

Você é um chefe de departamento à procura da pessoa perfeita para lidar com uma tarefa específica. Com uma grande quantidade de dados da empresa, encontrar a pessoa mais adequada é quase impossível, especialmente se sua tarefa for urgente.
Além disso, quem tem tempo para perguntar a todos se eles têm conhecimento suficiente sobre uma área específica?
Mas e se você pudesse simplesmente perguntar a um sistema: “Quem foi designado para [tarefa] mais vezes?” e obter uma resposta instantânea e precisa com base em dados reais? É isso que os sistemas de recuperação de informações fazem.
Esses sistemas vasculham montanhas de dados para encontrar exatamente o que você precisa.
Agora, amplie essa ideia para um banco de dados global — um sistema de IR organiza grandes quantidades de dados, ajudando você a encontrar as respostas mais relevantes em segundos. Este guia explorará diferentes modelos de recuperação de informações, como eles funcionam e o papel das tecnologias de IA em um sistema de IR.
⏰ Resumo de 60 segundos
📌 Os sistemas de recuperação de informações (IR) ajudam a encontrar informações relevantes em grandes coleções de dados, funcionando como um assistente virtual que vasculha os dados para encontrar o que você precisa.
📌 Os sistemas de IR têm componentes essenciais: banco de dados, indexador, interface de pesquisa, processador de consultas, modelos de recuperação e mecanismos de classificação/pontuação.
📌 São utilizados quatro modelos principais de RI: Booleano (usa operadores AND/OR/NOT), Espaço vetorial (representa documentos como vetores), Probabilístico (usa abordagens estatísticas) e Interdependência de termos (analisa as relações entre termos).
📌 O aprendizado de máquina e o processamento de linguagem natural aprimoram os sistemas de RI, melhorando o reconhecimento de padrões, a classificação de resultados e a compreensão do contexto.
📌 Os principais desafios incluem privacidade de dados, escalabilidade e manutenção da qualidade dos dados durante o processamento de grandes conjuntos de dados.
O que é recuperação de informações (IR)?
Recuperação de informações (IR) significa simplesmente encontrar as informações certas em grandes coleções de dados, como bibliotecas digitais, bancos de dados ou arquivos da Internet.
É como ter um assistente virtual que analisa montanhas de dados para lhe trazer exatamente o que você precisa.
Superficialmente, o usuário insere uma consulta, geralmente usando palavras-chave ou frases, para pesquisar informações específicas. Nos bastidores, técnicas e algoritmos avançados analisam as sequências de pesquisa e as combinam com dados relevantes.
Em vez de identificar apenas uma única resposta, os sistemas de IR fornecem vários objetos, cada um com diferentes graus de relevância para sua consulta. Além disso, eles são usados em todos os lugares e têm várias aplicações (mais sobre isso em breve 🔔).
💡Dica profissional: Precisa encontrar a pessoa mais qualificada para uma tarefa? Insira termos específicos como “análise de relatórios de vendas do primeiro e segundo trimestres atribuídos a” no sistema de recuperação de informações. Assim, ele filtra rapidamente os dados irrelevantes e identifica quem mais lidou com eles.
Aplicações de IR em diferentes áreas
Da área da saúde ao comércio eletrônico, os sistemas de IR são usados em vários campos para gerenciar e categorizar dados. Aqui estão alguns exemplos 👇
Saúde
Na área da saúde, os sistemas de RI examinam bancos de dados de registros médicos e artigos científicos para ajudar médicos e pesquisadores a encontrar as informações mais relevantes. Como resultado, eles aceleram o diagnóstico de doenças, identificam opções de tratamento e encontram os estudos mais relevantes usando feedback relevante.
Atendimento ao cliente
As técnicas de recuperação de informações tornam o suporte ao cliente mais rápido e preciso. Por exemplo, os agentes podem digitar consultas de usuários como “política de reembolso” no sistema da empresa para obter respostas instantâneas.
Os chatbots de IA e os serviços de assistência técnica alimentados pela recuperação de informações vão um passo além, oferecendo soluções em tempo real sem envolvimento humano. É por isso que suas perguntas são frequentemente respondidas em segundos!
Plataformas de comércio eletrônico
Os sistemas de IR facilitam as compras online. Eles analisam bancos de dados e combinam o comportamento do cliente para recomendar produtos que você vai adorar.
Por exemplo, a Amazon usa IR para sugerir itens com base no seu histórico de pesquisa e compras anteriores, ajudando você a encontrar exatamente o que precisa.
Componentes de um sistema de recuperação de informações
Agora sabemos o que é a recuperação de informações e como funciona. Vamos analisar os principais componentes de um sistema de RI. →
1. Banco de dados
Tudo começa com o banco de dados. É uma coleção de pontos de dados inter-relacionados, como documentos de texto, e-mails, páginas da web, imagens e vídeos. Quando você insere uma determinada consulta, o sistema de RI pesquisa essas correspondências no banco de dados para recuperar as informações mais relevantes para suas necessidades.
2. Indexador
Antes que o sistema possa recuperar qualquer coisa, o indexador organiza os dados. É como preparar um catálogo de biblioteca para tornar a pesquisa mais rápida. O indexador processa documentos por meio de:
- Tokenização: Dividir o conteúdo em partes menores, como separar frases em palavras ou expressões (chamadas tokens).
- Stemming: Simplificar palavras à sua forma básica (por exemplo, “correr” torna-se “correr”).
- Remoção de palavras irrelevantes: Ignore palavras de preenchimento como “e”, “ou” e “o” para se concentrar na consulta principal.
- Extração de palavras-chave: Identificar as principais palavras-chave no texto
- Extração de metadados: extrair detalhes adicionais, como autor, data de publicação ou título.
3. Interface de pesquisa
A interface de pesquisa funciona como sua porta de entrada para o sistema de RI. É aqui que você digita sua consulta usando palavras-chave simples ou filtros mais detalhados. Projetada para ser fácil de usar, ela garante que você possa comunicar facilmente suas necessidades de acesso à informação e obter os resultados relevantes que está procurando.
4. Processador de consultas
Depois de clicar em “pesquisar”, o processador de consultas assume o controle. Ele refina sua entrada aplicando técnicas listadas na seção indexador. Além disso, ele também lida com operadores booleanos como “AND”, “OR” e “NOT” para tornar sua consulta mais inteligente.
5. Modelos de recuperação
É aqui que a mágica acontece. O sistema compara sua consulta com os documentos indexados usando modelos de recuperação. Esses métodos decidem como combinar sua consulta com os dados armazenados. Alguns dos nomes mais comuns incluem:
- Modelos booleanos
- Modelos de espaço vetorial
- Modelos probabilísticos
- E muito mais... (discutido posteriormente)
6. Classificação e pontuação
Depois que as correspondências potenciais são encontradas, o sistema as classifica com base na relevância. Cada documento recebe uma pontuação usando métodos como TF-IDF (Term Frequency-Inverse Document Frequency) ou outros algoritmos. Isso garante que o resultado mais relevante apareça no topo.
7. Apresentação ou exibição
Por fim, os resultados são apresentados a você. Normalmente, o sistema mostra uma lista classificada de documentos de texto com recursos extras, como trechos, filtros ou opções de classificação. Isso facilita a escolha do documento mais relevante. No entanto, o número de resultados exibidos pode variar de acordo com suas preferências, consulta ou configurações do sistema.
🔍Você sabia?: Os sistemas tradicionais de recuperação de informações dependiam fortemente de bancos de dados estruturados e correspondência básica de palavras-chave. O resultado? Grandes problemas de relevância e personalização.
Foi então que as modernas tecnologias de IA transformaram a recuperação de texto por meio de:
- Aprendizado de máquina (ML): ajuda os sistemas de IR a aprender com os padrões de comportamento do usuário e melhorar os resultados de pesquisa ao longo do tempo.
- Redes Neurais Profundas: Algoritmos que podem processar dados não estruturados (como imagens ou vídeos) e descobrir relações complexas.
- Processamento de linguagem natural (NLP): permite que os sistemas compreendam o significado e o contexto das consultas para dar suporte ao reconhecimento de imagens e à análise de sentimentos, tornando o acesso à informação mais versátil.
Modelos de recuperação de informações
Existem diferentes sistemas de RI que simplificam o processo de localização de documentos relevantes. Vejamos os mais utilizados:
1. Teoria dos conjuntos e modelos booleanos
O modelo booleano é uma das técnicas de recuperação de informações mais simples. Veja como funciona:
- E: Recupera documentos que contêm todos os termos da consulta. Por exemplo, uma pesquisa por “gato E cachorro” retornará documentos que mencionam ambos em um mecanismo de pesquisa.
- OU: Encontra documentos que contenham qualquer dos termos da consulta. Para “gato OU cachorro”, ele recupera documentos que mencionam gato, cachorro ou ambos.
- NÃO: Exclui documentos que contenham um termo específico. Por exemplo, “gato E NÃO cachorro” retorna documentos que mencionam gato, mas não cachorro.
Este modelo usa o conceito de “saco de palavras”, no qual é criada uma matriz 2D. Nessa matriz:
- As colunas representam documentos
- As linhas representam termos da consulta.
Cada célula recebe um valor de 1 (se o termo estiver presente) ou 0 (se não estiver).

✅ Prós
- Fácil de entender e implementar
- Recupera documentos que correspondem exatamente aos termos da consulta
❌ Contras
- Os modelos booleanos não classificam os documentos por relevância, portanto, todos os resultados são tratados como igualmente importantes.
- Foca em correspondências exatas de termos, portanto, os resultados podem variar de acordo com o significado ou contexto da consulta.
2. Modelos de espaço vetorial
Um modelo de espaço vetorial é um modelo algébrico que representa documentos e consultas como vetores em um espaço multidimensional. É assim que funciona:
1. É criada uma matriz termo-documento, em que as linhas são termos e as colunas são documentos.
2. Um vetor de consulta é formado com base nos termos de pesquisa do usuário.
3. O sistema calcula uma pontuação numérica usando uma medida chamada similaridade coseno, que determina o grau de correspondência entre o vetor de consulta e os vetores do documento.

Como um sistema de recuperação de informações, os documentos são classificados com base nessas pontuações, sendo os mais bem classificados os mais relevantes.
✅ Prós
- Recupera itens mesmo que apenas alguns termos correspondam
- Variações no uso de termos e no comprimento dos documentos, acomodando diversos tipos de documentos
❌ Contras
- Vocabulários e coleções de documentos maiores tornam os cálculos de similaridade intensivos em recursos.
3. Modelos probabilísticos
Este modelo adota uma abordagem estatística, usando a probabilidade para estimar a relevância de um documento para a consulta. Ele considera:
- Frequência dos termos no documento
- Com que frequência os termos ocorrem juntos (coocorrência)
- Comprimento do documento e número total de termos de consulta
O sistema trata o processo de recuperação como um evento probabilístico, classificando os documentos armazenados com base em sua probabilidade de relevância. Essa abordagem adiciona profundidade ao avaliar objetos de dados além da presença básica de termos.
✅ Prós
- Adapta-se bem a várias aplicações, incluindo análises de confiabilidade e avaliações de fluxo de carga.
❌ Contras
- Baseia-se em suposições sobre as relações entre os dados, o que pode levar a resultados enganosos.
4. Modelos de interdependência de termos
Ao contrário dos modelos mais simples, os Modelos de Interdependência de Termos se concentram nas relações entre os termos, e não apenas em sua frequência. Esses modelos analisam como as palavras e frases se relacionam entre si para melhorar a precisão dos resultados.
Eles usam uma das duas abordagens:
- Modo imanente: explora as relações dentro do próprio texto.
- Modo transcendente: considera dados externos ou contexto para inferir relações
Esse método é especialmente útil para capturar nuances de significado, como sinônimos ou frases específicas do contexto.
✅ Prós
- Captura nuances na linguagem, levando em consideração as relações entre os termos.
- Melhora o desempenho da recuperação ao compreender as dependências dos termos e o contexto.
❌ Contras
- Requer dados extensos para modelar com precisão as relações entre termos, o que nem sempre está disponível.
É isso! Esses são alguns dos sistemas de recuperação de informações mais usados, com suas próprias vantagens e desvantagens.
➡️ Leia mais: 4 alternativas e concorrentes do Spotlight Search
Recuperação de informações x consulta de dados
Embora esses dois termos pareçam quase iguais, eles funcionam de maneira diferente. Então, vamos comparar a RI e a consulta de dados para ver como elas se comparam em termos de finalidade, casos de uso e exemplos:
| Aspecto | Recuperação de Informações (IR) | Consulta de dados |
| Definição | Funciona como um mecanismo de busca que vasculha toneladas de dados para trazer os resultados mais relevantes para você. | Pense nisso como fazer uma pergunta específica a um banco de dados em uma linguagem que ele entende (como SQL). |
| Objetivo/Finalidade | Ajuda você a encontrar informações ou recursos precisos e relevantes nos mecanismos de busca — de forma rápida e fácil. | Extraia dados exatos para que você possa analisar, atualizar ou processar números. |
| Casos de uso | Usado para pesquisas na web, recomendações de comércio eletrônico, bibliotecas digitais, insights sobre saúde e muito mais. | Ótimo para tarefas como gerenciamento de estoque em comércio eletrônico, análise financeira e otimização de cadeias de suprimentos. |
| Exemplo | Pesquisando “Melhores laptops entre US$ 800 e US$ 1000” no Google para obter resultados classificados | Consultar seu sistema de inventário com “SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000” para encontrar o que está em estoque. |
O papel do aprendizado de máquina e da PNL na recuperação de informações
Os sistemas de IR são como caçadores de tesouros de dados — eles vasculham grandes quantidades de informações para encontrar exatamente o que você está procurando. Mas quando o ML e o NLP unem forças, esses sistemas se tornam mais inteligentes, rápidos e muito mais precisos.
Pense no ML como o cérebro por trás dos sistemas de IR. 🧠
Isso ajuda o sistema a aprender, se adaptar e melhorar os resultados sempre que você pesquisar informações. Veja como funciona:
- Identificação de padrões: o ML estuda o que os usuários clicam, o que ignoram e o que passam mais tempo lendo. Em seguida, usa esse conhecimento para mostrar os resultados mais relevantes na próxima vez.
- Resultados de classificação: o ML recupera informações e também as classifica. Isso significa que os melhores e mais úteis resultados aparecem no topo da sua pesquisa.
- Adaptando-se com o tempo: a cada consulta, o ML fica melhor. Ele capta tendências, refina sua compreensão e lida facilmente até mesmo com as perguntas mais complicadas.
Por exemplo, se você pesquisar “melhores laptops econômicos” hoje e interagir com resultados específicos, o ML saberá priorizar opções semelhantes quando você pesquisar “notebooks acessíveis” mais tarde. Ao combinar IA com ML, os mecanismos de pesquisa na web podem até mesmo prever o que você pode precisar em seguida.
Agora vamos falar sobre PNL. Ela ajuda os sistemas de RI a entender o que você quer dizer, não apenas as palavras que você digita. Em palavras simples:
- Ele entende o contexto: o NLP sabe que quando você diz “jaguar”, você pode estar se referindo ao animal ou ao carro — e ele descobre isso com base no restante da sua consulta.
- Ele lida com linguagem complexa: seja sua consulta simples (“voos baratos”) ou detalhada (“voos diretos para Tóquio abaixo de US$ 500”), o NLP garante que o sistema entenda e forneça os resultados certos.
Juntas, a NLP e a IR tornam a pesquisa intuitiva, como se você estivesse conversando com alguém que simplesmente entende você. Isso significa menos rolagem, menos frustração e mais momentos “uau, isso é exatamente o que eu precisava!”.
O papel do ClickUp na recuperação de informações
O ClickUp, o “aplicativo completo para o trabalho”, aprimora o gerenciamento de dados com modelos de RI.
Sua IA integrada identifica e combina resultados de forma exclusiva com a consulta do usuário, levando a tecnologia inteligente a um novo patamar.
E para tornar tudo ainda melhor, a Pesquisa Conectada do ClickUp facilita a obtenção de tudo o que você precisa “imediatamente” ao seu alcance. Isso significa:
- Pesquise qualquer coisa: quem gosta de vasculhar e-mails e sistemas de gerenciamento de conhecimento para localizar arquivos importantes? Encontre qualquer arquivo em segundos usando a opção Pesquisa Conectada. Melhor ainda, pesquise arquivos em seus aplicativos conectados e acesse tudo em um só lugar.
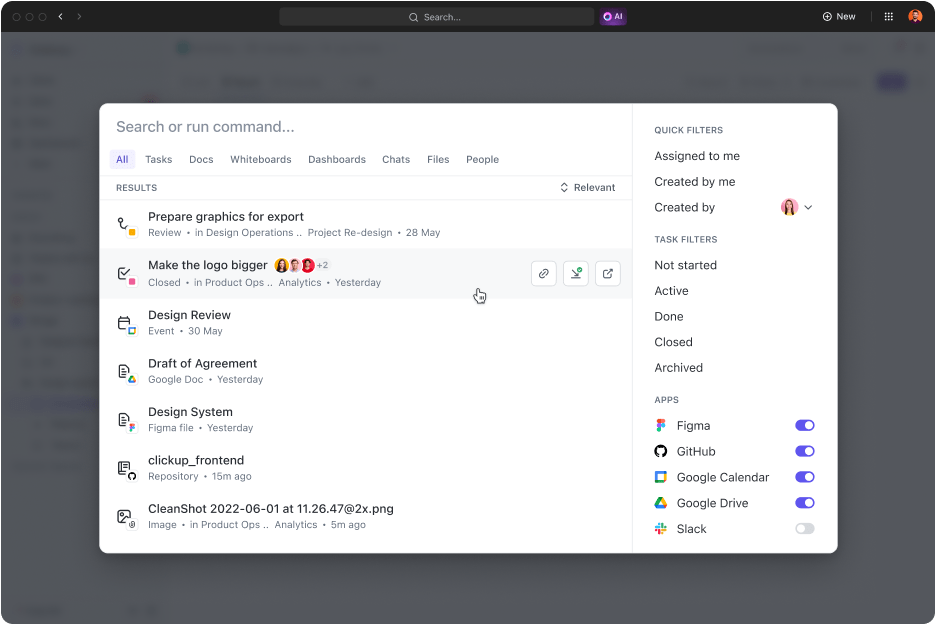
- Conecte seus aplicativos favoritos: o ClickUp possui algumas das melhores integrações que ampliam seus recursos de pesquisa para aplicativos de terceiros, como Google Drive, Slack, Dropbox, Figma e muito mais.

- Refine os resultados: quanto mais você usa, melhor ele fica em entender o que você está procurando, oferecendo resultados personalizados para você.
- Pesquise do seu jeito: acesse a Pesquisa Conectada e pesquise arquivos PDF rapidamente de qualquer lugar do seu espaço de trabalho. Por exemplo, você pode iniciar uma pesquisa a partir do Centro de Comando, da Barra de Ações Globais ou da sua área de trabalho.
- Crie comandos de pesquisa personalizados: adicione comandos de pesquisa personalizados, como atalhos para links, armazenamento de texto para uso posterior e muito mais, para otimizar seu fluxo de trabalho.
Para completar, e se houvesse uma maneira de automatizar tarefas tediosas, trabalhar mais rápido e realizar mais tarefas em menos tempo?
O ClickUp Brain, o assistente de IA integrado, torna isso realidade para você. É o assistente definitivo para gerenciamento de dados — inteligente, rápido e sempre pronto para ajudar.
Em resumo 👇
- Centro de conhecimento completo: nunca mais dependa de e-mails e mensagens para obter atualizações. Pergunte qualquer coisa sobre suas tarefas, documentos ou pessoas e relaxe enquanto o ClickUp Brain mapeia as respostas com base no contexto interno e nos aplicativos conectados.

- Encontre o que você precisa mais rapidamente: o ClickUp Brain classifica os resultados de forma inteligente, como um sistema avançado de IR. Ele prioriza arquivos relevantes, sugere tarefas relacionadas e até mesmo ajuda você a descobrir cargas de trabalho ocultas em seus dados.
- Automatize tarefas: o Brain automatiza a geração de relatórios ou o acompanhamento de prazos por meio de suas ferramentas de IA. É um assistente pessoal que libera seu tempo para decisões mais importantes, mantendo tudo sob controle.
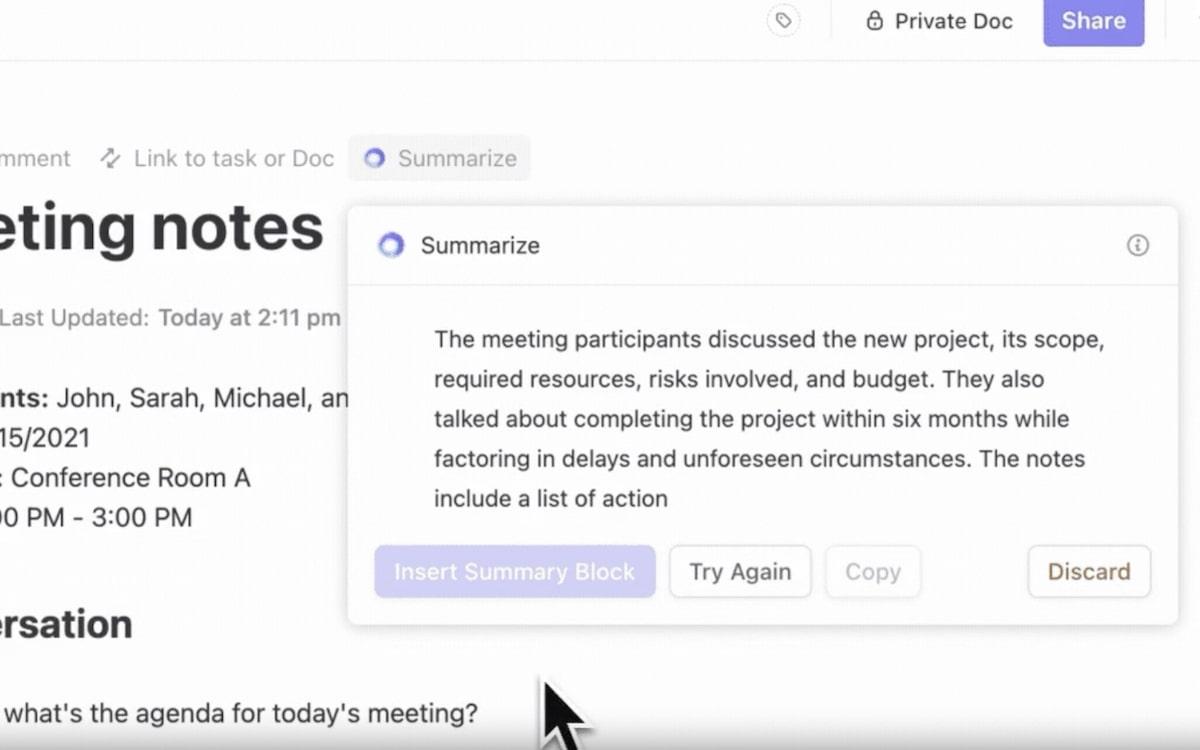
- Pesquisa contextual: com NLP, ele entende sua pergunta, mesmo que sua consulta seja complexa ou vaga. Por exemplo, pesquisar “relatório de vendas do primeiro trimestre” fornece o relatório exato vinculado à sua tarefa.
Desafios e direções futuras na recuperação de informações
O mundo da recuperação de informações consiste em dar sentido a grandes quantidades de dados, mas mesmo os sistemas de RI mais avançados enfrentam alguns obstáculos ao longo do caminho.
Vamos explorar os desafios comuns e as tendências empolgantes que moldam o futuro dessa disciplina científica essencial:
- Privacidade e segurança dos dados: para que um modelo de RI forneça resultados factuais, muitas vezes ele precisa acessar dados confidenciais. No entanto, proteger os dados dos usuários não é uma tarefa fácil para os recursos de recuperação de informações.
- Escalabilidade e desempenho: À medida que os usuários pesquisam em grandes conjuntos de dados, lidar com o aumento da coleta de conteúdo pode sobrecarregar até mesmo os modelos de recuperação mais robustos. O desafio é garantir uma recuperação eficiente sem comprometer a relevância dos resultados da pesquisa.
- Qualidade dos dados e compreensão contextual: consultas ambíguas ou metadados mal organizados podem levar a incompatibilidades, dificultando que o sistema identifique de forma única a intenção do usuário.
Tendências emergentes e avanços na tecnologia de RI
Apesar dos muitos obstáculos, os recentes avanços tecnológicos nos permitiram construir sistemas mais inteligentes e eficientes.
Os sistemas modernos de recuperação de informações agora usam métodos avançados, como análise baseada em gráficos, para interpretar os números, o texto, o contexto, os metadados e as relações entre os pontos de dados.
O que isso significa para os usuários? Permite uma recuperação de texto mais precisa e uma análise detalhada, especialmente em áreas como pesquisa e setores que lidam com grandes volumes de dados.
Combinado com tecnologias da web semântica, ele se concentra em cadeias de pesquisa e intenção do usuário. Esses sistemas podem ir além das correspondências literais e buscar documentos altamente relevantes, mesmo para consultas complicadas do usuário no processo de recuperação de informações.
Por exemplo, pesquisar “benefícios do trabalho remoto” pode fornecer resultados relacionados à produtividade, saúde mental e equilíbrio entre vida profissional e pessoal — tudo porque o sistema entende as conexões.
Recupere documentos rapidamente com o gerenciamento de dados do ClickUp
Vasculhar arquivos, aplicativos e ferramentas intermináveis para encontrar aquele documento importante é exaustivo. Imagine tentar analisar documentos recuperados como pesquisador, estudante, profissional de TI ou cientista de dados — e isso se torna apenas uma confusão de excesso de informações.
Mas com o ClickUp, você nunca mais perderá tempo procurando informações.
É a solução completa que reúne todo o seu trabalho em um só lugar. Com recursos como Pesquisa Conectada e ClickUp Brain, não importa onde seus dados estejam armazenados — o ClickUp facilita localizá-los, gerenciá-los e agir com base neles.
Por que se contentar com “razoável” quando você pode ter “incrível”? Experimente o ClickUp gratuitamente e veja como ele transforma seu fluxo de trabalho em algo ousado, eficiente e simplesmente imparável!