![Comment former Gemini à partir de vos propres données en [année]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Selon une récente étude menée auprès d'entreprises, 73 % des organisations déclarent que leurs modèles d'IA ne parviennent pas à comprendre la terminologie et le contexte spécifiques à leur entreprise, ce qui entraîne des résultats nécessitant d'importantes corrections manuelles. Cela devient l'un des plus grands défis liés à l'adoption de l'IA.
Les grands modèles linguistiques tels que Google Gemini sont déjà formés à partir d'énormes ensembles de données publiques. Ce dont la plupart des entreprises ont réellement besoin, ce n'est pas de former un nouveau modèle, mais d'enseigner à Gemini le contexte de votre entreprise : vos documents, vos flux de travail, vos clients et vos connaissances internes.
Ce guide vous accompagne tout au long du processus complet d'entraînement du modèle Gemini de Google à partir de vos propres données. Nous aborderons tout, de la préparation des ensembles de données au format JSONL approprié à l'exécution des tâches de réglage dans Google AI Studio.
Nous examinerons également si un environnement de travail convergent avec contexte IA intégré pourrait vous faire gagner plusieurs semaines d’installation.
Qu'est-ce que le réglage fin de Gemini et pourquoi est-il important ?
Le réglage fin de Gemini consiste à former le modèle de base de Google à partir de vos propres données.
Vous voulez une IA qui comprenne votre entreprise, mais les modèles prêts à l'emploi fournissent des réponses génériques qui ne correspondent pas à vos besoins. Vous perdez donc du temps à corriger constamment les résultats, à réexpliquer la terminologie de votre entreprise et à vous sentir frustré lorsque l'IA ne comprend tout simplement pas.
Ces allers-retours constants ralentissent votre équipe et compromettent la promesse de productivité de l'IA.
Le réglage fin de Gemini permet de créer un modèle Gemini personnalisé qui apprend vos modèles, votre ton et vos connaissances spécifiques, ce qui lui permet de répondre plus précisément à vos cas d'utilisation uniques. Cette approche fonctionne mieux pour les tâches cohérentes et répétitives où le modèle de base échoue à plusieurs reprises.
En quoi le réglage fin diffère-t-il de l'ingénierie des instructions ?
L'ingénierie des invites consiste à donner au modèle des instructions temporaires, basées sur la session, chaque fois que vous interagissez avec lui. Une fois la discussion terminée, le modèle oublie votre contexte.
Cette approche atteint ses limites lorsque votre cas d'utilisation nécessite des connaissances spécialisées que le modèle de base ne possède tout simplement pas. Vous ne pouvez donner qu'un nombre limité d'instructions avant que le modèle n'ait besoin d'apprendre réellement vos modèles.
En revanche, le réglage fin ajuste de manière permanente le comportement du modèle en modifiant ses pondérations internes en fonction de vos exemples d'entraînement, de sorte que les changements persistent dans toutes les sessions futures.
Le réglage fin n'est pas une solution rapide aux frustrations occasionnelles liées à l'IA ; il s'agit d'un investissement important en temps et en données. Il est particulièrement utile dans des scénarios spécifiques où le modèle de base est systématiquement insuffisant et où vous avez besoin d'une solution permanente.
Envisagez un réglage fin lorsque vous avez besoin que l'IA maîtrise :
- Terminologie spécialisée : votre secteur utilise un jargon que le modèle interprète systématiquement de manière erronée ou n'utilise pas correctement.
- Format de sortie cohérent : vous avez besoin de réponses dans une structure très spécifique à chaque fois, comme la génération de rapports ou d'extraits de code.
- Expertise dans le domaine : le modèle manque de connaissances sur vos produits de niche, vos processus internes ou vos flux de travail propriétaires.
- Voix de la marque : vous souhaitez que tous les résultats générés par l'IA correspondent parfaitement à la voix, au style et à la personnalité de votre entreprise.
| Aspect | Ingénierie des invites | Réglage fin |
| Qu'est-ce que c'est ? | Rédiger de meilleures instructions dans l'invite pour guider le comportement du modèle | Poursuivre l'entraînement du modèle à partir de vos propres exemples |
| Quels changements | Les données que vous envoyez au modèle | Les pondérations internes du modèle |
| Rapidité de mise en œuvre | Immédiat — travaille instantanément | Lent — nécessite un temps de préparation des données et d'entraînement |
| Complexité technique | Faible — aucune expertise en ML requise | Moyen à élevé — nécessite des pipelines ML |
| Données requises | Quelques bons exemples dans l'invite, les instructions | Des centaines, voire des milliers d'exemples avec un libellé |
| Cohérence des résultats | Moyen — varie selon les invitations | Élevé — le comportement est intégré au modèle |
| Idéal pour | Tâches ponctuelles, expériences, itération rapide | Tâches répétitives nécessitant des résultats cohérents |
L'ingénierie des invitations façonne la forme des instructions que vous donnez au modèle. Le réglage fin façonne la forme de la pensée du modèle.
Bien que cet article se concentre sur Gemini, comprendre les différentes approches de personnalisation de l'IA peut vous fournir une perspective précieuse sur les différentes méthodes permettant d'atteindre des objectifs similaires.
Cette vidéo montre comment créer un GPT personnalisé, une autre approche populaire pour adapter l'IA à des cas d'utilisation spécifiques :
📖 À lire également : Comment devenir ingénieur Prompt
Comment préparer vos données d'entraînement pour Gemini
La plupart des projets de réglage fin échouent avant même d'avoir commencé, car les équipes sous-estiment le processus de préparation des données. Gartner prévoit que 60 % des projets d'IA seront abandonnés en raison de données inadéquates pour l'IA.
Vous pouvez passer des semaines à collecter et à mettre en forme des données de manière incorrecte, pour finalement échouer dans votre tâche de formation ou obtenir un modèle inutilisable. Il s'agit souvent de la partie la plus chronophage de l'ensemble du processus, mais la réussir est le facteur le plus important pour assurer votre réussite.
Le principe « garbage in, garbage out » (si vous entrez des données erronées, vous obtiendrez des résultats erronés) s'applique particulièrement ici. La qualité de votre modèle personnalisé reflétera directement la qualité des données utilisées pour l'entraîner.
Exigences relatives à la mise en forme des ensembles de données
Gemini nécessite que vos données d'entraînement soient dans un format spécifique appelé JSONL, qui signifie JSON Lines. Dans un fichier JSONL, chaque ligne est un objet JSON complet et autonome qui représente un exemple d'entraînement. Cette structure permet au système de traiter facilement de grands ensembles de données, ligne par ligne.
Chaque exemple d'entraînement doit contenir deux champs clés :
- text_input : Il s'agit des instructions ou de la question que vous poseriez au modèle.
- Résultat : il s'agit de la réponse idéale et parfaite que vous souhaitez que le modèle apprenne à produire.
Pour plus de commodité, Google AI Studio accepte également les téléchargements au format CSV et les convertit pour vous dans la structure JSONL requise.
Cela peut faciliter l'entrée initiale des données si votre équipe est plus à l'aise avec les feuilles de calcul.
Recommandations concernant la taille des ensembles de données
Bien que la qualité prime sur la quantité, vous avez tout de même besoin d'un nombre minimum d'exemples pour que le modèle puisse reconnaître et apprendre des modèles. Si vous commencez avec trop peu d'exemples, le résultat sera un modèle incapable de généraliser ou de fonctionner de manière fiable.
Voici quelques recommandations générales concernant la taille des ensembles de données :
- Minimum viable : pour des tâches simples et très spécifiques, vous pouvez commencer à voir des résultats avec environ 100 à 500 exemples de haute qualité.
- Meilleurs résultats : pour des résultats plus complexes ou nuancés, visez entre 500 et 1 000 exemples afin d'obtenir un modèle plus robuste et plus fiable.
- Rendements décroissants : à partir d'un certain point, le simple fait d'ajouter davantage de données répétitives n'améliorera pas significativement les performances. Privilégiez la diversité et la qualité plutôt que le volume.
Rassembler des centaines d'exemples de haute qualité représente un défi de taille pour la plupart des équipes. Planifiez cette phase de collecte de données en conséquence avant de vous lancer dans le processus de réglage.
📮 ClickUp Insight : En moyenne, un professionnel passe plus de 30 minutes par jour à rechercher des informations liées à son travail, soit plus de 120 heures par an perdues à fouiller dans ses e-mails, ses fils de discussion Slack et ses fichiers éparpillés.
Un assistant IA intelligent intégré à votre environnement de travail peut changer cela. Découvrez ClickUp Brain. Il fournit des informations et des réponses instantanées en faisant apparaître les bons documents, discussions et détails de tâches en quelques secondes, afin que vous puissiez arrêter de chercher et commencer à travailler.
💫 Résultats concrets : des équipes telles que QubicaAMF ont gagné plus de 5 heures par semaine grâce à ClickUp, soit plus de 250 heures par an et par personne, en éliminant les processus de gestion des connaissances obsolètes. Imaginez ce que votre équipe pourrait accomplir avec une semaine supplémentaire de productivité chaque trimestre !
Bonnes pratiques pour la qualité des données
Des exemples incohérents ou contradictoires perturberont le modèle, conduisant à des résultats peu fiables et imprévisibles. Pour éviter cela, vos données d'entraînement doivent être soigneusement sélectionnées et nettoyées. Un seul mauvais exemple peut annuler l'apprentissage tiré de nombreux bons exemples.
Suivez ces directives pour garantir une qualité élevée des données:
- Cohérence : tous les exemples doivent respecter le même format, le même style et le même ton. Si vous souhaitez que l'IA soit formelle, tous vos exemples de sortie doivent être formels.
- Diversité : votre ensemble de données doit couvrir l'intervalle complet d'entrées que le modèle est susceptible de rencontrer dans le cadre d'une utilisation réelle. Ne vous contentez pas de l'entraîner sur des cas faciles.
- Précision : chaque exemple de résultat doit être parfait. Il doit s'agir de la réponse exacte que vous souhaitez que le modèle produise, sans aucune erreur ni faute de frappe.
- Propreté : avant l'entraînement, vous devez supprimer les exemples en double, corriger toutes les fautes d'orthographe et de grammaire, et résoudre toutes les contradictions dans les données.
Il est fortement recommandé de faire réviser et valider les exemples d'entraînement par plusieurs personnes. Un regard neuf permet souvent de repérer des erreurs ou des incohérences qui auraient pu vous échapper.
Comment régler Gemini étape par étape
Le processus de réglage fin de Gemini implique plusieurs étapes techniques sur les plateformes Google. Une seule erreur de configuration peut vous faire perdre des heures de formation et des ressources informatiques précieuses, vous obligeant à tout recommencer. Ce guide pratique est conçu pour réduire les essais et les erreurs, en vous guidant tout au long du processus, du début à la fin. 🛠️
Avant de commencer, vous devez disposer d'un compte Google Cloud avec facturation activée et d'un accès à Google AI Studio. Prévoyez au moins quelques heures pour l'installation initiale et votre première tâche de formation, ainsi que du temps supplémentaire pour tester et itérer votre modèle.
Étape 1 : Configurer Google AI Studio
Google AI Studio est l'interface Web qui vous permet de gérer l'ensemble du processus de réglage. Elle offre un moyen convivial de télécharger des données, de configurer l'entraînement et de tester votre modèle personnalisé sans avoir à écrire de code.
Commencez par vous rendre sur ai.google.dev et connectez-vous à l'aide de votre compte Google.
Vous devrez accepter les conditions générales et créer un nouveau projet dans Google Cloud Console si vous n'en avez pas déjà un. Veillez à activer les API nécessaires comme l'invite la plateforme.
Étape 2 : Téléchargez votre ensemble de données d'entraînement
Une fois la configuration terminée, accédez à la section de réglage dans Google AI Studio. Vous pourrez alors commencer à créer votre modèle personnalisé.
Sélectionnez l'option « Créer un modèle optimisé » et choisissez votre modèle de base. Gemini 1. 5 Flash est un choix courant et économique pour l'optimisation.
Ensuite, téléchargez le fichier JSONL ou CSV contenant votre ensemble de données d'entraînement préparé. La plateforme validera alors votre fichier pour s'assurer qu'il répond aux exigences de formatage, en signalant les erreurs courantes telles que les champs manquants ou les structures incorrectes.
Étape 3 : Configurez vos paramètres de réglage fin
Une fois vos données téléchargées et validées, vous configurerez les paramètres d'entraînement. Ces paramètres, appelés hyperparamètres, contrôlent la manière dont le modèle apprend à partir de vos données.
Les options clés que vous verrez sont les suivantes :
- Époques : cela détermine le nombre de fois que le modèle s'entraînera sur l'ensemble de votre ensemble de données. Plus il y a d'époques, meilleur sera l'apprentissage, mais cela augmente également le risque de surajustement.
- Taux d'apprentissage : ce paramètre contrôle l'agressivité avec laquelle le modèle ajuste ses pondérations en fonction de vos exemples.
- Taille du lot : ce paramètre définit le nombre d'exemples d'entraînement traités ensemble dans un seul groupe.
Pour votre première tentative, il est préférable de commencer avec les paramètres par défaut recommandés par Google AI Studio. La plateforme simplifie ces décisions complexes, les rendant accessibles même si vous n'êtes pas un expert en apprentissage automatique.
Étape 4 : Exécutez la tâche de réglage
Une fois vos paramètres configurés, vous pouvez lancer le processus de réglage. Les serveurs de Google commenceront à traiter vos données et à ajuster les paramètres du modèle. Ce processus d'entraînement peut prendre de quelques minutes à plusieurs heures, selon la taille de votre ensemble de données et le modèle que vous avez sélectionné.
Vous pouvez suivre la progression du travail directement dans le tableau de bord Google AI Studio. Comme le travail s'exécute sur les serveurs de Google, vous pouvez fermer votre navigateur en toute sécurité et revenir plus tard pour vérifier l'état d'avancement. Si un travail échoue, c'est presque toujours dû à un problème lié à la qualité ou au formatage de vos données d'entraînement.
Étape 5 : Testez votre modèle personnalisé
Une fois la formation achevée, votre modèle personnalisé est prêt à être testé. ✨
Vous pouvez y accéder via l'interface Playground dans Google IA Studio.
Commencez par lui envoyer des instructions de test similaires à vos exemples d'entraînement afin de vérifier sa précision. Testez-le ensuite sur des cas limites et de nouvelles variations qu'il n'a jamais rencontrées auparavant afin d'évaluer sa capacité à généraliser.
- Précision : produit-il les résultats exacts pour lesquels vous l'avez formé ?
- Généralisation : traite-t-il correctement les nouvelles entrées similaires mais non identiques à vos données d'entraînement ?
- Cohérence : ses réponses sont-elles fiables et prévisibles après plusieurs tentatives avec les mêmes instructions ?
Si les résultats ne sont pas satisfaisants, vous devrez probablement revenir en arrière, améliorer vos données d'entraînement en ajoutant davantage d'exemples ou en corrigeant les incohérences, puis réentraîner le modèle.
📖 À lire également : Comment tirer le meilleur parti de l'IA pour l'innovation et l'efficacité
Bonnes pratiques pour former Gemini à partir de données personnalisées
Le simple fait de suivre les étapes techniques ne garantit pas un modèle performant. De nombreuses équipes achevent le processus pour finalement être déçues des résultats, car elles passent à côté des stratégies d'optimisation utilisées par les praticiens expérimentés. C'est ce qui distingue un modèle fonctionnel d'un modèle hautement performant.
Sans surprise, le rapport de Deloitte intitulé « State of Generative AI in the Enterprise » (État des lieux de l'IA générative dans l'entreprise) révèle que deux tiers des entreprises déclarent que 30 % ou moins de leurs expériences en matière d'IA générative seront pleinement déployées dans les six mois.
L'adoption de ces bonnes pratiques vous fera gagner du temps et vous permettra d'obtenir de bien meilleurs résultats.
- Commencez modestement, puis développez : avant de procéder à la validation de votre approche, testez-la avec un petit sous-ensemble de vos données (par exemple, 100 exemples). Cela vous permettra de valider le format de vos données et d'avoir rapidement une idée des performances sans perdre de temps.
- Versionnez vos ensembles de données : lorsque vous ajoutez, supprimez ou effectuez des modifications en cours sur des exemples d'entraînement, enregistrez chaque version de votre ensemble de données. Cela vous permettra de suivre les modifications, de reproduire les résultats et de revenir à une version précédente si la nouvelle version donne de moins bons résultats.
- Test avant et après : avant de commencer le réglage fin, établissez une base de référence en évaluant les performances du modèle de base sur vos tâches clés. Cela vous permettra de mesurer objectivement les améliorations obtenues grâce à vos efforts de réglage fin.
- Répétez les échecs : lorsque votre modèle personnalisé produit une réponse erronée ou mal mise en forme, ne vous laissez pas décourager. Ajoutez ce cas d'échec spécifique comme nouvel exemple corrigé dans vos données d'entraînement pour la prochaine itération.
- Documentez votre processus : consignez chaque cycle d'entraînement dans un journal, en notant la version du jeu de données utilisée, les hyperparamètres et les résultats. Cette documentation est précieuse pour comprendre ce qui fonctionne et ce qui ne fonctionne pas au fil du temps.
La gestion de ces itérations, des versions des ensembles de données et de la documentation nécessite une gestion de projet rigoureuse. La centralisation de ce travail dans une plateforme conçue pour des flux de travail structurés peut éviter que le processus ne devienne chaotique.
Défis courants lors de la formation de Gemini
Les équipes investissent souvent beaucoup de temps et de ressources dans le réglage fin, pour finalement se heurter à des obstacles prévisibles qui entraînent un gaspillage d'efforts et de la frustration. Connaître à l'avance ces pièges courants peut vous aider à naviguer plus facilement dans le processus.
Voici quelques-uns des défis les plus fréquents et comment les relever :
- Surajustement : cela se produit lorsque le modèle mémorise parfaitement vos exemples d'entraînement, mais ne parvient pas à généraliser à de nouvelles entrées inconnues. Pour y remédier, vous pouvez ajouter plus de diversité à vos données d'entraînement, envisager de réduire le nombre d'époques ou explorer d'autres méthodes telles que la génération augmentée par la récupération.
- Résultats incohérents : si le modèle donne des réponses différentes à des questions très similaires, c'est probablement parce que vos données d'entraînement contiennent des exemples contradictoires ou incohérents. Un nettoyage approfondi des données est nécessaire pour résoudre ces conflits.
- Déviation de format : il arrive parfois qu'un modèle commence par suivre la structure de sortie souhaitée, mais s'en éloigne progressivement au fil du temps. La solution consiste à inclure des instructions de format explicites dans la sortie de vos exemples d'entraînement, et pas seulement dans le contenu.
- Cycles d'itération lents : lorsque chaque cycle d'entraînement prend des heures, cela ralentit considérablement votre capacité à expérimenter et à vous améliorer. Testez d'abord vos idées sur des ensembles de données plus petits afin d'obtenir un retour plus rapide avant de lancer un travail d'entraînement complet.
- Goulot d'étranglement dans la collecte de données: souvent, le plus difficile est de collecter suffisamment d'exemples de haute qualité. Commencez par exploiter vos meilleurs contenus existants, tels que les tickets d'assistance, les textes marketing ou les documents techniques, puis développez-les à partir de là.
Ces défis sont l'une des clés pour lesquelles de nombreuses équipes finissent par rechercher des alternatives au processus de réglage manuel.
📮ClickUp Insight : 88 % des personnes interrogées dans le cadre de notre sondage utilisent l'IA pour leurs tâches personnelles, mais plus de 50 % hésitent à l'utiliser au travail. Les trois principaux obstacles ? Le manque d'intégration transparente, les lacunes en matière de connaissances ou les préoccupations en matière de sécurité. Mais que se passerait-il si l'IA était intégrée à votre environnement de travail et était déjà sécurisée ? ClickUp Brain, l'assistant IA intégré à ClickUp, fait de cela une réalité. Il comprend les invites en langage clair, résolvant ainsi les trois préoccupations liées à l'adoption de l'IA tout en effectuant la connexion entre vos chats, tâches, documents et connaissances dans tout l'environnement de travail. Trouvez des réponses et des informations en un seul clic !
Pourquoi ClickUp est une alternative plus intelligente
Le réglage fin de Gemini est puissant, mais il s'agit également d'une solution de contournement.
Tout au long de cet article, nous avons vu que le réglage fin revient en fin de compte à une seule chose : apprendre à l'IA à comprendre le contexte de votre entreprise. Le problème est que le réglage fin le fait de manière indirecte. Vous préparez des ensembles de données, concevez des exemples, réentraînez des modèles et maintenez des pipelines, tout cela afin que l'IA puisse se rapprocher du mode de fonctionnement de votre équipe.
Cela est pertinent pour des cas d'utilisation spécialisés. Mais pour la plupart des équipes, le véritable objectif n'est pas la personnalisation de Gemini en soi. L'objectif est plus simple :
Vous voulez une IA qui comprenne votre travail.
C'est là que ClickUp adopte une approche fondamentalement différente et plus intelligente.
L'environnement de travail IA convergé de ClickUp offre à votre équipe une IA qui comprend instantanément votre contexte de travail, sans effort particulier. Au lieu de former l'IA à apprendre votre contexte ultérieurement, vous travaillez avec ClickUp Brain, l'assistant IA intégré, où votre contexte est déjà présent.
Vos tâches, vos documents, vos commentaires, l'historique de vos projets et vos décisions sont connectés de manière native. Il n'est pas nécessaire de former l'IA à partir de vos données, car elle est déjà présente là où vous travaillez et exploite votre écosystème de gestion des connaissances existant.
| Aspect | Réglage fin de Gemini | ClickUp Brain |
|---|---|---|
| Temps d'installation | Plusieurs jours à plusieurs semaines de préparation des données | Immédiat : fonctionne avec les données existantes de l'environnement de travail |
| Source du contexte | Exemples de formation sélectionnés manuellement | Accès automatique à tous les travaux connectés |
| Maintenance | Réentraînez-le lorsque vos besoins changent. | Mise à jour continue au fur et à mesure de l'évolution de votre environnement de travail |
| Compétences techniques requises | Modéré à élevé | Aucun |
Comme ClickUp est votre système de travail, ClickUp Brain fonctionne à l'intérieur de votre graphe de données connecté. Il n'y a pas de prolifération de l'IA dans des outils déconnectés, pas de pipelines de formation fragiles et aucun risque que le modèle ne soit plus synchronisé avec la façon dont votre équipe travaille réellement.
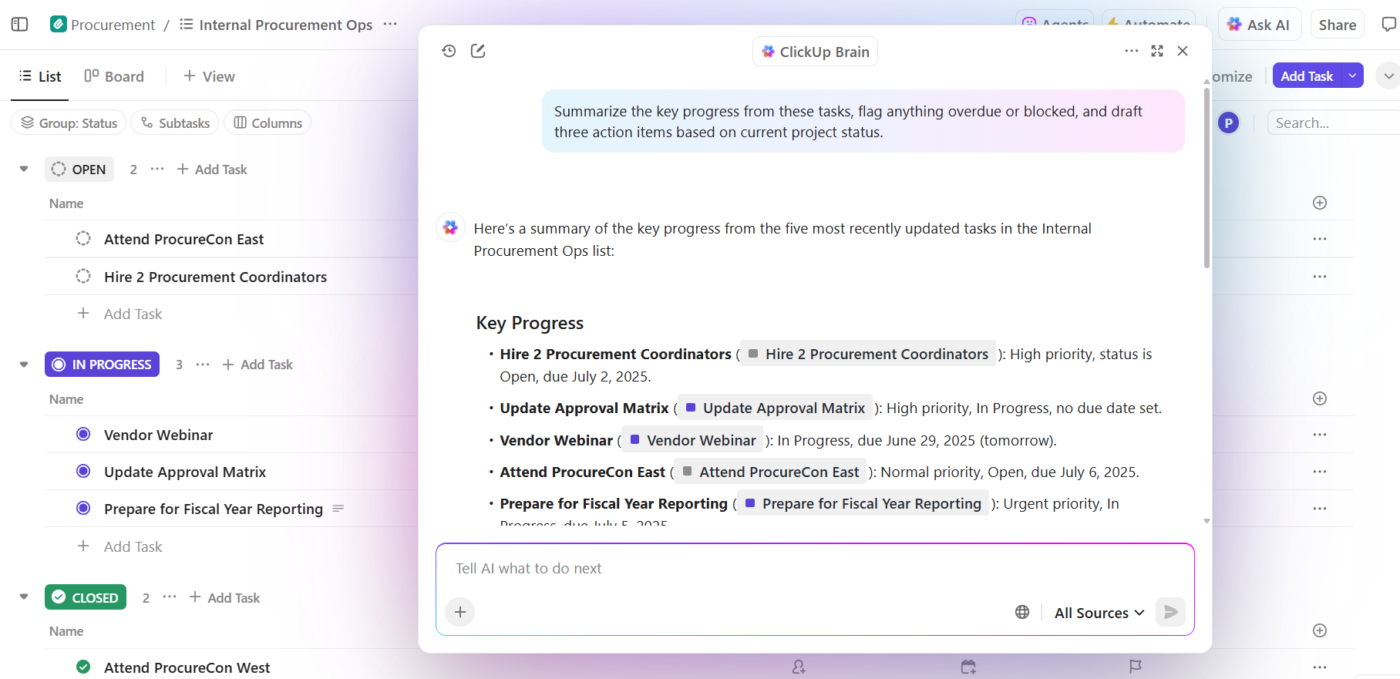
Voici à quoi cela ressemble dans la pratique :
- Posez des questions sur vos projets : ClickUp Brain effectue des recherches dans l'environnement de travail parmi les tâches, les documents, les commentaires et les mises à jour pour répondre à vos questions à l'aide des données réelles de vos projets, et non à l'aide de connaissances génériques issues de la formation.
- Générez du contenu avec du contexte : ClickUp Brain dispose déjà d'un accès sécurisé à vos tâches, fichiers, commentaires et historique de projet. Il peut créer des documents, des résumés et des mises à jour de statut qui font référence à votre travail réel, à vos échéanciers et à vos priorités. Finis les contextes dispersés, où les équipes perdent des heures à rechercher des informations dans différentes applications et fichiers.
- Automatisez en comprenant : avec ClickUp Automations, vous pouvez créer une automatisation qui réagit intelligemment au contexte du projet, comme les échéances, la propriété et les changements de statut, et pas seulement à des règles statiques. L'IA peut même les créer pour vous, sans aucun code.
💡Conseil de pro : exploitez toute la puissance de l'IA dans votre environnement de travail avec ClickUp Super Agents.
Les Super Agents sont les coéquipiers alimentés par l'IA de ClickUp, configurés comme des « utilisateurs » IA qui travaillent aux côtés de votre équipe dans l'environnement de travail. Ils sont ambiants et contextuels, et peuvent être affectés à des tâches, mentionnés dans des commentaires, déclenchés par des évènements ou des calendriers, ou dirigés via le chat, tout comme un coéquipier humain.
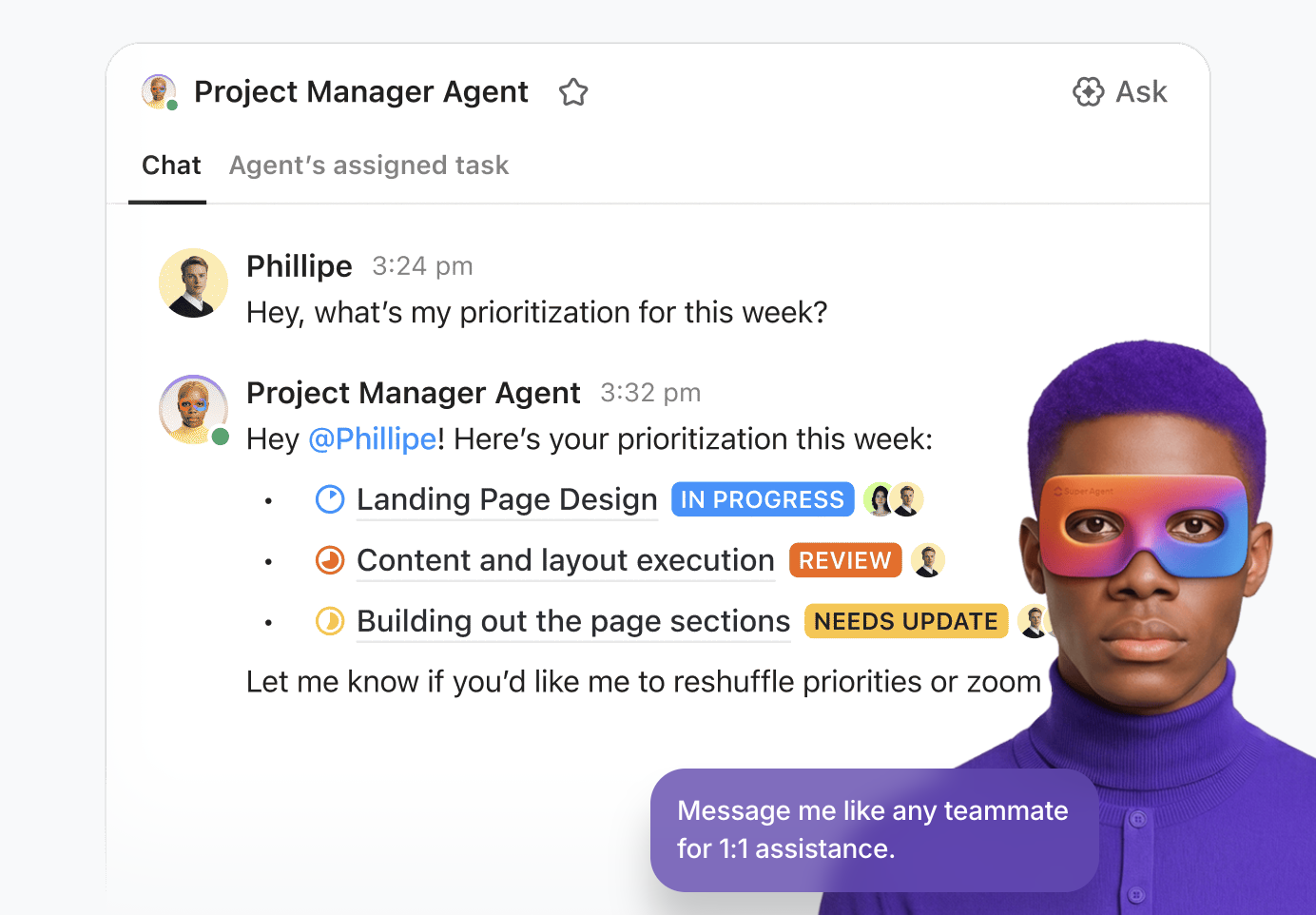
Vous pouvez les créer et les déployer à l'aide du générateur visuel sans code qui vous permet de :
- Identifiez l'évènement de départ, tel qu'un message ou un changement dans le statut d'une tâche.
- Définissez des règles opérationnelles, notamment comment résumer les données, déléguer le travail ou ajuster les priorités.
- Exécutez des actions externes via des outils et des extensions intégrés.
- Fournissez l'assistance nécessaire en effectuant la connexion de l'agent aux bases de connaissances pertinentes.
Pour en savoir plus sur les super agents, regardez la vidéo ci-dessous.
Affinez votre stratégie en matière d'IA : optez pour ClickUp
Le réglage fin apprend à une IA vos modèles à partir d'exemples statiques, mais l'utilisation d'un logiciel convergent dans un environnement de travail tel que ClickUp élimine la prolifération des contextes en fournissant à votre IA un contexte automatique et en temps réel.
C'est là le secret d'une transformation IA réussie : les équipes qui centralisent leur travail sur une plateforme connectée passent moins de temps à former l'IA et plus de temps à en tirer parti. À mesure que votre environnement de travail évolue, votre IA évolue automatiquement, sans nécessiter de cycles de reformatage.
Prêt à passer l'étape de formation et à commencer avec une IA qui connaît déjà votre travail ? Commencez gratuitement avec ClickUp et découvrez les avantages d'un environnement de travail convergent.
Foire aux questions (FAQ)
Votre modèle optimisé apprend à partir de vos exemples d'entraînement, mais le modèle Gemini de base de Google ne conserve pas et n'apprend pas à partir de vos données de discussion par défaut. Votre modèle personnalisé est distinct du modèle de base qui sert les autres utilisateurs.
Si la formation elle-même ne prend que quelques heures, la préparation de données de formation de haute qualité demande beaucoup plus de temps. Cette phase de préparation des données peut souvent prendre plusieurs jours, voire plusieurs semaines, pour être achevée.
Oui, vous pouvez affiner un modèle sans écrire de code en utilisant Google AI Studio. Il fournit une interface visuelle qui gère la plupart des complexités techniques, mais vous devrez tout de même comprendre les exigences en matière de formatage des données.
Les instructions personnalisées sont des invites temporaires, basées sur la session, qui guident le comportement du modèle pour une seule discussion. Le réglage fin, quant à lui, ajuste de manière permanente les paramètres internes du modèle en fonction de vos exemples d'entraînement, créant ainsi des changements durables dans son comportement.