
AIトレーニングプロジェクトが失敗するのは、モデルレベルではほとんどありません。実験、ドキュメント、ステークホルダーへの進捗報告が複数のツールに分散している場合にこそ、課題が生じるのです。
このガイドでは、主要なモデルと比較して最大2倍の計算効率を誇るLLM「Databricks DBRX」を用いたモデルトレーニングの手順を解説します。同時に、関連仕事をClickUpで整理する方法もご紹介します。
セットアップや微調整からドキュメント作成、チーム横断的な進捗共有まで、単一の統合ワークスペースがコンテキストの拡散を解消し、チームが検索ではなく構築に集中できる仕組みを体感してください。🛠
DBRXとは?
DBRXは、企業向けAIモデルのトレーニングと推論に特化した強力なオープンソース大規模言語モデル(LLM)です。Databricks Open Model Licenseのもとでオープンソース化されているため、チームはモデルの重みとアーキテクチャに完全アクセスでき、自由に検証・修正・展開が可能です。
2つのバリエーションが用意されています:深層事前学習向けの「DBRX Base」と、すぐに使える指示順守タスク向けの「DBRX Instruct」です。
DBRXのアーキテクチャとエキスパート混合モデル設計
DBRXは混合専門家モデル(MoE)アーキテクチャを用いてタスクを解決します。従来の大型言語モデルが数億ものパラメーターを全ての計算に使用するのとは異なり、DBRXは特定のタスクに対して総パラメーターのごく一部(最も関連性の高い専門家)のみを活性化させます。
専門家のチームと捉えてください。全員があらゆる問題に仕事をするのではなく、システムが各タスクを最適なパラメーターにインテリジェントに振り分けます。
これにより応答時間が短縮されるだけでなく、計算コストを大幅に削減しながら最高水準のパフォーマンスと出力を実現します。
主な仕様の概要は以下の通りです:
- 総パラメーター数: 全エキスパート合計で1320億
- アクティブパラメーター: 1回のフォワードパスあたり360億
- エキスパート数:合計16名(MoEトップ4ルーティング)、各トークンに対して4名が常時稼働
- コンテキストウィンドウ: 32Kトークン
DBRXトレーニングデータとトークン仕様
LLMの性能は、その学習データに依存します。DBRXはDatabricksチームが高度なデータ処理ツールを用いて厳選した、12兆トークン規模の膨大なデータセットで事前学習されています。これが業界ベンチマークで高い性能を発揮した理由です。
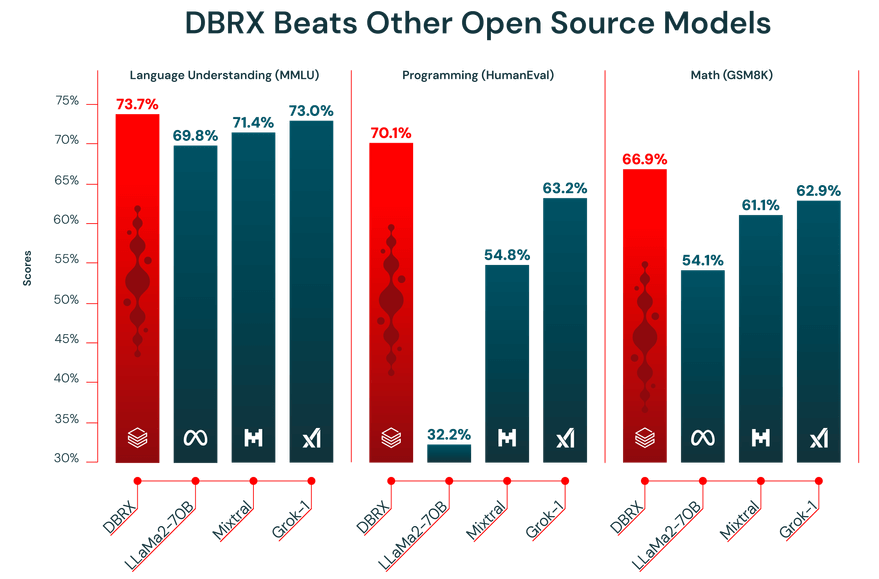
さらに、DBRXには32,000トークンのコンテキストウィンドウの機能があります。これはモデルが一度に考慮できるテキスト量です。長いレポートの要約、膨大な法的文書の精査、高度な検索拡張生成(RAG)システムの構築といった複雑なタスクにおいて、コンテキストウィンドウが大きいことは非常に有用です。これによりモデルは情報を切り詰めたり忘れたりすることなく、文脈を維持できるからです。
🎥 こちらのビデオで、プロジェクト調整の効率化がAIトレーニングワークフローをどう変革し、連携しないツール間の切り替えによる摩擦を解消するかをご覧ください。👇🏽
DBRXへのアクセス方法と設定手順
DBRXには主に2つのアクセス方法があり、いずれも許容的な商用利用条件のもとでモデル重みへの完全なアクセスを提供します。最大限の柔軟性を求める場合はHugging Faceを利用するか、より統合された環境を求める場合はDatabricks経由で直接アクセスできます。
Hugging Face経由でDBRXにアクセス
柔軟性を重視し、Hugging Faceエコシステムに既に慣れているチームにとって、hub経由でDBRXにアクセスするのが理想的な方法です。これにより、既存のTransformersベースのワークフローにモデルを統合できます。
始め方は以下の通りです:
- Hugging Faceアカウントを作成するか、ログインしてください
- hub上のDBRXモデルカードに移動し、利用規約に同意してください
- accelerateなどの必要な依存関係とともにtransformersライブラリをインストールする
- PythonスクリプトでAutoModelForCausalLMクラスを使用し、DBRXモデルを読み込みます
- 推論パイプラインを設定する際は、DBRXが効果的に動作するために大量のGPUメモリ(VRAM)を必要とする点に留意してください。
📖 詳細はこちら:LLMの温度設定方法
Databricks経由でDBRXにアクセス
チームがデータエンジニアリングや機械学習にDatabricksを既に利用している場合、プラットフォーム経由でDBRXにアクセスするのが最も簡単な方法です。これによりセットアップの手間が省け、MLOpsに必要なすべてのツールを、普段仕事をしている環境でそのまま利用できます。
Databricksワークスペース内で以下のステップに従って開始してください:
- モデルガーデンまたはモザイクAIセクションに移動してください
- ニーズに応じてDBRX BaseまたはDBRX Instructのいずれかを選択してください
- APIアクセス用のサービングエンドポイントを設定するか、対話型使用のためのノートブック環境をセットアップします。
- AIモデルのトレーニングやデプロイをスケールアップする前に、サンプルプロンプトで推論テストを開始し、すべてが正しく動作していることを確認しましょう。
このアプローチにより、実験追跡のためのMLflowやモデルガバナンスのためのUnity Catalogといったツールにシームレスにアクセスできます。
📮 ClickUpインサイト:平均的なビジネスパーソンは、仕事関連の情報を検索するのに1日30分以上を費やしています。これは電子メールやSlackのスレッド、散らばったファイルを探し回ることで、年間120時間以上が失われていることを意味します。
ワークスペースに組み込まれたインテリジェントなAIアシスタントがそれを変えます。ClickUp Brainの登場です。
適切な文書、会話、タスクの詳細を瞬時に表示することで、即座に洞察と回答を提供します。検索を止め、仕事を開始できるのです。
DBRXの微調整とカスタムAIモデルのトレーニング方法
既製のモデルは、どれほど高性能でも、貴社のビジネス特有のニュアンスを理解することは決してありません。DBRXはオープンソースであるため、貴社の言語を理解するカスタムモデルを作成したり、特定のタスクを処理できるように微調整したりすることが可能です。
これをやることの一般的な方法は以下の3つです:
1. Hugging FaceデータセットでDBRXを微調整する
初めて取り組むチームや一般的なタスクを扱うチームにとって、Hugging Face Hubの公開データセットは優れたリソースです。事前にフォーマット済みで読み込みが容易なため、データ準備に何時間も費やす必要がありません。
手順は非常にシンプルです:
- タスク(例:指示順守、要約する)に合ったデータセットをhubで探しましょう
- データセットライブラリを使用して読み込みます
- データが指示-応答ペア形式でフォーマットされていることを確認してください
- 学習率やバッチサイズなどのハイパーパラメータでトレーニングスクリプトを設定する
- トレーニングジョブを起動し、期間ごとにチェックポイントを保存するようにしてください
- 評価用に保持した検証データセットで微調整済みモデルを評価し、改善度を測定する
2. ローカルデータセットでDBRXを微調整する
自社固有のデータで微調整を行うことで、通常は最良の結果が得られます。これにより、自社の専門用語、スタイル、ドメイン知識をモデルに教えられるようになります。ただし、データがクリーンで適切に準備され、十分な量がある場合にのみ効果が得られる点に留意してください。
内部データを準備するには、以下のステップに従ってください:
- データ収集: 社内wiki、文書、データベースから高品質な例を収集します
- フォーマット変換:データを一貫した指示-応答形式(多くの場合JSONライン形式)に構造化します
- 品質フィルタリング: 低品質、重複、または関連性のない例をすべて除去します
- 検証用分割: モデルの性能評価用に、データのごく一部(通常10~15%)を確保します。
- プライバシー確認:個人を特定できる情報(PII)や機密データは削除またはマスキングしてください
3. StreamingDatasetによるDBRXの微調整
データセットが大きすぎてマシンメモリに収まらない場合でも心配無用です。Databricksのストリーミングデータセットライブラリを利用できます。これにより、モデルをトレーニング中にクラウドストレージから直接データをストリーミングでき、一度にメモリへ読み込む必要がなくなります。
そのことをやる方法は以下の通りです:
- データ準備: トレーニングデータをクリーンアップし構造化した後、JSONLやCSVなどのストリーム可能なフォーマットでクラウドストレージに保存します
- ストリーミングフォーマット変換: トレーニング中に効率的に読み込めるよう、Mosaic Data Shard(MDS)などのストリーミング対応フォーマットにデータセットを変換します。
- トレーニングローダーのセットアップ: リモートデータセットを指すようにトレーニングローダーをセットアップし、一時データストレージ用のローカルキャッシュを定義します
- モデルの初期化: LLM Foundryなど、StreamingDatasetをサポートするトレーニングフレームワークを使用して、DBRXの微調整プロセスを開始します。
- ストリーミングベースのトレーニング: トレーニング中にデータをメモリに完全に読み込むのではなく、バッチ単位でストリーミングしながらトレーニングジョブを実行します
- チェックポイントと復旧: 実行が中断された場合でも、データの重複やスキップなしにトレーニングをシームレスに再開
- 評価とデプロイ: ファインチューニング済みモデルの性能を検証し、お好みのサービングまたは推論セットアップでデプロイします
💡プロの秘訣: DBRXのトレーニングプランを一から構築する代わりに、ClickUpのAIおよび機械学習プロジェクトロードマップテンプレートを基に、チームのニーズに合わせて調整しましょう。データセットのプランニング、トレーニング段階、評価、デプロイメントのための明確な構造を提供するため、ワークフローの構築ではなく作業の整理に集中できます。
AIモデルトレーニングにおけるDBRXの活用事例
強力なモデルを持つことと、その真価を発揮する場面を正確に把握することは別物です。
モデルの長所が明確でない場合、適合しない領域で機能させようと時間とリソースを浪費しがちです。これは不十分な結果とフラストレーションにつながります。
DBRXの独自のアーキテクチャとトレーニングデータは、いくつかの主要な企業ユースケースに非常に適しています。これらの強みを理解することで、モデルをビジネス目標に整合させ、投資対効果を最大化できます。
テキスト生成とコンテンツ作成
DBRX Instructは指示の追従と高品質なテキスト生成に特化して調整されています。これにより、幅広いコンテンツ関連タスクの自動化を実現する強力なツールとなります。その大きなコンテキストウィンドウは大きな利点であり、長い文書を処理してもスレッドを途切れさせずに処理できます。
以下の用途にご利用いただけます:
- 技術文書: 製品マニュアル、APIリファレンス、ユーザーガイドの生成と改良
- マーケティングコンテンツ: ブログ記事、電子メールニュースレター、ソーシャルメディア更新のドラフト作成
- レポート生成:複雑なデータ分析結果を要約し、簡潔なエグゼクティブサマリーを作成します
- 翻訳とローカライズ: 既存コンテンツを新たな市場や対象者向けに適応させる
コード生成とデバッグタスク
DBRXのトレーニングデータの大部分はコードを含んでおり、開発者向けの強力なLLMサポートとなっています。反復的なコーディングタスクの自動化や複雑な問題解決の支援により、開発サイクルの加速に貢献します。
エンジニアリングチームが活用できる方法をいくつかご紹介します:
- コード補完: コメントやドキュメント文字列から関数本体を自動生成
- バグ検出:コードスニペットを分析し、潜在的なエラーや論理的欠陥を特定します
- コード解説: 複雑なアルゴリズムやレガシーコードを平易な日本語に翻訳する
- テスト生成: 機能の署名と期待される動作に基づいてユニットテストを作成する
RAGと長文コンテキストアプリケーション
検索拡張生成(RAG)は、モデルの応答を自社のプライベートデータに根ざす強力な技術です。しかし、RAGシステムはコンテキストウィンドウが小さいモデルでは、重要な文脈を失う可能性のある過度なデータ分割を余儀なくされることが多く課題を抱えています。DBRXの32Kコンテキストウィンドウは、堅牢なRAGアプリケーションの優れた基盤となります。
これにより、次のような強力な社内ツールを構築できます:
- 企業検索:社内ナレッジベースを活用した従業員向け質問応答チャットボットを作成
- カスタマーサポート: 製品ドキュメントに基づいたサポート応答を生成するエージェントを構築する
- 研究支援ツール:数百ページに及ぶ研究論文から情報を統合できるツールを開発する
- コンプライアンスチェック:マーケティングコピーを内部ブランドガイドラインや規制文書に対して自動的に検証します
DBRXトレーニングをチームワークフローに統合する方法
AIモデルトレーニングプロジェクトの成功は、コードや計算リソースだけでは実現できません。機械学習エンジニア、データサイエンティスト、プロダクトマネージャー、ステークホルダーが協力して取り組む共同作業なのです。
この連携がJupyterノートブック、Slackチャンネル、別々のプロジェクト管理ツールに分散すると、コンテキストの拡散が生じます。これは重要なプロジェクト情報があまりにも多くのツールに散らばってしまう状況です。
ClickUpがその課題を解決します。複数のツールを使い分ける代わりに、プロジェクト管理・ドキュメント管理・コミュニケーションが一体となった統合AIワークスペースを実現。計画から実行、評価まで実験プロセス全体をシームレスに接続させます。
実験と進捗を把握し続ける
複数の実験を実行する際、最も難しいのはモデルをトレーニングすることではなく、プロセス中に何が変わったかを追跡することです。どのデータセットバージョンが使用されたか、どの学習率が最も良好な結果を出したか、あるいはどの実行結果がリリースされたか?
ClickUpはこのプロセスを非常に簡単にします。ClickUpタスクで各トレーニング実行を個別に追跡でき、タスク内ではカスタムフィールドを使用して以下を記録できます:
- データセットのバージョン
- ハイパーパラメータ
- モデルバリエーション(DBRX Base 対 DBRX Instruct)
- トレーニングステータス(キュー中、実行中、評価中、デプロイ済み)
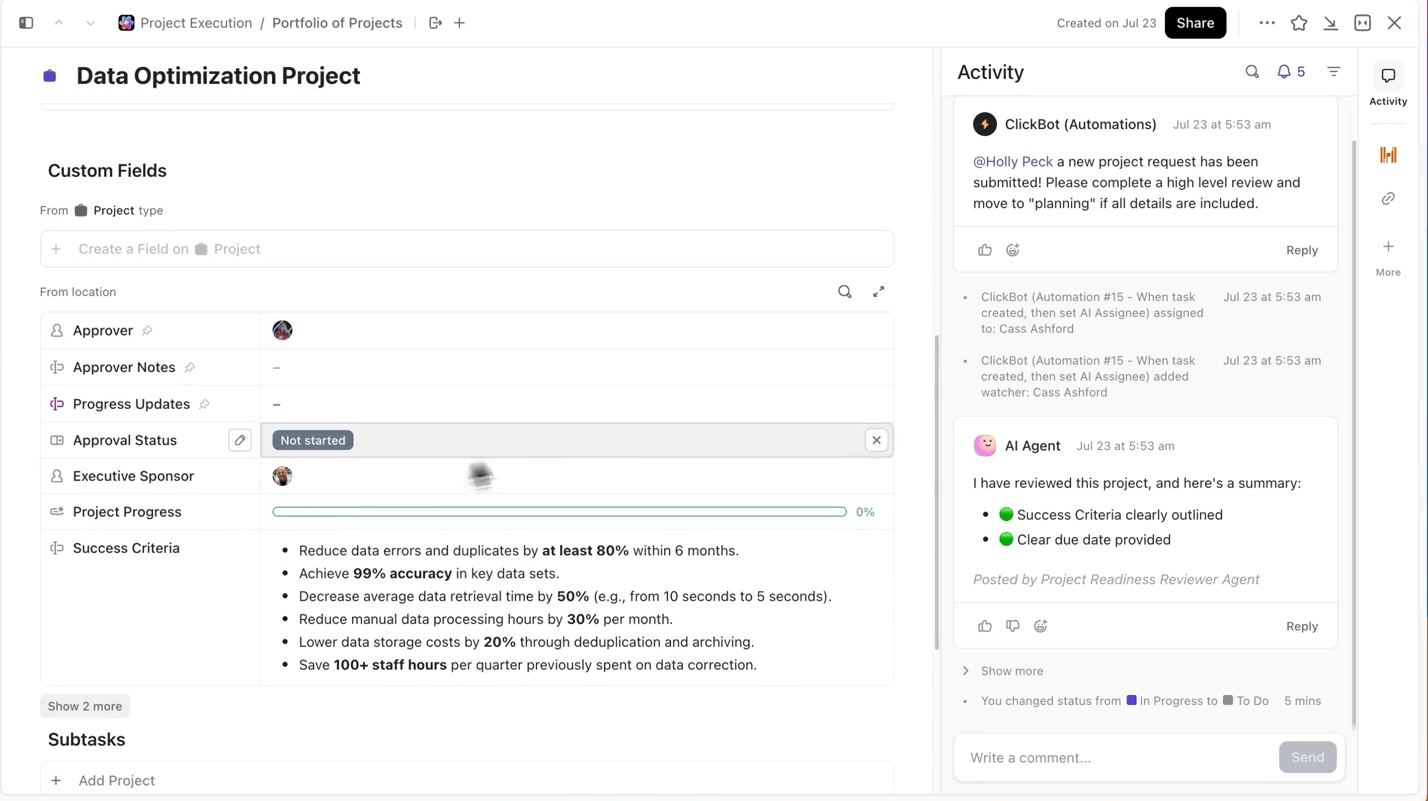
これにより、文書化されたすべての実験は検索可能で、他の実験との比較が容易になり、再現性が確保されます。
モデル文書化を仕事に紐づける
実験タスクの背景を理解するために、JupyterノートブックやREADMEファイル、Slackスレッドを行き来する必要はありません。
ClickUp Docsを使えば、モデルアーキテクチャ、データ準備スクリプト、評価メトリクスを整理し、アクセスしやすくできます。これらは検索可能なドキュメントに記録され、元となった実験タスクに直接リンクされています。

💡プロのコツ: ClickUp Docsで「生きているプロジェクト概要書」を維持しましょう。アーキテクチャからデプロイまで全ての決定事項を詳細に記録することで、新規メンバーは過去のスレッドを掘り起こすことなく、常にプロジェクトの詳細を把握できます。
ステークホルダーにリアルタイムの可視性を提供
ClickUpダッシュボードで実験の進捗状況とチームの作業負荷をリアルタイムで可視化。
更新を手動でまとめることや電子メール送信の代わりに、ダッシュボードはタスク内のデータに基づいて自動更新されます。そのため関係者はいつでもステータスを確認でき、「現状は?」といった質問で作業を中断させる必要がなくなります。
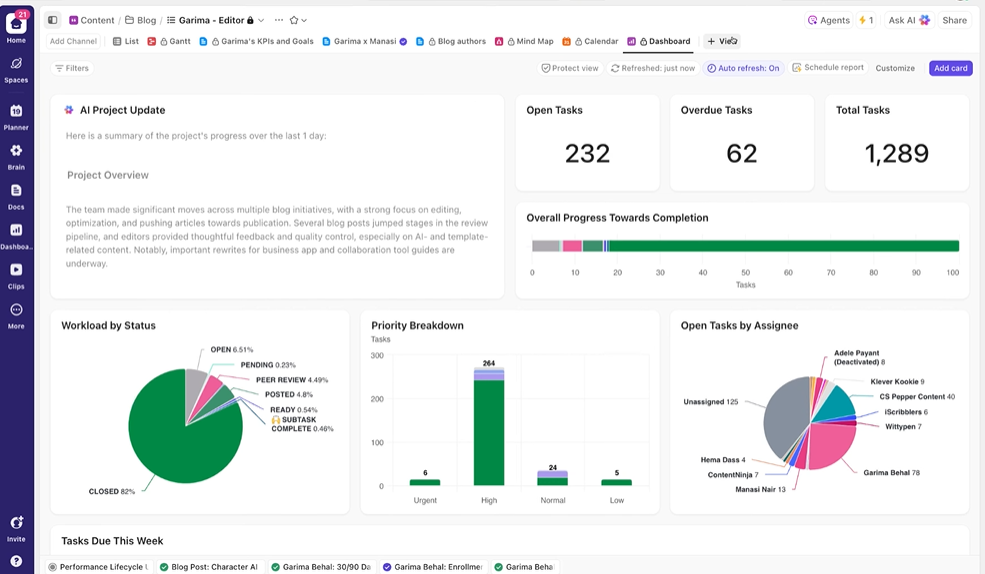
これにより、実験のレポート作成を手動で繰り返し行う必要がなくなり、実験の実行に集中できます。
AIをスマートなプロジェクトの相棒に変えよう
これまでの実験要約を得るために、何週間分ものトレーニングデータを手作業で掘り下げる必要はありません。タスクのコメント欄で@Brainをメンションするだけで、ClickUp Brainが過去のプロジェクトや進行中のプロジェクトの完全なコンテキストと共に必要な支援を提供します。
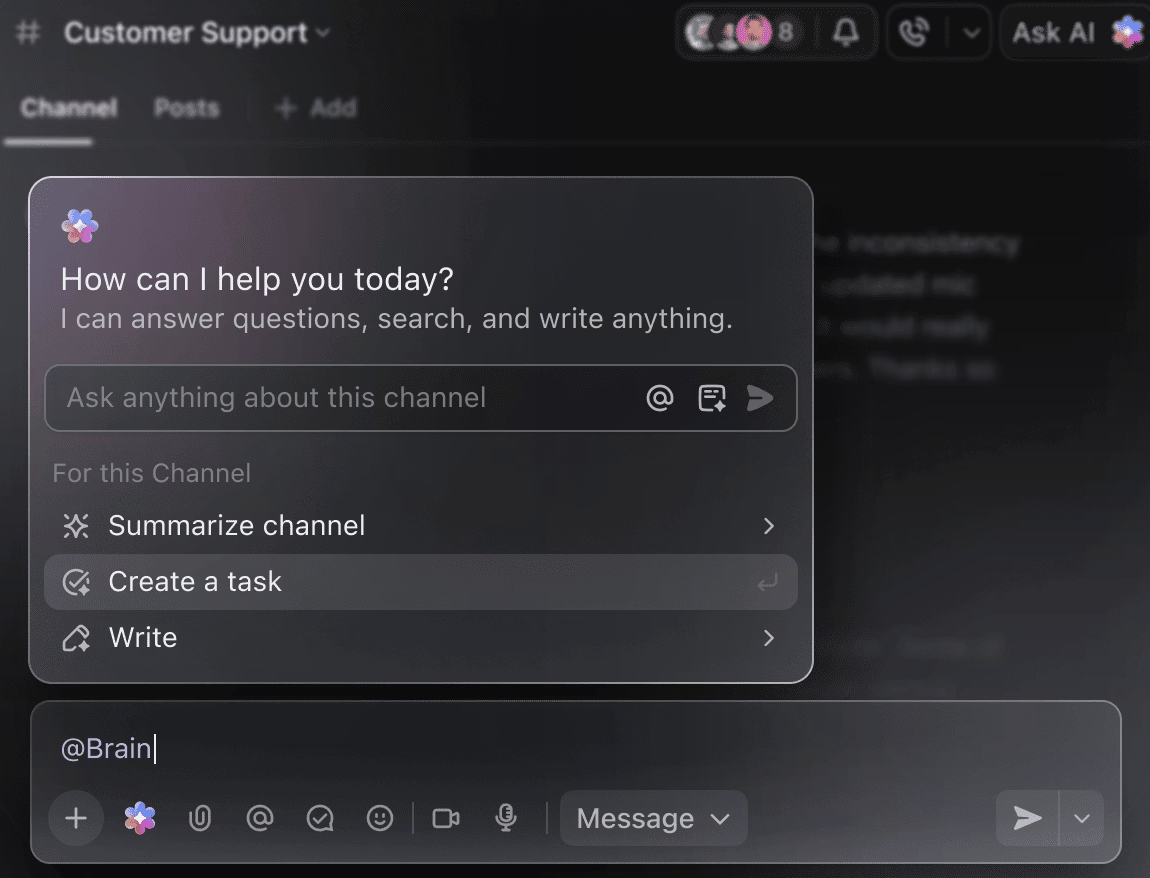
「先週の実験を5つの箇条書きで要約して」や「最新のハイパーパラメータ結果をまとめたドキュメントを作成して」とBrainに依頼すれば、洗練された出力が即座に得られます。
🧠 ClickUpの優位性:ClickUpのスーパーエージェントはさらに一歩進み、定義したトリガーに基づいてワークフロー全体を自動化します。単なる質問への回答にとどまりません。 スーパーエージェントを活用すれば、データセットがアップロードされるたびに自動的に新しいDBRXトレーニングタスクを作成し、チームに通知。トレーニング実行が完了またはチェックポイントに到達した際には関連ドキュメントがリンクされている状態となり、週次進捗要約を生成して関係者に自動配信します。一切の手動操作は不要です。
避けるべきよくある間違い
DBRXトレーニングプロジェクトの開始はワクワクするものですが、いくつかのよくある落とし穴が進捗を妨げる可能性があります。これらのミスを回避すれば、時間と費用、そして多くのストレスを節約できます。
- ハードウェア要件の過小評価: DBRXは強力ですが、同時に大規模でもあります。不十分なハードウェアで実行しようとすると、メモリ不足エラーやトレーニングジョブの失敗につながります。DBRX (132B) は、16ビット推論で少なくとも264GBのVRAM、4ビット量子化使用時は約70GB~80GBを必要とすることを念頭に置いてください。
- データ品質チェックの省略: ゴミを入れればゴミが出る。乱雑で低品質なデータセットで微調整を行っても、モデルが乱雑で低品質な出力を生成するよう学習させるだけです。
- コンテキスト長リミットの無視について: DBRXの32Kコンテキストウィンドウは十分ですが、無限ではありません。このリミットを超える入力をモデルに与えると、結果として黙って切り詰められ、性能が低下します。
- 適切な場面でのBaseの使用: DBRX Baseは、さらなる大規模トレーニングを目的とした未調整の事前学習済みモデルです。指示に従うタスクの大半では、その目的に合わせて既に微調整済みのDBRX Instructから始めるべきです。
- トレーニング仕事とプロジェクト調整のサイロ化:実験の追跡ツールとプロジェクトプランツールが別々だと、情報のサイロ化が発生します。ClickUpのような統合プラットフォームを活用し、技術仕事とプロジェクト調整を同期させましょう。
- デプロイ前の評価を怠る: トレーニングデータで良好な性能を示すモデルも、実環境では著しく失敗する可能性があります。常に、本番環境にデプロイする前に、保持したテストセットで微調整したモデルを検証してください。
- 微調整の複雑さを見落とす: DBRXは専門家混合モデルであるため、標準的な微調整スクリプトでは、複数GPUにまたがるパラメーター分割を処理するために、Megatron-LMやPyTorch FSDPなどの専用ライブラリが必要になる場合があります。
DBRXと他社AIトレーニングプラットフォームの比較
AIトレーニングプラットフォームの選択には根本的なトレードオフが伴います:制御性対利便性。プロプライエタリなAPI専用モデルは使いやすい反面、ベンダーのエコシステムに縛られることになります。
DBRXのようなオープンウェイトモデルは完全な制御を提供しますが、より高度な技術的専門知識とインフラを必要とします。この選択は行き詰まりを感じさせ、長期的な目標を実際にサポートする道筋が不確かな状態に陥りがちです。これは多くのチームがAI導入時に直面する課題です。
このテーブルは主要な違いを比較し、情報に基づいた判断を下すのに役立ちます。
| 重み | 開く(カスタム) | 独自開発 | 開く(カスタム) | 独自開発 |
| 微調整 | 完全な制御 | APIベース | 完全な制御 | APIベース |
| セルフホスティング | はい | No | はい | No |
| ライセンス | DB Open Model | OpenAI利用規約 | Llama Community | Anthropic Terms |
| 背景 | 32K | 128K – 1M | 128K | 20万~100万 |
DBRXは、モデルを完全に制御する必要がある場合、セキュリティやコンプライアンスのために自社ホスティングが必須の場合、あるいは柔軟な商用ライセンスを求める場合に最適な選択肢です。専用のGPUインフラがない場合、あるいは深いカスタマイズよりも市場投入のスピードを重視する場合は、APIベースの代替手段の方が適している可能性があります。
ClickUpでよりスマートなトレーニングを始めよう
DBRXは、独自モデルでは得られない透明性と制御性を備え、カスタムAIアプリケーション構築のための企業対応基盤を提供します。効率的なMoEアーキテクチャが推論コストを抑え、オープン設計により微調整が容易です。しかし優れた技術は成功の半分に過ぎません。
真の成功は、技術的な作業とチームの共同ワークフローを連携させることから生まれます。AIモデルのトレーニングはチームスポーツであり、実験、ドキュメント、ステークホルダーとのコミュニケーションを同期させることが極めて重要です。すべてを単一の統合ワークスペースに集約し、コンテキストの拡散を抑えることで、より優れたモデルをより迅速に提供できます。
ClickUpを無料で始め、AIトレーニングプロジェクトを1つのワークスペースで調整しましょう。✨
よくある質問
TensorBoard、Weights & Biases、MLflowなどの標準的な機械学習ツールを使用してトレーニングを監視できます。Databricksエコシステム内でトレーニングを行う場合、MLflowがネイティブに統合されており、シームレスな実験追跡が可能です。
はい、DBRXは標準的なMLOpsパイプラインに統合可能です。モデルをコンテナ化することで、KubeflowなどのオーケストレーションプラットフォームやカスタムCI/CDワークフローを用いたデプロイが可能になります。
DBRX Baseは、特定分野での継続的事前学習や深層アーキテクチャの微調整を目的とするチーム向けの基盤となる事前学習済みモデルです。DBRX Instructは指示に従うことに最適化された微調整済みバージョンであり、ほとんどのアプリケーション開発においてより優れた出発点となります。
主な違いは制御性です。DBRXはモデル重みへの完全なアクセス権を提供し、深いカスタムと自己ホスティングを可能にします。一方、GPT-4はAPIのみのサービスです。
DBRXモデルの重み付けは、Databricksオープンモデルライセンスのもと無料で利用可能です。ただし、モデルの実行や微調整に必要なコンピューティングインフラの費用は、お客様のご負担となります。