
De första tjänsterna är enkla. En rotation, en kanal och sedan en backup.
Men när ditt företag når dussintals mikrotjänster, flera regioner och skiktat ägande, upphör manuella eskaleringar att vara ett arbetsflöde och blir istället en belastning.
Den här guiden förklarar hur du automatiserar eskaleringsvägar för incidenter som skalar med din teknikorganisation utan att orsaka luckor i ditt jourssystem.
Vi kommer också att se hur ClickUp passar in i skapandet av ett eskaleringssystem som dina teknikteam kan lita på. 🎯
⭐ Utvald mall
Reagera snabbt och effektivt vid nödsituationer, från naturkatastrofer till dataintrång, med hjälp av ClickUps mall för incidentåtgärdsplan (IAP).

Mallen ger dig fördefinierade avsnitt för att:
- Definiera incidentmål och prioriteringar för respons
- Upprätta en tydlig befälsstruktur
- Samordna åtgärder mellan team i realtid
- Registrera beslut, tidslinjer och viktiga uppdateringar när de inträffar.
- Håll kontakten med eskalering och uppföljning
Eftersom det finns i ClickUp fungerar det som ett live-dokument för incidenthantering, inte som en statisk checklista.
Varför automatisera eskaleringsvägar för incidenter
När ditt team ansvarar för komplexa system med strikta SLA:er, bromsar manuell eskalering bara upp arbetet. Automatiserad eskalering gör din responsprocess förutsägbar och mindre stressig, även vid incidenter som kräver snabba åtgärder.
Här är varför du måste automatisera din organisations eskaleringsvägar. 👇
Risken med manuell eskalering
När du har att göra med dussintals tjänster, flera jourrotationer och ständigt skiftande ägarskap blir mänskliga steg snabbt ett problem.
Vanliga fallgropar är bland annat:
- Missade eller försenade aviseringar när någon missar ett e-postmeddelande, SMS eller chattmeddelande
- Förvirring vid överlämningar, särskilt när eskaleringsvägarna inte är tydligt dokumenterade
- Eskalering till fel team eftersom ägarskapet inte är uppdaterat
- Flaskhalsar som uppstår när man förlitar sig på en enda person för att ”skicka vidare larmet”
📖 Läs också: Hur man skriver en incidentrapport
Fördelar med automatisering
ITSM-automatisering ger dina eskaleringsvägar struktur och momentum. Istället för att hoppas att någon ser varningen, utför ditt system en fördefinierad sekvens omedelbart och konsekvent.
Här är vad teamen vinner på att använda AI för att automatisera uppgifter:
- Snabbare svarstider eftersom varningar når rätt person eller team inom några sekunder.
- Konsekvent genomförande av eskaleringssteg, även klockan 3 på natten, när beslutsfattandet går långsammare.
- Inbyggd redundans som säkerställer att reservpersonal får ett meddelande om den primära jourpersonen missar larmet.
- Tydlig översikt över alla team eftersom alla förstår hur eskaleringar fungerar
- Mindre brandbekämpning och mer förutsägbara jourupplevelser
📖 Läs också: Exempel på kontinuitetsplaner
Minska varningsutmattning och mänskliga förbiseenden
Varningsutmattning förstör effektiviteten i jourtjänsten. När ditt team blir kontaktat för ofta, eller av fel anledningar, slutar de att reagera med samma brådska. Automatisering hjälper till att filtrera och eskalera endast det som verkligen behöver mänsklig uppmärksamhet.
Med automatiserad eskaleringslogik:
- Varningar med svag signal eller dubbletter undertrycks innan de når jourhavande personal.
- Allvarlighetsbaserade regler säkerställer att mindre problem inte väcker någon i onödan.
- Varningar eskaleras endast om systemet upptäcker att det inte finns något svar inom en definierad tidsram.
- Teamen lägger mindre tid på att sortera brus och mer tid på att lösa verkliga problem.
Stöd för efterlevnad av SLA och jourpolicy
Automatiserad eskalering gör det enklare att upprätthålla efterlevnaden utan ständig manuell övervakning. För IT-chefer som hanterar strikta SLA:er eller interna tillförlitlighetsåtaganden fungerar AI som ett skyddsräcke som säkerställer förväntat beteende. Det hjälper dig att:
- Se till att incidentmeddelanden följer fördefinierade regler för vidarebefordran.
- Upprätthåll SLA-svarstider automatiskt med tidsbestämda eskaleringar.
- Genomför jourplaner utan att förlita dig på föråldrade kalkylblad
- Skapa revisionsspår för varje varning, eskalering och bekräftelse.
🎥 Vill du köra hela eskaleringsflödet utan att behöva göra något? Super Agents hjälper dig. 👇🏼
🔍 Visste du att? NASA:s Mission Control fungerar i huvudsak enligt en automatiserad eskaleringslogik. Om telemetrin går utanför intervallet skickar systemet omedelbart automatiska varningar till specialister inom respektive område.
Vad är en eskaleringspolicy inom incidenthantering?
En eskaleringspolicy är en fördefinierad uppsättning regler som avgör vem som ska underrättas, när de ska underrättas och hur ansvaret ska överföras uppåt eller mellan team.
Tänk på det som en strukturerad färdplan som förhindrar att incidenter fastnar, säkerställer att rätt experter kopplas in vid rätt tidpunkt och hjälper teamen att uppfylla SLA:er.
En välstrukturerad policy för eskaleringshantering innehåller vanligtvis följande:
- Regelbaserad vidarebefordran som definierar vem som står på tur när någon inte bekräftar eller inte kan lösa incidenten.
- Tidsinställda triggers som automatiskt eskalerar efter 5, 15 eller 30 minuter baserat på allvarlighetsgrad.
- Meddelandemetoder såsom telefonsamtal, SMS, chatt eller e-post
- Eskaleringsplanens nivåer från nivå 1 (primär jour) > nivå 2 (senioringenjörer/SME) > nivå 3 (ledning)
- Förväntningar på dokumentation så att nya responsgivare kan ta över utan att förlora viktig kontext
Typer av eskaleringspolicyer
Här är de viktigaste typerna av policyer som ditt team bör känna till:
1. Hierarkisk eskalering (vertikal)
Varningar flyttas uppåt i befälsordningen, från junioringenjörer till seniorspecialister till ledningen. Använd detta när situationen kräver djupare expertis, beslutsbefogenhet eller ledningens insyn.
2. Funktionell eskalering (horisontell)
I stället för att gå uppåt skickas larmet tvärs över teamen till den funktion som äger det berörda systemet. Detta är idealiskt för incidenter som är kopplade till en specifik domän, såsom databaser, nätverk, betalningar eller API:er.
3. Tidsbaserad eskalering
Detta är ryggraden i de flesta automatiserade system. I denna typ flyttas larmet till nästa nivå efter en viss tidsperiod, ofta direkt kopplad till SLA:er. Det är särskilt viktigt när du behöver garanterad respons efter kontorstid.
4. Effektsbaserad eskalering
Effektbaserad eskalering beror på allvarlighetsgraden eller påverkan på verksamheten, inte på hierarki eller tid. Det är användbart vid avbrott, betalningsfel, kundrelaterade problem eller säkerhetsöverträdelser.
5. Parallell eskalering
Här meddelas flera personer eller team samtidigt. Parallell eskalering används för allvarliga problem som kräver flera specialister eller för situationer där fördröjningar är oacceptabla.
🔍 Visste du att? En ny studie om varningssignaler har visat att extremt framträdande eller ”högljudda/ljusa” varningar kan fördröja reaktionstiden, särskilt om varningen är oväntad. Men när varningstypen blir förväntad (dvs. en del av ett förutbestämt eskalerings-/meddelandesystem) förbättras reaktionstiden. Detta tyder på att när du automatiserar eskaleringsvägar bör du inte bara översvämma människor med högprioriterade larm.
När ska automatisk eskalering utlösas?
Nu när du vet hur eskaleringsvägarna är strukturerade är nästa steg att bestämma när dessa regler ska köras automatiskt.
Nedan följer de viktigaste situationerna som utlöser automatisk eskalering och som utgör logiklagret bakom dina policyer. 💁
Allvarlighetsbaserad eskalering
Automatisk eskalering aktiveras när incidentens allvarlighetsgrad eller påverkan överskrider en viss tröskel. Incidenter med hög allvarlighetsgrad kräver omedelbar uppmärksamhet från ledningen, och automatisk eskalering kringgår flaskhalsar och informerar experterna inom några sekunder.
📌 Exempel: Ett fullständigt avbrott i tjänsten, ett fel i betalningsgatewayen eller en större försämring som påverkar många användare eller kärnsystem kräver automatisk eskalering.
Tidsbaserad eskalering
Om ingen bekräftar eller löser incidenten inom ett definierat tidsfönster eskaleras varningen automatiskt till nästa nivå. Detta förhindrar att ärenden stagnerar, särskilt utanför normal arbetstid eller när den första responsen inte är tillgänglig eller är överbelastad.
📌 Exempel: Efter 10–15 minuter utan bekräftelse eskaleras ärendet från den första responspersonen till en senioringenjör. Om ärendet fortfarande är olöst efter ytterligare 30–60 minuter eskaleras det ytterligare.
Kontextuell eskalering
Denna eskaleringslogik tar hänsyn till incidentens kontextuella attribut, såsom den drabbade tjänsten eller systemet, tjänsteägaren, det drabbade kundsegmentet (internt vs. externt, VIP vs. vanligt) eller den funktionella domänen (databas, nätverk, integration). Baserat på den kontexten dirigeras varningar till den mest relevanta responsenheten eller teamet.
Här undviker du att överbelasta teamen med irrelevanta incidenter, minskar responstiden och säkerställer att specialister hanterar problem inom sitt område.
📌 Exempel: En latensökning i betalningstjänsten bör direkt pingas till betalningsteamet, eller ett backend-fel i faktureringsmikrotjänsten bör meddelas faktureringsteamet.
Metadatabaserad eskalering
Moderna verktyg för varningar och incidenter samlar in metadata såsom ursprungskälla (vilket övervakningsverktyg eller vilken varningsregel som utlöste incidenten), användar-/kundidentitet, plats, historisk frekvens av liknande incidenter eller etiketter. Detta hjälper dig att tillämpa mer detaljerad, intelligent logik istället för att förlita dig på grova allvarlighetsgrader eller tidsbaserade regler.
📌 Exempel: Återkommande varningar från samma delsystem kan tyda på ett djupare, systemiskt problem som kräver snabbare eskalering. Eller så kan varningar för VIP-kunder utlösa ytterligare aviseringar.
Kombinera triggers för att skapa smartare, anpassningsbara eskaleringspolicyer
I praktiken förlitar sig många team inte bara på en typ av utlösare. Istället skapar de hybrideskaleringspolicyer som kombinerar regler för allvarlighetsgrad, tid, sammanhang och metadata.
Denna lagerindelade metod gör det möjligt för teamen att skapa eskaleringspolicyer som både är responsiva (snabba när det behövs) och smarta (selektiva för att minimera störningar), vilket resulterar i förbättrade incidentresultat och effektivare resursfördelning.
🔍 Visste du att? På 1700-talet använde besättningar på fartyg en strikt eskaleringskedja vid nödsituationer. Om en underordnad sjöman upptäckte en fara ringde han i en klocka och vidarebefordrade meddelandet uppåt i hierarkin tills kaptenen fattade det slutgiltiga beslutet.
Hur man utformar effektiva eskaleringsvägar
Att utforma eskaleringsvägar handlar om att bygga ett system som på ett tillförlitligt sätt vidarebefordrar rätt varningar till rätt personer med minimal friktion.
Här är ett praktiskt, stegvist ramverk som du kan använda i komplexa, distribuerade miljöer.
P.S. Vi kommer också att undersöka hur vissa ClickUp-funktioner kan hjälpa dig här! 🤩
Steg 1: Definiera tydliga eskaleringskriterier, nivåer och ansvarsområden
Börja med att definiera vad som utgör en incident som kräver eskalering. Dokumentera objektiva kriterier så att alla jourhavande tekniker, oavsett om de är nya L1-respondenter eller erfarna SRE, tolkar incidentens allvar på samma sätt.
Detta ger ett tydligt eskaleringsflöde, eliminerar oklarheter och säkerställer att automatiseringen endast aktiveras när det verkligen behövs.
Inkludera kriterier som:
- Allvarlighetsgränser: Tjänsten nere, betalningsfel, autentiseringsproblem, datakorruption och säkerhetsvarningar
- Konsekvenser: Kundpåverkande avbrott, försämrad intern service, fel i partner-API:er, efterlevnad eller säkerhetsrisker.
- Affärskritisk kontext: Stor påverkan på kunder, intäktspåverkande flöden, högrisk-system (t.ex. betalningar, fakturering)
När kriterier och utlösare har definierats, kartlägg vem som ska varnas och vilka deras ansvarsområden är vid varje eskaleringspunkt.
Definiera nivåer tydligt:
- Nivå ett (primär jourhavande incidenthanterare): Fungerar som första instans och ansvarar för bekräftelse, initial triage och försök till avhjälpande åtgärder.
- Nivå två (backup/specialist/SME): Tillhandahåller djup teknisk expertis och löser komplexa systemproblem.
- Nivå tre (teknikchef/ledning): Övervakar större incidenter, godkänner större åtgärder, samordnar kommunikation mellan team och initierar eskalering till leverantören vid behov.
🚀 Fördel med ClickUp: Använd ClickUp Docs för att upprätthålla en enda källa till information om eskaleringskriterier, nivåer och ansvarsområden, samt dokumentera roller och ansvarsområden, inklusive vem som:
- Bekräftar och mildrar
- Kommunicerar med intressenter
- Hanterar eskaleringar från leverantörer eller externa partners
- Leder incidentkommandot
Du kan också koppla dessa specifika roller till relevanta ClickUp-uppgifter för att hålla samman sammanhanget.
Skapa din egen kunskapsbas:
När eskaleringskriterier och ansvar har definierats behöver teamen ett konsekvent sätt att registrera, spåra och analysera tekniska incidenter. ClickUps mall för incidentrapportering erbjuder ett strukturerat, lättillgängligt system för att dokumentera IT- och driftsincidenter på ett och samma ställe.
Den är inbyggd i ClickUp Docs och hjälper incidenthanteringsteamen att registrera viktiga detaljer såsom incidentens allvarlighetsgrad, berörda tjänster, tidslinjer, sammanfattningar av grundorsaker, åtgärder för att mildra effekterna och uppföljningsåtgärder.
Steg 2: Standardisera skapandet av incidenter
Innan eskaleringsvägarna ens aktiveras behöver ditt team ett tillförlitligt sätt att samla in, normalisera och berika incidentdata. Om den initiala incidentrapporten är ofullständig eller inkonsekvent kommer även den mest sofistikerade eskaleringslogiken att misslyckas.
Standardiseringen bör:
- Sortera inkommande varningar: Konvertera varningar till enhetliga anpassade fält som allvarlighetsgrad, kategori, påverkad tjänst, incidenttyp och bekräftelsestatus.
- Berika incidenten automatiskt: Hämta metadata, inklusive kluster, distributions-ID, tjänsteägare eller beroenden.
- Se till att varje incident fångar sammanhanget: Logga vem som rapporterade den, hur den upptäcktes, miljö (produktion/staging) och alla relevanta loggar eller skärmdumpar.
Skapa ett ClickUp-formulär direkt från listan där incidenter spåras och utforma det så att det återspeglar din operativa verklighet och de relevanta data som din eskaleringslogik är beroende av. På så sätt registreras varje incident i ditt system i ett enhetligt format som automatiseringen kan hantera på ett tillförlitligt sätt, istället för fragmenterade meddelanden i chatt, e-post eller dashboards.

Gruppera fält medvetet så att varje incident sätts in i sitt sammanhang:
- Identifiering (titel, sammanfattning)
- Klassificering (allvarlighetsgrad, typ, påverkad tjänst)
- Källa (övervakning, användare, API)
- Bevis (loggar, skärmdumpar)
- Affärskontext (SLA-nivå, kundpåverkan)
Varje formulärinlämning skapar automatiskt en ny ClickUp-uppgift, där alla svar mappas till ClickUp-anpassade fält. Detta säkerställer att incidenter normaliseras vid skapandet, vilket eliminerar tvetydigheter och behovet av manuell incidenthantering.
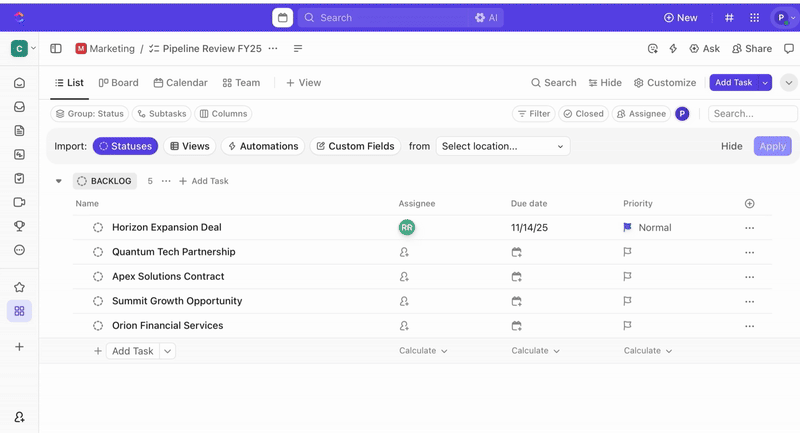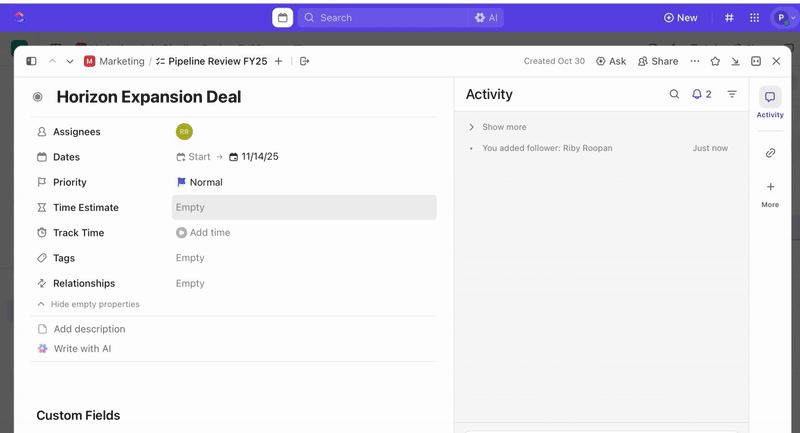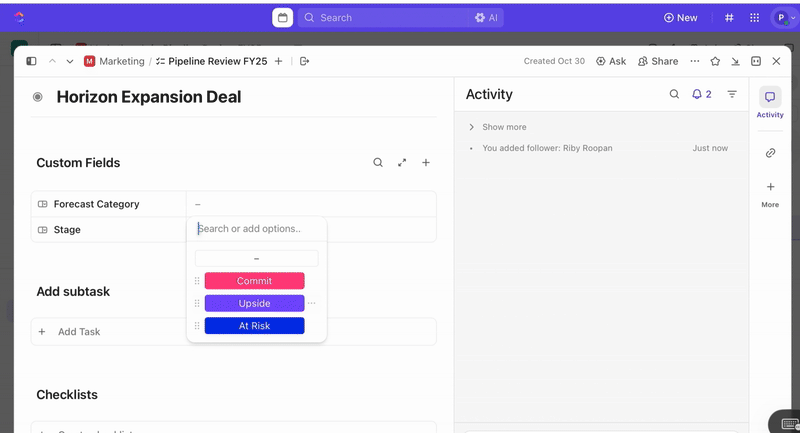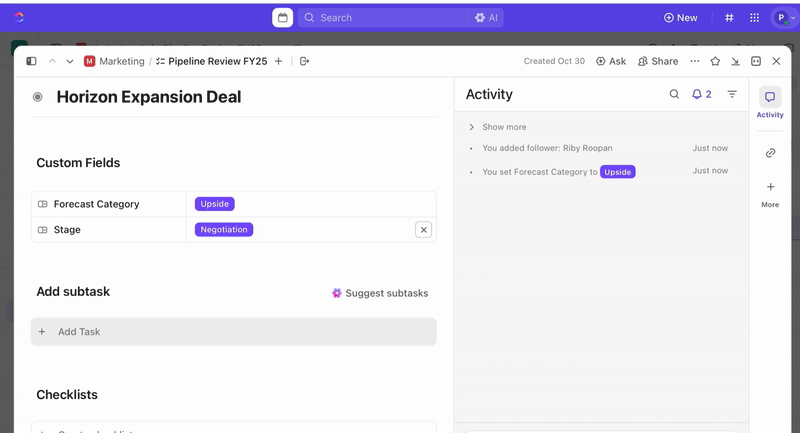
När uppgifterna har skapats kan du använda anpassade fält för att styra triagering och prioritering (t.ex. allvarlighetsgrad, påverkan, responsgrupp) och definiera anpassade statusar i ClickUp som återspeglar incidentens olika stadier (Ny > Triagering > Utredning > Åtgärd > Lösta).
Steg 3: Skapa eskaleringsvägen (dvs. sekvens + tidpunkt + kanaler)
Detta är kärnan i processen. Dela upp processen i steg, där varje steg definierar vem som ska meddelas, via vilken eller vilka kanaler och efter hur lång tid utan bekräftelse eller lösning.
- Definiera ”bekräftelsetidsgräns” och ”lösningstidsgräns”.
Här är ett exempel på ett arbetsflöde:
- Steg ett: Den första jourhavande personen som omedelbart underrättas via SMS/chattkanal måste bekräfta inom 5–10 minuter.
- Steg två: Om ingen bekräftelse eller åtgärd sker inom de närmaste 15–20 minuterna, eskalera till backup-/SRE-teamet + senioringenjören via SMS/chattkanal/e-post.
- Steg tre: Om problemet fortfarande inte är löst efter ytterligare 30–60 minuter, eskalera det till teknikchefen/ledningen och utlösa eventuellt en kanal för ”allvarliga incidenter”.
- Bestäm om eskaleringsvägen ska "upprepas" (meddela samma nivå igen) eller "gå vidare".
- För kritiska incidenter kan du ställa in upprepade aviseringar tills någon svarar. För incidenter med lägre prioritet kan det vara lämpligt med ett enda eskaleringsflöde.
- Se till att vägen dokumenteras med hjälp av en mall för kundtjänstsvar och att den är tillgänglig för all berörd personal.
❗️ Obs! En ”bekräftelsetidsgräns” är den tid som den första responsen har på sig att bekräfta att de har sett varningen, medan en ”lösningstidsgräns” är den tid som teamet har på sig att åtgärda eller mildra problemet innan nästa eskalering träder i kraft.
Steg 4: Integrera automatisering och verktygsstöd
När dina kriterier, triageprocess och berikningsstandarder är på plats är nästa steg att möjliggöra eskalering utan att förlita sig på att människor ska komma ihåg när eller till vem eskaleringen ska ske. Det är här ClickUp Automations blir en central del av ditt arbetsflöde.

Du kan ställa in automatiseringsmöjligheter som reagerar på samma signaler som ditt team använder vid incidenter. Här är några exempel:
- Om allvarlighetsgraden uppdateras till SEV-1 ➡️ Tilldela omedelbart senior SRE + meddela jourchattkanalen
- Om statusen förblir oförändrad i X minuter ➡️ Utlösa eskalering till nästa nivå
- Om förfallodagen passerar (t.ex. bekräftelsedatum) ➡️ Eskalera till L2
Och det är här ClickUp Brain tar saker och ting ännu längre. Det använder kontexten från din arbetsyta för att leverera omedelbara svar, automatiskt generera uppdateringar och stödja tillgång till kunskap.
Använd verktyg som AI Prioritize för att automatiskt utvärdera incidenter och ställa in rätt prioritet med hjälp av din egen logik. Exempel på frågor:
- Om incidenten påverkar produktionen och kunderna, ange Prioritet: Brådskande.
- Om den tilldelade personen är SRE-teamet och loggarna nämner "latens", ställ in Prioritet: Hög.
- Om beskrivningen innehåller säkerhetsrelaterade nyckelord som ”intrång”, ange Prioritet: Brådskande.
När prioriteten har fastställts tar AI Assign över och tilldelar automatiskt incidenter baserat på de villkor du definierar.
Du kan skapa uppmaningar som:
- Om prioriteten är brådskande och den påverkade tjänsten innehåller "betalningar", tilldela den till Senior SRE.
- Om incidenttypen är databas och regionen är US-East, tilldela DB On-Call.
- Om uppgiftsnamnet innehåller ”säkerhet” ska du tilldela den till SecOps-chefen.
Testa dessa uppmaningar på de tre första uppgifterna innan du tillämpar dem på hela listan.
🚀 ClickUp-fördel: Implementera intelligenta automatiseringsbots som finns i ditt arbetsutrymme och svarar på aktiviteter i realtid med ClickUp Super Agents.
De har fullständig kännedom om dina uppgifter, dokument, chattar och processer, så varje automatiserad åtgärd är kontextuell.
Du kan till exempel placera en Team StandUp Agent i din "Produktionsincidentmapp" så att den automatiskt publicerar en daglig sammanfattning varje morgon. Ditt team får en omedelbar översikt som visar antalet öppnade incidenter, vilka som fortfarande är olösta och vilka förändringar som har skett under de senaste 24 timmarna.
Koppla nu ihop det med en Ambient Answers Agent i din kanal #incident-room. När responspersonalen ställer frågor som ”Var finns SEV-1-runbooken?” eller ”Har denna API misslyckats tidigare?”, hämtar den information från din arbetsplats kunskap för att ge omedelbara, korrekta svar.

Steg 5: Standardisera kommunikationskanalerna
När incidenter eskalerar är det lika viktigt hur och var teamen kommunicerar som vem som får informationen. Utan standardiserade kanaler går uppdateringar förlorade, beslut dupliceras och intressenterna får motstridig information.
Definiera tydliga eskaleringskanaler för varje steg i incidentens livscykel och använd dem konsekvent i alla team:
| Kriterier | Kanalnamn | Syfte |
| SEV-1 eller SEV-2 upptäckt | #incident-critical | Central plats för allvarliga varningar och omedelbar prioritering |
| Aktiv felsökning pågår | #incident-warroom | Samarbetsplattform i realtid för ingenjörer, produktutveckling, kvalitetssäkring och support |
| Ledningens insyn krävs | #incident-leadership | Viktiga uppdateringar för chefer och ledande befattningshavare |
| Kommunikation med kunder krävs | #incident-comms | Utrymme för att utarbeta, granska och samordna extern kundkommunikation |
| Granskning efter incident initierad | #incident-retro | Strukturerad diskussion för retrospektiva anteckningar, lärdomar och åtgärdspunkter |
Varje kanal har en definierad målgrupp och ett definierat syfte, vilket hjälper teamen att minska störningarna samtidigt som de relevanta teamen hålls informerade.
🚀 ClickUp-fördel: Anpassa din kanalstrategi med ett inbyggt kommunikationslager med hjälp av ClickUp Chat. Varje varning, uppdatering och beslut förblir direkt kopplat till incidentens uppgift, lista eller utrymme där arbetet utförs.
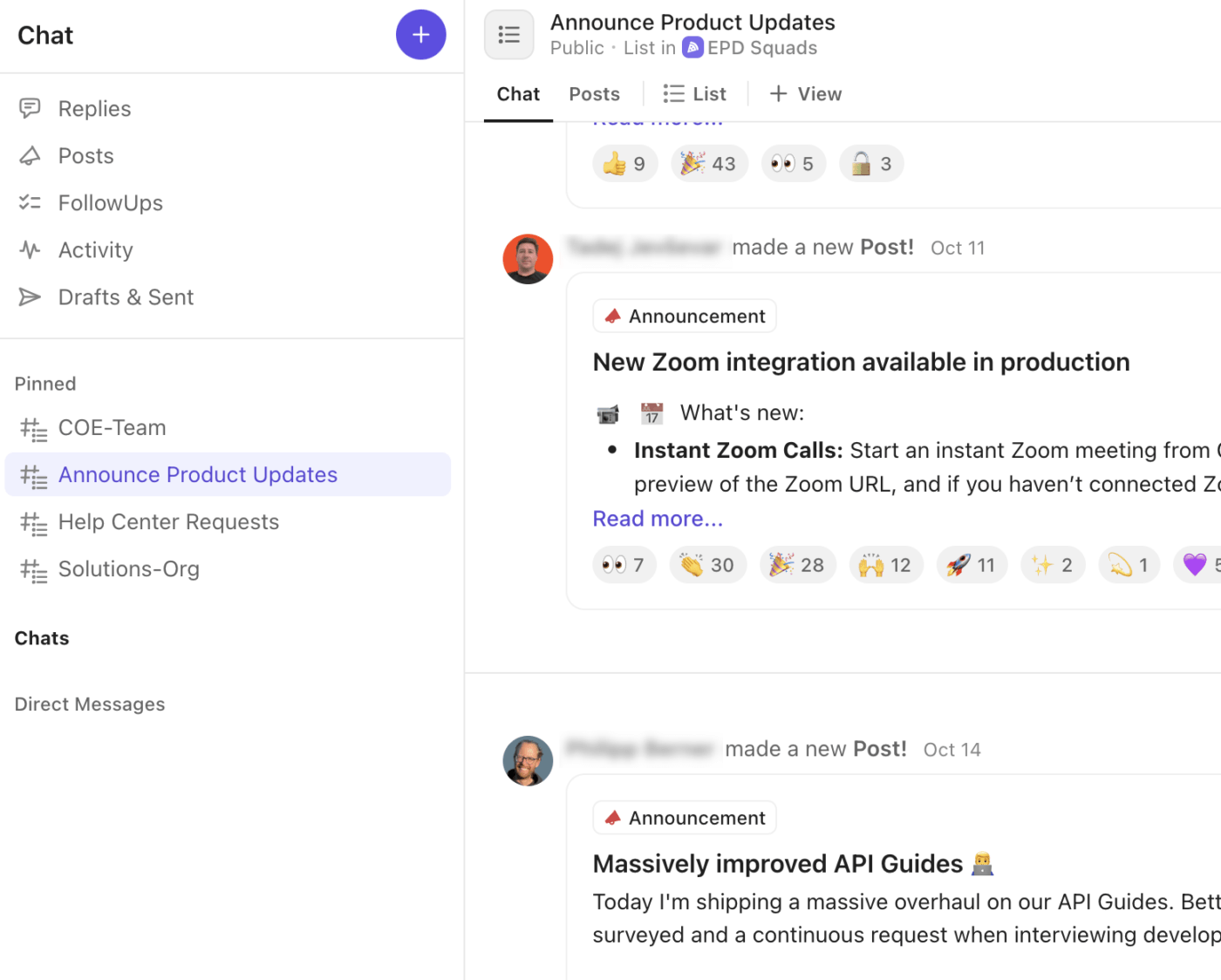
Så här förbättrar ClickUp Chat ditt incidentflöde:
- Skapa dedikerade chattrådar för kritiska diskussioner, krigsrum, ledarskap eller kundkommunikation.
- Omvandla chattmeddelanden till ClickUp-uppgifter direkt, så att beslut och uppföljningar inte går förlorade i konversationen.
- Hoppa in i snabba ljud- eller videosamtal med ClickUp SyncUps för livekoordinering av incidenter eller ledningsbriefingar.
- Publicera ”meddelanden” eller uppdateringar för att sprida information om incidentstatus på hög nivå inom hela företaget.
- Tagga teammedlemmar, lägg in skärmdumpar och bifoga loggar direkt i chatten, så att den tekniska kontexten finns nära till hands.
Steg 6: Testa, granska och förfina din eskaleringsväg
Eskaleringspolicyer måste utvecklas i takt med dina system. Här är vad du måste göra regelbundet:
| Aktivitet | Vad du ska testa eller granska | Varför det är viktigt |
| Brandövningar på jourtid (kvartalsvis) | Simulera P1- och P2-incidenter, verifiera eskaleringstid och routing | Säkerställer att automatiseringar och eskaleringsvägar fungerar under press |
| Validering av eskaleringsvägar | Kontrollera om det finns återvändsgränder i eskaleringarna eller saknade ägare. | Förhindrar att incidenter fastnar utan synlighet |
| Timers för bekräftelse- och lösningsprocesser | Jämför konfigurerade timers med faktiska MTTA och MTTR | Håller eskaleringstiderna realistiska och effektiva |
| Bedömning av varningsutmattning | Identifiera responspersonal som får överdrivna eller upprepade varningar | Minskar utbrändhet och missade kritiska varningar |
| Allvarlighetsgrad och prioriteringsnoggrannhet | Kontrollera om incidenterna har klassificerats korrekt. | Förbättrar vidarebefordran, responshastighet och eskaleringsnoggrannhet |
| Uppföljning efter incidenten | Se till att åtgärder från retrospektiva möten genomförs | Förhindrar upprepade incidenter och systemfel |
Verktyg och integrationer för automatisering av eskalering
I det här avsnittet går vi igenom incidenthanteringsprogramvara som hjälper dig att upptäcka incidenter snabbare, vidarebefordra dem direkt och hålla alla team informerade utan manuella uppföljningar.
1. ClickUp (bäst för att samla tvärfunktionella eskaleringar i ett sammankopplat arbetsutrymme för incidenter)
Traditionella eskaleringsmetoder tvingar teamen att jonglera med e-postmeddelanden, kalkylblad, chattråd och spridda anteckningar, vilket gör det nästan omöjligt att få en tydlig, realtidsbild av vad som händer.
ClickUps uppgiftshanteringsprogram för eskaleringshantering eliminerar störningar genom att samla alla eskaleringsdetaljer i ett enda, organiserat arbetsutrymme.
Låt oss titta på några funktioner i programvaran för IT-tillgångshantering som gör ClickUp till det bästa valet för team som hanterar stora volymer av eskaleringar och komplexa incidentarbetsflöden.
Se hur du arbetar på ditt sätt
Visualisera dina uppgifter från flera vinklar för att anpassa dem efter dina operativa behov med ClickUp Views:
- ClickUp List View så att SRE-ledare kan sortera incidenter efter allvarlighetsgrad, återstående SLA-tid eller jourgrupper för snabb triagering.
- ClickUp Board View låter teknikchefer visualisera överlämningar och teamansvar under eskaleringar.
- ClickUp Gantt View för programledare för att kartlägga milstolpar och beroenden för lösningar mellan olika tjänster.
- ClickUp Workload View för jourplanerare som säkerställer att teknikerna inte blir överbelastade under perioder med många incidenter.
Omvandla mötesdiskussioner till handling
Under eskaleringar och incidentgranskningar kan det vara svårt att på ett tillförlitligt sätt dokumentera diskussioner och åtgärder. ClickUp AI Notetaker ansluter automatiskt till möten som är schemalagda i Google Kalender, Outlook, Zoom eller Teams och spelar in och transkriberar konversationen.
Efter mötet:
- Få tillgång till sökbara transkriptioner och sammanfattningar av åtgärdspunkter
- Säkerställ tydlighet med hjälp av anteckningar som sparats i ClickUp Docs. Detta gör det enkelt att länka tillbaka till incidentuppgifter eller retrospektiva rapporter.
- Ställ frågor till ClickUp AI om mötesinnehåll för att klargöra beslut eller upptäcka missade uppföljningar.
Anslut till befintliga verktyg i din teknikstack
Bakom kulisserna säkerställer ClickUp Integrations och Webhooks-ekosystemet sömlös anslutning till resten av din stack.
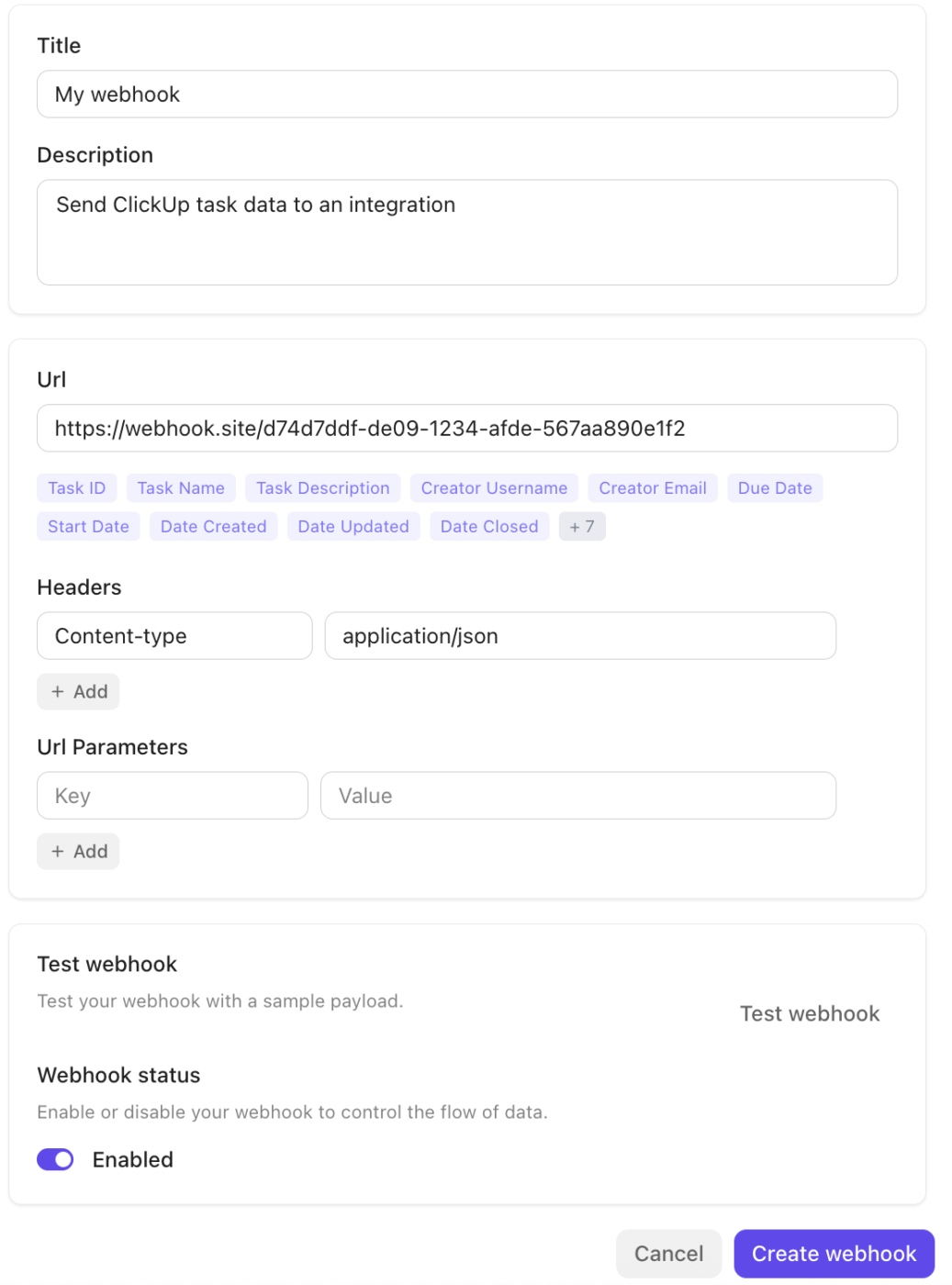
Plattformen integreras direkt med verktyg som Slack, GitHub, Zoom och andra, och stöder Webhooks via sitt offentliga API för att sända händelser (uppdateringar av uppgifter och statusändringar) till externa tjänster eller automatiseringspipelines. Detta gör det enkelt att starta arbetsflöden, synkronisera data eller eskalera incidenter mellan system utan manuella överlämningar.
Samla alla dina AI-verktyg
För att ta automatisering och kontext till nästa nivå erbjuder ClickUp BrainGPT kontextuell AI i dina eskaleringsarbetsflöden. Det är en kontextuell super-AI-app som förstår dina uppgifter, dokument och historiska sammanhang.
Med Enterprise Search och Connected Apps kan du omedelbart hämta information från din arbetsyta, Slack, Google Drive, GitHub och mer. Under live-samtal om incidenter kan du med Talk-to-Text i ClickUp diktera eskaleringsanteckningar eller instruktioner handsfree, så att ingenting missas.
Du kan också standardisera upprepbara uppgifter med anpassade AI-prompter och sparade prompter, till exempel: ”Sammanfatta alla olösta incidenter och rekommendera eskaleringsåtgärder.”
ClickUps bästa funktioner
- Prioritera kritiska problem: Använd ClickUp Task Priorities för att markera brådskande eller viktiga eskaleringar.
- Organisera komplexa eskaleringssekvenser: Ställ in ClickUp Task Dependencies för att länka relaterade uppgifter (t.ex. "Väntar på" eller "Blockerar") så att eskaleringsstegen undviker förhastade åtgärder eller flaskhalsar.
- Dela upp incidenter i hanterbara delar: Dela upp eskaleringar i detaljerade åtgärdspunkter och fördela dem mellan teamen med hjälp av inbäddade deluppgifter.
- Spåra lösningshastigheten noggrant: Logga och övervaka hur lång tid eskaleringsuppgifterna tar att bekräfta och lösa med ClickUps Project Time Tracking.
Begränsningar i ClickUp
- Med så många funktioner, vyer och anpassningsalternativ måste teamen ofta gå igenom en inlärningskurva innan allt känns intuitivt.
ClickUp-priser
[Prislista]
ClickUp-betyg och recensioner
- G2: 4,7/5 (över 10 300 recensioner)
- Capterra: 4,6/5 (över 4 400 recensioner)
Vad säger verkliga användare om ClickUp?
Denna recension säger verkligen allt:
ClickUp samlar alla mina uppgifter, projekt och kommunikation på ett ställe, vilket gör det otroligt enkelt att hålla ordning. Jag älskar att allt är så anpassningsbart – från vyer och arbetsflöden till instrumentpaneler – så att jag kan strukturera min arbetsyta precis som jag vill. Möjligheten att samarbeta i realtid, tilldela uppgifter och följa framstegen utan att byta verktyg är en enorm fördel.
ClickUp samlar alla mina uppgifter, projekt och kommunikation på ett ställe, vilket gör det otroligt enkelt att hålla ordning. Jag älskar att allt är så anpassningsbart – från vyer och arbetsflöden till instrumentpaneler – så att jag kan strukturera min arbetsyta precis som jag vill. Möjligheten att samarbeta i realtid, tilldela uppgifter och följa framstegen utan att byta verktyg är en enorm fördel.
📮 ClickUp Insight: 21 % av människor säger att mer än 80 % av deras arbetsdag går åt till repetitiva uppgifter. Ytterligare 20 % säger att repetitiva uppgifter tar upp minst 40 % av deras dag.
Det är nästan hälften av arbetsveckan (41 %) som ägnas åt uppgifter som inte kräver mycket strategiskt tänkande eller kreativitet (som uppföljningsmejl 👀).
ClickUps Super Agents hjälper till att eliminera detta slit. Tänk på att skapa uppgifter, påminnelser, uppdateringar, mötesanteckningar, utkast till e-postmeddelanden och till och med skapa heltäckande arbetsflöden! Allt detta (och mer) kan automatiseras på nolltid med ClickUp, din app för allt som rör arbetet.
💫 Verkliga resultat: Lulu Press sparar 1 timme per dag och anställd genom att använda ClickUp Automations, vilket leder till en 12-procentig ökning av arbetseffektiviteten.
2. PagerDuty (bäst för realtidsvarningar och intelligent jourrespons)
PagerDuty är en molnbaserad plattform för hantering av IT-incidenter och digitala operationer som hjälper team att snabbt upptäcka, reagera på och lösa kritiska incidenter som avbrott eller säkerhetshot. Den ger SRE-, DevOps- och supportledare en tydlig väg från signal till lösning, med stöd av automatisering, AI-driven triage och djupt integrerade arbetsflöden.
Funktioner som Jeli Incident Analysis, PagerDuty Analytics och Runbook Automation hjälper teamen att minska driftstopp, eliminera rutinuppgifter och lära sig av varje incident.
PagerDuty bästa funktioner
- Automatisera incidenthanteringen med inbyggd jourhantering och dynamiska eskaleringspolicyer.
- Påskynda triageringen med hjälp av AIOps, som filtrerar bort falska larm, korrelerar händelser och lyfter fram de verkliga signalerna.
- Håll interna och externa intressenter informerade med Stakeholder Comms, Status Update Templates och Status Pages.
- Samla dina verktyg med över 700 integrationer och utbyggbara API:er med hjälp av övervakning, loggning, CI/CD och supportsystem.
Begränsningar för PagerDuty
- Hög volym av larm om integrationer och smarta tröskelvärden inte är justerade, vilket leder till störningar och trötthet.
- Duplicerade eller upprepade varningar kan förekomma under toppar, vilket gör det svårare att bekräfta under press.
PagerDuty-priser
- Gratis
- Professional: 25 USD/månad per användare
- Företag: 49 USD/månad per användare
- Företag: anpassad prissättning
PagerDuty-betyg och recensioner
- G2: 4,5/5 (över 900 recensioner)
- Capterra: 4,6/5 (över 200 recensioner)
Vad säger verkliga användare om PagerDuty?
En riktig användare säger:
PagerDuty gör incidentvarningar snabba och tillförlitliga. Det skickar rätt aviseringar vid rätt tidpunkt och håller vårt team organiserat. […] PagerDuty kan ibland kännas störande när varningarna inte filtreras ordentligt. Vissa inställningar är lite komplexa för nya användare.
PagerDuty gör incidentvarningar snabba och tillförlitliga. Det skickar rätt aviseringar vid rätt tidpunkt och håller vårt team organiserat. […] PagerDuty kan ibland kännas störande när varningarna inte filtreras ordentligt. Vissa inställningar är lite komplexa för nya användare.
💡 Proffstips: Skapa undantag, även i en tydlig eskaleringsväg. Låt kritiska avbrott, säkerhetsvarningar eller incidenter i reglerade miljöer gå direkt till seniora eller specialiserade responser.
3. GLPi (Bäst för heltäckande tillgångshantering och ITIL-anpassad serviceverksamhet)
Gestionnaire Libre de Parc Informatique (GLPi) är en fullskalig, öppen källkodsplattform för IT-tjänstehantering (ITSM) och IT-tillgångshantering (ITAM). Team får fullständig insyn i sin infrastruktur (hårdvara, mjukvara, licenser och nätverksenheter) och kan hantera incidenter, serviceförfrågningar och förändringar med hjälp av ITIL-anpassade processer.
Alla dina kontrakt och dokument, inklusive garantier och serviceavtal, förblir välorganiserade och riskerar inte att försvinna mellan olika system. Om du hanterar datacenter kan du med GLPi till och med visualisera layouter, kabeldragningar och energianvändning så att du alltid vet vad som händer bakom kulisserna.
GLPi:s bästa funktioner
- Använd plugins GLPI Inventory, OCS Inventory eller FusionInventory för att automatiskt upptäcka och katalogisera nya IT-tillgångar.
- Automatisera repetitiva uppgifter, ärendehantering, aviseringar och återkommande händelser för att minska manuellt arbete.
- Skapa en kunskapsbas för vanliga frågor, dokumentation och artiklar kopplade till ärenden för självbetjäning och teknisk support.
- Anslut till Azure/Entra, Centreon, Google, OAuth2 och webhooks för att synkronisera data, utlösa arbetsflöden och förbättra din CMDB.
GLPi-begränsningar
- Plugin-kompatibiliteten kan brytas mellan versioner, vilket orsakar extra underhållskostnader.
- Rapporterings-, analys- och exportfunktionerna känns begränsade och behöver förbättras.
GLPi-prissättning
- Anpassad prissättning
GLPi-betyg och recensioner
- G2: 4,6/5 (över 30 recensioner)
- Capterra: 4,5/5 (över 40 recensioner)
Vad säger verkliga användare om GLPi?
Här är vad en användare hade att säga:
Mycket anpassningsbart öppen källkodssystem för hantering av IT-tillgångar och supportärenden med ett stort stödjande community. Användargränssnittet är lite komplicerat för nybörjare. Plugins stöds inte alltid från gamla versioner till nya.
Mycket anpassningsbart öppen källkodssystem för hantering av IT-tillgångar och supportärenden med ett stort stödjande community. Användargränssnittet är lite komplicerat för nybörjare. Plugins stöds inte alltid från gamla versioner till nya.
4. Splunk On-Call (bäst för att vidarebefordra övervakningsvarningar direkt till tekniker)
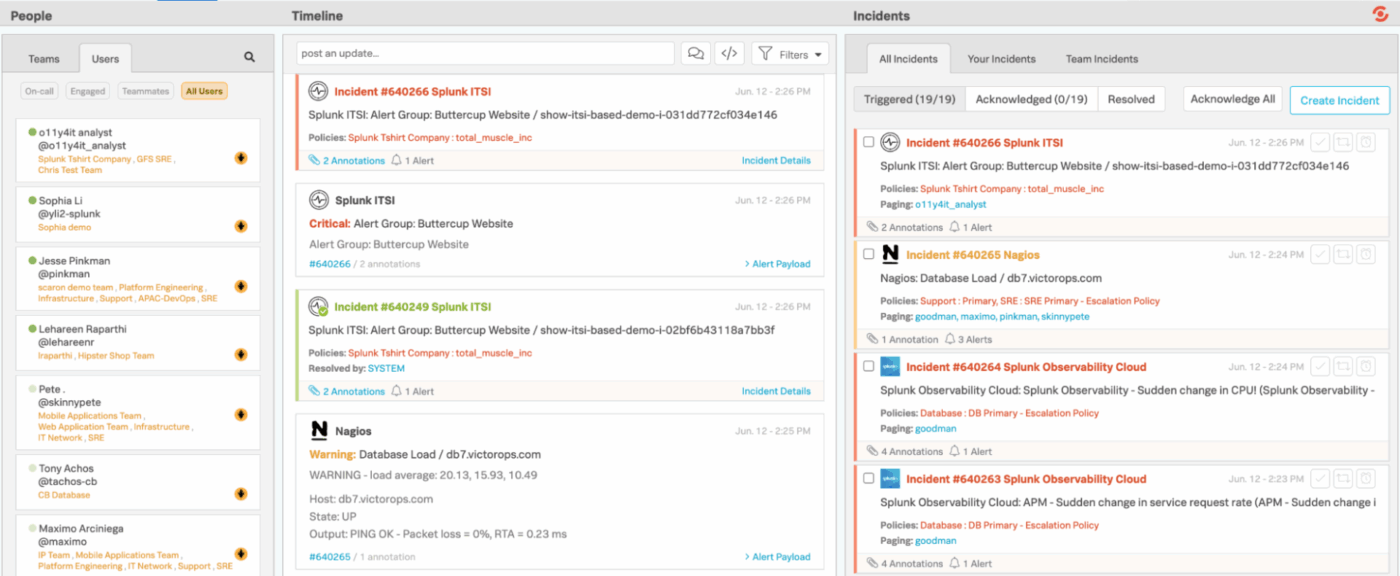
Splunk On-Call ger teknik- och jourteam ett snabbare och smidigare sätt att hantera incidenter, vilket eliminerar behovet av långsamma, traditionella ärendehanteringsflöden. Istället för att skicka varningar till en generisk kö integreras det direkt med din övervaknings- och observabilitetsstack och dirigerar omedelbart ärenden till rätt personer baserat på scheman, regler och sammanhang.
Mobil- och chattintegrationerna gör det enkelt att bekräfta, omdirigera eller lösa incidenter var du än befinner dig. Och bakom kulisserna håller Splunk On-Call en detaljerad förteckning över trender, beprövade mönster och eskaleringsbeteenden.
Splunk On-Calls bästa funktioner
- Utöka plattformens funktioner med över 1 000 granskade integrationer och tillägg från Splunk och det bredare communityt.
- Skapa anpassade instrumentpaneler och visuella rapporter för att övervaka volymen av larm, incidenternas status, responsenhetens prestanda och teamets arbetsbelastning.
- Filtrera snabbt incidenter efter din egen aktivitet, teamets incidenter eller allt som händer inom organisationen.
- Växla mellan Triggered, Acknowledged och Resolved Views för att se var varje incident befinner sig.
Begränsningar för Splunk On-Call
- Att schemalägga skift för flera team kan bli komplicerat om reglerna inte är fördefinierade.
- Begränsad möjlighet att generera detaljerade incidentrapporter med datumangivelser
Priser för Splunk On-Call
- Anpassad prissättning
Splunk On-Call-betyg och recensioner
- G2: 4,6/5 (över 40 recensioner)
- Capterra: 4,5/5 (över 30 recensioner)
Vad säger verkliga användare om Splunk On-Call?
En användare sammanfattade det så här:
Möjligheten att hantera incidenter, eskaleringar och ta över arbetsuppgifter från mina teamkamrater via mobilappen är fantastisk. […] Jag skulle vilja kunna schemalägga undantag och ändra den vanliga schemaläggningen från mobilappen för akuta schemaändringar.
Möjligheten att hantera incidenter, eskaleringar och ta över arbetsuppgifter från mina teamkamrater via mobilappen är fantastisk. […] Jag skulle vilja kunna schemalägga undantag och ändra den vanliga schemaläggningen från mobilappen för akuta schemaändringar.
🔍 Visste du att? Logiken att "vidarebefordra till rätt person om första nivån misslyckas" har sina rötter i de tidiga telefonväxlarna: när manuella operatörer inte kunde koppla ett samtal vidarebefordrade (eller eskalerade) systemet det till en annan operatör eller växel.
5. ServiceNow (bäst för att samordna företagsverksamhet med AI-assisterad automatisering)
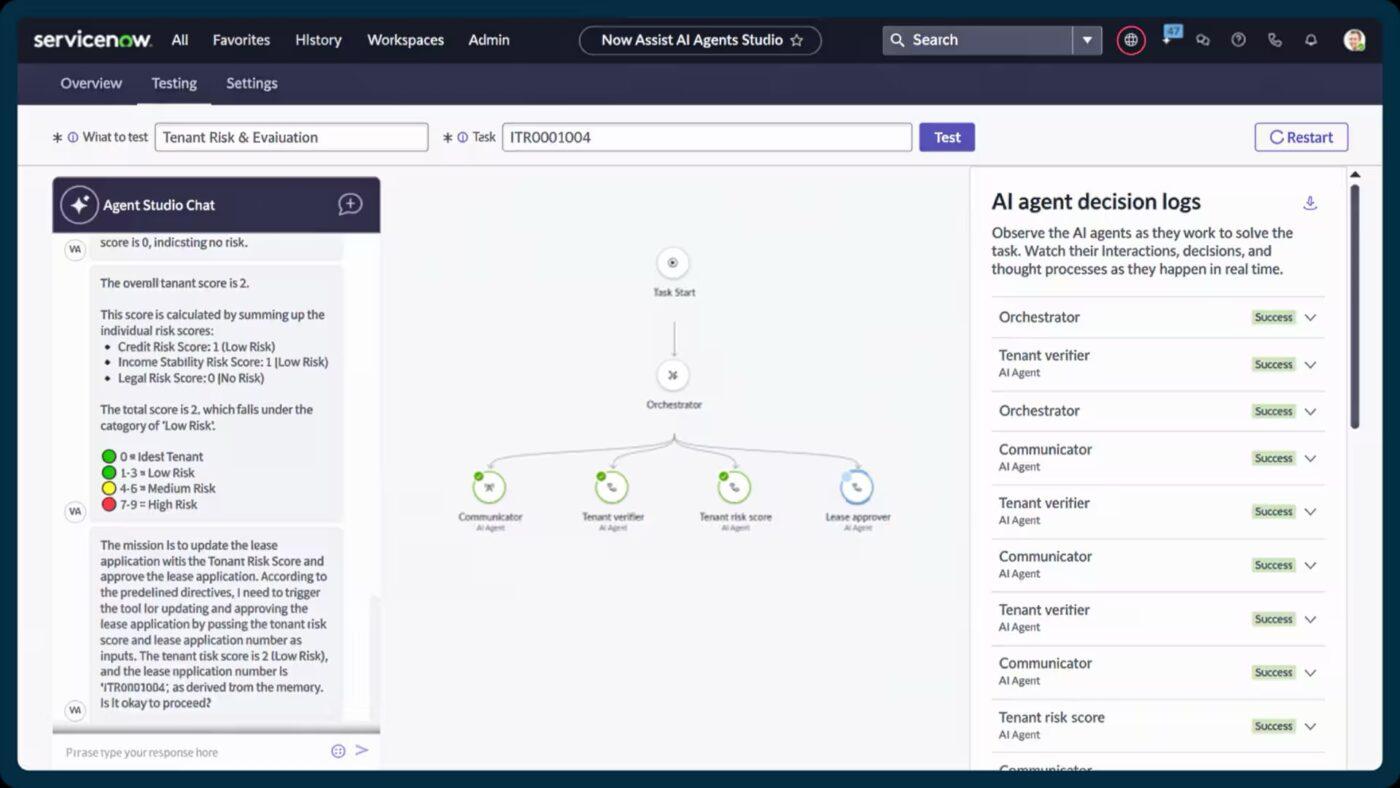
ServiceNow klassificerar, prioriterar och vidarebefordrar incidenter automatiskt så fort de loggas. Med funktioner som Now Assist för automatiserade rekommendationer om incidentärenden och smart innehållsgenerering kan responspersonalen lösa problem snabbare och med mer kontext.
Det sammanför incident-, förändrings- och tillgångshantering. På så sätt får du en realtidsbild av hur tjänsterna är kopplade, var flaskhalsar uppstår och vilka komponenter som kan bidra till återkommande störningar.
ServiceNows bästa funktioner
- Tilldela, vidarebefordra och övervaka fältuppgifter genom Field Service Management och Dispatcher Workspace.
- Ge anställda och kunder möjlighet att använda en självbetjäningsportal som drivs av AI Search och virtuella agenter.
- Använd inbyggda arbetsflöden och lågkodverktyg i App Engine för att utöka eller anpassa serviceprocesser.
- Automatisera repetitiva uppgifter och arbetsflöden mellan team med Flow Designer och Automation Engine.
Begränsningar i ServiceNow
- Användargränssnittet och portalens varumärkesalternativ känns föråldrade eller begränsande.
- Stort beroende av kvalificerad personal eller konsulter för implementering
Priser för ServiceNow
- Anpassad prissättning
Betyg och recensioner av ServiceNow
- G2: 4,4/5 (över 3 300 recensioner)
- Capterra: 4,5/5 (över 300 recensioner)
Vad säger verkliga användare om ServiceNow?
Så här uttryckte en användare det:
[…] De fördefinierade flödena är en annan höjdpunkt för mig, eftersom de effektiviserar processerna och sparar mycket tid, minimerar behovet av anpassade konfigurationer och möjliggör ett smidigare och effektivare arbetsflöde. […] Dessutom hade jag svårt att anpassa min anpassade lösning till kundtjänsthanteringssystemet, vilket krävde en hel del iterationer.
[…] De fördefinierade flödena är en annan höjdpunkt för mig, eftersom de effektiviserar processerna och sparar mycket tid, minimerar behovet av anpassade konfigurationer och möjliggör ett smidigare och effektivare arbetsflöde. […] Dessutom hade jag svårt att anpassa min anpassade lösning till kundtjänsthanteringssystemet, vilket krävde en hel del iterationer.
Bästa praxis och styrning
Här är några bästa praxis som säkerställer att automatiseringen förblir korrekt, undviker larmtrötthet och överensstämmer med affärs- och regelverkskrav.
- Definiera icke-förhandlingsbara eskaleringskriterier: Koppla utlösare till mätbara signaler som SLO-överträdelser, avvikelser, påverkan på kundnivå eller regleringskänslighet.
- Skapa tydliga roller på varje nivå: Använd en enkel RACI-karta för varje eskaleringsnivå så att ansvaret aldrig blir oklart under incidenter med hög press.
- Genomför dynamisk jourhantering: Justera automatiskt eskaleringsvägarna kring helger, helgdagar, kapacitetsgränser och överlämningar för att minska utbrändhet och förhindra tysta sidor.
- Infoga mänskliga kontrollpunkter för högrisk-scenarier: Även med automatisering, kräv manuell bekräftelse för incidenter som involverar exponering av kunddata, betalningar eller reglerade arbetsflöden.
- Håll fullständiga revisionsspår: Spara oföränderliga loggar över vem som blev uppringd, när de bekräftade, vilka automatiska åtgärder som vidtogs och vilka beslut som fattades.
🧠 Kul fakta: Världens äldsta kända skriftliga klagomål graverades på en lertavla omkring 1750 f.Kr. Det var i grunden en tidig eskalering av projektstatus. En kund vid namn Nanni skrev till köpmannen Ea-nāṣir och var rasande över att kopparn han fått var av sämre kvalitet än utlovat och att hans budbärare hade behandlats illa.
Vanliga utmaningar och hur man övervinner dem
Även med en tydlig eskaleringspolicy stöter teamen ofta på operativa hinder som fördröjer incidenthanteringen eller skapar förvirring.
Denna tabell belyser vanliga utmaningar som går utöver grundläggande inställningssteg och ger praktiska strategier för att övervinna dem.
| Utmaningar ❌ | Lösningar ✅ |
| Inkonsekvent kontext vid överlämningar | Använd ClickUps mallar för uppgiftslänkning och incidentrapporter för att upprätthålla en fullständig revisionsspår av incidentdetaljer, påverkade system och tidigare åtgärder på varje eskaleringsnivå. |
| Överbelasta responspersonal med varningar med låg prioritet | Implementera dynamisk prioritering med ClickUp Custom Fields och AI Prioritize för att filtrera incidenter baserat på allvarlighetsgrad, påverkan och SLA-trösklar. |
| Bristande synlighet mellan teamen | Skapa delade arbetsytor, lägg till kommentarer och skapa visuella ClickUp-whiteboards för att presentera uppdateringar i realtid för intressenter. |
| Fördröjd beslutsfattande vid kritiska incidenter | Automatisera aviseringar med hjälp av ClickUp Brain Max föreslagna åtgärder för att omedelbart varna rätt personal baserat på incidenttyp, allvarlighetsgrad och historiska mönster. |
| Svårigheter att spåra återkommande problem | Utnyttja ClickUps anpassade rapporterings- och återkommande uppgiftsmallar för att identifiera mönster, grundorsaker och återkommande incidenter för proaktiv förebyggande åtgärder. |
| Fragmenterad kunskap under eskalering | Håll centraliserade SOP:er, runbooks och incidentdokumentation i ClickUp Docs och länka dem till relevanta uppgifter för omedelbar referens under live-eskaleringar. |
| Ojämn fördelning av ansvar mellan skift | Använd ClickUps vyer för arbetsbelastning och tidslinje för att visualisera uppdrag och säkerställa att det inte uppstår överlappningar eller luckor vid skiftbyten eller överlämningar. |
| Manuell spårning av efterlevnad och revisionsbrister | Automatisera revisionsklara sammanfattningar med ClickUp Brain för att logga alla incidentåtgärder, aviseringar och lösningar. |
Mäta effekten av automatiserad eskalering
För att mäta effektiviteten hos automatiserad eskalering måste man fokusera på nyckeltal som volym, effektivitet och kvalitet. Dessa indikatorer visar om dina eskaleringsprocesser är snabbare, mer precisa och mindre frustrerande för både team och kunder.
Spåra följande mätvärden:
- Eskaleringsgrad (volym): Procentandel av ärenden som eskaleras bortom den första nivån. Höga grader kan indikera brister i den initiala prioriteringen eller kunskapsbaserna.
- Upprepad eskaleringsfrekvens (volym): Hur ofta samma problem eskaleras flera gånger. Indikerar ofullständiga lösningar eller förlorad kontext.
- Tid till eskalering (effektivitet): Tiden från upptäckt till eskalering. Kortare etappvaraktigheter indikerar snabbare automatiserad identifiering av kritiska problem.
- Fördröjningstid vid överlämning (effektivitet): Gapet mellan eskalering och när nästa team börjar arbeta för att belysa friktionen i vidarebefordran eller aviseringar.
- Lösningstid för eskalerade ärenden (effektivitet): Total tid från eskalering till lösning. Snabbare lösning visar automatiseringens effektivitet.
- Kundnöjdhetsbetyg (CSAT) (kvalitet): Feedback på eskalerade interaktioner för att mäta hur smidigt processen fungerar.
- Kontextöverföring (kvalitet): Om agenterna får tillgång till hela incidenthistoriken för att säkerställa att kunderna inte behöver upprepa informationen.
- Första kontaktlösning (FCR) (kvalitet): Andel problem som löses i en enda interaktion.
🚀 Fördelar med ClickUp: Få realtidsinformation, visuella och AI-drivna insikter om alla eskaleringsmått med ClickUp Dashboards.
Du kan spåra eskaleringstrender, flaskhalsar och prestanda med tabell-, cirkeldiagram-, stapeldiagram-, linjediagram-, beräknings- och tidsrapporteringskort. Övervaka eskaleringsfrekvens, upprepad eskalering och tid till eskalering med kort som är kopplade till uppgifter, anpassade fält och statusar.
För att ta det ett steg längre kan du använda AI-kort som AI Executive Summary, AI Project Update och AI StandUp för att belysa trender, förseningar och lösningsresultat.
Hantera dina incidenter snabbare med ClickUp
Många tror att eskalering av incidenter bara handlar om att vidarebefordra ett ärende till nästa person, men det är mycket mer än så. Det är ett strukturerat system där varje steg, från triage till lösning, fungerar i harmoni.
ClickUp ger dig den perfekta enhetliga arbetsytan. Med ClickUp Automations kan du automatiskt utlösa varningar, vidarebefordra uppgifter och uppdatera status. Och ClickUp Brain hjälper dig att prioritera incidenter, skapa sammanfattningar och föreslå nästa steg.
ClickUp AI Agents fungerar som intelligenta assistenter i din arbetsmiljö, medan ClickUp Dashboards ger en livevy av dina eskaleringar.
Registrera dig gratis på ClickUp idag!
Vanliga frågor (FAQ)
En eskaleringsväg för incidenter är en fördefinierad sekvens av steg som avgör hur ärenden ska vidarebefordras till rätt team eller person baserat på allvarlighetsgrad, påverkan och tidpunkt. Det säkerställer att incidenter hanteras effektivt och att ansvaret är tydligt. TEXT
Använd automatisering för väldefinierade incidenter med hög prioritet och tydliga kriterier (t.ex. driftstopp, säkerhetsöverträdelser). Reservera manuell eskalering för tvetydiga eller kritiska situationer som kräver mänskligt omdöme eller ytterligare kontext.
Plattformar som ClickUp, PagerDuty, Jira Service Management och ServiceNow möjliggör automatiserad vidarebefordran, aviseringar och uppdateringar. De hjälper teamen att minska förseningar och upprätthålla strukturerade incidentarbetsflöden.
Ställ in tydliga tröskelvärden för varningar, prioritera efter allvarlighetsgrad och använd intelligenta aviseringar. Begränsa upprepade aviseringar till kritiska incidenter och utnyttja instrumentpaneler eller AI-verktyg för att sammanfatta uppdateringar istället för att skicka varje mindre förändring.
Granska regelbundet eskaleringspolicyerna, minst en gång per kvartal eller efter större incidenter. Detta säkerställer att kriterier, ansvarsområden och automatiseringsregler återspeglar aktuella arbetsflöden, teamstrukturer och affärsprioriteringar.