

Les modèles linguistiques à grande échelle (LLM) ont débloqué de nouvelles possibilités passionnantes pour les applications logicielles. Ils permettent de créer des systèmes plus intelligents et plus dynamiques que jamais.
Les experts prévoient que d'ici 2025, les applications basées sur ces modèles pourraient réaliser l'automatisation de près de la moitié du travail numérique.
Cependant, à mesure que nous débloquons ces capacités, un défi se profile : comment mesurer de manière fiable la qualité de leur production à grande échelle ? Une petite modification des paramètres suffit pour obtenir un résultat sensiblement différent. Cette variabilité peut rendre difficile l'évaluation de leurs performances, ce qui est crucial lors de la préparation d'un modèle pour une utilisation dans le monde réel.
Cet article partagera les bonnes pratiques en matière d'évaluation des systèmes LLM, des tests préalables au déploiement à la mise en production. Alors, c'est parti !
Qu'est-ce qu'une évaluation LLM ?
Les indicateurs d'évaluation LLM permettent de déterminer si vos instructions, vos paramètres de modèle ou votre flux de travail atteignent les objectifs que vous vous êtes fixés. Ces indicateurs vous donnent un aperçu des performances de votre modèle linguistique à grande échelle et vous permettent de savoir s'il est vraiment prêt à être utilisé dans le monde réel.
Aujourd'hui, certains des indicateurs les plus courants mesurent la mémorisation du contexte dans les tâches de génération augmentée par la recherche (RAG), les correspondances exactes pour les classifications, la validation JSON pour les sorties structurées et la similarité sémantique pour les tâches plus créatives.
Chacun de ces indicateurs garantit de manière unique que le LLM répond aux normes de votre cas d'utilisation spécifique.
Pourquoi avez-vous besoin d'évaluer un LLM ?
Les modèles linguistiques à grande échelle (LLM) sont désormais utilisés dans un large éventail d'applications. Il est essentiel d'évaluer les performances des modèles afin de s'assurer qu'ils répondent aux normes attendues et qu'ils remplissent efficacement les objectifs fixés.
Considérez les choses sous cet angle : les LLM sont à la base de tout, des chatbots de service client aux outils créatifs, et à mesure qu'ils deviennent plus avancés, ils apparaissent dans de plus en plus d'endroits.
Cela signifie que nous avons besoin de meilleurs moyens pour les surveiller et les évaluer : les méthodes traditionnelles ne suffisent tout simplement pas pour toutes les tâches que ces modèles traitent.
De bons indicateurs d'évaluation sont comme un contrôle qualité pour les LLM. Ils montrent si le modèle est suffisamment fiable, précis et efficace pour être utilisé dans le monde réel. Sans ces contrôles, des erreurs pourraient passer inaperçues, ce qui conduirait à des expériences utilisateur frustrantes, voire trompeuses.
Lorsque vous disposez de indicateurs d'évaluation fiables, il est plus facile de repérer les problèmes, d'améliorer le modèle et de vous assurer qu'il est prêt à répondre aux besoins spécifiques de ses utilisateurs. Vous savez ainsi que la plateforme d'IA avec laquelle vous travaillez est conforme aux normes et peut fournir les résultats dont vous avez besoin.
📖 En savoir plus : LLM vs IA générative : guide détaillé
Types d'évaluations LLM
Les évaluations offrent une perspective unique pour examiner les capacités du modèle. Chaque type aborde différents aspects de la qualité, ce qui permet de créer un modèle de déploiement fiable, sûr et efficace.
Voici les différents types de méthodes d'évaluation LLM :
- L'évaluation intrinsèque se concentre sur les performances internes du modèle pour des tâches linguistiques ou de compréhension spécifiques, sans impliquer d'applications concrètes. Elle est généralement réalisée pendant l'étape de développement du modèle afin de comprendre ses capacités fondamentales.
- L'évaluation extrinsèque évalue les performances du modèle dans des applications concrètes. Ce type d'évaluation examine dans quelle mesure le modèle répond à des objectifs spécifiques dans un contexte donné.
- L'évaluation de la robustesse teste la stabilité et la fiabilité du modèle dans divers scénarios, y compris des entrées inattendues et des conditions défavorables. Elle identifie les faiblesses potentielles, garantissant ainsi que le modèle se comporte de manière prévisible.
- Les tests d'efficacité et de latence examinent l'utilisation des ressources, la vitesse et la latence du modèle. Ils garantissent que le modèle peut effectuer des tâches rapidement et à un coût de calcul raisonnable, ce qui est essentiel pour la scalabilité.
- L'évaluation éthique et de sécurité garantit que le modèle est conforme aux normes éthiques et aux directives de sécurité, ce qui est essentiel dans les applications sensibles.
Évaluations des modèles LLM vs évaluations des systèmes LLM
L'évaluation des grands modèles linguistiques (LLM) repose sur deux approches principales : l'évaluation des modèles et l'évaluation des systèmes. Chacune se concentre sur différents aspects des performances des LLM, et il est essentiel de connaître la différence entre les deux pour maximiser le potentiel de ces modèles.
🧠 Les évaluations de modèles examinent les compétences générales du LLM. Ce type d'évaluation teste la capacité du modèle à comprendre, générer et utiliser le langage avec précision dans divers contextes. Cela revient à évaluer la capacité du modèle à gérer différentes tâches, un peu comme un test d'intelligence générale.
Par exemple, les évaluations de modèles peuvent poser la question suivante : « Quel est le degré de polyvalence de ce modèle ? »
🎯 Les évaluations du système LLM mesurent les performances du LLM dans une installation ou un objectif spécifique, comme dans un chatbot de service client. Ici, il s'agit moins des capacités générales du modèle que de la manière dont il effectue des tâches spécifiques pour améliorer l'expérience de l'utilisateur.
Les évaluations du système, quant à elles, se concentrent sur des questions telles que « Dans quelle mesure le modèle gère-t-il cette tâche spécifique pour les utilisateurs ? »
Les évaluations de modèles aident les développeurs à comprendre les capacités et les limites globales du LLM, ce qui leur permet d'apporter des améliorations. Les évaluations du système se concentrent sur la manière dont le LLM répond aux besoins des utilisateurs dans des contextes spécifiques, garantissant ainsi une expérience utilisateur plus fluide.
Ensemble, ces évaluations fournissent une image complète des points forts et des domaines à améliorer du LLM, le rendant plus puissant et plus convivial dans les applications réelles.
Explorons maintenant les indicateurs spécifiques à l'évaluation LLM.
Indicateurs pour l'évaluation LLM
Voici quelques indicateurs d'évaluation fiables et tendance :
1. Perplexité
La perplexité mesure la capacité d'un modèle linguistique à prédire une séquence de mots. Essentiellement, elle indique le degré d'incertitude du modèle quant au mot suivant dans une phrase. Un score de perplexité faible signifie que le modèle est plus sûr de ses prédictions, ce qui se traduit par de meilleures performances.
📌 Exemple : imaginez qu'un modèle génère du texte à partir de l'invite « Le chat s'est assis sur le... ». S'il prédit une forte probabilité pour des mots tels que « tapis » et « sol », cela signifie qu'il comprend bien le contexte, ce qui entraîne un faible score de perplexité comme résultat.
En revanche, s'il suggère un mot sans rapport, tel que « vaisseau spatial », le score de perplexité sera plus élevé, indiquant que le modèle a du mal à prédire un texte sensé.
2. Score BLEU
Le score BLEU (Bilingual Evaluation Understudy) est principalement utilisé pour évaluer la traduction automatique et la génération de texte.
Elle mesure le nombre de n-grammes (séquences contiguës de n éléments provenant d'un échantillon de texte donné) dans la sortie qui chevauchent ceux d'un ou plusieurs textes de référence. L'intervalle de score varie de 0 à 1, les scores les plus élevés indiquant les meilleures performances.
📌 Exemple : si votre modèle génère la phrase « The quick brown fox jumps over the lazy dog » (Le renard brun rapide saute par-dessus le chien paresseux) et que le texte de référence est « A fast brown fox leaps over a lazy dog » (Un renard brun rapide bondit par-dessus un chien paresseux), BLEU comparera les n-grammes communs.
Un score élevé indique que la phrase générée correspond étroitement à la référence, tandis qu'un score plus faible peut suggérer que le résultat généré n'est pas tout à fait adapté.
3. Score F1
La métrique d'évaluation LLM F1 score est principalement utilisée pour les tâches de classification. Elle mesure l'équilibre entre la précision (l'exactitude des prédictions positives) et le rappel (la capacité à identifier toutes les instances pertinentes).
L'intervalle va de 0 à 1, où une note de 1 indique une précision parfaite.
📌 Exemple : dans une tâche de réponse à une question, si l'on demande au modèle « De quelle couleur est le ciel ? » et qu'il répond « Le ciel est bleu » (véritable positif) mais inclut également « Le ciel est vert » (faux positif), le score F1 tiendra compte à la fois de la pertinence de la réponse correcte et de celle incorrecte.
Cet indicateur permet de garantir une évaluation équilibrée des performances du modèle.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) va au-delà de la correspondance exacte des mots. Il prend en compte les synonymes, les racines et les paraphrases pour évaluer la similitude entre le texte généré et le texte de référence. Cet indicateur vise à se rapprocher davantage du jugement humain.
📌 Exemple : si votre modèle génère « Le félin se reposait sur le tapis » et que la référence est « Le chat était allongé sur le tapis », METEOR attribuera une note plus élevée que BLEU, car il reconnaît que « félin » est un synonyme de « chat » et que « tapis » et « moquette » ont des significations similaires.
Cela rend METEOR particulièrement utile pour saisir les nuances du langage.
5. BERTScore
BERTScore évalue la similarité des textes en se basant sur des intégrations contextuelles dérivées de modèles tels que BERT (Bidirectional Encoder Representations from Transformers). Il se concentre davantage sur le sens que sur la correspondance exacte des mots, ce qui permet une meilleure évaluation de la similarité sémantique.
📌 Exemple : lorsque l'on compare les phrases « La voiture a foncé sur la route » et « Le véhicule a roulé à toute vitesse dans la rue », BERTScore analyse les significations sous-jacentes plutôt que le simple choix des mots.
Même si les mots diffèrent, les idées générales sont similaires, ce qui conduit à un BERTScore élevé qui reflète l'efficacité du contenu généré.
6. Évaluation humaine
L'évaluation humaine reste un aspect crucial de l'évaluation LLM. Elle implique que des juges humains évaluent la qualité des résultats du modèle en fonction de divers critères tels que la fluidité et la pertinence. Des techniques telles que les échelles de Likert et les tests A/B peuvent être utilisées pour recueillir des commentaires.
📌 Exemple : après avoir généré des réponses à partir d'un chatbot de service client, des évaluateurs humains peuvent effectuer l'évaluation de chaque réponse sur une échelle de 1 à 5. Par exemple, si le chatbot fournit une réponse claire et utile à la demande d'un client, il peut recevoir un 5, tandis qu'une réponse vague ou confuse peut obtenir un 2.
7. Indicateurs spécifiques aux tâches
Les différentes tâches LLM nécessitent des indicateurs d'évaluation adaptés.
Pour les systèmes de dialogue, les indicateurs peuvent évaluer l'engagement des utilisateurs ou les taux d'achèvement des tâches. Pour la génération de code, la réussite peut être mesurée par la fréquence à laquelle le code généré est compilé ou passe les tests.
📌 Exemple : dans un chatbot de service client, les niveaux d'engagement peuvent être mesurés en fonction de la durée pendant laquelle les utilisateurs restent dans une discussion ou du nombre de questions complémentaires qu'ils posent.
Si les utilisateurs demandent fréquemment des informations supplémentaires, cela indique que le modèle réussit à les intéresser et à répondre efficacement à leurs requêtes.
8. Robustesse et équité
L'évaluation de la robustesse d'un modèle implique de tester sa capacité à répondre à des entrées inattendues ou inhabituelles. Les indicateurs d'équité permettent d'identifier les biais dans les résultats du modèle, garantissant ainsi qu'il fonctionne de manière équitable pour différents groupes démographiques et scénarios.
📌 Exemple : lorsque vous testez un modèle avec une question fantaisiste telle que « Que pensez-vous des licornes ? », celui-ci doit traiter la question avec élégance et fournir une réponse pertinente. S'il donne à la place une réponse absurde ou inappropriée, cela indique un manque de robustesse.
Les tests d'équité garantissent que le modèle ne produit pas de résultats biaisés ou préjudiciables, favorisant ainsi un système d'IA plus inclusif.
9. Indicateurs d'efficacité
À mesure que les modèles linguistiques gagnent en complexité, il devient de plus en plus important de mesurer leur efficacité en termes de vitesse, d'utilisation de la mémoire et de consommation d'énergie. Les indicateurs d'efficacité permettent d'évaluer la quantité de ressources nécessaires à un modèle pour générer des réponses.
📌 Exemple : pour un modèle linguistique de grande taille, la mesure de l'efficacité peut impliquer le suivi de la rapidité avec laquelle il génère des réponses aux requêtes des utilisateurs et la quantité de mémoire qu'il utilise pendant ce processus.
Si la réponse prend trop de temps ou consomme trop de ressources, cela peut poser problème pour les applications qui nécessitent des performances en temps réel, comme les chatbots ou les services de traduction.
Vous savez désormais comment évaluer un modèle LLM. Mais quels outils pouvez-vous utiliser pour mesurer cela ? Explorons cela ensemble.
Comment ClickUp Brain peut améliorer l'évaluation LLM
ClickUp est une application tout-en-un pour le travail, dotée d'un assistant personnel intégré appelé ClickUp Brain.
ClickUp Brain change la donne en matière d'évaluation des performances LLM. Alors, qu'est-ce que ClickUp Brain fait exactement ?
Il organise et met en évidence les données les plus pertinentes, permettant ainsi à votre équipe de rester sur la bonne voie. Grâce à ses fonctionnalités basées sur l'IA, ClickUp Brain est l'un des meilleurs logiciels de réseau neuronal disponibles sur le marché. Il rend l'ensemble du processus plus fluide, plus efficace et plus collaboratif que jamais. Découvrons ensemble ses capacités.
Gestion intelligente des connaissances
Lors de l'évaluation des modèles linguistiques à grande échelle (LLM), la gestion de grandes quantités de données peut s'avérer fastidieuse.

ClickUp Brain peut organiser et mettre en évidence les indicateurs et les ressources essentiels spécialement adaptés à l'évaluation LLM. Au lieu de fouiller dans des feuilles de calcul éparpillées et des rapports denses, ClickUp Brain rassemble tout en un seul endroit. Les indicateurs de performance, les données de benchmarking et les résultats des tests sont tous accessibles dans une interface claire et conviviale.
Cette organisation aide votre équipe à faire abstraction du bruit ambiant et à se concentrer sur les informations qui comptent vraiment, ce qui facilite l'interprétation des tendances et des modèles de performance.
Avec tout ce dont vous avez besoin à portée de main, vous pouvez passer de la simple collecte de données à une prise de décision efficace et fondée sur les données, transformant ainsi la surcharge d'informations en renseignements exploitables.
Planification de projet et gestion du flux de travail
Les évaluations LLM nécessitent une planification et une collaboration minutieuses, et ClickUp facilite la gestion de ce processus.
Vous pouvez facilement déléguer des responsabilités telles que la collecte de données, la formation de modèles et les tests de performance, tout en définissant des priorités afin de vous assurer que les tâches les plus critiques reçoivent toute l'attention nécessaire. En outre, les champs personnalisés vous permettent d'adapter les flux de travail aux besoins spécifiques de votre projet.

Avec ClickUp, tout le monde peut voir qui fait quoi et quand, ce qui permet d'éviter les retards et de garantir le bon déroulement des tâches au sein de l'équipe. C'est un excellent moyen de tout organiser et de rester sur la bonne voie du début à la fin.
Suivi des indicateurs via des tableaux de bord personnalisés
Vous souhaitez suivre de près les performances de vos systèmes LLM ?
Les tableaux de bord ClickUp visualisent les indicateurs de performance en temps réel. Ils vous permettent de suivre instantanément la progression de votre modèle. Ces tableaux de bord sont hautement personnalisables, vous permettant de créer des graphiques et des diagrammes qui présentent exactement ce dont vous avez besoin, quand vous en avez besoin.
Vous pouvez observer l'évolution de la précision de votre modèle au fil des étapes d'évaluation ou analyser la consommation de ressources à chaque phase. Ces informations vous permettent de repérer rapidement les tendances, d'identifier les points à améliorer et d'apporter des ajustements à la volée.
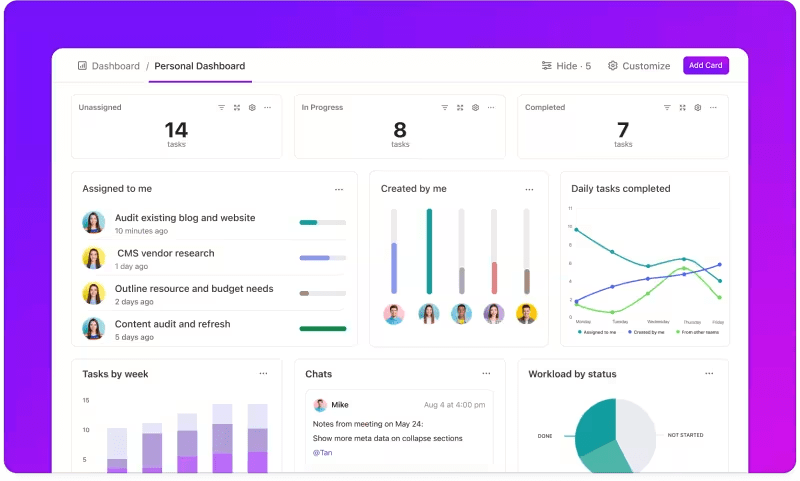
Au lieu d'attendre le prochain rapport détaillé, les tableaux de bord ClickUp vous permettent de rester informé et réactif, permettant ainsi à votre équipe de prendre des décisions fondées sur des données sans délai.
Informations automatisées
L'analyse des données peut prendre beaucoup de temps, mais les fonctionnalités de ClickUp Brain allègent la charge de travail en fournissant des informations précieuses. Elles mettent en évidence les tendances importantes et suggèrent même des recommandations basées sur les données, ce qui facilite la formulation de conclusions pertinentes.
Grâce aux informations automatisées de ClickUp Brain, vous n'avez plus besoin de passer au crible les données brutes pour détecter des tendances manuellement : le logiciel les repère pour vous. Cette automatisation permet à votre équipe de se concentrer sur l'amélioration des performances du modèle plutôt que de s'enliser dans des analyses de données répétitives.
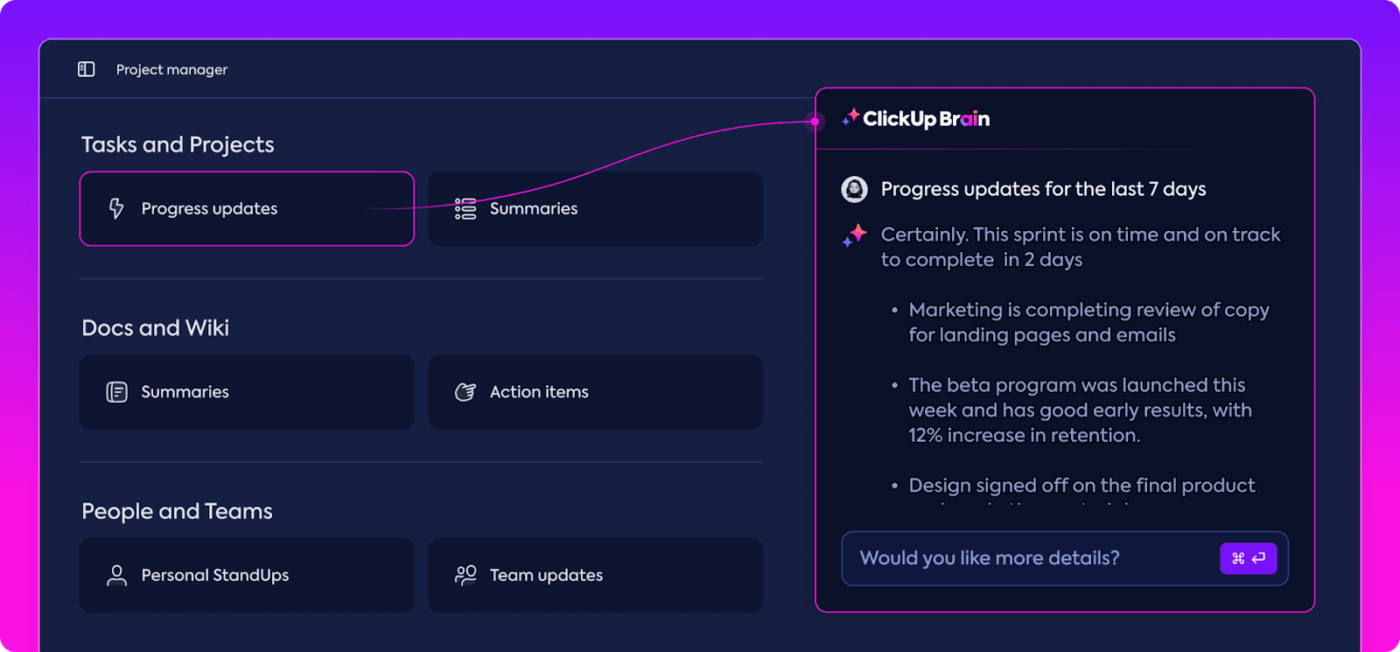
Les informations générées sont prêtes à l'emploi, ce qui permet à votre équipe de voir immédiatement ce qui fonctionne et où des changements pourraient être nécessaires. En réduisant le temps consacré à l'analyse, ClickUp aide votre équipe à accélérer le processus d'évaluation et à se concentrer sur la mise en œuvre.
Documentation et collaboration
Plus besoin de fouiller dans vos e-mails ou sur plusieurs plateformes pour trouver ce dont vous avez besoin ; tout est là, à votre disposition, quand vous le souhaitez.
ClickUp Docs est une plateforme centrale qui rassemble tout ce dont votre équipe a besoin pour une évaluation LLM fluide. Elle organise les documents clés du projet, tels que les critères de référence, les résultats des tests et les journaux de performance, en un seul endroit accessible afin que chacun puisse rapidement accéder aux dernières informations.
Ce qui distingue vraiment ClickUp Docs, ce sont ses fonctionnalités de collaboration en temps réel. Le chat et les commentaires intégrés à ClickUp permettent aux membres de l'équipe de discuter, de donner leur avis et de suggérer des modifications directement dans les documents.
Cela signifie que votre équipe peut discuter des résultats et apporter des ajustements directement sur la plateforme, en veillant à ce que toutes les discussions restent pertinentes et ciblées.

Tout, de la documentation au travail d'équipe, se fait dans ClickUp Docs, ce qui permet de créer un processus d'évaluation rationalisé où chacun peut voir, partager et agir sur les derniers développements.
Le résultat ? Un flux de travail fluide et unifié qui permet à votre équipe d'avancer vers ses objectifs en toute clarté.
Êtes-vous prêt à essayer ClickUp ? Avant cela, voyons quelques conseils et astuces pour tirer le meilleur parti de votre évaluation LLM.
Bonnes pratiques en matière d'évaluation LLM
Une approche bien structurée de l'évaluation LLM garantit que le modèle répond à vos besoins, correspond aux attentes des utilisateurs et fournit des résultats significatifs.
Définir des objectifs clairs, prendre en compte les utilisateurs finaux et utiliser divers indicateurs permet de mettre en place une évaluation approfondie qui révèle les points forts et les domaines à améliorer. Vous trouverez ci-dessous quelques bonnes pratiques pour vous guider dans votre processus.
🎯 Définissez des objectifs clairs
Avant de commencer le processus d'évaluation, il est essentiel de savoir exactement ce que vous attendez de votre modèle linguistique à grande échelle (LLM). Prenez le temps de définir les tâches ou les objectifs spécifiques du modèle.
📌 Exemple : si vous souhaitez améliorer les performances de la traduction automatique, clarifiez les niveaux de qualité que vous souhaitez atteindre. Le fait d'avoir des objectifs clairs vous aide à vous concentrer sur les indicateurs les plus pertinents, garantissant ainsi que votre évaluation reste alignée sur ces objectifs et mesure avec précision la réussite.
👥 Tenez compte de votre public
Réfléchissez aux utilisateurs du LLM et à leurs besoins. Il est essentiel d'adapter l'évaluation à vos utilisateurs cibles.
📌 Exemple : si votre modèle est destiné à générer du contenu attrayant, vous devrez porter une attention particulière à des indicateurs tels que la fluidité et la cohérence. Comprendre votre public vous aidera à affiner vos critères d'évaluation, afin de vous assurer que le modèle apporte une réelle valeur ajoutée dans les applications pratiques.
📊 Utilisez divers indicateurs
Ne vous fiez pas à un seul indicateur pour évaluer votre LLM ; une combinaison d'indicateurs vous donnera une image plus complète de ses performances. Chaque indicateur capture différents aspects, donc en utiliser plusieurs peut vous aider à identifier à la fois les forces et les faiblesses.
📌 Exemple : si les scores BLEU sont excellents pour mesurer la qualité d'une traduction, ils ne couvrent pas nécessairement toutes les nuances de l'écriture créative. L'intégration d'indicateurs tels que la perplexité pour la précision prédictive, voire des évaluations humaines pour le contexte, peut permettre de mieux comprendre les performances de votre modèle.
Références et outils LLM
L'évaluation des grands modèles linguistiques (LLM) repose souvent sur des benchmarks standardisés et des outils spécialisés qui permettent de mesurer les performances des modèles dans diverses tâches.
Voici une liste de certains benchmarks et outils largement utilisés qui apportent structure et clarté au processus d'évaluation.
Indicateurs clés
- GLUE (General Language Understanding Evaluation) : GLUE évalue les capacités des modèles à travers plusieurs tâches linguistiques, notamment la classification des phrases, la similarité et l'inférence. Il s'agit d'une référence incontournable pour les modèles qui doivent gérer la compréhension du langage général.
- SQuAD (Stanford Question Answering Dataset) : le cadre d'évaluation SQuAD est idéal pour la compréhension écrite et mesure la capacité d'un modèle à répondre à des questions basées sur un passage de texte. Il est couramment utilisé pour des tâches telles que le service client et la recherche basée sur les connaissances, où la précision des réponses est cruciale.
- SuperGLUE : version améliorée de GLUE, SuperGLUE évalue les modèles sur des tâches de raisonnement et de compréhension contextuelle plus complexes. Il fournit des informations plus approfondies, en particulier pour les applications nécessitant une compréhension avancée du langage.
Outils d'évaluation essentiels
- Hugging Face : très populaire pour sa vaste bibliothèque de modèles, ses ensembles de données et ses fonctionnalités d'évaluation. Son interface très intuitive permet aux utilisateurs de sélectionner facilement des benchmarks, de personnaliser les évaluations et de suivre les performances des modèles, ce qui le rend polyvalent pour de nombreuses applications LLM.
- SuperAnnotate: cet outil est spécialisé dans la gestion et l'annotation des données, ce qui est essentiel pour les tâches d'apprentissage supervisé. Il est particulièrement utile pour affiner la précision des modèles, car il facilite l'obtention de données annotées par des humains de haute qualité qui améliorent les performances des modèles sur des tâches complexes.
- AllenNLP: Développé par l'Allen Institute for IA, AllenNLP s'adresse aux chercheurs et développeurs travaillant sur des modèles NLP personnalisés. Il prend en charge un intervalle de benchmarks et fournit des outils pour former, tester et évaluer des modèles linguistiques, offrant ainsi une grande flexibilité pour diverses applications NLP.
L'utilisation combinée de ces repères et outils offre une approche complète de l'évaluation LLM. Les repères permettent de définir des normes pour toutes les tâches, tandis que les outils fournissent la structure et la flexibilité nécessaires pour suivre, affiner et améliorer efficacement les performances du modèle.
Ensemble, ils garantissent que les LLM répondent à la fois aux normes techniques et aux besoins pratiques.
Les défis de l'évaluation des modèles LLM
L'évaluation des grands modèles linguistiques (LLM) nécessite une approche nuancée. Elle se concentre sur la qualité des réponses et la compréhension de l'adaptabilité et des limites du modèle dans divers scénarios.
Comme ces modèles sont entraînés sur des ensembles de données volumineux, leur comportement est influencé par divers facteurs, ce qui rend indispensable d'évaluer plus que leur seule précision.
Une véritable évaluation consiste à examiner la fiabilité du modèle, sa résilience face à des invitations inhabituelles et la cohérence globale de ses réponses. Ce processus permet de dresser un tableau plus clair des forces et des faiblesses du modèle et de mettre en évidence les domaines à améliorer.
Voici un aperçu des défis courants qui se posent lors de l'évaluation LLM.
1. Chevauchement des données d'entraînement
Il est difficile de savoir si le modèle a déjà « vu » certaines des données de test. Les LLM étant entraînés sur des ensembles de données massifs, il est possible que certaines questions de test recoupent des exemples d'entraînement. Cela peut donner l'impression que le modèle est plus performant qu'il ne l'est en réalité, car il se peut qu'il se contente de répéter ce qu'il sait déjà au lieu de démontrer une véritable compréhension.
2. Performances inégales
Les LLM peuvent avoir des réponses imprévisibles. À un moment donné, ils fournissent des informations impressionnantes, et l'instant d'après, ils commettent des erreurs étranges ou présentent des informations imaginaires comme des faits (ce que l'on appelle des « hallucinations »).
Cette incohérence signifie que si les résultats du LLM peuvent être excellents dans certains domaines, ils peuvent être insuffisants dans d'autres, ce qui rend difficile d'évaluer avec précision sa fiabilité et sa qualité globales.
3. Vulnérabilités adversaires
Les LLM peuvent être vulnérables aux attaques adversaires, dans lesquelles des instructions habilement conçues les incitent à produire des réponses erronées ou nuisibles. Cette vulnérabilité expose les faiblesses du modèle et peut conduire à des résultats inattendus ou biaisés. Il est essentiel de tester ces faiblesses adversaires pour comprendre où se situent les limites du modèle.
Cas d'utilisation pratiques de l'évaluation LLM
Enfin, voici quelques situations courantes dans lesquelles l'évaluation LLM fait vraiment la différence :
Chatbots d'assistance au service client
Les LLM sont largement utilisés dans les chatbots pour traiter les requêtes des clients. Évaluer la qualité des réponses du modèle permet de s'assurer qu'il fournit des réponses précises, utiles et pertinentes dans le contexte.
Il est essentiel de mesurer sa capacité à comprendre l'intention du client, à traiter des questions diverses et à fournir des réponses semblables à celles d'un humain. Cela permettra aux entreprises de garantir une expérience client fluide tout en minimisant la frustration.
Génération de contenu
De nombreuses entreprises utilisent les LLM pour générer du contenu pour leurs blogs, leurs réseaux sociaux et leurs descriptions de produits. Évaluer la qualité du contenu généré permet de s'assurer qu'il est grammaticalement correct, attrayant et pertinent pour le public cible. Des indicateurs tels que la créativité, la cohérence et la pertinence par rapport au sujet sont importants pour maintenir un niveau de contenu élevé.
Analyse des sentiments
Les LLM peuvent analyser le sentiment exprimé dans les commentaires des clients, les publications sur les réseaux sociaux ou les avis sur les produits. Il est essentiel d'évaluer la précision avec laquelle le modèle identifie si un texte est positif, négatif ou neutre. Cela aide les entreprises à comprendre les émotions des clients, à affiner leurs produits ou services, à améliorer la satisfaction des utilisateurs et à optimiser leurs stratégies marketing.
Génération de code
Les développeurs utilisent souvent les LLM pour les aider à générer du code. Il est essentiel d'évaluer la capacité du modèle à produire un code fonctionnel et efficace.
Il est important de vérifier si le code généré est logique, exempt d'erreurs et répond aux exigences de la tâche. Cela permet de réduire la quantité de codage manuel nécessaire et d'améliorer la productivité.
Optimisez votre évaluation LLM avec ClickUp
Pour évaluer les LLM, il s'agit avant tout de choisir les bons indicateurs qui correspondent à vos objectifs. La clé est de comprendre vos objectifs spécifiques, qu'il s'agisse d'améliorer la qualité de la traduction, d'optimiser la génération de contenu ou d'affiner des tâches spécialisées.
La sélection des bons indicateurs pour évaluer les performances, tels que les indicateurs RAG ou de réglage fin, constitue la base d'une évaluation précise et pertinente. Parallèlement, des systèmes de notation avancés tels que G-Eval, Prometheus, SelfCheckGPT et QAG fournissent des informations précises grâce à leurs solides capacités de raisonnement.
Cependant, cela ne signifie pas que ces scores sont parfaits : il est toujours important de s'assurer qu'ils sont fiables.
Au fur et à mesure que vous avancez dans l'évaluation de votre application LLM, adaptez le processus à votre cas d'utilisation spécifique. Il n'existe pas d'indicateur universel qui fonctionne dans tous les cas de figure. Une combinaison d'indicateurs, associée à une attention particulière portée au contexte, vous donnera une image plus précise des performances de votre modèle.
Pour rationaliser votre évaluation LLM et améliorer la collaboration au sein de votre équipe, ClickUp est la solution idéale pour gérer les flux de travail et suivre les indicateurs importants.
Vous souhaitez améliorer la productivité de votre équipe ? Inscrivez-vous dès aujourd'hui à ClickUp et découvrez comment cet outil peut transformer votre flux de travail !