
Các dự án đào tạo AI hiếm khi thất bại ở cấp độ mô hình. Chúng gặp khó khăn khi các thí nghiệm, tài liệu và cập nhật cho các bên liên quan bị phân tán trên quá nhiều công cụ.
Hướng dẫn này sẽ hướng dẫn bạn qua quá trình đào tạo mô hình với Databricks DBRX—một mô hình ngôn ngữ lớn (LLM) có hiệu suất tính toán cao gấp đôi so với các mô hình hàng đầu khác—đồng thời giữ cho công việc xung quanh nó được tổ chức gọn gàng trong ClickUp.
Từ thiết lập và tinh chỉnh đến tài liệu và cập nhật giữa các nhóm, bạn sẽ thấy cách một không gian làm việc duy nhất, tích hợp giúp loại bỏ sự phân tán thông tin và giữ cho nhóm tập trung vào việc xây dựng, không phải tìm kiếm. 🛠
DBRX là gì?
DBRX là một mô hình ngôn ngữ lớn (LLM) mạnh mẽ, mã nguồn mở, được thiết kế riêng cho việc đào tạo và suy luận mô hình AI doanh nghiệp. Vì nó là mã nguồn mở theo Giấy phép Mô hình Mở Databricks, nhóm của bạn có quyền truy cập đầy đủ vào trọng số và kiến trúc của mô hình, cho phép bạn kiểm tra, điều chỉnh và triển khai nó theo điều kiện của riêng mình.
Nó có hai phiên bản: DBRX Base dành cho đào tạo sâu và DBRX Instruct dành cho các công việc tuân thủ hướng dẫn ngay lập tức.
Kiến trúc DBRX và thiết kế hỗn hợp chuyên gia
DBRX giải quyết các công việc bằng kiến trúc Mixture-of-Experts (MoE). Khác với các mô hình ngôn ngữ lớn truyền thống sử dụng tất cả hàng tỷ tham số của mình cho mỗi tính toán, DBRX chỉ kích hoạt một phần nhỏ của tổng số tham số (các chuyên gia liên quan nhất) cho bất kỳ công việc nào.
Hãy tưởng tượng nó như một nhóm chuyên gia chuyên môn; thay vì mọi người đều tham gia vào mọi công việc, hệ thống sẽ tự động phân công từng công việc đến những tham số chuyên môn phù hợp nhất.
Không chỉ giúp giảm thời gian phản hồi, mà còn mang lại hiệu suất và kết quả hàng đầu đồng thời giảm đáng kể chi phí tính toán.
Dưới đây là cái nhìn tổng quan về các thông số kỹ thuật chính của nó:
- Tổng số tham số: 132 tỷ trên tất cả các chuyên gia
- Tham số hoạt động: 36B mỗi lần truyền dữ liệu
- Số chuyên gia: 16 tổng cộng (MoE Top-4 routing), với 4 chuyên gia hoạt động cho bất kỳ token nào.
- Cửa sổ bối cảnh: 32K token
Dữ liệu đào tạo và thông số token của DBRX
Hiệu suất của một mô hình ngôn ngữ lớn (LLM) chỉ tốt như dữ liệu mà nó được đào tạo. DBRX đã được đào tạo trước trên một tập dữ liệu khổng lồ gồm 12 nghìn tỷ token, được nhóm Databricks tuyển chọn cẩn thận bằng các công cụ xử lý dữ liệu tiên tiến của họ. Chính vì vậy, nó đã thể hiện hiệu suất mạnh mẽ trên các tiêu chuẩn đánh giá ngành.
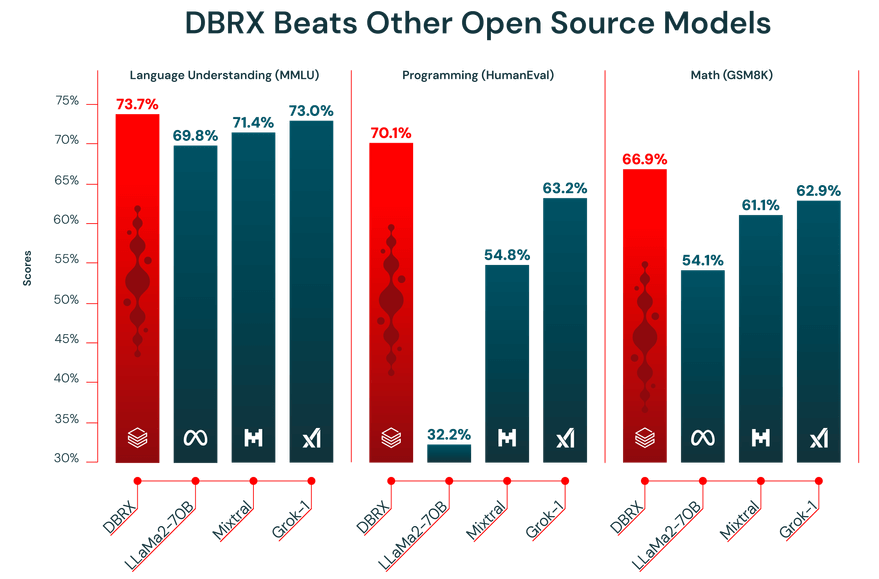
Ngoài ra, DBRX có tính năng cửa sổ ngữ cảnh 32.000 token. Đây là lượng văn bản mà mô hình có thể xem xét cùng một lúc. Cửa sổ ngữ cảnh lớn rất hữu ích cho các công việc phức tạp như tóm tắt báo cáo dài, phân tích tài liệu pháp lý dài dòng hoặc xây dựng hệ thống tạo sinh được tăng cường bằng truy xuất (RAG) nâng cao, vì nó cho phép mô hình duy trì ngữ cảnh mà không bị cắt ngắn hoặc quên thông tin.
🎥 Xem video này để thấy cách phối hợp dự án hiệu quả có thể biến đổi quy trình đào tạo AI của bạn và loại bỏ sự bất tiện khi chuyển đổi giữa các công cụ không kết nối. 👇🏽
Cách truy cập và cài đặt DBRX
DBRX cung cấp hai phương thức truy cập chính, cả hai đều cho phép truy cập đầy đủ vào trọng số mô hình dưới điều khoản thương mại linh hoạt. Bạn có thể sử dụng Hugging Face để có sự linh hoạt tối đa hoặc truy cập trực tiếp qua Databricks để có trải nghiệm tích hợp hơn.
Truy cập DBRX thông qua Hugging Face
Đối với các nhóm coi trọng tính linh hoạt và đã quen thuộc với hệ sinh thái Hugging Face, truy cập DBRX thông qua Hub là lựa chọn lý tưởng. Điều này cho phép bạn tích hợp mô hình vào các quy trình làm việc dựa trên transformers hiện có của mình.
Dưới đây là cách bắt đầu:
- Tạo hoặc đăng nhập vào tài khoản Hugging Face của bạn.
- Truy cập thẻ mô hình DBRX trên Hub và chấp nhận các điều khoản cấp phép.
- Cài đặt thư viện Transformers cùng với các phụ thuộc cần thiết như Accelerate.
- Sử dụng lớp AutoModelForCausalLM trong script Python của bạn để tải mô hình DBRX.
- Cấu hình đường ống suy luận của bạn, lưu ý rằng DBRX yêu cầu bộ nhớ GPU (VRAM) đáng kể để hoạt động hiệu quả.
📖 Đọc thêm: Cách cấu hình nhiệt độ LLM
Truy cập DBRX thông qua Databricks
Nếu nhóm của bạn đã sử dụng Databricks cho công việc kỹ thuật dữ liệu hoặc học máy, việc truy cập DBRX thông qua nền tảng này là cách dễ dàng nhất. Điều này loại bỏ các rào cản thiết lập và cung cấp cho bạn tất cả các công cụ cần thiết cho MLOps ngay tại nơi bạn đang thực hiện công việc.
Thực hiện các bước sau trong không gian làm việc Databricks của bạn để bắt đầu:
- Truy cập vào Model Garden hoặc phần Mosaic AI.
- Lựa chọn DBRX Base hoặc DBRX Instruct tùy theo nhu cầu của bạn.
- Cấu hình điểm cuối phục vụ cho truy cập API hoặc cài đặt môi trường notebook cho sử dụng tương tác.
- Bắt đầu thử nghiệm suy luận với các mẫu prompt để đảm bảo mọi thứ hoạt động chính xác trước khi mở rộng quy mô đào tạo hoặc triển khai mô hình AI của bạn.
Cách tiếp cận này cho phép bạn truy cập liền mạch vào các công cụ như MLflow để theo dõi thí nghiệm và Unity Catalog để quản lý mô hình.
📮 ClickUp Insight: Trung bình, mỗi chuyên gia dành hơn 30 phút mỗi ngày để tìm kiếm thông tin liên quan đến công việc—đó là hơn 120 giờ mỗi năm bị lãng phí khi phải lục lọi email, các chủ đề trên Slack và các tệp tin rải rác.
Một trợ lý AI thông minh được tích hợp vào không gian làm việc của bạn có thể thay đổi điều đó. Hãy gặp ClickUp Brain.
Nó cung cấp thông tin và câu trả lời tức thì bằng cách hiển thị các tài liệu, cuộc hội thoại và chi tiết công việc phù hợp chỉ trong vài giây — giúp bạn ngừng tìm kiếm và bắt đầu công việc.
Cách tinh chỉnh DBRX và đào tạo các mô hình AI tùy chỉnh
Một mô hình sẵn có, dù mạnh mẽ đến đâu, cũng sẽ không bao giờ hiểu được những đặc điểm riêng biệt của kinh doanh của bạn. Vì DBRX là mã nguồn mở, bạn có thể tinh chỉnh nó để tạo ra một mô hình tùy chỉnh phù hợp với ngôn ngữ của công ty bạn hoặc thực hiện một công việc cụ thể mà bạn mong muốn.
Dưới đây là ba cách phổ biến để thực hiện việc cần làm này:
1. Tinh chỉnh DBRX bằng các bộ dữ liệu của Hugging Face
Đối với các nhóm mới bắt đầu hoặc đang thực hiện các công việc thông thường, các bộ dữ liệu công khai từ Hugging Face Hub là một nguồn tài nguyên tuyệt vời. Chúng đã được định dạng sẵn và dễ dàng tải lên, nghĩa là bạn không cần phải mất hàng giờ để chuẩn bị dữ liệu.
Quy trình này khá đơn giản:
- Tìm bộ dữ liệu trên Hub phù hợp với công việc của bạn (ví dụ: tuân thủ hướng dẫn, tóm tắt).
- Tải dữ liệu bằng thư viện dữ liệu.
- Đảm bảo dữ liệu được định dạng thành các cặp câu hỏi-trả lời.
- Cấu hình kịch bản đào tạo của bạn với các siêu tham số như tốc độ học và kích thước lô.
- Khởi chạy công việc đào tạo, đảm bảo lưu trữ các điểm kiểm tra kỳ.
- Đánh giá mô hình được tinh chỉnh trên tập dữ liệu kiểm tra được giữ lại để đo lường sự cải thiện.
2. Tinh chỉnh DBRX với tập dữ liệu địa phương
Bạn thường sẽ đạt được kết quả tốt nhất bằng cách tinh chỉnh mô hình với dữ liệu riêng của công ty. Điều này cho phép bạn dạy mô hình các thuật ngữ, phong cách và kiến thức chuyên môn cụ thể của công ty. Tuy nhiên, hãy nhớ rằng việc này chỉ mang lại hiệu quả nếu dữ liệu của bạn sạch sẽ, được chuẩn bị kỹ lưỡng và có đủ khối lượng.
Thực hiện các bước sau để chuẩn bị dữ liệu nội bộ của bạn:
- Thu thập dữ liệu: Thu thập các ví dụ chất lượng cao từ các wiki nội bộ, tài liệu và cơ sở dữ liệu của bạn.
- Chuyển đổi định dạng: Tổ chức dữ liệu của bạn thành định dạng câu lệnh-phản hồi nhất quán, thường dưới dạng các dòng JSON.
- Lọc chất lượng: Loại bỏ các ví dụ chất lượng thấp, trùng lặp hoặc không liên quan.
- Phân chia dữ liệu kiểm tra: Tách ra một phần nhỏ dữ liệu (thường là 10-15%) để đánh giá hiệu suất của mô hình.
- Kiểm tra bảo mật: Xóa hoặc che giấu bất kỳ thông tin nhận dạng cá nhân (PII) hoặc dữ liệu nhạy cảm nào.
3. Tinh chỉnh DBRX với StreamingDataset
Nếu tập dữ liệu của bạn quá lớn để vừa với bộ nhớ của máy tính, đừng lo lắng, bạn có thể sử dụng thư viện Streaming Dataset của Databricks. Thư viện này cho phép bạn truyền dữ liệu trực tiếp từ lưu trữ đám mây trong quá trình đào tạo mô hình, thay vì tải toàn bộ dữ liệu vào bộ nhớ cùng một lúc.
Dưới đây là việc cần làm:
- Chuẩn bị dữ liệu: Làm sạch và cấu trúc dữ liệu đào tạo của bạn, sau đó lưu trữ nó dưới định dạng có thể truyền tải như JSONL hoặc CSV trên lưu trữ đám mây.
- Chuyển đổi định dạng dữ liệu phát trực tuyến: Chuyển đổi tập dữ liệu của bạn sang định dạng thân thiện với phát trực tuyến, chẳng hạn như Mosaic Data Shard (MDS), để có thể đọc hiệu quả trong quá trình đào tạo.
- Thiết lập trình tải dữ liệu đào tạo: Cấu hình trình tải dữ liệu đào tạo để trỏ đến bộ dữ liệu từ xa và định nghĩa bộ nhớ đệm cục bộ cho việc lưu trữ dữ liệu tạm thời.
- Khởi tạo mô hình: Bắt đầu quá trình tinh chỉnh DBRX bằng cách sử dụng khung đào tạo hỗ trợ StreamingDataset, chẳng hạn như LLM Foundry.
- Đào tạo dựa trên luồng dữ liệu: Chạy công việc đào tạo trong khi dữ liệu được truyền vào theo từng lô trong quá trình đào tạo, thay vì tải toàn bộ vào bộ nhớ.
- Điểm kiểm tra và khôi phục: Tiếp tục đào tạo một cách liền mạch nếu quá trình đào tạo bị gián đoạn, mà không cần sao chép hoặc bỏ qua dữ liệu.
- Đánh giá và triển khai: Xác minh hiệu suất của mô hình đã được tinh chỉnh và triển khai nó bằng cách sử dụng thiết lập phục vụ hoặc suy luận ưa thích của bạn.
💡Mẹo chuyên nghiệp: Thay vì xây dựng kế hoạch đào tạo DBRX từ đầu, hãy bắt đầu với mẫu AI và Machine Learning Dự án Roadmap Template của ClickUp và điều chỉnh nó theo nhu cầu của nhóm. Mẫu này cung cấp cấu trúc rõ ràng cho việc lập kế hoạch tập dữ liệu, giai đoạn đào tạo, đánh giá và triển khai, giúp bạn tập trung vào việc tổ chức công việc thay vì xây dựng quy trình làm việc.
Các trường hợp sử dụng DBRX cho việc đào tạo mô hình AI
Có một mô hình mạnh mẽ là một chuyện, nhưng biết chính xác nơi nó phát huy hiệu quả lại là chuyện khác.
Khi bạn không có cái nhìn rõ ràng về điểm mạnh của một mô hình, dễ dàng lãng phí thời gian và tài nguyên để cố gắng áp dụng nó vào những tình huống mà nó không phù hợp. Điều này dẫn đến kết quả kém và sự thất vọng.
Kiến trúc độc đáo và dữ liệu đào tạo của DBRX khiến nó đặc biệt phù hợp cho nhiều trường hợp sử dụng quan trọng trong doanh nghiệp. Hiểu rõ những ưu điểm này giúp bạn điều chỉnh mô hình phù hợp với mục tiêu kinh doanh và tối đa hóa lợi nhuận đầu tư.
Sinh văn bản và tạo/lập nội dung
DBRX Instruct được tối ưu hóa để tuân thủ hướng dẫn và tạo ra văn bản chất lượng cao. Điều này khiến nó trở thành công cụ mạnh mẽ để tự động hóa một phạm vi rộng của các công việc liên quan đến nội dung. Cửa sổ ngữ cảnh lớn của nó là một lợi thế đáng kể, cho phép xử lý các tài liệu dài mà không mất mạch.
Bạn có thể sử dụng nó cho:
- Tài liệu kỹ thuật: Tạo và hoàn thiện tài liệu sản phẩm, tài liệu tham khảo API và hướng dẫn cho người dùng.
- Nội dung tiếp thị: Soạn thảo bài đăng blog, bản tin email và cập nhật trên mạng xã hội.
- Tạo báo cáo: Tóm tắt các kết quả phân tích dữ liệu phức tạp và tạo các bản tóm tắt điều hành ngắn gọn.
- Dịch thuật và địa phương hóa: Thích ứng nội dung hiện có cho các thị trường và đối tượng mới.
Các công việc tạo mã và gỡ lỗi
Một phần lớn dữ liệu đào tạo của DBRX bao gồm mã nguồn, giúp nó trở thành một công cụ hỗ trợ mạnh mẽ cho các nhà phát triển. Nó có thể giúp đẩy nhanh chu kỳ phát triển bằng cách tự động hóa các công việc lập trình lặp đi lặp lại và hỗ trợ giải quyết các vấn đề phức tạp.
Dưới đây là một số cách mà nhóm kỹ thuật của bạn có thể tận dụng nó:
- Hoàn thành mã: Tự động tạo thân hàm từ các bình luận hoặc docstring.
- Phát hiện lỗi: Phân tích các đoạn mã để xác định các lỗi tiềm ẩn hoặc lỗ hổng logic.
- Giải thích mã nguồn: Dịch các thuật toán phức tạp hoặc mã nguồn cũ sang tiếng Anh thông thường.
- Tạo bài kiểm tra: Tạo các bài kiểm tra đơn vị dựa trên chữ ký hàm và hành vi mong đợi của hàm.
RAG và các ứng dụng có bối cảnh dài
Retrieval-Augmented Generation (RAG) là một kỹ thuật mạnh mẽ giúp các phản hồi của mô hình dựa trên dữ liệu riêng tư của công ty bạn. Tuy nhiên, các hệ thống RAG thường gặp khó khăn với các mô hình có cửa sổ ngữ cảnh nhỏ, buộc phải chia nhỏ dữ liệu một cách mạnh mẽ, có thể làm mất đi ngữ cảnh quan trọng. Cửa sổ ngữ cảnh 32K của DBRX là nền tảng tuyệt vời cho các ứng dụng RAG mạnh mẽ.
Điều này cho phép bạn xây dựng các công cụ nội bộ mạnh mẽ, chẳng hạn như:
- Tìm kiếm doanh nghiệp: Tạo chatbot trả lời câu hỏi của nhân viên bằng cách sử dụng cơ sở kiến thức nội bộ của bạn.
- Hỗ trợ khách hàng: Tạo một chatbot có thể tạo ra các phản hồi hỗ trợ dựa trên tài liệu sản phẩm của bạn.
- Hỗ trợ nghiên cứu: Phát triển một công cụ có thể tổng hợp thông tin từ hàng trăm trang tài liệu nghiên cứu.
- Kiểm tra tuân thủ: Tự động xác minh nội dung tiếp thị so với các hướng dẫn thương hiệu nội bộ hoặc tài liệu quy định.
Cách tích hợp đào tạo DBRX vào quy trình làm việc của nhóm
Một dự án đào tạo mô hình AI thành công không chỉ đơn thuần là về mã nguồn và tài nguyên tính toán. Đó là nỗ lực hợp tác giữa các kỹ sư machine learning, nhà khoa học dữ liệu, quản lý sản phẩm và các bên liên quan.
Khi sự hợp tác này được phân tán trên các notebook Jupyter, kênh Slack và các công cụ quản lý dự án riêng biệt, bạn sẽ tạo ra sự phân tán ngữ cảnh, một tình huống mà thông tin quan trọng của dự án bị phân tán trên quá nhiều công cụ.
ClickUp giải quyết vấn đề đó. Thay vì phải sử dụng nhiều công cụ khác nhau, bạn sẽ có một Không gian Làm việc AI tích hợp, nơi quản lý dự án, tài liệu và giao tiếp được tích hợp sẵn – giúp các thí nghiệm của bạn luôn được kết nối từ giai đoạn kế hoạch, thực thi đến đánh giá.
Không bao giờ mất dấu các thí nghiệm và tiến độ.
Khi thực hiện nhiều thí nghiệm, phần khó khăn nhất không phải là đào tạo mô hình; mà là đang theo dõi những thay đổi trong quá trình. Phiên bản tập dữ liệu nào đã được sử dụng, tỷ lệ học nào hoạt động tốt nhất, hoặc phiên bản nào đã được triển khai?
ClickUp giúp quá trình này trở nên cực kỳ đơn giản cho bạn. Bạn có thể theo dõi từng lần đào tạo riêng biệt trong nhiệm vụ ClickUp, và trong các nhiệm vụ, bạn có thể sử dụng Trường Tùy chỉnh để ghi lại:
- Phiên bản tập dữ liệu
- Siêu tham số
- Biến thể mô hình (DBRX Base so với DBRX Instruct)
- Trạng thái đào tạo (Đang chờ, Đang chạy, Đang đánh giá, Đã triển khai)
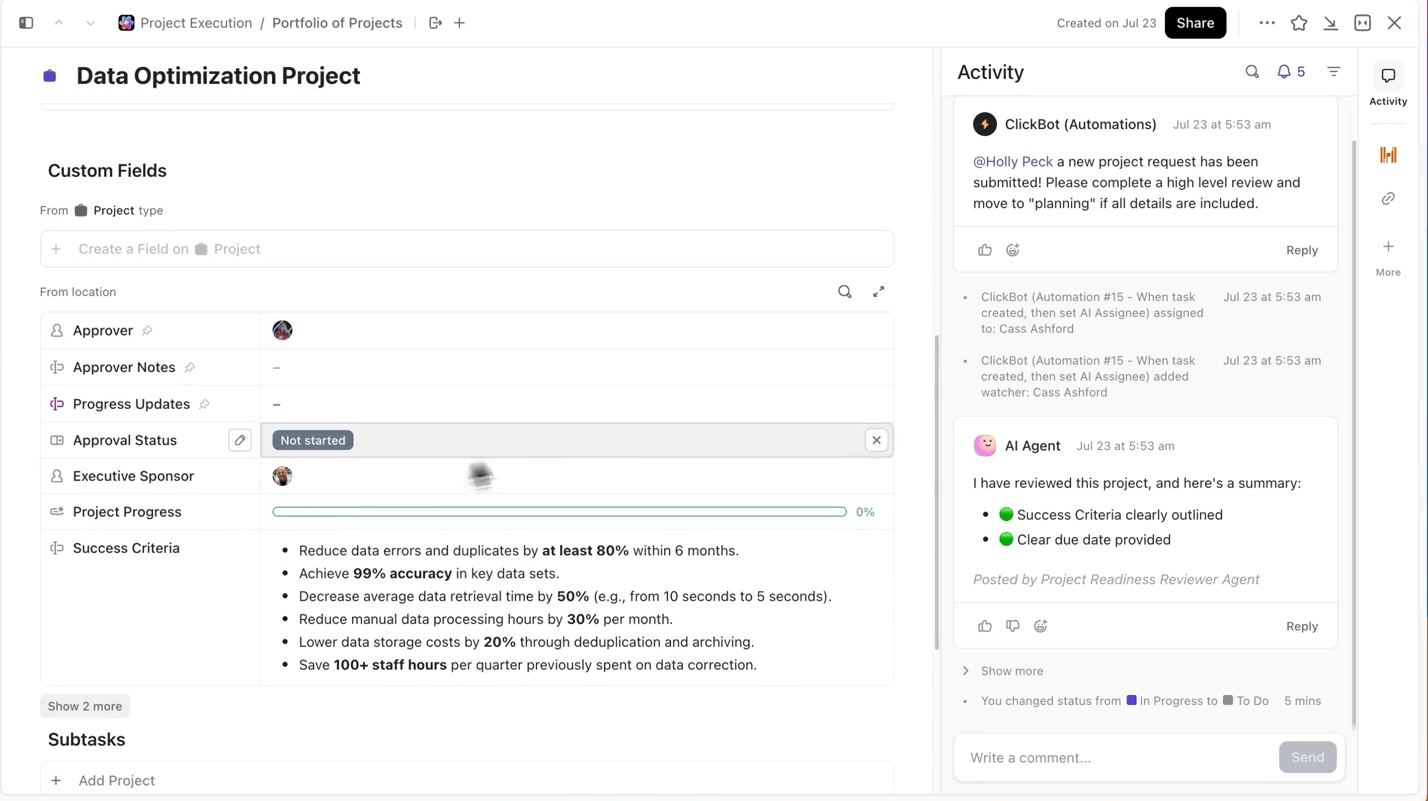
Như vậy, mọi thí nghiệm được ghi chép đều có thể tìm kiếm, dễ so sánh với các thí nghiệm khác và có thể tái tạo.
Giữ tài liệu mô hình liên kết với công việc
Bạn không cần phải chuyển đổi giữa các notebook Jupyter, tệp README hoặc các chủ đề trên Slack để hiểu bối cảnh của công việc trong một thí nghiệm.
Với ClickUp Docs, bạn có thể tổ chức và truy cập dễ dàng kiến trúc mô hình, kịch bản chuẩn bị dữ liệu hoặc các chỉ số đánh giá bằng cách tài liệu hóa chúng trong một tài liệu có thể tìm kiếm, liên kết trực tiếp với các công việc thí nghiệm mà chúng xuất phát.

💡Mẹo chuyên nghiệp: Duy trì một tài liệu dự án cập nhật liên tục trong ClickUp Docs, ghi chi tiết mọi quyết định từ kiến trúc đến triển khai, để các thành viên mới có thể nhanh chóng nắm bắt thông tin dự án mà không cần phải lục lọi các chủ đề cũ.
Hiển thị cho các bên liên quan khả năng theo dõi theo thời gian thực.
Bảng điều khiển ClickUp hiển thị tiến độ thí nghiệm và khối lượng công việc của nhóm theo thời gian thực.
Thay vì phải cập nhật thủ công hoặc gửi email, các bảng điều khiển sẽ tự động cập nhật dựa trên dữ liệu trong các công việc của bạn. Nhờ đó, các bên liên quan có thể kiểm tra trạng thái bất cứ lúc nào, xem tiến độ công việc và không bao giờ phải làm phiền bạn với những câu hỏi như “Trạng thái hiện tại thế nào?”
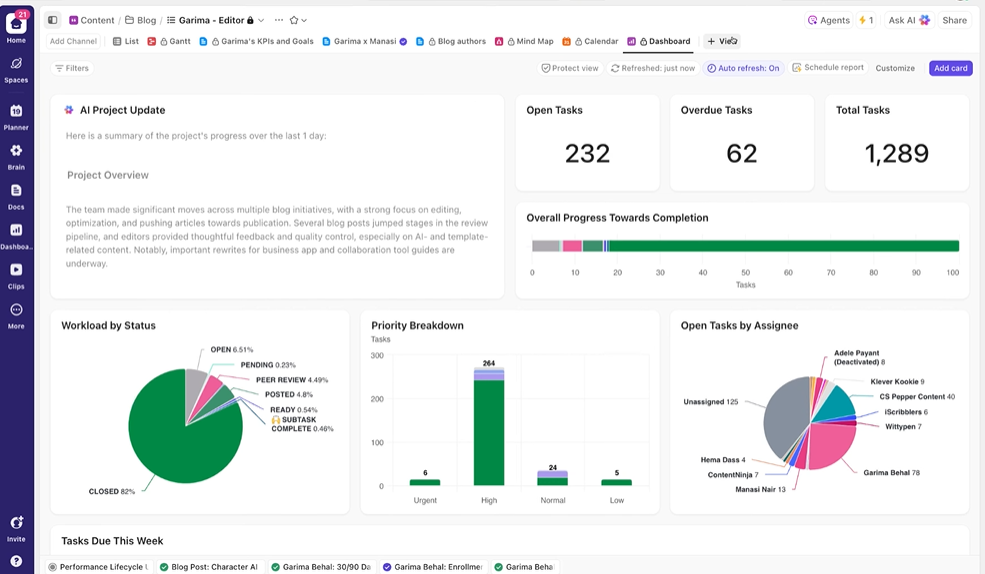
Như vậy, bạn có thể tập trung vào việc thực hiện các thí nghiệm thay vì phải báo cáo chúng thủ công liên tục.
Biến AI thành trợ thủ thông minh cho dự án của bạn
Bạn không cần phải tự tay lục lọi hàng tuần dữ liệu đào tạo để có được tóm tắt về các thí nghiệm cho đến nay. Chỉ cần đề cập @Brain trong bất kỳ bình luận công việc nào, và ClickUp Brain sẽ cung cấp cho bạn sự hỗ trợ cần thiết với đầy đủ bối cảnh về các dự án đã qua và đang diễn ra của bạn.
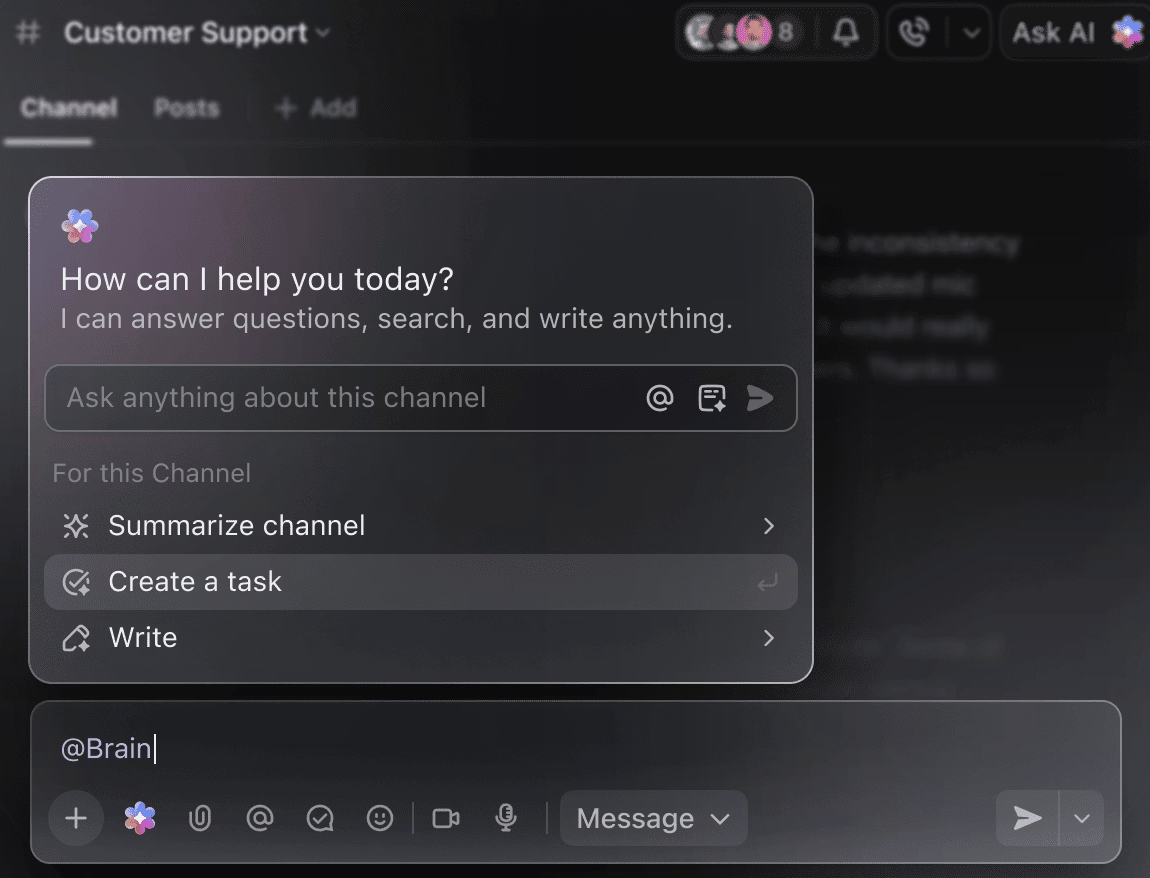
Bạn có thể yêu cầu Brain 'Tóm tắt các thí nghiệm của tuần trước trong 5 điểm chính' hoặc 'Soạn thảo tài liệu với kết quả siêu tham số mới nhất', và ngay lập tức nhận được kết quả hoàn chỉnh.
🧠 Ưu điểm của ClickUp: Các Super Agents của ClickUp mang lại nhiều lợi ích hơn nữa — chúng có thể tự động hóa toàn bộ quy trình làm việc dựa trên các kích hoạt bạn định nghĩa, không chỉ trả lời các câu hỏi của bạn. Với Super Agents, bạn có thể tự động tạo một công việc đào tạo DBRX mới mỗi khi tập dữ liệu được tải lên, thông báo cho nhóm của bạn, và liên kết các tài liệu liên quan khi quá trình đào tạo hoàn thành hoặc đạt đến điểm kiểm tra, đồng thời tạo bản tóm tắt tiến độ hàng tuần và đẩy nó đến các bên liên quan mà không cần bạn phải làm gì.
Những sai lầm thường gặp cần tránh
Bắt đầu một dự án đào tạo DBRX là điều thú vị, nhưng một số sai lầm phổ biến có thể làm chậm tiến độ của bạn. Tránh những sai lầm này sẽ giúp bạn tiết kiệm thời gian, tiền bạc và rất nhiều phiền toái.
- Đánh giá thấp yêu cầu phần cứng: DBRX rất mạnh mẽ, nhưng cũng rất lớn. Việc cố gắng chạy nó trên phần cứng không đủ mạnh sẽ dẫn đến lỗi hết bộ nhớ và các tác vụ đào tạo thất bại. Hãy nhớ rằng DBRX (132B) yêu cầu ít nhất 264GB VRAM cho suy luận 16-bit, hoặc khoảng 70GB-80GB khi sử dụng lượng tử hóa 4-bit.
- Bỏ qua kiểm tra chất lượng dữ liệu: Dữ liệu đầu vào kém chất lượng sẽ dẫn đến kết quả đầu ra kém chất lượng. Việc tinh chỉnh mô hình trên bộ dữ liệu lộn xộn, chất lượng thấp chỉ khiến mô hình học cách tạo ra kết quả đầu ra lộn xộn, chất lượng thấp.
- Bỏ qua giới hạn độ dài bối cảnh: Mặc dù cửa sổ bối cảnh 32K của DBRX khá rộng rãi, nhưng nó không phải là vô hạn. Việc cung cấp cho mô hình các đầu vào vượt quá giới hạn này sẽ dẫn đến kết quả là cắt bớt dữ liệu mà không có cảnh báo và hiệu suất kém.
- Sử dụng Base khi Instruct là phù hợp: DBRX Base là mô hình đã được huấn luyện sẵn, chưa qua tinh chỉnh, dành cho việc huấn luyện quy mô lớn tiếp theo. Đối với hầu hết các công việc tuân thủ hướng dẫn, bạn nên bắt đầu với DBRX Instruct, mô hình đã được tinh chỉnh sẵn cho mục đích đó.
- Tách biệt công việc đào tạo khỏi việc điều phối dự án: Khi việc theo dõi thí nghiệm được thực hiện trong một công cụ và kế hoạch dự án trong một công cụ khác, bạn tạo ra các "hộp đen" thông tin. Sử dụng nền tảng tích hợp như ClickUp để đồng bộ hóa công việc kỹ thuật và việc điều phối dự án.
- Bỏ qua việc đánh giá trước khi triển khai: Một mô hình hoạt động tốt trên dữ liệu đào tạo có thể thất bại thảm hại trong thế giới thực. Luôn kiểm tra mô hình đã được tinh chỉnh trên tập dữ liệu kiểm tra được giữ lại trước khi triển khai vào sản xuất.
- Bỏ qua độ phức tạp của việc tinh chỉnh: Vì DBRX là mô hình Mixture-of-Experts, các kịch bản tinh chỉnh tiêu chuẩn có thể yêu cầu các thư viện chuyên dụng như Megatron-LM hoặc PyTorch FSDP để xử lý việc chia sẻ tham số trên nhiều GPU.
DBRX so với các nền tảng đào tạo AI khác
Việc lựa chọn nền tảng đào tạo AI đòi hỏi một sự đánh đổi cơ bản: kiểm soát so với tiện lợi. Các mô hình độc quyền, chỉ hỗ trợ API, dễ sử dụng nhưng sẽ khiến bạn bị ràng buộc vào hệ sinh thái của nhà cung cấp.
Các mô hình trọng số mở như DBRX cung cấp quyền kiểm soát hoàn toàn nhưng đòi hỏi nhiều kiến thức kỹ thuật và hạ tầng hơn. Lựa chọn này có thể khiến bạn cảm thấy bế tắc, không chắc chắn con đường nào thực sự hỗ trợ mục tiêu dài hạn của mình—một thách thức mà nhiều nhóm gặp phải trong quá trình áp dụng AI.
Bảng này phân tích các điểm khác biệt chính để giúp bạn đưa ra quyết định thông minh.
| Trọng số | Mở (Tùy chỉnh) | Độc quyền | Mở (Tùy chỉnh) | Độc quyền |
| Tinh chỉnh | Kiểm soát hoàn toàn | Dựa trên API | Kiểm soát hoàn toàn | Dựa trên API |
| Tự lưu trữ | Có | Không | Có | Không |
| Giấy phép | Mô hình mở DBRX | Điều khoản của OpenAI | Cộng đồng Llama | Điều khoản của Anthropic |
| Bối cảnh | 32K | 128K – 1M | 128K | 200.000 – 1.000.000 |
DBRX là lựa chọn phù hợp khi bạn cần kiểm soát hoàn toàn mô hình, phải tự lưu trữ để đảm bảo bảo mật hoặc tuân thủ quy định, hoặc muốn sự linh hoạt của giấy phép thương mại có quyền truy cập. Nếu bạn không có hạ tầng GPU chuyên dụng—hoặc bạn coi trọng tốc độ đưa sản phẩm ra thị trường hơn là tùy chỉnh sâu—các giải pháp dựa trên API có thể phù hợp hơn.
Bắt đầu đào tạo thông minh hơn với ClickUp
DBRX cung cấp cho bạn một nền tảng sẵn sàng cho doanh nghiệp để xây dựng các ứng dụng AI tùy chỉnh, với tính minh bạch và kiểm soát mà bạn không thể có được từ các mô hình độc quyền. Kiến trúc MoE hiệu quả của nó giúp giảm chi phí suy luận, và thiết kế mở của nó khiến việc tinh chỉnh trở nên dễ dàng. Nhưng công nghệ mạnh mẽ chỉ là một nửa của phương trình.
Thành công thực sự đến từ việc đồng bộ hóa công việc kỹ thuật của bạn với quy trình làm việc hợp tác của đội ngũ. Đào tạo mô hình AI là một công việc nhóm, và việc duy trì sự đồng bộ giữa các thí nghiệm, tài liệu và giao tiếp với các bên liên quan là điều quan trọng. Khi bạn đưa mọi thứ vào một không gian làm việc tích hợp duy nhất và giảm thiểu sự phân tán thông tin, bạn có thể triển khai các mô hình tốt hơn, nhanh hơn.
Bắt đầu miễn phí với ClickUp để phối hợp các dự án đào tạo AI của bạn trong một không gian làm việc. ✨
Câu hỏi thường gặp
Bạn có thể theo dõi quá trình đào tạo bằng các công cụ ML tiêu chuẩn như TensorBoard, Weights & Biases hoặc MLflow. Nếu bạn đang đào tạo trong hệ sinh thái Databricks, MLflow được tích hợp sẵn để theo dõi thí nghiệm một cách liền mạch.
Có, DBRX có thể được tích hợp vào các quy trình MLOps tiêu chuẩn. Bằng cách đóng gói mô hình vào container, bạn có thể triển khai nó thông qua các nền tảng điều phối như Kubeflow hoặc các quy trình CI/CD tùy chỉnh.
DBRX Base là mô hình được huấn luyện sẵn cơ bản, dành cho các nhóm muốn thực hiện huấn luyện tiếp tục chuyên sâu hoặc tinh chỉnh kiến trúc sâu. DBRX Instruct là phiên bản được tinh chỉnh tối ưu cho việc tuân theo hướng dẫn, làm điểm khởi đầu tốt hơn cho hầu hết các dự án phát triển ứng dụng.
Sự khác biệt chính là khả năng kiểm soát. DBRX cung cấp quyền truy cập đầy đủ vào trọng số mô hình để tùy chỉnh sâu và tự lưu trữ, trong khi GPT-4 là dịch vụ chỉ hỗ trợ qua API.
Các trọng số mô hình DBRX có sẵn miễn phí theo Giấy phép Mô hình Mở Databricks. Tuy nhiên, bạn phải chịu trách nhiệm về chi phí cơ sở hạ tầng tính toán cần thiết để chạy hoặc tinh chỉnh mô hình.