
オープンソースAIモデルを検討するチームの多くは、MetaのLLaMAが稀に見る性能と柔軟性を兼ね備えていることに気づきます。しかし技術的なセットアップは、説明書なしでの家具組み立てのように感じられるかもしれません。
本ガイドでは、ハードウェア要件やモデルアクセスからプロンプトエンジニアリング、デプロイ戦略まで、機能するLLaMAチャットボットをゼロから構築する全工程を解説します。
さあ始めましょう!
LLaMAとは何か?なぜチャットボットに活用するのか?
独自APIを用いたチャットボット構築は、他社のシステムに縛られ、予測不能なコストやデータプライバシー問題に直面しているように感じられることが少なくありません。このベンダーロックインにより、チームの固有ニーズに合わせてモデルを真にカスタムできず、汎用的な応答やコンプライアンス上の問題が生じる可能性があります。
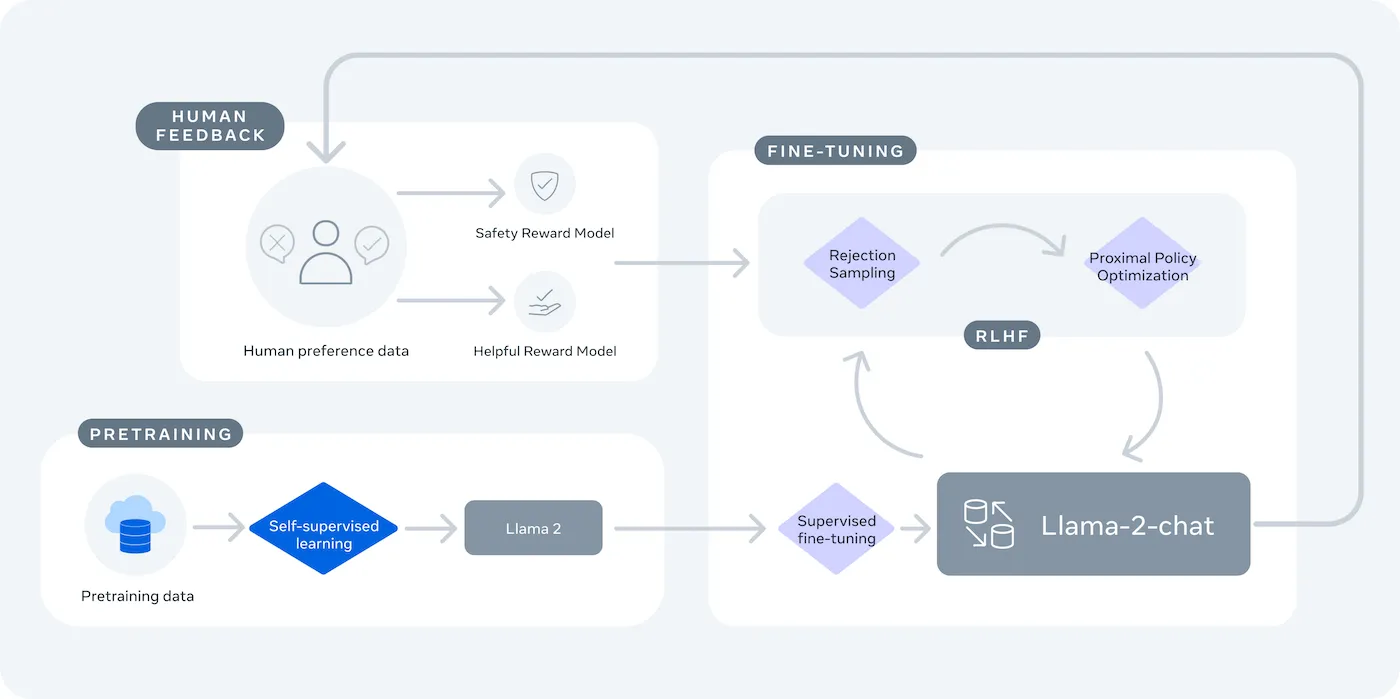
LLaMA(Large Language Model Meta AI)はMetaのオープンソース大規模言語モデル群であり、強力な代替手段を提供します。研究と商用利用の両方に設計されており、閉じたソースモデルでは得られない制御性を実現します。
LLaMAモデルはパラメーター数(例:7B、13B、70B)で測定される異なるサイズで提供されます。パラメーターはモデルの複雑さと能力の尺度と考えてください。より大きなモデルは能力が高い反面、より多くの計算リソースを必要とします。
LLaMAチャットボットを活用すべき理由:
- データプライバシー:自社インフラでモデルを実行する場合、会話データは環境外に流出することはありません。機密情報を扱うチームにとって極めて重要です。
- カスタム: 自社内部文書やデータでLLaMAモデルの微調整が可能です。これにより特定の文脈を理解し、より関連性の高い回答を提供できるようになります。
- コスト予測可能性: 初期のハードウェアセットアップ後は、トークンごとのAPI課金について心配する必要はありません。コストは固定化され、予測可能になります。
- レートリミットなし:チャットボットのキャパシティはベンダーの割り当てではなく、自社ハードウェアによってのみ制限されます。必要に応じてスケーリング可能です
主なトレードオフは利便性と制御性のバランスです。LLaMAはプラグアンドプレイAPIよりも技術的なセットアップが必要です。本番環境のチャットボットでは、チームは通常LLaMA 2またはより新しいLLaMA 3を使用します。これらは推論能力が向上し、一度に処理できるテキスト量も増加しています。
LLaMAチャットボット構築前に必要なもの
適切なツールなしで開発プロジェクトに飛び込むのは、挫折への道筋です。途中で重要なハードウェアやソフトウェアへのアクセスが不足していることに気づき、進捗が頓挫し、何時間も無駄にしてしまうことになります。
これを避けるには、必要なものを事前にすべて揃えましょう。スムーズなスタートを切るためのチェックリストはこちらです。🛠️
ハードウェア要件
| モデルサイズ | 最小VRAM | 代替オプション |
|---|---|---|
| 70億パラメーター | 8GB | クラウドGPUインスタンス |
| 130億パラメーター | 16GB | クラウドGPUインスタンス |
| 700億パラメーター | 複数GPU | 量子化かクラウドか |
ローカルマシンに十分な性能のグラフィックス処理ユニット(GPU)がない場合、AWSやGCPなどのクラウドサービスを利用できます。BasetenやReplicateなどの推論プラットフォームも従量課金制のGPUアクセスを提供しています。
ソフトウェア要件
- Python 3.8以上:機械学習プロジェクトの標準プログラミング言語です
- パッケージマネージャー: プロジェクトに必要なライブラリをインストールするには、pipまたはCondaが必要です。
- 仮想環境: これはベストプラクティスであり、プロジェクトの依存関係をマシン上の他のPythonプロジェクトから分離します。
アクセス要件
- Hugging Faceアカウント: LLaMAモデルの重みをダウンロードするにはアカウントが必要です
- Metaの承認: LLaMAモデルを利用するにはMetaのライセンス契約に同意する必要があります。承認は通常数時間以内に完了します。
- APIキー: モデルをローカルで実行せず、ホストされた推論エンドポイントを使用する場合にのみ必要です。
このガイドではLangChainフレームワークを使用します。プロンプト管理や会話履歴管理など、チャットボット構築の複雑な部分を簡素化します。
{kind=link}
LLaMAでチャットボットを構築するステップバイステップガイド
チャットボットの技術的要素(モデル、プロンプト、メモリ)をすべて接続するのは、圧倒されるかもしれません。コードに埋もれてしまい、バグが発生したり、期待通りに動作しないチャットボットにつながりかねません。このステップバイステップガイドでは、プロセスをシンプルで管理しやすい部分に分解します。
この手法は、モデルを自身のマシンで実行する場合でも、ホスト型サービスを利用する場合でも有効です。
ステップ1: 必要なパッケージをインストールする
まず、コアとなるPythonライブラリをインストールする必要があります。ターミナルを開き、次のコマンドを実行してください:
pip install langchain transformers accelerate torch
推論にBasetenのようなホスト型サービスを利用する場合、そのサービス固有のソフトウェア開発キット(SDK)もインストールする必要があります:
pip install baseten
各パッケージのやること:
- Langchain: 大規模言語モデルを活用したアプリケーション構築を支援するフレームワーク。会話の連鎖管理やメモリ管理を含む。
- Transformers: LLaMAモデルの読み込みと実行のためのHugging Faceライブラリ
- Accelerate: CPUとGPUへのモデル読み込みを最適化するライブラリ
- Torch: モデルの計算処理を支えるバックエンド機能を提供するPyTorchライブラリ
NVIDIA GPUを搭載したマシンでモデルをローカル実行する場合、CUDAが正しくインストール・設定されていることを確認してください。これによりモデルがGPUを活用し、大幅に高速なパフォーマンスを実現します。
ステップ2: LLaMAモデルへのアクセスを取得する
モデルをダウンロードする前に、Hugging Faceを通じてMetaから公式アクセス権を取得する必要があります。
- huggingface.coでアカウントを作成する
- モデルのページに移動してください。例:meta-llama/Llama-2-7b-チャット-hf
- 「リポジトリにアクセス」をクリックし、Metaのライセンス条項に同意してください
- Hugging Faceアカウント設定で、新しいアクセストークンを生成してください
- ターミナルで `huggingface-cli login` を実行し、トークンを貼り付けてマシンを認証してください
承認は通常迅速です。会話タスク向けに特別に訓練されたモデルであるため、名称に「チャット」を含むモデルバリエーションを選択してください。
ステップ3: LLaMAモデルの読み込み
これでモデルをコードに読み込めます。ハードウェアに応じて主に2つの選択肢があります。
十分な性能のGPUがあれば、モデルをローカルで読み込めます:
ハードウェアのリミットが厳しい場合は、ホスト型推論サービスを利用できます:
device_map="auto" コマンドは、Transformersライブラリに対し、利用可能なGPU全体にモデルを自動的に配布させるよう指示します。
メモリ不足が続く場合は、量子化と呼ばれる手法でモデルのサイズを縮小できますが、これにより性能がわずかに低下する可能性があります。
ステップ4: プロンプトテンプレートの作成
LLaMAチャットモデルは特定のフォーマットのプロンプトを想定して訓練されています。プロンプトテンプレートを使用することで、入力が正しく構造化されます。
このフォーマットを分解してみましょう:
- <
>: このセクションにはシステムプロンプトが含まれており、モデルに中核となる指示を与え、その個性を定義します - [INST]: これはユーザーの質問または指示の開始を示す
- [/INST]: これはモデルに対して応答を生成するタイミングであることを示します
異なるバージョンのLLaMAでは、使用するテンプレートが若干異なる可能性があることに留意してください。正しいフォーマットについては、必ずHugging Face上のモデルドキュメントを確認してください。
ステップ5: チャットボットチェーンの設定
次に、LangChainを使用してモデルとプロンプトテンプレートを会話チェーンに接続します。このチェーンには会話の追跡を可能にするメモリも含まれます。
LangChainは複数の種類のメモリを提供します:
- 会話バッファメモリ: 最もシンプルな選択肢です。会話履歴全体を保存します。
- 会話要約メモリ: スペースを節約するため、このオプションは定期的に会話の古い部分を要約します
- ConversationBufferWindowMemory: メモリ内に直近の数回のやり取りのみを保持し、コンテキストが過度に長くなるのを防ぐのに有用です
テストには、ConversationBufferMemoryが最適な出発点です。
ステップ6:チャットボットループの実行
最後に、ターミナルからチャットボットとやり取りするためのシンプルなループを作成できます。
実際のアプリケーションでは、このループをFastAPIやFlaskなどのフレームワークを使用したAPIエンドポイントに置き換えます。モデルの応答をユーザーにストリーミングすることも可能で、これによりチャットボットの応答が大幅に高速化されます。
応答のランダム性を制御するため、温度などのパラメーターを調整することも可能です。低い温度(例:0.2)は出力をより決定論的で事実に基づいたものにし、高い温度(例:0.8)はより創造性を促進します。
LLaMAチャットボットのテスト方法
質問に答えるチャットボットは構築できましたが、実際のユーザーに対応できる状態でしょうか?テストされていないボットをデプロイすると、誤った情報の提供や不適切なコンテンツの生成といった恥ずかしい失敗を招き、企業の評判を損なう可能性があります。
体系的なテストプランこそが、この不確実性への解決策です。これにより、チャットボットの堅牢性、信頼性、安全性が保証されます。
機能テスト:
- エッジケース: ボットが空入力、非常に長いメッセージ、特殊文字をどのように処理するかテストする
- メモリ検証: 会話の複数ターンにわたってチャットボットが文脈を記憶していることを確認する
- 指示に従う: ボットがシステムプロンプトで設定したルールに準拠しているか確認する
品質評価:
- 関連性: 応答は実際にユーザーの質問に答えていますか
- 正確性: 提供する情報は正しいか
- 一貫性: 会話のフローは論理的か
- 安全性: ボットは不適切または有害な要求への応答を拒否しますか
性能テスト:
また、幻覚(誤った情報を確信を持って述べる)、文脈ドリフト(長時間の会話で話題を見失う)、反復といったLLMの一般的な問題にも注意が必要です。テスト会話をすべて記録することは、パターンを発見し、ユーザーに届く前に問題を修正する優れた方法です。
📚 こちらもご覧ください:機能テストと非機能テストの違い
チーム向けLLaMAチャットボット活用事例
微調整やデプロイの仕組みを理解したら、LLaMAは抽象的なAIデモではなく、日常的なチーム課題に応用する際に真価を発揮します。チームが本当に必要としているのは「チャットボット」ではなく、知識への迅速なアクセス、手動での引き継ぎ削減、そして反復仕事の軽減なのです。
社内ナレッジアシスタント
内部文書、wiki、FAQでLLaMAを微調整するか、RAGベースのナレッジベースと組み合わせることで、チームは自然言語で質問し、文脈を認識した正確な回答を得られます。これにより、散在するツールを横断して検索する手間が解消され、機密データをサードパーティAPIに送信することなく完全に内部で保持できます。
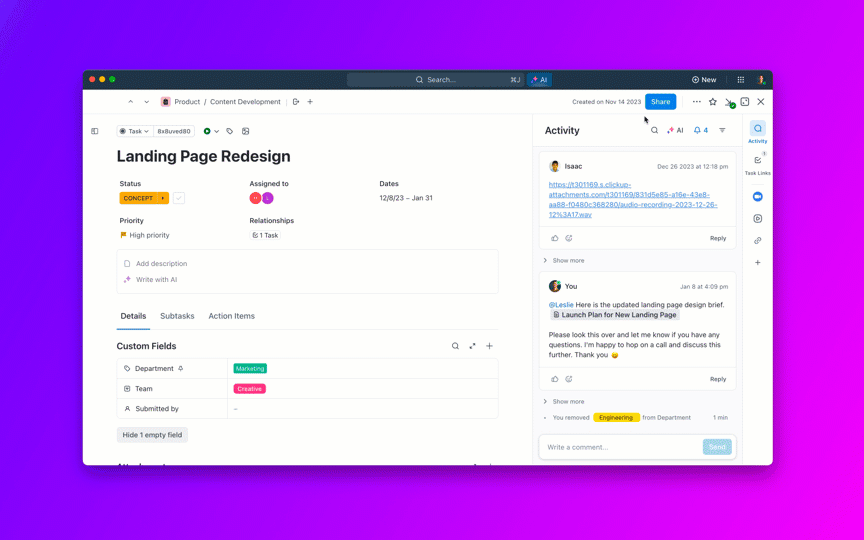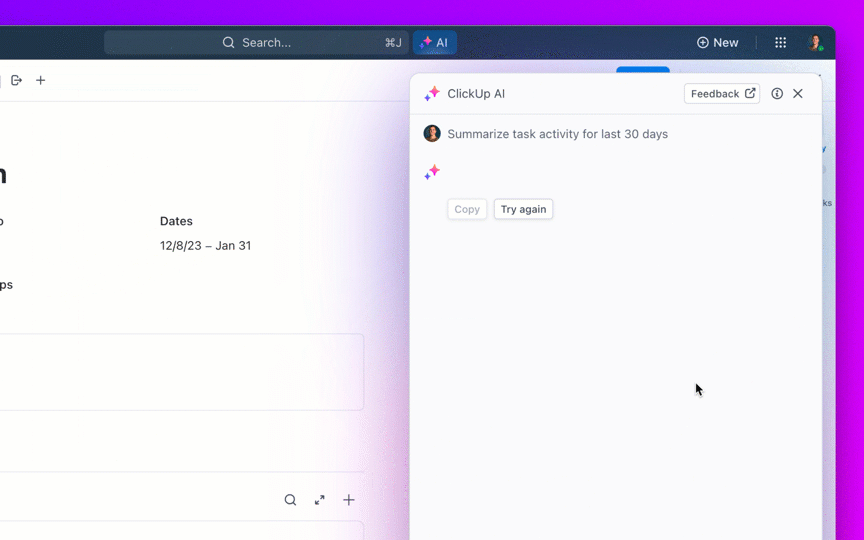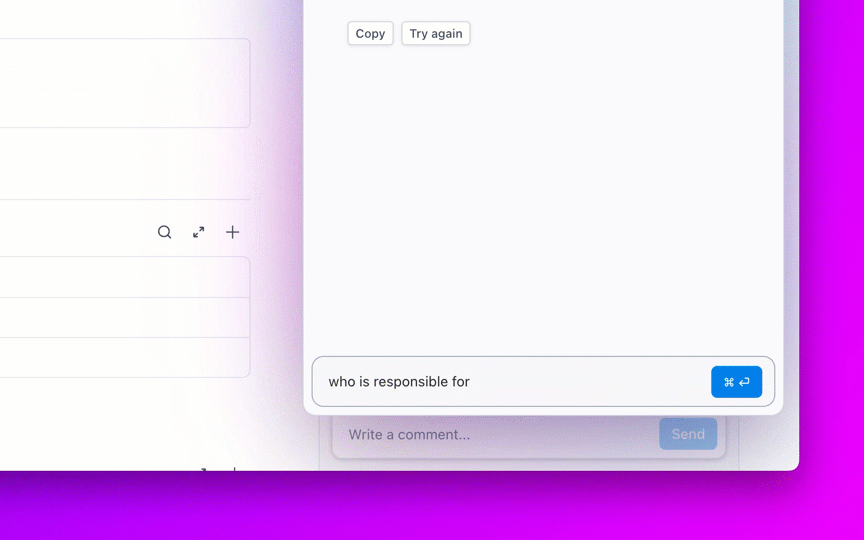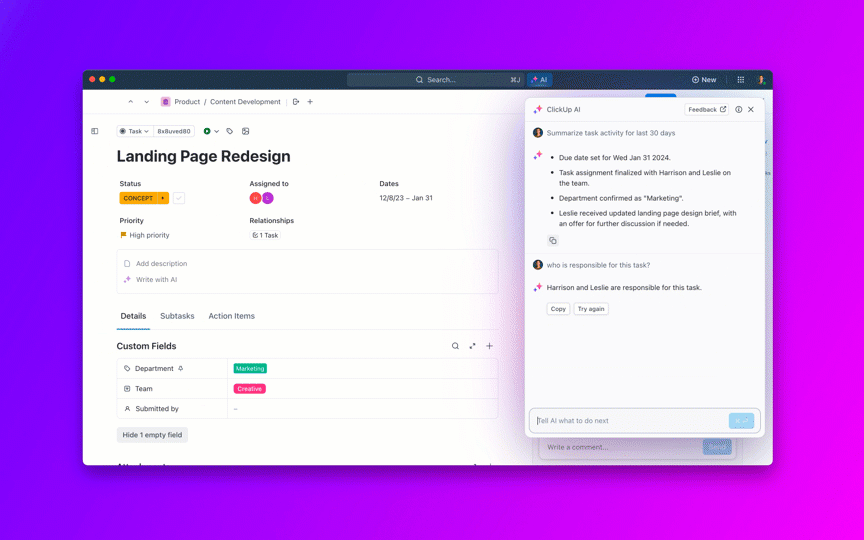
🌟ClickUpの企業検索と事前構築済みのAmbient Answersエージェントは、ClickUpワークスペース内の知識を活用し、質問に対して詳細な文脈に沿った回答を提供します。
コードレビュー支援ツール
自社コードベースとスタイルガイドでトレーニングされたLLaMAは、文脈に沿ったコードレビューアシスタントとして機能します。汎用的なベストプラクティスではなく、開発者はチームの慣習、アーキテクチャ上の決定、過去のパターンに沿った提案を得られます。
🌟 LLaMAベースのコードレビュー支援ツールは、問題点の抽出、改善提案、未知のコードの説明が可能です。ClickUpのCodegenはさらに一歩進み、開発ワークフロー内で直接動作します——プルリクエストの作成、リファクタリングの適用、それらの洞察に応じたファイルの直接更新などを行います。これにより、「考える」と「実行する」の間のコピー&貼り付け作業や、引き継ぎ時の不具合が減少します。
カスタマーサポートのトリアージ
LLaMAは意図分類のトレーニングが可能で、顧客からのクエリを理解し適切なチームやワークフローへ振り分けます。一般的なクエリは自動処理され、特殊ケースは文脈情報を添付して人間オペレーターへエスカレーションされるため、品質を損なうことなく応答時間を短縮できます。
ClickUpワークスペース内で自然言語を用いたトリアージスーパーエージェントを構築することも可能です。詳細はこちら
ミーティング要約とフォローアップ
ミーティング議事録を入力として、LLaMAは決定事項、アクションアイテム、主要な議論ポイントを抽出できます。これらの出力がタスク管理ツールに直接連携され、会話が追跡可能な仕事に転換されることで真の価値が生まれます。
🌟ClickUpのAIミーティングノートテイカーは、単なる議事録作成にとどまりません。要約の起草、アクション項目の生成、議事録とドキュメントやタスクの連携を実現します。
文書作成と反復作業
チームは既存のテンプレートや過去の例に基づき、LLaMAでレポート・提案書・ドキュメントの初稿を生成できます。これにより、白紙状態からの作成作業からレビューと精緻化へ努力を移行でき、品質を落とさずに納期を短縮します。
🌟 ClickUp Brainはドキュメントの下書きを素早く生成し、職場の知識を文脈に沿って管理します。今すぐお試しください。
LLaMA搭載チャットボットは、単独ツールとして運用するよりも、既存のワークフロー(ドキュメント管理、プロジェクト管理、チームコミュニケーション)に組み込むことで最大の効果を発揮します。
ワークスペースにAIを直接統合することで、大きな違いが生まれます。別途ツールを構築する代わりに、チームが既に活動している場所に会話型AIを導入できます。
例えば、カスタムLLaMAボットをナレッジアシスタントとして作成できます。しかし、プロジェクト管理ツールの外部に存在する場合、チームは質問するためにコンテキストを切り替える必要があります。これにより摩擦が生じ、全員の作業が遅延します。
ワークフローに既に組み込まれたAIを活用することで、このコンテキスト切り替えを排除します。
ClickUp Brainを使えば、ClickUpを離れることなくプロジェクト・タスク・ドキュメントに関する質問が可能です。タスクコメントやClickUpチャットで「@brain」と入力するだけで、文脈を把握した即答が得られます。まるでワークスペース全体を完璧に把握したチームメンバーがいるようなものです。🤩
これによりチャットボットは単なる目新しさから脱却し、チームの生産性エンジンの中核へと変貌を遂げます。
LLaMAを用いたチャットボット構築のリミット
LLaMAチャットボットの構築は可能性を広げますが、チームは隠れた複雑性に不意を突かれることが多々あります。「無料」のオープンソースモデルは、予想以上に高コストで管理が困難になり、結果としてユーザー体験の悪化や、リソースを消耗する継続的なメンテナンスサイクルを招く可能性があります。
コミットする前にリミットを理解することが重要です。
- 技術的難易度: LLaMAモデルの設定と維持には機械学習インフラの知識が必要です
- ハードウェア要件:より大規模で高性能なモデルを実行するには高価なGPUハードウェアが必要であり、クラウドコストは急速に膨れ上がる可能性があります
- コンテキストウィンドウの制約: LLaMAモデルはメモリリミットがあります(LLaMA 2の場合4Kトークン)。長文や長時間の会話処理には複雑なチャンキング戦略が必要です。
- 組み込みの安全対策なし: コンテンツフィルタリングや安全対策の実装はご自身で行ってください
- 継続的なメンテナンス: 新しいモデルがリリースされるたびにシステムを更新する必要があり、微調整済みモデルは再トレーニングが必要になる場合があります。
セルフホスト型モデルは通常、高度に最適化された商用APIよりも遅延が大きくなります。これらはすべて運用上の負担であり、マネージドソリューションが代行します。
📮ClickUpインサイト:アンケートの回答者の88%が個人タスクにAIを活用している一方、50%以上が仕事での使用を避けています。主な障壁は3つ:シームレスな統合の欠如、知識不足、セキュリティ懸念です。
しかし、もしAIがワークスペースに組み込まれていて、すでにセキュリティが確保されているなら?ClickUp Brain(ClickUpの組み込みAIアシスタント)がこれを実現します。平易な言語でのプロンプトを理解し、AI導入の3つの懸念をすべて解決しながら、ワークスペース全体のチャット、タスク、ドキュメント、ナレッジを接続します。ワンクリックで答えと洞察を見つけましょう!
チャットボット構築のためのLLaMA代替案
LLaMAは数あるAIモデルの一つに過ぎず、どれが自分に適しているかを判断するのは困難を極めることがあります。
代替手段の現状は以下の通りです。
その他のオープンソースモデル:
- ミストラル: 小規模モデルのサイズでも高い性能を発揮することで知られ、効率的な運用を実現します。
- Falcon: 非常に許可の多いライセンスが付帯しており、商用アプリケーションに最適です
- MPT: 長文文書や会話の処理に最適化
商用API:
- OpenAI(GPT-4、GPT-3.5): 一般的に最も高性能な大規模言語モデルと見なされており、非常に簡単に統合できます。
- Anthropic (Claude): 強力な安全機能と非常に大きなコンテキストウィンドウで知られる
- Google (Gemini): 強力なマルチモーダル機能を提供し、テキスト、画像、音声の理解を可能にします
オープンソースモデルで自作する、商用APIを有料で利用する、あるいは各種AIエージェントを事前統合したソリューションを提供する統合型AIワークスペースを活用するといった選択肢があります。
📚 こちらもご覧ください:ビジネスでチャットボットを活用する方法
ClickUpでコンテキスト認識型AIアシスタントを構築する
LLaMAでチャットボットを構築すると、データ管理・コスト管理・カスタマイズにおいて驚くべき制御力を得られます。しかしその制御には、インフラ・保守・安全性の責任が伴います——これらはすべてマネージドAPIが代行する領域です。目的は単にボットを構築することではなく、チームの生産性向上にあります。複雑なエンジニアリングプロジェクトは、時にその本質から目をそらす原因となり得ます。
適切な選択は、チームのリソースと優先度によって異なります。機械学習の専門知識があり、厳格なプライバシー要件がある場合は、LLaMAが素晴らしい選択肢です。スピードと簡便性を優先する場合は、統合ツールの方が適しているかもしれません。
ClickUpなら、統合AIワークスペースで全てのタスク、ドキュメント、会話を一元管理。統合AIによりコンテキストの分散を解消し、カスタマイズ可能なスーパーエージェントとコンテキストAIで必要な情報を即座に提供。チームの作業効率と生産性を飛躍的に向上させます。
インフラ構築に時間を浪費するのはやめましょう。一から構築することなく、今日からコンテキスト認識型AIアシスタントのメリットを享受できます。ClickUpで今すぐ無料で始めましょう。
よくある質問(FAQ)
コストは完全にデプロイ方法に依存し、プロジェクト予測で概算が可能です。自社ハードウェアを使用する場合、GPUの初期費用は発生しますが、クエリごとの継続的な費用は発生しません。クラウドプロバイダーはGPUとモデルサイズに基づき時間単位で課金します。
はい、LLaMA 2およびLLaMA 3のライセンスは商用利用を許可しています。ただし、Metaの利用規約に同意し、製品内で必要な帰属表示を提供する必要があります。
LLaMA 3はより新しく高性能なモデルであり、優れた推論能力とより大きなコンテキストウィンドウ(LLaMA 2の4Kトークンに対し8Kトークン)を提供します。これにより、より長い会話や文書を処理できますが、実行にはより多くの計算リソースを必要とします。
Pythonは豊富なライブラリにより機械学習で最も一般的な言語ですが、必須ではありません。一部のプラットフォームでは、グラフィカルインターフェースでLLaMAチャットボットをデプロイできるノーコード/ローコードソリューションの提供が始まっています。