
Proyek pelatihan AI jarang gagal pada tingkat model. Masalah muncul ketika eksperimen, dokumentasi, dan pembaruan untuk pemangku kepentingan tersebar di terlalu banyak alat.
Panduan ini akan memandu Anda melalui proses melatih model dengan Databricks DBRX—sebuah LLM yang hingga dua kali lebih efisien dalam penggunaan komputasi dibandingkan model-model terkemuka lainnya—sambil menjaga pekerjaan di sekitarnya tetap terorganisir di ClickUp.
Dari pengaturan dan penyempurnaan hingga dokumentasi dan pembaruan lintas tim, Anda akan melihat bagaimana ruang kerja tunggal yang terintegrasi membantu menghilangkan penyebaran konteks dan menjaga tim Anda tetap fokus pada pembangunan, bukan pencarian. 🛠
Apa itu DBRX?
DBRX adalah model bahasa besar (LLM) yang kuat dan open-source, dirancang khusus untuk pelatihan dan inferensi model AI perusahaan. Karena bersifat open-source di bawah lisensi Databricks Open Model License, tim Anda memiliki akses penuh ke bobot dan arsitektur model, memungkinkan Anda untuk memeriksa, memodifikasi, dan mengimplementasikannya sesuai kebutuhan Anda.
Tersedia dalam dua varian: DBRX Base untuk pra-pelatihan mendalam dan DBRX Instruct untuk tugas-tugas mengikuti instruksi secara langsung.
Arsitektur DBRX dan desain campuran ahli
DBRX menyelesaikan tugas menggunakan arsitektur Mixture-of-Experts (MoE). Berbeda dengan model bahasa besar tradisional yang menggunakan semua parameternya yang berjumlah miliaran untuk setiap perhitungan, DBRX hanya mengaktifkan sebagian kecil dari total parameternya (para ahli yang paling relevan) untuk setiap tugas yang diberikan.
Bayangkan ini sebagai tim ahli yang spesialis; alih-alih semua orang menangani setiap masalah, sistem secara cerdas mengalihkan setiap tugas ke parameter yang paling sesuai dan terampil.
Tidak hanya mengurangi waktu respons, tetapi juga memberikan kinerja dan output terbaik sambil secara signifikan mengurangi biaya komputasi.
Berikut ini adalah gambaran singkat tentang spesifikasi utamanya:
- Jumlah parameter: 132 miliar di seluruh model.
- Parameter aktif: 36B per forward pass
- Jumlah ahli: 16 total (MoE Top-4 routing), dengan 4 ahli aktif untuk setiap token.
- Jendela konteks: 32K token
Spesifikasi data pelatihan dan token DBRX
Kinerja sebuah LLM hanya sebaik data yang digunakan untuk melatihnya. DBRX telah dilatih sebelumnya pada dataset besar berukuran 12 triliun token yang dikurasi dengan cermat oleh tim Databricks menggunakan alat pemrosesan data canggih mereka. Itulah mengapa DBRX menunjukkan kinerja yang kuat pada benchmark industri.
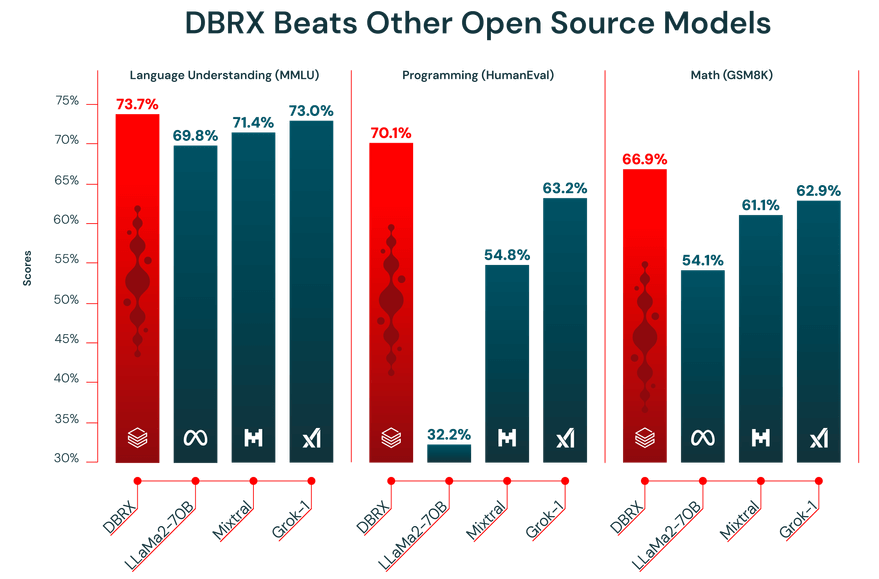
Selain itu, DBRX dilengkapi dengan jendela konteks 32.000 token. Ini adalah jumlah teks yang dapat dipertimbangkan model dalam satu waktu. Jendela konteks yang besar sangat berguna untuk tugas-tugas kompleks seperti merangkum laporan panjang, menganalisis dokumen hukum yang panjang, atau membangun sistem generasi yang diperkuat dengan penelusuran (RAG) canggih, karena memungkinkan model mempertahankan konteks tanpa memotong atau melupakan informasi.
🎥 Tonton video ini untuk melihat bagaimana koordinasi proyek yang terintegrasi dapat mengubah alur kerja pelatihan AI Anda dan menghilangkan hambatan saat beralih antara alat yang terpisah. 👇🏽
Cara Mengakses dan Mengatur DBRX
DBRX menawarkan dua jalur akses utama, keduanya memberikan akses penuh ke bobot model dengan syarat komersial yang fleksibel. Anda dapat menggunakan Hugging Face untuk fleksibilitas maksimal atau mengaksesnya langsung melalui Databricks untuk pengalaman yang lebih terintegrasi.
Akses DBRX melalui Hugging Face
Bagi tim yang mengutamakan fleksibilitas dan sudah terbiasa dengan ekosistem Hugging Face, mengakses DBRX melalui Hub adalah jalur yang ideal. Hal ini memungkinkan Anda mengintegrasikan model ke dalam alur kerja berbasis transformer yang sudah ada.
Begini cara memulainya:
- Buat atau masuk ke akun Hugging Face Anda.
- Buka kartu model DBRX di Hub dan terima syarat lisensi.
- Instal perpustakaan Transformers beserta dependensi yang diperlukan seperti Accelerate.
- Gunakan kelas AutoModelForCausalLM dalam skrip Python Anda untuk memuat model DBRX.
- Konfigurasikan pipeline inferensi Anda, dengan memperhatikan bahwa DBRX memerlukan memori GPU (VRAM) yang signifikan untuk beroperasi secara efektif.
📖 Baca Lebih Lanjut: Cara Mengonfigurasi Suhu LLM
Akses DBRX melalui Databricks
Jika tim Anda sudah menggunakan Databricks untuk data engineering atau machine learning, mengakses DBRX melalui platform tersebut adalah cara termudah. Hal ini menghilangkan hambatan pengaturan dan memberikan semua alat yang Anda butuhkan untuk MLOps tepat di tempat Anda sudah bekerja.
Ikuti langkah-langkah berikut di ruang kerja Databricks Anda untuk memulai:
- Navigasi ke Model Garden atau bagian Mosaic AI.
- Pilih antara DBRX Base atau DBRX Instruct, tergantung pada kebutuhan Anda.
- Konfigurasikan titik akhir layanan untuk akses API atau atur lingkungan notebook untuk penggunaan interaktif.
- Mulai uji inferensi dengan prompt contoh untuk memastikan semuanya berfungsi dengan benar sebelum memperluas pelatihan atau deployment model AI Anda.
Pendekatan ini memberikan akses yang mulus ke alat seperti MLflow untuk pelacakan eksperimen dan Unity Catalog untuk pengelolaan model.
📮 ClickUp Insight: Seorang profesional rata-rata menghabiskan lebih dari 30 menit sehari untuk mencari informasi terkait pekerjaan—itu berarti lebih dari 120 jam setahun terbuang untuk mencari melalui email, obrolan Slack, dan file yang tersebar.
Asisten AI cerdas yang terintegrasi dalam ruang kerja Anda dapat mengubah hal itu. Kenalkan ClickUp Brain.
Ini memberikan wawasan dan jawaban instan dengan menampilkan dokumen, percakapan, dan detail tugas yang tepat dalam hitungan detik—sehingga Anda dapat berhenti mencari dan mulai bekerja.
Cara Menyesuaikan DBRX dan Melatih Model AI Kustom
Model siap pakai, sekuat apa pun, tidak akan pernah memahami nuansa unik bisnis Anda. Karena DBRX bersifat open source, Anda dapat menyesuaikannya untuk membuat model kustom yang sesuai dengan bahasa perusahaan Anda atau melakukan tugas spesifik yang ingin Anda tangani.
Berikut adalah tiga cara umum yang dapat Anda lakukan:
1. Lakukan fine-tuning DBRX menggunakan dataset Hugging Face.
Bagi tim yang baru memulai atau bekerja pada tugas-tugas umum, dataset publik dari Hugging Face Hub merupakan sumber daya yang sangat berguna. Data tersebut sudah diformat dengan baik dan mudah dimuat, artinya Anda tidak perlu menghabiskan berjam-jam untuk menyiapkan data.
Prosesnya cukup sederhana:
- Temukan dataset di Hub yang sesuai dengan tugas Anda (misalnya, mengikuti instruksi, ringkasan).
- Muat menggunakan perpustakaan dataset.
- Pastikan data diformat menjadi pasangan instruksi-respons.
- Konfigurasikan skrip pelatihan Anda dengan hiperparameter seperti laju pembelajaran dan ukuran batch.
- Jalankan tugas pelatihan, pastikan untuk menyimpan titik pemeriksaan secara berkala.
- Evaluasi model yang telah disesuaikan pada set validasi yang disisihkan untuk mengukur peningkatan.
2. Lakukan penyempurnaan DBRX dengan dataset lokal.
Anda biasanya akan mendapatkan hasil terbaik dengan melakukan fine-tuning menggunakan data proprietary Anda sendiri. Hal ini memungkinkan Anda untuk mengajarkan model tersebut terminologi, gaya, dan pengetahuan domain spesifik perusahaan Anda. Perlu diingat bahwa hal ini hanya akan memberikan hasil yang optimal jika data Anda bersih, terorganisir dengan baik, dan memiliki volume yang cukup.
Ikuti langkah-langkah berikut untuk menyiapkan data internal Anda:
- Pengumpulan data: Kumpulkan contoh berkualitas tinggi dari wiki internal, dokumen, dan basis data Anda.
- Konversi format: Susun data Anda ke dalam format instruksi-respons yang konsisten, seringkali dalam bentuk baris JSON.
- Penyaringan kualitas: Hapus contoh-contoh berkualitas rendah, duplikat, atau tidak relevan.
- Pembagian validasi: Sisihkan sebagian kecil data Anda (biasanya 10-15%) untuk mengevaluasi kinerja model.
- Peninjauan privasi: Hapus atau samarkan informasi pribadi yang dapat diidentifikasi (PII) atau data sensitif.
3. Lakukan fine-tuning DBRX dengan StreamingDataset
Jika dataset Anda terlalu besar untuk muat dalam memori mesin, jangan khawatir, Anda dapat menggunakan perpustakaan Streaming Dataset dari Databricks. Perpustakaan ini memungkinkan Anda mengalirkan data langsung dari penyimpanan cloud saat model sedang dilatih, daripada memuat semua data ke dalam memori sekaligus.
Begini cara melakukannya:
- Persiapan data: Bersihkan dan strukturkan data pelatihan Anda, lalu simpan dalam format yang dapat diakses secara streaming seperti JSONL atau CSV di penyimpanan cloud.
- Konversi format streaming: Konversikan dataset Anda ke format yang ramah streaming, seperti Mosaic Data Shard (MDS), sehingga dapat dibaca secara efisien selama proses pelatihan.
- Pengaturan loader pelatihan: Konfigurasikan loader pelatihan Anda untuk mengarah ke dataset jarak jauh dan tentukan cache lokal untuk penyimpanan data sementara.
- Inisialisasi model: Mulai proses penyempurnaan DBRX menggunakan kerangka kerja pelatihan yang mendukung StreamingDataset, seperti LLM Foundry.
- Pelatihan berbasis streaming: Jalankan tugas pelatihan saat data dikirim secara bertahap selama proses pelatihan, daripada memuat seluruh data ke dalam memori.
- Checkpointing dan pemulihan: Lanjutkan pelatihan secara mulus jika proses pelatihan terputus, tanpa perlu menduplikasi atau melewatkan data.
- Evaluasi dan implementasi: Validasi kinerja model yang telah disesuaikan dan implementasikan menggunakan konfigurasi serving atau inferensi pilihan Anda.
💡Tips pro: Daripada membuat rencana pelatihan DBRX dari awal, mulailah dengan templat AI dan Machine Learning Projects Roadmap dari ClickUp dan sesuaikan dengan kebutuhan tim Anda. Templat ini menyediakan struktur yang jelas untuk merencanakan dataset, fase pelatihan, evaluasi, dan deployment, sehingga Anda dapat fokus pada pengorganisasian pekerjaan daripada merancang alur kerja.
Kasus Penggunaan DBRX untuk Pelatihan Model AI
Memiliki model yang kuat adalah satu hal, tetapi mengetahui di mana tepatnya model tersebut unggul adalah hal lain.
Ketika Anda tidak memiliki gambaran yang jelas tentang kelebihan suatu model, mudah untuk menghabiskan waktu dan sumber daya mencoba membuatnya berfungsi di tempat yang sebenarnya tidak cocok. Hal ini menyebabkan hasil yang kurang memuaskan dan frustrasi.
Arsitektur unik DBRX dan data pelatihan yang dimilikinya membuatnya sangat cocok untuk beberapa kasus penggunaan utama di lingkungan perusahaan. Memahami keunggulan ini membantu Anda menyelaraskan model dengan tujuan bisnis Anda dan memaksimalkan pengembalian investasi.
Pembangkitan teks dan pembuatan konten
DBRX Instruct dirancang secara khusus untuk mengikuti instruksi dan menghasilkan teks berkualitas tinggi. Hal ini menjadikannya alat yang powerful untuk mengotomatisasi berbagai tugas terkait konten. Jendela konteks yang besar merupakan keunggulan utama, memungkinkan model ini menangani dokumen panjang tanpa kehilangan alur.
Anda dapat menggunakannya untuk:
- Dokumentasi teknis: Buat dan sempurnakan manual produk, referensi API, dan panduan pengguna.
- Konten pemasaran: Buat draf posting blog, buletin email, dan pembaruan media sosial.
- Pembuatan laporan: Ringkas temuan data yang kompleks dan buat ringkasan eksekutif yang ringkas.
- Terjemahan dan lokalisasi: Sesuaikan konten yang sudah ada untuk pasar dan audiens baru.
Tugas pembangkitan kode dan debugging
Sebagian besar data pelatihan DBRX mencakup kode, menjadikannya dukungan LLM yang handal bagi para pengembang. Hal ini dapat mempercepat siklus pengembangan dengan mengotomatisasi tugas-tugas pemrograman yang berulang dan membantu dalam pemecahan masalah yang kompleks.
Berikut adalah beberapa cara tim teknik Anda dapat memanfaatkannya:
- Pengkodean otomatis: Secara otomatis menghasilkan tubuh fungsi dari komentar atau docstring.
- Deteksi bug: Analisis potongan kode untuk mengidentifikasi potensi kesalahan atau kelemahan logika.
- Penjelasan kode: Terjemahkan algoritma kompleks atau kode warisan menjadi bahasa Inggris yang mudah dipahami.
- Pembuatan tes: Buat tes unit berdasarkan tanda tangan fungsi dan perilaku yang diharapkan.
RAG dan aplikasi dengan konteks panjang
Retrieval-Augmented Generation (RAG) adalah teknik yang kuat yang mendasarkan respons model pada data pribadi perusahaan Anda. Namun, sistem RAG seringkali kesulitan dengan model yang memiliki jendela konteks kecil, memaksa pemotongan data yang agresif yang dapat kehilangan konteks penting. Jendela konteks 32K DBRX menjadikannya dasar yang sangat baik untuk aplikasi RAG yang andal.
Ini memungkinkan Anda membangun alat internal yang kuat, seperti:
- Pencarian perusahaan: Buat chatbot yang menjawab pertanyaan karyawan menggunakan basis pengetahuan internal Anda.
- Dukungan pelanggan: Buat agen yang menghasilkan respons dukungan berdasarkan dokumentasi produk Anda.
- Bantuan penelitian: Kembangkan alat yang dapat mensintesis informasi dari ratusan halaman makalah penelitian.
- Pemeriksaan kepatuhan: Verifikasi otomatis salinan pemasaran sesuai dengan pedoman merek internal atau dokumen regulasi.
Cara Mengintegrasikan Pelatihan DBRX dengan Alur Kerja Tim Anda
Proyek pelatihan model AI yang sukses tidak hanya tentang kode dan komputasi. Ini adalah upaya kolaboratif yang melibatkan insinyur ML, ilmuwan data, manajer produk, dan pemangku kepentingan.
Ketika kolaborasi ini tersebar di Jupyter notebooks, saluran Slack, dan alat manajemen proyek terpisah, Anda menciptakan context sprawl, yaitu situasi di mana informasi proyek kritis tersebar di terlalu banyak alat.
ClickUp menyelesaikannya. Alih-alih menggunakan beberapa alat, Anda mendapatkan satu Converged AI Workspace di mana manajemen proyek, dokumentasi, dan komunikasi berada dalam satu tempat—sehingga eksperimen Anda tetap terhubung dari perencanaan hingga eksekusi hingga evaluasi.
Jangan pernah kehilangan jejak eksperimen dan kemajuan.
Saat menjalankan beberapa eksperimen, bagian tersulit bukanlah melatih model; melainkan melacak perubahan apa yang terjadi selama proses. Versi dataset mana yang digunakan, laju pembelajaran mana yang paling efektif, atau run mana yang dikirimkan?
ClickUp membuat proses ini sangat mudah bagi Anda. Anda dapat melacak setiap sesi pelatihan secara terpisah di ClickUp Tasks, dan di dalam tugas, Anda dapat menggunakan Custom Fields untuk mencatat:
- Versi dataset
- Hiperparameter
- Varian model (DBRX Base vs DBRX Instruct)
- Status pelatihan (Antrian, Berjalan, Evaluasi, Diimplementasikan)
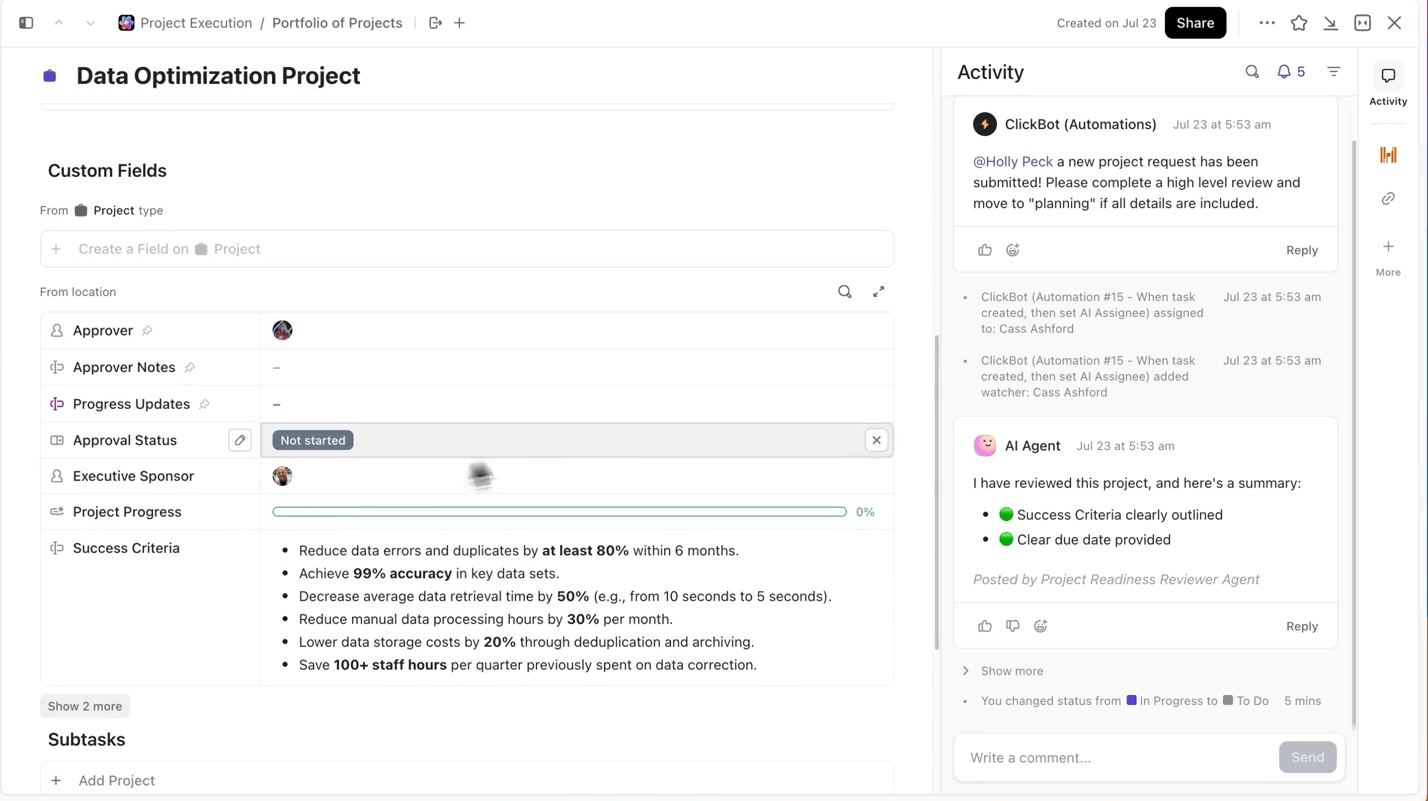
Dengan cara ini, setiap eksperimen yang didokumentasikan dapat dicari, mudah dibandingkan dengan yang lain, dan dapat direproduksi.
Pastikan dokumentasi model tetap terhubung dengan pekerjaan.
Anda tidak perlu berpindah-pindah antara Jupyter notebooks, berkas README, atau obrolan Slack untuk memahami konteks tugas dalam sebuah eksperimen.
Dengan ClickUp Docs, Anda dapat menjaga arsitektur model, skrip persiapan data, atau metrik evaluasi tetap terorganisir dan mudah diakses dengan mendokumentasikannya dalam dokumen yang dapat dicari dan terhubung langsung ke tugas eksperimen asal mereka.

💡Tips Pro: Jaga dokumen proyek yang selalu diperbarui di ClickUp Docs yang menjelaskan setiap keputusan, mulai dari arsitektur hingga deployment, sehingga anggota tim baru dapat dengan mudah memahami detail proyek tanpa harus mencari-cari di thread lama.
Berikan visibilitas kepada pemangku kepentingan secara real-time.
Dashboard ClickUp menampilkan kemajuan eksperimen dan beban kerja tim secara real-time. I
Alih-alih mengompilasi pembaruan secara manual atau mengirim email, dasbor diperbarui secara otomatis berdasarkan data dalam tugas Anda. Sehingga pemangku kepentingan dapat memeriksa kapan saja, melihat perkembangan terkini, dan tidak perlu mengganggu Anda dengan pertanyaan "bagaimana statusnya?".
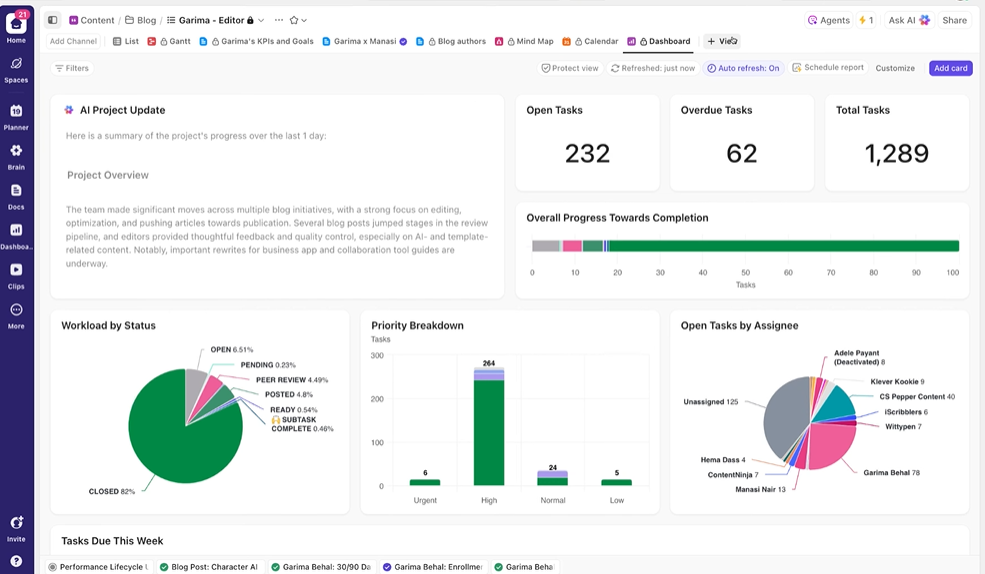
Dengan cara ini, Anda dapat fokus pada pelaksanaan eksperimen daripada harus terus-menerus melaporkannya secara manual.
Jadikan AI sebagai asisten proyek cerdas Anda.
Anda tidak perlu secara manual menggali data pelatihan selama berminggu-minggu untuk mendapatkan ringkasan eksperimen sejauh ini. Cukup sebutkan @Brain pada komentar tugas apa pun, dan ClickUp Brain akan memberikan bantuan yang Anda butuhkan dengan konteks lengkap untuk proyek-proyek masa lalu dan yang sedang berjalan.
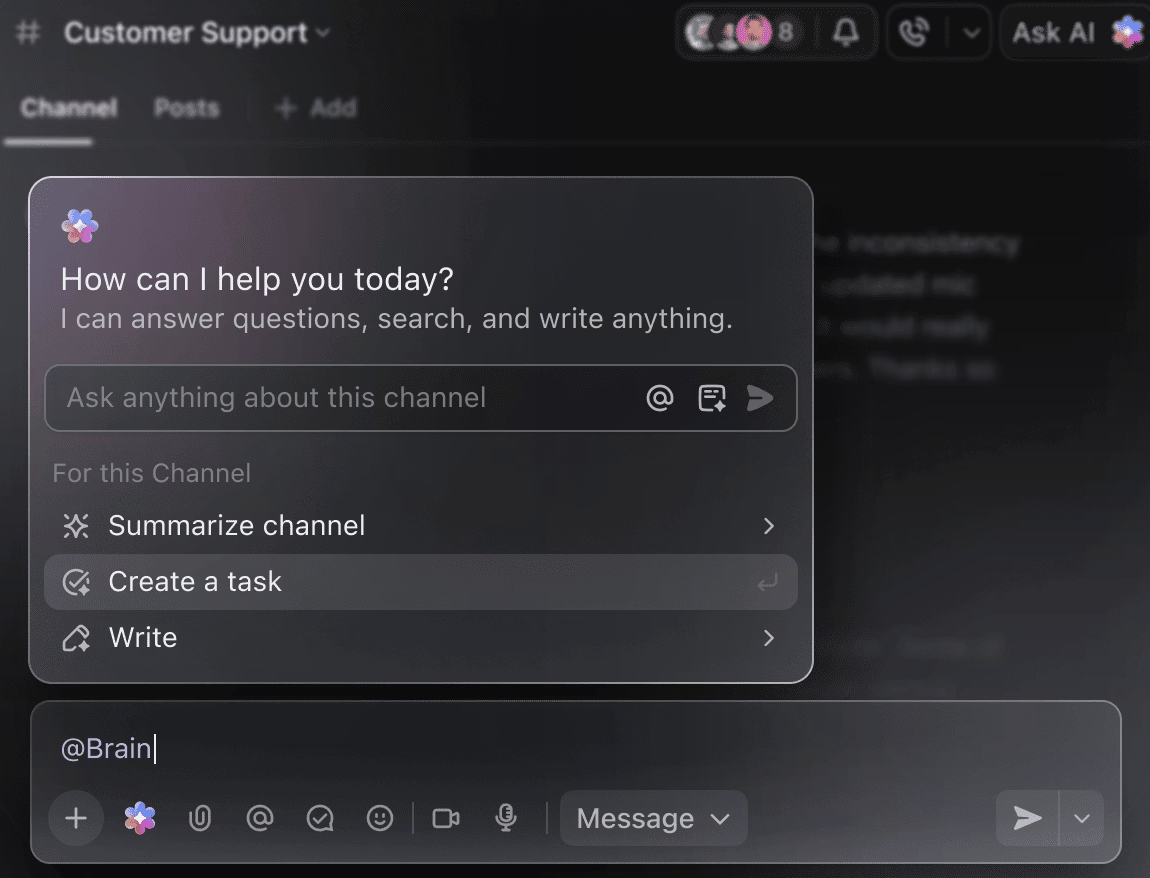
Anda dapat meminta Brain untuk ‘Ringkas eksperimen minggu lalu dalam 5 poin’ atau ‘Buat draf dokumen dengan hasil hyperparameter terbaru,’ dan langsung mendapatkan output yang rapi.
🧠 Keunggulan ClickUp: Super Agents ClickUp membawa ini lebih jauh—mereka dapat mengotomatisasi alur kerja secara keseluruhan berdasarkan pemicu yang Anda tentukan, bukan hanya menjawab pertanyaan Anda. Dengan Super Agents, Anda dapat secara otomatis membuat tugas pelatihan DBRX baru setiap kali dataset diunggah, memberi tahu tim Anda, dan menghubungkan dokumen terkait saat proses pelatihan selesai atau mencapai titik pemeriksaan, serta menghasilkan ringkasan kemajuan mingguan dan mengirimkannya ke pemangku kepentingan tanpa Anda perlu melakukan apa pun.
Kesalahan Umum yang Harus Dihindari
Memulai proyek pelatihan DBRX memang menarik, tetapi beberapa kesalahan umum dapat menghambat kemajuan Anda. Menghindari kesalahan-kesalahan ini akan menghemat waktu, uang, dan banyak frustrasi.
- Mengabaikan persyaratan hardware: DBRX sangat powerful, tetapi juga membutuhkan sumber daya yang besar. Mencoba menjalankannya pada hardware yang tidak memadai akan menyebabkan kesalahan kehabisan memori dan kegagalan tugas pelatihan. Perlu diingat bahwa DBRX (132B) membutuhkan setidaknya 264GB VRAM untuk inferensi 16-bit, atau sekitar 70GB-80GB saat menggunakan kuantisasi 4-bit.
- Mengabaikan pemeriksaan kualitas data: Sampah masuk, sampah keluar. Melakukan fine-tuning pada dataset yang berantakan dan berkualitas rendah hanya akan mengajarkan model untuk menghasilkan output yang berantakan dan berkualitas rendah.
- Mengabaikan batasan panjang konteks: Meskipun jendela konteks 32K DBRX cukup besar, itu tidak tak terbatas. Memberikan masukan model yang melebihi batas ini akan mengakibatkan pemotongan diam-diam dan kinerja yang buruk.
- Menggunakan Base saat Instruct sesuai: DBRX Base adalah model mentah yang telah dilatih sebelumnya, dirancang untuk pelatihan skala besar lebih lanjut. Untuk sebagian besar tugas mengikuti instruksi, Anda sebaiknya memulai dengan DBRX Instruct, yang telah disesuaikan secara khusus untuk tujuan tersebut.
- Memisahkan pekerjaan pelatihan dari koordinasi proyek: Ketika pelacakan eksperimen berada di satu alat dan rencana proyek di alat lain, Anda menciptakan silo informasi. Gunakan platform terintegrasi seperti ClickUp untuk menjaga pekerjaan teknis dan koordinasi proyek tetap sinkron.
- Mengabaikan evaluasi sebelum deployment: Model yang berkinerja baik pada data pelatihan Anda mungkin gagal secara spektakuler di dunia nyata. Selalu validasi model yang telah disesuaikan pada set data uji yang disisihkan sebelum mengimplementasikannya ke produksi.
- Mengabaikan kompleksitas fine-tuning: Karena DBRX adalah model Mixture-of-Experts, skrip fine-tuning standar mungkin memerlukan perpustakaan khusus seperti Megatron-LM atau PyTorch FSDP untuk menangani pembagian parameter di antara beberapa GPU.
DBRX vs. Platform Pelatihan AI Lainnya
Memilih platform pelatihan AI melibatkan pertukaran fundamental: kontrol versus kenyamanan. Model eksklusif yang hanya menggunakan API mudah digunakan tetapi mengunci Anda dalam ekosistem vendor.
Model AI terbuka seperti DBRX menawarkan kontrol penuh tetapi memerlukan keahlian teknis dan infrastruktur yang lebih besar. Pilihan ini dapat membuat Anda merasa bingung, tidak yakin mana yang sebenarnya mendukung tujuan jangka panjang Anda—tantangan yang banyak dihadapi tim selama adopsi AI.
Tabel ini memaparkan perbedaan utama untuk membantu Anda membuat keputusan yang terinformasi.
| Bobot | Buka (Kustom) | Proprietary | Buka (Kustom) | Proprietary |
| Penyesuaian | Kontrol Penuh | Berbasis API | Kontrol Penuh | Berbasis API |
| Self-hosting | Ya | Tidak | Ya | Tidak |
| Lisensi | DB Open Model | Syarat dan Ketentuan OpenAI | Komunitas Llama | Istilah Anthropic |
| Kontekstual | 32K | 128K – 1M | 128K | 200K – 1M |
DBRX adalah pilihan yang tepat ketika Anda membutuhkan kendali penuh atas model, harus menghosting sendiri untuk keamanan atau kepatuhan, atau menginginkan fleksibilitas lisensi komersial yang permisif. Jika Anda tidak memiliki infrastruktur GPU khusus—atau Anda lebih mengutamakan kecepatan masuk pasar daripada kustomisasi mendalam—alternatif berbasis API mungkin lebih cocok.
Mulai Latih AI dengan Lebih Cerdas Menggunakan ClickUp
DBRX memberikan fondasi yang siap digunakan untuk membangun aplikasi AI kustom, dengan transparansi dan kontrol yang tidak Anda dapatkan dari model proprietary. Arsitektur MoE yang efisiennya menjaga biaya inferensi tetap rendah, dan desain terbuka membuat penyesuaian model menjadi mudah. Namun, teknologi yang kuat hanyalah setengah dari persamaan.
Kesuksesan sejati berasal dari menyelaraskan pekerjaan teknis Anda dengan alur kerja kolaboratif tim Anda. Pelatihan model AI adalah pekerjaan tim, dan menjaga eksperimen, dokumentasi, dan komunikasi dengan pemangku kepentingan tetap sinkron sangat penting. Ketika Anda mengintegrasikan semuanya ke dalam satu ruang kerja terpadu dan mengurangi penyebaran konteks, Anda dapat menghasilkan model yang lebih baik dengan lebih cepat.
Mulai secara gratis dengan ClickUp untuk mengoordinasikan proyek pelatihan AI Anda dalam satu ruang kerja. ✨
Pertanyaan yang Sering Diajukan
Anda dapat memantau pelatihan menggunakan alat ML standar seperti TensorBoard, Weights & Biases, atau MLflow. Jika Anda melatih model di ekosistem Databricks, MLflow terintegrasi secara native untuk pelacakan eksperimen yang lancar.
Ya, DBRX dapat diintegrasikan ke dalam pipeline MLOps standar. Dengan mengontainerisasi model, Anda dapat mengimplementasikannya menggunakan platform orkestrasi seperti Kubeflow atau alur kerja CI/CD kustom.
DBRX Base adalah model pra-latih dasar yang dirancang untuk tim yang ingin melakukan pra-latih lanjutan spesifik domain atau penyesuaian arsitektur mendalam. DBRX Instruct adalah versi yang telah disesuaikan secara optimal untuk mengikuti instruksi, menjadikannya titik awal yang lebih baik untuk sebagian besar pengembangan aplikasi.
Perbedaan utamanya adalah kontrol. DBRX memberikan akses penuh ke bobot model untuk penyesuaian mendalam dan hosting mandiri, sedangkan GPT-4 adalah layanan berbasis API saja.
Bobot model DBRX tersedia secara gratis di bawah Lisensi Model Terbuka Databricks. Namun, Anda bertanggung jawab atas biaya infrastruktur komputasi yang diperlukan untuk menjalankan atau menyesuaikan model tersebut.