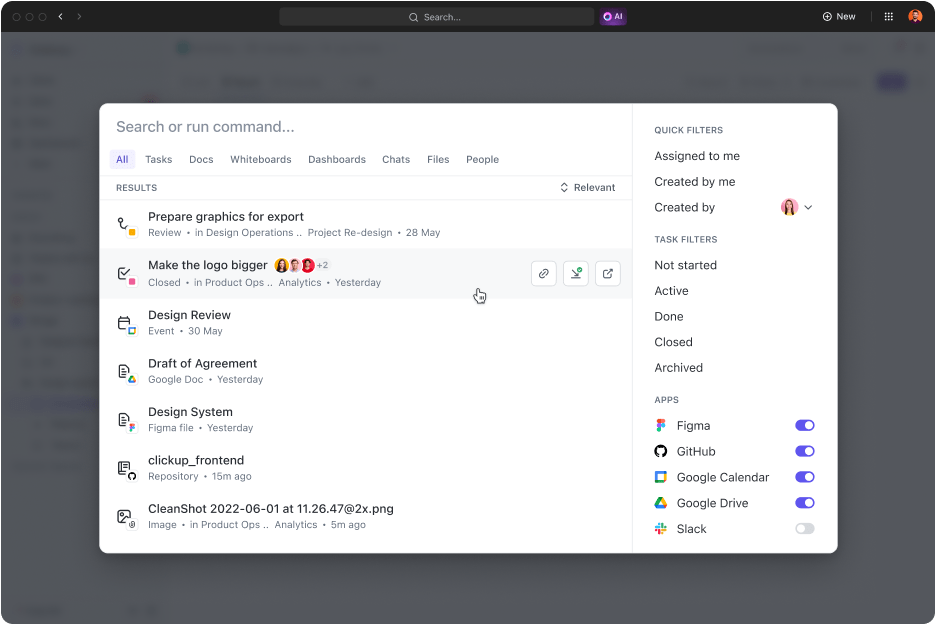
- Conecta tus aplicaciones favoritas: ClickUp cuenta con algunas de las mejores integraciones que amplían sus capacidades de búsqueda a aplicaciones de terceros como Google Drive, Slack, Dropbox, Figma y muchas más.

- Refina los resultados: cuanto más lo uses, mejor comprenderá lo que estás buscando y te ofrecerá resultados personalizados para ti.
- Busca a tu manera: accede a la búsqueda conectada y busca archivos PDF rápidamente desde cualquier lugar de tu entorno de trabajo. Por ejemplo, puedes iniciar una búsqueda desde el centro de comandos, la barra de acciones global o tu escritorio.
- Crea comandos de búsqueda personalizados: añade comandos de búsqueda personalizados, como atajos a enlaces, almacenamiento de texto para más tarde y mucho más, con el fin de optimizar tu flujo de trabajo.
Por si fuera poco, ¿y si existiera una forma de automatizar las tareas tediosas, trabajar más rápido y hacer más cosas en menos tiempo?
ClickUp Brain, el asistente de IA integrado, lo hace realidad. Es el asistente definitivo para la gestión de datos: inteligente, rápido y siempre dispuesto a ayudar.
En resumen 👇
- Centro de conocimiento todo en uno: No vuelvas a depender de los correos electrónicos y los mensajes para recibir actualizaciones. Pregunta cualquier cosa sobre tus tareas, documentos o personas y relájate mientras ClickUp Brain correlaciona respuestas basadas en el contexto de las aplicaciones internas y conectadas.

- Encuentre lo que necesita más rápido: ClickUp Brain clasifica los resultados de forma inteligente, como un sistema avanzado de IR. Prioriza los archivos relevantes, sugiere tareas relacionadas e incluso le ayuda a descubrir cargas de trabajo ocultas en sus datos.
- Automatice tareas: Brain automatiza la generación de informes o el seguimiento de plazos mediante sus herramientas de IA. Es un asistente personal que le libera tiempo para tomar decisiones más importantes, al tiempo que mantiene todo bajo control.
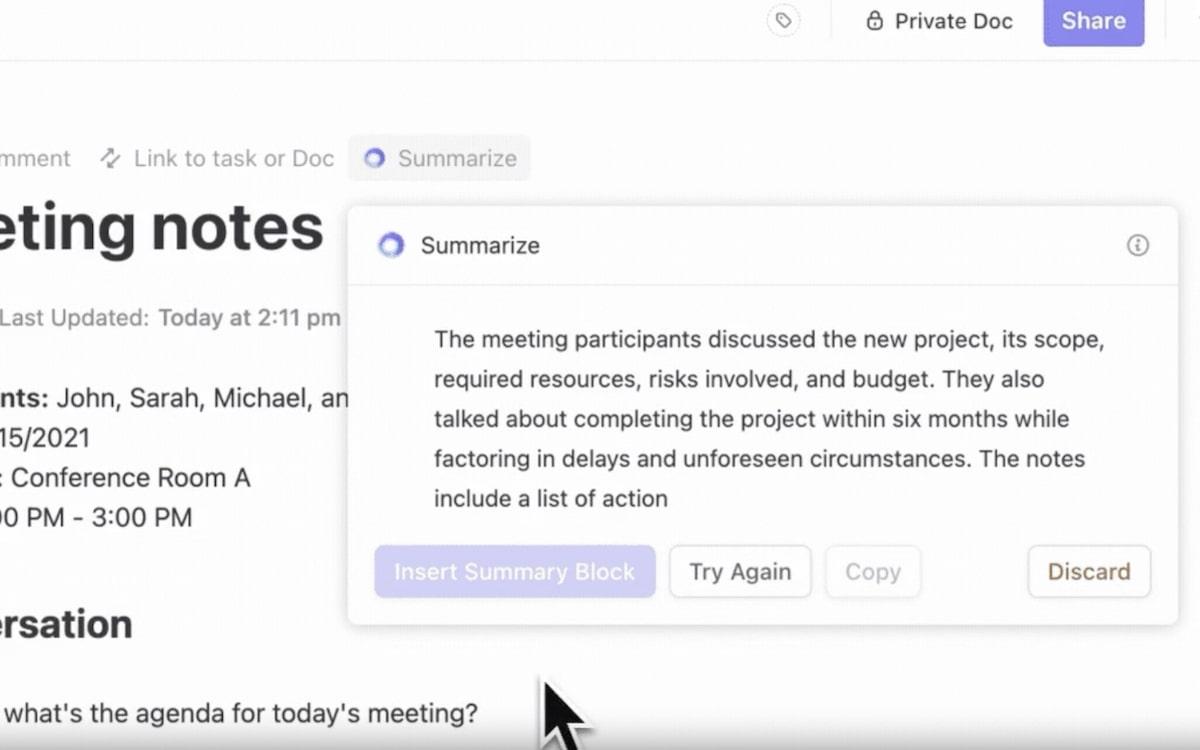
- Búsqueda contextual: gracias al procesamiento del lenguaje natural (NLP), entiende tu pregunta, incluso si tu consulta es compleja o vaga. Por ejemplo, al buscar «informe de ventas del primer trimestre», obtienes el informe exacto relacionado con tu tarea.
➡️ Más información: ¿Qué es un sistema de gestión del trabajo y cómo implementarlo?
Retos y perspectivas futuras en la recuperación de información
El mundo de la recuperación de información consiste en dar sentido a grandes cantidades de datos, pero incluso los sistemas de IR más avanzados se enfrentan a algunos obstáculos en el camino.
Exploremos los retos comunes y las interesantes tendencias que están dando forma al futuro de esta disciplina científica esencial:
- Privacidad y seguridad de los datos: para que un modelo de IR proporcione resultados objetivos, a menudo necesita acceder a datos confidenciales. Sin embargo, proteger los datos de los usuarios no es tarea fácil para los recursos de recuperación de información.
- Escalabilidad y rendimiento: A medida que los usuarios realizan búsquedas en grandes conjuntos de datos, el manejo de la creciente recopilación de contenido puede sobrecargar incluso los modelos de recuperación más robustos. El reto consiste en garantizar una recuperación eficiente sin comprometer la relevancia de los resultados de búsqueda.
- Calidad de los datos y comprensión contextual: las consultas ambiguas o los metadatos mal organizados pueden dar lugar a discrepancias, lo que dificulta que el sistema identifique de forma única la intención del usuario.
Tendencias emergentes y avances en la tecnología de IR.
A pesar de los numerosos obstáculos, los recientes avances tecnológicos nos han permitido crear sistemas más inteligentes y eficientes.
Los sistemas modernos de recuperación de información utilizan ahora métodos avanzados, como el análisis basado en gráficos, para interpretar los números, el texto y el contexto, los metadatos y las relaciones entre los puntos de datos.
¿Qué significa esto para los usuarios? Permite una recuperación de texto más precisa y un análisis detallado, especialmente en campos como la investigación y las industrias con gran volumen de datos.
En combinación con tecnologías web semánticas, se centra en las cadenas de búsqueda y la intención del usuario. Estos sistemas pueden ir más allá de las coincidencias literales y capturar documentos muy relevantes, incluso para consultas complicadas de los usuarios en el proceso de recuperación de información.
Por ejemplo, al buscar «beneficios del teletrabajo», se pueden obtener resultados relacionados con la productividad, la salud mental y el equilibrio entre la vida laboral y personal, todo ello gracias a que el sistema comprende las conexiones.
Recupere documentos rápidamente con la gestión de datos de ClickUp.
Buscar entre un sinfín de archivos, aplicaciones y herramientas para encontrar ese documento importante es agotador. Imagina intentar analizar los documentos recuperados como investigador, estudiante, profesional de TI o científico de datos, y que se convierta en una mezcolanza de sobrecarga de información.
Pero con ClickUp, nunca más volverás a perder tiempo buscando información.
Es la solución todo en uno que reúne todo tu trabajo en un solo lugar. Con funciones como Connected Search y ClickUp Brain, no importa dónde se encuentren tus datos: ClickUp te permite encontrarlos, gestionarlos y actuar sobre ellos fácilmente.
¿Por qué conformarse con «lo aceptable» cuando puede tener «lo increíble»? Pruebe ClickUp gratis y vea cómo transforma su flujo de trabajo en algo audaz, eficiente y francamente imparable.