
La plupart des développeurs qui créent un script de résumé Hugging Face se heurtent au même obstacle : le résumé fonctionne parfaitement dans leur terminal. Mais il n'établit pas de connexion avec le travail réel qu'il est censé soutenir.
Ce guide vous explique comment créer un résumeur de texte à l'aide de la bibliothèque Transformers de Hugging Face, puis vous montre pourquoi même une implémentation parfaite peut créer plus de problèmes qu'elle n'en résout lorsque votre équipe a besoin de résumés qui sont réellement liés aux tâches, aux projets et aux décisions.
Qu'est-ce que le résumé de texte ?
Les équipes croulent sous les informations. Vous êtes confronté à de longs documents, des transcriptions de réunions interminables, des articles de recherche denses et des rapports trimestriels qui prennent des heures à digérer manuellement. Cette surcharge constante d'informations ralentit la prise de décision et nuit à la productivité.
Le résumé de texte est le processus qui consiste à utiliser le traitement du langage naturel (NLP) pour condenser ce contenu en une version courte et cohérente qui préserve les informations les plus importantes. Considérez-le comme un résumé exécutif instantané pour n'importe quel document. Cette technologie de résumé NLP utilise généralement l'une des deux approches suivantes :
Résumé extractif : cette méthode consiste à identifier et à extraire les phrases les plus importantes directement du texte source. C'est comme si un surligneur sélectionnait automatiquement les clés pour vous. Le résumé final est un ensemble de phrases originales.
Résumé abstrait : cette méthode plus avancée génère des phrases entièrement nouvelles pour capturer le sens profond du texte source. Elle paraphrase les informations, ce qui donne un résumé plus fluide et plus humain, un peu comme une personne expliquerait une longue histoire avec ses propres mots.
Vous pouvez voir les résultats de cette approche partout. Elle est utilisée pour condenser les notes de réunion en éléments à mener, distiller les commentaires des clients en tendances et créer des aperçus rapides de la documentation des projets. L'objectif est toujours le même : obtenir les informations essentielles sans avoir à lire chaque mot.
📮 ClickUp Insight : En moyenne, un professionnel passe plus de 30 minutes par jour à rechercher des informations liées à son travail. Cela représente plus de 120 heures par an perdues à fouiller dans les e-mails, les fils de discussion Slack et les fichiers éparpillés. Un assistant IA intelligent intégré à votre environnement de travail peut changer cela. ClickUp Brain fournit des informations et des réponses instantanées en faisant apparaître les bons documents, discussions et détails de tâches en quelques secondes, afin que vous puissiez arrêter de chercher et commencer à travailler.
💫 Résultats réels : des équipes telles que QubicaAMF ont gagné plus de 5 heures par semaine grâce à ClickUp, soit plus de 250 heures par an et par personne, en éliminant les processus de gestion des connaissances obsolètes.
Pourquoi utiliser Hugging Face pour la résumation de texte ?
Créer un modèle de résumé de texte personnalisé à partir de zéro est une tâche colossale. Cela nécessite d'énormes ensembles de données pour l'entraînement, des ressources informatiques puissantes et coûteuses, ainsi qu'une équipe d'experts en apprentissage automatique. Cette barrière à l'entrée très élevée empêche la plupart des équipes d'ingénieurs et de produits de se lancer.
Hugging Face est la plateforme qui résout ce problème. Il s'agit d'une communauté open source et d'une plateforme de science des données qui vous donne accès à des milliers de modèles pré-entraînés, démocratisant ainsi efficacement la résumation LLM pour les développeurs. Au lieu de partir de zéro, vous pouvez commencer avec un modèle puissant qui est déjà prêt à 99 %.
Voici pourquoi tant de développeurs se tournent vers Hugging Face : 🛠️
Accès aux modèles pré-entraînés : Hugging Face Hub est un immense référentiel contenant plus de 2 millions de modèles publics entraînés par des entreprises telles que Google, Meta et OpenAI. Vous pouvez télécharger et utiliser ces points de contrôle de pointe pour vos propres projets.
API de pipeline simplifiée : la fonction pipeline est une API de haut niveau qui gère toutes les étapes complexes, telles que le prétraitement du texte, l'inférence du modèle et le formatage de la sortie, en quelques lignes de code seulement.
Variété de modèles : vous n'êtes pas limité à une seule option. Vous pouvez choisir parmi un large intervalle d'architectures telles que BART, T5 et Pegasus, chacune présentant des atouts, des tailles et des caractéristiques de performance différents.
Flexibilité du framework : la bibliothèque Transformers fonctionne de manière transparente avec les deux frameworks d'apprentissage profond les plus populaires, PyTorch et TensorFlow. Vous pouvez utiliser celui avec lequel votre équipe est déjà à l'aise.
Assistance communautaire : grâce à une documentation complète, des cours officiels et une communauté active de développeurs, il est facile de trouver des tutoriels et d'obtenir de l'aide lorsque vous rencontrez des problèmes.
Bien que Hugging Face soit incroyablement puissant pour les développeurs, il est important de se rappeler qu'il s'agit d'une solution basée sur du code. Sa mise en œuvre et sa maintenance nécessitent une expertise technique. Cela ne convient pas toujours aux équipes non techniques qui ont simplement besoin de résumer leur travail.
🧐 Le saviez-vous ? La bibliothèque Transformers de Hugging Face a permis de généraliser l'utilisation de modèles NLP de pointe en quelques lignes de code, c'est pourquoi les prototypes de résumé commencent souvent par là.
Que sont les transformateurs Hugging Face ?
Vous avez donc décidé d'utiliser Hugging Face, mais quelle est la technologie qui permet de le faire fonctionner ? La technologie de base est une architecture appelée Transformer. Lorsqu'elle a été présentée dans un article intitulé « Attention Is All You Need » en 2017, elle a complètement révolutionné le champ du traitement du langage naturel (NLP).
Avant les Transformers, les modèles avaient du mal à comprendre le contexte des phrases longues. La clé de l'innovation du Transformer est le mécanisme d'attention, qui permet au modèle d'évaluer l'importance des différents mots dans le texte d'entrée lors du traitement d'un mot spécifique. Cela l'aide à saisir les dépendances à long terme et à comprendre le contexte, ce qui est essentiel pour créer des résumés cohérents.
La bibliothèque Hugging Face Transformers est un package Python qui vous permet d'utiliser très facilement ces modèles complexes. Vous n'avez pas besoin d'un doctorat en apprentissage automatique. La bibliothèque se charge des tâches les plus difficiles.
Les trois éléments essentiels que vous devez connaître
- Tokenizers : les modèles ne comprennent pas les mots, ils comprennent les nombres. Un tokenizer prend votre texte d'entrée et le convertit en une séquence de jetons numériques (un processus appelé tokenisation ) que le modèle peut traiter.
- Modèles : il s'agit des réseaux neuronaux pré-entraînés eux-mêmes. Pour résumer, il s'agit généralement de modèles séquence-à-séquence avec une structure encodeur-décodeur. L'encodeur lit le texte saisi pour créer une représentation numérique, et le décodeur utilise cette représentation pour générer le résumé.
- Pipelines : C'est la façon la plus simple d'utiliser un modèle. Un pipeline regroupe un modèle pré-entraîné avec son tokenizer correspondant et gère pour vous toutes les étapes de pré-traitement de l'entrée et de post-traitement de la sortie.
Les deux modèles les plus populaires pour la synthèse sont BART et T5. BART (Bidirectional and Auto-Regressive Transformer) est particulièrement performant pour la synthèse abstraite, produisant des résumés qui se lisent très naturellement. T5 (Text-to-Text Transfer Transformer) est un modèle polyvalent qui encadre chaque tâche de NLP comme un problème de texte à texte, ce qui en fait un outil puissant et polyvalent.
🎥 Regardez cette vidéo pour comparer les meilleurs résumeurs PDF basés sur l'IA et découvrir quels outils fournissent les résumés les plus rapides et les plus précis sans perdre le contexte.
Comment créer un résumeur de texte avec Hugging Face
Prêt à créer votre propre exemple de résumeur ? Tout ce dont vous avez besoin, c'est de quelques connaissances de base en Python, d'un éditeur de code comme VS Code et d'une connexion Internet. Le processus complet ne comporte que quatre étapes. Vous disposerez d'un résumeur fonctionnel en quelques minutes.
Étape 1 : Installez les bibliothèques requises
Tout d'abord, vous devez installer les bibliothèques nécessaires. La principale est transformers. Vous aurez également besoin d'un framework d'apprentissage profond comme PyTorch ou TensorFlow. Nous utiliserons PyTorch pour cet exemple.
Ouvrez votre terminal ou votre invite de commande et exécutez la commande suivante :

Certains modèles, comme T5, nécessitent également la bibliothèque sentencepiece pour leur tokenizer. Il est recommandé de l'installer également.

💡 Conseil de pro : créez un environnement virtuel Python avant d'installer ces paquets. Cela permet d'isoler les dépendances de votre projet et d'éviter les conflits avec d'autres projets sur votre machine.
Étape 2 : Charger le modèle et le tokenizer
La façon la plus simple de commencer est d'utiliser la fonction pipeline. Elle se charge automatiquement de charger le modèle et le tokenizer appropriés pour la tâche de résumé.
Dans votre script Python, importez le pipeline et initialisez-le comme suit :

Ici, nous précisons deux choses :
La tâche : nous indiquons au pipeline que nous voulons effectuer une « résumation ».
Le modèle : nous choisissons un point de contrôle de modèle pré-entraîné spécifique à partir du Hugging Face Hub. facebook/bart-large-cnn est un choix populaire entraîné sur des articles d'actualité et qui fonctionne bien pour la résumation à usage général. Pour des tests plus rapides, vous pouvez utiliser un modèle plus petit comme t5-small.
La première fois que vous exécuterez ce code, il téléchargera les poids du modèle depuis le hub, ce qui peut prendre quelques minutes. Ensuite, le modèle sera mis en cache sur votre machine locale pour un chargement instantané.
Étape 3 : créer la fonction de résumé
Pour que votre code soit propre et réutilisable, il est préférable d'intégrer la logique de résumé dans une fonction. Cela facilite également l'expérimentation de différents paramètres.
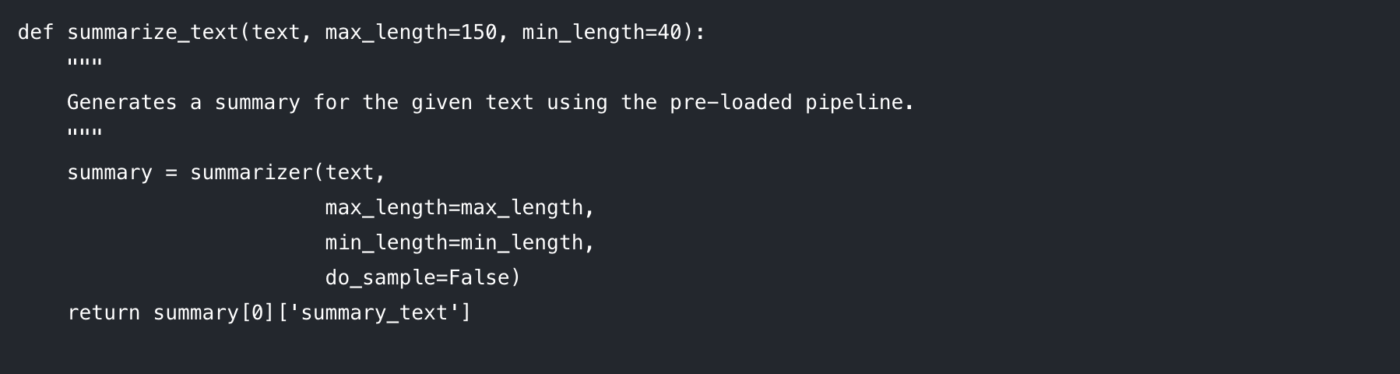
Décomposons les paramètres que vous pouvez contrôler :
max_length : ce paramètre définit le nombre maximal de jetons (environ, mots) pour le résumé de sortie.
min_length : ce paramètre définit le nombre minimum de jetons afin d'empêcher le modèle de générer des résumés trop courts ou vides.
do_sample : lorsqu'il est défini sur False, le modèle utilise une méthode déterministe (comme la recherche par faisceau) pour générer le résumé le plus probable. Le définir sur True introduit un caractère aléatoire, ce qui peut produire des résultats plus créatifs mais moins prévisibles.
Le réglage de ces paramètres est essentiel pour obtenir la qualité de sortie souhaitée.
Étape 4 : Générez votre résumé
Passons maintenant à la partie amusante. Transmettez votre texte à la fonction et imprimez le résultat. 🤩

Vous devriez voir une version condensée de l'article s'afficher sur votre console. Si vous rencontrez des problèmes, voici quelques solutions rapides :
Texte saisi trop long : le modèle peut générer une erreur si votre saisie dépasse sa longueur maximale (souvent 512 ou 1024 jetons). Ajoutez truncation=True dans l'appel summarizer() pour couper automatiquement les saisies trop longues.
Le résumé est trop générique : essayez d'augmenter le paramètre num_beams (par exemple, num_beams=4). Cela permet au modèle de rechercher plus minutieusement un meilleur résumé, mais peut être légèrement plus lent.
Cette approche basée sur le code est fantastique pour les développeurs qui créent des applications personnalisées. Mais que se passe-t-il lorsque vous devez l'intégrer dans le travail quotidien d'une équipe ? C'est là que les limites commencent à apparaître.
Limites de Hugging Face pour la résumation de texte
Hugging Face est une excellente option lorsque vous recherchez flexibilité et contrôle. Mais dès que vous essayez de l'utiliser pour de véritables flux de travail d'équipe (et pas seulement pour un notebook de démonstration), quelques défis prévisibles apparaissent rapidement.
Limites de jetons et casse-tête liés aux documents longs
La plupart des modèles de résumé ont une longueur d'entrée maximale fixe. Par exemple, facebook/bart-large-cnn est configuré avec max_position_embeddings = 1024. Cela signifie que les documents plus longs nécessitent souvent d'être tronqués ou fragmentés.
Si vous avez seulement besoin d'une base rapide, vous pouvez activer la troncature dans le pipeline et passer à autre chose. Mais si vous avez besoin de résumés fidèles de longs documents, vous finissez généralement par créer une logique de découpage, puis par effectuer un deuxième passage, un « résumé des résumés », pour assembler les résultats. Cela demande un travail d'ingénierie supplémentaire et il est facile d'obtenir des résultats incohérents.
Risque d'hallucination (et coût de vérification)
Les modèles abstractifs peuvent parfois halluciner, générant des textes qui semblent plausibles mais qui sont factuellement incorrects. Pour une utilisation critique pour l'entreprise, cela pose un problème : chaque résumé doit faire l'objet d'une vérification manuelle. À ce stade, vous ne gagnez pas vraiment de temps, vous ne faites que déplacer le travail vers une autre partie du processus.
Manque de connaissance du contexte
Un modèle Hugging Face ne connaît que le texte que vous lui fournissez. Il ne comprend pas les objectifs de votre projet, les personnes impliquées ou les liens entre les documents, car il ne dispose pas de l'intelligence contextuelle des systèmes modernes. Il ne peut pas vous dire si le résumé d'un appel client contredit le document des exigences du projet, car il fonctionne de manière isolée.
Coût d'intégration (le problème du « dernier kilomètre »)
Générer un résumé est généralement la partie la plus facile. Le véritable défi réside dans ce qui vient ensuite.
Où va le résumé ? Qui le voit ? Comment se transforme-t-il en tâche réalisable ? Comment établir la connexion avec le travail qui l'a déclenché ?
Pour résoudre ce « dernier obstacle », il faut créer des intégrations personnalisées et du code de liaison. Cela ajoute du travail pour les développeurs en amont et crée souvent un flux de travail fastidieux pour tout le monde.
Obstacle technique et maintenance continue
Une approche basée sur Python est principalement accessible aux personnes qui savent coder. Cela crée un obstacle pratique pour les équipes de marketing, commerciales et d'exploitation, ce qui signifie que son adoption reste limitée.
Il comprend également une maintenance continue : gestion des dépendances, mise à jour des bibliothèques et maintien du bon fonctionnement de tout l'ensemble à mesure que les API et les modèles évoluent. Ce qui commence comme un gain rapide peut discrètement devenir un autre système à surveiller.
📮 ClickUp Insight : 42 % des perturbations au travail proviennent de la gestion simultanée de plusieurs plateformes, des e-mails et des allers-retours entre les réunions. Et si vous pouviez éliminer ces interruptions coûteuses ? ClickUp regroupe vos flux de travail (et vos discussions) sur une seule plateforme rationalisée. Lancez et gérez vos tâches à partir de discussions, de documents, de Tableaux blancs et plus encore, tandis que les fonctionnalités alimentées par l'IA maintiennent le contexte connecté, consultable et gérable.
Le problème plus important : la prolifération du contexte
Même si votre script de résumé fonctionne parfaitement, votre équipe peut encore perdre du temps car le résultat est déconnecté du lieu où le travail est réellement effectué.
C'est ce qu'on appelle la prolifération du contexte, lorsque les équipes perdent des heures à rechercher des informations, à passer d'une application à l'autre et à rechercher des fichiers sur des plateformes déconnectées.
C'est là qu'un espace de travail convergent change la donne. Au lieu de générer des résumés à un seul endroit et d'essayer de les « transférer dans le travail » plus tard, un système convergent regroupe les projets, les documents et les discussions, avec ClickUp Brain intégré comme couche d'intelligence. Vos résumés restent liés aux tâches et aux documents, de sorte que la prochaine étape est évidente et que le transfert est immédiat.
Un résumé qui se transforme en action avec ClickUp
Un script de résumé peut fonctionner parfaitement et pourtant décevoir votre équipe d'une manière agaçante : le résumé finit par se retrouver quelque part, loin du travail.
Cet écart crée une prolifération de contextes, où les informations sont dispersées dans des documents, des fils de discussion, des tâches et des « notes rapides » dans des outils qui ne sont pas connectés entre eux. Les gens passent plus de temps à rechercher le résumé qu'à l'utiliser. Le véritable avantage n'est pas seulement de générer un résumé. Il s'agit de garder ce résumé lié aux décisions, aux propriétaires et aux prochaines étapes là où le travail est réellement effectué.
C'est ce qui distingue ClickUp Brain. Il résume les tâches, les documents et les discussions au sein du même espace de travail que vos projets, afin que votre équipe puisse comprendre et agir sans changer d'outil.

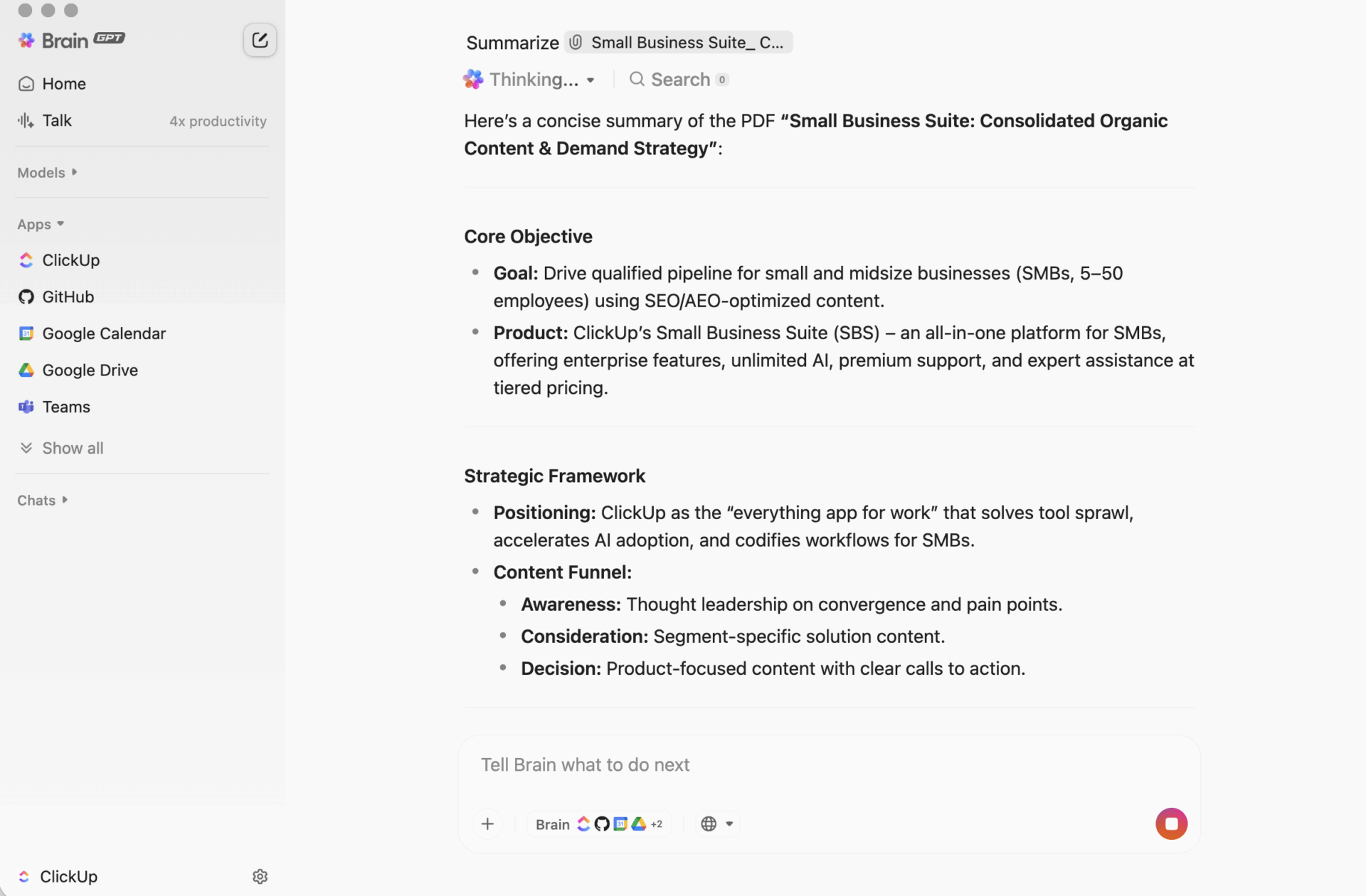
ClickUp BrainGPT : interagissez avec les résumés en utilisant le langage naturel
Sur bureau, BrainGPT est l'interface conversationnelle de ClickUp Brain. Au lieu d'ouvrir des scripts, des carnets ou des Outils d'IA externes, votre équipe peut demander ce dont elle a besoin en langage clair, directement dans ClickUp.
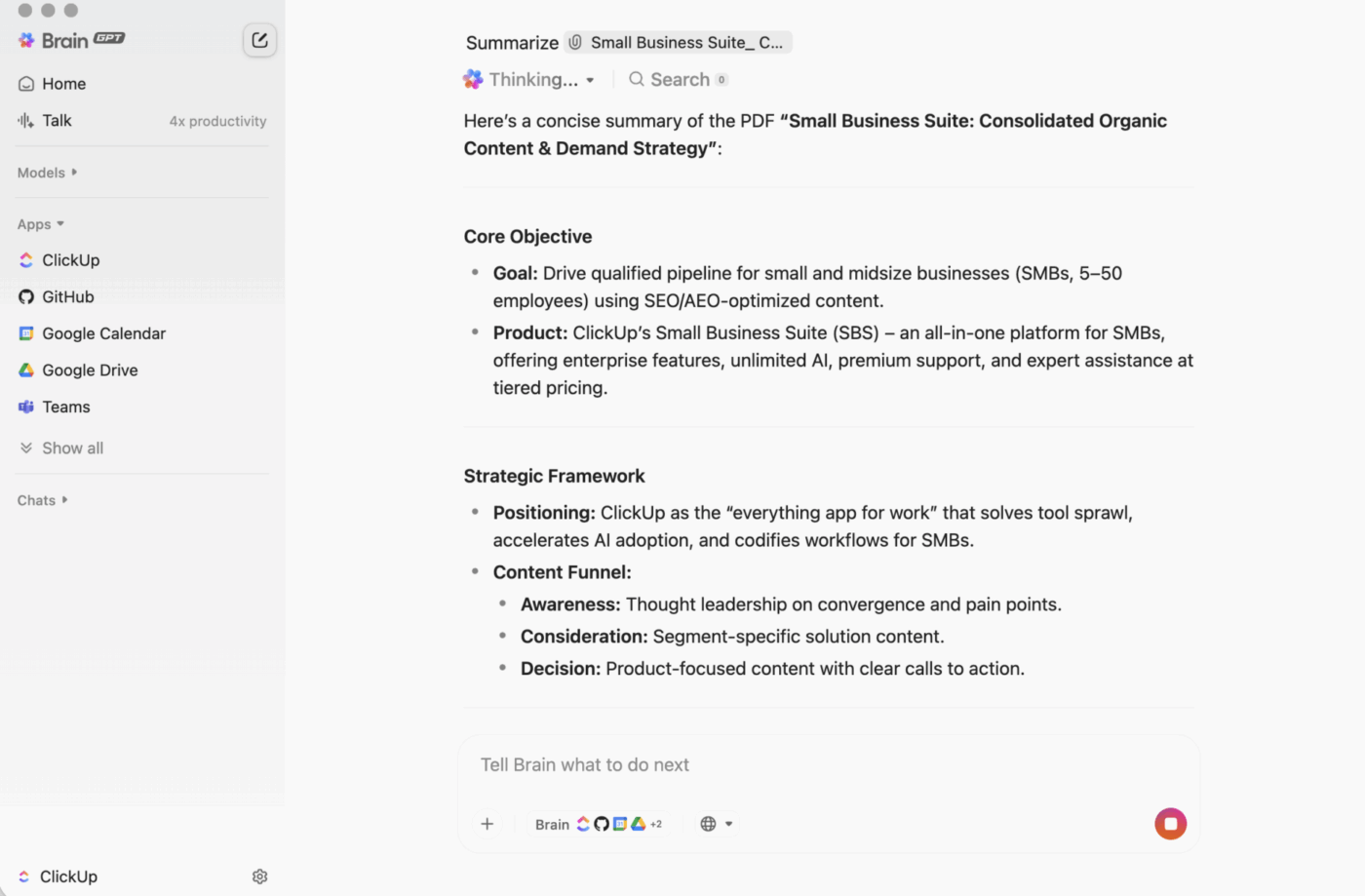
Vous pouvez taper (ou utiliser la fonction de reconnaissance vocale) pour :
- Résumez une longue description de tâche, un fil de commentaires ou un document.
- Poursuivez avec des questions telles que « Quelles sont les prochaines étapes ? » ou « Qui en est responsable ? ».
- Transformez un résumé en action en créant des tâches à partir de celui-ci, avec des propriétaires et des dates d'échéance.
Comme ClickUp Brain fonctionne au sein de votre environnement de travail, le résultat est ancré dans le contexte en temps réel : descriptions des tâches, commentaires, sous-tâches, documents liés et structure du projet. Vous n'avez pas besoin de coller du texte dans un outil séparé en espérant ne rien oublier d'important.
Pourquoi cette méthode est préférable à un flux de travail de résumé basé sur du code pour la plupart des équipes
Un flux de travail conçu par des développeurs peut générer des résumés efficaces. Les difficultés apparaissent ensuite, lorsque quelqu'un doit copier le résultat dans l'espace de travail, puis le traduire en tâches et enfin en assurer le suivi.
ClickUp Brain boucle la boucle :
Aucune connaissance en codage requiseTous les membres de l'équipe peuvent résumer un document, un fil de discussion ou un ensemble de commentaires désordonnés sans avoir à installer quoi que ce soit ni à écrire de code.
Résumés contextuelsClickUp Brain peut inclure les éléments que les gens oublient généralement : les décisions enfouies dans les commentaires, les obstacles mentionnés dans les réponses, les sous-tâches qui changent la signification du mot « terminé ».
Les résumés vivent là où se trouve le travailVous pouvez vous mettre à jour dans une tâche, ajouter un résumé en haut de ClickUp Docs ou récapituler rapidement une discussion sans créer un autre « document de résumé » que personne ne consulte.
Moins d'outilsVous n'avez pas besoin de scripts séparés, de notebooks Jupyter, de clés API ou d'un flux de travail que seule une personne comprend. Vos documents, vos tâches et vos résumés restent tous dans le même système.
C'est là l'avantage pratique d'un environnement de travail convergent : on résume, on effectue l'action et on collabore simultanément, au lieu d'être assemblées après coup.
C'est là l'avantage pratique d'un environnement de travail convergent : on résume, on effectue l'action et on collabore simultanément, au lieu d'être assemblées après coup.
Comment cela fonctionne dans la vie réelle
Voici quelques modèles courants utilisés par les équipes :
- Résumez un fil de commentaires : ouvrez une tâche comportant une longue discussion, cliquez sur l'option IA et obtenez un résumé rapide des changements et des points importants.
- Résumez un document : ouvrez un document ClickUp et utilisez « Ask IA » pour générer un résumé de la page afin que tout le monde puisse s'y retrouver rapidement.
- Extrayez les éléments à faire : prenez le résumé et convertissez immédiatement les prochaines étapes en tâches avec des personnes assignées et des dates d'échéance, afin que l'élan ne s'essouffle pas lors du transfert.
| Capacité | Hugging Face (basé sur du code) | ClickUp Brain |
|---|---|---|
| Installation requise | Environnement Python, bibliothèques, codage | Aucun, intégré |
| Conscience du contexte | Texte uniquement (ce que vous transmettez) | Contexte complet de l'environnement de travail (tâches, documents, commentaires, sous-tâches) |
| Intégration du flux de travail | Exportation/importation manuelle | Natif : les résumés peuvent devenir des tâches et des mises à jour. |
| Compétences techniques requises | Niveau développeur | Tous les membres de l'équipe |
| Maintenance | Maintenance continue du modèle et du code | Mises à jour automatiques |
Des résumés à l'exécution avec Super Agents
Les résumés sont utiles. Le plus difficile est de s'assurer qu'ils se transforment systématiquement en actions concrètes, en particulier lorsque leur volume augmente.
C'est là qu'interviennent les ClickUp Super Agents . Ils peuvent utiliser les informations résumées et faire avancer le travail en fonction de déclencheurs et de conditions, au sein du même environnement de travail.
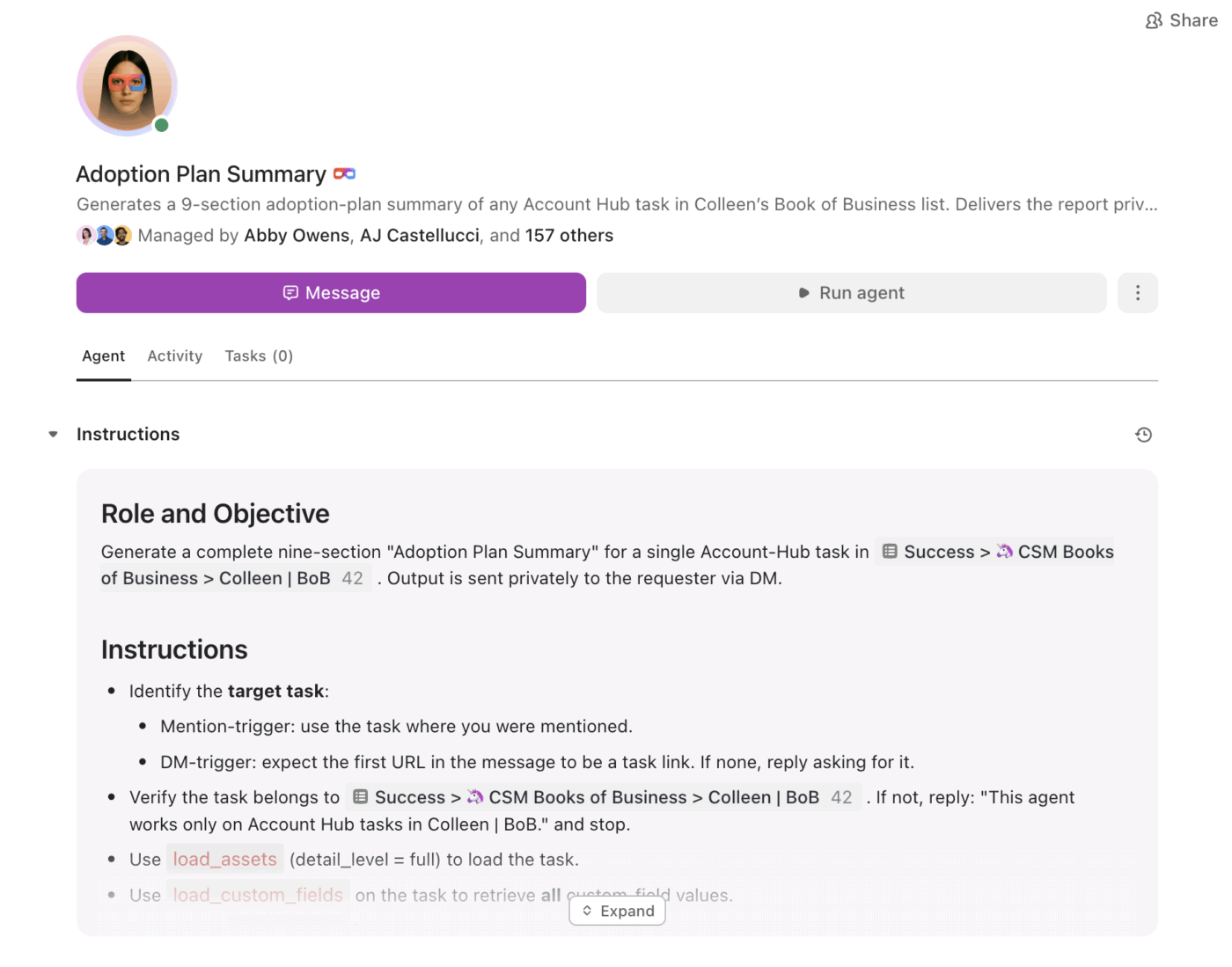
Avec Super Agents, les équipes peuvent :
- Résumez les changements selon un calendrier (récapitulatif hebdomadaire du projet, synthèses quotidiennes du statut)
- Extrayez automatiquement les éléments à entreprendre et attribuez-les à leurs propriétaires.
- Signalez le travail en suspens (tâches bloquées en cours de révision, fils de discussion sans réponse, prochaines étapes en retard)
- Maintenez une visibilité élevée sur le leadership sans rapports manuels
Au lieu d'un résumé sous forme de texte statique, les agents contribuent à faire en sorte que le résumé devienne un plan, et que le plan se transforme en progrès.
Un résumé qui vit là où le travail se fait
Les transformateurs Hugging Face sont parfaits lorsque vous avez besoin d'une application personnalisée, d'un pipeline sur mesure ou d'un contrôle total sur le comportement du modèle.
Mais pour la plupart des équipes, le plus gros problème n'est pas « Pouvons-nous résumer cela ? », mais « Pouvons-nous résumer cela et le transformer immédiatement en travail, avec des propriétaires, des délais et de la visibilité ? ».
Si votre objectif est la productivité de l'équipe et une exécution rapide, ClickUp Brain vous fournit des résumés contextualisés, là où le travail est effectué, avec un chemin clair allant de « voici l'essentiel » à « voici ce que nous allons faire ensuite ».
Prêt à passer l'étape de l'installation et à commencer à résumer là où se trouve réellement votre travail ? Commencez gratuitement avec ClickUp et laissez Brain s'occuper du gros du travail.