
エージェント推論は、AIシステムが構築される際の基盤となりつつあります。特に、AIシステムが指示に従う以上のことを行う必要がある場合には、その傾向が顕著です。もはや、入力待ちのツールを求めている時代ではありません。思考し、適応し、次の手を打てるシステムが必要なのです。
今日、ほとんどのAIは依然として反応型です。質問に答え、タスクを自動化し、スクリプトに基づいて実行します。しかし、プロジェクトがより複雑になり、データソースが増加するにつれ、それだけでは不十分です。実行だけでなく、推論も必要です。
そこで登場するのがエージェンティックAIです。複雑なタスクを処理し、曖昧性をナビゲートし、企業データから情報を引き出してより賢明な意思決定を行います。「次に何をやればいいのか?」と尋ねるのではなく、すでに知っているのです。
ClickUp Brainは、このようなインテリジェンスをサポートするために開発されました。ハイコンテクストかつ高速なワークフローを実行するチーム向けに設計されており、プランニング、優先順位付け、自動化をサポートします。これらすべてにコンテクスト認識機能が組み込まれています。
興味深いと思いませんか? それでは、エージェントAIの推論がどのように機能するのか、従来のシステムと何が違うのか、そして、それを効果的にワークフローに実装する方法について、さらに詳しく見ていきましょう。
⏰ 60秒でわかる要約
指示に従うだけのAIでは、もはや十分ではありません。エージェント的推論がインテリジェントシステムの仕事のやり方を再定義している理由を説明します。
- エージェント推論を使用して、目標を設定し、プランを立て、適応し、意図を持って行動するAIシステムを作成します。
- 曖昧性を処理し、タスクを管理し、フィードバックから学習するエージェントを導入することで、静的な自動化の限界を超える
- 製品提供、サポートの優先順位付け、企業検索、戦略にエージェントシステムを適用し、大きな成果を導く
- 推論エンジン、動的なワークフロー、フィードバックループ、人間による介入制御を使用して、よりスマートなアーキテクチャを設計する
- 構造化データ、適応可能なインフラ、進捗中のチーム導入戦略により、スケーリングの落とし穴を回避
- 自動化、優先順位付け、状況認識に基づく意思決定機能を備えたClickUp Brainを使用して、インテリジェントなワークフローをより迅速に構築できます。
エージェンシー推論の理解
エージェンティック推論とは、AIシステムが目標を設定し、意思決定を行い、行動を起こすことを指します。 常に指示を必要とすることなく、これらすべてを実行します。 これは、受動的な実行からインテリジェントな自律性への転換です。
実際の動作は、次の場面でご覧いただけます。
- AIアシスタントが、影響度と緊急度に基づいて製品バックログアイテムの優先順位付けを行います。
- コーディングエージェントは、過去のスプリント全体にわたるエラーパターンを分析することで、お客様のコードベースをリファクタリングします。
- 一部のナレッジアシスタントは、サポートチケットが提出される前に、内部文書をスキャンして解決策を提案します。
これらはハードコードされたタスクではありません。文脈を解釈し、目的に沿ったアクションを選択する推論モデルによってサポートされた目標主導の行動です。
それがエージェントAI推論を際立たせ、現代のインテリジェントシステムの基盤となっている理由です。
人工知能におけるエージェンティック・レリジョンの役割
より高度なAIモデルを扱うようになると、従来のロジックツリーや事前定義のスクリプトではリミットが出てきます。
必要なシステムとは:
- あいまいまたは不完全なユーザー入力を解釈する
- トレーニングデータと現在の状況から情報を引き出す
- ステップバイステップの指示なしで特定のタスクを実行する
- データソース全体にわたるあいまいなリクエストを処理する
エージェントAI推論が真価を発揮するのは、まさにこの場面です。AIエージェントは、特に企業検索、製品管理、大規模ソフトウェア開発などの複雑な環境において、意図と実行のギャップを埋めることができます。
また、時とともに改善するAIシステムの構築への扉を開きます。適切なアーキテクチャがあれば、エージェントモデルは継続的に改善し、優先度を調整し、仕事の内容に基づいて出力を洗練させることができます。
😎 楽しい お読みください:機械学習と人工知能の違い
エージェント型システムと非エージェント型システム
現実世界のAIワークフローに適用した場合の2つのアプローチの比較は次のとおりです。
| 機能* | エージェントシステム | 非エージェントシステム |
| 意思決定 | 自律的で、状況を認識する | トリガーベースの反応型 |
| 目標設定 | 動的かつ内部的な | 外部入力によってあらかじめ定義された |
| 適応性 | 結果とフィードバックから学ぶ | 手動での介入が必要 |
| データ処理 | 複数のデータソースを統合 | 一度に1つのタスクまたはデータセットにリミット |
| 出力 | パーソナライズされた進化する対応 | 静的でテンプレート化された出力 |
非エージェント型のワークフローは、主に反復的な自動化や狭い範囲のツールなど、一定の用途があります。しかし、複雑な問題解決、コンテキストの切り替え、戦略的実行などを目的として構築する場合は、エージェント型モデルの方がはるかに幅広い機能を提供できます。
AIにおけるエージェンティック・レリジョンのコアコンポーネント
エージェント型インテリジェンスの構築とは、既存の自動化にさらにレイヤーを追加することではありません。現実のエージェントが目標を設定し、進捗を評価し、時間をかけて適応していく方法を反映した推論プロセスを備えたAIシステムを設計することです。
エージェント型ワークフローを動かすために不可欠なコンポーネントは次のとおりです。
1. 目標の策定
あらゆる推論システムは、明確な目的から始まります。この目標は、ユーザー定義である場合もあれば、新しい入力や新たなパターンに基づいてエージェンティックAIシステム内で生成される場合もあります。
- 製品担当者は、チーム間の妨げとなる要因に基づいて遅延リスクを特定するかもしれません。
- カスタマーサポートエージェントは、繰り返し発生する問題を検出し、解決ワークフローの優先順位付けを行うことができます。
鍵となるのはイニシアティブであり、目標はただフォロワーとして従うだけではなく、自ら生み出し、評価し、改善していくものです。
2. プランニングと分解
目標が定義されると、AIはそれをより小さなタスクに分解します。これには、依存関係、利用可能なリソース、タイミングに関する推論が含まれます。
例えば、レガシーデータベースの移行を依頼されたエージェントは、以下のようなことを行うかもしれません。
- 時代遅れのスキーマを特定する
- 現代的な代替案と照らし合わせる
- 移行を順序立てて行うことで、ダウンタイムを最小限に抑える
これらのシステムは、ただステップを完了するだけではなく、最適な操作の順序を推論します。
3. 文脈記憶とフィードバック
記憶がなければ、適応は不可能です。エージェントAIには、過去のイベント、決定、外部の変化に関する持続的な理解が必要です。この記憶は以下をサポートします。
- 長期目標の進捗状況の追跡
- リアルタイムのフィードバックに基づく戦略の調整
- 関連する結果を保存して、将来の推論を改善する
従来のロジックツリーとは異なり、エージェントモデルはうまくいったこととうまくいかなかったことを評価し、反復を通じて継続的に改善することができます。
4. 適応的な実行
実行は最終ステップではなく、継続的な進化プロセスです。推論エンジンは各タスクの結果を監視し、必要に応じて調整を行います。
例えば、文書要約のワークフローでは、エージェントは以下のような行動を取るかもしれません。
- 低品質の入力データを認識する
- ソース選択の優先順位付けをやり直す
- 聴衆のフィードバックに基づいて要約スタイルを調整する
この柔軟性により、非エージェント型ワークフローは、独立して動作し、なおかつ正確で文脈を認識した応答を生成できるインテリジェントシステムと区別されます。
これらのコンポーネントが連携して仕事をする場合、学習し、適応し、複雑性に対応するより賢いシステムが実現します。 エンジニアリング、製品、またはナレッジマネジメントのためのAIアプリケーションを構築する場合でも、エージェント推論は一貫したインテリジェントな成果の基礎となります。
📖 こちらもご覧ください:AIナレッジベースの構築と最適化方法
エージェンシー推論の導入
仕事をやることだけを考えるAIの設計は簡単です。 仕事の内容とやり方を決定するAIの設計こそが、興味深いものです。 そこでは、エージェンティック・レリジョニングが単なる機能以上のものになります。 アーキテクチャとなるのです。
それをあなたのスタックに実装するために必要なものは次のとおりです。
スクリプトではなく、意思決定の境界を定義する
エージェントシステムにステップバイステップの指示を与えるわけではありません。エージェントが触れることができるもの、追求すべき目標、探索が許可される範囲などの境界を定義します。
つまり:
- 静的なルールではなく、オブジェクト機能を作成する
- エージェントがトレードオフ(速度と精度、短期利益と長期利益)を評価できるようにする
- エージェントにコマンドではなく制約を与える
これにより、システムは柔軟性を備えることになります。予期せぬ入力、プロジェクト範囲の変更、不完全なデータにもフローを中断することなく対応できます。
プランニングと優先順位の変更が可能な推論エンジンを構築する
実装の中心となるのは、推論エンジンです。ロジック層は、目標をタスクに変換し、フィードバックに適応し、アクションを動的に順序付けする役割を担います。
これを設計するには、次のものが必要です。
- 高レベルの目標を実行可能なタスクに分解するプランナー
- 完了したこと、うまくいったこと、避けるべきことを記憶するメモリ層
- 進捗、不整合、妨害をチェックする制御ループ
AI内部にプロダクトマネージャーを構築するようなものだと考えてみてください。当初に要求されたことだけでなく、今何が重要かを常に評価するものです。
適応型ワークフローをサポートするツールと統合する
ほとんどの導入が失敗する理由は、非エージェントシステムの上にインテリジェントエージェントを構築していることです。エージェント的行動を硬直した直線的なワークフローに組み込んでも、うまくいきません。
お客様の環境がサポートしている必要があります。
- 優先度の動的な再順序付け
- スプリントの途中で変更可能なタスクの所有権
- コンテクストに基づく部門横断的なトリガー
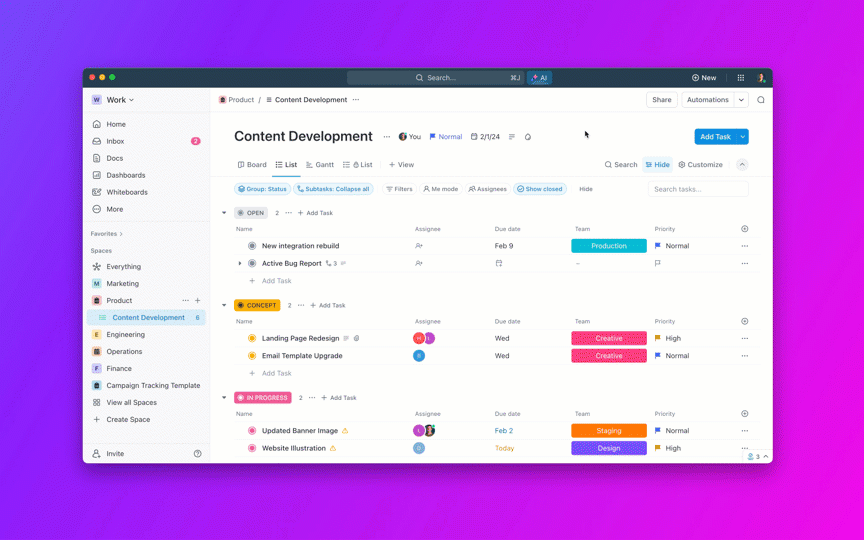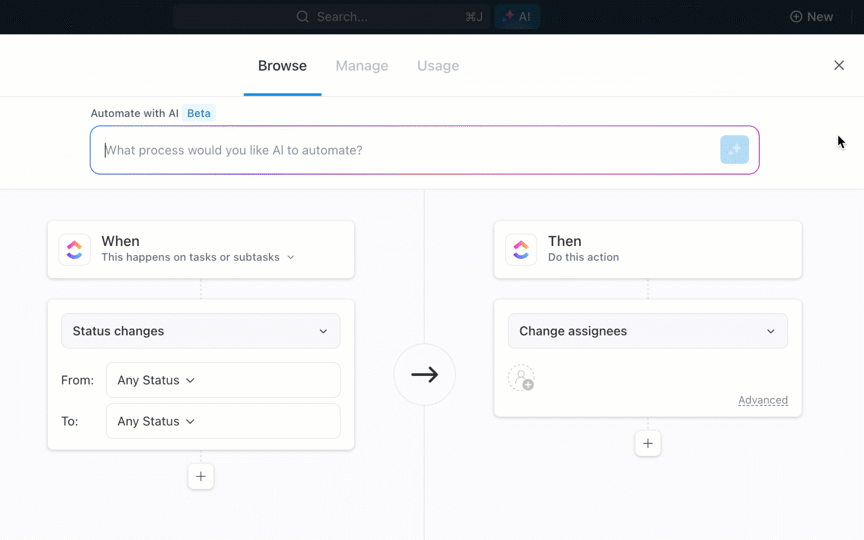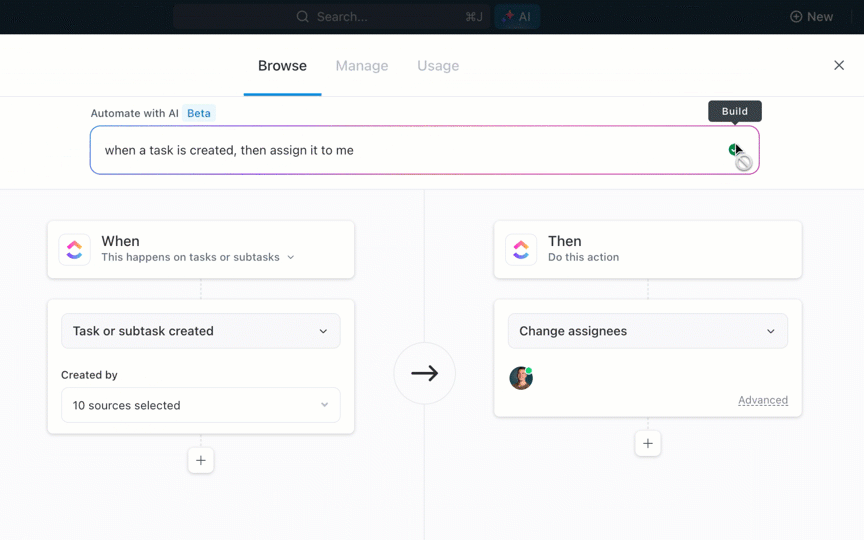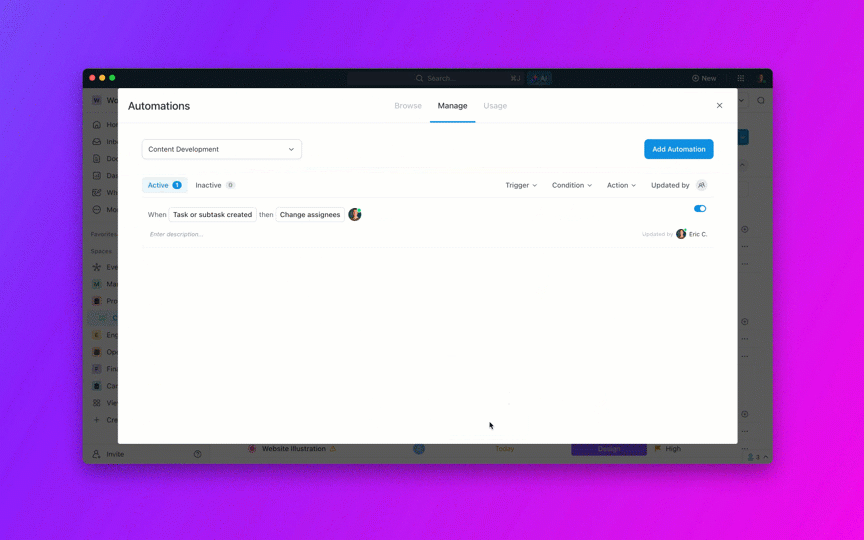
そこでClickUp Brainの出番です。ただ自動化するだけでなく、エージェントがタスク、ドキュメント、データ、依存関係をまたいで推論することを可能にします。エージェントが仕様書が古くなっていると判断した場合、あなたが気づくのを待たずに、そのドキュメントにフラグを付け、タスクを再割り当てし、スプリント目標を調整することができます。
ClickUp Brainは、分析、整理、実行可能な洞察の提供という機能により、意思決定と問題解決において重要な役割を果たします。以下はその例です。
- 情報集約:ClickUp Brainはタスク、ドキュメント、コメントからのデータを集約し、意思決定のための包括的なビューを提供します。
- コンテクスチュアル分析:さまざまなアセットにわたる関係性やパターンを識別し、選択肢のコンテクストを理解するのに役立ちます。
- 優先順位付け*:タスクの優先度と期限を分析することで、ClickUp Brainは重要な問題が最初に処理されるようにします。
- コラボレーションとコミュニケーション:議論を要約し、鍵となるポイントを強調することで、すべての利害関係者が必要な情報にアクセスできるようにします。
- 問題の特定:ClickUp Brainはボトルネックや期限切れのタスクを検出し、問題が深刻化する前に潜在的な問題を警告します。
- 意思決定サポート:正確な情報に基づく情報に基づいた意思決定を促進するための洞察と推奨を提供します。
- 効率性と自動化:反復的なタスクを自動化することで、ClickUp Brainは時間を節約し、戦略的な意思決定に集中できるようにします。
AIによるタスクの推奨機能やワークフロー自動化機能を活用することで、目標の設定や進捗管理、タスクの自動化、情報に基づいた意思決定を簡単に行うことができます。ClickUp Brainは、目標の設定と進捗管理を簡素化し、戦略目標との整合性を確保します。
- 目標とOKRのトラッキング:ClickUpを使用して、目標とOKRのトラッキング用に作業スペースの階層を整理しましょう。リストビューやガントチャートビューなどのツールを使用して、進捗状況を視覚化し、目標が軌道に乗っていることを確認できます。ClickUp AIは、洞察と推奨を提供することで、目標を測定可能かつ実行可能な状態に保ち、これをさらに強化します。
- Docsの更新を統合する:ClickUp Docsで目標とOKRの更新を統合します。これにより、情報を一元化し、関係者にタグ付けし、タスクを参照することができます。ClickUp AIは、更新の作成、進捗状況の要約、ミーティングメモからの実行可能な洞察の生成までサポートします。
- AI プロバイダー:目標やアップデートを明確に表現することに苦労していませんか?ClickUp AI はコンテンツの草案を作成し、要約を提供し、さらには次のステップを提案することで、時間と努力を節約します。
ClickUp Brainの中心には自動化があり、反復的なプロセスがシームレスに処理されるため、価値の高いタスクに集中することができます。
- ワークフローの自動化:ClickUp BrainのAutoAI機能を使用すると、タスクの作成、更新、接続を自動化できます。 例えば、サブタスクが完了したときに親タスクのステータスを更新するなど、特定の条件に基づいてアクションをトリガーする自動化を設定できます。
- AIが生成するサブタスク*:シンプルなタスク名から、ClickUp Brainは詳細なサブタスクを生成し、ワークフローで何かを見落とすことがないようにします。
- カスタム自動化:毎日のタスクのスケジュール、テンプレートの適用、依存関係の管理など、独自のニーズに合わせて自動化をカスタマイズします。これにより、手動による努力を軽減し、プロジェクト全体の一貫性を確保します。
ClickUp Brainは、リアルタイムの洞察と推奨を提供することで、データ主導の意思決定を可能にします。
- AIによるタスク推奨機能*:ClickUp Brainはあなたの作業スペースを分析し、注意が必要なタスクを提案することで、効果的な優先順位付けをサポートします。これにより、重要なタスクが迅速に対処され、全体的な効率が向上します。
- リアルタイム要約:個々のタスクを開かなくても、プロジェクトの概要と最新情報を即座に確認できます。この機能は、進捗状況と潜在的な障害に関する概要を必要とするマネージャーにとって特に便利です。
- 接続された検索と洞察:ClickUp BrainはGoogle DriveやSharePointなどの外部ツールと統合されており、プラットフォームをまたいで情報を検索し、分析することができます。これにより、情報に基づいた意思決定に必要なすべてのデータが確保されます。
ClickUp Brainをワークフローに統合することで、より高い効率性、明瞭性、集中力を実現できます。野心的な目標の設定、反復的なタスクの自動化、戦略的決定など、ClickUp Brainは究極の推論パートナーです。

AIによるタスク推奨やワークフロー自動化などの機能が組み込まれたClickUp Brainは、エージェントが実行だけでなく、インパクトにも集中できるようにサポートします。
完璧ではなくフィードバックを考慮した設計
エージェントは最初から正しく機能するわけではありません。しかし、学習するように構築されたシステムであれば問題ありません。フィードバックループこそが、エージェント型AIの能力を向上させるのです。
あなたの仕事は次のとおりです。
- 環境を計測し、高品質なフィードバック(タスクの成果、妨げとなる要因、解決時間)を取得する
- エージェントにパフォーマンスに基づいて自身の行動を修正させる
- 初期の論理に過剰適合しないようにし、使用状況に応じて成長させる
チームやプロジェクト全体にわたってスケーリングできるシステムを求めるのであれば、柔軟性と関連性のトレードオフを考慮する必要があります。
エージェンティック・レリジョンは、単にインテリジェンスに関するものではありません。それはインフラストラクチャに関するものです。目標、プランニング、フィードバック、環境に関する選択が、エージェントが思考する以上のことをやれるかどうかを決定します。
また、ClickUp Brainのようなツールを使用すれば、古いワークフローに推論を無理やり取り付ける必要はありません。チームの動きと同じくらい素早く意思決定ができるシステムを構築できます。
📖 Read More: より良い自動化のためのAIエージェントの構築方法
AIシステムにおけるエージェンティック・レリジョンの応用
エージェンティック・レリジョニングは、ロジックツリーや静的な自動化が機能しない生産環境で実装されています。これらは、複雑性、曖昧性、戦略的意思決定を解決するライブシステムです。
実際の動作は次のようになります。
1. スコープと妨げとなる要因を管理する製品デリバリーエージェント
5つの製品チームにまたがる毎週のスプリントを実施しているフィンテック企業では、エージェンティックシステムが導入され、スコープの肥大化とスプリントの速度を監視しています。
エージェント:
- Jira、Notion、GitHubにわたるストーリーをスキャン
- 速度の傾向のずれ(例えば、3つのバックログストーリーが次のスプリントに持ち越される)を検出する
- マイルストーンを維持するために、納品リスクを警告し、範囲縮小を自動的に提案する
それは、時間、依存関係、進捗データ全体にわたって推論を行い、プロジェクトのメタデータだけでなく、
2. 社内での解決策を訓練されたエージェントのトリアージをサポート
B2B SaaS企業では、L2サポートエージェントが繰り返しエスカレーションに追われていました。エージェントは、社内チケットスレッド、ドキュメントの更新、製品ログについてトレーニングを受けていました。
現在:
- 複数の意図推論により新しいチケットを分類
- 過去のチケットのログと過去の解決策を参照する
- 文脈に応じた応答の提案を自動的に作成し、エッジケースを適切なチームに振り分ける
時間が経つにつれ、繰り返されるパターンから製品のバグが浮上し始めた。チャネルが断片化しているため、人間には見つけられなかったものだ。
3. 展開パイプラインにおけるインフラ最適化エージェント
モデルの展開(MLFlow、Airflow、Jenkins)を管理するAIインフラチームは、過去の失敗に基づいてトレーニングされたDevOpsエージェントを実装しました。
それは自律的に:
- 失敗するジョブと根本原因(ディスクスペースのオーバーフロー、メモリの制限など)を検出
- 影響と下流のタスクチェーンに基づいてビルドキューの優先順位を再設定
- より優先度の高いワークフローをブロック解除するために、デプロイメントの注文を変更する
これにより、インシデント対応が手動のアラートから自動化された推論とアクションに移行し、構築のダウンタイムが削減されました。
👀 やること:AIエージェントの概念は1950年代にまで遡ります。当時、研究者たちはチェスをプレイし、手を考え抜くプログラムを作成しました。
これにより、ゲーム戦略は自律的な意思決定の最初の現実世界のテストの1つとなります。
4. 企業検索における知識の統合
数千件もの社内メモ、契約書、規制の更新を管理する法律事務所では、検索が膨大な量に耐えられず失敗していました。
現在、検索エージェントは:
- 「SEC開示に関する最近の判例を要約する」といったクエリを解釈する
- 内部データベース、規制、過去のクライアント向けアドバイスメモから情報を取得
- 引用と表面レベルのリスク評価を含む要約をまとめる
違いは何か?キーワード一致ではない。構造化データと非構造化データの両方に対して、ユーザーの役割とケースのコンテキストに合わせて推論を行う。
5. 運用チームと戦略チームのOKRエージェント
急速に市場を拡大するヘルステック企業では、経営陣は四半期ごとのOKRを適応させる方法が必要でした。
プランニングエージェントは、以下を行うように訓練されました。
- KPIの動きを監視する(例えば、ある地域での患者獲得の遅れなど)
- 根本的な機能(例えば、オンボーディングの遅延、サポートの待ち時間)に起因する障害を追跡する
- OKRスコープの修正と部門横断的なリソースシフトを推奨する
これにより、四半期内の目標を適応させることが可能になり、以前はリトロスペクティブプランニングに限定されていたことが可能になりました。
これらの応用例から、これらのエージェンティック推論システムが、AIを実際のビジネスロジック内で動作させることが可能であることが明確に示されています。静的なルールやワークフローでは対応できない場合でもです。
📖 こちらもどうぞ:AIワークフロー自動化による生産性最大化ガイド
課題と考慮事項
エージェントAIの構築は、アーキテクチャの転換を意味します。そして、それには現実的な摩擦が伴います。潜在的な可能性は非常に大きいものの、エージェント推論を実用化するには独自の課題が伴います。
導入を真剣に検討している場合は、これらの制約を考慮して設計する必要があります。
1. 自律性と制御のバランス
エージェントシステムは、独立して行動することを約束していますが、それにはリスクもあります。明確な境界がなければ、エージェントは間違った目的のために最適化したり、十分な文脈なしに行動したりする可能性があります。
必要なもの:
- 各エージェントの許容可能な動作パラメーターを定義する
- 機密性の高い操作には、人間による上書きレイヤーを構築する
- チェックポイントを設定し、鍵となる意思決定ノードにおけるエージェントの行動を評価する
完全な自由が目標なのではありません。安全で目標に沿った自律性が目標なのです。
2. 質の悪い訓練データ = 予測不可能な動作
エージェントは、その基盤となるトレーニングデータが優れているほど優れており、ほとんどの組織では、断片化された、時代遅れ、または矛盾したデータセットが依然として存在しています。
信頼できる信号がなければ、推論エンジンは以下のように動作します。
- 無関係または質の低い回答を浮き彫りにする
- 文脈の多い環境における関連性の誤った解釈
- 限定的なユースケースを超えて意思決定を拡大することに苦労する
これを修正するには、データソースを統合し、標準を強化し、ラベル付けされたデータセットを継続的に改善する必要があります。
3. 推論は静的なインフラストラクチャではスケールしない
多くの企業が、柔軟性のない適応性のないシステムにエージェント機能を無理やり取り付けようとしていますが、すぐに壊れてしまいます。
エージェントシステムに必要なもの:
- エージェントの決定にリアルタイムで適応できるイベント駆動型アーキテクチャ
- 変化する目標に動的に対応するAPIとワークフロー
- フィードバックループをサポートするインフラストラクチャ、単なるアウトプットにとどまらない
現在のスタックが適応できない場合、エージェントがどれほど賢くても限界にぶつかります。
👀 ご存知でしたか? NASAのキュリオシティ・ローバーは、火星で分析する岩石を自律的に選択するために、AEGISと呼ばれるAIシステムを使用しています。
地球からの指示を待つことなく、リアルタイムで科学的判断を下すことができました。
4. 推論のないRAGシステムは壁にぶつかる
Retrieval-Augmented Generation(RAG)は強力ですが、エージェント的ロジックがなければ、ほとんどのRAGシステムは受動的なままです。
問題が生じるのは、以下の場合です。
- 検索ロジックは成功の結果に基づいて適応することができない
- エージェントは文書の品質や統合ギャップを評価できない
- クエリ構築には文脈認識が欠けている
このギャップを埋めるには、RAGシステムが何を取得すべきか、なぜそれが重要なのか、そしてそれがどのようにタスクに適合するのかを推論する必要があります。そして、見つけたものからただテキストを生成するだけではなく、検索エンジンではなく戦略家のように機能するようRAGシステムをアップグレードする必要があります。
5. 組織での導入が最大の障害となることがよくあります。
たとえ技術がうまく機能しても、人々はAIに優先順位付け、プランニング、または部門横断的な調整を任せることに抵抗を感じます。
必要なもの:
- 非エージェント型ワークフローから始めて、徐々に進化させていく
- エージェントの可視性、監査可能性を維持し、簡単に上書きできるようにする
- エージェントシステムがどのように推論を行うかをチームに教育し、時間をかけて信頼を構築する
導入はモデルよりも、明確性、制御、透明性の方が重要です。
6. エージェントは構造化されたフィードバックなしでは適応できない
エージェントの適応能力は、何を学習するかによって決まります。フィードバックループが適切に機能していない場合、エージェントは停滞してしまいます。
つまり、それは次のことを意味します。
- タスク完了だけでなく、あらゆる結果(成功/失敗)を記録する
- 定性的および定量的なパフォーマンスデータのフィードバック
- モデル更新を推進するためにそれを使用し、メトリクスダッシュボードだけでなく
エージェンティックAIシステムは、常に改善を続けることを目的としています。フィードバック構造がなければ、停滞してしまいます。
エージェンティック・レージョンは、プレッシャーのかかる状況下でも推論できるように構築された、モデル、ロジック、制約、ワークフローのシステムです。単なる自動化レイヤーのように扱うと、失敗します。
しかし、関連性、フィードバック、制御を考慮して設計すれば、システムはただ行動するだけでなく、考え、常に改善し続けます。
思考できるシステムが未来を担う
エージェント推論は、現実世界環境におけるインテリジェントシステムの新しい標準となりつつあります。 大規模な言語モデルを使用して複雑なクエリを処理したり、意思決定の自動化にAIソリューションを導入したり、ツール、データ、チーム全体にわたってタスクを実行できるエージェントを設計したりする場合、これらのシステムは現在、新たな課題に直面しています。 これらのシステムは、コンテクストと意図を考慮して推論、適応、行動する必要があります。
最も関連性の高い文書を浮上させることから、断片化された企業知識を理解し、適切な文脈で複雑なタスクを実行することまで、適切なタイミングで関連性の高い情報を提供する能力は、もはやオプションではありません。
ClickUp Brainを使用すると、タスクを完了するだけでなく、仕事を目標に一致させるエージェンティックなワークフローの構築を開始できます。今すぐClickUpをお試しください。