

あらゆるインタラクションから学習するカスタマーサービスボット。リアルタイムの洞察に基づいて戦略を調整する営業アシスタント。これらは単なる概念ではなく、AI学習エージェントのおかげで現実のものとなっている。
しかし、これらのエージェントの特徴は何であり、学習エージェントはこの適応性を達成するためにどのように機能するのだろうか?
固定されたプログラミングで動作する従来のAIシステムとは異なり、学習エージェントは進化する。
時間の経過とともに適応し、改善し、行動を洗練させていくので、自律走行車やヘルスケアのように、柔軟性と精度が譲れない産業には欠かせない存在となる。
学習エージェントは、人間のように経験を積むことで賢くなるAIだと考えてほしい。
このブログでは、AIにおける学習エージェントの鍵となる構成要素、プロセス、種類、そして応用例を探る。🤖
⏰ 60秒要約
ここでは、AIにおける学習エージェントについて簡単に説明します:
やること: 対話を通じて適応する。例えば、カスタマーサービスのボットは対応を洗練させる。
主な用途: ロボット工学、パーソナライズされたサービス、ホーム・デバイスのようなスマート・システム。
コア・コンポーネント:
- 学習要素: パフォーマンスを向上させるために知識を収集する。
- **学習した知識に基づいてタスクを実行する。
- 批評家: 行動を評価し、フィードバックを提供する。
- 問題発生要素:さらなる学習の機会を特定する
**学習方法
- 教師あり学習:*ラベル付きデータを用いてパターンを認識する。
- 教師なし学習:ラベル付けされていないデータの構造を識別する
- 強化学習:試用版を通して学習する。
現実世界への影響:** 様々な産業における適応性、効率性、意思決定を強化する。
⚙️ ボーナス: AIの専門用語に圧倒されそうですか?私たちの包括的な AI用語集をご覧ください。 を参照すると、基本的な概念や高度な用語を簡単に理解することができます。
AIにおける学習エージェントとは?
**AIにおける学習エージェントは、環境から学習することによって、時間の経過とともに改善するシステムである。
固定されたままの従来のAIシステムとは異なり、学習エージェントは継続的に進化する。そのため、予測不可能で常に条件が変化するロボット工学やパーソナライズされたレコメンデーションには欠かせない。
クリックアップAI
**学習エージェントは、環境を認識し、フィードバックから学び、行動を改善するというフィードバックループで動作します。これは、人間が経験から学ぶ方法にヒントを得ています。
学習エージェントの鍵となる要素
学習エージェントは、通常、適応性と時間の経過に伴う改善を確実にするために、相互に連携するいくつかのコンポーネントで構成されます。
以下は、この学習プロセスの重要な構成要素である。📋
学習要素
エージェントの中心的な責任は、データ、インタラクション、フィードバックを分析することによって、知識を獲得し、パフォーマンスを向上させることである。
学習要素
/参照 https://clickup.com/blog/ai-techniques// AIテクニック /%href/
教師あり学習、強化学習、教師なし学習などのAI技術により、エージェントはその機能を高めるために行動を適応・更新する。
*例:📌 Siriのようなバーチャルアシスタントは、より正確でパーソナライズされた応答を提供するために、頻繁に使用されるコマンドや特定のアクセントなど、時間の経過とともにユーザーの好みを学習する。
性能要素
このコンポーネントは、環境と相互作用し、利用可能な情報に基づいて意思決定を行うことで、タスクを実行する。基本的にエージェントの "アクションアーム "です。
例:📌 **自律走行車では、パフォーマンスエレメントが交通データと環境条件を処理して、赤信号での停止や障害物の回避など、リアルタイムの意思決定を行います。
評論家
批評家は、パフォーマンス・エレメントが取った行動を評価し、フィードバックを提供する。このフィードバックは、学習要素がうまくいった点と改善が必要な点を特定するのに役立ちます。
例:📌 **推薦システムでは、批評家はユーザーのインタラクション(クリックやスキップなど)を分析し、どの提案が成功したかを判断し、学習要素が将来の推薦を改良するのを助けます。
問題ジェネレーター
このコンポーネントは、エージェントがテストする新しいシナリオやアクションを提案することで、探索を促します。
エージェントのコンフォートゾーンを超えさせ、継続的な改善を保証します。また、エージェントの経験範囲を広げることで、最適でない結果を防ぎます。
**例: 📌 eコマースAIでは、問題ジェネレーターがパーソナライズされたマーケティング戦略を提案したり、カスタマーの行動パターンをシミュレートしたりします。これは、AIが様々なユーザーの嗜好に合わせた推奨を提供するためのアプローチを改良するのに役立ちます。
学習エージェントにおける学習プロセス
学習エージェントは、適応し改善するために、主に3つの鍵に依存している。その概要は以下の通りである。👇
**1.教師あり学習
エージェントはラベル付きデータセットから学習し、各入力は特定の出力に対応する。
この方法は、学習のために正確にラベル付けされた大量のデータを必要とし、画像認識、言語翻訳、不正検出などのアプリケーションで広く使用されている。
**例:📌 電子メールフィルタリングシステムは、履歴データに基づいて、電子メールを スパムとして分類するかどうかを学習する。学習要素は、入力(電子メールコンテンツ)と出力(分類ラベル)の間のパターンを識別し、正確な予測を行う。
**2.教師なし学習
エージェントが明示的なラベルなしで情報を分析することで、データ内の隠れたパターンやリレーションシップが現れる。このアプローチは、異常の検出、推薦システムの作成、データ圧縮の最適化などに有効な仕事である。
また、ラベル付きデータではすぐに見えない可視性を特定するのにも役立ちます。
**例: 📌 マーケティングにおけるカスタムセグメンテーションは、ユーザーを行動に基づいてグループ化し、ターゲットを絞ったキャンペーンを設計することができる。その焦点は、構造を理解し、クラスターや関連性を形成することである。
**3.強化学習
上記とは異なり、強化学習(RL)は、エージェントがある環境において、時間の経過とともに累積報酬が最大になるように行動することを含む。
エージェントは試用版によって学習し、報酬やペナルティによってフィードバックを受ける。
🔔 覚えておいてほしいこと:学習方法の選択は、問題、データの利用可能性、環境の複雑さに依存関係する。強化学習は、行動を適応させるためにフィードバックループを使用するため、直接的な監視のないタスクには不可欠です。
強化学習のテクニック
- ポリシーの反復: 状態を行動にマップするポリシーを直接学習することで、報酬の期待値を最適化する。
- **各状態と行動のペアの価値を計算することで、最適な行動を決定する。
- モンテカルロ法:**行動報酬を予測するために複数の将来シナリオをシミュレートする。
実際のRL応用例
- 自律走行: RLアルゴリズムは、シミュレーション環境から継続的に学習することで、車両が安全にナビゲートし、ルートを最適化し、交通条件に適応するよう訓練する。
- **アルファ碁とゲームAI:強化学習は、Googleのアルファ碁を動かし、囲碁のような複雑なゲームの最適な戦略を学習することで、人間のチャンピオンを打ち負かした。
- ダイナミック・プライシング: eコマース・プラットフォームはRLを使用して、需要パターンと競合の行動に基づいて価格戦略を調整し、収益を最大化する。
**学習エージェントはチェスやスタークラフトのようなゲームで人間のチャンピオンを破り、その適応性と知性を示している。
Q学習とニューラルネットワークのアプローチ
Q学習は広く使われているRLアルゴリズムであり、エージェントは探索とフィードバックを通じて各状態-行動ペアの価値を学習する。エージェントはQテーブルを構築し、状態-行動ペアに期待報酬を割り当てるマトリックスを作成する。
エージェントは最も高いQ値を持つアクションを選択し、精度を向上させるために繰り返しテーブルを改良する。
**例:📌 効率的に荷物を配達するために学習するAI搭載のドローンは、Q学習を使ってルートを評価する。これは、時間通りに配達した場合は報酬を、遅延や衝突があった場合はペナルティを割り当てることでやることである。時間をかけてQテーブルを改良し、最も効率的で安全な配達経路を選択する。
しかし、高次元の状態スペースを持つ複雑な環境では、Qテーブルは実用的でなくなる。
そこでニューラルネットワークがステップを踏み、Q値を明示的に記憶する代わりに近似する。このシフトにより、強化学習はより複雑な問題に取り組むことができるようになる。
ディープQネットワーク(DQN)はこれをさらに進め、ディープラーニングを活用して画像やセンサー入力のような生の非構造化データを処理する。これらのネットワークは、拡張機能エンジニアリングの必要性を回避し、感覚情報を行動に直接マップすることができる。
**例:📌 自動運転車では、DQNはリアルタイムのセンサーデータを処理して、車線変更や障害物回避などの運転戦略を、事前にプログラムされたルールなしで学習する。
これらの高度な手法により、エージェントは高い計算能力と適応性を必要とするタスクに学習能力を拡張することができる。
⚙️ ボーナス: エージェントを作成し、改良する方法を学びます。 AI知識ベース 情報管理を効率化し、意思決定を改善し、チームの生産性を高める。
エージェントの学習プロセスは、インテリジェントな意思決定のための戦略をリアルタイムで作成することに価値を置く。意思決定を支援する鍵はここにある:
- 探索と利用:エージェントは、より良い戦略を見つけるために新しい行動を探索することと、報酬を最大化するために既知の行動を利用することのバランスをとる。
- マルチエージェントの意思決定: 協調的または競争的設定では、エージェントは相互作用し、共有目標または敵対戦術に基づいて戦略を適応させる。
- 戦略的トレードオフ: エージェントはまた、配送システムにおける速度と正確さのバランスのような、文脈に基づいた目標の優先順位を学習する。
🎤 ポッドキャスト・アラート: 人気のあるポッドキャストのリストをご覧ください。 AIポッドキャスト を見て、学習エージェントの操作について理解を深めよう。
AIエージェントの種類
人工知能における学習エージェントは様々なフォームがあり、それぞれが特定のタスクや課題に合わせて調整されています。
私の仕事のメカニズム、ユニークな特徴、実際の例を探ってみよう。👀
単純な反射エージェント
このようなエージェントは、あらかじめ定義されたルールに基づいて刺激に直接反応する。条件行動(if-then)メカニズムを使用し、履歴や未来を考慮することなく、現在の環境に基づいて行動を選択する。
特徴
- 論理ベースの条件行動システムで動作する
- 変化に適応したり、過去の行動から学んだりすることはしない。
- 透明で予測可能な環境で最高のパフォーマンスを発揮する
例
サーモスタットは、温度が設定されたしきい値を下回ると暖房を設定し、上 昇すると暖房を切る、単純な反射エージェントとして機能する。サーモスタットは純粋に現在の温度測定値に基づいて意思決定を行う。
**学習エージェントに空腹や喉の渇きのような模擬的な欲求を与え、目標指向の行動を発達させ、これらの「欲求」を効果的に満たす方法を学習するように促す実験もある。
モデルベース反射エージェント
これらのエージェントは、自分の行動の影響を考慮できるように、世界の内部モデルを保持している。また、すぐに知覚できる範囲を超えて、環境の状態を推測する。
特徴
- 蓄積された環境モデルを意思決定に利用する。
- 部分的に観測可能な環境を扱うために、現在の状態を推定する。
- 単純な反射エージェントと比較して、柔軟性と適応性が高い
例
テスラの自動運転車は、道路をナビゲートするためにモデルベースのエージェントを利用している。可視性の障害物を検知し、高度なセンサーとリアルタイムのデータを用いて、死角にある車両を含む周辺車両の動きを予測する。これにより、正確な情報に基づいた運転判断が可能になり、安全性と効率が向上します。
**学習エージェントのコンセプトは、試行錯誤型学習や報酬型学習など、動物で観察される行動を模倣することが多い。
ソフトウェア・エージェントとバーチャル・アシスタントの機能
これらのエージェントはデジタル環境で動作し、自律的に特定のタスクを実行する。
SiriやAlexaのようなバーチャルアシスタントは、自然言語処理(NLP)を使用してユーザーの入力を処理し、クエリに答えたりスマートデバイスを制御したりするようなアクションを実行します。
特徴
- スケジュール設定、リマインダー設定、デバイスのコントロールなど、日々のタスクを簡素化
- 学習アルゴリズムとユーザー対話データを使用して継続的に改善
- 非同期で動作し、リアルタイムまたはトリガーで応答
例
Alexaは、音声コマンドを解釈し、クラウドベースのシステムに接続し、適切なアクションを実行することで、音楽を再生したり、リマインダーを設定したり、スマートホームデバイスを制御したりすることができる。
**ユーティリティベースのエージェントは、さまざまな行動を評価することで結果を最大化することに重点を置き、AIでは学習ベースのエージェントと一緒に仕事をすることが多い。学習型エージェントは経験に基づいて時間をかけて戦略を洗練させ、効用ベースの意思決定を使ってより賢い選択をすることができる。
マルチエージェントシステムとゲーム理論の応用
マルチエージェントシステムとは、複数の相互作用するエージェントが、個人または集団の目標を達成するために、協力したり、競争したり、あるいは独立して仕事をしたりするシステムである。
さらに、ゲーム理論の原理は、しばしば競争シナリオにおける彼らの行動を導く。
特徴
- エージェント間の調整や交渉が必要
- 動的で分散した環境で仕事をする。
- サプライチェーンや都市交通のような複雑なシステムのシミュレーションや管理
例
Amazonの倉庫自動化システムでは、ロボット(エージェント)が協力して仕事をし、アイテムをピッキング、仕分け、運搬する。これらのロボットは衝突を回避し、円滑なオペレーションを確保するために互いにコミュニケーションをとる。ゲーム理論の原則は、以下のような管理に役立ちます。 競合する優先度 システムが効率的に動作するように、スピードとリソースのバランスを取るような。
学習エージェント**の応用
学習エージェントは、効率と意思決定を改善することで、多くの産業を変革してきた。
以下はその主な応用例である。📚
ロボット工学と自動化**。
学習エージェントは現代のロボット工学の中核であり、ロボットがダイナミックな環境で自律的かつ適応的に動作することを可能にする。
タスクごとに詳細なプログラミングを必要とする従来のシステムとは異なり、学習エージェントは相互作用とフィードバックを通じてロボットの自己改善を可能にする。
仕事の仕組み
学習エージェントを搭載したロボットは、強化学習のような技術を用いて周囲の環境と相互作用し、自分の行動の結果を評価する。ロボットは時間をかけて行動を洗練させ、報酬を最大化し、ペナルティを回避することに集中する。
ニューラルネットワークはこれをさらに進め、ロボットが視覚入力や空間レイアウトのような複雑なデータを処理できるようにし、高度な意思決定を促進する。
例
- **農業では、学習エージェントが自律走行するトラクターを動かし、フィールドをナビゲートし、変化する土壌条件に適応し、植え付けや収穫のプロセスを最適化する。リアルタイムのデータを利用して効率を改善し、無駄を省く。
- 産業用ロボット: 製造業では、学習エージェントを搭載したロボットアームが、自動車の組み立てラインなどにおいて、精度、効率、安全性を向上させるために動きを微調整する。
📖あわせてお読みください: より速く、より賢く、より良くするAIハック
シミュレーションとエージェントベースモデル
学習エージェントは、複雑なシステムを研究するための費用対効果が高く、リスクのない方法を提供するシミュレーションを支援します。
これらのシステムは、明確な行動と適応能力を持つエージェントをモデル化することで、実世界のダイナミクスを再現し、結果を予測し、戦略を最適化する。
私の仕事
シミュレーションにおける学習エージェントは、環境を観察し、行動をテストし、効果を最大化するために戦略を調整する。学習エージェントは継続的に学習し、時間の経過とともに改善され、結果を最適化することができます。
シミュレーションは、サプライチェーン・マネジメント、都市プランニング、ロボット開発において非常に効果的である。
例
- 交通管理:* シミュレーテッド・エージェントは都市の交通フローをモデル化する。これにより、研究者は新しい道路や渋滞対策のような介入策を実施前にテストすることができる。
- 疫学:* パンデミックシミュレーションでは、学習エージェントが人間の行動を模倣し、病気の蔓延を評価する。また、社会的距離を置くなどの封じ込め策の有効性を評価するのにも役立ちます。
**のデータ前処理を最適化する。 AI機械学習 学習エージェントの精度と効率を向上させる。質の高い入力により、より信頼性の高い意思決定が可能になる。
インテリジェント・システム
学習エージェントは、リアルタイムのデータ処理とユーザーの行動や嗜好への適応を可能にすることで、インテリジェント・システムを推進します。
スマート家電から自律的な清掃機器まで、これらのシステムはユーザーとテクノロジーとの関わり方を変革し、日常のタスクをより効率的でパーソナライズされたものにします。
私の仕事**とは?
ルンバのようなデバイスは、搭載されたセンサーと学習エージェントを使って、ホームのレイアウトをマップし、障害物を避け、掃除ルートを最適化する。頻繁に掃除が必要な場所や家具の配置などのデータを常に収集・分析し、使用するたびにパフォーマンスを向上させる。
例
- スマートホーム機器: Nestのようなサーモスタットは、ユーザーのスケジュールや温度の好みを学習する。快適さを維持しながら、省エネになるように設定を自動調整する。
- **ロボット掃除機:ルンバは1秒間に多くのデータを収集する。ルンバは毎秒多くのデータを収集し、家具の周囲を移動したり、人の出入りが多い場所を特定して効率的に掃除することを学習する。
これらのインテリジェント・システムは、ワークフローの合理化など、日常生活における学習エージェントの実用的な応用を浮き彫りにしている。
/参照 https://clickup.com/ja/blog/176413/how-to-use-ai-to-automate-tasks/ 反復タスクの自動化 /%href/
を利用して効率化を図る。
**ルンバは1秒間に230,400件以上のデータを収集し、ホームのマップを作成します。
インターネット・フォーラムとバーチャル・アシスタント**。
学習エージェントは、オンライン対話とデジタル支援を強化するのに役立っている。学習エージェントは、フォーラムやバーチャル・アシスタントがパーソナライズされた体験を提供することを可能にする。
学習エージェントは、フォーラムやバーチャルアシスタントがパーソナライズされた体験を提供できるようにする。
学習エージェントは、フォーラムでのディスカッションをモデレートし、スパムや有害なコンテンツを識別して削除する。利息はまた、ユーザーの閲覧履歴に基づいて、関連するトピックをユーザーに推奨する。
/参照 https://clickup.com/ja/blog/76234/ai-tools-for-virtual-assistants/ AIバーチャルアシスタント /%href/
アレクサやGoogleアシスタントのようなAIバーチャルアシスタントは、自然言語入力を処理するために学習エージェントを使用し、時間の経過とともに文脈理解を向上させる。
例
- インターネット・フォーラム:* Redditのモデレーション・ボットは、ルール違反や有害な言葉遣いの投稿をスキャンするために学習エージェントを採用している。このようなAIベースの衛生管理によって、オンライン・コミュニティは安全で魅力的なものに保たれている。
- バーチャルアシスタント: アレクサは、お気に入りのプレイリストやよく使うスマートホームのコマンドなど、ユーザーの好みを学習し、パーソナライズされたプロアクティブな支援を提供する。
**⚙️ ボーナス 職場でAIを活用する方法 インテリジェント・エージェントを使って生産性を高め、タスクを効率化する。
学習エージェントの開発における課題
学習エージェントの開発には、アルゴリズム設計、計算需要、実世界での実装など、技術的、倫理的、実用的な課題が含まれる。
AI開発が進化する中で直面する鍵を見てみよう。🚧
探索と利用**のバランス
学習エージェントは、探索と利用のバランスをとるというジレンマに直面する。
ε-greedyのようなアルゴリズムが助けになるとはいえ、適切なバランスを達成することは、文脈に大きく依存する。さらに、過剰な探索は非効率的な結果をもたらす可能性があり、一方、過剰な探索への依存は最適解を生み出さない可能性がある。
高い計算コストの管理
洗練された学習エージェントの訓練には、しばしば拡張機能を必要とする。これは、複雑なダイナミクスや大きな状態行動スペースを持つ環境では、より適用しやすい。
Deep Q-Learningのようなニューラルネットワークによる強化学習のようなアルゴリズムは、かなりの処理能力とメモリを必要とすることを覚えておいてください。リソースに制約のあるアプリケーションでリアルタイム学習を実用化するには、助けが必要だ。
スケーラビリティと転移学習の克服
学習エージェントを大規模で多次元的な環境で効果的に動作させるためのスケーリングは、依然として困難である。エージェントがあるドメインから別のドメインに知識を適用する転移学習は、まだ初期段階にある。
そのため、タスクや環境を超えて汎化する能力はリミットされている。
**例:チェス用に訓練されたAIエージェントは、ルールやオブジェクトが大きく異なるため、囲碁では苦労するだろう。
データの質と可用性
学習エージェントの性能は、学習データの質と多様性に大きく依存する。
データが不十分であったり、偏っていたりすると、不完全な学習や誤った学習につながり、最適でない、あるいは非倫理的な決定を下す結果になりかねない。さらに、学習のために実世界のデータを収集することは、費用と時間がかかる可能性がある。
⚙️ ボーナス: Explore
/参照 https://clickup.com/ja/blog/145870/ai-courses/ AIコース /%href/
を受講し、他のエージェントへの理解を深める。
エージェントを学習するためのツールとリソース
開発者や研究者は、学習エージェントを構築し訓練するために様々なツールを利用しています。TensorFlow、PyTorch、OpenAI Gymのようなフレームワークは、機械学習アルゴリズムを実装するための基盤となるインフラを提供します。
これらのツールは、シミュレーション環境の構築にも役立ちます。いくつかの AIアプリ もこのプロセスを簡素化し、強化する。
伝統的な機械学習アプローチでは、Scikit-learnのようなツールが依然として信頼性が高く効果的だ。
AIの研究開発プロジェクトの管理に、 ClickUp よりも
/以上 https://clickup.com/ja/blog/3892/task-management-software/ タスク管理 /タスク管理
-タスクを整理し、進捗を追跡し、チーム間のシームレスなコラボレーションを可能にする集中ハブとして機能する。
/イメージ https://clickup.com/blog/wp-content/uploads/2024/12/ClickUp-4.png AIプロジェクトマネージャーのためのClickUp:目標ベースのエージェントを簡単に扱える。 /%img/
ClickUp for AIプロジェクトマネージャーを使用して、チームの成果を向上させましょう。
/参照 https://clickup.com/teams/project-management ClickUp for AIプロジェクトマネージャー /%href/
タスクステータスの評価やタスクの割り当てにかかる手作業を削減します。
各タスクを手作業で確認したり、誰が手が空いているかを調べたりする代わりに、/AIが力仕事をやります。進捗状況を自動的に更新し、ボトルネックを特定し、作業負荷とスキルに基づいて各タスクに最適な人材を提案することができる。
こうすることで、面倒な管理業務に費やす時間を減らし、プロジェクトを前進させるという重要な業務に多くの時間を費やすことができる。
以下は、AIを活用した機能です。🤩
ClickUp Brain**(クリックアップブレイン
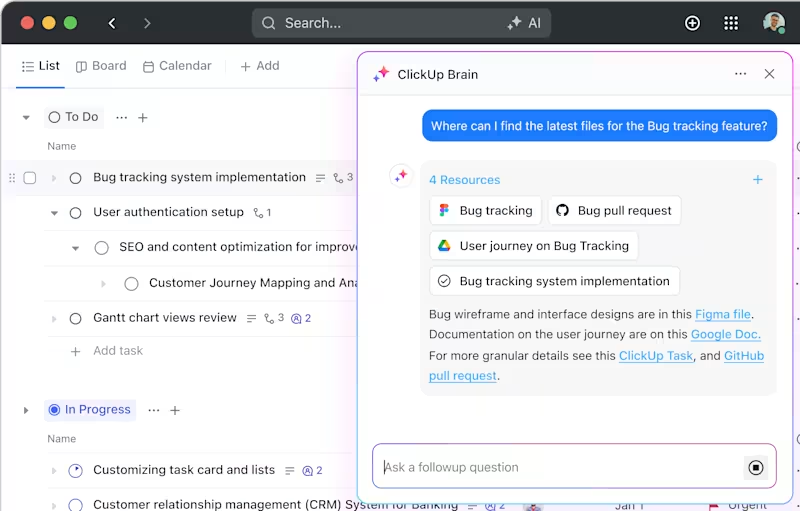
ClickUpブレイン
/参照 https://clickup.com/ai ClickUpブレイン /%href/
プラットフォームに組み込まれたAI搭載のアシスタント、ClickUp Brainは、最も複雑なプロジェクトでさえも簡素化します。拡張機能を管理可能なタスクとサブタスクに分解し、整理整頓された軌道を維持するのに役立ちます。
実験結果や文書に素早くアクセスする必要がありますか?クエリを入力するだけで、ClickUp Brainは必要なものをすべて数秒で検索します。既存のデータに基づいてフォローアップの質問をすることもでき、まるで個人秘書のようです。
さらに、タスクを関連リソースに自動的にリンクされるので、時間と努力を節約できます。
例えば、強化学習エージェントが時間とともにどのように改善されるかについて研究しているとしましょう。
文献調査、データ収集、実験、分析など、複数のフェーズがあります。ClickUp Brainを使えば、「この研究をタスクに分割してください」と頼むと、各フェーズのサブタスクが自動的に作成されます。
そして、Q-learningに関する関連論文を引き出したり、エージェントのパフォーマンスに関するデータセットを取得するように指示すると、即座にやってくれる。タスクをこなしながら、ClickUp Brainは特定の研究論文や実験結果をタスクに直接リンクさせることができ、すべてを整理しておくことができる。
ClickUp Brainは、研究フレームワークに取り組む場合でも、日常的なプロジェクトに取り組む場合でも、よりスマートに仕事を進めることができます。
クリックアップ自動化機能
/画像 https://clickup.com/blog/wp-content/uploads/2024/12/ClickUp-Automations-9.png タスクの優先度や担当者などを自動更新するためにClickUpタスクを適用する。 /クリックアップオートメーション
ClickUpタスクを適用してタスクの優先度や担当者などを自動更新する
/参照 https://clickup.com/features/automations ClickUp自動化 /クリックアップオートメーション
は、ワークフローを効率化するシンプルでパワフルな方法です。
前提条件が完了したら即座にタスクを割り当てたり、進捗マイルストーンを関係者に通知したり、遅延のフラグを立てたりすることができます。
また、自然言語でコマンドを使用できるため、ワークフロー管理がさらに簡単になります。複雑な設定や専門用語に触れる必要はありません。ClickUpに必要なことを伝えるだけで、自動化が実行されます。
完了したらタスクを次のフェーズに移動する」「優先度が高いタスクをサラに割り当てる」など、ClickUpはあなたの要望を理解し、自動的に設定します。
📖 Also Read:
/参照 https://clickup.com/blog/how-to-use-ai-for-productivity// 生産性を高めるAI活用術(ユースケース&ツール編) /%href/
クリックアップで学習エージェントを開発する
AI学習エージェントを構築するには、構造化されたワークフローと適応ツールの専門的な組み合わせが必要です。技術的な専門知識が要求されるため、特にこのようなタスクが統計的でデータに裏打ちされたものであることを考慮すると、その難易度はさらに高くなる。
このようなプロジェクトを効率化するために、ClickUpの利用をご検討ください。このツールは、単なる整理整頓にとどまらず、回避可能な非効率性を排除することで、チームのイノベーションをサポートします。
ClickUp Brainは、複雑なタスクを分解し、関連リソースを即座に検索し、AIを活用した洞察を提供することで、プロジェクトを整理して軌道に乗せることができます。一方、ClickUp自動化は、ステータスの更新や新しいタスクの割り当てなどの反復タスクを処理し、チームが全体像に集中できるようにします。
これらの機能を組み合わせることで、非効率を排除し、チームがよりスマートに仕事を進められるようになり、イノベーションと進捗がスムーズになります。
/参照 https://clickup.com/signup ClickUpに登録する /%href/
に無料登録。✅