![[年]に自社データでGeminiをトレーニングする方法](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

最近の企業調査によると、73%の組織がAIモデルが自社固有の用語や文脈を理解できず、多大な手動修正を必要とする出力を生み出していると報告しています。これはAI導入における最大の課題の一つとなっています。
Google Geminiのような大規模言語モデルは、既に膨大な公開データセットで学習済みです。多くの企業が真に必要としているのは、新たなモデルを学習させることではなく、Geminiに自社のビジネス環境を教えることです。つまり、自社の文書、ワークフロー、顧客、内部知識を教えることです。
このガイドでは、GoogleのGeminiモデルを自社データでトレーニングする全プロセスを解説します。データセットを正しいJSONLフォーマットで準備する方法から、Google AI Studioでのチューニングジョブの実行まで、すべてを網羅します。
また、AIコンテキストを組み込んだ統合ワークスペースが、数週間ものセットアップ時間を削減できる可能性についても検証します。
Geminiの微調整とは何か?なぜ重要なのか?
Geminiのファインチューニングとは、Googleの基盤モデルを自社データでトレーニングするプロセスです。
自社ビジネスを理解するAIを求めているのに、既成モデルは的を外した汎用的な応答しか返しません。その結果、出力の修正に時間を浪費し、自社の専門用語を繰り返し説明し、AIが理解できないことに苛立ちを覚える日々が続くのです。
この絶え間ない行き来はチームの作業を遅らせ、AIが約束する生産性向上を損ないます。
Geminiの微調整により、特定のパターン、トーン、ドメイン知識を学習したカスタムGeminiモデルが生成されます。これにより、独自のユースケースに対してより正確に応答できるようになります。この手法は、ベースモデルが繰り返し失敗する一貫性のある反復可能なタスクに最適です。
ファインチューニングとプロンプトエンジニアリングの違い
プロンプトエンジニアリングとは、モデルと対話するたびに一時的なセッションベースの指示を与えることです。会話が終了すると、モデルはコンテキストを忘れます。
この手法には限界があります。ベースモデルが持たない専門知識が必要なユースケースでは、一定の指示を与えるだけでは不十分です。最終的にはモデルに実際のパターンを学習させる必要があります。
一方、ファインチューニングはトレーニング例に基づいてモデルの内部重みを変更することで、その挙動を恒久的に調整します。そのため、変更は将来のすべてのセッションに持続的に反映されます。
微調整は、AIの偶発的な問題に対する即効薬ではありません。時間とデータへの大きな投資です。ベースモデルが一貫して不十分で恒久的な解決策が必要な特定のシナリオにおいて、最も意味をなす手法です。
AIに以下のスキルを習得させたい場合に微調整を検討してください:
- 専門用語:御社の業界では、モデルが一貫して誤解釈したり正しく使用できなかったりする専門用語が使われています
- 一貫したフォーマット: レポート作成やコードスニペットの生成など、毎回非常に特定の構造で応答を得る必要があります
- 専門知識の不足: モデルは貴社のニッチ製品、内部プロセス、独自のワークフローに関する知識を欠いています
- ブランドボイス:AIが生成するすべての出力が、御社のブランドボイス、スタイル、パーソナリティに完全に一致することを望んでいます
| アスペクト | プロンプトエンジニアリング | 微調整 |
| 概要 | モデルの挙動を導くため、プロンプト内の指示をより効果的に作成する | 自社事例を用いたモデルの追加トレーニング |
| 変更点 | モデルに送信する入力データ | モデルの内部重み |
| 実装までのスピード | 即時 — 瞬時に動作します | 遅い — データセットの準備とトレーニング時間が必要 |
| 技術的な複雑さ | 低 — 機械学習の専門知識は不要 | 中~高レベル — MLパイプラインが必要 |
| 必要なデータ | プロンプト内の優れた例をいくつか | 数百から数千のラベル付き例 |
| 出力の一貫性 | Medium — プロンプトによって異なります | 高 — 行動特性がモデルに組み込まれている |
| 最適: | 単発タスク、実験、迅速な反復 | 一貫した出力を必要とする反復的なタスク |
プロンプトエンジニアリングはモデルへの指示内容を形作り、ファインチューニングはモデルの思考方法を形作ります。
本記事はGeminiに焦点を当てていますが、AIカスタマイズの代替アプローチを理解することは、同様の目標を達成するための異なる手法について貴重な視点を提供します。
このビデオでは、特定のユースケース向けにAIをカスタマイズするもう一つの人気手法であるカスタムGPTの作成方法を実演します:
📖 こちらもご覧ください:プロンプトエンジニアになる方法
Geminiのトレーニングデータ準備方法
ほとんどの微調整プロジェクトは、チームがデータ準備プロセスを過小評価するため、開始前に失敗します。ガートナーは、AI対応データの不足によりAIプロジェクトの60%が放棄されると予測しています。
データの収集やフォーマットを誤ると、数週間を費やした末にトレーニングが失敗したり、役に立たないモデルが生成されたりする可能性があります。これはプロセス全体で最も時間がかかる部分ですが、正しく行うことが成功の最も重要な要素です。
「ゴミを入れればゴミが出る」という原則がここに強く当てはまります。カスタムモデルの品質は、トレーニングに使用するデータの品質を直接反映します。
データセットのフォーマット要件
Geminiは、トレーニングデータをJSONL(JSON Lines)と呼ばれる特定のフォーマットで要求します。JSONLファイルでは、各行が1つのトレーニング例を表す完全な独立したJSONオブジェクトとなります。この構造により、システムは大規模なデータセットを1行ずつ処理しやすくなります。
各トレーニング例には以下の2つの主要フィールドを含める必要があります:
- text_input: モデルに投げかけるプロンプトまたは質問です
- 出力: モデルに学習させたい理想的な完璧な応答です
利便性のため、Google AI StudioではCSVフォーマットのアップロードも受け付け、必要なJSONL構造へ自動的に変換します。
チームがスプレッドシートでの仕事に慣れている場合、初期のデータエントリーが少し楽になる可能性があります。
データセットのサイズの推奨事項
質は量よりも重要ですが、モデルがパターンを認識・学習するには最低限の例数が必要です。例数が少なすぎると、モデルは汎化できず、信頼性の高い性能を発揮できません。
データセットのサイズに関する一般的なガイドラインは以下の通りです:
- 最小限の実用性: 単純で非常に特化したタスクの場合、約100~500の高品質な例で結果が出始めます
- より良い結果を得るには:より複雑またはニュアンスのある出力を目指す場合、500~1,000例を目標とすることで、より堅牢で信頼性の高いモデルが得られます
- 限界効用の逓減:ある時点を超えると、単純に反復的なデータを追加しても性能は大きく向上しません。量よりも多様性と質に焦点を当てましょう。
数百もの高品質な例を収集することは、ほとんどのチームにとって大きな課題です。微調整プロセスに着手する前に、このデータ収集フェーズを適切にプランニングしてください。
📮 ClickUpインサイト:平均的なビジネスパーソンは、仕事関連の情報を検索するのに1日30分以上を費やしています。これは電子メールやSlackのスレッド、散らばったファイルを掘り起こすために年間120時間以上を浪費していることを意味します。
ワークスペースに組み込まれた知能型AIアシスタントがそれを変えます。ClickUp Brainの登場です。適切な文書、会話、タスク詳細を瞬時に提示し、即座に洞察と回答を提供します。検索を止め、作業を始めましょう。
💫 実証済み結果:QubicaAMFのようなチームは、時代遅れのナレッジ管理プロセスを排除することで、ClickUpを活用し週5時間以上(年間1人あたり250時間以上)の時間を創出しました。四半期ごとに1週間分の生産性が追加されたら、あなたのチームが何を創造できるか想像してみてください!
データ品質のベストプラクティス
矛盾した例や不整合な例はモデルを混乱させ、信頼性の低い予測不能な出力を引き起こします。これを防ぐには、トレーニングデータを細心の注意を払って選別・整理する必要があります。たった1つの不良例が、多くの良質な例から得た学習効果を台無しにすることがあります。
データ品質を高く保つためのガイドラインに従ってください:
- 一貫性: 全ての例は同じフォーマット、スタイル、トーンに従う必要があります。AIにフォーマルな表現を求めたい場合は、出力例も全てフォーマルな表現で統一してください。
- 多様性: データセットは、モデルが実運用で遭遇する可能性のある入力の全範囲を網羅している必要があります。簡単なケースだけでトレーニングしてはいけません。
- 正確性:出力される例は一つ残らず完璧でなければなりません。モデルに生成させたい正確な応答であり、エラーやタイプミスが一切ない状態であるべきです。
- データの品質管理: トレーニング前に、重複する例を削除し、すべてのスペルミスや文法ミスを修正し、データ内の矛盾を解決する必要があります。
トレーニング例を複数人でレビューし検証することを強く推奨します。新たな視点は、見落としがちなエラーや矛盾をしばしば発見できます。
Geminiの微調整をステップごとに行う方法
Geminiの微調整プロセスには、Googleのプラットフォームを跨ぐ複数の技術的ステップが含まれます。設定エラー一つで貴重なトレーニング時間やコンピューティングリソースを無駄にし、最初からやり直す羽目になる可能性があります。この実践的な手順書は、そうした試行錯誤を減らすために設計されており、プロセスを最初から最後までガイドします。🛠️
開始前に、課金機能が有効化されたGoogle CloudアカウントとGoogleAI Studioへのアクセス権が必要です。セットアップと最初のトレーニングジョブには少なくとも数時間を確保し、モデルのテストと反復作業には追加の時間を見込んでください。
ステップ1: Google AI Studioの設定
Google AI Studioは、ファインチューニングプロセス全体を管理するウェブベースのインターフェースです。コードを書かずにデータをアップロードし、トレーニングを設定し、カスタムモデルをテストするユーザーフレンドリーな方法を提供します。
まず、ai.google.devにアクセスし、Google アカウントでサインインしてください。
Google Cloud Consoleで利用規約に同意し、新規プロジェクトを作成する必要があります(未作成の場合)。プラットフォームのプロンプトに従い、必要なAPIを必ず有効化してください。
ステップ2: トレーニング用データセットをアップロードする
設定が完了したら、Google AI Studio内のチューニングセクションに移動してください。ここでカスタムモデル作成のプロセスを開始します。
「調整済みモデルを作成」オプションを選択し、ベースモデルを選んでください。Gemini 1.5 Flashは、ファインチューニングに広く採用され、費用対効果の高い選択肢です。
次に、準備したトレーニングデータセットを含むJSONLまたはCSVファイルをアップロードします。プラットフォームはファイルを検証し、フォーマット要件を満たしていることを確認します。フィールドの欠落や不適切な構造など、よくあるエラーがあればフラグを立てます。
ステップ3: ファインチューニング設定の構成
データのアップロードと検証が完了したら、トレーニングパラメーターを設定します。これらの設定(ハイパーパラメーターと呼ばれる)は、モデルがデータから学習する方法を制御します。
主な設定項目は以下の通りです:
- エポック数: これはモデルがデータセット全体で学習する回数を決定します。エポック数を増やすと学習効果が高まる可能性がありますが、過学習のリスクも伴います。
- 学習率: 学習例に基づいてモデルが重みを調整する速度を制御します
- バッチサイズ: 1つのグループでまとめて処理するトレーニング例の数
初めての試みでは、Google AI Studioが推奨するデフォルト設定から始めるのが最適です。このプラットフォームは複雑な判断を簡素化し、機械学習の専門家でなくても利用できるようにしています。
ステップ4: チューニングジョブを実行する
設定が完了したら、チューニングジョブを開始できます。Googleのサーバーがデータの処理を開始し、モデルのパラメーターを調整します。このトレーニングプロセスには、データセットのサイズや選択したモデルに応じて、数分から数時間かかる場合があります。
ジョブの進捗状況はGoogle AI Studioダッシュボード内で直接確認できます。ジョブはGoogleのサーバー上で実行されるため、ブラウザを安全に閉じて後でステータスを確認することも可能です。ジョブが失敗する場合、その原因はほぼ確実にトレーニングデータの品質やフォーマットの問題にあります。
ステップ5:カスタムモデルのテスト
トレーニングジョブが完了したら、カスタムモデルのテスト準備が整います。✨
Google AI Studioのプレイグラウンドインターフェースからアクセスできます。
まず、トレーニング例と類似したテストプロンプトを送信し、精度を確認します。次に、これまで遭遇したことのないエッジケースや新たなバリエーションでテストし、汎化能力を評価します。
- 精度: トレーニングした通りの正確な出力を生成していますか?
- 汎化能力: トレーニングデータと類似しているが同一ではない新しい入力に対して、正しく処理できますか?
- 一貫性:同じプロンプトで複数回試行した場合、その応答は信頼性が高く予測可能ですか?
結果が満足のいくものでない場合、おそらく戻って、より多くの例を追加したり矛盾を修正したりしてトレーニングデータを改善し、モデルを再トレーニングする必要があるでしょう。
📖 こちらもご覧ください:革新と効率化のためにAIを最大限活用する方法
カスタムデータでGeminiをトレーニングするためのベストプラクティス
技術的なステップを単に踏むだけでは優れたモデルは保証されません。多くのチームはプロセスを完了しても、経験豊富な実践者が用いる最適化戦略を見逃すため、結果に失望します。これが機能するモデルと高性能なモデルを分ける要因です。
当然ながら、デロイトの「企業における生成AIの現状」レポートによると、企業の3分の2が、自社で行っている生成AI実験の30%以下しか6か月以内に完全な規模拡大に至らないと報告している。
これらのベストプラクティスを採用することで、時間を節約し、はるかに優れた結果を得られます。
- 小規模から始めて、スケールアップ: フルトレーニングを実行する前に、データの一部(例:100件のサンプル)でアプローチをテストしましょう。これにより、フォーマットの検証やパフォーマンスの簡易評価が可能となり、時間を無駄にせずに済みます。
- データセットのバージョン管理: トレーニング例を追加、削除、編集する際は、データセットの各バージョンを保存してください。これにより変更の追跡、結果の再現が可能となり、新しいバージョンが性能を低下させた場合に以前のバージョンへロールバックできます。
- 調整前後のテスト: ファインチューニングを開始する前に、主要タスクにおけるベースモデルの性能を評価し、基準値を設定してください。これにより、ファインチューニングの努力による改善効果を客観的に測定できます。
- 失敗から学ぶ:カスタムモデルが誤った回答や不適切なフォーマットの回答を生成した場合、ただイライラするだけではいけません。その特定の失敗事例を修正済み例としてトレーニングデータに追加し、次の反復学習に活用しましょう。
- プロセスを文書化する:各トレーニング実行のログを記録し、使用したデータセットのバージョン、ハイパーパラメータ、結果をメモしてください。この文書化は、時間の経過とともに何が機能し何が機能しないかを理解する上で非常に貴重です。
これらの反復作業、データセットのバージョン管理、ドキュメント管理には、堅牢なプロジェクト管理が必要です。構造化されたワークフロー向けに設計されたプラットフォームでこれらの仕事を一元化することで、プロセスが混乱するのを防げます。
Geminiのトレーニングにおける一般的な課題
チームは微調整に多大な時間とリソースを費やすことが多く、結局は予測可能な障害に直面し、努力が無駄になりフラストレーションが溜まります。こうしたよくある落とし穴を事前に把握することで、プロセスをよりスムーズに進めることができます。
以下に、よくある課題とその対処法をご紹介します:
- 過学習(オーバーフィッティング): モデルが学習例を完璧に記憶する一方で、新規の未見入力への汎化に失敗する現象です。これを修正するには、学習データに多様性を追加する、エポック数を減らす、検索拡張生成(Retrieval-Augmented Generation)などの代替手法を検討するなどの方法があります。
- 出力の不一致: 非常に類似した質問に対してモデルが異なる回答を返す場合、トレーニングデータに矛盾や不一致のある例が含まれている可能性があります。こうした矛盾を解消するには、徹底的なデータクリーニングが必要です。
- フォーマットドリフト: モデルは当初、望ましい出力構造に従っていても、時間の経過とともにそこから「ドリフト」することがあります。解決策は、トレーニング例の出力にコンテンツだけでなく、明示的なフォーマット指示を含めることです。
- 遅い反復サイクル: トレーニングの実行に数時間かかる場合、実験や改善のスピードが大幅に低下します。本格的なトレーニングジョブを実行する前に、まず小規模なデータセットでアイデアをテストし、迅速なフィードバックを得ましょう。
- データ収集のボトルネック: 多くの場合、最も困難なのは、十分な高品質な例を収集するという単純なデータ収集のボトルネックです。既存の優れたコンテンツ(サポートチケット、マーケティングコピー、技術ドキュメントなど)を活用することから始め、そこから範囲を広げていきましょう。
これらの課題こそが、多くのチームが最終的に手動での微調整プロセスに代わる手段を求める主な理由です。
📮ClickUpインサイト: アンケート回答者の88%が個人タスクにAIを活用している一方、50%以上が仕事での使用を避けています。 主な障壁は?シームレスな統合の欠如、知識のギャップ、セキュリティ懸念の3点です。しかし、AIがワークスペースに組み込まれており、既に安全性が確保されているとしたら?ClickUp Brain(ClickUp内蔵AIアシスタント)がこれを実現します。平易な言語でのプロンプトを理解し、AI導入の3つの懸念を解決しながら、チャット・タスク・ドキュメント・ナレッジをワークスペース全体で接続。ワンクリックで答えと洞察を見つけられます!
ClickUpがより賢い選択肢である理由
Geminiの微調整は強力ですが、それはあくまで回避策です。
本記事を通じて、ファインチューニングの本質は「AIに自社のビジネス環境を理解させること」であることが明らかになりました。問題は、ファインチューニングがこれを間接的に行う点です。データセットの準備、事例のエンジニアリング、モデルの再学習、パイプラインの維持管理——これら全ては、AIが自社のチーム運営方法を近似できるようにするために行われるのです。
これは特殊なユースケースでは理にかなっています。しかし、ほとんどのチームにとって真の目標は、Geminiのパーソナライゼーションそのものではありません。目標はもっとシンプルです:
仕事を理解するAIを求めている
ここでClickUpは根本的に異なる、そしてよりスマートなアプローチを取ります。
ClickUpの統合型AIワークスペースは、チームの仕事状況を瞬時に理解するAIを提供します。面倒な設定は不要です。後から文脈を学習させるAIをトレーニングする代わりに、統合型AIアシスタント「ClickUp Brain」を活用しましょう。そこには既にあなたの文脈が組み込まれています。
タスク、ドキュメント、コメント、プロジェクト履歴、意思決定がネイティブに接続されています。AIを自社データでトレーニングする必要はありません。AIは既に仕事が行われる場所に存在し、既存のナレッジマネジメントエコシステムを活用しているからです。
| アスペクト | Geminiの微調整 | ClickUp Brain |
|---|---|---|
| セットアップ時間 | データ準備に要する日数~数週間 | 即時対応—既存のワークスペースデータで動作します |
| コンテキストソース | 手動で精選したトレーニング用例 | 接続されたすべての仕事への自動アクセス |
| メンテナンス | ニーズの変化に応じて再トレーニングを実施 | ワークスペースの進化に合わせて継続的に更新されます |
| 技術的スキルが必要 | 中~高 | None |
ClickUpが業務基盤であるため、ClickUp Brainは接続されたデータグラフ内で動作します。断片化されたツールにAIが拡散することもなく、脆弱なトレーニングパイプラインも存在せず、モデルがチームの実際の業務方法と同期を失うリスクもありません。
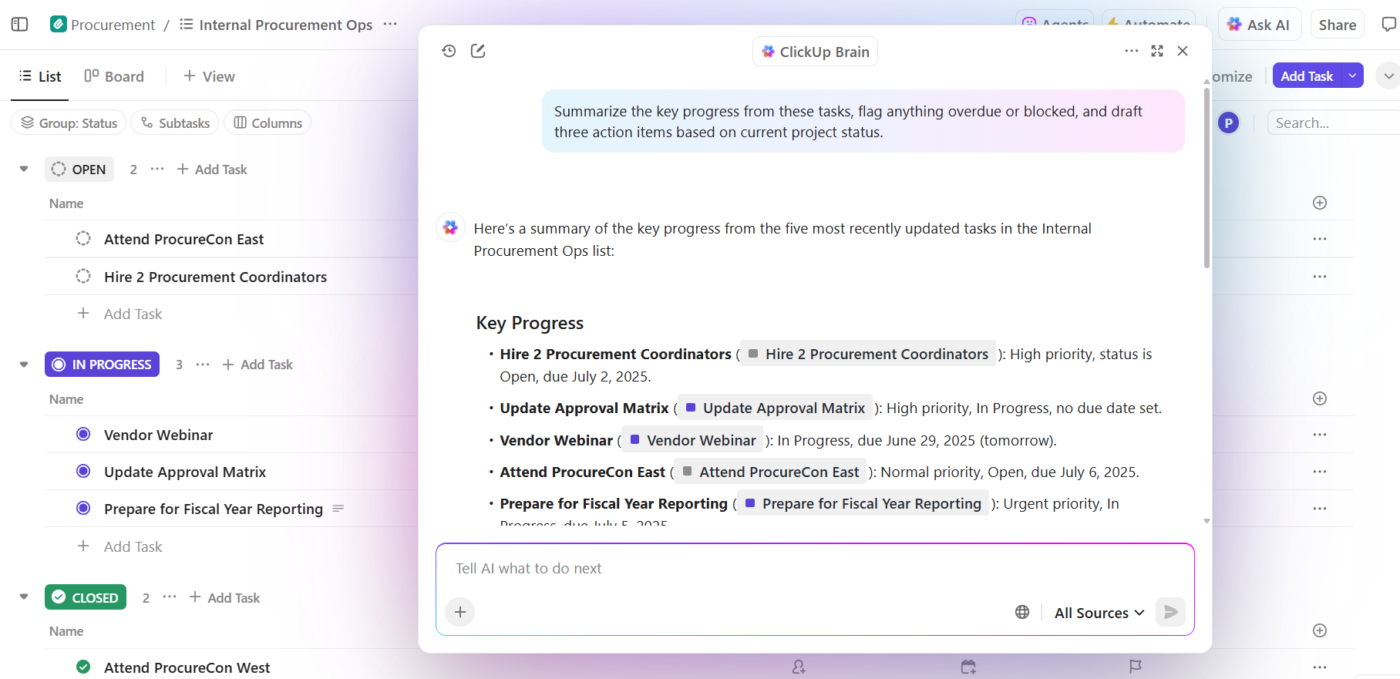
実際の運用では次のような流れになります:
- プロジェクトに関する質問を投げかけよう:ClickUp Brainはタスク・ドキュメント・コメント・更新情報を横断検索し、汎用的なトレーニング知識ではなく実際のプロジェクトデータを用いて質問に回答します
- 文脈に沿ったコンテンツ生成:ClickUp Brainは既にタスク、ファイル、コメント、プロジェクト履歴への安全なアクセス権を有しています。実際の業務内容、タイムライン、優先度を参照したドキュメント、要約、ステータス報告を作成可能です。アプリやファイルをまたいで情報を探すのにチームが時間を浪費する「文脈の拡散」は終わりです。
- 理解に基づく自動化:ClickUp Automationsを使えば、期限や所有権、ステータス変更といったプロジェクトの文脈に知的に反応する自動化を構築できます。単なる静的なルールに縛られません。AIがコード不要でこれらを構築することも可能です。
💡プロの秘訣:ClickUp Super Agentsを活用し、ワークスペースでAIの真の力を引き出しましょう。
スーパーエージェントは、ClickUpのAI搭載型チームメイトです。ワークスペース内でチームと共に働くAI「ユーザー」として設定されます。周囲の状況や文脈を把握し、タスクの割り当て、コメントでのメンション、イベントやスケジュールによるトリガー、チャットでの指示など、人間のチームメイトと同様に活用できます。
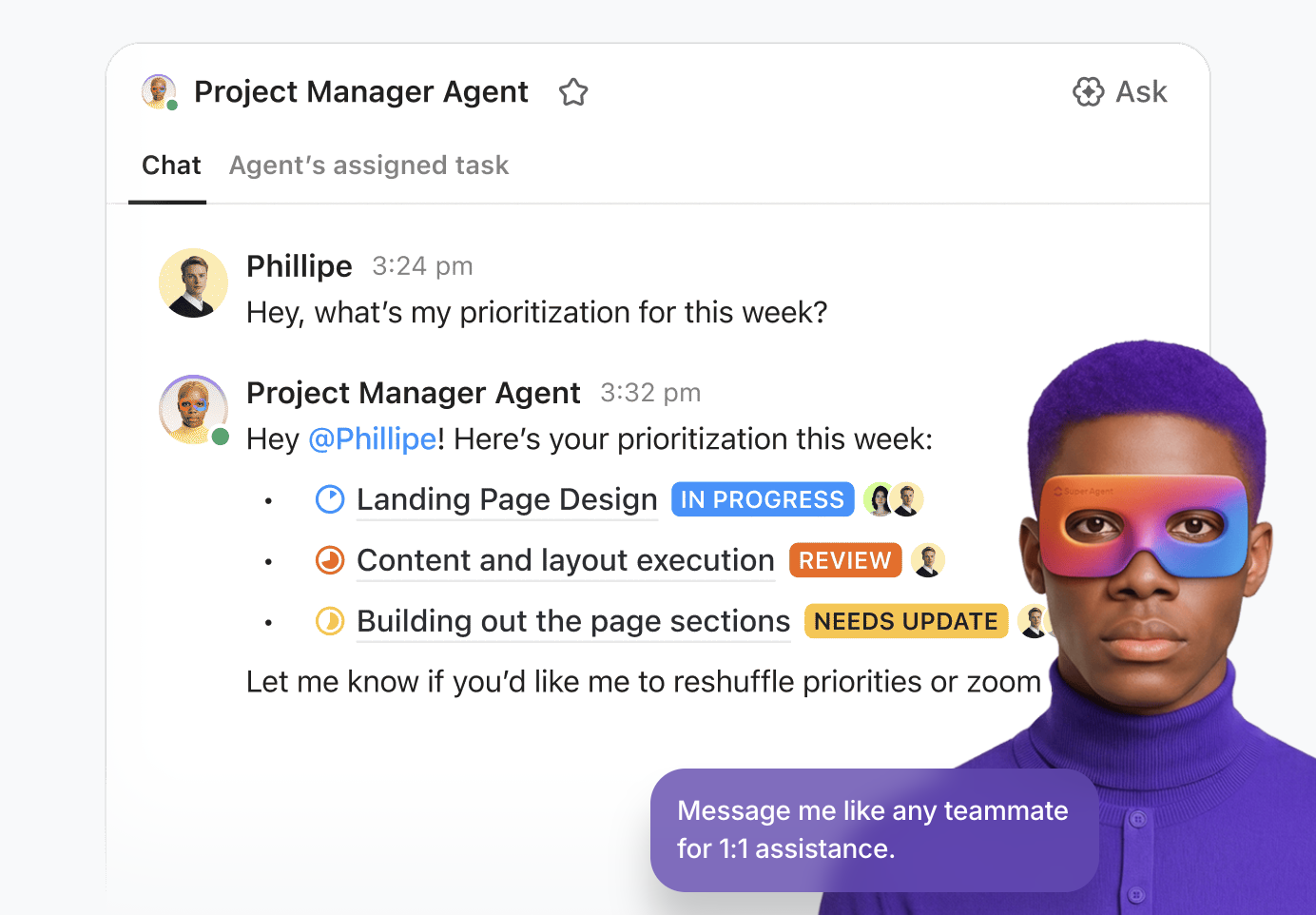
ノーコードのビジュアルビルダーを使用して構築・デプロイでき、以下の操作が可能です:
- 開始イベント(例:メッセージやタスクステータスの変化)を特定する
- 運用ルールを定義します。これにはデータの要約方法、仕事の委任方法、優先度の調整方法などが含まれます。
- 統合ツールや拡張機能を通じて外部アクションを実行
- エージェントを関連するナレッジベースに接続し、サポートデータを提供してください
スーパーエージェントの詳細はこちらのビデオをご覧ください。
AI戦略を微調整:ClickUpを導入
ファインチューニングは静的な例を通じてAIにパターンを教えますが、ClickUpのようなワークスペースで統合ソフトウェアを使用すれば、AIにリアルタイムで自動的なコンテキストを提供することで、コンテキストの拡散を防ぎます。
これがAI変革を成功させる核心です:連携プラットフォームで業務を集中管理するチームは、AIのトレーニングに費やす時間を削減し、その恩恵を享受する時間を増やせます。ワークスペースが進化するにつれ、AIも自動的に進化します——再トレーニングのサイクルは不要です。
トレーニングをスキップして、仕事を既に理解したAIをすぐに活用したいですか?ClickUpで無料で始め、統合ワークスペースのメリットを体験してください。
よくある質問(FAQ)
微調整したモデルはトレーニング例から学習しますが、GoogleのベースGeminiモデルはデフォルトで会話データを保持せず、そこから学習しません。カスタムモデルは他のユーザーに提供される基盤モデルとは別個に扱われます。
トレーニング作業自体は数時間で完了する場合もありますが、より多くの時間を要するのは高品質なトレーニングデータの準備です。このデータ準備フェーズは、適切に完了させるために数日から数週間かかることがよくあります。
はい、Google AI Studioを使用すればコードを書かずにモデルの微調整が可能です。技術的な複雑さのほとんどを処理するビジュアルインターフェースを提供しますが、データのフォーマット要件を理解する必要は依然としてあります。
カスタム指示は一時的なセッションベースのプロンプトであり、単一の会話におけるモデルの挙動を導きます。一方、ファインチューニングはトレーニング例に基づいてモデルの内部パラメーターを恒久的に調整し、その挙動に永続的な変化をもたらします。