

Vous êtes chef de service et recherchez la personne idéale pour accomplir une tâche particulière. Avec les vastes données dont dispose votre entreprise, trouver la personne la plus adaptée est presque impossible, surtout si votre tâche est urgente.
De plus, qui a le temps de demander à tout le monde s'il dispose de connaissances suffisantes dans un domaine spécifique ?
Mais que se passerait-il si vous pouviez simplement demander à un système : « Qui a été affecté le plus souvent à [tâche] ? » et obtenir une réponse instantanée et précise basée sur des données réelles ? C'est ce que font les systèmes de recherche d'informations.
Ces systèmes passent au crible des montagnes de données pour trouver exactement ce dont vous avez besoin.
Maintenant, transposez cette idée à une base de données mondiale : un système IR organise de grandes quantités de données, vous aidant à trouver les réponses les plus pertinentes en quelques secondes. Ce guide explore différents modèles de recherche d'informations, leur fonctionnement et le rôle des technologies d'IA dans un système IR.
⏰ Résumé en 60 secondes
📌 Les systèmes de recherche d'informations (IR) aident à trouver des informations pertinentes dans de grandes collections de données, fonctionnant comme un assistant virtuel qui passe au crible les données pour trouver ce dont vous avez besoin.
📌 Les systèmes IR comportent des éléments clés : base de données, indexeur, interface de recherche, processeur de requêtes, modèles de recherche et mécanismes de classement/notation.
📌 Quatre principaux modèles IR sont utilisés : booléen (utilise les opérateurs AND/OR/NOT), espace vectoriel (représente les documents sous forme de vecteurs), probabiliste (utilise des approches statistiques) et interdépendance des termes (analyse les relations entre les termes).
📌 L'apprentissage automatique et le traitement du langage naturel améliorent les systèmes IR en optimisant la reconnaissance des modèles, le classement des résultats et la compréhension du contexte.
📌 Les principaux défis à relever sont la confidentialité des données, l'évolutivité et la maintenance de la qualité des données lors du traitement de grands ensembles de données.
Qu'est-ce que la recherche d'informations (IR) ?
La recherche d'informations (IR) consiste simplement à trouver les bonnes informations dans de grandes collections de données, telles que des bibliothèques numériques, des bases de données ou des archives Internet.
C'est comme avoir un assistant virtuel qui passe au crible des montagnes de données pour vous apporter exactement ce dont vous avez besoin.
En apparence, l'utilisateur saisit une requête, souvent à l'aide de mots-clés ou d'expressions, pour rechercher des informations spécifiques. En coulisses, des techniques et des algorithmes avancés analysent les chaînes de recherche et les mettent en correspondance avec les données pertinentes.
Au lieu de se contenter d'identifier une seule réponse, les systèmes IR fournissent plusieurs objets, chacun présentant un degré de pertinence différent par rapport à votre requête. De plus, ils sont utilisés partout et ont de multiples applications (nous y reviendrons bientôt 🔔).
💡Conseil de pro : vous avez besoin de trouver la personne la plus compétente pour une tâche ? Saisissez des termes spécifiques tels que « analyse des rapports de vente T1 et T2 tâches attribuées à » dans le système de recherche d'informations. En un clin d'œil, il filtre les données non pertinentes et identifie la personne qui s'en est le plus occupée.
Applications de l'IR dans différents champs
Des soins de santé au commerce électronique, les systèmes IR sont utilisés dans de nombreux champs pour gérer et classer les données. Voici quelques exemples 👇
Santé
Dans le domaine de la santé, les systèmes IR analysent les bases de données contenant des dossiers médicaux et des articles de recherche pour aider les médecins et les chercheurs à trouver les informations les plus pertinentes. Le résultat est que ces systèmes accélèrent le diagnostic des maladies, identifient les options de traitement et trouvent les études les plus pertinentes à l'aide de commentaires pertinents.
Service client personnalisé
Les techniques de recherche d'informations rendent le service client plus rapide et plus précis. Par exemple, les agents peuvent saisir des requêtes d'utilisateurs telles que « politique de remboursement » dans le système de l'entreprise pour récupérer des réponses instantanées.
Les chatbots IA et les services d'assistance alimentés par la recherche d'informations vont encore plus loin en proposant des solutions en temps réel sans intervention humaine. C'est pourquoi vos questions trouvent souvent une réponse en quelques secondes !
Plateformes de commerce électronique
Les systèmes de recherche d'informations facilitent les achats en ligne. Ils analysent les bases de données et associent le comportement des clients pour recommander des produits qui vous plairont.
Par exemple, Amazon utilise l'IR pour suggérer des éléments en fonction de votre historique de recherche et de vos achats précédents, vous aidant ainsi à trouver exactement ce dont vous avez besoin.
Composants d'un système de recherche d'informations
Nous savons désormais ce qu'est la recherche d'informations et comment elle fonctionne. Analysons les blocs clés d'un système IR. →
1. Base de données
Tout commence par la base de données. Il s'agit d'un ensemble de points de données interdépendants, tels que des documents texte, des e-mails, des pages web, des images et des vidéos. Lorsque vous saisissez une requête donnée, le système IR effectue une recherche dans ces correspondances de la base de données afin de récupérer les informations les plus pertinentes pour vos besoins.
2. Indexeur
Avant que le système puisse récupérer quoi que ce soit, l'indexeur organise les données. C'est comme préparer un catalogue de bibliothèque pour accélérer la recherche. L'indexeur traite les documents en :
- Tokenisation : division du contenu en petits morceaux, comme la division des phrases en mots ou en expressions (appelés tokens).
- Stemming : simplification des mots à leur forme de base (par exemple, « running » devient « run »).
- Suppression des mots vides : ignorez les mots de remplissage tels que « et », « ou » et « le » pour vous concentrer sur la requête principale.
- Extraction de mots-clés : identification des principaux mots-clés dans le texte
- Extraction de métadonnées : extraire des informations supplémentaires telles que l'auteur, la date de publication ou le titre.
3. Interface de recherche
L'interface de recherche sert de passerelle vers le système IR. C'est là que vous saisissez votre requête à l'aide de mots-clés simples ou de filtres plus détaillés. Conçue pour être conviviale, elle vous permet de communiquer facilement vos besoins en matière d'accès à l'information et d'obtenir les résultats pertinents que vous recherchez.
4. Processeur de requêtes
Une fois que vous avez cliqué sur « Rechercher », le processeur de requêtes prend le relais. Il affine votre requête en appliquant les techniques répertoriées dans la section « Indexation ». De plus, il gère également les opérateurs booléens tels que « AND », « OR » et « NOT » afin de rendre votre requête plus intelligente.
5. Modèles de recherche
C'est là que la magie opère. Le système compare votre requête aux documents indexés à l'aide de modèles de recherche. Ces méthodes déterminent comment faire correspondre votre requête aux données stockées. Voici quelques-uns des noms courants :
- Modèles booléens
- Modèles d'espace vectoriel
- Modèles probabilistes
- Et bien plus encore... (à voir plus tard)
6. Classement et notation
Une fois les correspondances potentielles trouvées, le système les classe en fonction de leur pertinence. Chaque document obtient un score à l'aide de méthodes telles que TF-IDF (fréquence des termes - fréquence inverse des documents) ou d'autres algorithmes. Cela garantit que le résultat le plus pertinent apparaît en tête de liste.
7. Présentation ou affichage
Enfin, les résultats vous sont présentés. En général, le système affiche une liste classée de documents texte avec des fonctionnalités supplémentaires telles que des extraits, des filtres ou des options de tri. Cela facilite la sélection du document le plus pertinent. Cependant, le nombre de résultats affichés peut varier en fonction de vos préférences, de votre requête ou des paramètres du système.
🔍Le saviez-vous ? : Les systèmes traditionnels de recherche d'informations reposaient largement sur des bases de données structurées et la correspondance de mots-clés de base. Le résultat ? Des problèmes majeurs de pertinence et de personnalisation.
C'est alors que les technologies modernes d'IA ont transformé la recherche de texte grâce à :
- Apprentissage automatique (ML) : aide les systèmes IR à apprendre à partir des modèles de comportement des utilisateurs et à améliorer les résultats de recherche au fil du temps.
- Réseaux neuronaux profonds : algorithmes capables de traiter des données non structurées (telles que des images ou des vidéos) et de mettre au jour des relations complexes.
- Traitement du langage naturel (NLP) : permet aux systèmes de comprendre le sens et le contexte des requêtes afin d'offrir de l'assistance pour la reconnaissance d'images et l'analyse des sentiments, rendant ainsi l'accès à l'information plus polyvalent.
Modèles de recherche d'informations
Il existe différents systèmes de recherche d'informations qui rationalisent le processus de recherche de documents pertinents. Examinons les plus couramment utilisés :
1. Théorie des ensembles et modèles booléens
Le modèle booléen est l'une des techniques de recherche d'informations les plus simples. Voici comment il fonctionne :
- ET : Récupère les documents contenant tous les termes de la requête. Par exemple, une recherche sur « chat ET chien » renverra les documents qui mentionnent les deux termes dans un moteur de recherche.
- OU : Trouve les documents contenant n'importe lequel des termes de la requête. Pour « chat OU chien », il récupère les documents qui font mention soit de chat, soit de chien, soit des deux.
- NOT : exclut les documents contenant un terme spécifique. Par exemple, « chat AND NOT chien » renvoie les documents qui mentionnent le chat mais pas le chien.
Ce modèle utilise le concept de « sac de mots », dans lequel une matrice 2D est créée. Dans cette matrice :
- Les colonnes représentent des documents.
- Les lignes représentent les termes de la requête.
Chaque cellule se voit attribuer une valeur de 1 (si le terme est présent) ou 0 (s'il n'est pas présent).

✅ Avantages
- Facile à comprendre et à mettre en œuvre
- Récupère les documents qui correspondent exactement aux termes de la requête.
❌ Inconvénients
- Les modèles booléens ne classent pas les documents par pertinence, tous les résultats sont donc considérés comme ayant la même importance.
- Se concentre sur les correspondances exactes, les résultats peuvent donc varier en fonction du sens ou du contexte de la requête.
2. Modèles d'espace vectoriel
Un modèle d'espace vectoriel est un modèle algébrique qui représente à la fois les documents et les requêtes sous forme de vecteurs dans un espace multidimensionnel. Voici comment cela fonctionne :
1. Une matrice terme-document est créée, où les lignes correspondent aux termes et les colonnes aux documents.
2. Un vecteur de requête est formé à partir des termes de recherche de l'utilisateur.
3. Le système calcule un score numérique à l'aide d'une mesure appelée similarité cosinus, qui détermine le degré de correspondance entre le vecteur de requête et les vecteurs de document.

En tant que système de recherche d'informations, les documents sont ensuite classés en fonction de ces scores, les mieux classés étant les plus pertinents.
✅ Avantages
- Récupère les éléments même si seuls certains termes correspondent.
- Variations dans l'utilisation des termes et la longueur des documents, s'adaptant à divers types de documents
❌ Inconvénients
- Les vocabulaires et les collections de documents plus volumineux rendent les calculs de similarité très gourmands en ressources.
3. Modèles probabilistes
Ce modèle adopte une approche statistique, utilisant la probabilité pour estimer la pertinence d'un document par rapport à la requête. Il prend en compte :
- Fréquence des termes dans le document
- À quelle fréquence les termes apparaissent-ils ensemble (cooccurrence) ?
- Longueur du document et nombre total de termes de requête
Le système traite le processus de recherche comme un évènement probabiliste, classant les documents stockés en fonction de leur pertinence. Cette approche ajoute de la profondeur en évaluant les objets de données au-delà de la simple présence de termes.
✅ Avantages
- S'adapte bien à diverses applications, notamment l'analyse de fiabilité et les évaluations de flux de charge.
❌ Inconvénients
- S'appuie sur des hypothèses concernant les relations entre les données, ce qui peut conduire à des résultats trompeurs.
4. Modèles d'interdépendance des termes
Contrairement aux modèles plus simples, les modèles d'interdépendance des termes se concentrent sur les relations entre les termes plutôt que sur leur fréquence. Ces modèles analysent les relations entre les mots et les expressions afin d'améliorer la précision des résultats.
Ils utilisent l'une des deux approches suivantes :
- Mode immanent : explore les relations au sein du texte lui-même.
- Mode transcendant : prend en compte les données externes ou le contexte pour déduire des relations.
Cette méthode est particulièrement utile pour saisir les nuances de sens, telles que les synonymes ou les expressions spécifiques au contexte.
✅ Avantages
- Capture les nuances linguistiques en tenant compte des relations entre les termes.
- Améliore les performances de recherche en comprenant les dépendances entre les termes et le contexte.
❌ Inconvénients
- Nécessite des données exhaustives pour modéliser avec précision les relations entre les termes, qui ne sont pas toujours disponibles.
C'est tout ! Voici quelques-uns des systèmes de recherche d'informations les plus couramment utilisés, avec leurs avantages et leurs inconvénients respectifs.
➡️ En savoir plus : 4 alternatives et concurrents de Spotlight Search
Récupération d'informations vs requête de données
Bien que ces deux termes semblent presque identiques, ils fonctionnent différemment. Comparons donc la recherche d'informations et la requête de données pour voir comment elles se comparent en termes d'objectif, de cas d'utilisation et d'exemples :
| Aspect | Récupération d'informations (IR) | Requête de données |
| Définition | Fonctionne comme un moteur de recherche qui parcourt des tonnes de données pour vous fournir les résultats les plus pertinents. | Considérez cela comme poser une question spécifique à une base de données dans un langage qu'elle comprend (comme SQL). |
| Objectif/But | Vous aide à trouver rapidement et facilement des informations ou des ressources précises et pertinentes sur les moteurs de recherche. | Extrait des données exactes afin que vous puissiez analyser, mettre à jour ou traiter des nombres. |
| Cas d'utilisation | Utilisé pour les recherches sur le Web, les recommandations en matière de commerce électronique, les bibliothèques numériques, les informations sur les soins de santé, etc. | Idéal pour des tâches telles que la gestion des stocks dans le commerce électronique, l'analyse financière et l'optimisation des chaînes d'approvisionnement. |
| Exemple | Rechercher « Meilleurs ordinateurs portables entre 800 et 1 000 dollars » sur Google pour obtenir des résultats classés | Interrogez votre système d'inventaire avec la requête « SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000 » pour trouver les articles en stock. |
Le rôle de l'apprentissage automatique et du traitement du langage naturel dans la recherche d'informations
Les systèmes IR sont comme des chasseurs de trésors pour les données : ils passent au crible d'énormes quantités d'informations pour trouver exactement ce que vous recherchez. Mais lorsque le ML et le NLP s'associent, ces systèmes deviennent plus intelligents, plus rapides et beaucoup plus précis.
Considérez le ML comme le cerveau derrière les systèmes IR. 🧠
Cela aide le système à apprendre, à s'adapter et à améliorer les résultats chaque fois que vous recherchez des informations. Voici comment cela fonctionne :
- Repérer les tendances : le ML étudie ce sur quoi les utilisateurs cliquent, ce qu'ils ignorent et ce qu'ils passent le plus de temps à lire. Il utilise ensuite ces informations pour vous montrer les résultats les plus pertinents la prochaine fois.
- Résultats du classement : le ML récupère les informations et les classe également. Cela signifie que les résultats les meilleurs et les plus utiles apparaissent en haut de votre recherche.
- S'adapter au fil du temps : à chaque requête, le ML s'améliore. Il identifie les tendances, affine sa compréhension et traite facilement même les questions les plus complexes.
Par exemple, si vous recherchez aujourd'hui « meilleurs ordinateurs portables bon marché » et que vous interagissez avec des résultats spécifiques, le ML saura donner la priorité à des options similaires lorsque vous rechercherez plus tard « ordinateurs portables abordables ». En combinant l'IA et le ML, les moteurs de recherche Web peuvent même prédire ce dont vous pourriez avoir besoin ensuite.
Parlons maintenant du NLP. Il aide les systèmes IR à comprendre ce que vous voulez dire, et pas seulement les mots que vous tapez. En termes simples :
- Il comprend le contexte : le NLP sait que lorsque vous dites « jaguar », vous pouvez faire référence à l'animal ou à la voiture, et il le détermine en fonction du reste de votre requête.
- Il gère les langages complexes : que votre requête soit simple (« vols pas chers ») ou détaillée (« vols directs vers Tokyo à moins de 500 $ »), le NLP veille à ce que le système comprenne et fournisse les résultats appropriés.
Ensemble, le NLP et l'IR rendent la recherche intuitive, comme si vous parliez à quelqu'un qui vous comprend parfaitement. Cela signifie moins de défilement, moins de frustration et plus de moments où vous vous dites « Waouh, c'est exactement ce dont j'avais besoin ! ».
Le rôle de ClickUp dans la recherche d'informations
ClickUp, « l'application tout-en-un pour le travail », améliore la gestion des données grâce à des modèles IR.
Son IA intégrée identifie et associe de manière unique les résultats à la requête d'un utilisateur, faisant passer la technologie intelligente à un niveau supérieur.
Et pour couronner le tout, la fonction Connected Search de ClickUp vous permet d'accéder « immédiatement » à tout ce dont vous avez besoin. Cela signifie que :
- Recherchez tout ce que vous voulez : qui aime fouiller dans ses e-mails et ses systèmes de gestion des connaissances pour trouver des fichiers importants ? Trouvez n'importe quel fichier en quelques secondes grâce à l'option de recherche connectée. Mieux encore, recherchez des fichiers dans toutes vos applications connectées et accédez à tout en un seul endroit.
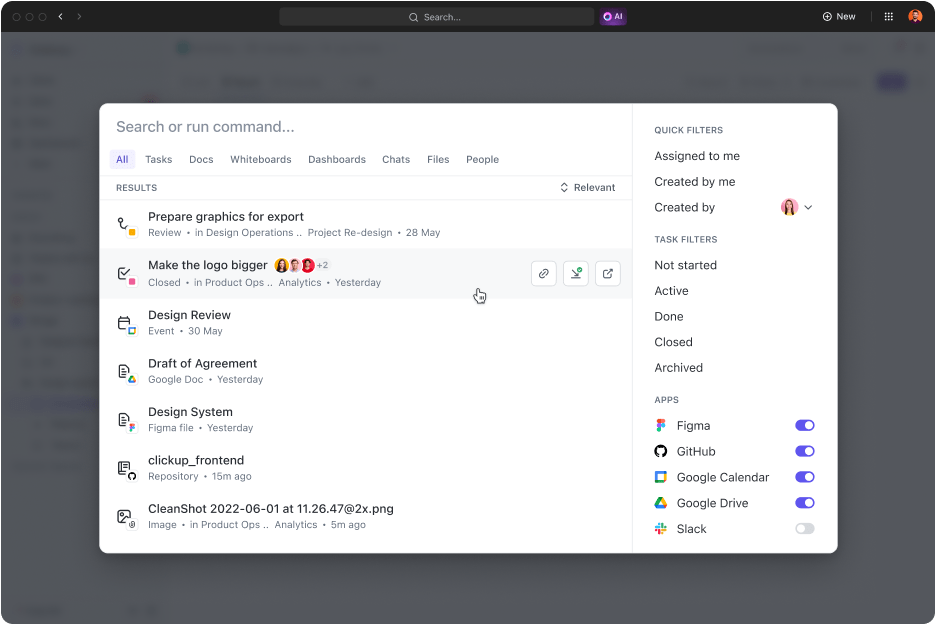
- Connectez vos applications préférées : ClickUp dispose de certaines des meilleures intégrations qui étendent ses capacités de recherche à des applications tierces telles que Google Drive, Slack, Dropbox, Figma, etc.

- Affiner les résultats : plus vous l'utilisez, plus il comprend ce que vous recherchez et vous fournit des résultats personnalisés.
- Effectuez vos recherches à votre façon : accédez à la recherche connectée et recherchez rapidement des fichiers PDF depuis n'importe où dans votre environnement de travail. Vous pouvez par exemple lancer une recherche depuis le centre de commande, la barre d'actions globale ou votre bureau.
- Créez des commandes de recherche personnalisées : ajoutez des commandes de recherche personnalisées telles que des raccourcis vers des liens, l'enregistrement de texte pour plus tard, etc. afin de rationaliser votre flux de travail.
Pour couronner le tout, et s'il existait un moyen d'automatiser les tâches fastidieuses, de travailler plus rapidement et d'accomplir davantage de choses en un rien de temps ?
ClickUp Brain, l'assistant IA intégré, vous permet d'y parvenir. C'est l'assistant ultime pour la gestion des données : intelligent, rapide et toujours prêt à vous aider.
En bref 👇
- Centre de connaissances tout-en-un : ne dépendez plus jamais des e-mails et des messages pour obtenir des mises à jour. Posez toutes vos questions sur vos tâches, vos documents ou vos collaborateurs, puis détendez-vous pendant que ClickUp Brain trouve les réponses en fonction du contexte à partir des applications internes et connectées.

- Trouvez plus rapidement ce dont vous avez besoin : ClickUp Brain classe les résultats de manière intelligente, à l'instar d'un système IR avancé. Il hiérarchise les fichiers pertinents, suggère des tâches connexes et vous aide même à découvrir les charges de travail cachées dans vos données.
- Automatisez les tâches : Brain automatise la génération de rapports ou le suivi des échéances grâce à ses Outils d'IA. C'est un assistant personnel qui vous libère du temps pour prendre des décisions plus importantes tout en gardant le cap.
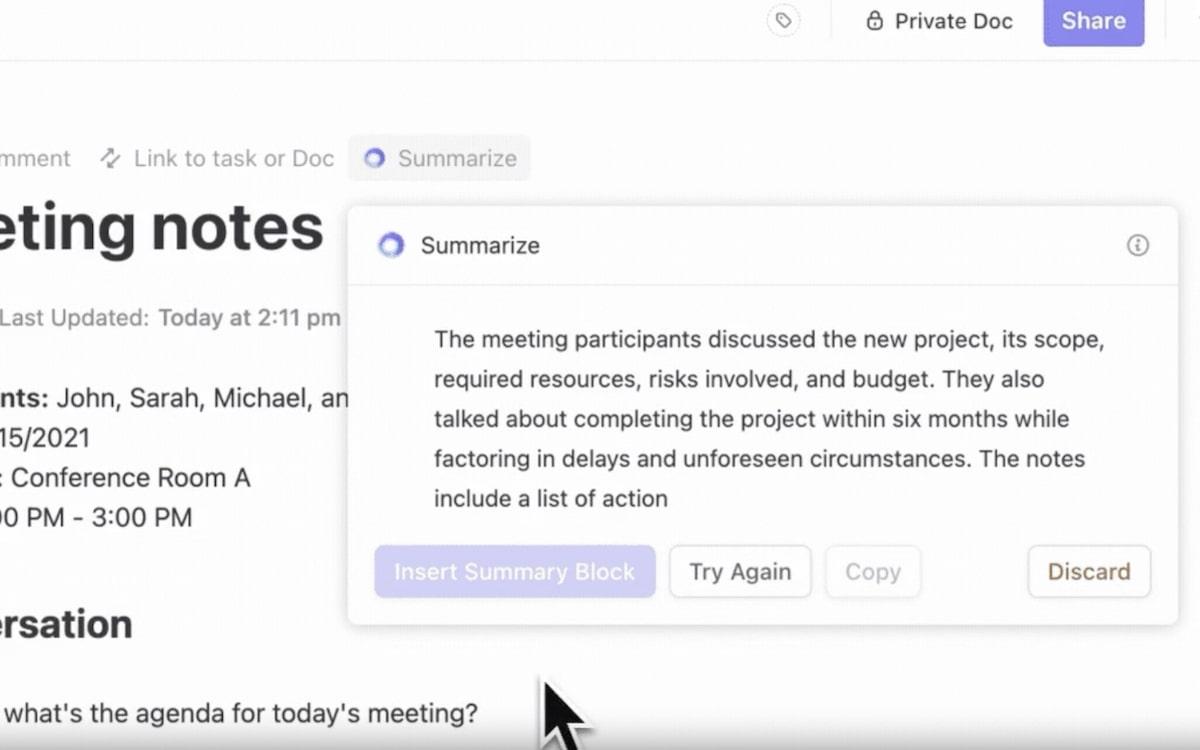
- Recherche contextuelle : grâce au NLP, le système comprend votre question, même si votre requête est complexe ou vague. Par exemple, en recherchant « rapport sur les ventes du premier trimestre », vous obtenez le rapport exact lié à votre tâche.
➡️ En savoir plus : Qu'est-ce qu'un système de gestion du travail et comment le mettre en œuvre ?
Défis et orientations futures dans le domaine de la recherche d'informations
Le monde de la recherche d'informations consiste à donner du sens à de vastes quantités de données, mais même les systèmes IR les plus avancés rencontrent quelques obstacles en cours de route.
Explorons les défis courants et les tendances passionnantes qui forment l'avenir de cette discipline scientifique essentielle :
- Confidentialité et sécurité des données : pour qu'un modèle IR fournisse des résultats factuels, il doit souvent avoir accès à des données sensibles. Cependant, la protection des données des utilisateurs n'est pas une mince affaire pour les ressources de recherche d'informations.
- Évolutivité et performances : lorsque les utilisateurs effectuent des recherches dans de grands ensembles de données, la gestion d'une collection de contenus en constante augmentation peut submerger même les modèles de recherche les plus robustes. Le défi consiste à garantir une recherche efficace sans compromettre la pertinence des résultats.
- Qualité des données et compréhension contextuelle : les requêtes ambiguës ou les métadonnées mal organisées peuvent entraîner des incohérences, rendant difficile pour le système d'identifier de manière unique l'intention de l'utilisateur.
Tendances émergentes et avancées dans la technologie IR
Malgré les nombreux obstacles, les récentes avancées technologiques nous ont permis de créer des systèmes plus intelligents et plus efficaces.
Les systèmes modernes de recherche d'informations utilisent désormais des méthodes avancées telles que l'analyse graphique pour interpréter les nombres, le texte, le contexte, les métadonnées et les relations entre les points de données.
Qu'est-ce que cela signifie pour les utilisateurs ? Cela permet une recherche de texte plus précise et une analyse plus détaillée, en particulier dans des champs tels que la recherche et les industries traitant de grandes quantités de données.
Combiné aux technologies du web sémantique, il se concentre sur les chaînes de recherche et l'intention de l'utilisateur. Ces systèmes peuvent aller au-delà des correspondances littérales et récupérer des documents très pertinents, même pour des requêtes utilisateur complexes dans le processus de recherche d'informations.
Par exemple, une recherche sur les « avantages du télétravail » peut donner des résultats liés à la productivité, à la santé mentale et à l'équilibre entre travail et vie privée, tout cela parce que le système comprend les connexions entre ces éléments.
Récupérez rapidement des documents grâce à la gestion des données de ClickUp
Fouiller dans une multitude de fichiers, d'applications et d'outils pour trouver ce document important est épuisant. Imaginez que vous essayez d'analyser les documents récupérés en tant que chercheur, étudiant, professionnel de l'informatique ou scientifique des données : cela devient vite un véritable fouillis d'informations.
Mais avec ClickUp, vous ne perdrez plus jamais de temps à rechercher des informations.
Il s'agit d'une solution tout-en-un qui regroupe toutes vos tâches en un seul endroit. Grâce à des fonctionnalités telles que Connected Search et ClickUp Brain, peu importe où se trouvent vos données : ClickUp vous permet de les trouver, de les gérer et d'agir facilement.
Pourquoi se contenter d'un résultat « correct » quand vous pouvez obtenir un résultat « exceptionnel » ? Essayez ClickUp gratuitement et découvrez comment il transforme votre flux de travail en un processus audacieux, efficace et tout simplement imparable !