

Sie sind Abteilungsleiter und suchen nach der perfekten Person für eine bestimmte Aufgabe. Angesichts der riesigen Datenmengen Ihres Unternehmens ist es fast unmöglich, den besten Kandidaten zu finden, insbesondere wenn Ihre Aufgabe zeitkritisch ist.
Außerdem: Wer hat schon die Zeit, alle zu fragen, ob sie über ausreichende Kenntnisse in einem bestimmten Bereich verfügen?
Was wäre, wenn Sie einfach ein System fragen könnten: „Wem wurde [Aufgabe] am häufigsten zugewiesen?“ und sofort eine genaue Antwort auf der Grundlage realer Daten erhalten würden? Genau das leisten Informationsabrufsysteme.
Diese Systeme durchsuchen Berge von Daten, um genau das zu finden, was Sie brauchen.
Übertragen Sie diese Idee nun auf eine globale Datenbank – ein IR-System organisiert riesige Datenmengen und hilft Ihnen, innerhalb von Sekunden die relevantesten Antworten zu finden. In diesem Leitfaden werden verschiedene Modelle zur Informationsgewinnung, ihre Funktionsweise und die Rolle von KI-Technologien in einem IR-System vorgestellt.
⏰ 60-Sekunden-Zusammenfassung
📌 Informationsabrufsysteme (IR-Systeme) helfen dabei, relevante Informationen aus großen Datensammlungen zu finden. Sie haben die Funktion, Daten zu durchsuchen, um das zu finden, was Sie benötigen.
📌 IR-Systeme bestehen aus folgenden Schlüsselkomponenten: Datenbank, Index, Suchschnittstelle, Abfrageprozessor, Abrufmodelle und Ranking-/Bewertungsmechanismen.
📌 Es werden vier Haupt-IR-Modelle verwendet: Boolesche (verwendet AND/OR/NOT-Operatoren), Vektorraum (stellt Dokumente als Vektoren dar), Probabilistisch (verwendet statistische Ansätze) und Term Interdependence (analysiert Beziehungen zwischen Begriffen).
📌 Maschinelles Lernen und natürliche Sprachverarbeitung verbessern IR-Systeme durch optimierte Mustererkennung, Bewertung des Ergebnisses und Kontextverständnis.
📌 Zu den größten Herausforderungen zählen Datenschutz, Skalierbarkeit und die Aufrechterhaltung der Datenqualität bei der Verarbeitung großer Datensätze.
Was ist Informationsgewinnung (IR)?
Informationsgewinnung (IR) bedeutet einfach das Auffinden der richtigen Informationen aus großen Datensammlungen wie digitalen Bibliotheken, Datenbanken oder Internetarchiven.
Es ist, als hätten Sie einen virtuellen Assistenten, der Berge von Daten durchforstet, um Ihnen genau das zu liefern, was Sie brauchen. *
Oberflächlich betrachtet gibt der Benutzer eine Abfrage ein, häufig unter Verwendung von Schlüsselwörtern oder Phrasen, um nach bestimmten Informationen zu suchen. Hinter den Kulissen analysieren fortschrittliche Techniken und Algorithmen die Zeichenfolgen und gleichen sie mit relevanten Daten ab.
Anstatt nur eine einzige Antwort zu identifizieren, liefern IR-Systeme mehrere Objekte – jedes mit unterschiedlichem Relevanzgrad für Ihre Abfrage. Außerdem werden sie überall eingesetzt und haben vielfältige Anwendungsmöglichkeiten (mehr dazu in Kürze 🔔).
💡Profi-Tipp: Sie suchen die kompetenteste Person für eine Aufgabe? Geben Sie bestimmte Begriffe wie „Analyse des Verkaufsberichts Q1 und Q2, zugewiesene Aufgaben” in das Informationsabrufsystem ein. Auf diese Weise werden irrelevante Daten schnell herausgefiltert und die Person ermittelt, die am häufigsten damit zu tun hatte.
Anwendungen von IR in verschiedenen Feldern
Von der Gesundheitsversorgung bis zum E-Commerce werden IR-Systeme in zahlreichen Feldern zur Verwaltung und Kategorisierung von Daten eingesetzt. Hier sind einige Beispiele 👇
Gesundheitswesen
Im Gesundheitswesen ist das Ergebnis, dass IR-Systeme Datenbanken mit Krankenakten und Forschungsarbeiten durchsuchen, um Ärzten und Forschern dabei zu helfen, die relevantesten Informationen zu finden. Dadurch beschleunigen sie die Diagnose von Krankheiten, identifizieren Behandlungsmöglichkeiten und finden anhand relevanter Rückmeldungen die relevantesten Studien.
Kundenservice
Techniken zur Informationsgewinnung machen den Kundensupport schneller und genauer. Beispielsweise können Mitarbeiter Benutzerabfragen wie „Rückerstattungsrichtlinie” in das System eines Unternehmens eingeben, um sofort Antworten abzurufen.
KI-Chatbots und Helpdesks, die auf Informationsgewinnung basieren, gehen noch einen Schritt weiter und bieten Echtzeitlösungen ohne menschliches Zutun. Deshalb werden Ihre Fragen oft innerhalb von Sekunden beantwortet!
E-Commerce-Plattformen
IR-Systeme machen Online-Shopping zum Kinderspiel. Sie analysieren Datenbanken und passen das Kundenverhalten an, um Produkte zu empfehlen, die Ihnen gefallen werden.
Amazon nutzt beispielsweise IR, um Ihnen auf Grundlage Ihres Suchverlaufs und Ihrer früheren Einkäufe Elemente vorzuschlagen, damit Sie genau das finden, was Sie brauchen.
Komponenten eines Informationsabrufsystems
Jetzt wissen wir, was Informationsgewinnung ist und wie sie funktioniert. Lassen Sie uns die wichtigsten Blöcke eines IR-Systems genauer betrachten. →
1. Datenbank
Alles beginnt mit der Datenbank. Dabei handelt es sich um eine Sammlung miteinander verbundener Datenpunkte, wie Textdokumente, E-Mails, Seiten, Bilder und Videos. Wenn Sie eine bestimmte Abfrage eingeben, durchsucht das IR-System diese Datenbankübereinstimmungen, um die für Ihre Bedürfnisse relevantesten Informationen abzurufen.
2. Indexer
Bevor das System etwas abrufen kann, organisiert der Index die Daten. Das ist vergleichbar mit der Erstellung eines Bibliothekskatalogs, um die Suche zu beschleunigen. Der Index verarbeitet Dokumente wie folgt:
- Tokenisierung: Aufteilung von Inhalten in kleinere Einheiten, beispielsweise durch Zerlegen von Sätzen in Wörter oder Phrasen (sogenannte Tokens).
- Stemming: Vereinfachung von Wörtern auf ihre Grundform (z. B. wird „running” zu „run”).
- Entfernen von Stoppwörtern: Überspringen Sie Füllwörter wie „und“, „oder“ und „der“, um sich auf die primäre Abfrage zu konzentrieren.
- Schlüsselwort-Extraktion: Identifizieren Sie die wichtigsten Schlüsselwörter im Text.
- Metadaten-Extraktion: Abrufen zusätzlicher Details wie Verfasser, Veröffentlichungsdatum oder Titel
3. Suchoberfläche
Die Suchoberfläche fungiert als Ihr Zugang zum IR-System. Hier geben Sie Ihre Abfrage mit einfachen Schlüsselwörtern oder detaillierteren Filtern ein. Die benutzerfreundliche Oberfläche sorgt dafür, dass Sie Ihre Anforderungen an den Informationszugriff einfach kommunizieren und die gewünschten relevanten Ergebnisse erhalten können.
4. Abfrageprozessor
Sobald Sie auf „Suchen” klicken, übernimmt der Abfrageprozessor. Er verfeinert Ihre Eingabe, indem er die in der Liste der Techniken des Indexers aufgeführten Techniken anwendet. Außerdem verarbeitet er boolische Operatoren wie „AND”, „OR” und „NOT”, um Ihre Abfrage intelligenter zu gestalten.
5. Suchmodelle
Hier geschieht das Wunder. Das System vergleicht Ihre eingegebene Abfrage mit den Dokumenten im Index mithilfe von Suchmodellen. Diese Methoden entscheiden, wie Ihre Abfrage mit den gespeicherten Daten abgeglichen wird. Einige der gängigen Namen sind:
- Boolesche Modelle
- Vektorraummodelle
- Probabilistische Modelle
- Und vieles mehr … (wird später erläutert)
6. Rangfolge und Bewertung
Sobald potenzielle Treffer gefunden wurden, ordnet das System diese nach ihrer Relevanz. Jedes Dokument erhält eine Bewertung anhand von Methoden wie TF-IDF (Term Frequency-Inverse Document Frequency) oder anderen Algorithmen. So wird sichergestellt, dass das relevanteste Ergebnis ganz oben angezeigt wird.
7. Präsentation oder Anzeige
Schließlich werden Ihnen die Ergebnisse präsentiert. In der Regel zeigt das System eine Rangliste von Textdokumenten mit zusätzlichen Features wie Ausschnitten, Filtern oder Sortieroptionen an. Dies erleichtert die Auswahl des relevantesten Dokuments. Die Anzahl der angezeigten Ergebnisse kann jedoch je nach Ihren Präferenzen, Ihrer Abfrage oder den Systemeinstellungen variieren.
🔍Wussten Sie schon?: Herkömmliche Informationsabrufsysteme stützten sich stark auf strukturierte Datenbanken und einfache Stichwortabgleiche. Das Ergebnis? Erhebliche Probleme hinsichtlich Relevanz und Personalisierung.
Damals haben moderne KI-Technologien die Textsuche durch folgende Maßnahmen revolutioniert:
- Maschinelles Lernen (ML): Hilft IR-Systemen, aus Mustern im Verhalten der Benutzer zu lernen und die Suchergebnisse im Laufe der Zeit zu verbessern.
- Tiefe neuronale Netze: Algorithmen, die unstrukturierte Daten (wie Bilder oder Videos) verarbeiten und komplexe Beziehungen aufdecken können.
- Natürliche Sprachverarbeitung (Natural Language Processing, NLP): Ermöglicht es Systemen, die Bedeutung und den Kontext von Abfragen zu verstehen, um die Bilderkennung und Stimmungsanalyse zu unterstützen, wodurch der Zugriff auf Informationen vielseitiger wird.
Modelle der Informationsgewinnung
Es gibt verschiedene IR-Systeme, die den Prozess der Suche nach relevanten Dokumenten optimieren. Sehen wir uns die am häufigsten verwendeten an:
1. Mengenlehre und boolesche Modelle
Das boolesche Modell ist eine der einfachsten Techniken zur Informationsgewinnung. So funktioniert es:
- UND: Ruft Dokumente ab, die alle Begriffe der Abfrage enthalten. Eine Suche nach „Katze UND Hund“ erwähnt beide Begriffe.
- ODER: Findet Dokumente, die einen beliebigen der Begriffe in der Abfrage enthalten. Bei „Katze ODER Hund“ werden Dokumente gefunden, die entweder Katze, Hund oder beide Begriffe erwähnen.
- NOT: Schließt Dokumente aus, die einen bestimmten Begriff enthalten. Beispiel: „Katze AND NOT Hund“ liefert Dokumente, die Katze erwähnen, aber nicht Hund.
Dieses Modell verwendet ein „Bag-of-Words”-Konzept, bei dem eine 2D-Matrix erstellt wird. In dieser Matrix:
- Spalten stehen für Dokumente
- Die Zeilen stehen für Begriffe aus der Abfrage.
Jeder Zelle wird ein Wert von 1 (wenn der Begriff vorhanden ist) oder 0 (wenn er nicht vorhanden ist) zugewiesen.

✅ Vorteile
- Leicht verständlich und einfach umzusetzen
- Ruft Dokumente ab, die genau mit den Begriffen der Abfrage übereinstimmen.
❌ Nachteile
- Boolesche Modelle ordnen Dokumente nicht nach Relevanz, sodass alle Ergebnisse als gleich wichtig behandelt werden.
- Der Fokus liegt auf exakten Begriffsabgleichen, sodass die Ergebnisse je nach Bedeutung oder Kontext der Abfrage variieren können.
2. Vektorraummodelle
Ein Vektorraummodell ist ein algebraisches Modell, das sowohl Dokumente als auch Abfragen als Vektoren in einem mehrdimensionalen Raum darstellt. So funktioniert es:
1. Es wird eine Begriff-Dokument-Matrix erstellt, in der die Zeilen Begriffe und die Spalten Dokumente darstellen.
2. Auf Grundlage der Suchbegriffe des Benutzers wird ein Abfragevektor gebildet.
3. Das System berechnet eine numerische Punktzahl anhand einer Kennzahl namens Kosinusähnlichkeit, die bestimmt, wie gut der Vektor der Abfrage mit den Dokumentvektoren übereinstimmt.

Als Informationsabrufsystem werden die Dokumente dann anhand dieser Bewertungen gereiht, wobei die am höchsten bewerteten Dokumente am relevantesten sind.
✅ Vorteile
- Ruft Elemente auch dann ab, wenn nur einige Begriffe übereinstimmen.
- Variationen in der Verwendung von Begriffen und der Dokumentlänge, Anpassung an verschiedene Dokumenttypen
❌ Nachteile
- Größere Vokabulare und Dokumentensammlungen machen Ähnlichkeitsberechnungen ressourcenintensiv.
3. Probabilistische Modelle
Dieses Modell verfolgt einen statistischen Ansatz und verwendet Wahrscheinlichkeiten, um die Relevanz eines Dokuments für die Abfrage zu schätzen. Es berücksichtigt:
- Häufigkeit von Begriffen im Dokument
- Wie oft treten Begriffe gemeinsam auf (Ko-Vorkommen)?
- Dokumentlänge und Gesamtzahl der Abfragen
Das System behandelt den Abfrageprozess als probabilistisches Ereignis und ordnet die gespeicherten Dokumente nach ihrer Relevanzwahrscheinlichkeit. Dieser Ansatz sorgt für mehr Tiefe, indem er Datenobjekte über das bloße Vorhandensein von Begriffen hinaus bewertet.
✅ Vorteile
- Passt sich gut an verschiedene Anwendungen an, darunter Zuverlässigkeitsanalysen und Bewertungen des Flow-Verhaltens.
❌ Nachteile
- Basiert auf Annahmen über Datenbeziehungen, was zu irreführenden Ergebnissen führen kann.
4. Modelle zur Begriffsabhängigkeit
Im Gegensatz zu einfacheren Modellen konzentrieren sich Term Interdependence Models (Modelle zur Begriffsabhängigkeit) nicht nur auf die Häufigkeit von Begriffen, sondern auch auf die Beziehungen zwischen ihnen. Diese Modelle analysieren, wie Wörter und Phrasen miteinander in Beziehung stehen, um die Genauigkeit der Ergebnisse zu verbessern.
Dabei kommen zwei Ansätze zum Einsatz:
- Immanenter Modus: Untersucht Beziehungen innerhalb des Textes selbst.
- Transzendenter Modus: Berücksichtigt externe Daten oder Kontexte, um Beziehungen abzuleiten.
Diese Methode ist besonders nützlich, um Bedeutungsnuancen wie Synonyme oder kontextspezifische Ausdrücke zu erfassen.
✅ Vorteile
- Erfasst sprachliche Nuancen durch Berücksichtigung von Begriffsbeziehungen
- Verbessert die Suchleistung durch Verständnis der Abhängigkeiten zwischen Begriffen und des Kontexts.
❌ Nachteile
- Erfordert umfangreiche Daten, um Begriffsbeziehungen genau zu modellieren, die möglicherweise nicht immer verfügbar sind.
Das war's! Dies sind einige der häufig verwendeten Informationsabrufsysteme mit ihren jeweiligen Vor- und Nachteilen.
➡️ Weiterlesen: 4 Spotlight-Suchalternativen und -Konkurrenten
Informationsabruf vs. Datenabfrage
Obwohl diese beiden Begriffe fast gleich erscheinen, funktionieren sie unterschiedlich. Lassen Sie uns also IR und Datenabfrage nebeneinander stellen, um zu sehen, wie sie sich in Bezug auf Zweck, Anwendungsfälle und Beispiele unterscheiden:
| Aspekt | Informationsgewinnung (IR) | Daten-Abfrage |
| Definition | Funktioniert wie eine Suchmaschine, die unzählige Daten durchsucht, um Ihnen die relevantesten Ergebnisse zu liefern. | Stellen Sie sich das so vor, als würden Sie einer Datenbank eine bestimmte Frage in einer Sprache stellen, die sie versteht (wie SQL). |
| Ziel/Zweck | Hilft Ihnen, genaue und relevante Informationen oder Ressourcen in Suchmaschinen zu finden – schnell und einfach. | Ruft exakte Daten ab, damit Sie Zahlen analysieren, aktualisieren oder berechnen können. |
| Anwendungsfälle | Verwendet für Websuchen, E-Commerce-Empfehlungen, digitale Bibliotheken, Einblicke in das Gesundheitswesen und vieles mehr. | Ideal für Aufgaben wie die Verwaltung von Lagerbeständen im E-Commerce, die Analyse von Finanzen und die Optimierung von Lieferketten. |
| Beispiel | Suche nach „Beste Laptops zwischen 800 und 1000 Dollar” auf Google, um Ranglistenergebnisse zu erhalten | Abfrage Ihres Inventarsystems mit „SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000”, um zu sehen, was auf Lager ist. |
Die Rolle von maschinellem Lernen und NLP bei der Informationsgewinnung
IR-Systeme sind wie Schatzsucher für Daten – sie durchsuchen riesige Informationsmengen, um genau das zu finden, wonach Sie suchen. Wenn jedoch ML und NLP zusammenkommen, werden diese Systeme intelligenter, schneller und wesentlich genauer.
Stellen Sie sich ML als das Gehirn hinter IR-Systemen vor. 🧠
Das System lernt, passt sich an und verbessert die Ergebnisse bei jeder Informationssuche. So funktioniert es:
- Muster erkennen: ML untersucht, worauf Benutzer klicken, was sie ignorieren und womit sie sich am längsten beschäftigen. Diese Erkenntnisse werden dann genutzt, um Ihnen beim nächsten Mal die relevantesten Ergebnisse anzuzeigen.
- Ranking-Ergebnisse: ML ruft Informationen ab und ordnet sie auch nach ihrer Relevanz. Das bedeutet, dass die besten und nützlichsten Ergebnisse ganz oben in Ihrer Suche angezeigt werden.
- Anpassung an die Zeit: Mit jeder Abfrage wird ML besser. Es erkennt Trends, verfeinert sein Verständnis und bewältigt selbst die kniffligsten Fragen mühelos.
Als Beispiel: Wenn Sie heute nach „günstigen Laptops“ suchen und mit bestimmten Ergebnissen interagieren, weiß ML, dass es ähnliche Optionen priorisieren muss, wenn Sie später nach „erschwinglichen Notebooks“ suchen. Durch die Kombination von KI und ML können Web-Suchmaschinen sogar vorhersagen, was Sie als Nächstes benötigen könnten.
Kommen wir nun zu NLP. Es hilft IR-Systemen dabei, nicht nur die von Ihnen eingegebenen Wörter zu verstehen, sondern auch, was Sie damit meinen. Einfach ausgedrückt:
- Es versteht den Kontext: NLP weiß, dass Sie mit „Jaguar“ entweder das Tier oder das Auto meinen könnten – und es findet dies anhand des restlichen Teils Ihrer Abfrage heraus.
- Es verarbeitet komplexe Sprache: Unabhängig davon, ob Ihre Abfrage einfach („günstige Flüge“) oder detailliert („Direktflüge nach Tokio unter 500 Dollar“) ist, sorgt NLP dafür, dass das System die richtigen Ergebnisse versteht und liefert.
Zusammen sorgen NLP und IR dafür, dass die Suche intuitiv ist, als würde man mit jemandem sprechen, der einen einfach versteht. Das bedeutet weniger Scrollen, weniger Frust und mehr Momente, in denen man denkt: „Wow, das ist genau das, was ich gebraucht habe!“.
Die Rolle von ClickUp bei der Informationsbeschaffung
ClickUp, die „Alles-App für die Arbeit“, verbessert das Datenmanagement mit IR-Modellen.
Die integrierte KI identifiziert und gleicht Ergebnisse auf einzigartige Weise mit der Abfrage eines Benutzers ab und hebt intelligente Technologie damit auf die nächste Stufe.
Und um das Ganze noch zu versüßen, macht es Ihnen die Connected Search von ClickUp kinderleicht, alles, was Sie brauchen, „sofort“ zur Hand zu haben. Das bedeutet:
- Alles suchen: Wer hat schon Lust, E-Mails und Wissensmanagementsysteme zu durchforsten, um wichtige Dateien zu finden? Mit der Option „Connected Search” finden Sie jede Datei in Sekundenschnelle. Und noch besser: Sie können Dateien in all Ihren verbundenen Apps suchen und haben Zugriff auf alles an einem Ort.
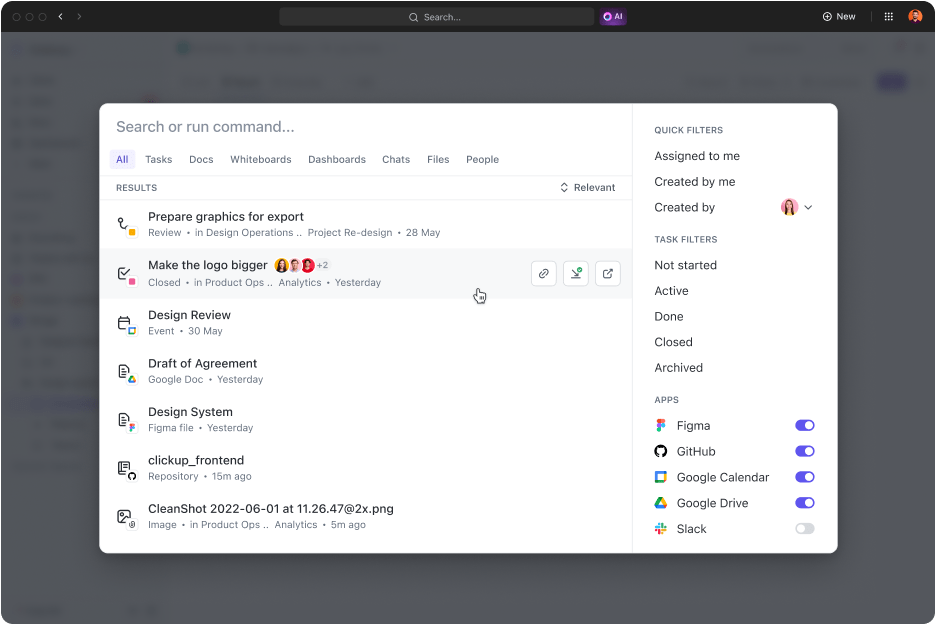
- Verbinden Sie Ihre bevorzugten Apps: ClickUp verfügt über einige der besten Integrationen, die seine Suchfunktionen auf Drittanbieter-Apps wie Google Drive, Slack, Dropbox, Figma und andere ausweiten.

- Ergebnisse verfeinern: Je häufiger Sie die Funktion nutzen, desto besser versteht sie, wonach Sie suchen, und liefert Ihnen maßgeschneiderte Ergebnisse.
- Suchen Sie auf Ihre Weise: Greifen Sie auf die vernetzte Suche zu und durchsuchen Sie PDF-Dateien schnell von überall in Ihrem Workspace. Sie können beispielsweise eine Suche über das Command-Center, die globale Aktionsleiste oder Ihren Desktop starten.
- Erstellen Sie benutzerdefinierte Suchbefehle: Fügen Sie benutzerdefinierte Suchbefehle wie Verknüpfungen zu Links, Speichern von Text für später und mehr hinzu, um Ihren Workflow zu optimieren.
Und was wäre, wenn es eine Möglichkeit gäbe, mühsame Aufgaben zu automatisieren, schneller zu arbeiten und in kürzester Zeit mehr zu erledigen?
ClickUp Brain, der integrierte KI-Assistent, macht dies für Sie möglich. Er ist der ultimative Assistent für das Datenmanagement – intelligent, schnell und immer bereit zu helfen.
Kurz zusammengefasst 👇
- All-in-One-Wissenshub: Verlassen Sie sich nie wieder auf E-Mails und Nachrichten, um Updates zu erhalten. Stellen Sie Fragen zu Ihren Aufgaben, Dokumenten oder Personen und lehnen Sie sich zurück, während ClickUp Brain anhand des Kontexts aus internen und verbundenen Apps Antworten ermittelt.

- Finden Sie schneller, was Sie brauchen: ClickUp Brain ordnet Ergebnisse intelligent wie ein fortschrittliches IR-System. Es priorisiert relevante Dateien, schlägt verwandte Aufgaben vor und hilft Ihnen sogar dabei, versteckte Workloads in Ihren Daten aufzudecken.
- Aufgaben automatisieren: Brain automatisiert die Berichterstellung oder die Nachverfolgung von Terminen mithilfe seiner KI-Tools. Es ist ein persönlicher Assistent, der Ihnen Zeit für wichtigere Entscheidungen verschafft und gleichzeitig dafür sorgt, dass alles nach Plan läuft.
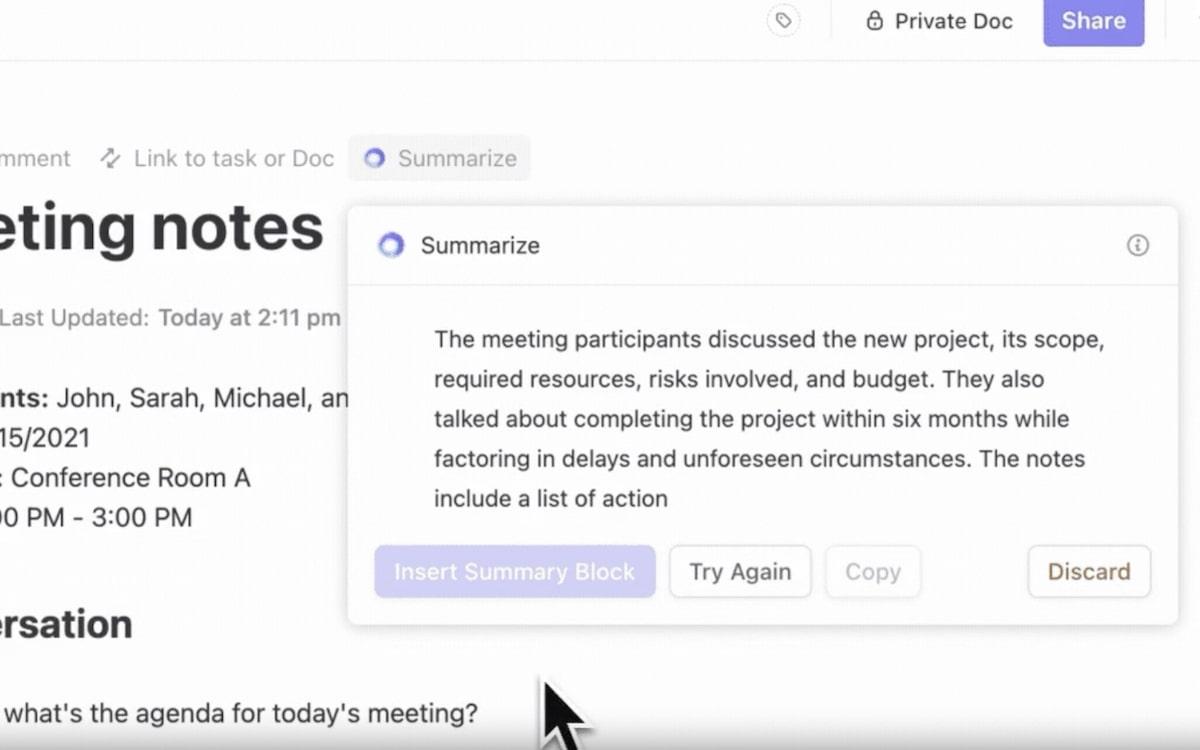
- Kontextsensitive Suche: Dank NLP versteht das System Ihre Frage – selbst wenn Ihre Abfrage komplex oder vage ist. Beispiel: Wenn Sie beispielsweise nach „Bericht über den Umsatz im ersten Quartal” suchen, erhalten Sie den genauen Bericht, der mit Ihrer Aufgabe verknüpft ist.
Herausforderungen und zukünftige Entwicklungen in der Informationsbeschaffung
In der Welt der Informationsgewinnung geht es darum, riesige Datenmengen sinnvoll zu verarbeiten, aber selbst die fortschrittlichsten IR-Systeme stoßen dabei auf einige Hindernisse.
Lassen Sie uns die gemeinsamen Herausforderungen und spannenden Trends erkunden, die die Form der Zukunft dieser wichtigen wissenschaftlichen Disziplin bestimmen:
- Datenschutz und Sicherheit: Damit ein IR-Modell sachliche Ergebnisse liefern kann, benötigt es oft Zugriff auf sensible Daten. Der Schutz von Benutzerdaten ist jedoch für Ressourcen zur Informationsgewinnung keine leichte Aufgabe.
- Skalierbarkeit und Leistung: Wenn Benutzer große Datensätze durchsuchen, kann die Verarbeitung der ständig wachsenden Menge an Inhalt selbst die robustesten Abrufmodelle überfordern. Die Herausforderung besteht darin, einen effizienten Abruf zu gewährleisten, ohne die Relevanz der Suchergebnisse zu beeinträchtigen.
- Datenqualität und Kontextverständnis: Mehrdeutige Abfragen oder schlecht organisierte Metadaten können zu Fehlern führen, wodurch es für das System schwierig wird, die Absicht des Benutzers eindeutig zu identifizieren.
Neue Trends und Fortschritte in der IR-Technologie
Trotz zahlreicher Hindernisse haben uns die jüngsten technologischen Fortschritte in die Lage versetzt, intelligentere und effizientere Systeme zu entwickeln.
Moderne Informationsabrufsysteme verwenden heute fortschrittliche Methoden wie graphbasierte Analysen, um Nummern, Texte und Kontexte, Metadaten und Beziehungen zwischen Datenpunkten zu interpretieren.
Was bedeutet das für die Benutzer? Es ermöglicht eine präzisere Textsuche und detaillierte Analysen, insbesondere in Feldern wie Forschung und datenintensiven Branchen.
In Kombination mit semantischen Webtechnologien konzentriert es sich auf Suchzeichenfolgen und die Absicht des Benutzers. Diese Systeme können über wörtliche Übereinstimmungen hinausgehen und selbst bei komplizierten Abfragen im Informationsabrufprozess hochrelevante Dokumente abrufen.
Als Beispiel suchen Sie beispielsweise nach „Vorteile der Remote-Arbeit” und erhalten Ergebnisse zu Produktivität, psychischer Gesundheit und Work-Life-Balance – weil das System die Verbindungen versteht.
Schnelles Abrufen von Dokumenten mit der Datenverwaltung von ClickUp
Es ist anstrengend, endlose Dateien, Apps und tools zu durchforsten, um dieses eine wichtige Dokument zu finden. Stellen Sie sich vor, Sie versuchen als Forscher, Student, IT-Experte oder Datenwissenschaftler, die gefundenen Dokumente zu analysieren – und es entsteht nur ein Durcheinander von Informationen.
Mit ClickUp verschwenden Sie nie wieder Zeit mit der Suche nach Informationen.
Es ist die All-in-One-Lösung, die Ihre Arbeit an einem Ort zusammenführt. Mit Features wie Connected Search und ClickUp Brain spielt es keine Rolle, wo sich Ihre Daten befinden – ClickUp macht es Ihnen leicht, sie zu finden, zu verwalten und zu bearbeiten.
Warum sich mit „ganz okay” zufrieden geben, wenn Sie „fantastisch” haben können? Probieren Sie ClickUp kostenlos aus und erleben Sie, wie es Ihren Workflow in etwas Mutiges, Effizientes und geradezu Unaufhaltsames verwandelt!