

فتحت نماذج اللغات الكبيرة (LLMs) إمكانيات جديدة ومثيرة لتطبيقات البرمجيات. فهي تتيح أنظمة أكثر ذكاءً وديناميكية من أي وقت مضى.
ويتوقع الخبراء أنه بحلول عام 2025، يمكن للتطبيقات التي تعمل بهذه النماذج أن تقوم بأتمتة ما يقرب من نصف جميع الأعمال الرقمية .
ومع ذلك، بينما نطلق العنان لهذه الإمكانيات، يلوح في الأفق تحدٍ: كيف يمكننا قياس جودة مخرجاتها بشكل موثوق على نطاق واسع؟ أي تعديل بسيط في الإعدادات، وفجأة ستجد مخرجات مختلفة بشكل ملحوظ. هذا التباين يمكن أن يجعل من الصعب قياس أدائها، وهو أمر بالغ الأهمية عند إعداد نموذج للاستخدام في العالم الحقيقي.
ستشارك هذه المقالة رؤى حول أفضل ممارسات تقييم نظام LLM، بدءًا من اختبار ما قبل النشر إلى الإنتاج. لذا، لنبدأ!
ما هو تقييم نظام LLM؟
مقاييس تقييم نظام LLM هي طريقة لمعرفة ما إذا كانت مطالباتك أو إعدادات النموذج أو سير العمل تحقق الأهداف التي حددتها. تمنحك هذه المقاييس رؤى حول مدى نجاح نموذج اللغة الكبير وما إذا كان جاهزًا حقًا للاستخدام في العالم الحقيقي.
واليوم، تقيس بعض المقاييس الأكثر شيوعًا استدعاء السياق في مهام التوليد المعزز للاسترجاع (RAG)، والمطابقات التامة للتصنيفات، والتحقق من صحة JSON للمخرجات المهيكلة، والتشابه الدلالي للمهام الأكثر إبداعًا.
يضمن كل مقياس من هذه المقاييس بشكل فريد أن يفي LLM بمعايير حالة الاستخدام الخاصة بك.
لماذا تحتاج إلى تقييم LLM؟
يتم الآن استخدام نماذج اللغات الكبيرة (LLMs) عبر مجموعة واسعة من التطبيقات. من الضروري تقييم أداء النماذج للتأكد من أنها تفي بالمعايير المتوقعة وتخدم الأغراض المقصودة منها بفعالية.
فكر في الأمر بهذه الطريقة: تعمل النماذج اللغوية الكبيرة على تشغيل كل شيء بدءاً من روبوتات الدردشة الآلية لدعم العملاء إلى الأدوات الإبداعية، وكلما أصبحت أكثر تقدماً، أصبحت تظهر في أماكن أكثر.
وهذا يعني أننا بحاجة إلى طرق أفضل لمراقبتها وتقييمها - فالطرق التقليدية لا يمكنها مواكبة جميع المهام التي تتعامل معها هذه النماذج.
تُعد مقاييس التقييم الجيدة بمثابة فحص جودة للنماذج ذات المستوى المنخفض. فهي تُظهر ما إذا كان النموذج موثوقًا ودقيقًا وفعالًا بما يكفي للاستخدام في العالم الحقيقي. بدون هذه الفحوصات، يمكن أن تفلت الأخطاء، مما يؤدي إلى تجارب مستخدمين محبطة أو حتى مضللة.
عندما يكون لديك مقاييس تقييم قوية، يكون من الأسهل اكتشاف المشاكل وتحسين النموذج والتأكد من أنه جاهز لتلبية الاحتياجات المحددة لمستخدميه. بهذه الطريقة، أنت تعرف منصة الذكاء الاصطناعي التي تعمل بها على مستوى قياسي ويمكنها تقديم النتائج التي تحتاجها.
📖 اقرأ المزيد: الذكاء الاصطناعي التوليدي مقابل الذكاء الاصطناعي التوليدي: دليل تفصيلي
أنواع تقييمات LLM ## أنواع تقييمات LLM
توفر التقييمات عدسة فريدة لفحص قدرات النموذج. يعالج كل نوع جوانب الجودة المختلفة، مما يساعد على بناء نموذج نشر موثوق وآمن وفعال.
فيما يلي الأنواع المختلفة لطرق تقييم LLM:
- التقييم الداخلي يركز على الأداء الداخلي للنموذج على مهام لغوية أو فهمية محددة دون إشراك تطبيقات العالم الحقيقي. ويتم إجراؤه عادةً خلال مرحلة تطوير النموذج لفهم القدرات الأساسية
- التقييم الخارجي يقيّم أداء النموذج في تطبيقات العالم الحقيقي. يفحص هذا النوع من التقييم مدى تلبية النموذج لأهداف محددة ضمن سياق معين
- تقييم المتانة يختبر ثبات النموذج وموثوقيته في سيناريوهات متنوعة، بما في ذلك المدخلات غير المتوقعة والظروف الصعبة. وهو يحدد نقاط الضعف المحتملة، ويضمن أن النموذج يتصرف بشكل متوقع
- اختبار الكفاءة والكمون يفحص استخدام موارد النموذج وسرعته ووقت الاستجابة. يضمن قدرة النموذج على أداء المهام بسرعة وبتكلفة حسابية معقولة، وهو أمر ضروري لقابلية التوسع
- تقييم الأخلاقيات والسلامة يضمن توافق النموذج مع المعايير الأخلاقية وإرشادات السلامة، وهو أمر حيوي في التطبيقات الحساسة
تقييمات نموذج LLM مقابل تقييمات نظام LLM
يتضمن تقييم النماذج اللغوية الكبيرة نهجين رئيسيين: تقييمات النموذج وتقييمات النظام. يركز كل منهما على جوانب مختلفة من أداء النماذج اللغوية الكبيرة، ومعرفة الفرق بينهما أمر ضروري لتعظيم إمكانات هذه النماذج
🧠 تنظر تقييمات النماذج في المهارات العامة لآلية التعلم الآلي. يختبر هذا النوع من التقييم قدرة النموذج على فهم اللغة وتوليدها والتعامل معها بدقة في سياقات مختلفة. إنه أشبه برؤية مدى قدرة النموذج على التعامل مع المهام المختلفة، تقريبًا كاختبار ذكاء عام.
**على سبيل المثال، قد تطرح تقييمات النماذج السؤال التالي: "ما مدى تنوع هذا النموذج؟
🎯 تقيس تقييمات النظام كيفية أداء نموذج LLM ضمن إعداد أو غرض معين، كما هو الحال في روبوت الدردشة الآلية لخدمة العملاء. هنا، لا يتعلق الأمر هنا بالقدرات الواسعة للنموذج بقدر ما يتعلق بكيفية أدائه لمهام محددة لتحسين تجربة المستخدم.
**ومع ذلك، تركز تقييمات النظام على أسئلة مثل "ما مدى جودة تعامل النموذج مع هذه المهمة المحددة للمستخدمين؟
تساعد تقييمات النماذج المطورين على فهم القدرات والقيود العامة للنموذج، وتوجيه التحسينات. تركز تقييمات النظام على مدى تلبية النموذج لاحتياجات المستخدم في سياقات محددة، مما يضمن تجربة أكثر سلاسة للمستخدم.
توفر هذه التقييمات مجتمعةً صورة كاملة عن نقاط قوة آلية التعلم الآلي ومجالات التحسين فيها، مما يجعلها أكثر قوة وسهولة في التطبيقات الحقيقية.
والآن، دعونا نستكشف المقاييس المحددة لتقييم LLM.
مقاييس تقييم LLM
تتضمن بعض مقاييس التقييم الموثوقة والعصرية ما يلي:
1. الحيرة
يقيس التعقيد مدى جودة تنبؤ النموذج اللغوي لتسلسل الكلمات. وهو يشير بشكل أساسي إلى مدى عدم يقين النموذج بشأن الكلمة التالية في الجملة. انخفاض درجة التعقيد يعني أن النموذج أكثر ثقة في تنبؤاته، مما يؤدي إلى أداء أفضل.
📌مثال:** تخيل أن نموذجًا يولد نصًا من المطالبة "جلست القطة على ال." إذا تنبأ النموذج باحتمالية عالية لكلمات مثل "حصيرة" و"أرضية"، فإنه يفهم السياق جيدًا، مما يؤدي إلى درجة تعقيد منخفضة.
من ناحية أخرى، إذا كان يقترح كلمة غير ذات صلة مثل "سفينة الفضاء"، فإن درجة الحيرة ستكون أعلى، مما يشير إلى أن النموذج يكافح لتوقع نص معقول.
2. درجة BLEU
تُستخدم درجة BLEU (تقييم ثنائي اللغة Understudy) في المقام الأول لتقييم الترجمة الآلية وتقييم توليد النص.
يقيس عدد ن-غرامات (تسلسلات متجاورة من العناصر n من عينة نصية معينة) في المخرجات التي تتداخل مع تلك الموجودة في نص مرجعي واحد أو أكثر. تتراوح الدرجة من 0 إلى 1، حيث تشير الدرجات الأعلى إلى أداء أفضل.
📌مثال:** إذا كان نموذجك يولد جملة "الثعلب البني السريع يقفز فوق الكلب الكسول" والنص المرجعي هو "الثعلب البني السريع يقفز فوق الكلب الكسول"، فإن BLEU سيقارن بين الجمل النونية المشتركة.
تشير الدرجة العالية إلى أن الجملة التي تم إنشاؤها تتطابق بشكل وثيق مع النص المرجعي، بينما قد تشير الدرجة المنخفضة إلى أن الناتج الذي تم إنشاؤه لا يتوافق بشكل جيد.
3. درجة F1
إن مقياس تقييم درجة F1 LLM هو في المقام الأول لمهام التصنيف. وهو يقيس التوازن بين الدقة (دقة التنبؤات الإيجابية) والاستدعاء (القدرة على تحديد جميع الحالات ذات الصلة)
يتراوح من 0 إلى 1، حيث تشير الدرجة 1 إلى الدقة التامة.
📌مثال:** في مهمة الإجابة عن سؤال، إذا سُئل النموذج "ما لون السماء؟" وأجاب ب "السماء زرقاء" (إجابة إيجابية صحيحة) ولكن يتضمن أيضًا "السماء خضراء" (إجابة إيجابية خاطئة)، فإن درجة F1 ستأخذ في الاعتبار أهمية الإجابة الصحيحة والإجابة الخاطئة.
يساعد هذا المقياس على ضمان تقييم متوازن لأداء النموذج.
4. ميتور
يتجاوز مقياس METEOR (مقياس تقييم الترجمة مع المطابقة الصريحة) المطابقة التامة للكلمات. إنه يأخذ في الاعتبار المترادفات والجذعية وإعادة الصياغة لتقييم التشابه بين النص الذي تم إنشاؤه والنص المرجعي. يهدف هذا المقياس إلى التوافق بشكل أوثق مع الحكم البشري.
📌 📌مثال:** إذا قام نموذجك بتوليد "استندت القطة على السجادة" وكان المرجع هو "استلقت القطة على السجادة"، فإن METEOR سيعطي هذا المقياس درجة أعلى من BLEU لأنه يدرك أن "القطط" مرادف لكلمة "قطة" وأن "السجادة" و"السجادة" تحملان معاني متشابهة.
وهذا يجعل METEOR مفيدًا بشكل خاص في التقاط الفروق الدقيقة في اللغة.
5. بيرتسكور
يُقيّم BERTScore تشابه النص استنادًا إلى التضمينات السياقية المستمدة من نماذج مثل BERT (تمثيلات التشفير ثنائية الاتجاه من المحولات). وهو يركز على المعنى أكثر من تركيزه على التطابق الدقيق للكلمات، مما يسمح بتقييم تشابه دلالي أفضل**
📌 مثال:** عند المقارنة بين جملتي "تسابقت السيارة على الطريق" و"انطلقت السيارة على طول الشارع"، يحلل BERTScore المعاني الأساسية بدلاً من مجرد اختيار الكلمات.
على الرغم من اختلاف الكلمات، إلا أن الأفكار العامة متشابهة، مما يؤدي إلى الحصول على درجة BERTScore عالية تعكس فعالية المحتوى الذي تم إنشاؤه.
6. التقييم البشري
يظل التقييم البشري جانبًا حاسمًا في تقييم LLM. يتضمن التقييم البشري تقييم القضاة البشريين لجودة مخرجات النموذج استنادًا إلى معايير مختلفة مثل الطلاقة والملاءمة. يمكن استخدام تقنيات مثل مقاييس Likert واختبار A/B لجمع الملاحظات.
📌مثال:** بعد توليد الردود من روبوت الدردشة الآلية لخدمة العملاء، قد يقوم المقيّمون البشريون بتقييم كل رد على مقياس من 1 إلى 5. على سبيل المثال، إذا قدم روبوت الدردشة الآلي إجابة واضحة ومفيدة على استفسار العميل، فقد يحصل على 5، بينما قد يحصل الرد الغامض أو المربك على 2.
7. مقاييس خاصة بالمهام
تتطلب مهام LLM المختلفة مقاييس تقييم مصممة خصيصًا.
بالنسبة لأنظمة الحوار، يمكن أن تقيّم المقاييس مشاركة المستخدم أو معدلات إنجاز المهام. وبالنسبة لتوليد التعليمات البرمجية، يمكن قياس النجاح من خلال عدد مرات تجميع التعليمات البرمجية التي تم إنشاؤها أو اجتيازها للاختبارات.
📌مثال:** في روبوت الدردشة الآلية لدعم العملاء، يمكن قياس مستويات المشاركة من خلال مدة بقاء المستخدمين في المحادثة أو عدد أسئلة المتابعة التي يطرحونها.
إذا كان المستخدمون يطلبون معلومات إضافية بشكل متكرر، فهذا يشير إلى أن النموذج يشركهم بنجاح ويعالج استفساراتهم بفعالية.
8. المتانة والإنصاف
ينطوي تقييم متانة النموذج على اختبار مدى استجابته للمدخلات غير المتوقعة أو غير الاعتيادية. تساعد مقاييس الإنصاف في تحديد التحيزات في مخرجات النموذج، مما يضمن أداءه بشكل متساوٍ عبر مختلف الفئات السكانية والسيناريوهات.
📌مثال: عند اختبار نموذج بسؤال غريب الأطوار مثل "ما رأيك في وحيد القرن؟" يجب أن يتعامل النموذج مع السؤال برشاقة ويقدم إجابة ذات صلة. إذا أعطى بدلاً من ذلك إجابة غير منطقية أو غير مناسبة، فهذا يشير إلى نقص في المتانة.
يضمن اختبار الإنصاف أن النموذج لا ينتج مخرجات متحيزة أو ضارة، مما يعزز من شمولية النموذج نظام ذكاء اصطناعي .
📖 اقرأ المزيد: الفرق بين التعلم الآلي والذكاء الاصطناعي
9. مقاييس الكفاءة
مع ازدياد تعقيد النماذج اللغوية، تزداد أهمية قياس كفاءتها بما يتعلق بالسرعة واستخدام الذاكرة واستهلاك الطاقة. تساعد مقاييس الكفاءة في تقييم مدى استهلاك النموذج للموارد عند توليد الاستجابات.
📌مثال: بالنسبة لنموذج لغوي كبير، قد يتضمن قياس الكفاءة تتبع سرعة توليد الإجابات على استفسارات المستخدم ومقدار الذاكرة التي يستخدمها أثناء هذه العملية.
إذا استغرق وقتًا طويلاً جدًا للاستجابة أو استهلك موارد زائدة، فقد يكون ذلك مصدر قلق للتطبيقات التي تتطلب أداءً في الوقت الفعلي، مثل روبوتات الدردشة أو خدمات الترجمة.
الآن، أنت تعرف كيفية تقييم نموذج LLM. لكن ما هي الأدوات التي يمكنك استخدامها لقياس ذلك؟ دعنا نستكشف ذلك.
كيف يمكن لـ ClickUp Brain تحسين تقييم نموذج LLM
ClickUp هو تطبيق لكل شيء من أجل العمل مع مساعد شخصي مدمج يسمى ClickUp Brain. ClickUp Brain هو مغيّر لقواعد اللعبة في تقييم أداء برنامج LLM. فماذا يفعل؟
يقوم بتنظيم وإبراز البيانات الأكثر صلة بالموضوع، مما يبقي فريقك على المسار الصحيح. بفضل ميزاته المدعومة بالذكاء الاصطناعي، يُعد ClickUp Brain واحدًا من أفضل برنامج الشبكة العصبية هناك. فهو يجعل العملية برمتها أكثر سلاسة وكفاءة وتعاوناً من أي وقت مضى. دعنا نستكشف قدراته معًا.
إدارة المعرفة الذكية
عند تقييم النماذج اللغوية الكبيرة (LLMs)، قد تكون إدارة كميات هائلة من البيانات أمراً مربكاً.

تلخيص البيانات وتبسيط تتبع مقاييس الأداء باستخدام ClickUp Brain ClickUp Brain تنظيم وتسليط الضوء على المقاييس والموارد الأساسية المصممة خصيصًا لتقييم الماجستير والدكتوراه. فبدلاً من البحث في جداول البيانات المبعثرة والتقارير الكثيفة، يجمع ClickUp Brain كل شيء في مكان واحد. يمكن الوصول إلى مقاييس الأداء وبيانات المقارنة المعيارية ونتائج الاختبارات في واجهة واضحة وسهلة الاستخدام.
يساعد هذا التنظيم فريقك على التخلص من الضوضاء والتركيز على الرؤى المهمة حقًا، مما يسهل تفسير الاتجاهات وأنماط الأداء.
مع وجود كل ما تحتاجه في مكان واحد، يمكنك الانتقال من مجرد جمع البيانات إلى اتخاذ قرارات مؤثرة تعتمد على البيانات، وتحويل المعلومات الزائدة إلى معلومات استخباراتية قابلة للتنفيذ.
تخطيط المشاريع وإدارة سير العمل
تتطلب تقييمات LLM تخطيطاً وتعاوناً دقيقين، ويجعل ClickUp إدارة هذه العملية أمراً سهلاً.
يمكنك بسهولة تفويض المسؤوليات مثل جمع البيانات والتدريب على النماذج واختبار الأداء مع تحديد الأولويات للتأكد من أن المهام الأكثر أهمية تحظى بالاهتمام أولاً. بالإضافة إلى ذلك، تسمح لك الحقول المخصصة بتخصيص مهام سير العمل حسب الاحتياجات المحددة لمشروعك.

إنشاء وتعيين المهام وتبسيط سير العمل باستخدام الذكاء الاصطناعي في ClickUp
باستخدام ClickUp، يمكن للجميع معرفة من يقوم بماذا ومتى، مما يساعد على تجنب التأخير والتأكد من أن المهام تتحرك بسلاسة عبر الفريق. إنها طريقة رائعة للحفاظ على تنظيم كل شيء وعلى المسار الصحيح من البداية إلى النهاية.
تتبع المقاييس من خلال لوحات المعلومات المخصصة
هل تريد مراقبة أداء أنظمة LLM الخاصة بك عن كثب؟ ClickUp Dashboards تصور مؤشرات الأداء في الوقت الفعلي. فهي تمكنك من مراقبة تقدم نموذجك على الفور. لوحات المعلومات هذه قابلة للتخصيص بدرجة كبيرة، مما يتيح لك إنشاء رسوم بيانية ومخططات تعرض ما تحتاجه بالضبط عندما تحتاج إليه.
يمكنك مشاهدة تطوّر دقة نموذجك عبر مراحل التقييم أو تحليل استهلاك الموارد في كل مرحلة. تسمح لك هذه المعلومات باكتشاف الاتجاهات بسرعة، وتحديد مجالات التحسين، وإجراء التعديلات على الفور.
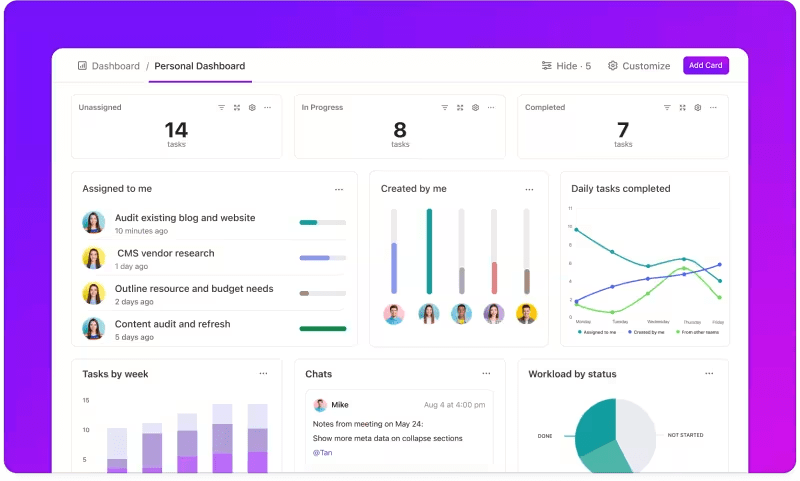
عرض التقدم المحرز في تقييمك في لمحة واحدة في لوحات معلومات ClickUp Dashboards
بدلاً من انتظار التقرير التفصيلي التالي, ClickUp Dashboards تتيح لك البقاء على اطلاع وسريع الاستجابة، وتمكين فريقك من اتخاذ قرارات قائمة على البيانات دون تأخير.
رؤى آلية
يمكن أن يستغرق تحليل البيانات وقتًا طويلاً، ولكن ميزات ClickUp Brain تخفيف العبء من خلال توفير رؤى قيمة. فهو يسلط الضوء على الاتجاهات المهمة بل ويقترح توصيات بناءً على البيانات، مما يسهل استخلاص استنتاجات ذات مغزى.
مع رؤى ClickUp Brain الآلية، لا حاجة إلى تمشيط البيانات الأولية بحثًا عن الأنماط يدويًا، بل يكتشفها لك. تعمل هذه الأتمتة على تحرير فريقك للتركيز على تحسين أداء النموذج بدلاً من الانغماس في تحليل البيانات المتكرر.
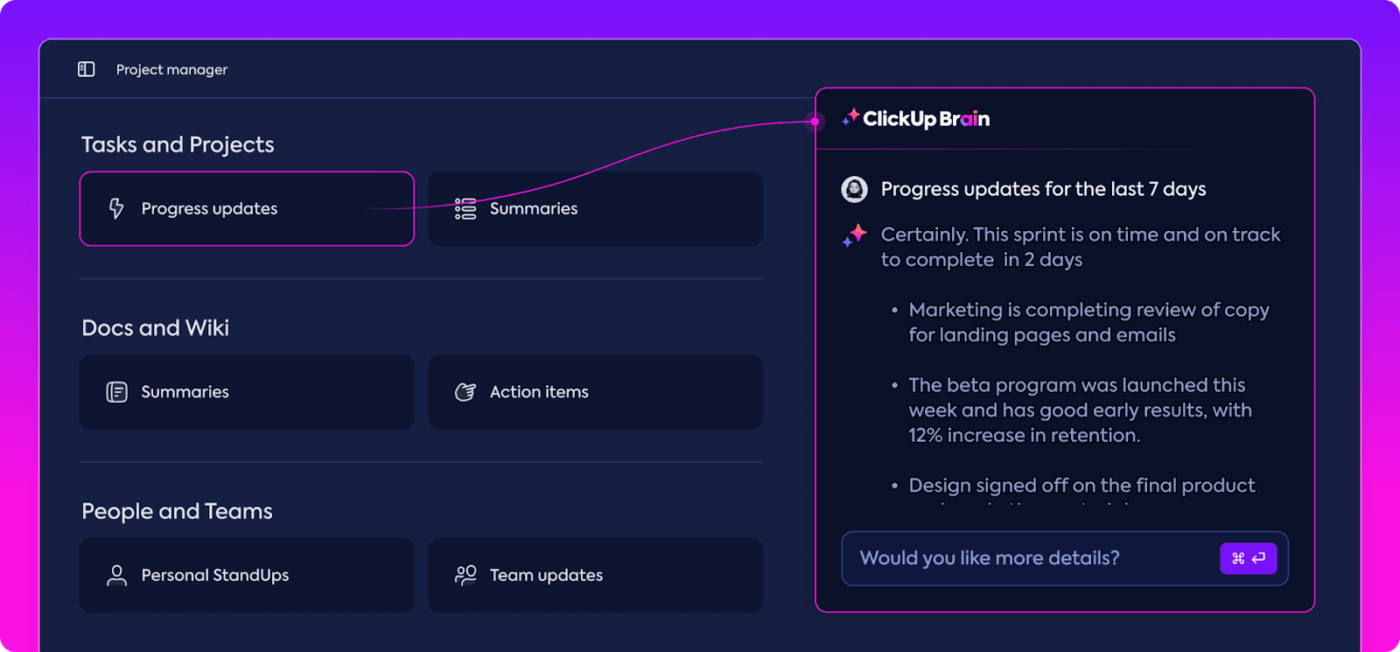
الحصول على رؤى قابلة للتنفيذ باستخدام ClickUp Brain
تكون الرؤى التي تم إنشاؤها جاهزة للاستخدام، مما يسمح لفريقك بمعرفة ما الذي يعمل على الفور وأين قد تكون هناك حاجة إلى إجراء تغييرات. من خلال تقليل الوقت المستغرق في التحليل، يساعد ClickUp فريقك على تسريع عملية التقييم والتركيز على التنفيذ.
التوثيق والتعاون
لا مزيد من البحث في رسائل البريد الإلكتروني أو منصات متعددة للعثور على ما تحتاج إليه؛ كل شيء موجود وجاهز عندما تكون جاهزًا. مستندات ClickUp هو مركز مركزي يجمع كل ما يحتاجه فريقك لإجراء تقييم سلس لإدارة التعلم الآلي. فهو ينظم وثائق المشروع الرئيسية - مثل معايير القياس ونتائج الاختبار وسجلات الأداء - في مكان واحد يسهل الوصول إليه حتى يتمكن الجميع من الوصول بسرعة إلى أحدث المعلومات.
ما يميز ClickUp Docs حقًا هو ميزات التعاون في الوقت الفعلي. الميزة المدمجة ClickUp Chat و
/مرجع/ https://clickup.com/features/assign-comments تعليقات /%href/
السماح لأعضاء الفريق بمناقشة الرؤى وإبداء الملاحظات واقتراح التغييرات مباشرةً داخل المستندات.
وهذا يعني أنه يمكن لفريقك مناقشة النتائج وإجراء التعديلات مباشرةً على المنصة، مما يجعل جميع المناقشات ذات صلة بالموضوع.

تعاون وتحرير مستندات ClickUp مع فريقك في الوقت الفعلي
كل شيء من التوثيق إلى العمل الجماعي يحدث داخل مستندات ClickUp Docs، مما يخلق عملية تقييم مبسطة حيث يمكن للجميع الاطلاع على آخر التطورات ومشاركتها والتصرف بناءً عليها.
والنتيجة؟ سير عمل سلس وموحد يتيح لفريقك التحرك نحو أهدافه بوضوح تام.
هل أنت مستعد لتجربة ClickUp؟ قبل ذلك، دعنا نناقش بعض النصائح والحيل لتحقيق أقصى استفادة من تقييم LLM الخاص بك.
أفضل الممارسات في تقييم LLM ## أفضل الممارسات في تقييم LLM
يضمن اتباع نهج منظم بشكل جيد لتقييم LLM أن النموذج يلبي احتياجاتك، ويتماشى مع توقعات المستخدم، ويقدم نتائج مفيدة.
يساعد تحديد أهداف واضحة ومراعاة المستخدمين النهائيين واستخدام مجموعة متنوعة من المقاييس في تشكيل تقييم شامل يكشف عن نقاط القوة ومجالات التحسين. فيما يلي بعض أفضل الممارسات لتوجيه عمليتك.
🎯 تحديد أهداف واضحة
قبل البدء في عملية التقييم، من الضروري أن تعرف بالضبط ما الذي تريد أن يحققه نموذج اللغة الكبيرة الخاص بك (LLM). خذ وقتك في تحديد المهام أو الأهداف المحددة للنموذج.
📌مثال: إذا كنت ترغب في تحسين أداء الترجمة الآلية، قم بتوضيح مستويات الجودة التي تريد الوصول إليها. إن وجود أهداف واضحة يساعدك على التركيز على المقاييس الأكثر صلة بالموضوع، مما يضمن أن يظل تقييمك متوافقًا مع هذه الأهداف ويقيس النجاح بدقة.
👥 ضع في اعتبارك جمهورك
فكر في الأشخاص الذين سيستخدمون آلية التعلم مدى الحياة وما هي احتياجاتهم. إن تكييف التقييم مع المستخدمين المستهدفين أمر بالغ الأهمية.
📌 على سبيل المثال:** إذا كان الهدف من نموذجك هو إنشاء محتوى جذاب، فستحتاج إلى إيلاء اهتمام وثيق لمقاييس مثل الطلاقة والتماسك. يساعد فهم جمهورك على تحسين معايير التقييم الخاصة بك، والتأكد من أن النموذج يقدم قيمة حقيقية في التطبيقات العملية
📊 استخدم مقاييس متنوعة
لا تعتمد على مقياس واحد فقط لتقييم نموذجك لتقييم نموذجك؛ فمزيج من المقاييس يمنحك صورة أكمل عن أدائه. يلتقط كل مقياس جوانب مختلفة، لذا فإن استخدام العديد من المقاييس يمكن أن يساعدك في تحديد نقاط القوة والضعف على حد سواء.
📌مثال: في حين أن درجات BLEU رائعة لقياس جودة الترجمة، إلا أنها قد لا تغطي جميع الفروق الدقيقة في الكتابة الإبداعية. يمكن أن يؤدي دمج مقاييس مثل الحيرة للدقة التنبؤية وحتى التقييمات البشرية للسياق إلى فهم أكثر شمولاً لمدى جودة أداء نموذجك
مقاييس وأدوات LLM المعيارية
غالبًا ما يعتمد تقييم النماذج اللغوية الكبيرة (LLMs) على معايير قياسية وأدوات متخصصة تساعد في قياس أداء النموذج في مختلف المهام.
فيما يلي تفصيل لبعض المعايير والأدوات المستخدمة على نطاق واسع والتي تضفي هيكلاً ووضوحًا على عملية التقييم.
المعايير الرئيسية
- تقييم فهم اللغة العام: يقيّم هذا المعيار قدرات النماذج عبر مهام لغوية متعددة، بما في ذلك تصنيف الجمل والتشابه والاستدلال. إنه معيار مرجعي للنماذج التي تحتاج إلى التعامل مع فهم اللغة للأغراض العامة
- SQuAD (مجموعة بيانات ستانفورد للإجابة على الأسئلة): يعتبر إطار تقييم SQuAD مثاليًا لفهم القراءة ويقيس مدى جودة النموذج في الإجابة على الأسئلة بناءً على مقطع نصي. وهو يُستخدم عادةً في مهام مثل دعم العملاء والاسترجاع القائم على المعرفة، حيث تكون الإجابات الدقيقة حاسمة
- SuperGLUE: كنسخة محسّنة من GLUE، يقوم SuperGLUE بتقييم النماذج على مهام أكثر تعقيدًا في التفكير وفهم السياق. يوفر رؤى أعمق، خاصةً للتطبيقات التي تتطلب فهمًا لغويًا متقدمًا
أدوات التقييم الأساسية
- وجه العناق : يحظى بشعبية واسعة بسبب مكتبة النماذج الواسعة ومجموعات البيانات وميزات التقييم. تسمح واجهته البديهية للغاية للمستخدمين بتحديد المعايير بسهولة، وتخصيص التقييمات، وتتبع أداء النموذج، مما يجعله متعدد الاستخدامات للعديد من تطبيقات LLM
- SuperAnnotate : إنه متخصص في إدارة البيانات وشرحها، وهو أمر بالغ الأهمية لمهام التعلم تحت الإشراف. وهي مفيدة بشكل خاص لتحسين دقة النموذج، حيث إنها تسهل البيانات عالية الجودة والمشروحة بشريًا والتي تعمل على تحسين أداء النموذج في المهام المعقدة
- AllenNLP : تم تطويره من قبل معهد ألين للذكاء الاصطناعي، ويستهدف AllenNLP الباحثين والمطورين الذين يعملون على نماذج البرمجة اللغوية العصبية المخصصة. وهو يدعم مجموعة من المعايير ويوفر أدوات لتدريب واختبار وتقييم النماذج اللغوية، مما يوفر مرونة لتطبيقات البرمجة اللغوية العصبية المتنوعة
يوفر استخدام مجموعة من هذه المعايير والأدوات نهجًا شاملاً لتقييم البرمجة اللغوية اللغوية العصبية. يمكن للمعايير أن تحدد المعايير عبر المهام، بينما توفر الأدوات الهيكلية والمرونة اللازمة لتتبع أداء النماذج وتحسينه وتحسينه بفعالية.
ويضمنان معًا أن تفي نماذج إدارة اللغات المحلية بكل من المعايير التقنية واحتياجات التطبيق العملي.
تحديات تقييم نموذج الإدارة المحلية منخفضة المخاطر
يتطلب تقييم نماذج اللغات الكبيرة (LLMs) نهجاً دقيقاً. فهو يركز على جودة الاستجابات وفهم قابلية النموذج للتكيف والقيود المفروضة عليه عبر سيناريوهات متنوعة.
ونظرًا لأن هذه النماذج يتم تدريبها على مجموعات بيانات واسعة النطاق، فإن سلوكها يتأثر بمجموعة من العوامل، مما يجعل من الضروري تقييم أكثر من مجرد الدقة.
فالتقييم الحقيقي يعني فحص موثوقية النموذج ومرونته في مواجهة الحالات غير العادية المطالبات واتساق الاستجابة بشكل عام. تساعد هذه العملية على رسم صورة أوضح لنقاط القوة والضعف في النموذج، وتكشف عن المجالات التي تحتاج إلى تحسين.
فيما يلي نظرة فاحصة على بعض التحديات الشائعة التي تنشأ أثناء تقييم نموذج LLM.
1. تداخل بيانات التدريب
من الصعب معرفة ما إذا كان النموذج قد _رأى بالفعل بعض بيانات الاختبار. نظرًا لأن نماذج LLM يتم تدريبها على مجموعات بيانات ضخمة، فهناك احتمال أن تتداخل بعض أسئلة الاختبار مع أمثلة التدريب. قد يجعل هذا النموذج يبدو أفضل مما هو عليه في الواقع، حيث قد يكون مجرد تكرار لما يعرفه بالفعل بدلاً من إظهار فهم حقيقي.
2. أداء غير متسق
يمكن أن تكون استجابات النماذج ذات الأداء المنخفض غير متوقعة. ففي لحظة ما، يقدمون رؤى مثيرة للإعجاب، وفي اللحظة التالية يرتكبون أخطاء غريبة أو يقدمون معلومات وهمية على أنها حقائق (تُعرف باسم "الهلوسة").
هذا التناقض يعني أنه بينما قد تتألق مخرجات LLM في بعض المجالات، إلا أنها قد تقصر في مجالات أخرى، مما يجعل من الصعب الحكم بدقة على موثوقيتها وجودتها الإجمالية.
3. نقاط الضعف العدائية
يمكن أن تكون الآلات الخادعة عرضة لهجمات الخصوم، حيث تخدعهم المطالبات المصممة بذكاء لإنتاج استجابات معيبة أو ضارة. تكشف هذه الثغرة نقاط الضعف في النموذج ويمكن أن تؤدي إلى مخرجات غير متوقعة أو متحيزة. يعد اختبار نقاط الضعف العدائية هذه أمرًا بالغ الأهمية لفهم أين تكمن حدود النموذج.
حالات استخدام تقييم LLM العملية
أخيرًا، إليك بعض الحالات الشائعة التي يُحدث فيها تقييم LLM فرقًا حقيقيًا:
روبوتات الدردشة لدعم العملاء
تُستخدم روبوتات دعم العملاء على نطاق واسع في روبوتات الدردشة الآلية للتعامل مع استفسارات العملاء. يضمن تقييم مدى جودة استجابة النموذج تقديم إجابات دقيقة ومفيدة وذات صلة بالسياق.
من المهم قياس قدرته على فهم نوايا العملاء، والتعامل مع الأسئلة المتنوعة، وتقديم إجابات شبيهة بالإنسان. سيسمح ذلك للشركات بضمان تجربة سلسة للعملاء مع تقليل الإحباط.
توليد المحتوى
تستخدم العديد من الشركات برامج إدارة المحتوى لتوليد محتوى المدونة ووسائل التواصل الاجتماعي وأوصاف المنتجات. يساعد تقييم جودة المحتوى الذي تم إنشاؤه على ضمان أن يكون صحيحًا نحويًا وجذابًا وملائمًا للجمهور المستهدف. تعتبر مقاييس مثل الإبداع والترابط والملاءمة للموضوع مهمة هنا للحفاظ على معايير عالية للمحتوى.
تحليل المشاعر
يمكن لـ LLMs تحليل مشاعر العملاء أو منشورات وسائل التواصل الاجتماعي أو مراجعات المنتجات. من الضروري تقييم مدى دقة النموذج في تحديد ما إذا كان النص إيجابيًا أو سلبيًا أو محايدًا. يساعد ذلك الشركات على فهم مشاعر العملاء، وتحسين المنتجات أو الخدمات، وتعزيز رضا المستخدمين، وتحسين استراتيجيات التسويق.
توليد الرموز
غالبًا ما يستخدم المطورون نماذج LLM للمساعدة في توليد التعليمات البرمجية. ومن المهم تقييم قدرة النموذج على إنتاج كود وظيفي وفعال.
من المهم التحقق مما إذا كان الكود الذي تم إنشاؤه سليمًا من الناحية المنطقية وخاليًا من الأخطاء ويلبي متطلبات المهمة. يساعد ذلك على تقليل كمية الترميز اليدوي اللازم وتحسين الإنتاجية.
قم بتحسين تقييم LLM الخاص بك مع ClickUp
يتمحور تقييم LLMs حول اختيار المقاييس الصحيحة التي تتماشى مع أهدافك. يكمن المفتاح في فهم أهدافك المحددة، سواء كانت تحسين جودة الترجمة، أو تحسين توليد المحتوى، أو الضبط الدقيق للمهام المتخصصة.
إن اختيار المقاييس الصحيحة لتقييم الأداء، مثل مقاييس RAG أو مقاييس الضبط الدقيق، يشكل أساس التقييم الدقيق والهادف. وفي الوقت نفسه، توفر مقاييس التقييم المتقدمة مثل G-Eval، و Prometheus، وSelfCheckGPT، وQAG رؤى دقيقة بفضل قدراتها المنطقية القوية.
ومع ذلك، هذا لا يعني أن هذه الدرجات مثالية - لا يزال من المهم التأكد من أنها موثوقة.
أثناء تقدمك في تقييم طلب الحصول على درجة الماجستير في القانون، قم بتخصيص العملية لتناسب حالة الاستخدام الخاصة بك. لا يوجد مقياس عالمي يصلح لكل سيناريو. ستمنحك مجموعة من المقاييس، إلى جانب التركيز على السياق، صورة أكثر دقة لأداء نموذجك.
لتبسيط عملية تقييم LLM وتحسين تعاون فريقك، فإن ClickUp هو الحل المثالي لإدارة سير العمل وتتبع المقاييس المهمة.
هل تريد تحسين إنتاجية فريقك؟ اشترك في ClickUp اليوم وجرّب كيف يمكن أن يحوّل سير عملك!