
A legtöbb AI-bevezetési projekt nem azért bukik meg, mert a csapatok rossz modellt választottak, hanem azért, mert három hónap múlva senki sem emlékszik már, miért választották azt, vagy hogyan lehetne megismételni a beállítást. Az AI-projektek 46%-a a koncepció bizonyítása és a széles körű bevezetés között kerül törlésre.
Ez az útmutató végigvezeti Önt a Hugging Face AI-telepítéshez való használatán – a modellek kiválasztásától és tesztelésétől a telepítési folyamat kezeléséig –, így csapata gyorsabban szállíthat, anélkül, hogy kritikus döntések vesznének el a Slack-szálakban és szétszórt táblázatokban.
Mi az a Hugging Face?
A Hugging Face egy nyílt forráskódú platform és közösségi központ, amely előre betanított AI-modelleket, adatkészleteket és eszközöket biztosít gépi tanulási alkalmazások építéséhez és telepítéséhez.
Képzelje el úgy, mint egy hatalmas digitális könyvtárat, ahol használatra kész AI modelleket találhat, ahelyett, hogy hónapokat és jelentős erőforrásokat fordítana azok nulláról történő felépítésére.
A programot gépi tanulási mérnökök és adatelemzők számára tervezték, de eszközeit egyre gyakrabban használják többfunkciós termék-, tervező- és mérnöki csapatok is az AI integrálására a munkafolyamataikba.
Tudta-e, hogy: a szervezetek 63%-a nem rendelkezik megfelelő adatkezelési gyakorlatokkal az AI-hez. Ez gyakran projektek leállásához és erőforrások pazarlásához vezet.
Sok csapat számára a legnagyobb kihívást az AI bevezetésének rendkívüli összetettsége jelenti. A folyamat magában foglalja a megfelelő modell kiválasztását több ezer lehetőség közül, az alapul szolgáló infrastruktúra kezelését, a kísérletek verziókezelését, valamint a technikai és nem technikai érdekelt felek összehangolásának biztosítását.
A Hugging Face ezt egyszerűsíti a Model Hub segítségével, egy központi adattárral, amely több mint 2 millió modellt tartalmaz. A platform transzformátor-könyvtára a kulcs, amely ezeket a modelleket elérhetővé teszi, lehetővé téve azok betöltését és használatát néhány sor Python kóddal.
Még ezekkel a hatékony eszközökkel is az AI bevezetése továbbra is kihívást jelent a projektmenedzsment számára, mivel a siker érdekében gondosan nyomon kell követni a modell kiválasztását, tesztelését és bevezetését.
📮ClickUp Insight: A tudásmunkások 92%-a kockáztatja, hogy fontos döntései elvesznek a csevegések, e-mailek és táblázatok között. Egységes rendszer nélkül a döntések rögzítésére és nyomon követésére a kritikus üzleti információk elvesznek a digitális zajban.
A ClickUp feladatkezelési funkcióival soha nem kell aggódnia emiatt. Készítsen feladatokat csevegésből, feladatkommentekből, dokumentumokból és e-mailekből egyetlen kattintással!
📚 Olvassa el még: A legjobb Hugging Face alternatívák LLM-ek, NLP és AI munkafolyamatokhoz
Hugging Face modellek, amelyeket telepíthet
A Hugging Face Hub használata kezdetben nyomasztónak tűnhet. Több százezer modell közül a legfontosabb, hogy megértsd a főbb kategóriákat, hogy megtaláld a projektedhez leginkább megfelelőt. A modellek skálája a kis, hatékony, egyetlen célra tervezett modellektől a hatalmas, általános célú modellekig terjed, amelyek komplex érvelést is képesek kezelni.
Feladatspecifikus nyelvi modellek
Ha csapatának egy jól meghatározott problémát kell megoldania, gyakran nincs szüksége hatalmas, általános célú modellre. Egy ilyen modell futtatásának ideje és költségei meghaladhatják a lehetőségeket, különösen akkor, ha egy kisebb, célzottabb AI-eszköz jobban megfelelne a feladatra. Itt jönnek képbe a feladatspecifikus modellek.
Ezek olyan modellek, amelyeket egy adott funkcióra képeztek ki és optimalizáltak. Mivel specializáltak, általában kisebbek, gyorsabbak és erőforrás-hatékonyabbak, mint nagyobb társaik.
Ez ideálisvá teszi őket olyan termelési környezetekben, ahol a sebesség és a költség fontos tényezők. Sokuk akár standard CPU hardveren is futtatható, így drága GPU-k nélkül is elérhetőek.
A feladatspecifikus modellek gyakori típusai a következők:
- Szövegbesorolás: Használja ezt a funkciót a szövegek előre meghatározott címkékbe sorolásához, például az ügyfél-visszajelzések „pozitív” vagy „negatív” kategóriákba sorolásához, vagy a támogatási jegyek témák szerinti címkézéséhez.
- Érzelemelemzés: Ez segít meghatározni egy szöveg érzelmi hangvételét, ami hasznos lehet a márka figyelemmel kíséréséhez a közösségi médiában.
- Névvel ellátott entitások felismerése: Kivonjon dokumentumokból konkrét entitásokat, például személyeket, helyeket és szervezeteket, hogy segítsen strukturálni a strukturálatlan adatokat.
- Összefoglalás: Hosszú cikkeket vagy jelentéseket tömör összefoglalókba sűrítsen, ezzel értékes olvasási időt takarítva meg csapatának.
- Fordítás: A szöveg automatikus átalakítása egyik nyelvről a másikra
📚 Olvassa el még: Hogyan használhatja a Hugging Face-t szövegösszefoglaláshoz?
Nagy nyelvi modellek
Előfordul, hogy a projektje többet igényel, mint egyszerű osztályozást vagy összefoglalást. Lehet, hogy olyan AI-ra van szüksége, amely kreatív marketing szövegeket tud generálni, kódot tud írni, vagy komplex felhasználói kérdésekre tud beszélgetésszerűen válaszolni. Ilyen esetekben valószínűleg egy nagy nyelvi modell (LLM) felé fog fordulni.
Az LLM-ek olyan modellek, amelyek milliárdnyi paraméterrel rendelkeznek, és hatalmas mennyiségű internetes szöveg és adat alapján vannak betanítva. Ez a kiterjedt betanítás lehetővé teszi számukra, hogy megértsék a finom árnyalatokat, a kontextust és a komplex érvelést. A Hugging Face-en elérhető népszerű nyílt forráskódú LLM-ek között megtalálhatók a Llama, Mistral és Falcon családok modelljei.
Ennek az erőnek az ára a jelentős számítási erőforrásigény. Ezeknek a modelleknek a telepítéséhez szinte mindig nagy teljesítményű GPU-kra és sok memóriára (VRAM) van szükség.
Hogy azok hozzáférhetőbbek legyenek, használhat olyan technikákat, mint a kvantálás, amely kis teljesítménycsökkenés mellett csökkenti a modell méretét, így az kevésbé erős hardveren is futtatható.
📚 Olvassa el még: Mik azok az LLM-ügynökök az AI-ban, és hogyan működnek?
Szöveg-kép és multimodális modellek
Az adatok nem mindig csak szövegek. Lehet, hogy csapatának képeket kell generálnia egy marketingkampányhoz, le kell írnia egy megbeszélés hanganyagát, vagy meg kell értenie egy videó tartalmát. Ilyenkor válnak elengedhetetlenül fontossá a multimodális modellek, amelyeket különböző típusú adatok kezelésére terveztek.
A multimodális modellek legnépszerűbb típusa a szöveg-kép modell, amely szöveges leírásokból generál képeket. Az olyan modellek, mint a Stable Diffusion , diffúziónak nevezett technikát használnak, hogy egyszerű utasításokból lenyűgöző vizuális elemeket hozzanak létre. De a lehetőségek messze túlmutatnak a képgeneráláson.
A Hugging Face-ről telepíthető egyéb gyakori multimodális modellek:
- Képaláírás: Képekhez automatikusan generáljon leíró szöveget, ami kiválóan alkalmas az akadálymentes hozzáférés és a tartalomkezeléshez.
- Beszédfelismerés: Írja le a beszélt hangot írásos szöveggé olyan modellekkel, mint az OpenAI Whisperje.
- Vizuális kérdés-válasz: Tegyen fel kérdéseket egy képpel kapcsolatban, és kapjon szöveges választ, például: „Milyen színű az autó ezen a fotón?”
Az LLM-ekhez hasonlóan ezek a modellek is nagy számítási teljesítményt igényelnek, és általában GPU-ra van szükségük a hatékony működéshez.
📚 Olvassa el még: Több mint 50 AI-képes prompt lenyűgöző vizuális effektek létrehozásához
Ha szeretné megtudni, hogyan alkalmazhatók ezek a különböző típusú AI-modellek a gyakorlatban, nézze meg ezt az áttekintést a valós AI-alkalmazásokról különböző iparágakban és funkciókban.
Milyen szintű az AI-érettség a szervezetében?
316 szakember bevonásával végzett felmérésünkből kiderül, hogy a valódi AI-átalakulás nem csupán az AI-funkciók bevezetését igényli. Töltse ki az AI-érettségi értékelést, hogy megtudja, hol áll a szervezete, és mit tehet a pontszámának javítása érdekében.
Hogyan állítsa be a Hugging Face-t mesterséges intelligencia telepítéséhez
Mielőtt telepítené az első modellt, helyesen kell beállítania a helyi környezetet és a Hugging Face fiókot. Gyakori frusztrációt okoz a csapatoknak, ha a különböző tagok beállításai nem konzisztensek, ami a klasszikus „az én gépemen működik” problémához vezet. Ha néhány percet szán ennek a folyamatnak a szabványosítására, azzal órákat takaríthat meg a későbbi hibaelhárításban.
- Hozzon létre egy Hugging Face fiókot, és generáljon hozzáférési tokent. Először regisztráljon egy ingyenes fiókot a Hugging Face weboldalán. Miután bejelentkezett, lépjen a profiljába, kattintson a „Beállítások” gombra, majd válassza az „Access Tokens” (Hozzáférési tokenek) fület. Generáljon egy új tokent, amely legalább „olvasási” jogosultsággal rendelkezik; erre lesz szüksége a modellek letöltéséhez.
- Telepítse a szükséges Python könyvtárakat. Nyissa meg a terminált, és telepítse a szükséges alapvető könyvtárakat. A két legfontosabb a transformers és a huggingface_hub. A pip segítségével telepítheti őket: pip install transformers huggingface_hub
- Konfigurálja a hitelesítést. Az elérési token használatához bejelentkezhet a parancssoron keresztül a huggingface-cli login parancs futtatásával, és a kérésre beillesztheti a tokenjét, vagy beállíthatja azt környezeti változóként a rendszerében. A parancssori bejelentkezés gyakran a legegyszerűbb módja a kezdésnek.
- Ellenőrizze a beállítást. A legjobb módja annak, hogy megbizonyosodjon arról, hogy minden működik, egy egyszerű kód futtatása. Próbáljon meg betölteni egy alapmodellt a transformers könyvtár pipeline funkciójával. Ha hiba nélkül fut, akkor készen áll a használatra.
Ne feledje, hogy a Hub egyes modelljei „zárt” modellek, ami azt jelenti, hogy a modell oldalán található licencfeltételeket kell elfogadnia, mielőtt tokenjével hozzáférhetne azokhoz.
Ne feledje, hogy nyomon követni, hogy ki rendelkezik milyen jogosultságokkal és milyen környezetkonfigurációkat használnak, önmagában is egy projektmenedzsment feladat, amely a csapat növekedésével egyre kritikusabbá válik.
🌟 Ha Hugging Face modelleket integrál szélesebb körű szoftverrendszerekbe, a ClickUp szoftverintegrációs sablonja segít a munkafolyamatok vizualizálásában és a több lépésből álló technikai integrációk nyomon követésében.
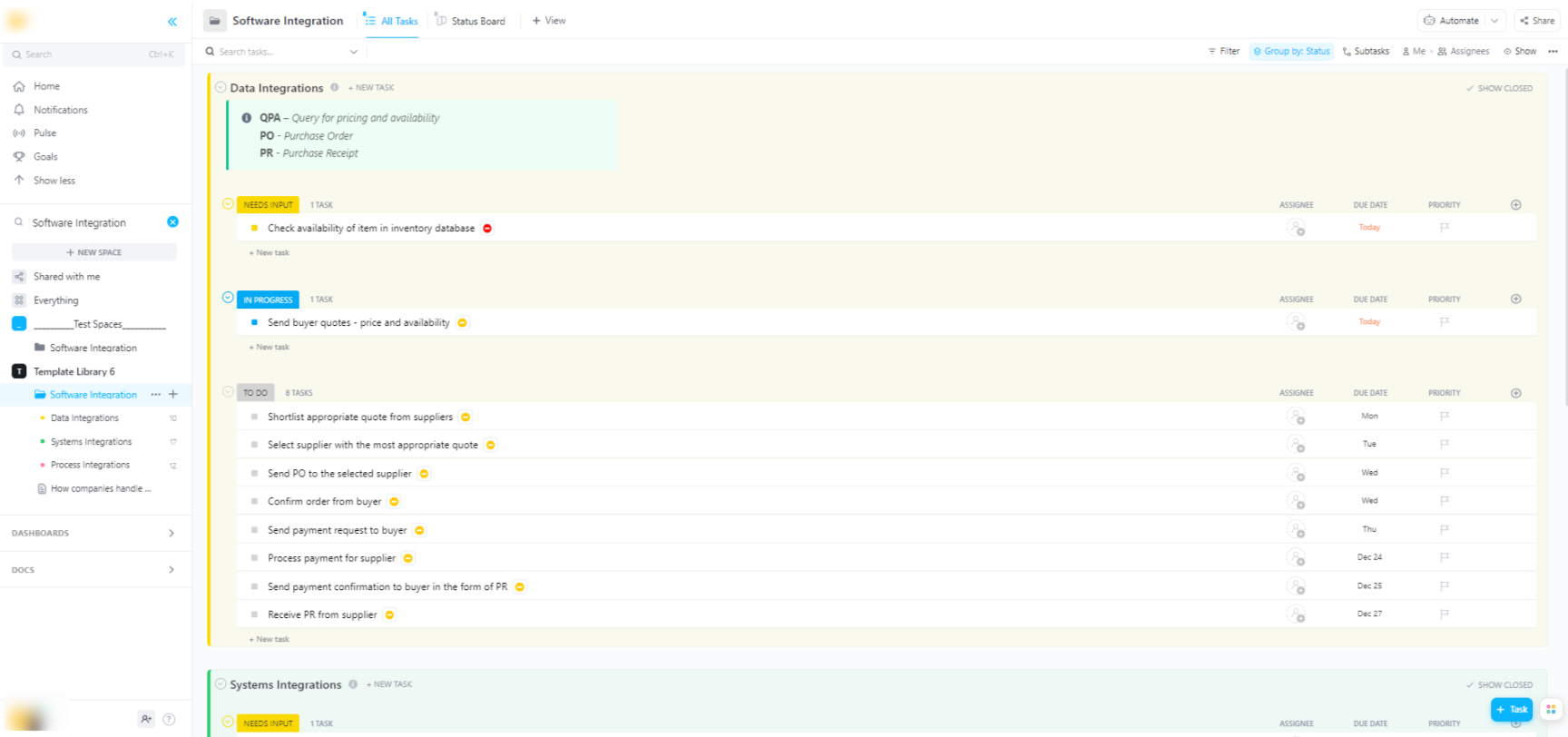
A sablon egy könnyen követhető rendszert biztosít, amelynek segítségével:
- Vizualizálja a különböző szoftvermegoldások közötti kapcsolatokat
- Hozzon létre és rendeljen feladatokat a csapat tagjaihoz a zökkenőmentesebb együttműködés érdekében.
- Az integrációval kapcsolatos összes feladatot egy helyen szervezze meg
A Hugging Face modellek telepítési lehetőségei
Miután helyben tesztelte a modellt, a következő kérdés az: hol fogja használni? A modell telepítése egy olyan termelési környezetbe, ahol mások is használhatják, kritikus lépés, de a lehetőségek zavarosak lehetnek. A rossz út választása lassú teljesítményhez, magas költségekhez vagy a felhasználói forgalom kezelésének képtelenségéhez vezethet.
A választás a konkrét igényeitől függ, például a várható forgalomtól, a költségvetéstől és attól, hogy gyors prototípust vagy skálázható, termeléskész alkalmazást fejleszt-e.
Hugging Face Spaces
Ha gyorsan kell létrehoznia egy demót vagy egy belső eszközt, a Hugging Face Spaces gyakran a legjobb választás. A Spaces egy ingyenes platform gépi tanulási alkalmazások tárolására, és tökéletesen alkalmas olyan prototípusok létrehozására, amelyeket megoszthat a csapatával vagy az érdekelt felekkel.
Az alkalmazás felhasználói felületét olyan népszerű keretrendszerekkel építheti fel, mint a Gradio vagy a Streamlit, amelyek segítségével néhány sor Python kóddal könnyedén interaktív demókat hozhat létre.
A Space létrehozása olyan egyszerű, mint kiválasztani a kívánt SDK-t, összekapcsolni a Git-tárat a kódjával, és kiválasztani a hardvert. Míg a Spaces ingyenes CPU-szintet kínál az alapvető alkalmazásokhoz, a nagyobb igénybevételt jelentő modellekhez fizetős GPU-hardverre is frissíthet.
Ne feledje a korlátozásokat:
- Nem alkalmas nagy forgalmú API-khoz: A Spaces demókhoz lett tervezve, nem pedig több ezer egyidejű API-kérés kiszolgálásához.
- Hidegindítás: Ha a Space inaktív, akkor erőforrás-megtakarítás céljából „alvó módba” kerülhet, ami késleltetheti az első felhasználó hozzáférését.
- Git-alapú munkafolyamat: Az összes alkalmazáskódját egy Git-tárházon keresztül kezeli, ami kiválóan alkalmas a verziókezelésre.
Hugging Face Inference API
Ha modellt kell integrálnia egy meglévő alkalmazásba, akkor valószínűleg API-t szeretne használni. A Hugging Face Inference API lehetővé teszi a modellek futtatását anélkül, hogy magának kellene kezelnie az alapul szolgáló infrastruktúrát. Egyszerűen elküldi az HTTP-kérelmet az adataival, és visszakapja az előrejelzést.
Ez a megközelítés ideális, ha nem szeretne szerverrel, méretezéssel vagy karbantartással foglalkozni. A Hugging Face két fő szintet kínál ehhez a szolgáltatáshoz:
- Ingyenes Inference API: Ez egy sebességkorlátozott, megosztott infrastruktúra opció, amely kiválóan alkalmas fejlesztésre és tesztelésre. Tökéletes alacsony forgalmú felhasználási esetekhez vagy akkor, ha még csak most kezded.
- Inference Endpoints: Termelési alkalmazásokhoz érdemes az Inference Endpoints szolgáltatást használni. Ez egy fizetős szolgáltatás, amely dedikált, automatikusan méretezhető infrastruktúrát biztosít, így alkalmazása nagy terhelés mellett is gyors és megbízható marad.
Az API használata magában foglalja egy JSON payload elküldését a modell végpontjának URL-jére, az azonosító tokenjével a kérés fejlécében.
Felhőalapú platform telepítése
Azoknál a csapatoknál, amelyek már jelentős jelenléttel rendelkeznek egy nagy felhőszolgáltatónál, mint például az Amazon Web Services (AWS), a Google Cloud Platform (GCP) vagy a Microsoft Azure, a leglogikusabb választás lehet a telepítés ott. Ez a megközelítés biztosítja a legnagyobb ellenőrzést, és lehetővé teszi a modell integrálását a meglévő felhőszolgáltatásokkal és biztonsági protokollokkal.
Az általános munkafolyamat magában foglalja a modell és függőségeinek „konténerizálását” a Docker segítségével, majd a konténer telepítését egy felhőalapú számítástechnikai szolgáltatásra. Minden felhőszolgáltató rendelkezik olyan szolgáltatásokkal és integrációkkal, amelyek egyszerűsítik ezt a folyamatot:
- AWS SageMaker: natív integrációt kínál a Hugging Face modellek képzéséhez és telepítéséhez.
- Google Cloud Vertex AI: Lehetővé teszi a Hub-ból származó modellek telepítését a kezelt végpontokra.
- Azure Machine Learning: Eszközöket biztosít a Hugging Face modellek importálásához és kiszolgálásához.
Bár ez a módszer több beállítást és DevOps szakértelmet igényel, gyakran ez a legjobb megoldás nagy léptékű, vállalati szintű telepítésekhez, ahol teljes ellenőrzést kell gyakorolni a környezet felett.
📚 Olvassa el még: Munkafolyamat-automatizálás: automatizálja a munkafolyamatokat a termelékenység növelése érdekében
Hogyan futtassuk a Hugging Face modelleket következtetéshez?
A Hugging Face AI-telepítéshez való használatakor a „következtetés futtatása” az a folyamat, amikor a betanított modellt új, még nem látott adatokra vonatkozó előrejelzések készítésére használja. Ez az a pillanat, amikor a modell elvégzi azt a munkát, amelyre telepítette. Ennek a lépésnek a helyes végrehajtása elengedhetetlen a reagáló és hatékony alkalmazás létrehozásához.
A csapatok számára a legnagyobb frusztrációt a lassú vagy hatástalan következtető kód írása jelenti, ami rossz felhasználói élményhez és magas működési költségekhez vezethet. Szerencsére a transformers könyvtár többféle lehetőséget kínál a következtetés futtatására, amelyek mindegyike a egyszerűség és az ellenőrzés között egyensúlyt teremt.
- Pipeline API: Ez a legegyszerűbb és leggyakoribb módja a kezdésnek. A pipeline() függvény elvonja a figyelmet a legtöbb bonyolult feladatról, és elvégzi az adatok előfeldolgozását, a modell továbbítását és az utómunkálatokat. Sok standard feladat, például az érzelemelemzés esetében egyetlen sor kóddal előrejelzést kaphat.
- AutoModel + AutoTokenizer: Ha nagyobb ellenőrzést szeretne gyakorolni a következtetés folyamatára, közvetlenül használhatja az AutoModel és AutoTokenizer osztályokat. Ez lehetővé teszi, hogy manuálisan kezelje a szöveg tokenizálását és a modell nyers kimenetének ember által olvasható előrejelzéssé történő konvertálását. Ez a megközelítés akkor hasznos, ha egyéni feladaton dolgozik, vagy speciális elő- vagy utómunkálati logikát kell implementálnia.
- Kötegelt feldolgozás: A hatékonyság maximalizálása érdekében, különösen GPU-n, a bemeneteket kötegben, nem pedig egyenként kell feldolgozni. A bemenetek kötegének egyetlen előrehaladási lépésben történő elküldése a modellen keresztül lényegesen gyorsabb, mint az egyes bemenetek egyenkénti elküldése.
Az inferencia kód teljesítményének figyelemmel kísérése a telepítési életciklus kulcsfontosságú része. Az olyan mutatók nyomon követése, mint a késleltetés (mennyi időt vesz igénybe egy előrejelzés) és az átviteli sebesség (hány előrejelzést lehet másodpercenként készíteni), koordinációt és egyértelmű dokumentációt igényel, különösen akkor, ha a csapat különböző tagjai új modellverziókat tesztelnek.
📚 Olvassa el még: A legjobb AI-csapatok együttműködési eszközei
Lépésről lépésre: Hugging Face modell telepítése
Vessünk egy pillantást egy egyszerű érzelemelemző modell telepítésének teljes példájára. Az alábbi lépések végigvezetik Önt a modell kiválasztásától a tesztelhető végpontig.
- Válassza ki a modellt: Lépjen a Hugging Face Hub oldalra, és a bal oldalon található szűrők segítségével keressen olyan modelleket, amelyek „szövegklasszifikációt” végeznek. Jó kiindulási pont a distilbert-base-uncased-finetuned-sst-2-english. Olvassa el a modellkártyát, hogy megértse a modell teljesítményét és használatát.
- Telepítse a függőségeket: Helyi Python környezetében győződjön meg arról, hogy a szükséges könyvtárak telepítve vannak. Ehhez a modellhez csak a transformers és a torch szükséges. Futtassa a pip install transformers torch parancsot.
- Helyi tesztelés: A telepítés előtt mindig győződjön meg arról, hogy a modell a várakozásoknak megfelelően működik a gépen. Írjon egy rövid Python szkriptet a modell betöltéséhez a pipeline segítségével, és tesztelje azt egy minta mondattal. Például: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english"), majd classifier("A ClickUp a legjobb termelékenységi platform!").
- Telepítés létrehozása: Ebben a példában a Hugging Face Spaces szolgáltatást használjuk a gyors és egyszerű telepítéshez. Hozzon létre egy új Space-t, válassza ki a Gradio SDK-t, és hozzon létre egy app.py fájlt, amely betölti a modellt, és meghatározza az azzal való interakcióhoz szükséges egyszerű Gradio felületet.
- Telepítés ellenőrzése: Miután a Space elindult, az interaktív felület segítségével tesztelheti azt. Közvetlen API-kérést is küldhet a Space végpontjára, hogy JSON-választ kapjon, amely megerősíti, hogy programozási szempontból működik.
Ezeket a lépéseket követően már rendelkezik egy működő modellel. A projekt következő fázisában figyelemmel kell kísérni a modell használatát, meg kell tervezni a frissítéseket, és ha a modell népszerűvé válik, akkor esetlegesen bővíteni kell az infrastruktúrát.
Azok számára, akik több fázisból álló komplex AI-telepítési projekteket irányítanak – az adatelőkészítéstől a termelési telepítésig –, a ClickUp Software Project Management Advanced Template átfogó struktúrát biztosít.
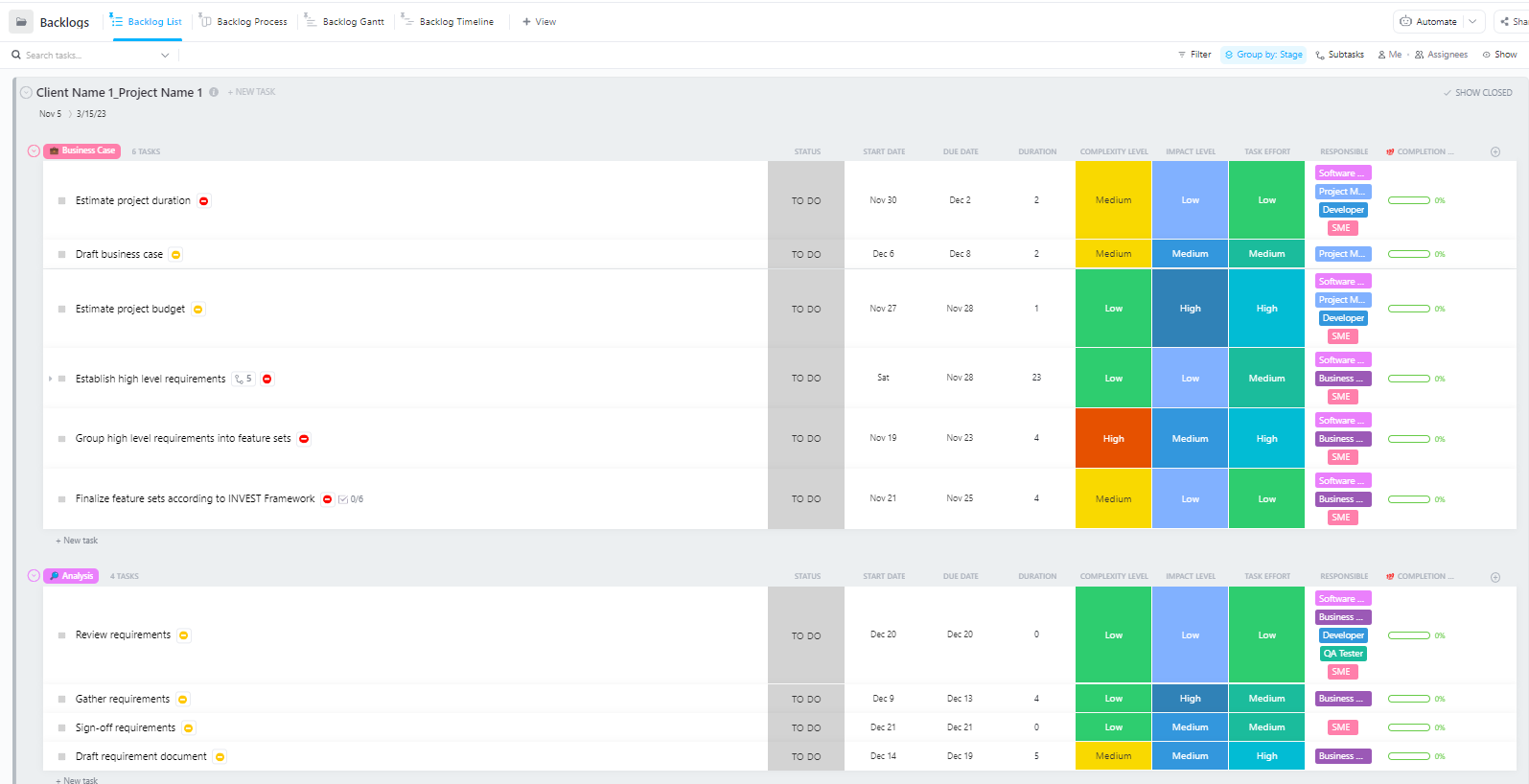
Ez a sablon a következőket segíti a csapatoknak:
- Kezelje a projekteket több mérföldkővel, feladattal, erőforrással és függőséggel
- A projekt előrehaladását Gantt-diagramokkal és ütemtervekkel szemléltetheti.
- Dolgozzon zökkenőmentesen együtt csapattársaival a sikeres befejezés érdekében.
A Hugging Face telepítésének gyakori kihívásai és azok megoldása
Még egy világos tervvel is előfordulhat, hogy a telepítés során néhány akadályba ütközik. A rejtélyes hibaüzenetekre bámulni rendkívül frusztráló lehet, és megakadályozhatja a csapat előrehaladását. Íme néhány a leggyakoribb kihívások közül, és azok megoldása. 🛠️
🚨Probléma: „A modell hitelesítést igényel”
- Ok: Megpróbál hozzáférni egy „zárt” modellhez, amelyhez el kell fogadnia a licencfeltételeket.
- Megoldás: Lépjen a modell oldalára a Hubon, olvassa el és fogadja el a licencszerződést. Győződjön meg arról, hogy a használt hozzáférési token rendelkezik „olvasási” jogosultsággal.
🚨Probléma: „CUDA memóriahiány”
- Ok: A betölteni kívánt modell túl nagy a GPU memóriájához (VRAM) képest.
- Megoldás: A leggyorsabb megoldás egy kisebb verziójú vagy kvantált modell használata. Megpróbálhatja csökkenteni a kötegméretet is a következtetés során.
🚨Probléma: „trust_remote_code error”
- Ok: A Hub egyes modelljeinek futtatásához egyedi kód szükséges, és biztonsági okokból a könyvtár alapértelmezés szerint nem hajtja végre azt.
- Megoldás: Ezt megkerülheti úgy, hogy a modell betöltésekor hozzáadja a trust_remote_code=True parancsot. Mindig először ellenőrizze a forráskódot, hogy megbizonyosodjon a biztonságáról.
🚨Probléma: „Tokenizer mismatch”
- Ok: Az Ön által használt tokenizer nem pontosan az, amellyel a modellt betanították, ami helytelen bemenetekhez és gyenge teljesítményhez vezet.
- Megoldás: Mindig ugyanabból a modell ellenőrzőpontból töltse be a tokenizálót, mint magát a modellt. Például: AutoTokenizer. from_pretrained("modell-név")
🚨Probléma: „A sebességkorlát túllépése”
- Ok: Túl sok kérést küldött a rövid idő alatt az ingyenes Inference API-nak.
- Megoldás: Termelési használatra frissítsen egy dedikált Inference Endpointra. Fejlesztéshez cache-t alkalmazhat, hogy elkerülje ugyanazon kérések többszöri elküldését.
Elengedhetetlen, hogy nyomon kövessük, mely megoldások működnek mely problémák esetén. Ha nincs egy központi hely, ahol ezeket a megállapításokat dokumentálhatjuk, a csapatok gyakran ugyanazt a problémát oldják meg újra és újra.
📮 ClickUp Insight: Minden negyedik alkalmazott négy vagy több eszközt használ csak azért, hogy kontextust teremtsen a munkában. Egy fontos részlet elrejtve lehet egy e-mailben, kibővítve egy Slack szálban, és dokumentálva egy külön eszközben, ami arra kényszeríti a csapatokat, hogy időt pazaroljanak az információk keresésére ahelyett, hogy elvégeznék a munkájukat.
A ClickUp az egész munkafolyamatot egyetlen egységes platformra egyesíti. Az olyan funkcióknak köszönhetően, mint a ClickUp Email Project Management, a ClickUp Chat, a ClickUp Docs és a ClickUp Brain, minden összekapcsolódik, szinkronizálódik és azonnal elérhetővé válik. Búcsút inthet a „munkával kapcsolatos munkának”, és visszaszerezheti produktív idejét.
💫 Valós eredmények: A csapatok a ClickUp használatával hetente több mint 5 órát spórolhatnak meg – ez évente több mint 250 óra fejenként –, mivel megszüntetik az elavult tudásmenedzsment-folyamatokat. Képzelje el, mit tudna létrehozni a csapata egy extra hétnyi termelékenységgel minden negyedévben!
Hogyan kezelje az AI-bevezetési projekteket a ClickUp-ban
A Hugging Face használata az AI telepítéséhez megkönnyíti a modellek csomagolását, tárolását és kiszolgálását, de nem szünteti meg a valós telepítéssel járó koordinációs terheket. A csapatoknak továbbra is nyomon kell követniük, mely modelleket tesztelik, össze kell hangolniuk a konfigurációkat, dokumentálniuk kell a döntéseket, és mindenkit – az ML-mérnököktől a termék- és üzemeltetési szakemberekig – egyformán tájékoztatniuk kell.
Amikor a mérnöki csapat különböző modelleket tesztel, a termékcsapat meghatározza a követelményeket, és az érdekelt felek frissítéseket kérnek, az információk szétszóródnak a Slacken, az e-mailekben, a táblázatokban és a különböző dokumentumokban.
Ez a munkaterjedés – a munkatevékenységek több, egymással nem kommunikáló eszköz között való felaprózódása – zavart kelt és mindenki munkáját lassítja.
Itt játszik kulcsszerepet a ClickUp, a világ első konvergált AI munkaterülete, amely a projektmenedzsmentet, a dokumentációt és a csapatkommunikációt egyetlen munkaterületbe egyesíti.
Ez a konvergencia különösen értékes az AI-bevezetési projektekben, ahol a technikai és nem technikai érdekelt feleknek közös láthatóságra van szükségük anélkül, hogy öt különböző eszközt kellene használniuk.
Ahelyett, hogy a frissítéseket jegyzetek, dokumentumok és csevegési szálak között szétszórnák, a csapatok egy helyen kezelhetik a teljes telepítési életciklust.
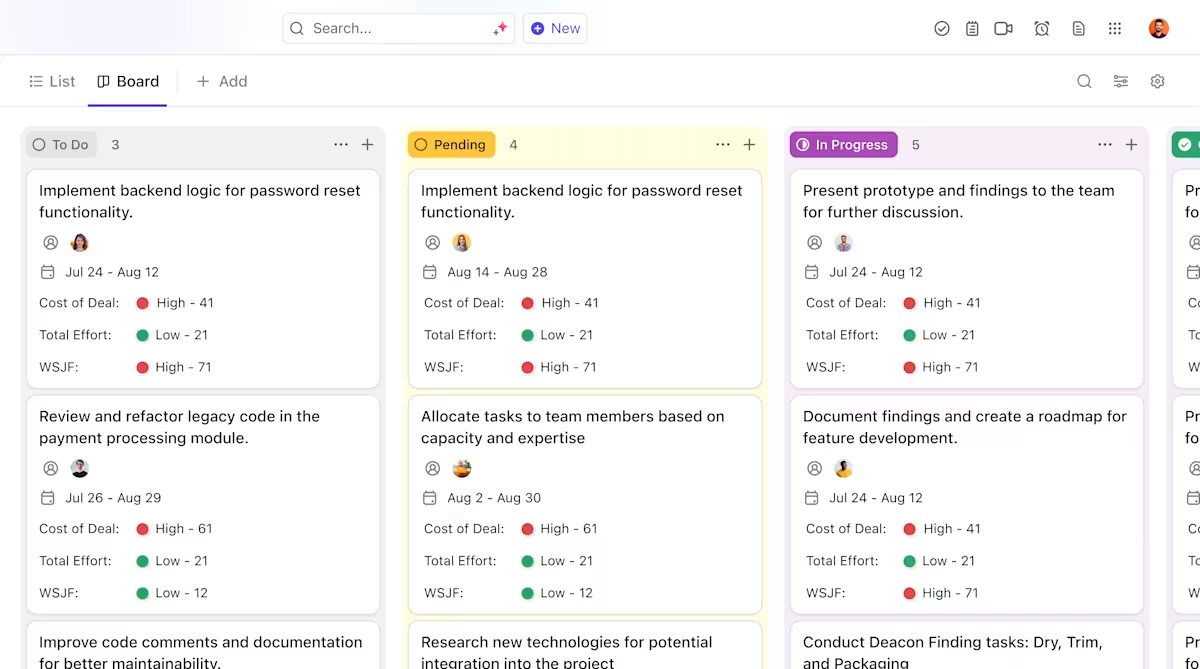
Így segítheti a ClickUp az AI-bevezetési projektjét:
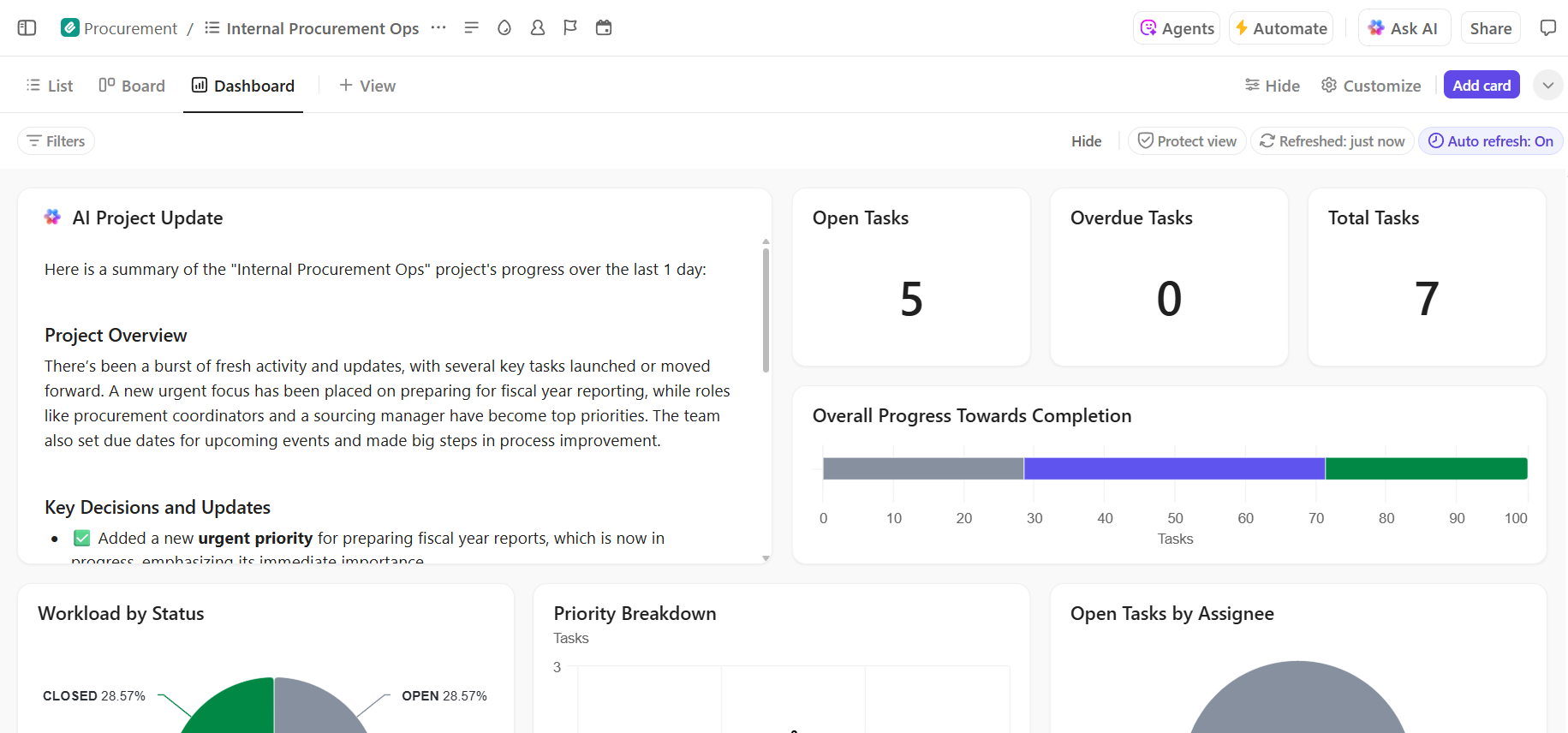
- Egyértelmű tulajdonjog és nyomon követés a modell életciklusa során: Használja a ClickUp Tasks alkalmazást a Hugging Face modellek nyomon követéséhez az értékelés, tesztelés, előkészítés és gyártás során, egyedi állapotokkal, tulajdonosokkal és blokkolókkal, amelyek az egész csapat számára láthatók.
- Központosított, élő telepítési dokumentáció: Tartsa karban a telepítési futási könyveket, a környezetkonfigurációkat és a hibaelhárítási útmutatókat a ClickUp Docs-ban, így a dokumentáció a modellekkel együtt fejlődik, és könnyen kereshető és hivatkozható marad. Mivel a Docs feladatokhoz kapcsolódik, a dokumentációja közvetlenül a hozzá kapcsolódó munkával együtt található.
- Kontextusban történő együttműködés a munka terjeszkedése nélkül: tartsa a megbeszéléseket, döntéseket és frissítéseket közvetlenül a feladatokhoz és dokumentumokhoz kapcsolva, csökkentve ezzel a szétszórt Slack-szálakra, e-mailekre és egymástól független projekteszközökre való támaszkodást.
- A telepítés folyamatának teljes átláthatósága: Figyelje a telepítési folyamatot, azonosítsa a kockázatokat korai szakaszban, és egyensúlyozza a csapat kapacitását a ClickUp Dashboards segítségével, amely valós időben mutatja a folyamat előrehaladását és a szűk keresztmetszeteket.
- Gyorsabb bevezetés és döntéshozatal a beépített AI segítségével: Használja a ClickUp Brain alkalmazást a hosszú telepítési dokumentumok összefoglalásához, a korábbi telepítésekből származó releváns információk feltárásához, valamint az új csapattagok gyors beilleszkedésének elősegítéséhez anélkül, hogy át kellene nézniük a korábbi kontextust.
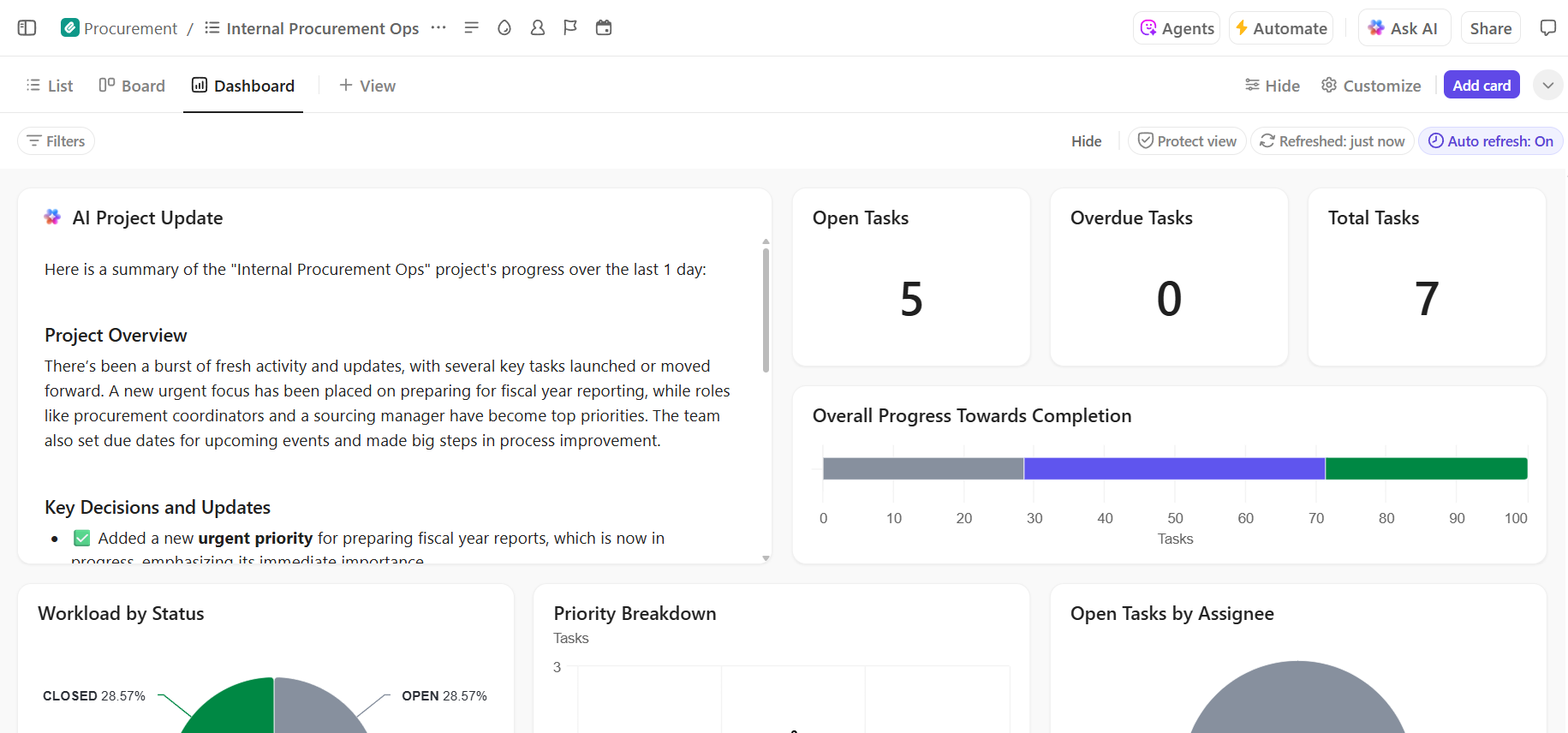
📚 Olvassa el még: Hogyan automatizálhatja a folyamatokat AI segítségével a gyorsabb, okosabb munkafolyamatok érdekében
Kezelje zökkenőmentesen AI-bevezetési projektjét a ClickUp segítségével
A Hugging Face sikeres bevezetése szilárd technikai alapokon és világos, szervezett projektmenedzsmenten múlik. Míg a technikai kihívások megoldhatók, gyakran a koordináció és a kommunikáció megszakadása okozza a projektek kudarcát.
Egyetlen platformon létrehozott egyértelmű munkafolyamat segítségével csapata gyorsabban szállíthat, és elkerülheti a kontextus szétszóródásának frusztrációját – amikor a csapatok órákat pazarolnak információk keresésére, alkalmazások közötti váltogatásra és több platformon történő frissítések ismétlésére.
A ClickUp, a munkához szükséges minden funkciót magában foglaló alkalmazás, egy helyen egyesíti a projektmenedzsmentet, a dokumentációt és a csapatkommunikációt, így egyetlen forrásból kaphat információkat az AI-bevezetés teljes életciklusáról.
Összehangolja AI-telepítési projektjeit, és szüntesse meg az eszközökkel kapcsolatos zűrzavart. Kezdje el még ma ingyenesen a ClickUp használatát.
Gyakran ismételt kérdések (GYIK)
Igen, a Hugging Face nagylelkű ingyenes csomagot kínál, amely magában foglalja a Model Hubhoz való hozzáférést, CPU-alapú Spaces-t a bemutatókhoz és egy sebességkorlátozott Inference API-t a teszteléshez. Azok számára, akiknek dedikált hardverre vagy magasabb korlátokra van szükségük a termeléshez, fizetős csomagok is rendelkezésre állnak.
A Spaces interaktív alkalmazások vizuális felületű tárolására lett tervezve, így ideális demókhoz és belső eszközökhöz. Az Inference API programozási hozzáférést biztosít a modellekhez, így egyszerű HTTP-kérésekkel integrálhatja őket alkalmazásaiba.
Természetesen. A Hugging Face Spaces-en található interaktív bemutatók segítségével a nem technikai háttérrel rendelkező csapat tagjai is kipróbálhatják a modelleket és visszajelzést adhatnak róluk anélkül, hogy egyetlen sor kódot is írniuk kellene.
Az ingyenes csomag fő korlátai az Inference API sebességkorlátozásai, a Spaces számára megosztott CPU hardver használata, ami lassú lehet, valamint a „hidegindítások”, amikor az inaktív alkalmazásoknak egy pillanatig tart, amíg felébrednek. /