

L'IA a modifié ce que les ingénieurs doivent documenter eux-mêmes. GitHub Copilot, Cursor et Mintlify peuvent générer des documents de première ébauche : descriptions de paramètres, résumés de fonctions et structures de fichiers README. Ce qu'ils ne peuvent pas rédiger, c'est la couche d'intention : la décision prise, le compromis accepté, la contrainte qui a pesé et l'option que l'équipe a rejetée.
Le code montre le comportement. Il enregistre rarement la justification. Cette justification se trouve généralement dans un fil de discussion Slack, un commentaire de ticket, un compte-rendu d'incident ou dans la mémoire de quelqu'un.
Le sondage 2024 de Stack Overflow auprès des développeurs a révélé que 61 % des développeurs professionnels passent plus de 30 minutes par jour à chercher des réponses au travail, et qu'un sur quatre y consacre plus d'une heure. Certaines recherches sont bien sûr inévitables. Mais le véritable gaspillage réside dans le contexte des sprints qui n'a jamais été consigné dans un document.
Ce guide indique ce que les ingénieurs doivent rédiger eux-mêmes, dans quels domaines l'IA peut les aider et comment garantir la pertinence de la documentation du code une fois le sprint terminé.
TL;DR
L'IA peut rédiger la partie technique de la documentation : chaînes de documentation, types de paramètres, résumés de fonctions et structures de fichiers README. Les ingénieurs doivent toujours rédiger la partie relative à l'intention : les décisions, les compromis, les contraintes et les options rejetées qui sous-tendent le code.
Les ingénieurs doivent toujours rédiger eux-mêmes ces éléments, dans les Architecture Decision Records, les descriptions de PR et les commentaires « why » validés avec le code. La couche d'intention évite au prochain développeur d'avoir à reconstituer les décisions à partir des noms de variables, des messages de validation et des anciennes PR. L'IA peut désormais rédiger les parties routinières : types de paramètres, descriptions de retour et résumés de fonctions de base.
Que devrait réellement expliquer la documentation du code ?
La documentation du code doit aider le prochain développeur à comprendre ce que fait le code, comment l'utiliser en toute sécurité et pourquoi il a été conçu de cette manière. Elle apparaît à deux endroits : à l'intérieur des fichiers source sous forme de commentaires et de chaînes de documentation, et à l'extérieur des fichiers source sous forme de fichiers README, de références API, de guides d'exploitation et de notes d'architecture.
La plupart des bases de code deviennent difficiles à lire une fois que le contexte décisionnel a disparu. Le développeur d'origine a peut-être fait un compromis judicieux. Le développeur suivant ne voit que le résultat, et non le raisonnement.
Résultat : chaque nouveau membre de l'équipe doit reconstituer l'intention à partir des noms de variables, des messages de validation et des anciennes pull requests. Cela ralentit l'intégration, les revues, le débogage et les modifications futures dans ce même domaine.
Une bonne documentation répond à quatre questions :
- À qui s'adresse ce code ? Aux développeurs internes, aux collaborateurs open source, aux utilisateurs externes d'API ou aux utilisateurs finaux
- Quel problème cela résout-il ? Le besoin de l'entreprise ou technique à l'origine du module
- Pourquoi cette approche a-t-elle été choisie ? Les alternatives envisagées et les compromis acceptés
- Où se trouvent les éléments connexes ? Modules dépendants, services en amont, choix architecturaux, tickets et guides d'exploitation
C'est la question du « pourquoi » qui mérite le plus d'attention de la part des humains.
La recherche représente déjà une charge de travail considérable en dehors du domaine de l'ingénierie. Le sondage de ClickUp sur la gestion des connaissances a révélé que 57 % des employés perdent du temps à rechercher des informations liées à leur travail dans des documents internes ou des bases de connaissances. Lorsqu'ils ne trouvent pas ce dont ils ont besoin, 1 sur 6 se rabat sur des solutions de contournement personnelles : fouiller dans d'anciens e-mails, des notes ou des captures d'écran.
La documentation du code fonctionne de la même manière : si les développeurs ne trouvent pas l'explication, c'est comme si elle n'existait pas.
Les conséquences d'une erreur sont lourdes. Un commentateur du forum r/AskProgramming a décrit un flux de travail RPA dans lequel un bouton non documenté a failli déclencher des frais bancaires d'automatisation et l'envoi de lettres aux clients.
La recherche représente déjà une charge de travail considérable en dehors du domaine de l'ingénierie. Le sondage de ClickUp sur la gestion des connaissances a révélé que 57 % des employés perdent du temps à rechercher des informations liées au travail dans des documents internes ou des bases de connaissances. Lorsqu'ils ne trouvent pas ce dont ils ont besoin, 1 sur 6 se rabat sur des solutions de contournement personnelles : fouiller dans d'anciens e-mails, des notes ou des captures d'écran.
La documentation du code fonctionne de la même manière : si les développeurs ne trouvent pas l'explication, c'est comme si elle n'existait pas.
Les conséquences d'une erreur sont lourdes. Un commentateur du forum r/AskProgramming a décrit un flux de travail RPA dans lequel un bouton non documenté a failli déclencher des frais bancaires d'automatisation et l'envoi de lettres personnalisées aux clients.
Quels sont les principaux types de documentation de code ?
Les cinq principaux types sont les commentaires en ligne, les chaînes de documentation, les fichiers README, les wikis internes et la documentation API externe. Chacun s'adresse à un lecteur différent à un moment différent. Les mélanger rend la documentation plus difficile à rédiger et à utiliser. Un fichier README qui se lit comme une chaîne de documentation décourage les nouveaux collaborateurs. Une chaîne de documentation qui se lit comme une page wiki devient un poids mort au sein des fichiers source.
Commentaires en ligne et chaînes de documentation
Les commentaires en ligne doivent expliquer les raisonnements qui ne sont pas évidents. Un commentaire reformulant x = x + 1 en « incrémenter x » n'apporte rien. Un commentaire indiquant « décalage pour une réponse API indexée à zéro » a sa place, car le code ne peut pas montrer cette contrainte externe. Réservez les commentaires en ligne à la logique non évidente au sein du corps d'une fonction.
Les chaînes de documentation (docstrings) sont des descriptions structurées associées à des fonctions, des classes ou des modules. Elles couvrent les paramètres, les valeurs de retour, les exceptions et les exemples d'utilisation. Chaque langage a ses propres conventions. Respectez la convention attendue par votre langage : PEP 257 pour les chaînes de documentation Python, Javadoc pour Java, et JSDoc pour JavaScript et TypeScript.
Comparez ces deux exemples :
Chaîne de documentation insuffisante :
Une chaîne de documentation efficace :
La seconde nomme clairement la fonction, documente ses paramètres et met en évidence une hypothèse : le flux de paiement utilise un taux de taxe de 8,25 %.
Fichiers README, wikis et documents externes
Un fichier README doit répondre à cinq questions dans l'ordre : Que fait ce projet ? Comment l'installer ? Comment l'utiliser ? Comment contribuer ? Où trouver de l'aide ? Si un nouveau collaborateur ne parvient pas à trouver rapidement le chemin d'installation, c'est que le fichier README est soit surchargé, soit mal organisé.
Les wikis et les bases de connaissances sont particulièrement adaptés aux contenus couvrant plusieurs référentiels ou services : décisions d'architecture, guides d'intégration et manuels d'exploitation. Un wiki auquel personne ne renvoie depuis le code devient un problème de recherche supplémentaire.
La documentation externe couvre les références API, les guides SDK et les documents destinés aux utilisateurs. Elle s'adresse aux utilisateurs de votre code, et non aux collaborateurs. Les documents externes doivent comporter davantage de détails sur l'installation, des étapes d'authentification plus claires et une structure de type référence, car le lecteur peut ne pas connaître du tout votre base de code.
Si l'équipe n'a pas encore de structure, commencez par un modèle de documentation technique pour l'architecture et les notes d'installation, ou un modèle de documentation de projet pour les objectifs, les responsables, les jalons et les décisions. Adaptez les sections plutôt que de créer un format à partir de zéro.
| Type | Public cible | Fréquence des mises à jour | Emplacement habituel |
|---|---|---|---|
| Commentaires en ligne | Les développeurs qui lisent un chemin de code spécifique | Lorsque le comportement du code change | Fichiers source |
| Chaînes de documentation | Développeurs appelant une fonction, une classe ou un module | Lorsque l'interface change | Fichiers source |
| README | Nouveaux collaborateurs et évaluateurs | À chaque nouvelle version majeure ou changement de projet | Racine du référentiel |
| Wiki ou base de connaissances | Équipes internes et parties prenantes inter-équipes | À mesure que les décisions ou les processus évoluent | Wiki du référentiel ou base de connaissances partagée |
| Documentation des API externes | Utilisateurs de l'API et utilisateurs finaux | Par version ou par version d'API | Plateforme de documentation |
Comment rédigez-vous réellement la documentation aujourd'hui ?
Utilisez l'IA pour les parties qu'elle peut rédiger. Consacrez le temps des humains aux décisions, aux contraintes et aux compromis.
/IA peut désormais rédiger une grande partie du travail mécanique : types de paramètres, descriptions des retours et résumés des fonctions de base. Le travail de documentation effectué par l'humain se divise en deux catégories.
Écrivez d'abord du code auto-documenté
La meilleure documentation est celle dont le code n'a pratiquement pas besoin. Des noms descriptifs, des fonctions à usage unique et des conventions cohérentes réduisent la charge de documentation avant même que vous n'écriviez le moindre commentaire.
Un code auto-documenté rend son comportement plus facile à lire. Il explique rarement le raisonnement qui sous-tend ce comportement. Les noms aident les développeurs à identifier ce que fait un élément. La documentation doit expliquer le raisonnement que le nom ne peut pas transmettre.
Avant d'ajouter un commentaire, demandez-vous si le fait de renommer une variable ou d'extraire une fonction rendrait ce commentaire inutile. Si la réponse est oui, procédez d'abord à une refactorisation. Un nom clair permet d'éliminer les commentaires qui ne font que traduire une mauvaise dénomination.
Avant :
Après :
La version refactorisée communique les mêmes informations par le biais de la seule nomenclature. Le seul commentaire utile à présent serait d'expliquer pourquoi certains rôles sont exclus, ce qui relève d'une décision stratégique que le code ne peut exprimer de lui-même.
Rédigez la couche d'intention (la partie que l'IA ne peut pas traiter)
La mise en œuvre est visible dans le code. L'intention disparaît à moins que quelqu'un ne la consigne par écrit. Le code conserve rarement les raisons d'un compromis, les contraintes qui ont guidé une conception ou les alternatives qui ont été rejetées.
Une règle courante chez les développeurs résume bien cela : documentez le pourquoi, pas le quoi. Un commentaire parmi les plus plébiscités sur r/coding:
Je vois que cette condition crée une branche entre les utilisateurs rouges et bleus. Expliquez-moi pourquoi les utilisateurs sont classés de cette manière et pourquoi nous créons une branche entre eux.
Je vois que cette condition crée une branche entre les utilisateurs rouges et bleus. Expliquez-moi pourquoi les utilisateurs sont classés de cette manière et pourquoi nous créons une branche entre eux.
Un message de validation peut être utile lors de la révision, mais il ne constitue pas un support adéquat à long terme pour la justification de la conception, car les futurs lecteurs le trouvent rarement au moment où ils en ont besoin.
Will Larson, ancien directeur technique de Calm et auteur de An Elegant Puzzle, a écrit sur l'intérêt des Architecture Decision Records, car elles permettent de conserver la justification technique en dehors du code source.
Les ADR sont utiles car ils offrent un cadre stable pour la justification de la conception. Si votre équipe ne dispose pas d'un format, empruntez un modèle d'ADR simple: décision, contexte, options envisagées, compromis et conséquences.
Concentrez votre documentation sur les catégories suivantes :
- Décisions de conception et alternatives : « Nous avons choisi ici un cache en écriture directe plutôt qu'en écriture différée, car la cohérence des données est plus importante que la latence d'écriture pour ce flux de paiement. »
- Limites connues : dette technique, contraintes d'évolutivité, solutions de contournement temporaires ou domaines nécessitant un nettoyage ultérieur
- Hypothèses : formats d'entrée attendus, exigences environnementales ou dépendances en amont que le code n'impose pas
- Références : Liens vers les tickets, RFC ou Architecture Decision Records (ADR) pertinents qui expliquent le contexte général
À chaque contexte son support. Les chaînes de documentation (docstrings) capturent l'intention au niveau des fonctions. Les commentaires de code traitent le raisonnement au niveau des lignes. Les descriptions des pull requests fournissent le contexte au niveau des modifications. Les ADR (documentations de décision) traitent les décisions au niveau du système. Les messages de validation sont également utiles, mais ils ne doivent pas constituer la seule trace d'une décision importante.
Un anti-modèle courant : documenter le fonctionnement d'un algorithme de tri ligne par ligne. La vraie question est de savoir pourquoi un tri personnalisé a été utilisé à la place de la bibliothèque standard. Pour les chemins de code personnalisés, documentez la décision qui a motivé la mise en œuvre.
Quelles sont les bonnes pratiques les plus importantes en matière de documentation ?
Cinq pratiques permettent de garantir que la documentation restera utile une fois le sprint terminé. La plupart des autres conseils en matière de documentation reposent sur la mise en œuvre préalable de ces habitudes.
- Documentez pendant que vous codez, pas après. Le contexte s'estompe rapidement. D'ici le prochain sprint, vous aurez oublié quelle alternative vous avez rejetée et pourquoi. Écrivez le commentaire expliquant le pourquoi dans le même commit que le code, sinon vous ne l'écrirez pas du tout
- Utilisez un guide de style cohérent. Choisissez un format de docstring, tel que le style Google, le style NumPy, Javadoc ou JSDoc, et appliquez-le lors de la révision du code ou du linting. La cohérence importe plus que le format que vous choisissez. Un guide de style commun élimine la question « comment dois-je mettre en forme cela ? » et rend possible l’automatisation du linting
- Considérez la documentation comme faisant partie intégrante de la révision du code. Ajoutez des vérifications de la documentation à votre checklist pour la révision des PR. Si une PR modifie le comportement, le réviseur doit vérifier que la documentation reflète bien ce changement. La documentation sur les pratiques d'ingénierie de Google demande aux réviseurs de vérifier si le code est correctement documenté. Appliquez la même règle en interne : si une PR modifie le comportement, les réviseurs doivent vérifier si les commentaires, les chaînes de documentation, les fichiers README et les guides d'exécution correspondent toujours.
- Supprimez la documentation obsolète. Les documents périmés causent de réels dommages, car ils orientent les lecteurs vers une implémentation, une API ou un processus erronés. Revoyez la documentation tous les trimestres ou avant chaque version majeure. Attribuez la propriété de la documentation à une personne afin qu’elle ne soit pas la responsabilité de tout le monde et, par conséquent, de personne.
- Veillez à ce que les exemples soient exécutables. Les exemples de code doivent être faciles à copier, à exécuter et à tester. C'est le moyen le plus sûr de détecter les dérives avant que les utilisateurs ne le fassent.
Quels outils utiliser pour générer de la documentation de code ?
Les outils de documentation se divisent en deux catégories : les générateurs traditionnels et les assistants IA. Ils remplissent des fonctions différentes.
Les générateurs traditionnels analysent les commentaires structurés de votre code source et produisent des références consultables. Le choix du générateur approprié dépend généralement du langage utilisé.
| Outil | Langage/Écosystème | Ce qu'elle génère |
|---|---|---|
| Javadoc | Java | Référence API à partir des commentaires de documentation |
| JSDoc | JavaScript/TypeScript | Référence API à partir de commentaires annotés |
| Sphinx | Python (offre l'assistance pour d'autres langages via des plugins) | Sites de documentation complets à partir de reStructuredText ou Markdown |
| Doxygen | C, C++, Java, Python et autres | Documentation de référence multilingue |
| Godoc | Aller | Documentation des paquets à partir des commentaires du code source |
La qualité du résultat dépend entièrement de vos chaînes de documentation. Elles mettent en forme et publient ce que vous avez écrit. Elles n'inventent pas les intentions manquantes.
Les assistants basés sur l'IA ajoutent une deuxième dimension. GitHub Copilot, Cursor et Windsurf peuvent rédiger des commentaires et des chaînes de documentation directement dans l'éditeur. Mintlify permet de générer et de maintenir la documentation destinée aux développeurs à partir du code et de la documentation existante. Swimm s'attache à maintenir la documentation interne en phase avec les modifications du code. ReadMe et GitBook aident les équipes à publier des références d'API et de la documentation destinée aux développeurs, souvent avec des fonctionnalités de recherche ou de rédaction assistées par l'IA.
L'étude Stack Overflow a révélé que la documentation était la catégorie d'automatisation par l'IA la plus fréquemment demandée, citée dans environ 33,9 % des réponses ouvertes des développeurs. Ces outils sont particulièrement efficaces lorsque le code source expose déjà clairement le comportement.
L'IA perd de son efficacité lorsque l'explication dépend de décisions prises en dehors du code : un fil de discussion Slack, une réunion de planification, un ticket ou un compte-rendu d'incident. Elle peut résumer la fonction. Elle ne peut pas savoir quelle contrainte était négociable, quelle option a été rejetée, ni pourquoi le compromis a été accepté.
Flux de travail pratique :
- Laissez l'IA rédiger le squelette : résumé de la fonction, paramètres, valeurs de retour et exceptions courantes
- Vérifiez-la par rapport au comportement réel du code
- Ajoutez le « pourquoi » : la décision, la contrainte, l'hypothèse ou l'alternative rejetée
- Rédigez un ADR pour les décisions au niveau du système
- Ne publiez pas de documents générés par l'IA sans les avoir relus au préalable
Les domaines où ClickUp est utile et ceux où il ne l'est pas
ClickUp n'est pas un générateur de documentation au niveau du code. Il ne remplacera pas Javadoc, Sphinx, JSDoc ou Godoc. Il facilite la documentation autour du code : fichiers README, guides d'exécution, guides d'intégration, ADR et journaux de décision qui doivent rester liés aux tâches, tickets et sprints qui les ont générés.
ClickUp Docs vous permet de rédiger ces documents parallèlement à votre travail d'ingénierie, et ClickUp Brain peut rédiger un document à partir du contexte d'une tâche ou d'un projet ; les développeurs peuvent ensuite y ajouter la justification de la décision, les contraintes et les compromis.
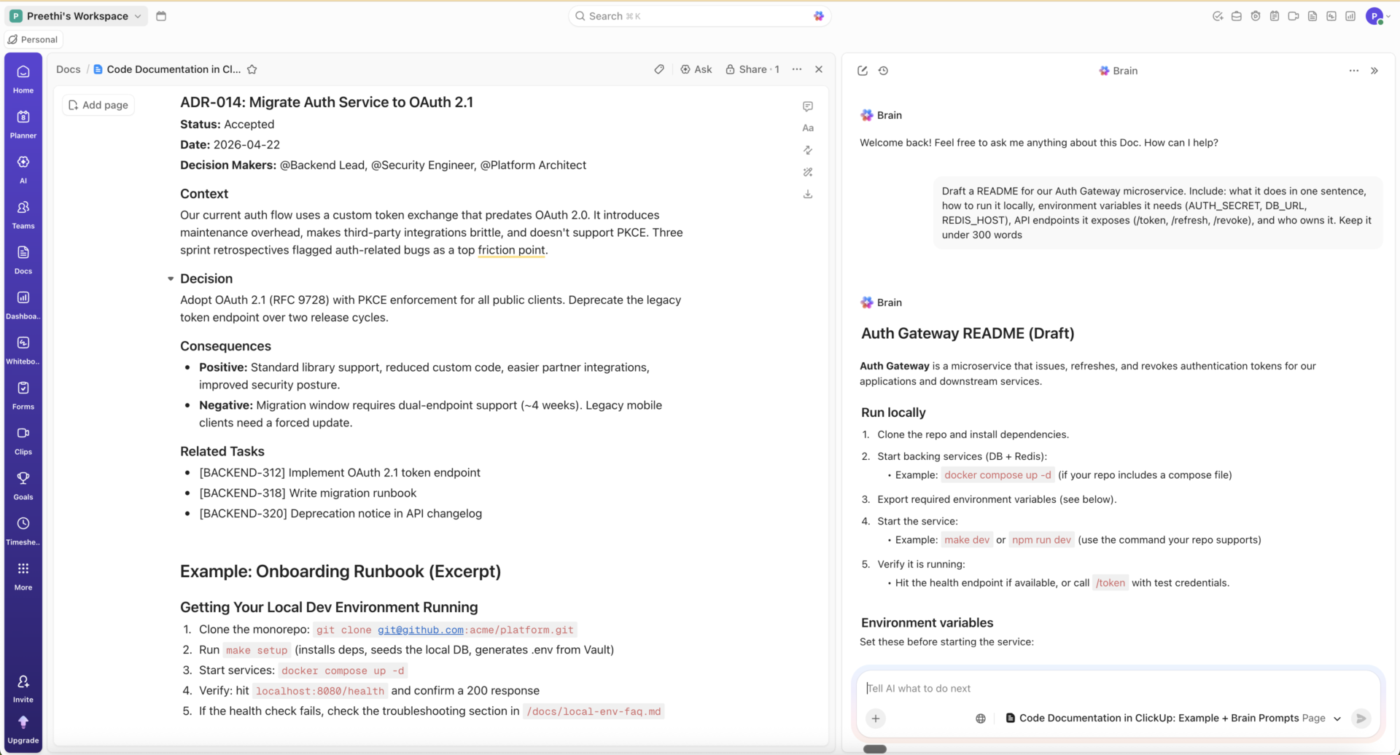
Pour les équipes d'ingénieurs, cela signifie moins de temps passé à fouiller dans des documents, des discussions et des tickets éparpillés, et plus de temps consacré à préserver les décisions que ces outils ont tendance à noyer.
Si votre problème est que « nos documents sont techniquement achevés, mais que personne ne les trouve », il s'agit d'un problème de visibilité. Un environnement de travail connecté peut vous aider.
Si votre problème est que « notre référence API est obsolète », il s'agit d'un problème de génération et de révision. Sphinx, Javadoc, JSDoc ou Godoc vous seront plus utiles qu'un outil d'environnement de travail. Ne confondez pas les deux.
Quels changements lorsque l'IA rédige la majeure partie de la documentation ?
Il y a une blague récurrente sur les fils de discussion r/developersIndia, r/webdev et r/AskProgramming à propos de la documentation technique. Quand quelqu'un demande comment l'équipe gère la documentation, la réponse la plus fréquente est généralement une version de : « Je suis la documentation. »
C'est drôle parce que c'est vrai. Depuis des années, la solution de contournement face à l'absence de documentation, c'est l'ingénieur qui se souvient par hasard.
L'IA change la donne. Elle peut rédiger rapidement la documentation courante, ce qui rend les décisions non documentées plus difficiles à justifier. Lorsque l'IA peut structurer les parties techniques de vos documents en quelques secondes, l'argument « je m'en souviendrai » ne suffit plus comme système d'enregistrement.
Cela réoriente le travail de l'ingénieur vers l'intention, les décisions et les compromis : des aspects que la syntaxe seule ne peut expliquer.
La plupart des anciens conseils en matière de documentation ont été rédigés pour un flux de travail antérieur à l'IA. Ils mettent fortement l'accent sur les descriptions de paramètres, les signatures de fonctions et les notes d'installation exhaustives.
L'IA peut désormais rédiger une grande partie de ce travail. Si les ingénieurs consacrent la majeure partie de leur temps de documentation à des résumés mécaniques, ils consacrent leur attention humaine à la couche la moins valorisante.
Consacrez ce temps à l'intention : pourquoi la fonction existe, quelle option vous avez rejetée et sur quelle hypothèse repose le code. Ce sont là les notes dont votre future équipe, les agents de codage IA et l'ingénieur qui héritera de la base de code en 2027 auront besoin.
Si votre problème de documentation réside dans un contexte dispersé, ClickUp peut vous aider à garder l'historique des décisions plus proche des tâches, des documents et des projets qui l'ont généré.
Foire aux questions sur la documentation du code
Qu'est-ce qu'un fichier README ?
Un fichier README réussit son premier test lorsqu'un collaborateur peut trouver rapidement cinq informations : ce que fait le projet, comment l'installer, comment l'utiliser, comment y contribuer et où trouver de l'aide. Si l'installation est noyée sous les badges, les notes d'architecture ou les détails du journal des modifications, le fichier README est mal organisé.
Quelle est la différence entre les commentaires de code et la documentation ?
Les commentaires de code se trouvent à l'intérieur des fichiers source et expliquent des lignes ou des blocs spécifiques. La documentation se trouve généralement en dehors des fichiers source, dans des fichiers README, des wikis, des sites de référence générés ou des documentations d'API. Les commentaires aident le prochain développeur qui lit votre fonction. La documentation aide la prochaine personne qui essaie d'utiliser, d'exécuter ou de contribuer à votre projet.
Qu'est-ce que la couche d'intention dans la documentation du code ?
La couche d'intention est la partie de la documentation du code qui rend compte de la raison d'être du code, et non de ce qu'il fait : la décision prise, le compromis accepté, la contrainte qui a guidé la conception et l'option que l'équipe a rejetée. Le code montre le comportement ; la couche d'intention préserve la justification. Les outils d'IA tels que GitHub Copilot et Mintlify peuvent rédiger la couche mécanique (types de paramètres, résumés de fonctions), mais ne peuvent pas déduire la couche d'intention à partir de la syntaxe. Celle-ci se trouve généralement dans les Architecture Decision Records, les descriptions de PR ou les commentaires qui expliquent pourquoi plutôt que quoi.
À quelle fréquence la documentation du code doit-elle être mise à jour ?
Mettez à jour la documentation dans la même demande de tirage qui modifie le comportement sous-jacent. Si la signature d'une fonction change, la chaîne de documentation change dans cette demande de tirage. Pour les fichiers README et la documentation d'architecture, effectuez un audit au moins une fois par version ou tous les trimestres. Une documentation obsolète est dangereuse car elle enseigne aux lecteurs un comportement, une API ou un processus erronés.
Quels sont les quatre types de documentation ?
Le framework Diátaxis, largement adopté, divise la documentation en quatre types : les tutoriels (axés sur l'apprentissage, pour les débutants), les guides pratiques (axés sur les tâches, pour les utilisateurs cherchant à résoudre un problème spécifique), les références (axées sur l'information, pour les utilisateurs recherchant des détails) et les explications (axées sur la compréhension, pour les utilisateurs souhaitant connaître le contexte). Les mélanger rend la documentation inutilisable. Un fichier README qui se veut un tutoriel complet peut masquer le chemin d'installation. Une page de référence rédigée comme un essai peut dissimuler l'appel à l'API.
Comment documenter le code à l'aide de l'IA ?
Utilisez l'IA pour la couche mécanique et rédigez vous-même la couche d'intention. Des outils tels que GitHub Copilot, Cursor et Mintlify peuvent rédiger des chaînes de documentation, des descriptions de paramètres, des valeurs de retour et des résumés de fonctions directement dans votre éditeur. Vérifiez le brouillon par rapport au comportement réel du code, puis ajoutez les éléments que l'IA ne peut pas déduire : la justification de la décision, la contrainte qui l'a motivée, l'option que vous avez rejetée et toute hypothèse sur laquelle le code dépend. Pour les décisions au niveau du système, rédigez un rapport de décision architecturale. Ne publiez jamais de documents générés par l'IA sans qu'ils aient été relus par un humain.
La documentation générée par l'IA est-elle fiable ?
La documentation générée par l'IA est utile pour les tâches mécaniques telles que les descriptions de paramètres, les valeurs de retour et les résumés de fonctions de base, mais elle nécessite toujours une révision humaine. Des outils comme GitHub Copilot, Cursor, Codeium et Mintlify gèrent bien ces aspects. L'IA ne peut pas déduire pourquoi un compromis a été fait, quelles alternatives ont été rejetées, ni quelles contraintes liées au produit, à l'entreprise ou à l'infrastructure ont influencé la conception. Utilisez l'IA pour la première ébauche. Ajoutez vous-même l'intention et le contexte.
Chaque fonction a-t-elle besoin d'une chaîne de documentation ?
Non. Les API publiques et toute fonction qu'un autre développeur est susceptible d'appeler nécessitent des chaînes de documentation. Les fonctions d'aide privées utilisées dans un seul fichier n'en ont généralement pas besoin, sauf si la logique n'est pas évidente. Une documentation excessive du code trivial alourdit la maintenance sans apporter de clarté. Adaptez le niveau de détail de la documentation au public cible de la fonction.
Quel est le meilleur outil pour générer de la documentation de code ?
Le choix de l'outil approprié dépend de votre langage. Les équipes Java utilisent Javadoc, celles travaillant avec JavaScript et TypeScript utilisent JSDoc, les équipes Python utilisent Sphinx, les équipes Go utilisent Godoc, et Doxygen prend en charge le C, le C++ et plusieurs autres langages. Les outils assistés par l'IA tels que Mintlify, Swimm, Copilot et Cursor peuvent aider à rédiger ou à effectuer la maintenance de la documentation à différentes étapes du flux de travail, mais ils ne remplacent pas les générateurs natifs du langage.
Quelle doit être la longueur d'un fichier README ?
Suffisamment longue pour répondre rapidement aux questions fondamentales : en quoi consiste le projet, comment l'installer, comment l'utiliser, comment y contribuer et où trouver de l'aide. Placez les détails plus approfondis concernant l'installation, l'architecture et l'API dans des documents liés ou des sous-répertoires.