

Piense en una base de datos relacional como un archivador bien organizado en el que cada cajón y carpeta tiene un rótulo y está clasificado para facilitar el acceso. Sin él, encontrar el documento adecuado puede ser una pesadilla.
Un sistema de gestión de bases de datos relacionales (RDBMS) robusto es fundamental para cualquier aplicación exitosa. Al organizar y gestionar los datos de manera eficiente, las bases de datos relacionales hacen que la gestión de datos sea intuitiva y potente.
Bases de datos relacionales bien diseñadas:
- Adáptese a las metas empresariales sin interrumpir el sistema.
- Permita una fácil recuperación de datos.
- No tenga redundancia de datos.
- Capture todos los datos necesarios.
Pero, ¿qué hace que un sistema de gestión de bases de datos relacionales sea «relacional» y por qué es tan esencial? En esta entrada del blog se exploran los conceptos que subyacen a un sistema de bases de datos relacionales y se le proporcionan las herramientas necesarias para crear uno.
Comprensión de las bases de datos relacionales
Una base de datos relacional almacena datos en un formato estructurado utilizando filas y columnas. Es como una base de datos Excel bien organizada, donde los datos se organizan en tablas. Cada tabla representa un tipo diferente de datos, y las relaciones entre las tablas se establecen a través de identificadores únicos conocidos como claves.
Esto le permite recuperar y manipular información de manera eficiente en la misma base de datos o en varias bases de datos.
Antiguamente, eran principalmente los desarrolladores quienes utilizaban las bases de datos. Extraían la información de las bases de datos con SQL o Structured Query Language, un lenguaje de programación. De hecho, un RDMBS también se denomina base de datos SQL.
Por el contrario, una base de datos no relacional, o base de datos NoSQL, almacena datos, pero sin las tablas, filas o claves que caracterizan a una base de datos relacional. En su lugar, las bases de datos no relacionales optimizan su almacenamiento en función del tipo de datos que se almacenan.
Componentes de una base de datos relacional
Comprender los componentes fundamentales de una base de datos relacional es necesario para gestionar y utilizar los datos de forma eficaz. En conjunto, estos componentes estructuran, almacenan y enlazan los datos para garantizar su precisión y eficiencia.
1. Tablas
Imagine las tablas como la base de datos, donde cada tabla contiene información sobre una entidad específica. Por ejemplo, puede tener una tabla de proyectos con columnas para el ID del proyecto, el nombre, la fecha de inicio y el estado. Cada fila de esta tabla representa un proyecto diferente, organizado de forma clara para facilitar el acceso.
— Crear la tabla del proyecto
CREATE TABLE Proyectos (
ProjectID INT PRIMARY KEY,
NombreProyecto VARCHAR(100),
StartDate DATE,
Estado VARCHAR(50)
);
2. Clave principal
Las claves primarias son identificadores únicos o insignias para cada registro que no pueden dejarse vacíos. Garantizan que una consulta pueda identificar claramente cada fila de una tabla, y una tabla solo puede tener una clave primaria. Por ejemplo, en una tabla de tareas, el ID de tarea podría ser la clave primaria, que distingue cada tarea del resto.
— Crear la tabla de tareas
Tareas CREATE TABLE (
TaskID INT PRIMARY KEY,
TaskName VARCHAR(100),
Fecha límite FECHA
);
3. Clave externa
Una clave externa es como una conexión lógica que vincula una tabla con otra. Es un campo de una tabla que crea un vínculo con otra al hacer referencia a una clave principal de esa tabla. Por ejemplo, supongamos que desea identificar los comentarios asociados a una tarea. Así, en una tabla Comentarios, el ID de tarea se convierte en una clave externa que enlaza con el ID de tarea en la tabla Tareas [arriba], mostrando a qué tarea está relacionado cada comentario.
— Crear la tabla de comentarios
CREATE TABLA Comentarios (
CommentID INT PRIMARY KEY,
TaskID INT,
ComentarioTexto TEXTO,
FOREIGN KEY (TaskID) REFERENCES Tasks(TaskID)
);
4. Índices
Los índices mejoran el rendimiento de las consultas al permitir un acceso rápido a las filas en función de los valores de las columnas. Por ejemplo, crear un índice en la columna StartDate de la tabla Projects acelera las consultas que filtran por fechas de inicio de proyectos.
— Cree un índice en la columna StartDate.
CREATE ÍNDICE idx_startdate ON Proyectos(StartDate);
5. Vistas
Las vistas son tablas virtuales creadas mediante la consulta de datos de una o varias tablas. Simplifican las consultas complejas al presentar los datos en un formato más accesible. Por ejemplo, una vista puede mostrar un resumen del estado de los proyectos y las tareas asociadas.
— Crear una vista para resumir las tareas del proyecto
CREATE VIEW ProjectTaskSummary AS
SELECT p. ProjectName, t. TaskName
DE Proyectos p
JOIN tareas t ON p. ProjectID = t. ProjectID;
Diferentes tipos de relaciones en las bases de datos relacionales
Establecer cómo interactúan las diferentes tablas en las bases de datos relacionales es fundamental para mantener la integridad de los datos y optimizar las consultas. Estas interacciones se definen a través de diversas relaciones, cada una de las cuales tiene un propósito específico para organizar y enlazar los datos de manera eficaz.
Comprender estas relaciones ayuda a diseñar un esquema de base de datos robusto que refleje con precisión las conexiones del mundo real entre diferentes entidades.
1. Relación uno a uno
Imagine un escenario en el que cada empleado [uno] tiene exactamente una insignia de identificación de empleado [una]. Por lo tanto, en los registros de la tabla Empleados, cada registro corresponderá a un único registro en la tabla Insignias de identificación de empleados. Se trata de una relación uno a uno entre tablas, en la que una entrada coincide exactamente con la otra.
Aquí tiene un código de muestra para ilustrar una relación uno a uno:
— Crear la tabla de empleados
CREATE TABLE Empleados (
EmployeeID INT clave PRIMARY KEY,
Nombre VARCHAR(100)
);
— Crear la tabla IDBadges
CREATE TABLE IDBadges (
BadgeID INT PRIMARY KEY,
EmployeeID INT UNIQUE,
FOREIGN CLAVE (EmployeeID) REFERENCES Employees(EmployeeID)
);
El campo EmployeeID de la tabla IDBadges corresponde de forma única [UNIQUE es un comando SQL que no permite datos duplicados ni entradas repetidas en los registros bajo el atributo] a una entrada del campo EmployeeID de la tabla Employees.
2. Relación uno a muchos
Piense en el director de gestión de proyectos de una gran organización [uno] que supervisa múltiples proyectos [muchos].
En este caso, la tabla Project Managers tiene una relación uno a muchos con la tabla Projects. El Project Manager gestiona muchos proyectos, pero cada proyecto pertenece a un solo Project Manager.
— Crear la tabla del gestor de proyectos
CREATE TABLE ProjectManagers (
ManagerID INT PRIMARY KEY,
ManagerName VARCHAR(100)
);
— Crear la tabla del proyecto
CREATE TABLE Proyectos (
ProjectID INT PRIMARY KEY,
NombreProyecto VARCHAR(100),
ManagerID INT,
FOREIGN CLAVE (ManagerID) REFERENCES ProjectManagers(ManagerID)
);
El campo ManagerID es la referencia que conecta ambas tablas. Sin embargo, no es único en la segunda tabla, lo que significa que puede haber varios registros de un solo ManagerID en la tabla, o que un gestor puede tener numerosos proyectos.
3. Relación muchos a muchos
Imagine un escenario en el que varios empleados [muchos] están trabajando en diversos proyectos [muchos].
Para realizar un seguimiento, utilizaría una tabla de unión, como Employee_Project_Assignments, que conecta a los empleados con los proyectos en los que están trabajando. Esta tabla tendrá claves externas que enlazan la tabla Employees y la tabla Projects.
— Crear la tabla de empleados
CREATE TABLE Empleados (
EmployeeID INT clave PRIMARY KEY,
EmployeeName VARCHAR(100)
);
— Crear la tabla del proyecto
CREATE TABLE Proyectos (
ProjectID INT PRIMARY KEY,
NombreProyecto VARCHAR(100)
);
— Crear la tabla de asignaciones de proyectos de los empleados
CREATE TABLA Employee_Project_Assignments (
EmployeeID INT,
ProjectID INT,
PRIMARY CLAVE (EmployeeID, ProjectID),
FOREIGN CLAVE (EmployeeID) REFERENCES Employees(EmployeeID),
FOREIGN CLAVE (ProjectID) REFERENCES Proyectos(ProjectID)
);
Aquí, Employee_Project_Assignments es la tabla de unión que enlaza a los empleados y los proyectos.
Ventajas de las bases de datos relacionales
Las bases de datos relacionales han cambiado el enfoque de la gestión de datos. Sus ventajas las convierten en la solución ideal para cualquiera que realice el trabajo con grandes conjuntos de datos interconectados.
1. Coherencia
Imagina intentar dar sentido a un conjunto de datos inconexos en el que las tablas y los campos no siguen las reglas de nomenclatura y están desordenados: confuso, ¿verdad?
Las bases de datos relacionales destacan porque se centran en la coherencia. Aplican reglas de integridad de datos que organizan la información para mantenerla precisa y fiable.
Por ejemplo, si está creando una base de datos de clientes, las bases de datos relacionales garantizan que los datos de contacto de los clientes estén correctamente enlazados a sus pedidos, lo que evita discrepancias o errores.
— Crear la tabla de clientes
CREATE TABLE clientes (
customer_id INT PRIMARY KEY,
nombre VARCHAR(100),
correo electrónico VARCHAR(100)
);
— Cree la tabla de pedidos con una restricción de clave externa
CREATE TABLE pedidos (
order_id INT PRIMARY KEY,
customer_id INT,
fecha_pedido FECHA,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
Este código evita que los pedidos sean enlazados con clientes inexistentes, lo que garantiza la coherencia de los datos. Así, al utilizar el modelo relacional, siempre trabajará con datos fiables, lo que facilitará sus análisis y la elaboración de informes.
2. Normalización
Manejar múltiples servidores y hojas de cálculo y lidiar con información duplicada de los clientes es agotador. Las bases de datos relacionales son un cambio revolucionario en este sentido.
La normalización organiza sus estructuras de datos en tablas claramente relacionadas que reducen la redundancia y optimizan el almacenamiento de datos utilizando el modelo relacional.
Imagine un sistema CRM (gestión de relaciones con los clientes). La normalización le ayuda a separar los datos de los clientes de sus interacciones y compras. Si un cliente actualiza su información de contacto, solo tendrá que actualizarla una vez.
A continuación le indicamos cómo puede realizar los ajustes:
— Crear una tabla de clientes
CREATE TABLE clientes (
customer_id INT PRIMARY KEY,
nombre VARCHAR(100),
correo electrónico VARCHAR(100),
teléfono VARCHAR(20)
);
— Crear una tabla de pedidos
CREATE TABLE pedidos (
order_id INT PRIMARY KEY,
customer_id INT,
fecha_pedido FECHA,
total_amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
— Crear una tabla de interacciones con los clientes:
CREATE TABLE customer_interactions (
interaction_id INT PRIMARY KEY,
customer_id INT,
interaction_date DATE,
interaction_type VARCHAR(50),
notas TEXTO,
FOREIGN CLAVE (customer_id) REFERENCES customers(customer_id)
);
Con esta configuración, actualizar el correo electrónico de un cliente es muy sencillo: basta con realizar el cambio en la tabla Clientes, sin que ello afecte a las consultas ni a otras tablas en ningún otro lugar. Esto hace que la gestión, la consulta y el almacenamiento de datos sean más eficientes y menos propensos a errores.
3. Escalabilidad
A medida que su empresa crezca, también lo harán su base de datos de empleados y su base de datos de clientes. Los desarrolladores de sistemas de software de bases de datos relacionales diseñan bases de datos relacionales para gestionar grandes volúmenes de datos.
Tanto si gestiona los registros de ventas de una startup como los múltiples usuarios de un gigante tecnológico, las bases de datos relacionales se adaptan sin esfuerzo al crecimiento de su empresa. Crean índices del modelo de datos y optimizan los conjuntos de datos para mantener un rendimiento fluido a medida que crecen sus datos.
Por ejemplo, para mejorar el rendimiento de las consultas en una tabla de pedidos grande, puede crear un índice en la columna order_date:
— Crear un índice en la columna order_date
CREATE ÍNDICE idx_order_date ON pedidos(order_date);
Este índice crea un conjunto de datos independiente que almacena la ubicación de la columna order_date y al que se puede acceder rápidamente.
La creación de un índice acelera la ejecución de consultas cuando se aplica un filtro o se ordena por fecha de pedido, lo que agiliza las transacciones de la base de datos relacional.
También ayuda a que sus sistemas de gestión de bases de datos relacionales se adapten al crecimiento de los pedidos.
4. Flexibilidad
La flexibilidad es fundamental cuando se trabaja con necesidades de datos en constante evolución, y las bases de datos relacionales ofrecen precisamente eso.
¿Necesita añadir nuevos campos o tablas? ¡Adelante!
Por ejemplo, si necesita realizar el seguimiento de los puntos de fidelidad de los clientes en la tabla de clientes de su base de datos de gestión de recursos de clientes (CRM), puede añadir una nueva columna:
— Añadir una nueva columna para los puntos de fidelidad
ALTER TABLE clientes ADD puntos_fidelidad INT predeterminado/a 0;
Esta adaptabilidad garantiza que su modelo de gestión de bases de datos relacionales pueda crecer y cambiar según las necesidades de su proyecto sin afectar al modelo de datos relacionales existente, las estructuras de almacenamiento físico, el modelo de almacenamiento físico de datos o las operaciones de la base de datos.
A medida que exploramos los sistemas de bases de datos relacionales, ClickUp destaca como una herramienta de gestión de proyectos versátil que ofrece potentes funciones de CRM y bases de datos relacionales.

El software de gestión de proyectos CRM de ClickUp transforma la forma en que gestiona las relaciones con los clientes y agiliza los procesos de ventas. Puede adaptar el modelo de base de datos relacional de clientes a su gusto enlazando tareas, documentos y acuerdos, y utilizar la automatización y los formularios para agilizar los flujos de trabajo, automatizar la asignación de tareas y desencadenar actualizaciones de estado.
Puede explorar la información sobre sus clientes con paneles de control de rendimiento para visualizar métricas críticas, como el valor del ciclo de vida del cliente y el tamaño medio de las transacciones.
Además, ClickUp CRM puede ayudarle a simplificar la gestión de cuentas, organizar clientes, gestionar canales, realizar el seguimiento de los pedidos e incluso añadir datos geográficos, todo ello diseñado para potenciar la eficiencia y la productividad de su CRM.
5. Potentes capacidades de consulta
Para descubrir información valiosa en su base de datos relacional, puede utilizar SQL para realizar búsquedas complejas, unir varias tablas y agregar datos.
Por ejemplo, supongamos que está analizando el rendimiento de las ventas buscando el número total de pedidos y su valor por cliente. Esta consulta une las tablas de clientes y pedidos para proporcionar un resumen del rendimiento de las ventas por cliente.
Un procedimiento almacenado es como un atajo en una base de datos. Los procedimientos almacenados son bloques de código SQL preescritos que se pueden ejecutar siempre que sea necesario realizar consultas complejas, automatizar tareas o gestionar procesos repetitivos.
Mediante el uso de procedimientos almacenados, optimiza las operaciones, aumenta la eficiencia y garantiza que las acciones de la base de datos sean coherentes y rápidas. Los procedimientos almacenados son perfectos para la validación de datos y la actualización de registros.
SQL le permite recopilar datos de diferentes tablas para crear informes detallados y visualizaciones. Esta capacidad de generar información significativa convierte a las bases de datos relacionales en una herramienta vital para los administradores de bases de datos, los analistas de datos o los desarrolladores de datos.
Pasos para crear una base de datos relacional
Ahora que hemos explorado y comprendido los componentes y los diferentes tipos de relaciones en las bases de datos relacionales, es el momento de aplicar lo que hemos aprendido. A continuación, le ofrecemos una guía paso a paso para crear una base de datos relacional. Para comprenderlo mejor, crearemos una base de datos de gestión de proyectos.
Paso 1: Defina el propósito
Comience por aclarar qué será lo pendiente para su sistema de base de datos relacional.
En nuestro ejemplo, estamos creando un modelo de base de datos relacional para realizar el seguimiento de las propiedades de la gestión de proyectos, como las tareas, los miembros del equipo y los plazos.
Usted desea que la base de datos relacional:
- Gestión de varios proyectos simultáneamente.
- Asigne tareas a los miembros del equipo y realice el seguimiento de su progreso.
- Supervise los plazos de las tareas y el estado de finalización.
- Genere informes sobre el progreso del proyecto y el rendimiento del equipo.
Paso 2: Diseñar el esquema
A continuación, esboce la estructura de su base de datos relacional.
Identifique las entidades clave [tablas], sus atributos de datos [columnas] y cómo interactúan. Este paso implica planear cómo se organizarán y relacionarán sus datos estructurados.
Entidades para la gestión de proyectos:
- Proyectos: Contiene detalles sobre cada proyecto.
- Tareas: Incluye información sobre tareas individuales.
- Miembros del equipo: Almacena detalles sobre el equipo.
- Asignación de tareas: vincula las tareas con los miembros del equipo.
Aquí tiene una muestra de esquema:
| Nombre de la tabla | Atributos | Descripción |
| Proyectos | project_id (INT, PK)project_name (VARCHAR(100))start_date (DATE)end_date (DATE) | La tabla almacena información sobre cada proyecto. |
| Tareas | task_id (INT, PK)project_id (INT, FK)task_name (VARCHAR(100))estado (VARCHAR(50))due_date (DATE) | La tabla contiene detalles de las tareas asociadas a los proyectos. |
| Miembros del equipo | member_id (INT, PK)name (VARCHAR(100))rol (VARCHAR(50)) | La tabla contiene información sobre los miembros del equipo. |
| TareasAsignaciones | task_id (INT, FK)member_id (INT, FK)assignment_date (DATE) | La tabla enlaza las tareas con los miembros del equipo y las fechas de asignación. |
Las relaciones entre estas estructuras de datos lógicas y las tablas de datos pueden resultar confusas en ocasiones, ya que la mayoría de los sistemas de gestión de bases de datos relacionales son cada vez más complejos.
Muchos prefieren una representación visual de las relaciones, normalmente mediante mapas mentales y herramientas de diseño de bases de datos relacionales .
Más adelante en este artículo abordaremos los mapas mentales y las herramientas de diseño de bases de datos relacionales.
Paso 3: Establecer relaciones
Anteriormente hemos hablado de los tipos de relaciones, y el esquema de la tabla ayuda a definir las relaciones entre las tablas.
La clave externa es fundamental para garantizar la coherencia de los datos y permitir consultas complejas.
Enlazan puntos de datos relacionados entre tablas y mantienen la integridad referencial de los datos en todo momento, garantizando que cada registro esté correctamente conectado con los demás.
Pero debe tener un uso compartido para facilitar su consulta, como en el ejemplo siguiente:
- Las tareas están relacionadas con los proyectos a través de project_id.
- Las asignaciones de tareas enlazan las tareas y los miembros del equipo mediante task_id y member_id.
Paso 4: Crear tablas
Ya hemos hablado en profundidad del proceso de creación de tablas y de la definición de claves primarias y externas. Puede consultar esas secciones cuando lo necesite. Sin embargo, a continuación encontrará las consultas SQL para crear una pequeña base de datos relacional para la gestión de proyectos como parte de la guía.
— Crear una tabla de proyectos
CREATE TABLE Proyectos (
project_id INT PRIMARY KEY,
project_name VARCHAR(100),
start_date DATE,
end_date DATE
);
— Crear una tabla de tareas
Tareas CREATE TABLE (
task_id INT PRIMARY KEY,
project_id INT,
task_name VARCHAR(100),
estado VARCHAR(50),
fecha_vencimiento FECHA,
FOREIGN CLAVE (project_id) REFERENCES Proyectos(project_id)
);
— Crear una tabla de miembros del equipo
CREATE TABLE TeamMembers (
member_id INT PRIMARY KEY,
nombre VARCHAR(100),
rol VARCHAR(50)
);
— Crear tabla de asignaciones de tareas
CREATE TABLE TaskAssignments (
task_id INT,
member_id INT,
assignment_date DATE,
FOREIGN KEY (task_id) REFERENCES Tasks(task_id),
FOREIGN CLAVE (member_id) REFERENCES TeamMembers(member_id),
PRIMARY CLAVE (task_id, member_id)
);
Paso 5: Introducir datos
Añada algunos datos reales a sus tablas para ver cómo funciona todo.
Este paso consiste en probar su configuración para asegurarse de que sus bases de datos relacionales funcionan según lo previsto. Incluiría insertar los detalles del proyecto, las descripciones de las tareas, los miembros del equipo y las asignaciones en la base de datos SQL.
Ejemplo de código SQL
— Insertar en la tabla Proyectos
INSERT INTO Proyectos (id_proyecto, nombre_proyecto, fecha_inicio, fecha_fin) VALORES
(1, «Rediseño del sitio web», «2024-01-01», «2024-06-30»),
(2, «Desarrollo de aplicaciones móviles», «2024-03-01», «2024-12-31»);
— Insertar en la tabla Tareas
INSERT INTO Tareas (id_tarea, id_proyecto, nombre_tarea, estado, fecha_vencimiento) VALORES
(1, 1, «Maquetas de diseño», «En curso», «15-02-2024»),
(2, 1, «Desarrollo front-end», «No iniciado», «30-04-2024»);
— Insertar en la tabla Miembros del equipo
INSERT INTO TeamMembers (member_id, name, rol) VALUES
(1, «Alice Johnson», «Diseñadora»),
(2, «Bob Smith», «Desarrollador»);
— Insertar en la tabla de asignaciones de tareas
INSERT INTO TaskAssignments (task_id, member_id, assignment_date) VALUES
(1, 1, «2024-01-10»),
(2, 2, «2024-03-01»);
Paso 6: Consulta de datos
Por último, una vez que los datos estén almacenados en su base de datos relacional, utilice consultas SQL para recuperarlos y analizarlos. Las consultas pueden ayudarle al seguimiento del progreso del proyecto, a la supervisión de la asignación de tareas y a la generación de informes valiosos.
Ejemplo de consulta SQL
— Consulta para encontrar todas las tareas de un proyecto específico
SELECT t. nombre_tarea, t. estado, t. fecha_vencimiento, tm. nombre
DESDE Tareas t
JOIN TaskAssignments ta ON t. task_id = ta. task_id
JOIN TeamMembers tm ON ta. member_id = tm. member_id
WHERE t. project_id = 1;
Creación de sistemas de gestión de bases de datos relacionales con la vista Tabla de ClickUp.
ClickUp destaca por crear bases de datos relacionales y hojas de cálculo limpias, organizadas y colaborativas utilizando su vista Tabla.
La vista Tabla de ClickUp admite más de 15 tipos de datos, desde fórmulas y progreso de tareas hasta costes y valoraciones, y le permite adjuntar documentos y enlaces directamente a sus tablas. Ofrece una forma visual e intuitiva de gestionar su base de datos relacional y la estructura de datos relacionales dentro de los proyectos.

Una guía paso a paso para crear un sistema de gestión de bases de datos relacionales utilizando la vista Tabla de ClickUp.
Paso 1: Defina la base de datos
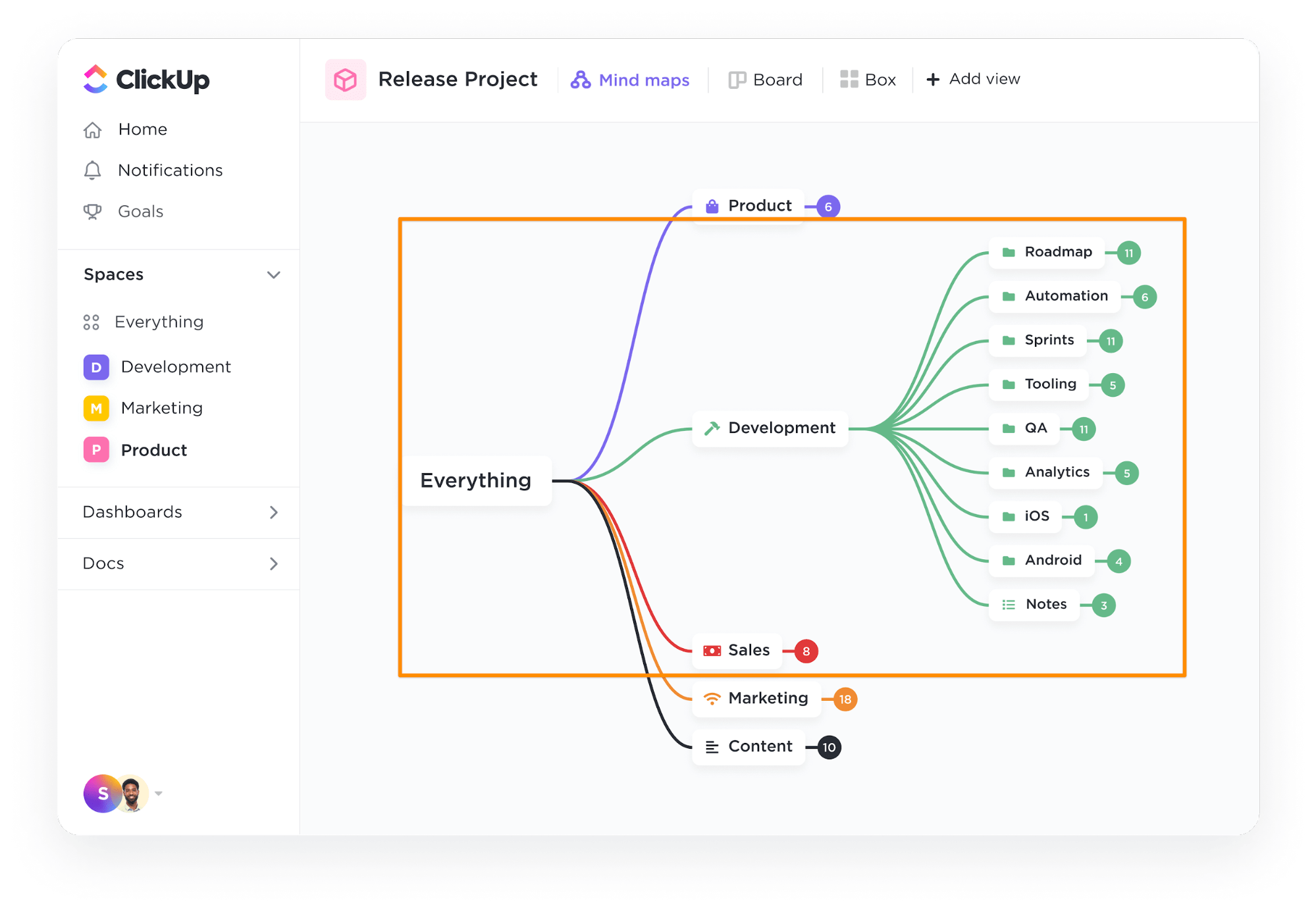
Utilice la herramienta ClickUp Mapas mentales para completar y definir el esquema de su base de datos, es decir, qué tablas crear y sus relaciones entre sí.
Paso 2: Configurar una vista Tabla
Navegue hasta el proyecto o entorno de trabajo deseado en ClickUp.

Añada una nueva vista y seleccione Vista Tabla.
Paso 3: Crear tablas
Utilice tareas y campos personalizados para representar tablas y columnas.

Organice los puntos de datos clave dentro de la vista Tabla.
Paso 4: Establecer relaciones
Utilice campos personalizados para vincular tareas relacionadas [por ejemplo, utilizando campos desplegables para hacer referencia a otras tareas].

Mantenga la integridad de los datos asegurándose de que los enlaces sean precisos.
Paso 5: Gestionar datos
Añada, edite y elimine entradas de datos directamente en la vista Tabla.

Utilice filtros y opciones de clasificación para gestionar y analizar datos.
Paso 6: Consultas e informes
Utilice las funciones avanzadas de filtrado y elaboración de informes de ClickUp para obtener información valiosa a partir de sus datos relacionales.

Las plantillas de bases de datos gratuitas y listas para usar de ClickUp pueden acelerar el proceso de creación de bases de datos relacionales y simplificar las cosas.

La plantilla de hoja de cálculo ClickUp recopila información crucial sobre los clientes para su empresa. Es una plantilla a nivel de lista que utiliza una base de datos de archivo plano.
Solo tienes que añadir la plantilla a tu espacio y utilizarla directamente.
Estas plantillas de hoja de cálculo le ayudan a recopilar y gestionar de forma eficiente los datos esenciales de los clientes. Puede almacenar datos de forma segura y crear bases de datos relacionales altamente eficientes que pueden ayudar al equipo de ventas de su organización.
La plantilla de hoja de cálculo editable de ClickUp es la plantilla más fácil de personalizar para gestionar datos financieros complejos. Esta plantilla agiliza el seguimiento del presupuesto y la planificación de proyectos.
Funciones como la importación automática de datos, fórmulas financieras personalizadas, elementos visuales intuitivos para realizar el seguimiento del progreso y estados, campos y vistas personalizados para organizar y gestionar de forma eficiente los registros financieros lo convierten en la herramienta ideal para expertos en datos financieros y gestores.
Con ClickUp, puede automatizar tareas, configurar actualizaciones periódicas y revisar su estructura de datos sin problemas, lo que garantiza la precisión y la coherencia en todos sus documentos.
La creación de contenido puede convertirse rápidamente en una tarea abrumadora debido a la cantidad de contenido que se genera. Para gestionar esto, una base de datos de contenido ayuda a organizar y realizar el seguimiento del contenido de manera eficiente, lo que facilita su ampliación a medida que crecen sus necesidades. Consolida toda la información relacionada con el contenido, como el estado y las métricas, en un sistema estandarizado, lo que ahorra tiempo y evita la duplicación de esfuerzos.
La plantilla de base de datos para blogs de ClickUp es tu herramienta imprescindible para gestionar de forma eficiente el contenido de tu blog. A diferencia de otras hojas de cálculo de Excel para la gestión de proyectos, es muy intuitiva y te ayuda a organizar las publicaciones, agilizar la creación y realizar el seguimiento del progreso desde el borrador hasta la publicación.

Puede utilizar esta plantilla para:
- Clasifique y subclasifique las entradas del blog para facilitar el acceso y la recuperación.
- Supervise el estado de cada publicación, desde su concepción hasta su publicación, con estados personalizados.
- Utilice múltiples vistas, como Tabla, Seguimiento de estado y Hub de bases de datos, para visualizar los datos.
- Utilice listas de control y campos prellenados para agilizar el proceso de creación de entradas de blog.
- Analice el rendimiento del blog y gestione los análisis para optimizar la estrategia de contenido.
Con el control de tiempo integrado, las etiquetas y las advertencias de dependencia, gestionar el contenido de tu blog nunca ha sido tan fácil.
Construya una base sólida con bases de datos relacionales.
Un sistema de gestión de bases de datos relacionales es más que una simple herramienta para un administrador de bases de datos: es la columna vertebral de una gestión de datos escalable y eficiente. Dominar las complejidades de las tablas, las claves primarias y externas, y las relaciones entre bases de datos le permite diseñar sistemas robustos y flexibles.
Aprovechando estos principios y ClickUp, puede mejorar la integridad de los datos, optimizar el acceso e impulsar soluciones innovadoras.
¿Está listo para mejorar su gestión de datos? ¡Regístrese hoy mismo en ClickUp y descubra cómo puede transformar la gestión de su base de datos relacional y su productividad!