
Du har ägnat timmar åt att utforma den ”perfekta” prompten. Du har visionen, modellen och potentialen för en enorm produktivitetsvinst. Men en liten justering får ditt resultat att spåra ur. Utan ett standardiserat sätt att betygsätta resultaten kan du inte avgöra om din AI faktiskt förbättras eller bara förändras.
Enligt Whartons Prompting Science Report kan faktiskt en enkel omformulering av en prompt påverka prestandan med upp till 60 procentenheter.
Den här guiden visar dig de bästa mallarna för prestandajämförelser av prompter i ClickUp. Dessa är dina återanvändbara mallar för att betygsätta resultat, spåra varje iteration och slutligen koppla dina utvärderingsdata till arbetet i din arbetsyta. ✨
Översikt över mallar för prestandajämförelser
Här är en snabb översikt över de mallar för prestandajämförelser av prompter som behandlas i den här guiden och den del av utvärderingsflödet som var och en stöder 👇
| Mall | Länk för nedladdning | Perfekt för | Viktiga funktioner |
|---|---|---|---|
| Mall för jämförelseanalys från ClickUp | Hämta gratis mall | Jämföra promptvarianter och betygsätta resultat | Visuell jämförelsetavla, betygsättningsfält, analys med flera vyer |
| Mall för experimentplan och resultat från ClickUp | Hämta gratis mall | Genomföra strukturerade prompt-experiment | Hypotesuppföljning, loggning av testuppsättningar, dokumentation av resultat |
| Mall för testhantering från ClickUp | Hämta gratis mall | Hantera storskaliga utvärderingsarbetsflöden | Spårning av testfall, exekveringsstatus, automatiseringsutlösare |
| Testfallmall från ClickUp | Hämta gratis mall | Dokumentera detaljerade fel i prompter | Logga in- och utdata, jämföra förväntat mot faktiskt resultat, spåra godkänd/underkänd |
| Mall för prestationsrapport från ClickUp | Hämta gratis mall | Kommunicera benchmarkresultat till intressenter | Sammanfattningar, datavisualisering, rekommendationsavsnitt |
| Mall för aktivitetsrapport från ClickUp | Hämta gratis mall | Spåra utvärderingsförlopp och arbetsbelastning | Aktivitetsloggar, tidsbaserad filtrering, insyn i arbetsbelastningen |
| Mall för balanserade styrkort från ClickUp | Hämta gratis mall | Anpassa prompternas prestanda till affärsmålen | Flerdimensionell poängsättning, viktade mått, strategikartläggning |
| Mall för projektutvärdering från ClickUp | Hämta gratis mall | Förbättra benchmarkingprocesserna över tid | Processutvärdering, lärdomar, riskuppföljning |
| Mall för heuristisk granskning av ClickUp | Hämta gratis mall | Genomföra kvalitativa utvärderingar av AI-resultat | Heuristiska kategorier, allvarlighetsgrader, insamling av expertfeedback |
| Mall för företagets OKR och mål från ClickUp | Hämta gratis mall | Koppla jämförelseresultat till strategiska mål | OKR-hierarki, framstegsspårning, synlighet mellan team |
🧠 Kul fakta: ”Benchmark” har inte sitt ursprung i mjukvaru- eller produktteam. Ursprungligen betydde det en lantmätares referenspunkt på 1800-talet, långt innan det blev standarden för att mäta allt från webbplatsexperiment till prestanda för prompter.
Vad är en mall för prestandajämförelse?
En mall för prestandajämförelse av prompter är ett ramverk för att utvärdera, jämföra och betygsätta resultat från AI-prompter. Den används för att mäta om en AI-prompt faktiskt fungerar eller om den i tysthet blir sämre för varje modelluppdatering.
Se det som en standardiserad experimentuppställning:
- Det definierar vad du testar
- Hur du mäter framgång
- Vilka indata du kör
- Hur du registrerar resultat
👀 Visste du att? Ett av de mest kända experimenten inom statistik började med en debatt om huruvida mjölk eller te skulle hällas i först. Ronald Fisher förvandlade den lilla meningsskiljaktigheten till ett formellt test med slumpmässigt utvalda koppar, och det blev en av de klassiska berättelserna bakom modern experimentell design.
Vad kännetecknar en bra mall för prestandajämförelse av prompter
En bra promptmall måste klara vissa specifika uppgifter väl, annars kommer den att samla damm efter den första sprinten:
- Standardiserade utvärderingskriterier: Definiera dimensioner som noggrannhet, relevans, ton och hallucinationsfrekvens innan någon börjar testa. Utan fördefinierade bedömningskriterier betygsätter varje granskare på olika sätt, och resultaten blir ojämförbara
- Versionsspårning: Varje benchmark-körning måste kopplas till en specifik promptversion, modell och uppsättning parametrar så att du kan spåra vad som har ändrats och varför
- Både numerisk och kvalitativ bedömning: Ett faktamässigt korrekt svar kan fortfarande låta robotlikt. De bästa mallarna kombinerar numeriska betyg med strukturerade skriftliga kommentarer, sida vid sida
- Jämförelselätt struktur: Du ska kunna placera två promptversioner bredvid varandra och se skillnaderna direkt
- Användbar information: En jämförelse som slutar med ”betyg: 7/10” är ofullständig. Utvärderarna måste notera varför betyget hamnade där det gjorde och vad som behöver ändras härnäst
- Kopplat till arbetet: Benchmarkresultat i ett isolerat system förlorar snabbt sitt sammanhang. Mallen fungerar bäst när den är kopplad till de uppgifter och arbetsflöden där utvecklingen av prompter faktiskt sker
📮ClickUp Insight: 92 % av kunskapsarbetare riskerar att förlora viktiga beslut som är utspridda över chatt, e-post och kalkylblad. Utan ett enhetligt system för att registrera och spåra beslut går kritiska affärsinsikter förlorade i det digitala bruset. Med ClickUps funktioner för uppgiftshantering behöver du aldrig oroa dig för detta. Skapa uppgifter från chatt, uppgiftskommentarer, dokument och e-postmeddelanden med ett enda klick!
📮ClickUp Insight: 92 % av kunskapsarbetare riskerar att förlora viktiga beslut som är utspridda i chattar, e-postmeddelanden och kalkylblad. Utan ett enhetligt system för att registrera och spåra beslut går kritiska affärsinsikter förlorade i det digitala bruset. Med ClickUps funktioner för uppgiftshantering behöver du aldrig oroa dig för detta. Skapa uppgifter från chattar, uppgiftskommentarer, dokument och e-postmeddelanden med ett enda klick!
10 mallar för prestandajämförelser för ditt team
Varje mall nedan tar upp olika aspekter av prestandajämförelser för prompter – från detaljerade testfall till strategisk rapportering. Vissa är specialutformade för jämförelser, medan andra är anpassningsbara ramverk som uppmuntrar teknikteam att återanvända dem för utvärderingsarbetsflöden.
Låt oss ta en titt:
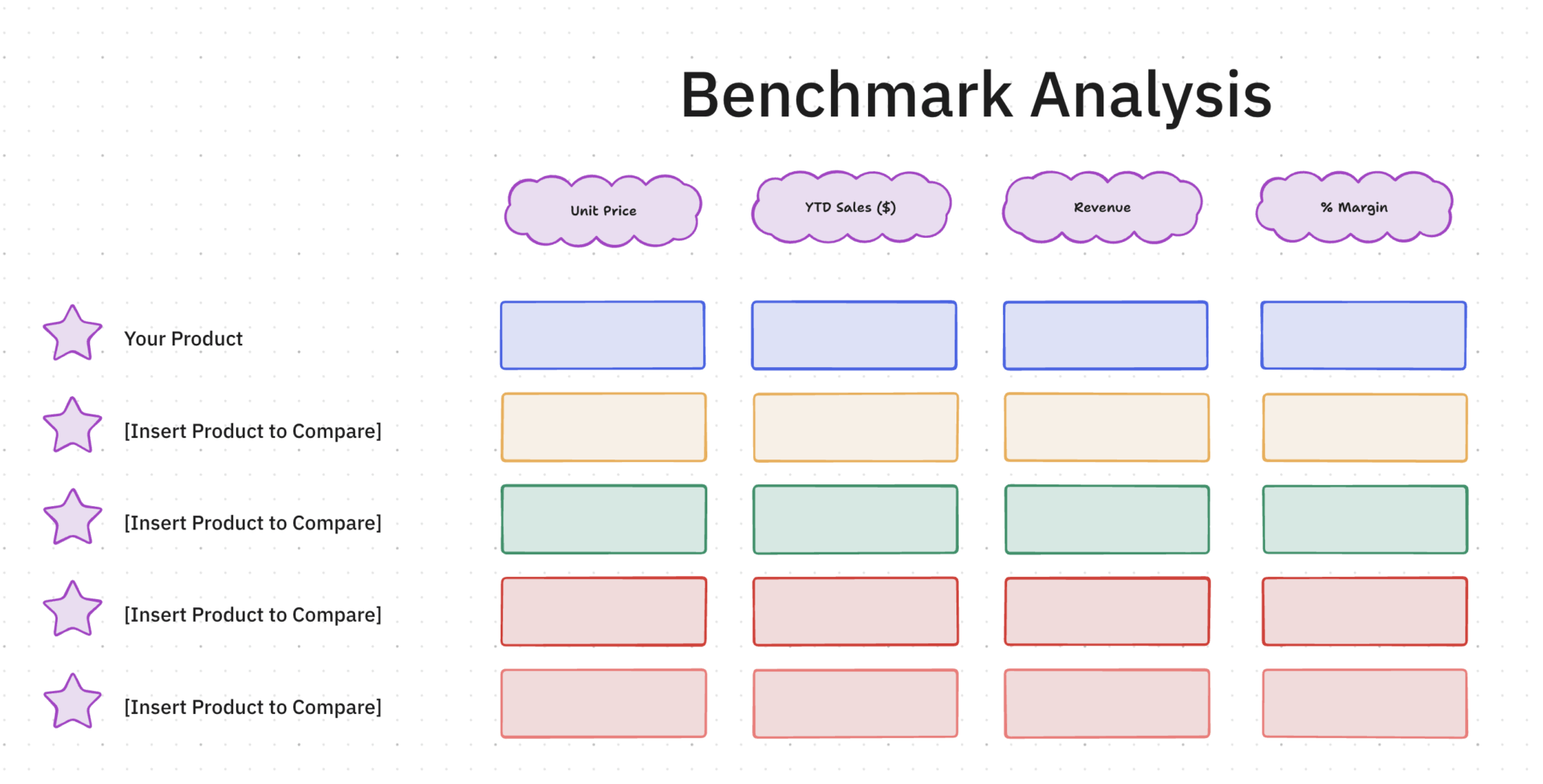
1. Mall för jämförelseanalys från ClickUp™
Att utvärdera prestanda blir oftast en subjektiv röra utan en fast referenspunkt för jämförelse. Om du bara läser igenom resultaten kommer du aldrig att veta vilken logisk justering som rättade till en hallucination eller förbättrade ett svar.
Mallen för jämförelseanalys från ClickUp™ fungerar som ett visuellt utvärderingslaboratorium på en ClickUp-whiteboard. Den låter dig plotta promptvarianter, bedömningskriterier och modellresultat på en enda oändlig arbetsyta så att du kan upptäcka mönster i modelllogiken som en vanlig listvy skulle dölja.
✨ Varför du kommer att älska den här mallen
- Anpassade bedömningsfält: Koppla varje utvärderingsdimension (faktamässig noggrannhet, svarets längd och frekvensen av hallucinationer) till ett särskilt anpassat fält i ClickUp
- Flera vyer: Växla mellan ClickUp-tabellvyn för jämförelse av rådata, ClickUp-tavlavyn för statusbaserad spårning (Väntar på granskning → Utvärderad → Behöver iteration) och över 15 anpassningsbara ClickUp-vyer
- Historisk spårning: Varje benchmark-körning är en uppgift med fullständig historik, så du kan bläddra tillbaka genom tidigare utvärderingar utan att behöva leta igenom kalkylblad med versionsnamn
✅ Perfekt för: AI-forskare och promptingenjörer som samordnar rigorösa A/B-tester över flera modellvarianter, produktionslogik och användningsfall med känslig data.
⚡️ Vill du ha fler mallar för jämförelseanalys att välja mellan? Vi har sammanställt en lista åt dig här: Gratis mallar för jämförelseanalys för team
2. Mall för experimentplan och resultat från ClickUp

Hur jämför man en prompt utan att förvanska förutsättningarna bakom dess prestanda? Mallen för experimentplan och resultat från ClickUp ger övningen metodologisk stringens. I denna mall inleds varje promptförsök med en angiven hypotes, en testuppställning och en logg över vad som förändrats mellan körningarna.
När resultaten kommer in omvandlar mallen spridda observationer till en beviskedja. Promptvarianter, jämförelsekriterier och anteckningar om resultat förblir kopplade till samma arbetsflöde, vilket ger ditt team en tydligare bild av prestandan.
✨ Varför du kommer att älska den här mallen
- Standardisera inlämningen av jämförelser: Använd ClickUp Forms för att samla in varje promptvariant, testmål, bedömningskriterier och gränsfallsscenarier i ett enhetligt intagsflöde innan utvärderingen påbörjas
- Gör varje promptkörning till ett ansvarigt arbete: Använd ClickUp-uppgifter för att tilldela ansvariga, ställa in granskningssteg, spåra beroenden och se till att varje benchmarkcykel följer en tydlig genomförandebana
- Bevara logiken bakom varje resultat: Dokumentera hypotesen, testförhållandena och de slutliga observationerna i en enda experimentrapport
✅ Perfekt för: Innehålls- eller supportansvariga som vill bygga upp ett mer tillförlitligt bibliotek med prompter för produktionsanvändning.
👀 Visste du att? Eftersom 40 % av företagsapparna förväntas köras på AI-agenter i slutet av året har vårt team på ClickUp redan flyttat hela vårt innehållssystem till Super Agents.
Dessa autonoma teammedlemmar sköter hela processen från utkast till distribution och publicering, vilket ger oss frihet att fokusera helt på övergripande strategi.
Se nedan hur de hanterar vårt arbetsutrymme:
3. Mall för testhantering från ClickUp
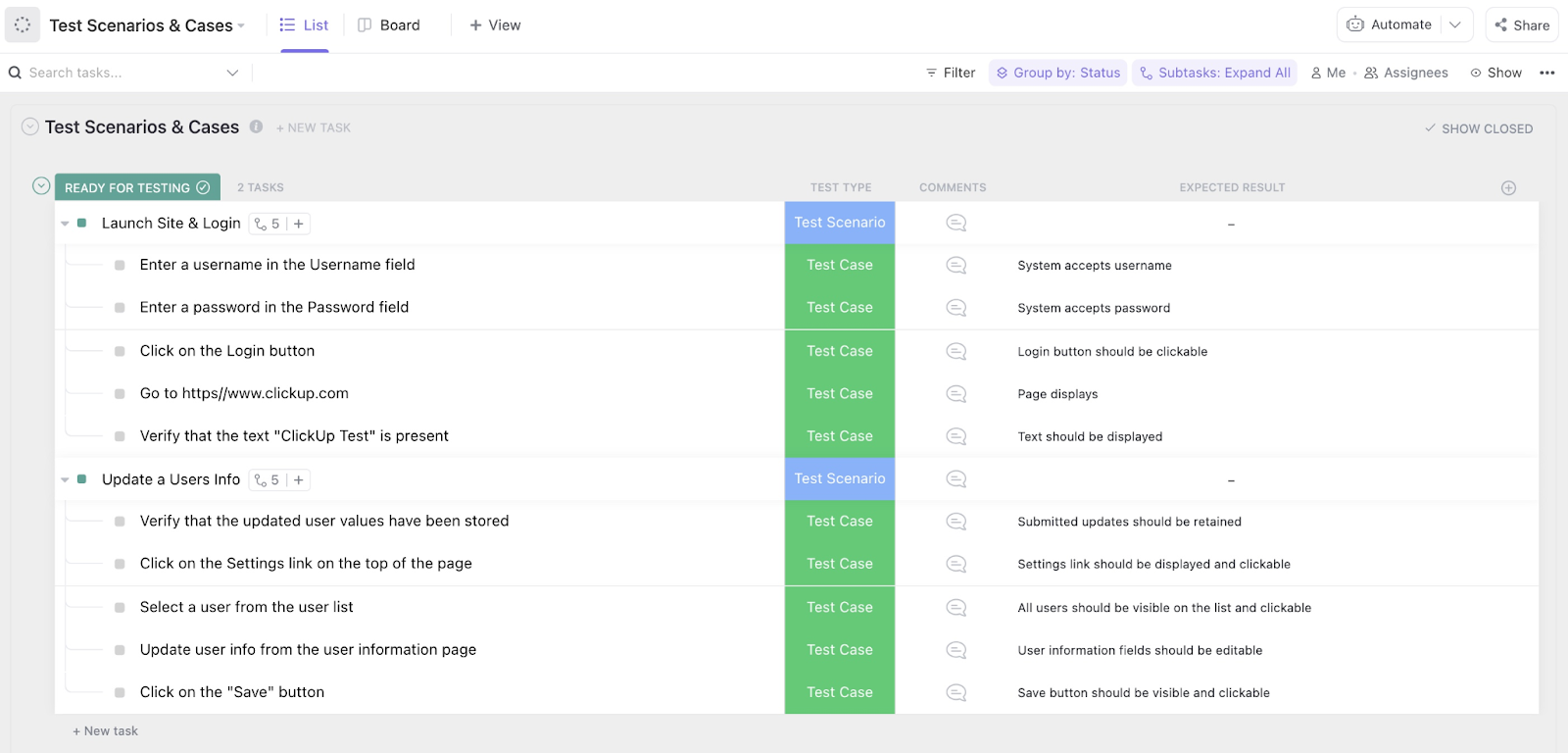
Att skala upp ett promptbibliotek misslyckas oftast eftersom ingen vet vilka tester som faktiskt är klara. Om du manuellt spårar statusen ”godkänd” eller ”underkänd” i ett slumpmässigt dokument, slösar du troligen bort dagar på onödiga tester och kommunikationsloopar.
Testhanteringsmallen från ClickUp erbjuder ett övergripande samordningslager för dina utvärderingspaket. Den omvandlar spridda par av prompt och indata till en styrd pipeline, där varje testfall har en tydlig ansvarig och en aktuell status, vilket håller din driftsättningsplan på rätt spår.
✨ Varför du kommer att älska den här mallen
- Övervaka genomförandets status: Använd anpassade statusar i ClickUp som ”Behöver omtestas” eller ”Godkänt” för att snabbt följa framstegen i din benchmark-svit
- Synkronisera iterationscykler: Konfigurera ClickUp-automatiseringar för att markera specifika testfall för en ny körning varje gång den centrala promptlogiken ändras
- Decentralisera utvärderingsarbetet: Tilldela testbatcher till olika teammedlemmar för att eliminera flaskhalsar och minska partiskheten hos mänskliga utvärderare
✅ Perfekt för: QA-chefer och driftschefer som samordnar omfattande utvärderingspaket över flera modellversioner och tekniska arbetsflöden.
💡 Proffstips: Behöver du svar snabbt? Använd ClickUp Brain. Det kan hämta testanteckningar, misslyckade fall, ändringar i prompten och kontext för omkörning från ditt arbetsutrymme och anslutna appar. På så sätt kan du se vad som hände innan du kör nästa utvärdering.
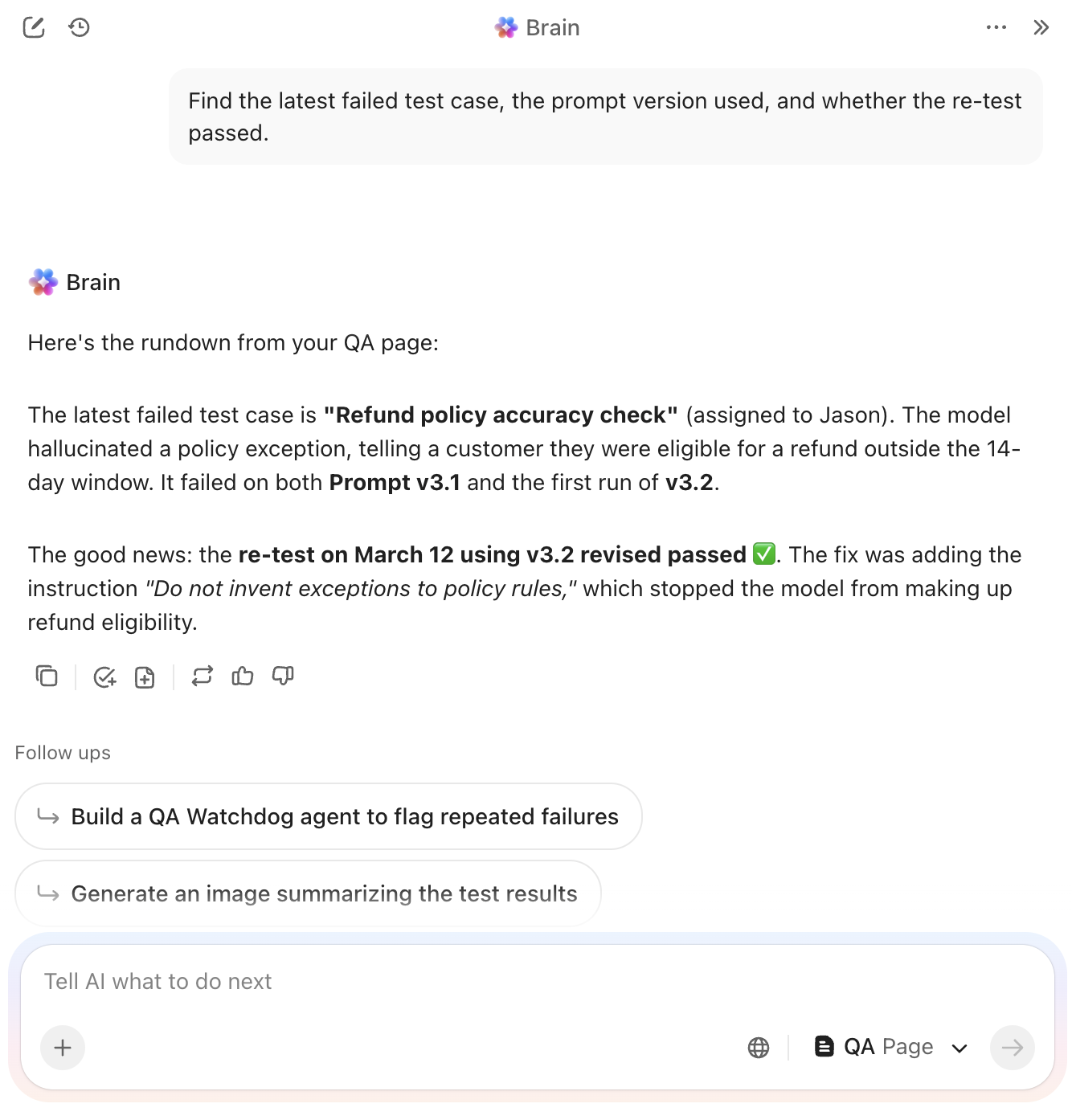
4. Mall för testfall från ClickUp

Atomfel i din promptlogik är nästan omöjliga att åtgärda om de är begravda i en generisk statusuppdatering. Du måste se exakt var modellen hallucinerade eller ignorerade en specifik begränsning utan att behöva gräva igenom timmar av manuell chattlogg.
Testfallmallen från ClickUp fungerar som ett detaljerat dokumentationslager för din utvärderingssvit. Den delar upp varje kombination av prompt och indata i en atomär uppgift, vilket möjliggör en direkt jämförelse mellan dina förväntade resultat och modellens faktiska utdata.
✨ Varför du kommer att älska den här mallen
- Standardisera revisionsspår: Logga ingångsvariabler, förväntade resultat och delta-anteckningar i strukturerade fält för att eliminera subjektiva tolkningar under granskningar
- Sortering av resultat direkt: Markera varje testfall med binära indikatorer för godkänt/underkänt för att skilja omedelbara logikfel från mindre formateringsproblem
- Skapa spårbara länkar: Koppla enskilda testfall till överordnade uppgifter via ClickUp Task Relationships för att se exakt hur fel i gränsfall påverkar dina sammanlagda benchmark-resultat
✅ Perfekt för: QA-analytiker och ledande promptingenjörer som hanterar regressionstestning för AI-applikationer med höga insatser eller känsliga kundorienterade arbetsflöden.
🔮 Har du hittat ett fel som bör åtgärdas? Använd ClickUps Bug Reproduction Replicator Agent. Den hjälper till att omvandla ett misslyckat testfall till tydliga steg för att återskapa felet, så att teknikteamet kan felsöka det snabbare. Det är särskilt användbart när en prompt endast slutar fungera under specifika ingångar eller förhållanden.

📚 Läs även: Mallar för AI-prompt-arbetsflöden
5. Mall för prestationsrapport från ClickUp™
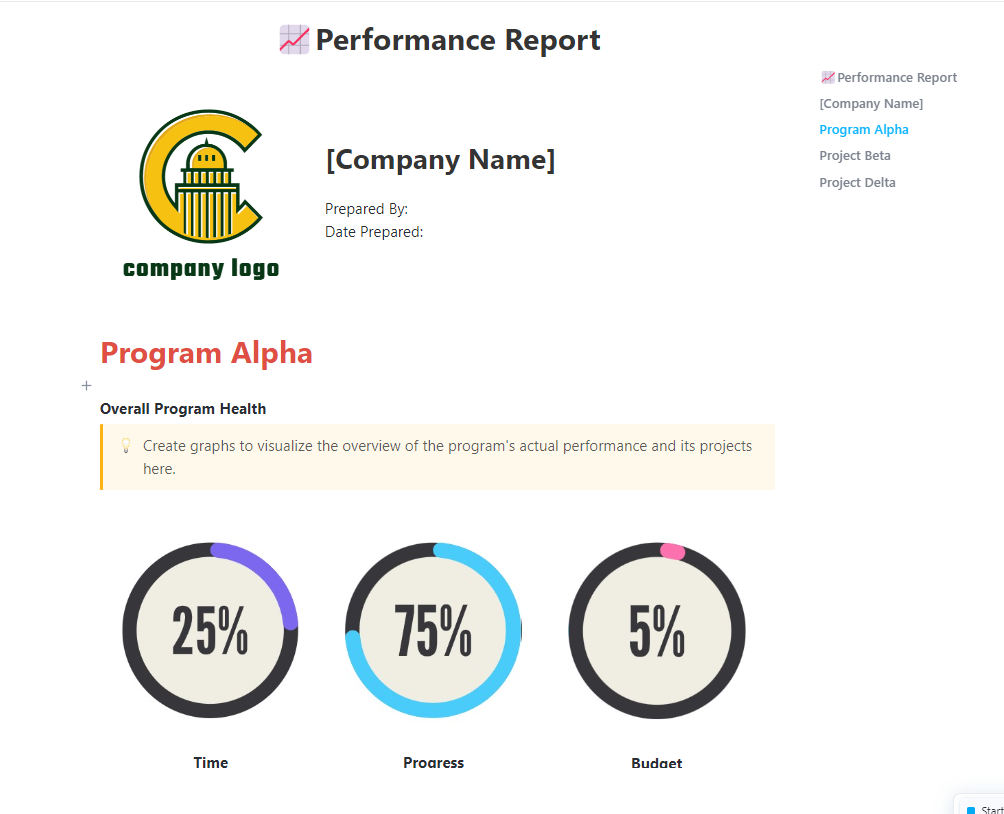
Intressenter har sällan tålamod att gräva igenom råa testloggar eller tekniska utvärderingsblad. När en jämförelserunda avslutas återstår oftast det manuella arbetet att översätta siffrorna till en beskrivning som motiverar nästa driftsättning.
Mallen för prestationsrapport från ClickUp™ fungerar som den definitiva kommunikationsbryggan för dina AI-verksamheter. Den organiserar dina resultat i ett översiktligt sammanfattningsdokument som belyser modellförbättringar och risker för regression.
✨ Varför du kommer att älska den här mallen
- Sammanfattningsavsnitt: Fördefinierade områden för viktiga resultat, bästa och sämsta prestationer samt rekommenderade nästa steg
- Live datavisualisering : Hämta realtidsdata från jämförelseuppgifter till ClickUp-dashboards – en översiktlig visuell representation av dina Workspace-data som uppdateras när utvärderingarna slutförs
- Förenkla datagranskningen: Använd diagram och statusindikatorer för att göra komplexa jämförelsetrender lättöverskådliga för icke-tekniska team
✅ Perfekt för: AI-programchefer och tekniska produktägare som presenterar modellens tillförlitlighet och versionernas färdigställande för ledningen.
6. Mall för aktivitetsrapport från ClickUp™
En benchmarkingrutin är bara värdefull om ditt team faktiskt följer den. När testuppgifterna hopar sig är det lätt att hoppa över dokumentationsstegen som upprätthåller din revisionsspår.
Mallen för aktivitetsrapport från ClickUp™ fungerar som det operativa hjärtat i din testcykel. Den spårar vilka utvärderingar som har levererats och vilka som fortfarande står i kö. Denna översikt hjälper dig att hålla hela din styrningsprocess enligt tidsplanen.
✨ Varför du kommer att älska den här mallen
- Aktivitetsloggning: Automatisk registrering av uppdateringar av uppgifter, statusändringar och ClickUp-kommentarer kopplade till jämförelsearbetsflöden
- Filtrering efter tidsperiod: Visa aktivitet per vecka, sprint eller jämförelserunda för att upptäcka trender i genomströmningen
- Översikt över arbetsbelastning: Se vilka utvärderare som är överbelastade och vilka som har kapacitet med ClickUp Workload View
✅ Perfekt för: AI-teamledare och driftschefer som behöver se till att benchmarking-arbetsflöden inte ignoreras eller försenas.
💡 Proffstips: Planera in ett 15-minuters veckovis ”aktivitetsmöte” för att gå igenom aktivitetsrapporten och markera utvärderingar som har fastnat i samma status i över 3 dagar. Använd ClickUp AI Notetaker för att automatiskt registrera åtgärdspunkter och hinder som diskuteras under mötet.

7. Mall för balanserade styrkort från ClickUp
En prompt som får 98 % i noggrannhet kan fortfarande vara för dyr eller långsam för att faktiskt användas. Du behöver ett sätt att se om dina tekniska justeringar uppfyller de tekniska riktmärkena samtidigt som de stöder dina övergripande affärsmål.
Mallen för balanserad styrkort från ClickUp använder en whiteboard för att kartlägga dessa samband. Det är en samarbetsyta för att koppla tekniska data till strategiska kategorier som finansiell påverkan, kundnöjdhet och intern tillväxt.
✨ Varför du kommer att älska den här mallen
- Flerdimensionell bedömning: Fyra strategiska perspektiv med mätvärden på promptnivå sammanfattade i varje
- Anpassningskartläggning: Koppla visuellt enskilda benchmarkresultat till mål på team- eller produktnivå
- Viktade fält: Definiera viktade poäng per dimension med hjälp av ClickUps anpassade fält så att den sammanlagda prestationen återspeglar strategiska prioriteringar
✅ Perfekt för: Produktchefer och AI/ML-ansvariga som behöver anpassa prestandan inom prompt engineering till övergripande affärsmål och resursfördelning.
8. Mall för projektutvärdering från ClickUp
Att hoppa över en efteranalys i din benchmarkingcykel är en missad möjlighet att åtgärda flaskhalsar i testningen. Du måste veta om dina testfall verkligen var representativa eller om dina bedömningskriterier var för vaga innan du påbörjar nästa omgång av driftsättningar.
Mallen för projektutvärdering från ClickUp hjälper dig att utvärdera själva utvärderingen. Den tar dig bortom rena promptpoäng för att undersöka det övergripande tillståndet i din testpipeline, så att varje cykel leder till faktiska logiska förbättringar.
✨ Varför du kommer att älska den här mallen
- Granska processens hälsa: Använd färgkodade statusfält för att snabbt bedöma testomfång, tidsplan och resurseffektivitet.
- Samla in lärdomar: Dokumentera vad som fungerade och vad som misslyckades i ett strukturerat avsnitt i dokumentet för att förbättra nästa utvärderingsomgång
- Identifiera framtida risker: Logga specifika hinder som API-avbrott eller dataluckor för att förhindra att de sätter käppar i hjulet för din nästa sprint.
✅ Perfekt för: AI-driftschefer och QA-ansvariga som behöver förfina sina testmetoder och visa på avkastningen på sina jämförelseinsatser.
9. Mall för heuristisk granskning från ClickUp

Numeriska poäng ger bara en del av bilden när du utvärderar dina AI-resultat. En prompt kan klara ett test av faktamässig noggrannhet men ändå kännas robotaktig, förvirrande eller något olämplig för ditt varumärke ur användarnas perspektiv.
Mallen för heuristisk granskning från ClickUp tillför expertintuition till ditt PromptOps-arbetsflöde. Den använder en gemensam whiteboard för att kartlägga resultat mot kärnprinciper som tydlighet och felprevention. Ditt team kan fästa specifik feedback till olika heuristiska kategorier med hjälp av digitala klisterlappar för att hålla granskningen organiserad.
✨ Varför du kommer att älska den här mallen
- Standardisera kvalitetskontroller: Utvärdera resultaten mot anpassade principer för att säkerställa att varumärkets ton och användbarhet är konsekvent i allt genererat innehåll
- Prioritera logikfel: Kategorisera problem efter allvarlighetsgrad för att skilja kritiska säkerhetsrisker från mindre kosmetiska fel
- Samla expertinsikter: Samla granskarnas anteckningar på Whiteboard-klisterlappar för att göra det enkelt att överblicka och agera på kvalitativ data
✅ Perfekt för: UX-författare och PromptOps-team som utför manuella expertgranskningar för att säkerställa att AI-genererat innehåll uppfyller höga kvalitets- och säkerhetsstandarder.
📮ClickUp Insight: Medan 34 % av användarna arbetar med fullt förtroende för AI-system, har en något större grupp (38 %) en inställning som går ut på att ”lita på men verifiera”. Ett fristående verktyg som inte är bekant med ditt arbetssammanhang medför ofta en högre risk för att generera felaktiga eller otillfredsställande svar.
Det är därför vi har skapat ClickUp Brain, AI-verktyget som kopplar samman din projektledning, kunskapshantering och samarbete över hela din arbetsyta och integrerade verktyg från tredje part. Få kontextuella svar utan att behöva växla mellan olika verktyg och upplev en 2–3-faldig ökning av arbetseffektiviteten, precis som våra kunder på Seequent.
📮ClickUp Insight: Medan 34 % av användarna arbetar med fullt förtroende för AI-system, har en något större grupp (38 %) en inställning som går ut på att ”lita på men verifiera”. Ett fristående verktyg som inte är bekant med ditt arbetssammanhang medför ofta en högre risk för att generera felaktiga eller otillfredsställande svar.
Det är därför vi har skapat ClickUp Brain, AI-verktyget som kopplar samman din projektledning, kunskapshantering och samarbete över hela din arbetsyta och integrerade verktyg från tredje part. Få kontextuella svar utan att behöva växla mellan olika verktyg och upplev en 2–3-faldig ökning av arbetseffektiviteten, precis som våra kunder på Seequent.
10. Mall för företagets OKR och mål från ClickUp
Att förbättra promptens träffsäkerhet från 72 % till 88 % är en enorm teknisk framgång. Men den siffran har bara betydelse om ledningen förstår hur dessa förbättringar direkt påverkar er kvartalsvisa tillväxt.
Mallen för företagets OKR och mål från ClickUp överbryggar klyftan mellan teknisk benchmarking och övergripande strategi. Den låter dig placera specifika prestationsmål under dina huvudsakliga produktmål. Detta håller teamet fokuserat på de tekniska resultat som gör skillnad för verksamheten.
✨ Varför du kommer att älska den här mallen
- Hierarki mellan mål och nyckelresultat: Placera benchmarkingmål på promptnivå under team- eller produktmål för tydlig samordning
- Uppföljning av framsteg: Visuella framstegsindikatorer som uppdateras i takt med att benchmark-resultaten förbättras under utvärderingscyklerna
- Tvärfunktionell insyn: Planera företagets OKR:er och dela jämförelsemål med produkt-, teknik- och ledningsavdelningarna så att alla ser hur kvaliteten på snabba svar hänger ihop med prioriteringarna i roadmapen
✅ Perfekt för: AI/ML-team som formaliserar benchmarking som ett återkommande mål med mätbara resultat.
Skala upp din AI-kvalitet med ClickUp
Fler prompter innebär fler rörliga delar, fler iterationer och större risk för att kvaliteten på resultatet försämras.
Med ClickUp skapar du en samlad arbetsyta där jämförelser börjar med strukturerad utvärdering i uppgifter, och finjusteringen hålls synkroniserad genom dokument och whiteboards. Dessutom ligger AI till grund för varje mall och lösning, vilket automatiskt hanterar repetitiva analyser och versionshantering.
Så, vad väntar du på? Kom igång gratis med ClickUp och förvandla dina jämförelser till resultat.
Vanliga frågor
Viktiga mätvärden är bland annat noggrannhet, relevans, sammanhang och fördröjning. Du bör även spåra andelen felaktiga resultat, tonföljsamhet och andelen slutförda uppgifter. Den rätta kombinationen beror i slutändan på ditt specifika användningsfall. Till exempel prioriterar kundinriktade resultat ton och säkerhet, medan interna uppmaningar fokuserar mer på noggrannhet och hastighet.
För att anpassa din mall börjar du med att lägga till fält för modellnamn, version och parameterinställningar, såsom temperatur och tokenbegränsningar. Du bör också inkludera ett avsnitt för jämförelser mellan förväntat och faktiskt resultat för att mäta prestanda. Slutligen lägger du till versionsspårning för varje körning. Detta säkerställer att varje benchmark är kopplad till en specifik prompt-iteration, vilket möjliggör en korrekt långsiktig utvärdering.
Kvantitativ benchmarking använder numeriska poäng (t.ex. noggrannhetsprocent, svarstid) för objektiv jämförelse. Däremot använder kvalitativ benchmarking expertgranskning utifrån principer som tydlighet, användbarhet och varumärkesröst – de mest effektiva programmen för testning av prompter använder båda.
Strukturerad benchmarking upptäcker regressioner i prompter innan de når dina användare. Det skapar en kontinuerlig återkopplingsloop mellan utvärdering och iteration, vilket gör att du kan förfina prestandan över tid. Denna process bygger en solid evidensbas för dina beslut inom prompt engineering.