![So trainieren Sie Gemini mit Ihren eigenen Daten im Jahr [Jahr]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Laut einer aktuellen Studie des Unternehmens geben 73 % der Organisationen an, dass ihre KI-Modelle die unternehmensspezifische Terminologie und den Kontext nicht verstehen, was zu Ergebnissen führt, die umfangreiche manuelle Korrekturen erfordern. Dies wird zu einer der größten Herausforderungen bei der Einführung von KI.
Große Sprachmodelle wie Google Gemini sind bereits anhand umfangreicher öffentlicher Datensätze trainiert. Was die meisten Unternehmen wirklich brauchen, ist nicht das Training eines neuen Modells, sondern Gemini Ihren Geschäftskontext beizubringen: Ihre Dokumente, Workflows, Kunden und internes Wissen.
Diese Anleitung führt Sie durch den gesamten Prozess des Trainings des Gemini-Modells von Google mit Ihren eigenen Daten. Wir behandeln alles von der Vorbereitung der Datensätze im richtigen JSONL-Format bis zur Ausführung von Optimierungsaufträgen in Google AI Studio.
Wir werden auch untersuchen, ob ein konvergierter Workspace mit integrierter KI-Kontextfunktionalität Ihnen Wochen an Setup-Zeit sparen könnte.
Was ist Gemini Fine-Tuning und warum ist es wichtig?
Die Feinabstimmung von Gemini ist der Prozess, bei dem das Basismodell von Google anhand Ihrer eigenen Daten trainiert wird.
Sie möchten eine KI, die Ihr Geschäft versteht, aber vorgefertigte Modelle liefern generische Antworten, die ihr Ziel verfehlen. Das bedeutet, dass Sie Zeit damit verschwenden, die Ergebnisse ständig zu korrigieren, die Terminologie Ihres Unternehmens erneut zu erklären und sich zu ärgern, wenn die KI es einfach nicht versteht.
Dieses ständige Hin und Her bremst Ihr Team und untergräbt das Versprechen der Produktivität der KI.
Durch die Feinabstimmung von Gemini wird ein benutzerdefiniertes Gemini-Modell erstellt, das Ihre spezifischen Muster, Ihren Tonfall und Ihr Fachwissen lernt, sodass es genauer auf Ihre individuellen Anwendungsfälle reagieren kann. Dieser Ansatz eignet sich am besten für konsistente, wiederholbare Aufgaben, bei denen das Basismodell wiederholt versagt.
Wie sich Feinabstimmung von Prompt Engineering unterscheidet
Beim Prompt Engineering erhält das Modell bei jeder Interaktion temporäre, sitzungsbasierte Anweisungen. Sobald die Unterhaltung beendet ist, vergisst das Modell Ihren Kontext.
Dieser Ansatz stößt an seine Grenzen, wenn Ihr Anwendungsfall spezielle Kenntnisse erfordert, über die das Basismodell einfach nicht verfügt. Sie können nur eine begrenzte Anzahl von Anweisungen geben, bevor das Modell Ihre Muster tatsächlich lernen muss.
Im Gegensatz dazu passt die Feinabstimmung das Verhalten des Modells dauerhaft an, indem sie seine internen Gewichte auf der Grundlage Ihrer Trainingsbeispiele modifiziert, sodass die Änderungen in allen zukünftigen Sitzungen bestehen bleiben.
Die Feinabstimmung ist keine schnelle Lösung für gelegentliche Frustrationen mit /AI, sondern eine erhebliche Investition an Zeit und Daten. Sie ist vor allem in bestimmten Szenarien sinnvoll, in denen das Basismodell durchweg unzureichend ist und Sie eine dauerhafte Lösung benötigen.
Erwägen Sie eine Feinabstimmung, wenn Sie möchten, dass die KI Folgendes beherrscht:
- Fachterminologie: In Ihrer Branche werden Fachbegriffe verwendet, die das Modell immer wieder falsch interpretiert oder nicht richtig verwendet.
- Konsistentes Format für die Ausgabe: Sie benötigen jedes Mal Antworten in einer ganz bestimmten Struktur, z. B. für die Berichterstellung oder zum Erstellen von Code-Schnipseln.
- Fachwissen: Dem Modell fehlen Kenntnisse über Ihre Nischenprodukte, internen Prozesse oder proprietären Workflows.
- Markenstimme: Sie möchten, dass alle KI-generierten Ergebnisse perfekt zur Markenstimme, zum Stil und zur Persönlichkeit Ihres Unternehmens passen.
| Aspekt | Prompt Engineering | Feinabstimmung |
| Was ist das? | Erstellen Sie bessere Anweisungen in der Eingabeaufforderung, um das Modellverhalten zu steuern. | Weiteres Trainieren des Modells anhand Ihrer eigenen Beispiele |
| Was ändert sich? | Die Eingabe, die Sie an das Modell senden | Die internen Gewichte des Modells |
| Schnelle Implementierung | Sofort – funktioniert sofort | Langsam – erfordert Zeit für die Vorbereitung des Datensatzes und das Training |
| Technische Komplexität | Gering – keine ML-Kenntnisse erforderlich | Mittel bis hoch – erfordert ML-Pipelines |
| Erforderliche Daten | Einige gute Beispiele innerhalb der Eingabeaufforderung | Hunderte bis Tausende von Beispielen mit Beschreibung |
| Konsistenz der Ausgabe | Mittel – variiert je nach Eingabeaufforderung | Hoch – das Verhalten ist in das Modell integriert |
| Am besten geeignet für | Einmalige Aufgaben, Experimente, schnelle Iteration | Wiederkehrende Aufgaben, die konsistente Ergebnisse erfordern |
Prompt Engineering gibt der Form vor, was Sie dem Modell mitteilen. Die Feinabstimmung gibt der Form vor, wie das Modell denkt.
Dieser Artikel konzentriert sich zwar auf Gemini, aber das Verständnis alternativer Ansätze zur benutzerdefinierten KI-Anpassung kann wertvolle Einblicke in verschiedene Methoden zur Erreichung ähnlicher Ziele liefern.
Dieses Video zeigt , wie Sie ein benutzerdefiniertes GPT erstellen, einen weiteren beliebten Ansatz zur Anpassung von KI an bestimmte Anwendungsfälle:
📖 Lesen Sie auch: Wie man Prompt Engineer wird
So bereiten Sie Ihre Trainingsdaten für Gemini vor
Die meisten Feinabstimmungsprojekte scheitern, bevor sie überhaupt begonnen haben, weil Teams den Prozess der Datenaufbereitung unterschätzen. Gartner prognostiziert, dass 60 % der KI-Projekte aufgrund unzureichender KI-fähiger Daten aufgegeben werden.
Sie können Wochen damit verbringen, Daten falsch zu sammeln und zu formatieren, nur um dann festzustellen, dass der Trainingsjob fehlschlägt oder ein unbrauchbares Modell erzeugt. Dies ist oft der zeitaufwändigste Teil des gesamten Prozesses, aber es richtig zu machen, ist der wichtigste Faktor für den Erfolg.
Das Prinzip „Garbage in, garbage out“ (Müll rein, Müll raus) trifft hier besonders zu. Die Qualität Ihres benutzerdefinierten Modells spiegelt direkt die Qualität der Daten wider, mit denen Sie es trainieren.
Anforderungen an das Format des Datensatzes
Gemini erfordert, dass Ihre Trainingsdaten in einem bestimmten Format namens JSONL (JSON Lines) vorliegen. In einer JSONL-Datei ist jede Zeile ein vollständiges, in sich geschlossenes JSON-Objekt, das ein Trainingsbeispiel darstellt. Diese Struktur erleichtert es dem System, große Datensätze zeilenweise zu verarbeiten.
Jedes Trainingsbeispiel muss zwei Schlüsselfelder enthalten:
- text_input: Dies ist die Eingabeaufforderung oder Frage, die Sie dem Modell stellen würden.
- Ausgabe: Dies ist die ideale, perfekte Antwort, die das Modell lernen soll, zu generieren.
Der Einfachheit halber akzeptiert Google KI Studio auch Uploads im CSV-Format und konvertiert diese für Sie in die erforderliche JSONL-Struktur.
Dies kann den ersten Eintrag etwas erleichtern, wenn Ihr Team lieber mit Tabellenkalkulationen arbeitet.
Empfehlungen zur Größe des Datensatzes
Obwohl Qualität wichtiger ist als Quantität, benötigen Sie dennoch eine Mindestanzahl an Beispielen, damit das Modell Muster erkennen und lernen kann. Wenn Sie mit zu wenigen Beispielen beginnen, führt dies zu einem Modell, das nicht verallgemeinern oder zuverlässig arbeiten kann.
Hier sind einige allgemeine Richtlinien für die Größe des Datensatzes:
- Mindestanforderungen: Bei einfachen, sehr spezifischen Aufgaben können Sie mit etwa 100 bis 500 hochwertigen Beispielen erste Ergebnisse erzielen.
- Bessere Ergebnisse: Für komplexere oder nuanciertere Ergebnisse sollten Sie 500 bis 1.000 Beispiele anstreben, um ein robusteres und zuverlässigeres Modell zu erhalten.
- Abnehmende Erträge: Ab einem bestimmten Punkt führt das einfache Hinzufügen weiterer repetitiver Daten nicht mehr zu einer signifikanten Leistungssteigerung. Konzentrieren Sie sich auf Vielfalt und Qualität statt auf reine Menge.
Das Sammeln von Hunderten hochwertiger Beispiele ist für die meisten Teams eine große Herausforderung. Planen Sie diese Datenerfassungsphase entsprechend, bevor Sie mit dem Feinabstimmungsprozess beginnen.
📮 ClickUp Insight: Der durchschnittliche Berufstätige verbringt täglich mehr als 30 Minuten mit der Suche nach Informationen zur Arbeit – das sind über 120 Stunden pro Jahr, die für das Durchsuchen von E-Mails, Slack-Threads und verstreuten Dateien verloren gehen.
Ein intelligenter KI-Assistent, der in Ihren Workspace eingebettet ist, kann das ändern. Hier kommt ClickUp Brain ins Spiel. Es liefert sofortige Einblicke und Antworten, indem es innerhalb von Sekunden die richtigen Dokumente, Unterhaltungen und Aufgabendetails anzeigt – so können Sie mit der Suche aufhören und mit der Arbeit beginnen.
💫 Echte Ergebnisse: Teams wie QubicaAMF haben durch die Abschaffung veralteter Wissensmanagementprozesse mit ClickUp mehr als 5 Stunden pro Woche eingespart – das sind über 250 Stunden pro Person und Jahr. Stellen Sie sich vor, was Ihr Team mit einer zusätzlichen Woche Produktivität pro Quartal erreichen könnte!
Best Practices für die Datenqualität
Inkonsistente oder widersprüchliche Beispiele verwirren das Modell und führen zu unzuverlässigen und unvorhersehbaren Ergebnissen. Um dies zu vermeiden, müssen Ihre Trainingsdaten sorgfältig kuratiert und bereinigt werden. Ein einziges schlechtes Beispiel kann das Gelernte aus vielen guten Beispielen zunichte machen.
Befolgen Sie diese Richtlinien, um eine hohe Datenqualität sicherzustellen:
- Konsistenz: Alle Beispiele sollten dem gleichen Format, Stil und Ton folgen. Wenn Sie möchten, dass die KI formell ist, sollten alle Ihre Ausgabebeispiele formell sein.
- Vielfalt: Ihr Datensatz sollte den gesamten Bereich der Eingaben abdecken, denen das Modell in der Praxis wahrscheinlich begegnen wird. Trainieren Sie es nicht nur anhand einfacher Fälle.
- Genauigkeit: Jedes einzelne Ausgabe-Beispiel muss perfekt sein. Es sollte genau die Antwort sein, die Sie vom Modell erwarten, frei von Fehlern oder Tippfehlern.
- Sauberkeit: Vor dem Training müssen Sie doppelte Beispiele entfernen, alle Rechtschreib- und Grammatikfehler korrigieren und Widersprüche in den Daten beseitigen.
Es wird dringend empfohlen, die Trainingsbeispiele von mehreren Personen überprüfen und validieren zu lassen. Ein frischer Blick kann oft Fehler oder Unstimmigkeiten aufdecken, die Ihnen möglicherweise entgangen sind.
So optimieren Sie Gemini Schritt für Schritt
Der Feinabstimmungsprozess von Gemini umfasst mehrere technische Schritte auf den Plattformen von Google. Ein einziger Fehler kann Stunden wertvoller Trainingszeit und Rechenressourcen verschwenden und Sie dazu zwingen, von vorne zu beginnen. Diese praktische Anleitung soll Ihnen dabei helfen, solche Fehler zu vermeiden, und führt Sie von Anfang bis Ende durch den Prozess. 🛠️
Bevor Sie beginnen, benötigen Sie ein Google Cloud-Konto mit aktivierter Abrechnung und Zugriff auf Google AI Studio. Planen Sie mindestens einige Stunden für das Setup und Ihren ersten Trainingsauftrag ein, sowie zusätzliche Zeit für das Testen und Iterieren Ihres Modells.
Schritt 1: Richten Sie Google KI Studio ein
Google AI Studio ist die webbasierte Oberfläche, über die Sie den gesamten Feinabstimmungsprozess verwalten können. Sie bietet eine benutzerfreundliche Möglichkeit, Daten hochzuladen, das Training zu konfigurieren und Ihr benutzerdefiniertes Modell zu testen, ohne Code schreiben zu müssen.
Navigieren Sie zunächst zu ai.google.dev und melden Sie sich mit Ihrem Google-Konto an.
Sie müssen die Vertragsbedingungen akzeptieren und ein neues Projekt in der Google Cloud Console erstellen, falls Sie noch keines haben. Stellen Sie sicher, dass Sie die erforderlichen APIs gemäß den Anweisungen der Plattform aktivieren.
Schritt 2: Laden Sie Ihren Trainingsdatensatz hoch
Sobald Sie die Einstellung abgeschlossen haben, navigieren Sie zum Abschnitt „Optimierung“ in Google AI Studio. Hier beginnen Sie mit der Erstellung Ihres benutzerdefinierten Modells.
Wählen Sie die Option „Optimiertes Modell erstellen” und wählen Sie Ihr Basismodell aus. Gemini 1. 5 Flash ist eine gängige und kostengünstige Wahl für die Feinabstimmung.
Laden Sie anschließend die JSONL- oder CSV-Datei mit Ihrem vorbereiteten Trainingsdatensatz hoch. Die Plattform überprüft dann Ihre Datei auf die Einhaltung der Formatierungsanforderungen und markiert häufige Fehler wie fehlende Felder oder eine falsche Struktur.
Schritt 3: Konfigurieren Sie Ihre Feinabstimmungseinstellungen
Nachdem Ihre Daten hochgeladen und validiert wurden, konfigurieren Sie die Trainingsparameter. Diese Einstellungen, die als Hyperparameter bezeichnet werden, steuern, wie das Modell aus Ihren Daten lernt.
Die wichtigsten Optionen sind:
- Epochen: Hiermit wird festgelegt, wie oft das Modell anhand Ihres gesamten Datensatzes trainiert wird. Mehr Epochen können zu einem besseren Lernergebnis führen, bergen jedoch auch das Risiko einer Überanpassung.
- Lernrate: Hiermit wird gesteuert, wie aggressiv das Modell seine Gewichte auf der Grundlage Ihrer Beispiele anpasst.
- Batchgröße: Hiermit wird festgelegt, wie viele Trainingsbeispiele in einer einzigen Gruppe zusammen verarbeitet werden.
Für Ihren ersten Versuch empfiehlt es sich, mit den von Google AI Studio empfohlenen Standard-Einstellungen zu beginnen. Die Plattform vereinfacht diese komplexen Entscheidungen und macht sie auch für Nicht-Experten im Bereich maschinelles Lernen zugänglich.
Schritt 4: Führen Sie den Optimierungsauftrag aus.
Nachdem Sie Ihre Einstellungen konfiguriert haben, können Sie nun mit der Optimierung beginnen. Die Server von Google beginnen mit der Verarbeitung Ihrer Daten und der Anpassung der Modell-Parameter. Dieser Trainingsprozess kann je nach Größe Ihres Datensatzes und der Auswahl des Modells zwischen wenigen Minuten und mehreren Stunden dauern.
Sie können den Fortschritt des Auftrags direkt im Google AI Studio-Dashboard überwachen. Da der Auftrag auf den Servern von Google ausgeführt wird, können Sie Ihren Browser sicher schließen und später zurückkehren, um den Status zu überprüfen. Wenn ein Auftrag fehlschlägt, liegt dies fast immer an einem Problem mit der Qualität oder Formatierung Ihrer Trainingsdaten.
Schritt 5: Testen Sie Ihr benutzerdefiniertes Modell
Sobald der Trainingsvorgang fertiggestellt ist, kann Ihr benutzerdefiniertes Modell getestet werden. ✨
Sie können über die Playground-Oberfläche in Google AI Studio darauf zugreifen.
Senden Sie zunächst Testanweisungen, die Ihren Trainingsbeispielen ähneln, um die Genauigkeit zu überprüfen. Testen Sie es anschließend anhand von Randfällen und neuen Varianten, die es zuvor noch nicht gesehen hat, um seine Generalisierungsfähigkeit zu bewerten.
- Genauigkeit: Liefert es genau die Ergebnisse, für die Sie es trainiert haben?
- Generalisierung: Verarbeitet es neue Eingaben, die Ihren Trainingsdaten ähnlich, aber nicht identisch sind, korrekt?
- Konsistenz: Sind die Antworten bei mehreren Versuchen mit derselben Eingabe zuverlässig und vorhersehbar?
Wenn das Ergebnis nicht zufriedenstellend ist, müssen Sie wahrscheinlich zurückgehen, Ihre Trainingsdaten durch Hinzufügen weiterer Beispiele oder Beheben von Inkonsistenzen verbessern und das Modell dann neu trainieren.
📖 Lesen Sie auch: So nutzen Sie KI optimal für Innovation und Effizienz
Best Practices für das Trainieren von Gemini mit benutzerdefinierten Daten
Das bloße Befolgen der technischen Schritte garantiert noch kein hervorragendes Modell. Viele Teams schließen den Prozess ab, sind dann aber von den Ergebnissen enttäuscht, weil ihnen die Optimierungsstrategien fehlen, die erfahrene Praktiker anwenden. Das ist es, was ein funktionales Modell von einem leistungsstarken Modell unterscheidet.
Es überrascht nicht, dass laut dem Bericht „State of Generative KI in the Enterprise” von Deloitte zwei Drittel der Unternehmen angeben, dass 30 % oder weniger ihrer Gen-AI-Experimente innerhalb von sechs Monaten vollständig skaliert werden.
Die Anwendung dieser Best Practices spart Ihnen Zeit und führt zu deutlich besseren Ergebnissen.
- Fangen Sie klein an und skalieren Sie dann: Bevor Sie sich auf einen vollständigen Trainingslauf festlegen, testen Sie Ihren Ansatz mit einem kleinen Teil Ihrer Daten (z. B. 100 Beispielen). So können Sie Ihr Format validieren und sich schnell einen Eindruck von der Leistung verschaffen, ohne Stunden zu verschwenden.
- Versionen Ihrer Datensätze: Wenn Sie Trainingsbeispiele hinzufügen, entfernen oder bearbeiten, speichern Sie jede Version Ihres Datensatzes. So können Sie Änderungen nachverfolgen, Ergebnisse reproduzieren und zu einer früheren Version zurückkehren, wenn eine neue Version schlechtere Ergebnisse liefert.
- Test vor und nach der Feinabstimmung: Bevor Sie mit der Feinabstimmung beginnen, legen Sie eine Basislinie fest, indem Sie die Leistung des Basismodells bei Ihren wichtigsten Aufgaben bewerten. So können Sie objektiv messen, wie viel Verbesserung der Aufwand für die Feinabstimmung erzielt hat.
- Aus Fehlern lernen: Wenn Ihr benutzerdefiniertes Modell eine falsche oder schlecht formatierte Antwort liefert, lassen Sie sich davon nicht entmutigen. Fügen Sie diesen speziellen Fehlerfall als neues, korrigiertes Beispiel zu Ihren Trainingsdaten für die nächste Iteration hinzu.
- Dokumentieren Sie Ihren Prozess: Führen Sie ein Protokoll über jeden Trainingslauf und notieren Sie dabei die verwendete Datensatzversion, die Hyperparameter und die Ergebnisse. Diese Dokumentation ist von unschätzbarem Wert, um zu verstehen, was im Laufe der Zeit funktioniert und was nicht.
Die Verwaltung dieser Iterationen, Datensatzversionen und Dokumentationen erfordert ein robustes Projektmanagement. Die Zentralisierung dieser Arbeit in einer Plattform, die für strukturierte Workflows ausgelegt ist, kann verhindern, dass der Prozess chaotisch wird.
Häufige Herausforderungen beim Trainieren von Gemini
Teams investieren oft viel Zeit und Ressourcen in die Feinabstimmung, nur um dann auf vorhersehbare Hindernisse zu stoßen, die zu vergeblichem Aufwand und Frustration führen. Wenn Sie diese häufigen Fallstricke im Voraus kennen, können Sie den Prozess reibungsloser gestalten.
Hier sind einige der häufigsten Herausforderungen und wie Sie diese angehen können:
- Überanpassung: Dies tritt auf, wenn das Modell Ihre Trainingsbeispiele perfekt speichert, aber nicht in der Lage ist, diese auf neue, unbekannte Eingaben zu übertragen. Um dies zu beheben, können Sie Ihre Trainingsdaten vielfältiger gestalten, die Anzahl der Epochen reduzieren oder alternative Methoden wie die Retrieval-Augmented Generation ausprobieren.
- Inkonsistente Ergebnisse: Wenn das Modell auf sehr ähnliche Fragen unterschiedliche Antworten gibt, liegt das wahrscheinlich daran, dass Ihre Trainingsdaten widersprüchliche oder inkonsistente Beispiele enthalten. Um diese Konflikte zu lösen, ist eine gründliche Datenbereinigung erforderlich.
- Formatdrift: Manchmal folgt ein Modell zunächst der von Ihnen gewünschten Ausgabestruktur, weicht dann aber im Laufe der Zeit davon ab. Die Lösung besteht darin, explizite Formatvorgaben in die Ausgabe Ihrer Trainingsbeispiele aufzunehmen, nicht nur den Inhalt.
- Langsame Zyklen: Wenn jeder Trainingslauf Stunden dauert, verlangsamt dies Ihre Fähigkeit zu experimentieren und Verbesserungen vorzunehmen erheblich. Testen Sie Ihre Ideen zunächst an kleineren Datensätzen, um schneller Feedback zu erhalten, bevor Sie einen vollständigen Trainingsjob starten.
- Engpass bei der Datenerfassung: Oftmals ist der schwierigste Teil der Engpass bei der Datenerfassung, also einfach genügend hochwertige Beispiele zu sammeln. Nutzen Sie zunächst Ihre besten vorhandenen Inhalte – wie Support-Tickets, Marketingtexte oder technische Dokumente – und bauen Sie darauf auf.
Diese Herausforderungen sind ein Schlüssel dafür, dass viele Teams letztendlich nach Alternativen zum manuellen Feinabstimmungsprozess suchen.
📮ClickUp Insight: 88 % der Befragten unserer Umfrage nutzen KI für ihre persönlichen Aufgaben, doch über 50 % scheuen sich, sie bei der Arbeit einzusetzen. Die drei größten Hindernisse? Mangelnde nahtlose Integration, Wissenslücken oder Sicherheitsbedenken. Aber was wäre, wenn KI in Ihren Workspace integriert und bereits sicher wäre? ClickUp Brain, der integrierte KI-Assistent von ClickUp, macht dies möglich. Er versteht Eingaben in einfacher Sprache und löst damit alle drei Bedenken hinsichtlich der Einführung von KI, während er Ihren Chat, Ihre Aufgaben, Dokumente und Ihr Wissen im gesamten Workspace miteinander verbindet. Finden Sie Antworten und Erkenntnisse mit einem einzigen Klick!
Warum ClickUp eine intelligentere Alternative ist
Die Feinabstimmung von Gemini ist leistungsstark – aber auch eine Notlösung.
In diesem Artikel haben wir gesehen, dass es bei der Feinabstimmung letztendlich um eines geht: der KI beizubringen, Ihren Geschäftskontext zu verstehen. Das Problem ist, dass die Feinabstimmung dies indirekt tut. Sie bereiten Datensätze vor, entwickeln Beispiele, trainieren Modelle neu und pflegen Pipelines, damit die KI die Arbeitsweise Ihres Teams annähernd nachvollziehen kann.
Das ist für spezielle Anwendungsfälle sinnvoll. Für die meisten Teams ist das eigentliche Ziel jedoch nicht die Personalisierung von Gemini an sich. Das Ziel ist einfacher:
Sie möchten eine KI, die Ihre Arbeit versteht.
Hier verfolgt ClickUp einen grundlegend anderen – und intelligenteren – Ansatz.
Der Converged AI Workspace von ClickUp bietet Ihrem Team eine KI, die Ihren Arbeitskontext sofort versteht – ohne großen Aufwand. Anstatt die KI zu trainieren, damit sie Ihren Kontext später „lernt”, arbeiten Sie mit ClickUp Brain, dem integrierten KI-Assistenten, in dem Ihr Kontext bereits vorhanden ist.
Ihre Aufgaben, Dokumente, Kommentare, Projektverlauf und Entscheidungen sind nativ miteinander verbunden. Es ist nicht erforderlich, die KI mit Ihren Daten zu trainieren, da sie bereits dort vorhanden ist, wo Sie arbeiten, und auf Ihr bestehendes Wissensmanagement-Ökosystem zurückgreift.
| Aspekt | Gemini-Feinabstimmung | ClickUp Brain |
|---|---|---|
| Setup-Zeit | Datenaufbereitung dauert Tage bis Wochen | Sofort einsatzbereit – funktioniert mit vorhandenen Workspace-Daten |
| Kontextquelle | Manuell kuratierte Trainingsbeispiele | Automatischer Zugriff auf alle verbundenen Arbeiten |
| Wartung | Trainieren Sie das Modell neu, wenn sich Ihre Anforderungen ändern. | Wird kontinuierlich aktualisiert, während sich Ihr Workspace weiterentwickelt. |
| Erforderliche technische Kenntnisse | Mittel bis hoch | Keine |
Da ClickUp Ihr Arbeitssystem ist, arbeitet ClickUp Brain innerhalb Ihres verbundenen Datengraphen. Es gibt keine KI-Ausbreitung über unverbundene Tools hinweg, keine brüchigen Trainingspipelines und kein Risiko, dass das Modell nicht mehr mit der tatsächlichen Arbeitsweise Ihres Teams synchronisiert ist.
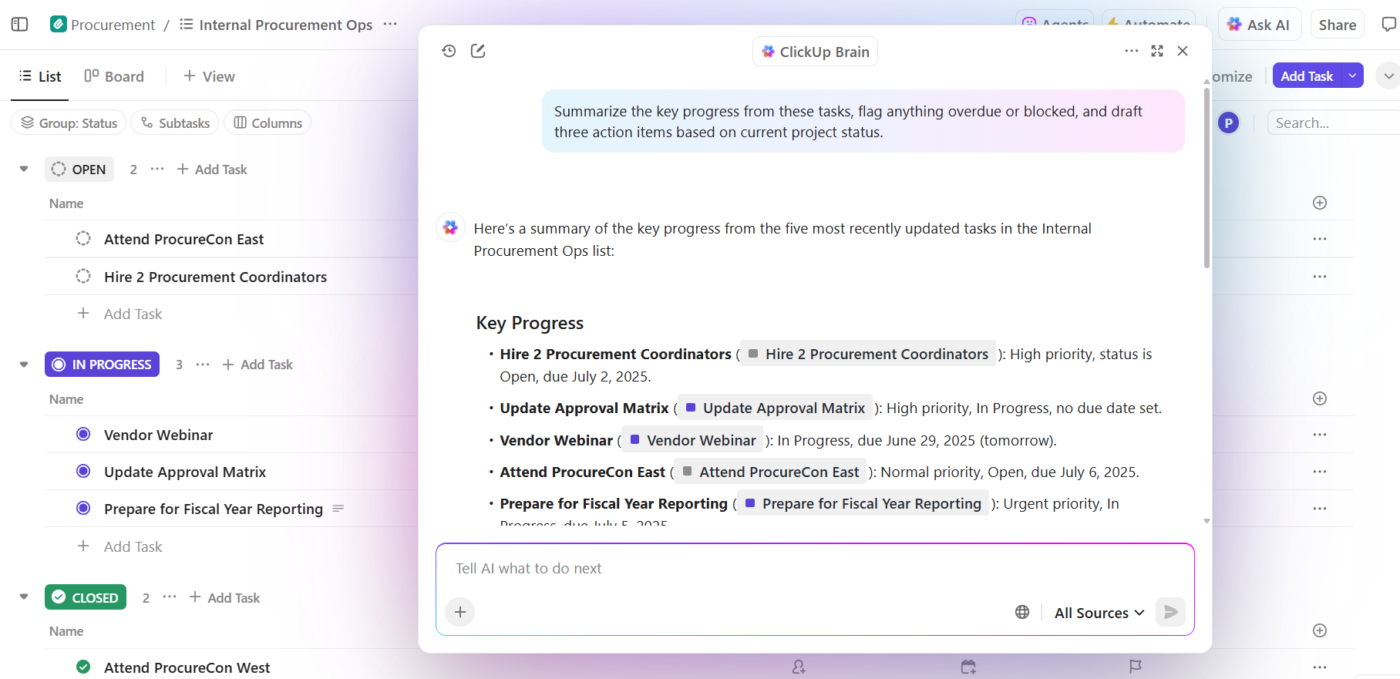
So sieht das in der Praxis aus:
- Stellen Sie Fragen zu Ihren Projekten: ClickUp Brain durchsucht den Workspace nach Aufgaben, Dokumenten, Kommentaren und Aktualisierungen, um Fragen anhand Ihrer realen Projektdaten zu beantworten – nicht anhand allgemeiner Trainingsdaten.
- Generieren Sie Inhalte mit Kontext: ClickUp Brain hat bereits sicheren Zugriff auf Ihre Aufgaben, Dateien, Kommentare und den Projektverlauf. Es kann Dokumente, Zusammenfassungen und Statusaktualisierungen erstellen, die sich auf Ihre tatsächliche Arbeit, Zeitleisten und Prioritäten beziehen. Keine unübersichtlichen Kontexte mehr, bei denen Teams Stunden damit verbringen, in verschiedenen Apps und Dateien nach Informationen zu suchen.
- Automatisieren Sie mit Verständnis: Mit ClickUp Automations können Sie Automatisierungen erstellen, die intelligent auf den Projektkontext reagieren, z. B. auf Fristen, Eigentümerschaft und Statusänderungen, und nicht nur auf statische Regeln. Die KI kann diese sogar für Sie erstellen, ganz ohne Code.
💡Profi-Tipp: Nutzen Sie die wahre Leistungsfähigkeit von KI in Ihrem Workspace mit ClickUp Super Agents.
Super Agents sind die KI-gestützten Teamkollegen von ClickUp – konfiguriert als KI-„Benutzer”, die innerhalb des Arbeitsbereichs mit Ihrem Team zusammenarbeiten. Sie sind umgebungs- und kontextbezogen und können Aufgaben zugewiesen, in Kommentaren erwähnt, durch Ereignisse oder Zeitpläne ausgelöst oder per Chat angeleitet werden – genau wie ein menschlicher Teamkollege.
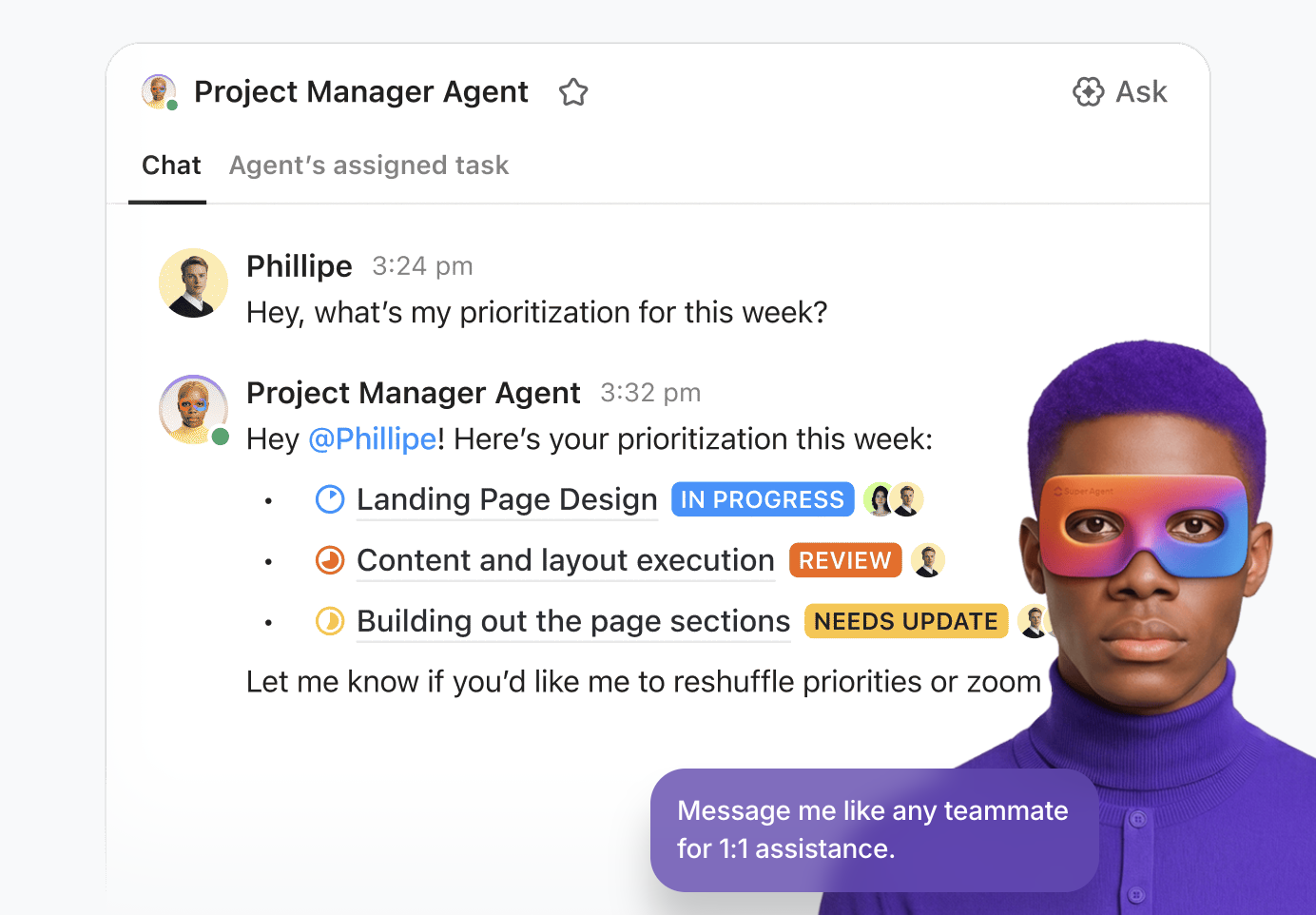
Sie können diese Modelle mit dem visuellen No-Code-Builder erstellen und bereitstellen, der Ihnen folgende Möglichkeiten bietet:
- Identifizieren Sie das Ausgangsereignis, z. B. eine Nachricht oder eine Änderung des Status der Aufgabe.
- Legen Sie operative Regeln fest, darunter wie Daten zusammengefasst, Arbeiten delegiert oder Prioritäten angepasst werden sollen.
- Führen Sie externe Aktionen über integrierte Tools und Erweiterungen aus.
- Stellen Sie unterstützende Daten bereit, indem Sie eine Verbindung zwischen dem Agenten und relevanten Wissensdatenbanken herstellen.
Erhalten Sie weitere Informationen über Super Agents im folgenden Video.
Optimieren Sie Ihre KI-Strategie: Holen Sie sich ClickUp
Durch Feinabstimmung lernt eine KI Ihre Muster anhand statischer Beispiele, aber die Verwendung konvergierter Software in einem Workspace wie ClickUp verhindert eine Kontextzerstreuung, indem sie Ihrer KI einen Live-Kontext in Echtzeit liefert.
Dies ist der Kern einer erfolgreichen KI-Transformation: Teams, die ihre Arbeit auf einer vernetzten Plattform zentralisieren, verbringen weniger Zeit mit dem Trainieren der KI und haben mehr Zeit, von ihr zu profitieren. Wenn sich Ihr Workspace weiterentwickelt, entwickelt sich Ihre KI automatisch mit – ohne dass erneute Trainingszyklen erforderlich sind.
Sind Sie bereit, das Training zu überspringen und mit einer KI zu beginnen, die Ihre Arbeit bereits kennt? Starten Sie kostenlos mit ClickUp und erleben Sie die Vorteile eines konvergenten Workspaces.
Häufig gestellte Fragen (FAQ)
Ihr fein abgestimmtes Modell lernt aus Ihren Trainingsbeispielen, aber das Basis-Gemini-Modell von Google speichert Ihre Daten der Unterhaltung standardmäßig nicht und lernt auch nicht daraus. Ihr benutzerdefiniertes Modell ist vom Basismodell, das anderen Benutzern zur Verfügung steht, getrennt.
Während der Trainingsvorgang selbst nur wenige Stunden dauert, ist der größte Zeitaufwand für die Vorbereitung der hochwertigen Trainingsdaten erforderlich. Diese Datenvorbereitungsphase kann oft Tage oder sogar Wochen in Anspruch nehmen, um ordnungsgemäß abgeschlossen zu werden.
Ja, mit Google AI Studio können Sie ein Modell ohne Code optimieren. Die visuelle Benutzeroberfläche übernimmt den Großteil der technischen Komplexität, allerdings müssen Sie sich dennoch mit den Anforderungen an das Datenformat auskennen.
Benutzerdefinierte Anweisungen sind temporäre, sitzungsbasierte Eingabeaufforderungen, die das Verhalten des Modells für eine einzelne Unterhaltung steuern. Durch die Feinabstimmung werden jedoch die internen Parameter des Modells auf der Grundlage Ihrer Trainingsbeispiele dauerhaft angepasst, wodurch sein Verhalten nachhaltig verändert wird.