
Sebagian besar tim yang menjelajahi model AI sumber terbuka menemukan bahwa LLaMA dari Meta menawarkan kombinasi langka antara kekuatan dan fleksibilitas, tetapi pengaturan teknisnya bisa terasa seperti merakit furnitur tanpa petunjuk.
Panduan ini akan memandu Anda dalam membangun chatbot LLaMA yang berfungsi dari awal, mencakup segala hal mulai dari persyaratan hardware dan akses model hingga teknik prompt dan strategi deployment.
Ayo mulai!
Apa Itu LLaMA dan Mengapa Menggunakannya untuk Chatbot?
Membangun chatbot dengan API eksklusif seringkali terasa seperti terikat pada sistem pihak lain, menghadapi biaya yang tidak terduga dan masalah privasi data. Ketergantungan pada vendor ini berarti Anda tidak dapat benar-benar menyesuaikan model sesuai kebutuhan unik tim Anda, yang mengakibatkan respons generik dan potensi masalah kepatuhan.
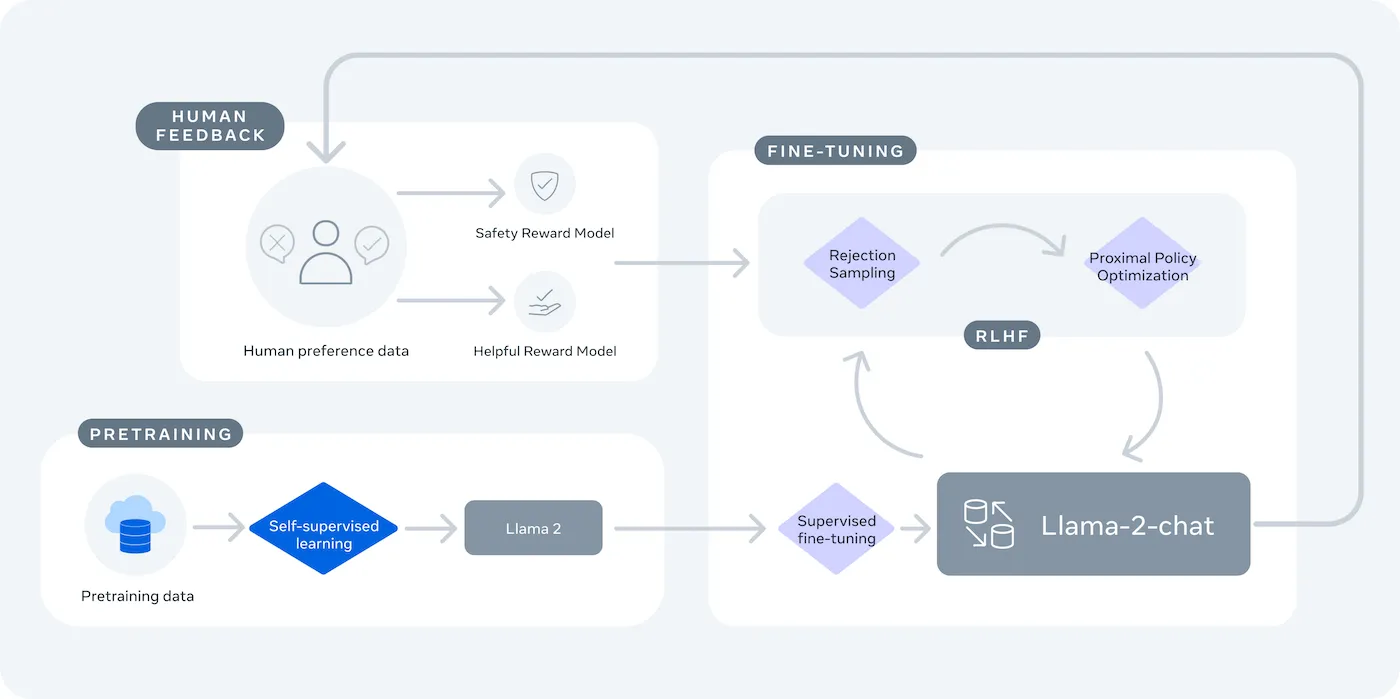
LLaMA (Large Language Model Meta AI) adalah keluarga model bahasa terbuka Meta, dan menawarkan alternatif yang kuat. Dirancang untuk penggunaan penelitian dan komersial, LLaMA memberikan kontrol yang tidak dimiliki oleh model sumber tertutup.
Model LLaMA tersedia dalam berbagai ukuran, diukur berdasarkan parameter (misalnya, 7B, 13B, 70B). Parameter dapat diartikan sebagai ukuran kompleksitas dan daya komputasi model—model yang lebih besar memiliki kemampuan lebih tinggi tetapi membutuhkan sumber daya komputasi yang lebih besar.
Inilah alasan mengapa Anda mungkin menggunakan chatbot LLaMA:
- Privasi data: Saat Anda menjalankan model di infrastruktur Anda sendiri, data percakapan Anda tidak pernah meninggalkan lingkungan Anda. Hal ini sangat penting bagi tim yang menangani informasi sensitif.
- Penyesuaian: Anda dapat menyesuaikan model LLaMA menggunakan dokumen atau data internal perusahaan Anda. Hal ini membantu model memahami konteks spesifik Anda dan memberikan jawaban yang jauh lebih relevan.
- Prediktabilitas biaya: Setelah pengaturan hardware awal, Anda tidak perlu khawatir tentang biaya API per token. Biaya Anda menjadi tetap dan dapat diprediksi.
- Tanpa batasan kuota: Kapasitas chatbot Anda ditentukan oleh hardware Anda sendiri, bukan oleh kuota penyedia layanan. Anda dapat menyesuaikan skala sesuai kebutuhan.
Pertukaran utama adalah kenyamanan versus kontrol. LLaMA memerlukan pengaturan teknis yang lebih kompleks dibandingkan dengan API plug-and-play. Untuk chatbot produksi, tim biasanya menggunakan LLaMA 2 atau versi terbaru LLaMA 3, yang menawarkan kemampuan penalaran yang lebih baik dan dapat menangani lebih banyak teks sekaligus.
Apa yang Anda Butuhkan Sebelum Membangun Chatbot LLaMA
Memasuki proyek pengembangan tanpa alat yang tepat adalah resep untuk frustrasi. Anda sudah setengah jalan, hanya untuk menyadari bahwa Anda kekurangan akses ke perangkat keras atau perangkat lunak yang penting, menghambat kemajuan Anda dan membuang-buang waktu berjam-jam.
Untuk menghindari hal ini, kumpulkan semua yang Anda butuhkan di awal. Berikut adalah daftar periksa untuk memastikan awal yang lancar. 🛠️
Persyaratan hardware
| Ukuran Model | VRAM minimum | Opsi Alternatif |
|---|---|---|
| 7 miliar parameter | 8GB | Instan GPU cloud |
| 13 miliar parameter | 16GB | Instan GPU cloud |
| 70 miliar parameter | Multiple GPUs | Kuantisasi atau cloud |
Jika mesin lokal Anda tidak memiliki unit pemrosesan grafis (GPU) yang cukup kuat, Anda dapat menggunakan layanan cloud seperti AWS atau GCP. Platform inferensi seperti Baseten dan Replicate juga menawarkan akses GPU dengan sistem bayar sesuai penggunaan.
Persyaratan perangkat lunak
- Python 3.8+: Ini adalah bahasa pemrograman standar untuk proyek machine learning.
- Manajer paket: Anda memerlukan pip atau Conda untuk menginstal perpustakaan yang diperlukan untuk proyek Anda.
- Lingkungan virtual: Ini adalah praktik terbaik yang menjaga ketergantungan proyek Anda terisolasi dari proyek Python lain di mesin Anda.
Persyaratan akses
- Akun Hugging Face: Anda memerlukan akun untuk mengunduh bobot model LLaMA.
- Persetujuan Meta: Anda harus menyetujui perjanjian lisensi Meta untuk mengakses model LLaMA, yang biasanya disetujui dalam beberapa jam.
- Kunci API: Kunci ini hanya diperlukan jika Anda memutuskan untuk menggunakan endpoint inferensi yang dihosting daripada menjalankan model secara lokal.
Untuk panduan ini, kami akan menggunakan kerangka kerja LangChain. Kerangka kerja ini menyederhanakan banyak bagian kompleks dalam membangun chatbot, seperti mengelola prompt dan riwayat percakapan.
{kind=link}
Cara Membangun Chatbot dengan LLaMA Langkah demi Langkah
Menghubungkan semua komponen teknis chatbot—model, prompt, dan memori—dapat terasa membingungkan. Mudah tersesat dalam kode, yang dapat menyebabkan bug dan chatbot yang tidak berfungsi sesuai harapan. Panduan langkah demi langkah ini membagi proses menjadi bagian-bagian sederhana dan terkelola.
Pendekatan ini berlaku baik Anda menjalankan model di mesin sendiri maupun menggunakan layanan terhosting.
Langkah 1: Instal paket yang diperlukan
Pertama, Anda perlu menginstal perpustakaan Python inti. Buka terminal Anda dan jalankan perintah ini:
pip install langchain transformers accelerate torch
Jika Anda menggunakan layanan terhosting seperti Baseten untuk inferensi, Anda juga perlu menginstal kit pengembangan perangkat lunak (SDK) khusus miliknya:
pip install baseten
Berikut ini adalah fungsi masing-masing paket:
- Langchain: Sebuah kerangka kerja yang membantu membangun aplikasi dengan model bahasa besar, termasuk mengelola rantai percakapan dan memori.
- Transformers: Perpustakaan Hugging Face untuk memuat dan menjalankan model LLaMA.
- Accelerate: Perpustakaan yang membantu mengoptimalkan cara model dimuat ke CPU dan GPU Anda.
- Torch: Perpustakaan PyTorch, yang menyediakan daya komputasi belakang layar untuk perhitungan model.
Jika Anda menjalankan model secara lokal di mesin dengan GPU NVIDIA, pastikan CUDA telah diinstal dan dikonfigurasi dengan benar. Hal ini memungkinkan model menggunakan GPU untuk kinerja yang jauh lebih cepat.
Langkah 2: Akses model LLaMA
Sebelum Anda dapat mengunduh model, Anda perlu mendapatkan akses resmi dari Meta melalui Hugging Face.
- Buat akun di huggingface.co
- Kunjungi halaman model, misalnya, meta-llama/Llama-2-7b-chat-hf
- Klik “Akses repositori” dan setujui syarat lisensi Meta.
- Di pengaturan akun Hugging Face Anda, buat token akses baru.
- Di terminal Anda, jalankan perintah huggingface-cli login dan tempelkan token Anda untuk mengautentikasi mesin Anda.
Persetujuan biasanya cepat. Pastikan Anda memilih varian model yang memiliki kata "chat" dalam namanya, karena varian ini telah dilatih secara khusus untuk tugas percakapan.
Langkah 3: Muat model LLaMA
Sekarang Anda dapat memuat model ke dalam kode Anda. Anda memiliki dua opsi utama tergantung pada perangkat keras Anda.
Jika Anda memiliki GPU yang cukup kuat, Anda dapat memuat model secara lokal:
Jika perangkat keras Anda terbatas, Anda dapat menggunakan layanan inferensi yang dihosting:
Perintah `device_map="auto"` memberitahu perpustakaan Transformers untuk mendistribusikan model secara otomatis ke semua GPU yang tersedia.
Jika Anda masih kehabisan memori, Anda dapat menggunakan teknik yang disebut kuantisasi untuk mengurangi ukuran model, meskipun hal ini mungkin sedikit mengurangi kinerjanya.
Langkah 4: Buat templat prompt
Model chat LLaMA dilatih untuk mengharapkan format tertentu untuk prompt. Template prompt memastikan masukan Anda terstruktur dengan benar.
Mari kita uraikan format ini:
- <
>: Bagian ini berisi prompt sistem, yang memberikan instruksi inti kepada model dan mendefinisikan kepribadiannya. - [INST]: Ini menandai awal pertanyaan atau instruksi pengguna.
- [/INST]: Ini menandakan kepada model bahwa saatnya untuk menghasilkan respons.
Perlu diingat bahwa versi berbeda dari LLaMA mungkin menggunakan templat yang sedikit berbeda. Selalu periksa dokumentasi model di Hugging Face untuk format yang benar.
Langkah 5: Konfigurasikan rantai chatbot
Selanjutnya, Anda akan menghubungkan model dan templat prompt Anda ke dalam rantai percakapan menggunakan LangChain. Rantai ini juga akan mencakup memori untuk melacak percakapan.
LangChain menawarkan beberapa jenis memori:
- ConversationBufferMemory: Ini adalah opsi termudah. Ia menyimpan seluruh riwayat percakapan.
- ConversationSummaryMemory: Untuk menghemat ruang, opsi ini secara berkala merangkum bagian-bagian percakapan yang lebih lama.
- ConversationBufferWindowMemory: Ini hanya menyimpan beberapa percakapan terakhir di memori, yang berguna untuk mencegah konteks menjadi terlalu panjang.
Untuk pengujian, ConversationBufferMemory adalah tempat yang bagus untuk memulai.
Langkah 6: Jalankan loop chatbot
Akhirnya, Anda dapat membuat loop sederhana untuk berinteraksi dengan chatbot Anda dari terminal.
Dalam aplikasi dunia nyata, Anda akan mengganti loop ini dengan endpoint API menggunakan framework seperti FastAPI atau Flask. Anda juga dapat mengalirkan respons model kembali ke pengguna, yang membuat chatbot terasa jauh lebih cepat.
Anda juga dapat menyesuaikan parameter seperti suhu untuk mengontrol tingkat keacakan respons. Suhu rendah (misalnya, 0,2) membuat output lebih deterministik dan faktual, sementara suhu tinggi (misalnya, 0,8) mendorong kreativitas yang lebih besar.
Cara Menguji Chatbot LLaMA Anda
Anda telah membangun chatbot yang memberikan jawaban, tetapi apakah chatbot tersebut siap untuk pengguna nyata? Deploying chatbot yang belum diuji dapat menyebabkan kegagalan yang memalukan, seperti memberikan informasi yang salah atau menghasilkan konten yang tidak pantas, yang dapat merusak reputasi perusahaan Anda.
Rencana pengujian sistematis adalah solusi untuk ketidakpastian ini. Hal ini memastikan chatbot Anda tangguh, andal, dan aman.
Pengujian fungsional:
- Kasus khusus: Uji bagaimana bot menangani masukan kosong, pesan yang sangat panjang, dan karakter khusus.
- Verifikasi memori: Pastikan chatbot mengingat konteks percakapan di seluruh putaran percakapan.
- Penerapan instruksi: Periksa apakah bot mematuhi aturan yang Anda tetapkan dalam prompt sistem.
Evaluasi kualitas:
- Relevansi: Apakah respons tersebut benar-benar menjawab pertanyaan pengguna?
- Akurasi: Apakah informasi yang disediakannya benar?
- Kohesi: Apakah percakapan berjalan secara logis?
- Keamanan: Apakah bot menolak untuk menjawab permintaan yang tidak pantas atau berbahaya?
Pengujian kinerja:
- Latency: Ukur berapa lama waktu yang dibutuhkan bot untuk mulai merespons dan menyelesaikan responsnya.
- Penggunaan sumber daya: Pantau seberapa banyak memori GPU yang digunakan model selama inferensi.
- Koncurrency: Uji bagaimana sistem berfungsi saat beberapa pengguna berinteraksi dengannya secara bersamaan.
Selain itu, waspadai masalah umum LLM seperti halusinasi (menyampaikan informasi palsu dengan keyakinan), pergeseran konteks (kehilangan fokus pada topik dalam percakapan panjang), dan pengulangan. Mencatat semua percakapan uji coba adalah cara yang bagus untuk mengidentifikasi pola dan memperbaiki masalah sebelum mencapai pengguna Anda.
Kasus Penggunaan Chatbot LLaMA untuk Tim
Setelah melewati tahap penyempurnaan dan deployment, LLaMA menjadi paling berguna saat diterapkan pada masalah sehari-hari tim—bukan demo AI yang abstrak. Tim biasanya tidak membutuhkan "chatbot"; mereka membutuhkan akses lebih cepat ke pengetahuan, pengalihan manual yang lebih sedikit, dan pekerjaan repetitif yang lebih sedikit.
Asisten pengetahuan internal
Dengan menyesuaikan LLaMA pada dokumentasi internal, wiki, dan FAQ—atau mengombinasikannya dengan basis pengetahuan berbasis RAG—tim dapat mengajukan pertanyaan dalam bahasa alami dan mendapatkan jawaban yang akurat dan sadar konteks. Hal ini menghilangkan hambatan dalam mencari informasi di berbagai alat terpisah sambil menjaga data sensitif tetap internal, daripada mengirimkannya ke API pihak ketiga.
🌟 Pencarian Perusahaan di ClickUp, bersama dengan agen Ambient Answers yang sudah siap pakai, memberikan jawaban kontekstual yang detail untuk pertanyaan Anda menggunakan pengetahuan yang ada di ruang kerja ClickUp Anda.
Bantuan tinjauan kode
Ketika dilatih menggunakan kode sumber dan panduan gaya Anda sendiri, LLaMA dapat bertindak sebagai asisten tinjauan kode yang kontekstual. Alih-alih praktik terbaik yang generik, pengembang akan mendapatkan saran yang sesuai dengan konvensi tim, keputusan arsitektur, dan pola historis.
🌟 Asisten tinjauan kode berbasis LLaMA dapat mengidentifikasi masalah, menyarankan perbaikan, atau menjelaskan kode yang tidak familiar. ClickUp’s Codegen melangkah lebih jauh dengan beroperasi di dalam alur kerja pengembangan—membuat permintaan pull, menerapkan refaktorisasi, atau memperbarui file secara langsung berdasarkan wawasan tersebut. Hasilnya adalah pengurangan salin-tempel dan lebih sedikit handoff yang terputus antara “berpikir” dan “melakukan.”
Penanganan dukungan pelanggan
LLaMA dapat dilatih untuk klasifikasi niat guna memahami pertanyaan pelanggan yang masuk dan mengarahkan mereka ke tim atau alur kerja yang tepat. Pertanyaan umum dapat ditangani secara otomatis, sementara kasus khusus diteruskan ke agen manusia dengan konteks yang terlampir, mengurangi waktu respons tanpa mengorbankan kualitas.
Anda juga dapat membuat Triage Super Agent menggunakan bahasa alami di ruang kerja ClickUp Anda. Pelajari lebih lanjut
Ringkasan rapat dan tindak lanjut
Dengan menggunakan transkrip rapat sebagai masukan, LLaMA dapat mengekstrak keputusan, tindakan yang harus dilakukan, dan poin pembahasan utama. Nilai sebenarnya muncul ketika output ini mengalir langsung ke alat manajemen tugas, mengubah percakapan menjadi pekerjaan yang tercatat.
🌟 Asisten Catatan Rapat AI ClickUp tidak hanya mencatat rapat; ia juga menyusun ringkasan, menghasilkan daftar tindakan, dan menghubungkan catatan rapat dengan dokumen dan tugas Anda.
Penyusunan dokumen dan iterasi
Tim dapat menggunakan LLaMA untuk menghasilkan draf awal laporan, proposal, atau dokumentasi berdasarkan templat yang ada dan contoh sebelumnya. Hal ini memindahkan upaya dari pembuatan halaman kosong ke tinjauan dan penyempurnaan, mempercepat pengiriman tanpa menurunkan standar.
🌟 ClickUp Brain dapat dengan cepat menghasilkan draf untuk dokumentasi, menjaga semua pengetahuan di tempat kerja Anda tetap relevan. Coba sekarang.
Chatbot yang didukung LLaMA paling efektif ketika diintegrasikan ke dalam alur kerja yang sudah ada—dokumentasi, manajemen proyek, dan komunikasi tim—daripada beroperasi sebagai alat mandiri.
Inilah saatnya mengintegrasikan AI langsung ke dalam ruang kerja Anda membuat perbedaan besar. Alih-alih membangun alat terpisah, Anda dapat membawa AI percakapan ke tempat tim Anda sudah beroperasi.
Misalnya, Anda dapat membuat bot LLaMA kustom untuk bertindak sebagai asisten pengetahuan. Namun, jika bot tersebut berada di luar alat manajemen proyek Anda, tim Anda harus beralih konteks untuk menanyakan sesuatu kepadanya. Hal ini menimbulkan gesekan dan memperlambat semua orang.
Hindari pergantian konteks dengan menggunakan AI yang sudah menjadi bagian dari alur kerja Anda.
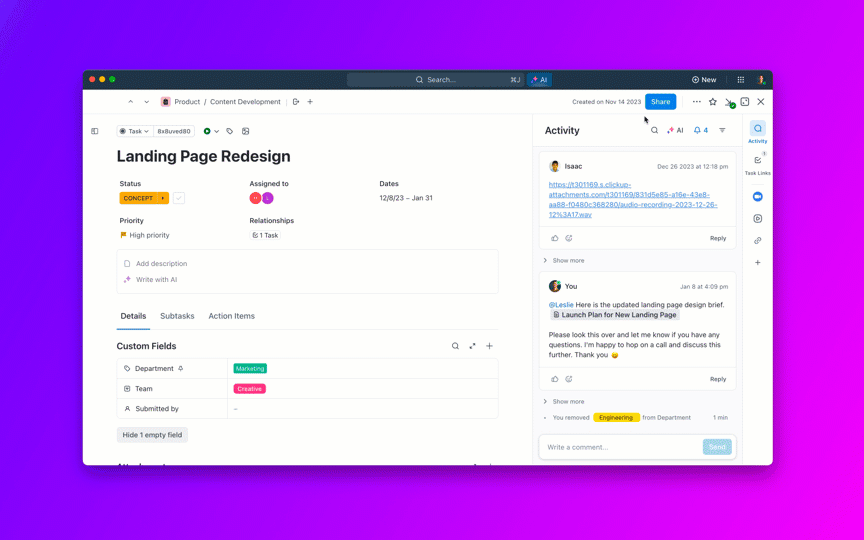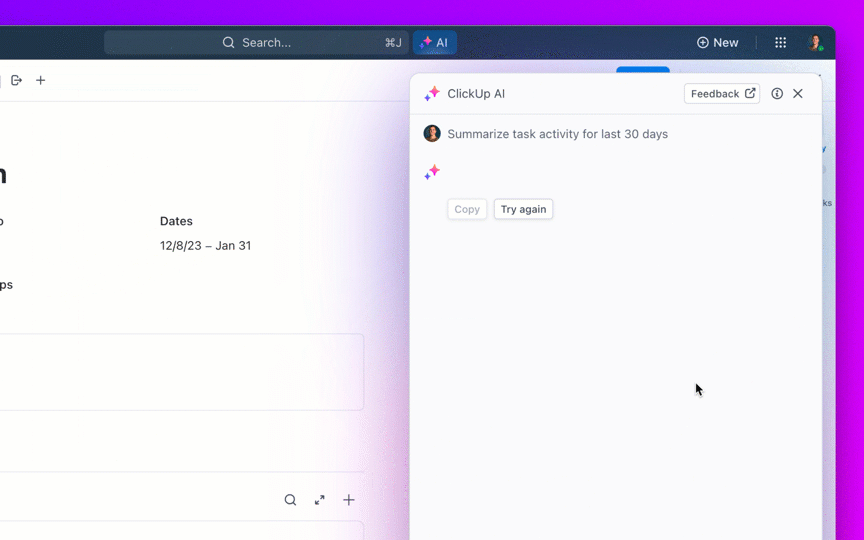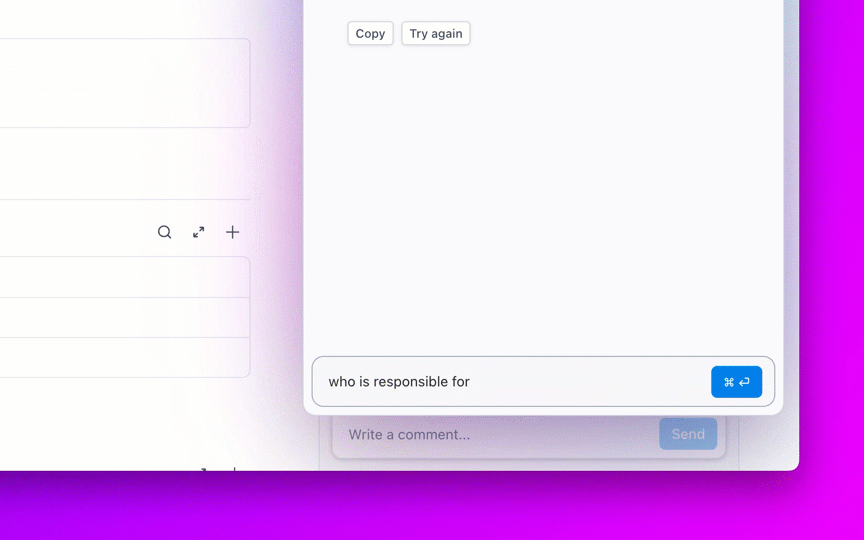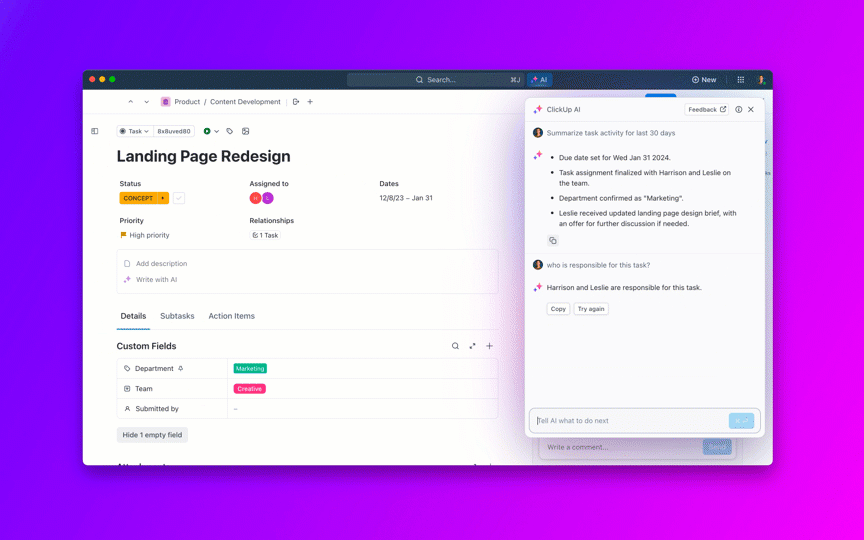
Tanyakan pertanyaan tentang proyek, tugas, dan dokumen Anda tanpa perlu meninggalkan ClickUp menggunakan ClickUp Brain. Cukup ketik @brain di komentar tugas atau ClickUp Chat untuk mendapatkan jawaban instan yang memahami konteks. Ini seperti memiliki anggota tim yang memiliki pengetahuan sempurna tentang seluruh ruang kerja Anda. 🤩
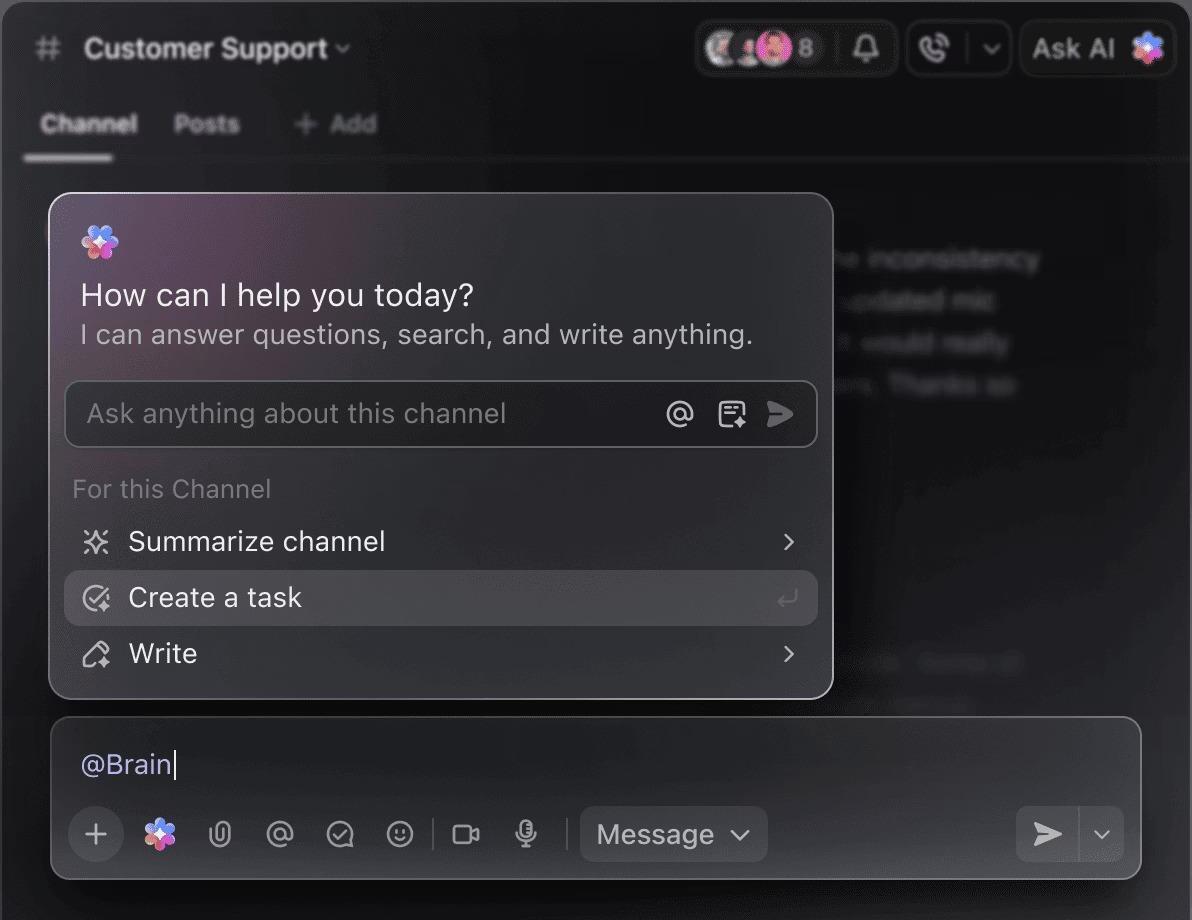
Ini mengubah chatbot dari sekadar fitur baru menjadi bagian inti dari mesin produktivitas tim Anda.
Batasan Penggunaan LLaMA dalam Membangun Chatbot
Membangun chatbot LLaMA dapat menjadi hal yang memberdayakan, tetapi tim sering kali terkejut oleh kompleksitas tersembunyi. Model open-source "gratis" ini bisa berakhir lebih mahal dan sulit dikelola daripada yang diharapkan, menyebabkan pengalaman pengguna yang buruk dan siklus pemeliharaan yang terus-menerus dan menguras sumber daya.
Penting untuk memahami batasan-batasan sebelum Anda memutuskan untuk menggunakannya.
- Kompleksitas teknis: Mengatur dan memelihara model LLaMA memerlukan pengetahuan tentang infrastruktur pembelajaran mesin.
- Persyaratan hardware: Menjalankan model yang lebih besar dan canggih memerlukan hardware GPU yang mahal, dan biaya cloud dapat dengan cepat bertambah.
- Batasan jendela konteks: Model LLaMA memiliki memori terbatas ( 4K token untuk LLaMA 2 ). Mengelola dokumen atau percakapan yang panjang memerlukan strategi pemotongan yang kompleks.
- Tidak ada fitur keamanan bawaan: Anda bertanggung jawab untuk menerapkan filter konten dan langkah-langkah keamanan sendiri.
- Pemeliharaan berkelanjutan: Saat model baru dirilis, Anda perlu memperbarui sistem Anda, dan model yang telah disesuaikan mungkin memerlukan pelatihan ulang.
Model yang dihosting sendiri umumnya memiliki latensi yang lebih tinggi dibandingkan dengan API komersial yang sangat dioptimalkan. Semua beban operasional ini ditangani oleh solusi terkelola untuk Anda.
📮ClickUp Insight: 88% responden survei kami menggunakan AI untuk tugas pribadi mereka, namun lebih dari 50% enggan menggunakannya di tempat kerja. Tiga hambatan utama? Kurangnya integrasi yang mulus, kesenjangan pengetahuan, atau kekhawatiran keamanan.
Tapi bagaimana jika AI sudah terintegrasi ke dalam ruang kerja Anda dan sudah aman? ClickUp Brain, asisten AI bawaan ClickUp, menjadikan hal ini kenyataan. Ia memahami prompt dalam bahasa sehari-hari, mengatasi ketiga kekhawatiran adopsi AI sambil menghubungkan obrolan, tugas, dokumen, dan pengetahuan Anda di seluruh ruang kerja. Temukan jawaban dan wawasan dengan satu klik!
Alternatif LLaMA untuk Membangun Chatbot
LLaMA hanyalah salah satu pilihan di antara banyak model AI, dan bisa jadi membingungkan untuk menentukan mana yang tepat untuk Anda.
Inilah cara pemetaan alternatif terbagi.
Model open-source lainnya:
- Mistral: Dikenal karena kinerjanya yang kuat bahkan dengan ukuran model yang lebih kecil, menjadikannya efisien.
- Falcon: Dilengkapi dengan lisensi yang sangat fleksibel, yang sangat cocok untuk aplikasi komersial.
- MPT: Dioptimalkan untuk menangani dokumen dan percakapan yang panjang.
API Komersial:
- OpenAI (GPT-4, GPT-3.5): Umumnya dianggap sebagai model bahasa besar yang paling canggih, dan sangat mudah diintegrasikan.
- Anthropic (Claude): Dikenal karena fitur keamanan yang kuat dan jendela konteks yang sangat besar.
- Google (Gemini): Menawarkan kemampuan multimodal yang kuat, memungkinkan untuk memahami teks, gambar, dan audio.
Anda dapat membangunnya sendiri dengan model open-source, membayar API komersial, atau menggunakan ruang kerja AI terintegrasi yang menawarkan solusi pra-integrasi dengan berbagai jenis agen AI.
📚 Baca Juga: Cara Menggunakan Chatbot untuk Bisnis Anda
Bangun Asisten AI yang Sadar Konteks dengan ClickUp
Membuat chatbot dengan LLaMA memberi Anda kendali penuh atas data, biaya, dan kustomisasi. Namun, kendali tersebut juga membawa tanggung jawab atas infrastruktur, pemeliharaan, dan keamanan—semua hal yang ditangani oleh API yang dikelola untuk Anda. Tujuannya bukan hanya untuk membuat bot—tetapi untuk meningkatkan produktivitas tim Anda, dan proyek teknik yang kompleks terkadang dapat mengalihkan perhatian dari tujuan tersebut.
Pilihan yang tepat tergantung pada sumber daya dan prioritas tim Anda. Jika Anda memiliki keahlian ML dan kebutuhan privasi yang ketat, LLaMA adalah pilihan yang fantastis. Jika Anda memprioritaskan kecepatan dan kesederhanaan, alat terintegrasi mungkin lebih cocok.
Dengan ClickUp, Anda mendapatkan Ruang Kerja AI Terintegrasi yang menggabungkan semua tugas, dokumen, dan percakapan Anda dalam satu tempat, didukung oleh AI terintegrasi. Ini mengurangi penyebaran konteks dan membantu tim bekerja lebih cepat dan efektif, dengan informasi yang tepat di ujung jari mereka melalui Super Agents yang dapat disesuaikan dan AI kontekstual.
Hentikan pemborosan waktu pada infrastruktur dan nikmati manfaat asisten AI yang memahami konteks hari ini tanpa perlu membangun dari nol. Mulai secara gratis dengan ClickUp.
Pertanyaan yang Sering Diajukan (FAQ)
Biaya sepenuhnya bergantung pada metode deployment yang Anda pilih, dan perkiraan proyek dapat membantu Anda memperkirakan biayanya. Jika Anda menggunakan hardware sendiri, Anda akan memiliki biaya awal untuk GPU tetapi tidak ada biaya per-query yang berkelanjutan. Penyedia cloud mengenakan tarif per jam berdasarkan ukuran GPU dan model.
Ya, lisensi untuk LLaMA 2 dan LLaMA 3 memungkinkan penggunaan komersial. Namun, Anda harus menyetujui syarat dan ketentuan Meta serta memberikan atribusi yang diperlukan dalam produk Anda.
LLaMA 3 adalah model yang lebih baru dan lebih canggih, menawarkan kemampuan penalaran yang lebih baik dan jendela konteks yang lebih besar (8K token vs. 4K untuk LLaMA 2). Ini berarti model ini dapat menangani percakapan dan dokumen yang lebih panjang, tetapi juga memerlukan sumber daya komputasi yang lebih besar untuk dijalankan.
Meskipun Python adalah bahasa pemrograman paling umum untuk machine learning berkat perpustakaannya yang luas, hal ini tidak mutlak diperlukan. Beberapa platform mulai menawarkan solusi tanpa kode atau dengan kode minimal yang memungkinkan Anda mengimplementasikan chatbot LLaMA melalui antarmuka grafis. /