

A nagy nyelvi modellek (LLM-ek) izgalmas új lehetőségeket nyitottak meg a szoftveralkalmazások számára. Lehetővé teszik a valaha voltnál intelligensebb és dinamikusabb rendszerek létrehozását.
A szakértők előrejelzése szerint 2025-re az ezeken a modelleken alapuló alkalmazások a digitális munkák közel felét automatizálhatják.
Mégis, miközben ezeket a képességeket felszabadítjuk, egy kihívás merül fel: hogyan mérhetjük megbízhatóan a kimenet minőségét nagy léptékben? Egy apró beállítási módosítás, és hirtelen máris észrevehetően eltérő kimenetet látunk. Ez a változékonyság megnehezítheti a teljesítményük felmérését, ami pedig elengedhetetlen a modell valós használatra való felkészítésekor.
Ez a cikk betekintést nyújt a legjobb LLM-rendszerértékelési gyakorlatokba, a telepítés előtti teszteléstől a gyártásig. Kezdjük hát!
Mi az LLM-értékelés?
Az LLM értékelési mutatók segítségével ellenőrizheti, hogy a promptok, a modellbeállítások vagy a munkafolyamatok megfelelnek-e a kitűzött céloknak. Ezek a mutatók betekintést nyújtanak a nagy nyelvi modell teljesítményébe, és abba, hogy valóban készen áll-e a valós használatra.
Ma a leggyakoribb mutatók közé tartozik a kontextus-visszahívás a visszakereséssel kiegészített generálás (RAG) feladatokban, a pontos egyezések a osztályozásokban, a JSON-érvényesítés a strukturált kimenetekben és a szemantikai hasonlóság a kreatívabb feladatokban.
Ezek a mutatók egyedi módon biztosítják, hogy az LLM megfeleljen az Ön konkrét felhasználási esetének követelményeinek.
Miért kell értékelni az LLM-et?
A nagy nyelvi modelleket (LLM) ma már számos alkalmazásban használják. Fontos, hogy értékeljük a modellek teljesítményét, hogy megbizonyosodjunk arról, hogy megfelelnek-e a várt szabványoknak, és hatékonyan szolgálják-e a tervezett célokat.
Gondoljon rá így: az LLM-ek mindent működtetnek, az ügyfélszolgálati chatbotoktól a kreatív eszközökig, és ahogy egyre fejlettebbek lesznek, egyre több helyen jelennek meg.
Ez azt jelenti, hogy jobb módszerekre van szükségünk azok figyelemmel kíséréséhez és értékeléséhez – a hagyományos módszerek egyszerűen nem tudnak lépést tartani azokkal a feladatokkal, amelyeket ezek a modellek kezelnek.
A jó értékelési mutatók olyanok, mint egy minőség-ellenőrzés az LLM-ek számára. Megmutatják, hogy a modell megbízható, pontos és elég hatékony-e a valós használathoz. Ezek nélkül a hibák elkerülhetők, ami frusztráló vagy akár félrevezető felhasználói élményhez vezethet.
Ha rendelkezik megbízható értékelési mutatókkal, könnyebb felismerni a problémákat, javítani a modellt és biztosítani, hogy az megfeleljen a felhasználók egyedi igényeinek. Így biztos lehet benne, hogy az Ön által használt AI-platform megfelel a szabványoknak és képes a kívánt eredményeket elérni.
📖 További információ: LLM vs. generatív AI: részletes útmutató
Az LLM-értékelések típusai
Az értékelések egyedülálló lehetőséget nyújtanak a modell képességeinek vizsgálatára. Minden típus különböző minőségi szempontokat vizsgál, segítve egy megbízható, biztonságos és hatékony telepítési modell kialakítását.
Az LLM értékelés különböző típusai:
- A belső értékelés a modell belső teljesítményére összpontosít konkrét nyelvi vagy szövegértési feladatok során, anélkül, hogy valós alkalmazásokat vonna be. Általában a modell fejlesztési szakaszában végzik el, hogy megértsék az alapvető képességeket.
- A külső értékelés a modell teljesítményét valós alkalmazásokban méri. Ez a típusú értékelés azt vizsgálja, hogy a modell mennyire felel meg bizonyos céloknak egy adott kontextusban.
- A robusztusság értékelése teszteli a modell stabilitását és megbízhatóságát különböző forgatókönyvekben, beleértve a váratlan bemeneteket és az ellenséges körülményeket is. Azonosítja a potenciális gyengeségeket, biztosítva, hogy a modell előre jelezhető módon viselkedjen.
- A hatékonysági és késleltetési tesztelés a modell erőforrás-használatát, sebességét és késleltetését vizsgálja. Biztosítja, hogy a modell gyorsan és ésszerű számítási költségekkel végezze el a feladatokat, ami elengedhetetlen a skálázhatóság szempontjából.
- Az etikai és biztonsági értékelés biztosítja, hogy a modell megfeleljen az etikai normáknak és a biztonsági irányelveknek, ami érzékeny alkalmazások esetén elengedhetetlen.
LLM-modell értékelések vs. LLM-rendszer értékelések
A nagy nyelvi modellek (LLM) értékelése két fő megközelítést foglal magában: a modellértékelést és a rendszerértékelést. Mindkettő az LLM teljesítményének különböző aspektusaira összpontosít, és ezeknek a különbségeknek a megismerése elengedhetetlen a modellek potenciáljának maximális kihasználásához.
🧠 A modellértékelések az LLM általános képességeit vizsgálják. Ez a típusú értékelés a modell különböző kontextusokban való pontos nyelvértési, nyelvgenerálási és nyelvhasználati képességeit teszteli. Ez olyan, mintha megnéznénk, hogy a modell mennyire képes különböző feladatokat kezelni, szinte mint egy általános intelligencia-teszt.
Például a modellértékelések során felmerülhet a kérdés: „Mennyire sokoldalú ez a modell?”
🎯 Az LLM rendszerértékelések azt mérik, hogy az LLM hogyan teljesít egy adott beállítás vagy cél keretében, például egy ügyfélszolgálati chatbotban. Itt nem annyira a modell általános képességei a fontosak, hanem inkább az, hogy hogyan teljesít bizonyos feladatokat a felhasználói élmény javítása érdekében.
A rendszerértékelések azonban olyan kérdésekre koncentrálnak, mint például: „Mennyire jól kezeli a modell ezt a konkrét feladatot a felhasználók számára?”
A modellértékelések segítenek a fejlesztőknek megérteni az LLM általános képességeit és korlátait, és iránymutatást adnak a fejlesztésekhez. A rendszerértékelések arra összpontosítanak, hogy az LLM mennyire felel meg a felhasználói igényeknek konkrét kontextusokban, biztosítva ezzel a zökkenőmentesebb felhasználói élményt.
Ezek az értékelések együttesen teljes képet adnak az LLM erősségeiről és fejlesztendő területeiről, így az valós alkalmazásokban hatékonyabbá és felhasználóbarátabbá válik.
Most nézzük meg az LLM értékelés konkrét mutatóit.
Mérőszámok az LLM értékeléshez
Néhány megbízható és divatos értékelési mutató:
1. Perplexity
A perplexitás azt méri, hogy egy nyelvi modell mennyire jól képes megjósolni a szavak sorrendjét. Lényegében a modell bizonytalanságát jelzi a mondat következő szavával kapcsolatban. Alacsonyabb perplexitási pontszám azt jelenti, hogy a modell magabiztosabb a jóslataiban, ami jobb teljesítményhez vezet.
📌 Példa: Képzelje el, hogy egy modell szöveget generál a „A macska ült a...” promptból. Ha nagy valószínűséggel jósolja meg az „szőnyeg” és „padló” szavakat, akkor jól érti a kontextust, ami alacsony perplexitási pontszámot eredményez.
Ha viszont egy nem kapcsolódó szót javasol, például „űrhajó”, akkor a zavarosság pontszáma magasabb lesz, ami azt jelzi, hogy a modellnek nehézséget okoz a értelmes szöveg előrejelzése.
2. BLEU pontszám
A BLEU (Bilingual Evaluation Understudy) pontszámot elsősorban gépi fordítások értékelésére és szöveggenerálás értékelésére használják.
Megméri, hogy a kimenetben hány n-gram (egy adott szövegmintából származó n elem egymást követő sorozata) esik egybe egy vagy több referenciaszövegben találhatóval. A pontszám 0 és 1 között lehet, a magasabb pontszámok jobb teljesítményt jelentenek.
📌 Példa: Ha a modellje a „The quick brown fox jumps over the lazy dog” (A gyors barna róka átugorja a lusta kutyát) mondatot generálja, és a referencia szöveg „A fast brown fox leaps over a lazy dog” (A gyors barna róka átugorja a lusta kutyát), akkor a BLEU összehasonlítja a közös n-gramokat.
A magas pontszám azt jelzi, hogy a generált mondat szorosan illeszkedik a referenciához, míg az alacsonyabb pontszám arra utalhat, hogy a generált kimenet nem illeszkedik jól.
3. F1 pontszám
Az F1 pontszám LLM értékelési mutató elsősorban osztályozási feladatokhoz használható. Ez a pontosság (a pozitív előrejelzések pontossága) és a visszahívás (az összes releváns eset azonosításának képessége) közötti egyensúlyt méri.
A skála 0 és 1 között mozog, ahol az 1-es pontszám tökéletes pontosságot jelöl.
📌 Példa: Egy kérdés-válasz feladatban, ha a modellt megkérdezik: „Milyen színű az ég?”, és az „Az ég kék” (igaz pozitív) válasszal reagál, de azt is hozzáfűzi, hogy „Az ég zöld” (hamis pozitív), akkor az F1 pontszám mind a helyes, mind a helytelen válasz relevanciáját figyelembe veszi.
Ez a mutató segít biztosítani a modell teljesítményének kiegyensúlyozott értékelését.
4. METEOR
A METEOR (Metric for Evaluation of Translation with Explicit ORdering) túlmutat a pontos szóegyezéseken. Szinonimákat, szógyököket és parafrázisokat vesz figyelembe a generált szöveg és a referencia szöveg közötti hasonlóság értékeléséhez. Ez a mérőszám célja, hogy jobban igazodjon az emberi ítélethez.
📌 Példa: Ha a modellje a „A macska a szőnyegen pihent” mondatot generálja, és a referencia „A macska a szőnyegen feküdt”, akkor a METEOR magasabb pontszámot adna neki, mint a BLEU, mert felismeri, hogy a „macska” szinonimája a „kiscica”, és a „szőnyeg” és a „szőnyeg” hasonló jelentést hordoznak.
Ezért a METEOR különösen hasznos a nyelv finom árnyalatainak megragadásához.
5. BERTScore
A BERTScore a szövegek hasonlóságát a BERT (Bidirectional Encoder Representations from Transformers) és hasonló modellekből származó kontextuális beágyazások alapján értékeli. Inkább a jelentésre, mint a pontos szóegyezésekre koncentrál, így jobb szemantikai hasonlóságértékelést tesz lehetővé.
📌 Példa: A „The car raced down the road” (Az autó száguldott az úton) és a „The vehicle sped along the street” (A jármű száguldott az utcán) mondatok összehasonlításakor a BERTScore nem csak a szóválasztást, hanem az alapvető jelentést is elemzi.
Bár a szavak eltérőek, az általános gondolatok hasonlóak, ami magas BERTScore-t eredményez, amely tükrözi a generált tartalom hatékonyságát.
6. Emberi értékelés
Az emberi értékelés továbbra is kulcsfontosságú eleme az LLM értékelésének. Ennek során emberi bírák értékelik a modell kimeneteinek minőségét különböző kritériumok, például a folyékonyság és a relevancia alapján. A visszajelzések gyűjtéséhez olyan technikák alkalmazhatók, mint a Likert-skála és az A/B tesztelés.
📌 Példa: Miután a ügyfélszolgálati chatbot válaszokat generált, az emberi értékelők 1-től 5-ig terjedő skálán értékelhetik az egyes válaszokat. Például, ha a chatbot egyértelmű és hasznos választ ad egy ügyfél kérdésére, akkor 5-ös értékelést kaphat, míg egy homályos vagy zavaros válasz 2-es értékelést kaphat.
7. Feladatspecifikus mutatók
A különböző LLM-feladatokhoz testreszabott értékelési mutatókra van szükség.
A párbeszédrendszerek esetében a mutatók értékelhetik a felhasználói elkötelezettséget vagy a feladatok teljesítési arányát. A kódgenerálás esetében a siker mérhető azzal, hogy a generált kód milyen gyakran fordítható le vagy teljesíti a teszteket.
📌 Példa: Egy ügyfélszolgálati chatbotban az elkötelezettség szintjét az alapján lehet mérni, hogy a felhasználók mennyi ideig maradnak a beszélgetésben, vagy hány további kérdést tesznek fel.
Ha a felhasználók gyakran kérnek további információkat, az azt jelzi, hogy a modell sikeresen vonzza őket és hatékonyan kezeli a kérdéseiket.
8. Robusztusság és méltányosság
A modell robusztusságának értékelése magában foglalja annak tesztelését, hogy mennyire jól reagál váratlan vagy szokatlan bemenetekre. A méltányossági mutatók segítenek azonosítani a modell kimeneteiben fellelhető torzításokat, biztosítva, hogy a modell különböző demográfiai csoportok és forgatókönyvek esetén is méltányosan működjön.
📌 Példa: Ha egy modellt olyan szeszélyes kérdéssel tesztelünk, mint „Mit gondolsz az egyszarvúakról?”, akkor a modellnek elegánsan kell kezelnie a kérdést, és releváns választ kell adnia. Ha helyette értelmetlen vagy nem megfelelő választ ad, az a modell robusztusságának hiányát jelzi.
A méltányossági tesztelés biztosítja, hogy a modell ne hozzon létre elfogult vagy káros eredményeket, elősegítve ezzel egy inkluzívabb AI-rendszer kialakítását.
📖 További információ: A gépi tanulás és a mesterséges intelligencia közötti különbség
9. Hatékonysági mutatók
A nyelvi modellek egyre összetettebbé válnak, ezért egyre fontosabbá válik azok hatékonyságának mérése a sebesség, a memóriahasználat és az energiafogyasztás tekintetében. A hatékonysági mutatók segítenek értékelni, hogy egy modell mennyire erőforrás-igényes a válaszok generálásakor.
📌 Példa: Egy nagy nyelvi modell esetében a hatékonyság mérése magában foglalhatja annak nyomon követését, hogy milyen gyorsan generál válaszokat a felhasználói lekérdezésekre, és mennyi memóriát használ fel ezalatt a folyamat alatt.
Ha a válaszadás túl sok időt vesz igénybe vagy túlzott erőforrásokat igényel, ez problémát jelenthet a valós idejű teljesítményt igénylő alkalmazások, például a csevegőrobotok vagy a fordítási szolgáltatások esetében.
Most már tudja, hogyan kell értékelni egy LLM modellt. De milyen eszközöket használhat ehhez? Nézzük meg!
Hogyan javíthatja a ClickUp Brain az LLM értékelést?
A ClickUp egy mindenre kiterjedő munkaalkalmazás, amelybe beépített személyi asszisztens, a ClickUp Brain is tartozik.
A ClickUp Brain forradalmasítja az LLM teljesítményértékelést. Mit is csinál pontosan?
A legrelevánsabb adatokat rendszerezi és kiemeli, így csapata mindig a terv szerint haladhat. AI-alapú funkcióival a ClickUp Brain az egyik legjobb neurális hálózati szoftver a piacon. Az egész folyamatot simábbá, hatékonyabbá és együttműködőbbé teszi, mint valaha. Fedezzük fel együtt a képességeit!
Intelligens tudásmenedzsment
A nagy nyelvi modellek (LLM) értékelésekor a hatalmas adatmennyiség kezelése megterhelő lehet.

A ClickUp Brain képes rendszerezni és kiemelni az LLM értékeléshez kifejezetten kialakított alapvető mutatókat és erőforrásokat. A ClickUp Brain nem kényszeríti Önt arra, hogy szétszórt táblázatokban és sűrű jelentésekben turkáljon, hanem mindent egy helyen összegyűjt. A teljesítménymutatók, a benchmarking adatok és a teszt eredmények egy világos és felhasználóbarát felületen érhetők el.
Ez a szervezet segít csapatának kiszűrni a zavaró tényezőket, és a valóban fontos információkra koncentrálni, így könnyebb értelmezni a trendeket és a teljesítménymintákat.
Mivel minden szükséges eszköz egy helyen található, a puszta adatgyűjtésről átállhat a hatékony, adatalapú döntéshozatalra, és az információtúlterhelést hasznosítható intelligenciává alakíthatja.
Projekttervezés és munkafolyamat-kezelés
Az LLM-értékelések gondos tervezést és együttműködést igényelnek, és a ClickUp megkönnyíti ennek a folyamatnak a kezelését.
Könnyedén delegálhatja az adatgyűjtés, a modellképzés és a teljesítménytesztelés feladatait, miközben prioritásokat is meghatározhat, hogy a legfontosabb feladatok kapjanak elsőbbséget. Ezenkívül az egyéni mezők lehetővé teszik, hogy a munkafolyamatokat a projekt konkrét igényeihez igazítsa.

A ClickUp segítségével mindenki láthatja, ki mit csinál és mikor, így elkerülhetők a késések, és biztosítható, hogy a feladatok zökkenőmentesen haladjanak a csapatban. Ez egy remek módszer arra, hogy mindent szervezetten és a terv szerint tartsunk a kezdetektől a végéig.
Mérőszámok nyomon követése egyedi irányítópultokon keresztül
Szeretné figyelemmel kísérni LLM-rendszerei teljesítményét?
A ClickUp Dashboards valós időben jeleníti meg a teljesítménymutatókat. Ez lehetővé teszi, hogy azonnal nyomon kövesse modellje előrehaladását. Ezek a műszerfalak nagymértékben testreszabhatók, így olyan grafikonokat és táblázatokat készíthet, amelyek pontosan azt mutatják, amire szüksége van, amikor szüksége van rá.
Megfigyelheti modellje pontosságának alakulását az értékelési szakaszok során, vagy lebontja az egyes fázisok erőforrás-fogyasztását. Ez az információ lehetővé teszi, hogy gyorsan felismerje a trendeket, azonosítsa a fejlesztendő területeket, és azonnal módosításokat hajtson végre.
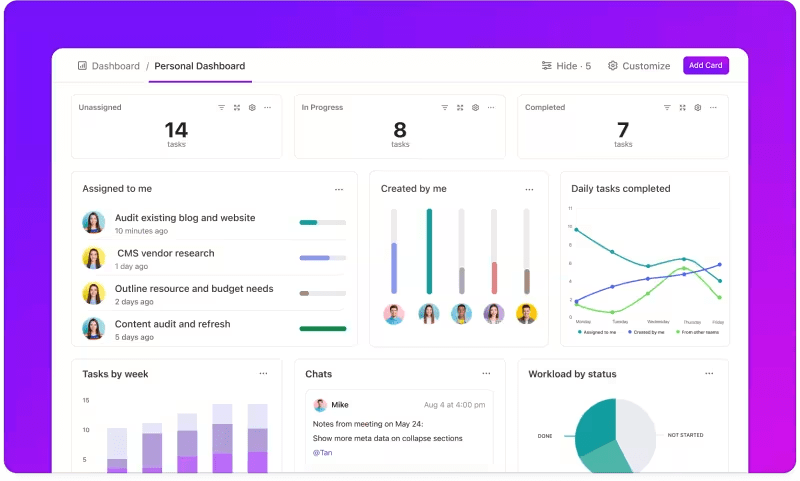
Ahelyett, hogy a következő részletes jelentésre várna, a ClickUp Dashboards segítségével folyamatosan tájékozott és reagálóképes maradhat, így csapata késedelem nélkül hozhat adat alapú döntéseket.
Automatizált betekintés
Az adatelemzés időigényes lehet, de a ClickUp Brain funkciók értékes betekintést nyújtanak, ezzel könnyítve a munkát. Kiemeli a fontos trendeket, és az adatok alapján ajánlásokat is tesz, így könnyebb értelmes következtetéseket levonni.
A ClickUp Brain automatizált betekintésével nincs szükség a nyers adatok kézi átvizsgálására a minták felkutatásához – a rendszer automatikusan megtalálja azokat. Ez az automatizálás felszabadítja a csapatát, hogy a modell teljesítményének finomítására koncentrálhasson, ahelyett, hogy ismétlődő adatelemzésekkel kellene foglalkoznia.
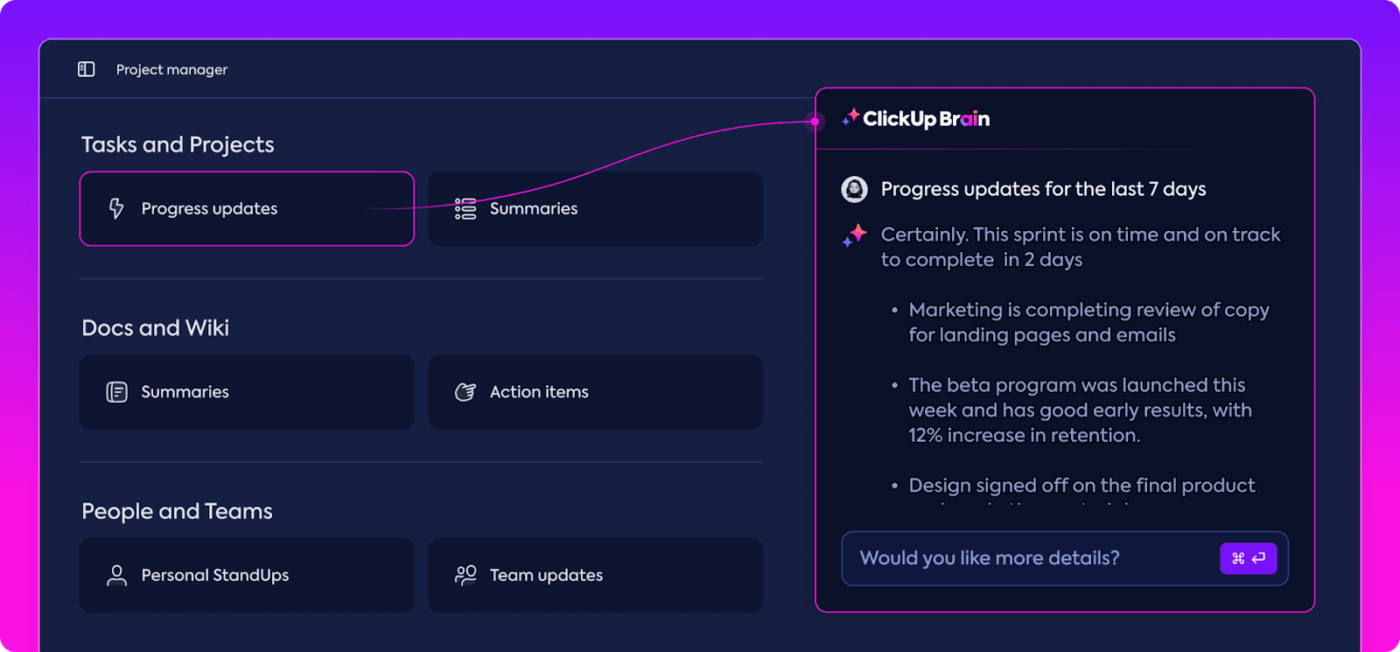
A generált betekintések azonnal felhasználhatók, így csapata azonnal láthatja, mi működik és hol lehet szükség változtatásokra. Az elemzésre fordított idő csökkentésével a ClickUp segít csapatának felgyorsítani az értékelési folyamatot és a megvalósításra koncentrálni.
Dokumentáció és együttműködés
Nincs többé e-mailek vagy több platform átkutatására, hogy megtalálja, amire szüksége van; minden ott van, készen áll, amikor Ön is.
A ClickUp Docs egy központi hub, amely összefogja mindazt, amire a csapatának szüksége van a zökkenőmentes LLM-értékeléshez. A legfontosabb projektdokumentációt – például a benchmarking kritériumokat, a tesztelési eredményeket és a teljesítménynaplókat – egy könnyen elérhető helyen szervezi, így mindenki gyorsan hozzáférhet a legfrissebb információkhoz.
A ClickUp Docs valódi különlegessége a valós idejű együttműködési funkciókban rejlik. Az integrált ClickUp Chat és Comments funkciók lehetővé teszik a csapat tagjainak, hogy megvitassák észrevételeiket, visszajelzéseket adjanak és változtatásokat javasoljanak közvetlenül a dokumentumokban.
Ez azt jelenti, hogy csapata megbeszélheti a megállapításokat és közvetlenül a platformon végezheti el a szükséges módosításokat, így minden megbeszélés releváns és célszerű marad.

A dokumentációtól a csapatmunkáig minden a ClickUp Docs-ban történik, így egy egyszerűsített értékelési folyamat jön létre, amelyben mindenki láthatja, megoszthatja és felhasználhatja a legújabb fejleményeket.
Az eredmény? Zökkenőmentes, egységes munkafolyamat, amelynek köszönhetően csapata teljes átláthatósággal haladhat céljai felé.
Készen áll arra, hogy kipróbálja a ClickUp-ot? Előtte azonban beszéljünk néhány tippről és trükkről, amelyekkel a legtöbbet hozhatja ki az LLM értékelésből.
A legjobb gyakorlatok az LLM értékelésében
A jól felépített LLM-értékelési megközelítés biztosítja, hogy a modell megfeleljen az Ön igényeinek, összhangban legyen a felhasználói elvárásokkal, és értelmes eredményeket szolgáltasson.
A világos célok kitűzése, a végfelhasználók figyelembevétele és különböző mutatók használata segít kialakítani egy átfogó értékelést, amely feltárja az erősségeket és a fejlesztendő területeket. Az alábbiakban néhány bevált gyakorlatot mutatunk be, amelyek segíthetnek a folyamatban.
🎯 Határozzon meg egyértelmű célokat
Az értékelési folyamat megkezdése előtt elengedhetetlen, hogy pontosan tudja, mit szeretne elérni a nagy nyelvi modelljével (LLM). Szánjon időt arra, hogy felvázolja a modell konkrét feladatait vagy céljait.
📌 Példa: Ha javítani szeretné a gépi fordítás teljesítményét, tisztázza, milyen minőségi szintet szeretne elérni. A világos célok segítenek abban, hogy a legrelevánsabb mutatókra koncentráljon, biztosítva, hogy az értékelés összhangban maradjon ezekkel a célokkal, és pontosan mérje a sikert.
👥 Vegye figyelembe a közönségét
Gondoljon arra, hogy kik fogják használni az LLM-et, és milyen igényeik vannak. Az értékelésnek a célzott felhasználókhoz való igazítása elengedhetetlen.
📌 Példa: Ha a modellje célja vonzó tartalom generálása, akkor különös figyelmet kell fordítania olyan mutatókra, mint a folyékonyság és a koherencia. A közönség megértése segít finomítani az értékelési kritériumokat, biztosítva, hogy a modell valódi értéket nyújtson a gyakorlati alkalmazásokban.
📊 Használjon különböző mutatókat
Ne támaszkodjon csak egy mutatóra az LLM értékeléséhez; a mutatók kombinációja teljesebb képet ad a teljesítményéről. Minden mutató különböző szempontokat ragad meg, ezért több mutató használata segít azonosítani az erősségeket és a gyengeségeket egyaránt.
📌 Példa: Bár a BLEU pontszámok kiválóan alkalmasak a fordítás minőségének mérésére, nem feltétlenül fedik le a kreatív írás minden finom árnyalatát. Az előrejelzési pontosságot mérő perplexity mutatók, sőt akár a kontextust értékelő emberi értékelések beépítése is sokkal átfogóbb képet adhat a modell teljesítményéről.
LLM-benchmarkok és eszközök
A nagy nyelvi modellek (LLM) értékelése gyakran iparági szabványos referenciaértékeken és speciális eszközökön alapul, amelyek segítenek a modell teljesítményének különböző feladatok során történő mérésében.
Íme néhány széles körben használt referenciaérték és eszköz, amelyek strukturálják és átláthatóbbá teszik az értékelési folyamatot.
Főbb referenciaértékek
- GLUE (általános nyelvértés értékelése): A GLUE több nyelvi feladat, például mondatbesorolás, hasonlóság és következtetés alapján értékeli a modell képességeit. Ez a referenciaérték azoknak a modelleknek, amelyeknek általános célú nyelvértéssel kell foglalkozniuk.
- SQuAD (Stanford Question Answering Dataset): Az SQuAD értékelési keretrendszer ideális az olvasásértéshez, és méri, hogy egy modell mennyire jól válaszol a szövegrészletek alapján feltett kérdésekre. Általában olyan feladatokhoz használják, mint az ügyfélszolgálat és a tudásalapú visszakeresés, ahol a pontos válaszok elengedhetetlenek.
- SuperGLUE: A GLUE továbbfejlesztett verziójaként a SuperGLUE a modelleket összetettebb érvelési és kontextusértelmezési feladatok alapján értékeli. Mélyebb betekintést nyújt, különösen a fejlett nyelvi megértést igénylő alkalmazások esetében.
Alapvető értékelési eszközök
- Hugging Face : Széles körben népszerű kiterjedt modellkönyvtáráról, adatkészleteiről és értékelési funkcióiról. Rendkívül intuitív felülete lehetővé teszi a felhasználók számára, hogy könnyedén kiválasszák a referenciaértékeket, testreszabják az értékeléseket és nyomon kövessék a modell teljesítményét, így sokoldalúan használható számos LLM-alkalmazáshoz.
- SuperAnnotate: Adatok kezelésére és annotálására specializálódott, ami elengedhetetlen a felügyelt tanulási feladatokhoz. Különösen hasznos a modell pontosságának finomításához, mivel elősegíti a magas minőségű, ember által annotált adatok létrehozását, amelyek javítják a modell teljesítményét komplex feladatok esetén.
- AllenNLP: Az Allen Institute for AI által fejlesztett AllenNLP azoknak a kutatóknak és fejlesztőknek szól, akik egyedi NLP-modelleken dolgoznak. Számos benchmarkot támogat, és eszközöket biztosít a nyelvi modellek képzéséhez, teszteléséhez és értékeléséhez, így rugalmasságot kínál a különböző NLP-alkalmazásokhoz.
Ezeknek a referenciaértékeknek és eszközöknek a kombinált használata átfogó megközelítést kínál az LLM értékeléshez. A referenciaértékek szabványokat állapíthatnak meg a feladatok között, míg az eszközök biztosítják a modell teljesítményének hatékony nyomon követéséhez, finomításához és javításához szükséges struktúrát és rugalmasságot.
Együttesen biztosítják, hogy az LLM-ek megfeleljenek mind a műszaki szabványoknak, mind a gyakorlati alkalmazási igényeknek.
Az LLM-modell értékelésének kihívásai
A nagy nyelvi modellek (LLM) értékelése finom megközelítést igényel. A válaszok minőségére, valamint a modell alkalmazkodóképességének és korlátainak megértésére összpontosít különböző forgatókönyvekben.
Mivel ezek a modellek kiterjedt adatkészleteken vannak betanítva, viselkedésüket számos tényező befolyásolja, ezért elengedhetetlen, hogy ne csak a pontosságot értékeljük.
A valódi értékelés azt jelenti, hogy megvizsgáljuk a modell megbízhatóságát, a szokatlan utasításokkal szembeni ellenálló képességét és az általános válaszok konzisztenciáját. Ez a folyamat segít tisztább képet alkotni a modell erősségeiről és gyengeségeiről, és feltárja a finomításra szoruló területeket.
Az alábbiakban közelebbről megvizsgáljuk az LLM értékelés során felmerülő néhány gyakori kihívást.
1. A képzési adatok átfedése
Nehéz megmondani, hogy a modell már látta-e a tesztadatok egy részét. Mivel az LLM-ek hatalmas adathalmazokon vannak betanítva, előfordulhat, hogy egyes tesztkérdések átfedésben vannak a betanítási példákkal. Ezáltal a modell jobbnak tűnhet, mint amilyen valójában, mivel lehet, hogy csak azt ismételgeti, amit már tud, ahelyett, hogy valódi megértést mutatna.
2. Inkonzisztens teljesítmény
Az LLM-ek válaszai kiszámíthatatlanok lehetnek. Az egyik pillanatban lenyűgöző betekintést nyújtanak, a következőben pedig furcsa hibákat követnek el, vagy kitalált információkat tényekként tálalnak (ezeket „hallucinációknak” nevezik).
Ez az inkonzisztencia azt jelenti, hogy míg az LLM kimenetei egyes területeken kiemelkedőek lehetnek, más területeken elmaradhatnak a várakozásoktól, ami megnehezíti az általános megbízhatóság és minőség pontos megítélését.
3. Ellenséges sebezhetőségek
Az LLM-ek érzékenyek lehetnek az ellenséges támadásokra, amikor ügyesen megfogalmazott utasítások ráveszik őket hibás vagy káros válaszok létrehozására. Ez a sebezhetőség feltárja a modell gyengeségeit, és váratlan vagy elfogult eredményekhez vezethet. Az ilyen ellenséges gyengeségek tesztelése elengedhetetlen ahhoz, hogy megértsük, hol vannak a modell határai.
Gyakorlati LLM értékelési felhasználási esetek
Végül, íme néhány gyakori helyzet, amelyekben az LLM értékelés valóban jelentős különbséget jelent:
Ügyfélszolgálati chatbotok
Az LLM-eket széles körben használják a csevegőrobotokban az ügyfelek kérdéseinek kezelésére. A modell válaszadási képességének értékelése biztosítja, hogy pontos, hasznos és kontextusban releváns válaszokat adjon.
Rendkívül fontos mérni a rendszer képességét az ügyfelek szándékainak megértésére, a különböző kérdések kezelésére és az emberhez hasonló válaszok adására. Ez lehetővé teszi a vállalkozások számára, hogy zökkenőmentes ügyfélélményt biztosítsanak, miközben minimalizálják a frusztrációt.
Tartalomgenerálás
Sok vállalkozás használ LLM-eket blogtartalmak, közösségi média és termékleírások generálásához. A generált tartalom minőségének értékelése segít biztosítani, hogy az nyelvtanilag helyes, vonzó és releváns legyen a célközönség számára. A magas tartalmi színvonal fenntartásához fontosak olyan mutatók, mint a kreativitás, a koherencia és a témához való relevancia.
Érzelemelemzés
Az LLM-ek elemezhetik az ügyfelek visszajelzéseinek, a közösségi médiában megjelenő bejegyzéseknek vagy a termékértékeléseknek a hangulatát. Fontos értékelni, hogy a modell mennyire pontosan azonosítja, hogy egy szöveg pozitív, negatív vagy semleges. Ez segít a vállalkozásoknak megérteni az ügyfelek érzelmeit, finomítani a termékeket vagy szolgáltatásokat, növelni a felhasználói elégedettséget és javítani a marketingstratégiákat.
Kódgenerálás
A fejlesztők gyakran használnak LLM-eket a kód generálásához. Elengedhetetlen a modell funkcionális és hatékony kód előállítási képességének értékelése.
Fontos ellenőrizni, hogy a generált kód logikailag helyes-e, hibamentes-e és megfelel-e a feladat követelményeinek. Ez segít csökkenteni a szükséges kézi kódolás mennyiségét és javítja a termelékenységet.
Optimalizálja LLM-értékelését a ClickUp segítségével
Az LLM-ek értékelése során a legfontosabb, hogy olyan mutatókat válasszon, amelyek összhangban vannak a céljaival. A kulcs az, hogy megértse a konkrét céljait, legyen az a fordítás minőségének javítása, a tartalomgenerálás fejlesztése vagy speciális feladatok finomhangolása.
A teljesítményértékeléshez megfelelő mutatók, például RAG vagy finomhangolási mutatók kiválasztása képezi a pontos és értelmes értékelés alapját. Eközben a G-Eval, Prometheus, SelfCheckGPT és QAG fejlett pontozók erős érvelési képességeiknek köszönhetően pontos betekintést nyújtanak.
Ez azonban nem jelenti azt, hogy ezek a pontszámok tökéletesek – továbbra is fontos biztosítani, hogy megbízhatóak legyenek.
Az LLM-alkalmazás értékelésének előrehaladtával igazítsa a folyamatot az Ön konkrét felhasználási esetéhez. Nincs olyan univerzális mérőszám, amely minden esetben működne. A mérőszámok kombinációja, valamint a kontextusra való összpontosítás pontosabb képet ad a modell teljesítményéről.
Az LLM értékelés egyszerűsítéséhez és a csapatmunka javításához a ClickUp az ideális megoldás a munkafolyamatok kezeléséhez és a fontos mutatók nyomon követéséhez.
Növelni szeretné csapata termelékenységét? Regisztráljon még ma a ClickUp-ra, és tapasztalja meg, hogyan tudja átalakítani munkafolyamatát!