

Bạn là trưởng phòng đang tìm kiếm người phù hợp nhất để xử lý một công việc cụ thể. Với lượng dữ liệu khổng lồ của công ty, việc tìm kiếm người phù hợp nhất là gần như không thể, đặc biệt nếu công việc của bạn có thời hạn.
Hơn nữa, ai có đủ thời gian và nguồn lực để hỏi mọi người xem họ có đủ kiến thức về một lĩnh vực cụ thể hay không?
Nhưng nếu bạn có thể chỉ cần hỏi hệ thống, "Ai là người được giao [công việc] nhiều nhất?" và nhận được câu trả lời chính xác ngay lập tức dựa trên dữ liệu thực tế thì sao? Đó chính là công việc của Hệ thống truy xuất thông tin.
Các hệ thống này lọc qua lượng dữ liệu khổng lồ để tìm chính xác những gì bạn cần.
Giờ đây, hãy mở rộng ý tưởng đó sang cơ sở dữ liệu toàn cầu — hệ thống IR tổ chức lượng dữ liệu khổng lồ, giúp bạn tìm thấy câu trả lời phù hợp nhất trong vài giây. Hướng dẫn này sẽ khám phá các mô hình truy xuất thông tin khác nhau, cách thức hoạt động của chúng và vai trò của công nghệ AI trong hệ thống IR.
⏰ Tóm tắt 60 giây
📌 Hệ thống truy xuất thông tin (IR) giúp tìm kiếm thông tin liên quan từ các bộ sưu tập dữ liệu lớn, hoạt động như một trợ lý ảo lọc dữ liệu để tìm kiếm những gì bạn cần
📌 Hệ thống IR có các thành phần khóa: cơ sở dữ liệu, chỉ mục, giao diện tìm kiếm, bộ xử lý truy vấn, mô hình truy xuất và cơ chế xếp hạng/chấm điểm
📌 Bốn mô hình IR chính được sử dụng: Boolean (sử dụng các toán tử AND/OR/NOT), Vector Space (biểu diễn tài liệu dưới dạng vectơ), Probabilistic (sử dụng phương pháp thống kê) và Term Interdependence (phân tích mối quan hệ giữa các thuật ngữ)
📌 Học máy và xử lý ngôn ngữ tự nhiên cải thiện hệ thống IR bằng cách nâng cao khả năng nhận dạng mẫu, xếp hạng kết quả và hiểu ngữ cảnh
📌 Những thách thức chính bao gồm bảo mật dữ liệu, khả năng mở rộng và duy trì chất lượng dữ liệu trong khi xử lý các tập dữ liệu lớn
Thu thập thông tin (IR) là gì?
Tìm kiếm thông tin (IR) đơn giản là tìm kiếm thông tin chính xác từ các bộ sưu tập dữ liệu lớn, chẳng hạn như thư viện kỹ thuật số, cơ sở dữ liệu hoặc kho lưu trữ Internet.
Đó giống như có một trợ lý ảo giúp bạn lọc qua hàng núi dữ liệu để mang đến chính xác những gì bạn cần. *
Bề ngoài, người dùng nhập truy vấn, thường sử dụng từ khóa hoặc cụm từ, để tìm kiếm thông tin cụ thể. Đằng sau đó, các kỹ thuật và thuật toán tiên tiến phân tích các chuỗi tìm kiếm và kết hợp chúng với dữ liệu có liên quan.
Thay vì chỉ xác định một câu trả lời duy nhất, hệ thống IR cung cấp một số đối tượng, mỗi đối tượng có mức độ liên quan khác nhau với truy vấn của bạn. Ngoài ra, chúng được sử dụng ở mọi nơi và có nhiều ứng dụng (sẽ có thêm thông tin về điều này trong thời gian tới 🔔).
💡Mẹo chuyên nghiệp: Cần tìm người có kỹ năng nhất cho một công việc? Nhập các thuật ngữ cụ thể như "phân tích báo cáo bán hàng Q1 và Q2 được giao" vào hệ thống truy xuất thông tin. Chỉ cần vậy, hệ thống sẽ nhanh chóng lọc ra các dữ liệu không liên quan và xác định chính xác người đã xử lý nhiều nhất.
Ứng dụng IR trong các trường khác nhau
Từ chăm sóc sức khỏe đến thương mại điện tử, hệ thống IR được sử dụng trong nhiều trường để quản lý và phân loại dữ liệu. Dưới đây là một vài ví dụ 👇
Y tế
Trong lĩnh vực chăm sóc sức khỏe, hệ thống IR quét cơ sở dữ liệu hồ sơ y tế và các bài báo nghiên cứu để giúp bác sĩ và nhà nghiên cứu tìm thấy thông tin phù hợp nhất. Kết quả là, họ có thể chẩn đoán bệnh nhanh hơn, xác định phương án điều trị và tìm thấy các nghiên cứu phù hợp nhất bằng cách sử dụng phản hồi có liên quan.
Dịch vụ khách hàng
Các kỹ thuật truy xuất thông tin giúp hỗ trợ khách hàng nhanh hơn và chính xác hơn. Ví dụ: nhân viên hỗ trợ có thể nhập truy vấn của người dùng như "chính sách hoàn tiền" vào hệ thống của công ty để lấy câu trả lời ngay lập tức.
Chatbot AI và bộ phận trợ giúp được hỗ trợ bởi truy xuất thông tin tiến thêm một bước nữa, cung cấp các giải pháp thời gian thực mà không cần sự can thiệp của con người. Đó là lý do tại sao câu hỏi của bạn thường được trả lời trong vài giây!
Nền tảng thương mại điện tử
Hệ thống IR giúp mua sắm trực tuyến trở nên dễ dàng. Chúng phân tích cơ sở dữ liệu và phù hợp với hành vi của khách hàng để đề xuất các sản phẩm bạn sẽ yêu thích.
Ví dụ: Amazon sử dụng IR để đề xuất các mục dựa trên lịch sử tìm kiếm và các giao dịch mua trước đó của bạn, giúp bạn tìm thấy chính xác những gì bạn cần.
Các thành phần của hệ thống tìm kiếm thông tin
Bây giờ chúng ta đã biết tìm kiếm thông tin là gì và cách thức hoạt động của nó. Hãy phân tích các khối xây dựng khóa của hệ thống IR. →
1. Cơ sở dữ liệu
Mọi thứ bắt đầu từ cơ sở dữ liệu. Cơ sở dữ liệu là tập hợp các điểm dữ liệu liên quan đến nhau, chẳng hạn như tài liệu văn bản, email, trang web, hình ảnh và video. Khi bạn nhập truy vấn nhất định, hệ thống IR sẽ tìm kiếm trong các kết quả phù hợp trong cơ sở dữ liệu để truy xuất thông tin phù hợp nhất với nhu cầu của bạn.
2. Chỉ mục
Trước khi hệ thống có thể truy xuất bất kỳ thông tin nào, trình chỉ mục sẽ sắp xếp dữ liệu. Quá trình này giống như việc chuẩn bị danh mục thư viện để tìm kiếm nhanh hơn. Trình chỉ mục xử lý tài liệu bằng cách:
- Tokenization: Chia nội dung thành các phần nhỏ hơn, như chia câu thành các từ hoặc cụm từ (gọi là token)
- Stemming: Đơn giản hóa các từ thành biểu mẫu cơ bản (ví dụ: 'running' trở thành 'run')
- Loại bỏ từ không có nghĩa: Bỏ qua các từ bổ sung như 'và', 'hoặc' và 'the' để tập trung vào truy vấn chính
- Trích xuất từ khóa: Xác định các từ khóa chính trong văn bản
- Trích xuất siêu dữ liệu: Lấy thêm thông tin chi tiết như tác giả, ngày xuất bản hoặc tiêu đề
3. Giao diện tìm kiếm
Giao diện tìm kiếm đóng vai trò là cổng vào hệ thống IR. Đây là nơi bạn nhập truy vấn bằng các từ khóa đơn giản hoặc bộ lọc chi tiết hơn. Được thiết kế thân thiện với người dùng, giao diện này đảm bảo bạn có thể dễ dàng truyền đạt nhu cầu truy cập thông tin và nhận được kết quả phù hợp mà bạn đang tìm kiếm.
4. Bộ xử lý truy vấn
Khi bạn nhấn 'tìm kiếm', bộ xử lý truy vấn sẽ bắt đầu hoạt động. Nó sẽ tinh chỉnh đầu vào của bạn bằng cách áp dụng các kỹ thuật được liệt kê trong phần chỉ mục. Ngoài ra, nó còn xử lý các toán tử Boolean như 'AND', 'OR' và 'NOT' để làm cho truy vấn của bạn thông minh hơn.
5. Mô hình truy xuất
Đây là nơi điều kỳ diệu xảy ra. Hệ thống so sánh truy vấn của bạn với các tài liệu được chỉ mục bằng cách sử dụng các mô hình truy xuất. Các phương pháp này quyết định cách kết hợp truy vấn của bạn với dữ liệu được lưu trữ. Một số tên phổ biến bao gồm:
- Mô hình boolean
- Mô hình không gian véc tơ
- Mô hình xác suất
- Và nhiều hơn nữa… (sẽ được thảo luận sau)
6. Xếp hạng và đánh giá
Khi tìm thấy các kết quả phù hợp, hệ thống sẽ xếp hạng chúng dựa trên mức độ liên quan. Mỗi tài liệu sẽ được chấm điểm bằng các phương pháp như TF-IDF (Tần suất thuật ngữ-Tần suất tài liệu nghịch đảo) hoặc các thuật toán khác. Điều này đảm bảo kết quả phù hợp nhất sẽ xuất hiện ở đầu danh sách.
7. Trình bày hoặc hiển thị
Cuối cùng, kết quả sẽ được hiển thị cho bạn. Thông thường, hệ thống hiển thị danh sách các tài liệu văn bản được xếp hạng kèm theo các tính năng bổ sung như đoạn trích, bộ lọc hoặc tùy chọn sắp xếp. Điều này giúp bạn dễ dàng chọn tài liệu phù hợp nhất. Tuy nhiên, số kết quả hiển thị có thể khác nhau tùy thuộc vào sở thích, truy vấn hoặc cài đặt hệ thống của bạn.
🔍Bạn có biết?: Các hệ thống truy xuất thông tin truyền thống phụ thuộc rất nhiều vào cơ sở dữ liệu có cấu trúc và khớp từ khóa cơ bản. Kết quả là gì? Các vấn đề lớn về mức độ liên quan và cá nhân hóa.
Đó là khi các công nghệ AI hiện đại đã biến đổi truy xuất văn bản thông qua:
- Học máy (ML): Giúp hệ thống IR học hỏi từ các mẫu hành vi của người dùng và cải thiện kết quả tìm kiếm theo thời gian
- Mạng nơ-ron sâu: Các thuật toán có thể xử lý dữ liệu không có cấu trúc (như hình ảnh hoặc video) và khám phá các mối quan hệ phức tạp
- Xử lý ngôn ngữ tự nhiên (NLP): Cho phép hệ thống hiểu ý nghĩa và ngữ cảnh của các truy vấn để hỗ trợ nhận dạng hình ảnh và phân tích cảm xúc, giúp truy cập thông tin trở nên linh hoạt hơn
Các mô hình tìm kiếm thông tin
Có nhiều hệ thống IR khác nhau giúp tối ưu hóa quá trình tìm kiếm tài liệu liên quan. Hãy cùng tìm hiểu về những hệ thống được sử dụng phổ biến nhất:
1. Lý thuyết tập hợp và mô hình Boolean
Mô hình Boolean là một trong những kỹ thuật truy xuất thông tin đơn giản nhất. Cách thức hoạt động như sau:
- VÀ: Truy xuất các tài liệu chứa tất cả các thuật ngữ trong truy vấn. Ví dụ: tìm kiếm 'cat AND dog' sẽ trả về các tài liệu đề cập đến cả hai thuật ngữ trên công cụ tìm kiếm
- HOẶC: Tìm các tài liệu chứa bất kỳ thuật ngữ nào trong truy vấn. Đối với 'cat OR dog', nó sẽ truy xuất các tài liệu đề cập đến cat, dog hoặc cả hai
- LƯU Ý: Không bao gồm các tài liệu có chứa một thuật ngữ cụ thể. Ví dụ: 'cat AND NOT dog' sẽ trả về các tài liệu đề cập đến cat nhưng không đề cập đến dog
Mô hình này sử dụng khái niệm 'túi từ', trong đó một ma trận 2D được tạo ra. Trong ma trận này:
- Các cột đại diện cho các tài liệu
- Các hàng đại diện cho các thuật ngữ trong truy vấn
Mỗi ô được gán giá trị 1 (nếu thuật ngữ có mặt) hoặc 0 (nếu không có).

✅ Ưu điểm
- Dễ hiểu và dễ thực hiện
- Truy xuất các tài liệu khớp chính xác với các thuật ngữ truy vấn
❌ Nhược điểm
- Mô hình boolean không xếp hạng tài liệu theo mức độ liên quan, vì vậy tất cả kết quả đều được coi là quan trọng như nhau
- Tập trung vào các kết quả khớp chính xác, do đó kết quả có thể khác nhau tùy theo ý nghĩa hoặc ngữ cảnh của truy vấn
2. Mô hình không gian véc tơ
Mô hình Vector Space là một mô hình đại số thể hiện cả tài liệu và truy vấn dưới dạng vectơ trong một không gian đa chiều. Cách thức hoạt động như sau:
1. Một ma trận thuật ngữ-tài liệu được tạo ra, trong đó các hàng là các thuật ngữ và các cột là các tài liệu
2. Một véc tơ truy vấn được hình thành dựa trên các thuật ngữ tìm kiếm của người dùng
3. Hệ thống tính toán điểm số bằng cách sử dụng thước đo gọi là độ tương đồng cosine, xác định mức độ phù hợp giữa véc tơ truy vấn và véc tơ tài liệu

Là một hệ thống tìm kiếm thông tin, các tài liệu sau đó được xếp hạng dựa trên các điểm số này, với các tài liệu có điểm số cao nhất được coi là phù hợp nhất
✅ Ưu điểm
- Truy xuất các mục ngay cả khi chỉ một số thuật ngữ phù hợp
- Sự khác biệt trong cách sử dụng thuật ngữ và độ dài tài liệu, hỗ trợ các loại tài liệu đa dạng
❌ Nhược điểm
- Các từ vựng lớn và bộ sưu tập tài liệu khiến các tính toán độ tương đồng trở nên tốn kém về tài nguyên
3. Mô hình xác suất
Mô hình này sử dụng phương pháp thống kê, sử dụng xác suất để ước tính mức độ liên quan của tài liệu đối với truy vấn. Mô hình này xem xét:
- Tần suất xuất hiện của các thuật ngữ trong tài liệu
- Tần suất các thuật ngữ xuất hiện cùng nhau (cùng xuất hiện)
- Độ dài tài liệu và tổng số thuật ngữ truy vấn
Hệ thống coi quá trình truy xuất là một sự kiện xác suất, xếp hạng các tài liệu được lưu trữ dựa trên mức độ liên quan của chúng. Cách tiếp cận này tăng thêm chiều sâu bằng cách đánh giá các đối tượng dữ liệu ngoài sự hiện diện của các thuật ngữ cơ bản.
✅ Ưu điểm
- Thích ứng tốt với các ứng dụng khác nhau, bao gồm phân tích độ tin cậy và đánh giá luồng tải
❌ Nhược điểm
- Dựa trên các giả định về mối quan hệ giữa các dữ liệu, điều này có thể dẫn đến kết quả sai lệch
4. Mô hình tương tác giữa các thuật ngữ
Không giống như các mô hình đơn giản hơn, Mô hình phụ thuộc lẫn nhau giữa các thuật ngữ tập trung vào mối quan hệ giữa các thuật ngữ thay vì chỉ tập trung vào tần suất xuất hiện của chúng. Các mô hình này phân tích mối quan hệ giữa các từ và cụm từ để cải thiện độ chính xác của kết quả.
Họ sử dụng một trong hai phương pháp sau:
- Chế độ nội tại: Khám phá các mối quan hệ trong chính văn bản
- Chế độ siêu việt: Xem xét dữ liệu hoặc bối cảnh bên ngoài để suy ra các mối quan hệ
Phương pháp này đặc biệt hữu ích trong việc nắm bắt các sắc thái ý nghĩa, chẳng hạn như từ đồng nghĩa hoặc các cụm từ cụ thể trong ngữ cảnh.
✅ Ưu điểm
- Nắm bắt các sắc thái trong ngôn ngữ bằng cách xem xét mối quan hệ giữa các thuật ngữ
- Tăng cường hiệu suất truy xuất bằng cách hiểu các phụ thuộc và ngữ cảnh của thuật ngữ
❌ Nhược điểm
- Yêu cầu dữ liệu phong phú để mô hình hóa chính xác các mối quan hệ giữa các thuật ngữ, điều này không phải lúc nào cũng khả thi
Đó là tất cả! Đây là một số hệ thống tìm kiếm thông tin phổ biến, mỗi hệ thống có những ưu và nhược điểm riêng.
➡️ Đọc thêm: 4 giải pháp tìm kiếm nổi bật và đối thủ cạnh tranh
Truy xuất thông tin so với truy vấn dữ liệu
Mặc dù hai thuật ngữ này có vẻ gần giống nhau, nhưng chúng hoạt động khác nhau. Vì vậy, hãy đặt IR và Truy vấn dữ liệu cạnh nhau để xem chúng khác nhau như thế nào về mục đích, trường hợp sử dụng và ví dụ:
| Aspect | Tìm kiếm thông tin (IR) | Truy vấn dữ liệu |
| Định nghĩa | Hoạt động như một công cụ tìm kiếm, tìm kiếm trong hàng tấn dữ liệu để mang đến cho bạn kết quả phù hợp nhất | Hãy tưởng tượng việc này giống như đặt một câu hỏi cụ thể cho cơ sở dữ liệu bằng ngôn ngữ mà nó hiểu (như SQL) |
| Mục tiêu/Mục đích | Giúp bạn tìm kiếm thông tin chính xác và liên quan trên các công cụ tìm kiếm — nhanh chóng và dễ dàng | Trích xuất dữ liệu chính xác để bạn có thể phân tích, cập nhật hoặc xử lý số liệu |
| Trường hợp sử dụng | Được sử dụng cho tìm kiếm web, đề xuất thương mại điện tử, thư viện kỹ thuật số, phân tích y tế và nhiều ứng dụng khác | Rất phù hợp cho các công việc như quản lý hàng tồn kho trong thương mại điện tử, phân tích tài chính và tối ưu hóa chuỗi cung ứng |
| Ví dụ | Tìm kiếm "Máy tính xách tay tốt nhất trong khoảng giá 800-1000 đô la" trên Google để nhận kết quả xếp hạng | Truy vấn hệ thống kho của bạn bằng câu lệnh 'SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000' để tìm những mặt hàng còn trong kho |
Vai trò của học máy và NLP trong truy xuất thông tin
Hệ thống IR giống như những thợ săn kho báu cho dữ liệu – chúng lọc qua lượng thông tin khổng lồ để tìm chính xác những gì bạn cần. Nhưng khi ML và NLP kết hợp, các hệ thống này trở nên thông minh hơn, nhanh hơn và chính xác hơn rất nhiều.
Hãy xem ML như bộ não đằng sau các hệ thống IR. 🧠
Nó giúp hệ thống học hỏi, thích ứng và cải thiện kết quả mỗi khi bạn tìm kiếm thông tin. Cách thức hoạt động như sau:
- Phát hiện mẫu: ML nghiên cứu những gì người dùng nhấp vào, những gì họ bỏ qua và những gì họ dành nhiều thời gian nhất để đọc. Sau đó, nó sử dụng kiến thức này để hiển thị cho bạn kết quả phù hợp nhất vào lần tiếp theo
- Kết quả xếp hạng: ML truy xuất thông tin và xếp hạng thông tin đó. Điều đó có nghĩa là kết quả tốt nhất và hữu ích nhất sẽ xuất hiện ở đầu trang tìm kiếm của bạn
- Thích ứng theo thời gian: Với mỗi truy vấn, ML sẽ trở nên tốt hơn. Nó nắm bắt xu hướng, tinh chỉnh sự hiểu biết và xử lý dễ dàng cả những câu hỏi khó nhất
Ví dụ: nếu hôm nay bạn tìm kiếm "máy tính xách tay giá rẻ tốt nhất" và tương tác với các kết quả cụ thể, ML sẽ biết ưu tiên các tùy chọn tương tự khi bạn tìm kiếm "máy tính xách tay giá cả phải chăng" sau này. Bằng cách kết hợp AI với ML, công cụ tìm kiếm web thậm chí có thể dự đoán những gì bạn có thể cần tiếp theo.
Bây giờ hãy nói về NLP. Nó giúp các hệ thống IR hiểu ý nghĩa của bạn, không chỉ các từ bạn gõ. Nói một cách đơn giản:
- Nó hiểu ngữ cảnh: NLP biết rằng khi bạn nói "jaguar", bạn có thể ám chỉ loài động vật hoặc chiếc xe hơi — và nó sẽ hiểu dựa trên phần còn lại của truy vấn của bạn
- Xử lý ngôn ngữ phức tạp: Cho dù truy vấn của bạn đơn giản ('chuyến bay giá rẻ') hay chi tiết ('chuyến bay thẳng đến Tokyo dưới 500 đô la'), NLP đảm bảo hệ thống hiểu và cung cấp kết quả chính xác
Kết hợp NLP và IR giúp việc tìm kiếm trở nên trực quan, giống như trò chuyện với ai đó thực sự hiểu bạn. Điều này có nghĩa là ít cuộn trang hơn, ít bực bội hơn và nhiều khoảnh khắc "Wow, chính xác là điều tôi cần!" hơn.
Vai trò của ClickUp trong truy xuất thông tin
ClickUp, "ứng dụng cho mọi công việc", cải thiện quản lý dữ liệu với các mô hình IR.
AI tích hợp sẵn của nó xác định và khớp kết quả với truy vấn của người dùng một cách độc đáo, đưa công nghệ thông minh lên một tầm cao mới.
Và để làm cho thỏa thuận trở nên hấp dẫn hơn, Tìm kiếm kết nối của ClickUp giúp bạn dễ dàng có được mọi thứ bạn cần 'ngay lập tức' trong tầm tay. Điều đó có nghĩa là:
- Tìm kiếm bất cứ thứ gì: Ai thích lục lọi email và hệ thống quản lý kiến thức để tìm các tệp quan trọng? Tìm bất kỳ tệp nào trong vài giây bằng tùy chọn Tìm kiếm kết nối. Tốt hơn nữa, tìm kiếm tệp trên các ứng dụng được kết nối và truy cập mọi thứ ở một nơi
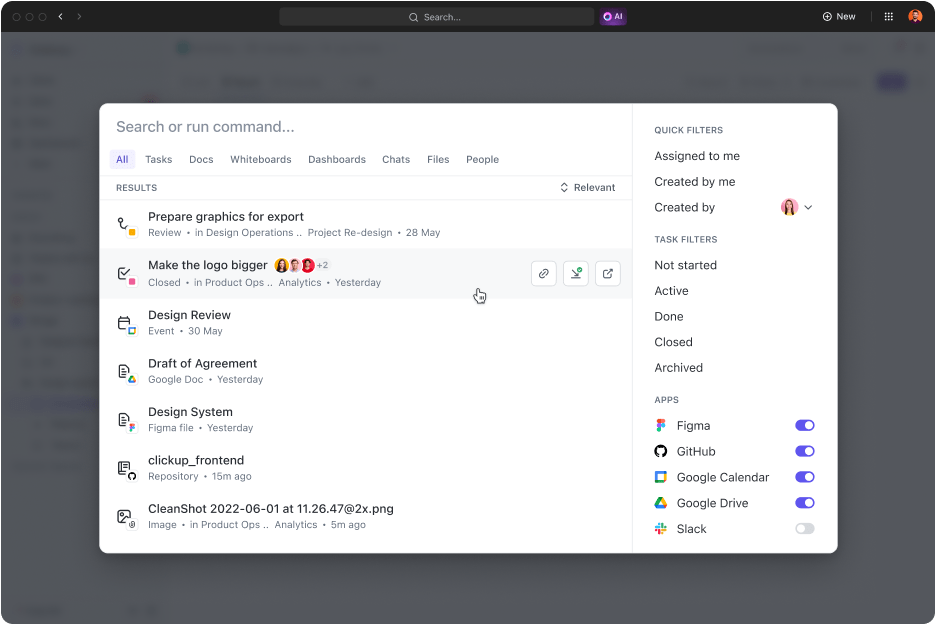
- Kết nối các ứng dụng yêu thích của bạn: ClickUp có một số tích hợp tốt nhất giúp mở rộng khả năng tìm kiếm sang các ứng dụng của bên thứ ba như Google Drive, Slack, Dropbox, Figma, v.v

- Tinh chỉnh kết quả: Càng sử dụng nhiều, nó càng hiểu rõ hơn những gì bạn đang tìm kiếm, mang lại kết quả phù hợp nhất với bạn
- Tìm kiếm theo cách của bạn: Truy cập Tìm kiếm kết nối và tìm kiếm tệp PDF nhanh chóng từ mọi nơi trong không gian làm việc của bạn. Ví dụ: bạn có thể bắt đầu tìm kiếm từ Trung tâm Lệnh, Thanh hành động toàn cầu hoặc máy tính để bàn của bạn
- Tạo lệnh tìm kiếm tùy chỉnh: Thêm lệnh tìm kiếm tùy chỉnh như phím tắt đến liên kết, lưu trữ văn bản để sử dụng sau và hơn thế nữa để hợp lý hóa quy trình làm việc của bạn
Hơn nữa, nếu có một cách để tự động hóa các công việc nhàm chán, làm việc nhanh hơn và hoàn thành nhiều việc hơn trong thời gian ngắn thì sao?
ClickUp Brain, trợ lý AI tích hợp sẵn, biến điều này thành hiện thực cho bạn. Đây là trợ lý tối ưu cho quản lý dữ liệu — thông minh, nhanh chóng và luôn sẵn sàng trợ giúp.
Tóm tắt 👇
- Trung tâm kiến thức tất cả trong một: Không bao giờ phải phụ thuộc vào email và tin nhắn để cập nhật thông tin nữa. Hỏi bất cứ điều gì về Nhiệm vụ, Tài liệu hoặc Người dùng của bạn và ngồi thư giãn trong khi ClickUp Brain lập bản đồ câu trả lời dựa trên bối cảnh từ bên trong và các ứng dụng được kết nối

- Tìm thấy những gì bạn cần nhanh hơn: ClickUp Brain xếp hạng kết quả một cách thông minh như một hệ thống IR tiên tiến. Nó sắp xếp các tệp tin có liên quan theo mức độ ưu tiên, đề xuất các công việc liên quan và thậm chí còn giúp bạn phát hiện khối lượng công việc ẩn trong dữ liệu của mình
- Tự động hóa công việc: Brain tự động hóa việc tạo báo cáo hoặc theo dõi thời hạn thông qua các công cụ AI. Đây là một trợ lý cá nhân giúp bạn tiết kiệm thời gian để tập trung vào những quyết định quan trọng hơn trong khi vẫn đảm bảo mọi việc diễn ra theo đúng kế hoạch
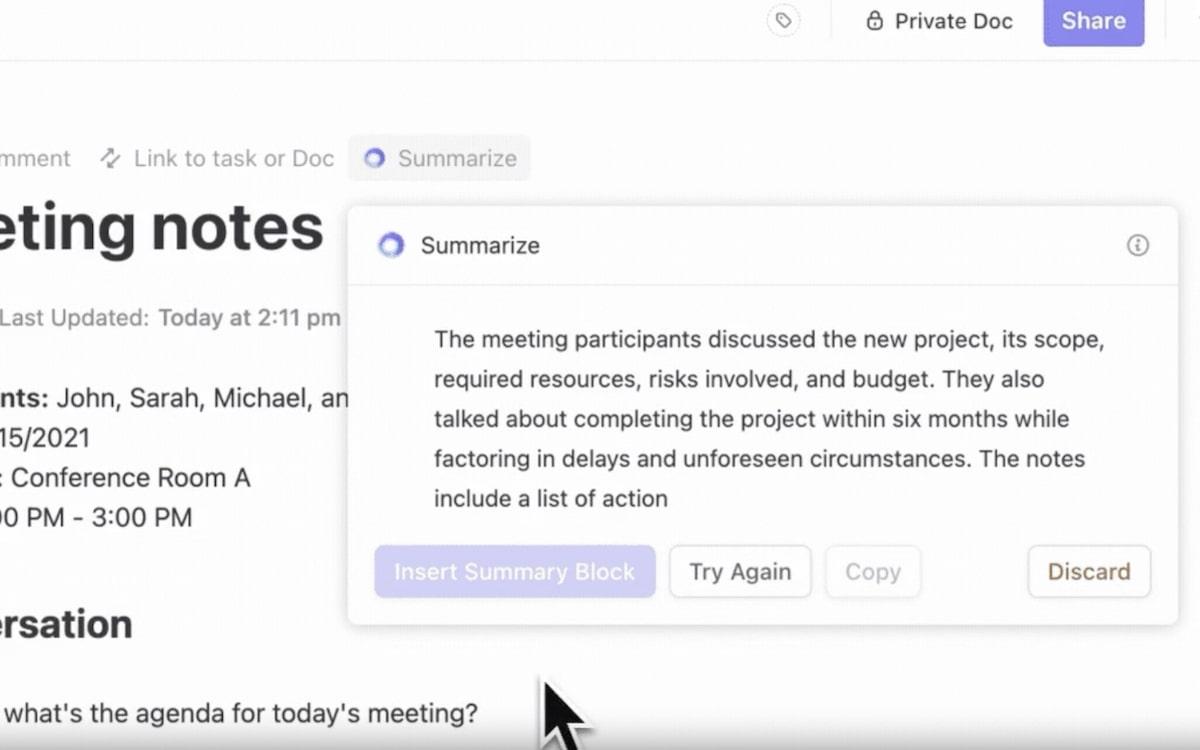
- Tìm kiếm theo ngữ cảnh: Với NLP, nó hiểu câu hỏi của bạn — ngay cả khi truy vấn của bạn phức tạp hoặc mơ hồ. Ví dụ: tìm kiếm "báo cáo về doanh số quý 1" sẽ cho bạn báo cáo chính xác liên quan đến công việc của bạn
➡️ Đọc thêm: Hệ thống quản lý công việc là gì và cách triển khai?
Thách thức và Hướng phát triển trong Lưu trữ thông tin
Thế giới của tìm kiếm thông tin xoay quanh việc hiểu và khai thác lượng dữ liệu khổng lồ, nhưng ngay cả các hệ thống IR tiên tiến nhất cũng gặp phải một số thách thức trên hành trình phát triển.
Hãy cùng khám phá những thách thức phổ biến và những xu hướng thú vị đang định hình tương lai của lĩnh vực khoa học quan trọng này:
- Bảo mật và quyền riêng tư dữ liệu: Để mô hình IR cung cấp kết quả thực tế, nó thường cần truy cập vào dữ liệu nhạy cảm. Tuy nhiên, bảo vệ dữ liệu người dùng không phải là việc dễ dàng đối với các tài nguyên truy xuất thông tin
- Khả năng mở rộng và hiệu suất: Khi người dùng tìm kiếm trong các tập dữ liệu lớn, việc xử lý lượng nội dung ngày càng tăng có thể làm quá tải ngay cả các mô hình truy xuất mạnh mẽ nhất. Thách thức là đảm bảo truy xuất hiệu quả mà không ảnh hưởng đến mức độ liên quan của kết quả tìm kiếm
- Chất lượng dữ liệu và hiểu biết theo ngữ cảnh: Các truy vấn mơ hồ hoặc siêu dữ liệu được tổ chức kém có thể dẫn đến sự không khớp, khiến hệ thống khó xác định ý định của người dùng một cách chính xác
Các xu hướng mới và tiến bộ trong công nghệ IR
Mặc dù gặp nhiều thách thức, những tiến bộ công nghệ gần đây đã giúp chúng ta xây dựng các hệ thống thông minh và hiệu quả hơn
Các hệ thống truy xuất thông tin hiện đại hiện nay sử dụng các phương pháp tiên tiến như phân tích dựa trên đồ thị để giải thích các số và văn bản, bối cảnh, siêu dữ liệu và mối quan hệ giữa các điểm dữ liệu.
Điều này có ý nghĩa gì đối với người dùng? Nó cho phép truy xuất văn bản chính xác hơn và phân tích chi tiết hơn, đặc biệt là trong các lĩnh vực như nghiên cứu và các ngành công nghiệp sử dụng nhiều dữ liệu.
Kết hợp với công nghệ web ngữ nghĩa, nó tập trung vào chuỗi tìm kiếm và ý định của người dùng. Các hệ thống này có thể vượt ra ngoài kết quả tìm kiếm theo nghĩa đen và tìm kiếm các tài liệu có liên quan cao, ngay cả đối với các truy vấn phức tạp của người dùng trong quá trình truy xuất thông tin.
Ví dụ: tìm kiếm "lợi ích của công việc từ xa" có thể mang lại kết quả liên quan đến năng suất, sức khỏe tinh thần và cân bằng cuộc sống - tất cả là do hệ thống hiểu được các kết nối.
Truy xuất tài liệu nhanh chóng với tính năng quản lý dữ liệu của ClickUp
Việc tìm kiếm trong vô số tệp, ứng dụng và công cụ để tìm ra một tài liệu quan trọng thật mệt mỏi. Hãy tưởng tượng bạn là một nhà nghiên cứu, sinh viên, chuyên gia CNTT hoặc nhà khoa học dữ liệu và đang cố gắng phân tích các tài liệu đã tìm được — và kết quả là một mớ hỗn độn thông tin quá tải.
Nhưng với ClickUp, bạn sẽ không bao giờ phải mất thời gian tìm kiếm thông tin nữa.
Đây là giải pháp tất cả trong một giúp tập hợp công việc của bạn vào một nơi. Với các tính năng như Tìm kiếm kết nối và ClickUp Brain, không quan trọng dữ liệu của bạn được lưu trữ ở đâu — ClickUp giúp bạn dễ dàng tìm kiếm, quản lý và thực hiện các hành động trên dữ liệu đó.
Tại sao phải chấp nhận "chỉ tạm được" khi bạn có thể có "tuyệt vời"? Hãy dùng thử ClickUp miễn phí và xem nó biến quy trình làm việc của bạn thành một thứ táo bạo, hiệu quả và hoàn toàn không thể ngăn cản!