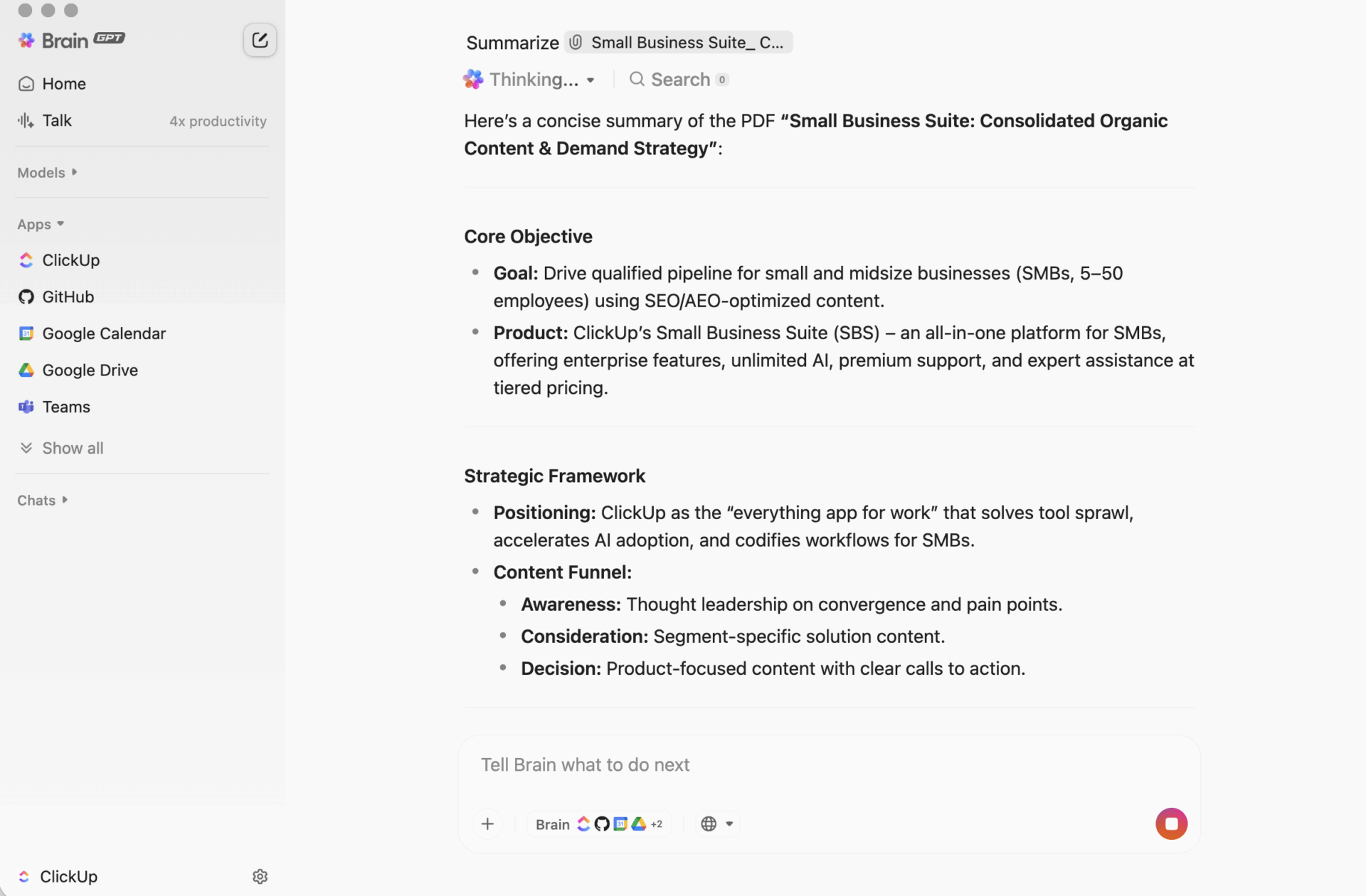

A Hugging Face összefoglaló szkriptet készítő fejlesztők többsége ugyanazzal a problémával szembesül: az összefoglaló tökéletesen működik a terminálon. De ritkán kapcsolódik a tényleges munkához, amelyet támogatnia kellene.
Ez az útmutató végigvezeti Önt a Hugging Face Transformers könyvtárával történő szövegösszefoglaló készítésén, majd megmutatja, miért okozhat még a hibátlan megvalósítás is több problémát, mint amennyit megold, ha csapatának olyan összefoglalókra van szüksége, amelyek valóban kapcsolódnak a feladatokhoz, projektekhez és döntésekhez.
Mi az a szövegösszefoglalás?
A csapatok információkban fulladnak. Hosszú dokumentumokkal, végtelenül hosszú értekezletek jegyzőkönyveivel, sűrű kutatási cikkekkel és negyedéves jelentésekkel kell szembenéznie, amelyek kézi feldolgozása órákat vesz igénybe. Ez a folyamatos információtúlterhelés lassítja a döntéshozatalt és csökkenti a termelékenységet.
A szövegösszefoglalás az a folyamat, amelynek során természetes nyelvfeldolgozás (NLP) segítségével a tartalom rövid, koherens változatba sűrűsödik, megőrizve a legfontosabb információkat. Gondoljon rá úgy, mint egy dokumentum azonnali vezetői összefoglalójára. Ez az NLP-összefoglalási technológia általában két megközelítés egyikét alkalmazza:
Kivonatoló összefoglalás: Ez a módszer úgy működik, hogy azonosítja és kivonja a legfontosabb mondatokat közvetlenül a forrás szövegből. Olyan, mintha egy kiemelő automatikusan kiválasztaná a legfontosabb pontokat. A végső összefoglaló az eredeti mondatok gyűjteménye.
Absztrakt összefoglalás: Ez a fejlettebb módszer teljesen új mondatokat generál, hogy megragadja a forrás szövegének alapvető jelentését. Átfogalmazza az információkat, így folyékonyabb és emberibb összefoglalást eredményez, hasonlóan ahhoz, ahogyan egy ember saját szavaival elmagyarázná egy hosszú történetet.
Ennek eredményeit mindenhol láthatja. Használják a találkozók jegyzetének cselekvési pontokká történő sűrítésére, az ügyfelek visszajelzéseinek trendekké történő összefoglalására és a projektdokumentáció gyors áttekintésének elkészítésére. A cél mindig ugyanaz: a lényeges információk megszerzése anélkül, hogy minden egyes szót el kellene olvasni.
📮 ClickUp Insight: Az átlagos szakember naponta több mint 30 percet tölt munkával kapcsolatos információk keresésével. Ez több mint 120 óra évente, amit e-mailek, Slack-szálak és szétszórt fájlok átkutatásával veszít el. A munkaterületébe beágyazott intelligens AI-asszisztens megváltoztathatja ezt. A ClickUp Brain másodpercek alatt megjeleníti a megfelelő dokumentumokat, beszélgetéseket és feladatokat, így azonnali betekintést és válaszokat nyújt, így abbahagyhatja a keresést és elkezdheti a munkát.
💫 Valós eredmények: A QubicaAMF-hez hasonló csapatok a ClickUp használatával hetente több mint 5 órát, évente pedig személyenként több mint 250 órát spóroltak meg az elavult tudásmenedzsment-folyamatok kiküszöbölésével.
Miért érdemes a Hugging Face-t használni szövegösszefoglaláshoz?
Egy egyedi szövegösszefoglaló modell felépítése a semmiből hatalmas feladat. Hatalmas adathalmazokra van szükség a képzéshez, nagy teljesítményű és drága számítási erőforrásokra, valamint egy gépi tanulás szakértőiből álló csapatra. Ez a magas belépési küszöb megakadályozza a legtöbb mérnöki és termékfejlesztő csapatot abban, hogy egyáltalán belekezdjenek a munkába.
A Hugging Face egy olyan platform, amely megoldja ezt a problémát. Ez egy nyílt forráskódú közösségi és adattudományi platform, amely hozzáférést biztosít több ezer előre betanított modellhez, hatékonyan demokratizálva az LLM összefoglalást a fejlesztők számára. Ahelyett, hogy a nulláról kezdené, egy már 99%-ban kész, hatékony modellel indulhat.
Íme, miért fordulnak olyan sok fejlesztő a Hugging Face-hez: 🛠️
Előre betanított modellekhez való hozzáférés: A Hugging Face Hub egy hatalmas adattár, amely több mint 2 millió nyilvános modellt tartalmaz, amelyeket olyan cégek tanítottak be, mint a Google, a Meta és az OpenAI. Ezeket a legmodernebb ellenőrzőpontokat letöltheti és felhasználhatja saját projektjeihez.
Egyszerűsített pipeline API: A pipeline funkció egy magas szintű API, amely néhány sor kóddal kezeli az összes komplex lépést, például a szöveg előfeldolgozását, a modell következtetését és a kimenet formázását.
Modellválaszték: Nem kell egy lehetőséghez ragaszkodnia. Számos architektúra közül választhat, például BART, T5 és Pegasus, amelyek mindegyike különböző erősségekkel, méretekkel és teljesítményjellemzőkkel rendelkezik.
A keretrendszer rugalmassága: A Transformers könyvtár zökkenőmentesen működik a két legnépszerűbb mélytanulási keretrendszerrel, a PyTorch-csal és a TensorFlow-val. Bármelyiket használhatja, amelyikkel a csapata már jól ismeri magát.
Közösségi támogatás: A kiterjedt dokumentáció, a hivatalos tanfolyamok és az aktív fejlesztői közösség segítségével könnyen megtalálhatók a bemutatók és segítséget kaphat, ha problémába ütközik.
Bár a Hugging Face rendkívül hatékony eszköz a fejlesztők számára, fontos megjegyezni, hogy ez egy kódalapú megoldás. A megvalósításához és karbantartásához technikai szakértelemre van szükség. Ez nem mindig megfelelő megoldás azoknak a nem technikai csapatoknak, akiknek csak összefoglalniuk kell a munkájukat.
🧐 Tudta? A Hugging Face Transformers könyvtára népszerűvé tette a legmodernebb NLP modellek használatát néhány sor kóddal, ezért az összefoglaló prototípusok gyakran itt kezdődnek.
Mik azok a Hugging Face transzformátorok?
Tehát úgy döntött, hogy a Hugging Face-t fogja használni, de mi is az a technológia, amelyik ezt a munkát végzi? A központi technológia egy Transformer nevű architektúra. Amikor 2017-ben egy „Attention Is All You Need” című cikkben bemutatták, teljesen megváltoztatta az NLP területét.
A Transformers megjelenése előtt a modellek nehezen értették meg a hosszú mondatok kontextusát. A Transformer legfontosabb újítása az figyelemmechanizmus, amely lehetővé teszi a modell számára, hogy egy adott szó feldolgozása során mérlegelje a bemeneti szövegben szereplő különböző szavak fontosságát. Ez segít a hosszú távú függőségek megragadásában és a kontextus megértésében, ami elengedhetetlen a koherens összefoglalók létrehozásához.
A Hugging Face Transformers könyvtár egy Python csomag, amely hihetetlenül egyszerűvé teszi ezeknek a komplex modelleknek a használatát. Nincs szükséged gépi tanulásból szerzett doktori címre. A könyvtár elvégzi a nehéz munkát.
A három alapvető összetevő, amit tudnia kell
- Tokenizálók: A modellek nem értik a szavakat, csak a számokat. A tokenizáló a bevitt szöveget numerikus tokenek sorozatává alakítja át – ez a folyamat a tokenizálás –, amelyet a modell feldolgozni tud.
- Modellek: Ezek maguk a előre betanított neurális hálózatok. Az összefoglaláshoz ezek általában szekvencia-szekvencia modellek, kódoló-dekódoló szerkezettel. A kódoló elolvassa a bevitt szöveget, hogy numerikus ábrázolást hozzon létre, a dekódoló pedig ezt az ábrázolást használja az összefoglalás generálásához.
- Pipelines: Ez a legegyszerűbb módja a modell használatának. A pipeline egy előre betanított modellt és a hozzá tartozó tokenizálót csomagol össze, és elvégzi az input előfeldolgozásának és az output utólagos feldolgozásának minden lépését.
A két legnépszerűbb összefoglaló modell a BART és a T5. A BART (Bidirectional and Auto-Regressive Transformer) különösen jó az absztrakt összefoglalásban, nagyon természetesen olvasható összefoglalókat készít. A T5 (Text-to-Text Transfer Transformer) egy sokoldalú modell, amely minden NLP feladatot szöveg-szöveg problémaként fogalmaz meg, így egy hatékony, sokoldalú eszközzé teszi.
🎥 Nézze meg ezt a videót, hogy összehasonlítsa a legjobb AI PDF-összefoglalókat, és megtudja, mely eszközökkel készíthetők a leggyorsabb és legpontosabb összefoglalók a kontextus elvesztése nélkül.
Hogyan készítsünk szövegösszefoglalót a Hugging Face segítségével
Készen állsz a saját összefoglaló példád elkészítésére? Csak néhány alapvető Python ismeretre, egy kódszerkesztőre, például a VS Code-ra, és internetkapcsolatra van szükséged. Az egész folyamat mindössze négy lépésből áll. Percek alatt elkészül a működő összefoglalód.
1. lépés: Telepítse a szükséges könyvtárakat
Először telepítenie kell a szükséges könyvtárakat. A legfontosabb a transformers. Szüksége lesz egy mélytanulási keretrendszerre is, például PyTorch vagy TensorFlow. Ebben a példában a PyTorch-ot fogjuk használni.
Nyissa meg a terminált vagy a parancssort, és futtassa a következő parancsot:

Egyes modellek, például a T5, a tokenizerhez a sentencepiece könyvtárat is igénylik. Javasolt ezt is telepíteni.

💡 Profi tipp: A csomagok telepítése előtt hozzon létre egy Python virtuális környezetet. Ezzel elszigeteli a projekt függőségeit, és megakadályozza a gépen lévő más projektekkel való ütközéseket.
2. lépés: Töltse be a modellt és a tokenizálót
A legegyszerűbb módja a kezdésnek a pipeline funkció használata. Ez automatikusan kezeli a megfelelő modell és tokenizer betöltését az összefoglalási feladat elvégzéséhez.
Python szkriptjében importálja a pipeline-t, és inicializálja a következőképpen:

Itt két dolgot határozzunk meg:
A feladat: Megadjuk a folyamatnak, hogy „összefoglalást” szeretnénk végrehajtani.
A modell: Kiválasztunk egy előre betanított modell ellenőrzőpontot a Hugging Face Hub-ból. A facebook/bart-large-cnn egy népszerű választás, amelyet híradások alapján tanítottak be, és általános célú összefoglalásokhoz jól használható. A gyorsabb teszteléshez használhat egy kisebb modellt is, például a t5-small-t.
Amikor először futtatja ezt a kódot, a modell súlyait letölti a Hubról, ami néhány percet vehet igénybe. Ezt követően a modell a helyi gépen tárolódik, hogy azonnal betölthető legyen.
3. lépés: Hozza létre az összefoglaló funkciót
Ahhoz, hogy kódja tiszta és újrafelhasználható legyen, a legjobb, ha az összefoglalási logikát egy függvénybe csomagolja. Ez megkönnyíti a különböző paraméterekkel való kísérletezést is.
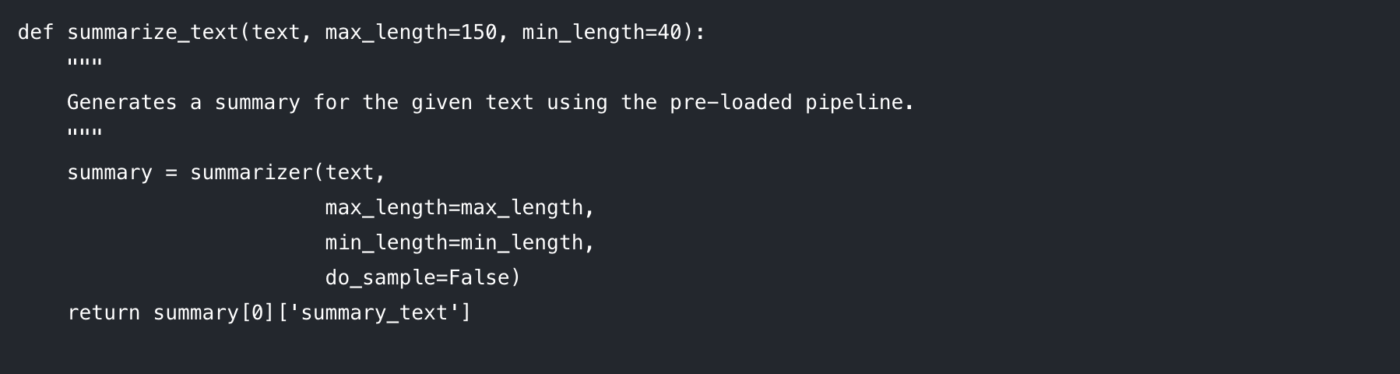
Vessünk egy pillantást azokra a paraméterekre, amelyeket Ön szabályozhat:
max_length: Ez határozza meg a kimeneti összefoglaló maximális tokenek (nagyjából szavak) számát.
min_length: Ez beállítja a tokenek minimális számát, hogy a modell ne generáljon túl rövid vagy üres összefoglalókat.
do_sample: Ha False értékre van állítva, a modell determinisztikus módszert (például sugárkeresést) használ a legvalószínűbb összefoglaló generálásához. Ha True értékre állítjuk, véletlenszerűséget vezet be, ami kreatívabb, de kevésbé megjósolható eredményeket hozhat.
Ezen paraméterek beállítása kulcsfontosságú a kívánt kimeneti minőség eléréséhez.
4. lépés: Összefoglalás létrehozása
Most jön a szórakoztató rész. Adja át a szöveget a függvénynek, és nyomtassa ki az eredményt. 🤩

A konzolon megjelenik a cikk rövidített változata. Ha problémákba ütközik, íme néhány gyors megoldás:
A bevitt szöveg túl hosszú: A modell hibaüzenetet jelezhet, ha a bevitt szöveg meghaladja a maximális hosszúságot (gyakran 512 vagy 1024 token). Adja hozzá a truncation=True parancsot a summarizer() híváshoz, hogy a hosszú bevitt szövegeket automatikusan levágja.
Az összefoglalás túl általános: Próbálja meg növelni a num_beams paramétert (pl. num_beams=4). Ezáltal a modell alaposabban keres jobb összefoglalást, de kissé lassabb lehet.
Ez a kódalapú megközelítés fantasztikus azoknak a fejlesztőknek, akik egyedi alkalmazásokat készítenek. De mi történik, ha ezt be kell integrálni egy csapat napi munkájába? Itt kezdődnek a korlátok.
A Hugging Face korlátai a szövegösszefoglalás terén
A Hugging Face remek választás, ha rugalmasságot és kontrollt szeretne. De amint megpróbálja valódi csapatmunka-folyamatokban használni (nem csak egy demo notebookban), néhány előre látható kihívás gyorsan felmerül.
Token-korlátok és hosszú dokumentumok okozta fejfájások
A legtöbb összefoglaló modellnek van egy fix maximális bemeneti hossza. Például a facebook/bart-large-cnn max_position_embeddings = 1024 értékre van beállítva. Ez azt jelenti, hogy a hosszabb dokumentumokat gyakran meg kell rövidíteni vagy darabokra kell bontani.
Ha csak egy gyors alapvonalra van szüksége, engedélyezheti a csonkítást a folyamatban, és folytathatja a munkát. De ha hűséges, hosszú dokumentumok összefoglalására van szüksége, akkor általában darabokra bontási logikát kell építenie, majd egy második lépésben, az „összefoglalók összefoglalásában” össze kell fűznie az eredményeket. Ez extra mérnöki munkát jelent, és könnyen előfordulhat, hogy az eredmények nem lesznek konzisztensek.
Hallucinációs kockázat (és az ellenőrzés költsége)
Az absztrakt modellek néha hallucinálnak, és olyan szöveget generálnak, amely hihetőnek tűnik, de ténylegesen helytelen. Üzleti szempontból ez problémát jelent: minden összefoglalót manuálisan kell ellenőrizni. Ekkor valójában nem spórolunk időt, csak a munka egy másik részére helyezzük át.
A kontextus ismeretének hiánya
A Hugging Face modell csak az Ön által bevitt szöveget ismeri. Nem érti a projekt céljait, a résztvevőket, vagy hogy az egyes dokumentumok hogyan kapcsolódnak egymáshoz, mivel hiányzik belőle a modern rendszerek kontextusérzékenysége. Nem tudja megmondani, hogy egy ügyfélhívás összefoglalója ellentmond-e a projekt követelményeinek, mert elszigetelten működik.
Integrációs többletköltség (az „utolsó mérföld” probléma)
Az összefoglaló elkészítése általában a könnyebbik rész. Az igazi nehézség azután következik.
Hová kerül az összefoglaló? Ki látja? Hogyan alakul cselekvésre késztető feladattá? Hogyan kapcsolja össze azt a munkával, amely kiváltotta?
Az „utolsó mérföld” megoldása egyedi integrációk és összekötő kódok létrehozását jelenti. Ez előre megnöveli a fejlesztők munkáját, és gyakran nehézkes munkafolyamatot eredményez mindenki más számára.
Műszaki akadályok és folyamatos karbantartás
A Python-alapú megközelítés leginkább azok számára elérhető, akik tudnak programozni. Ez gyakorlati akadályt jelent a marketing-, értékesítési és operációs csapatok számára, ami azt jelenti, hogy az alkalmazásuk korlátozott marad.
Emellett folyamatos karbantartást is igényel: a függőségek kezelését, a könyvtárak frissítését és az API-k és modellek fejlődésével minden működésének biztosítását. Ami gyors sikernek indul, csendben egy újabb rendszerré válhat, amelyet gondozni kell.
📮 ClickUp Insight: A munkahelyi zavarok 42%-a a platformok közötti váltakozásból, az e-mailek kezeléséből és a megbeszélések közötti ugrálásból származik. Mi lenne, ha megszüntethetné ezeket a költséges zavaró tényezőket? A ClickUp egyetlen, egyszerűsített platformon egyesíti a munkafolyamatokat (és a csevegést). Indítsa el és kezelje feladatait csevegés, dokumentumok, táblák és más eszközök segítségével, miközben az AI-alapú funkciók biztosítják a kontextus összekapcsolását, kereshetőségét és kezelhetőségét.
A nagyobb probléma: a kontextus elterjedése
Még ha az összefoglaló szkriptje tökéletesen működik is, a csapata akkor is időt veszíthet, mert az eredmény nem kapcsolódik ahhoz a helyhez, ahol a munka ténylegesen zajlik.
Ez a kontextus szétaprózódása, amikor a csapatok órákat pazarolnak információk keresésére, alkalmazások közötti váltogatásra és fájlok felkutatására egymástól független platformokon.
Itt jön be a képbe a konvergált munkaterület. Ahelyett, hogy egy helyen generálna összefoglalókat, majd később megpróbálná azokat „átvinni a munkába”, a konvergált rendszer a projekteket, dokumentumokat és beszélgetéseket egy helyen tartja, a ClickUp Brain intelligencia rétegeként. Az összefoglalók kapcsolatban maradnak a feladatokkal és a dokumentumokkal, így a következő lépés egyértelmű, és az átadás azonnal megtörténik.
A ClickUp segítségével cselekvéssé váló összefoglalás
Egy összefoglaló szkript tökéletesen működhet, mégis egy bosszantó módon kudarcot vallhat a csapatod számára: az összefoglaló végül a munkától elkülönülten marad.
Ez a rés kontextus-szétszóródást eredményez, ahol az információk dokumentumok, csevegési szálak, feladatok és „gyorsjegyzetek” között szétszóródnak olyan eszközökben, amelyek nem kapcsolódnak egymáshoz. Az emberek több időt töltenek az összefoglaló keresésével, mint annak használatával. Az igazi győzelem nem csak az összefoglaló létrehozása. Az, hogy az összefoglaló kapcsolódjon a döntésekhez, a felelősökhöz és a következő lépésekhez, ahol a munka ténylegesen zajlik.
Ez az, amit a ClickUp Brain másképp csinál. Összefoglalja a feladatokat, dokumentumokat és beszélgetéseket azonos munkaterületen belül, ahol a projektjei is találhatóak, így a csapata megértheti a dolgokat és cselekedhet anélkül, hogy más eszközökre kellene átváltania.

ClickUp BrainGPT: interakció az összefoglalásokkal természetes nyelv használatával
Asztali számítógépen a BrainGPT a ClickUp Brain beszélgetési felülete. Ahelyett, hogy szkripteket, jegyzetfüzeteket vagy külső AI eszközöket nyitnának meg, a csapata egyszerű nyelven, közvetlenül a ClickUp-ban kérheti meg, amire szüksége van.
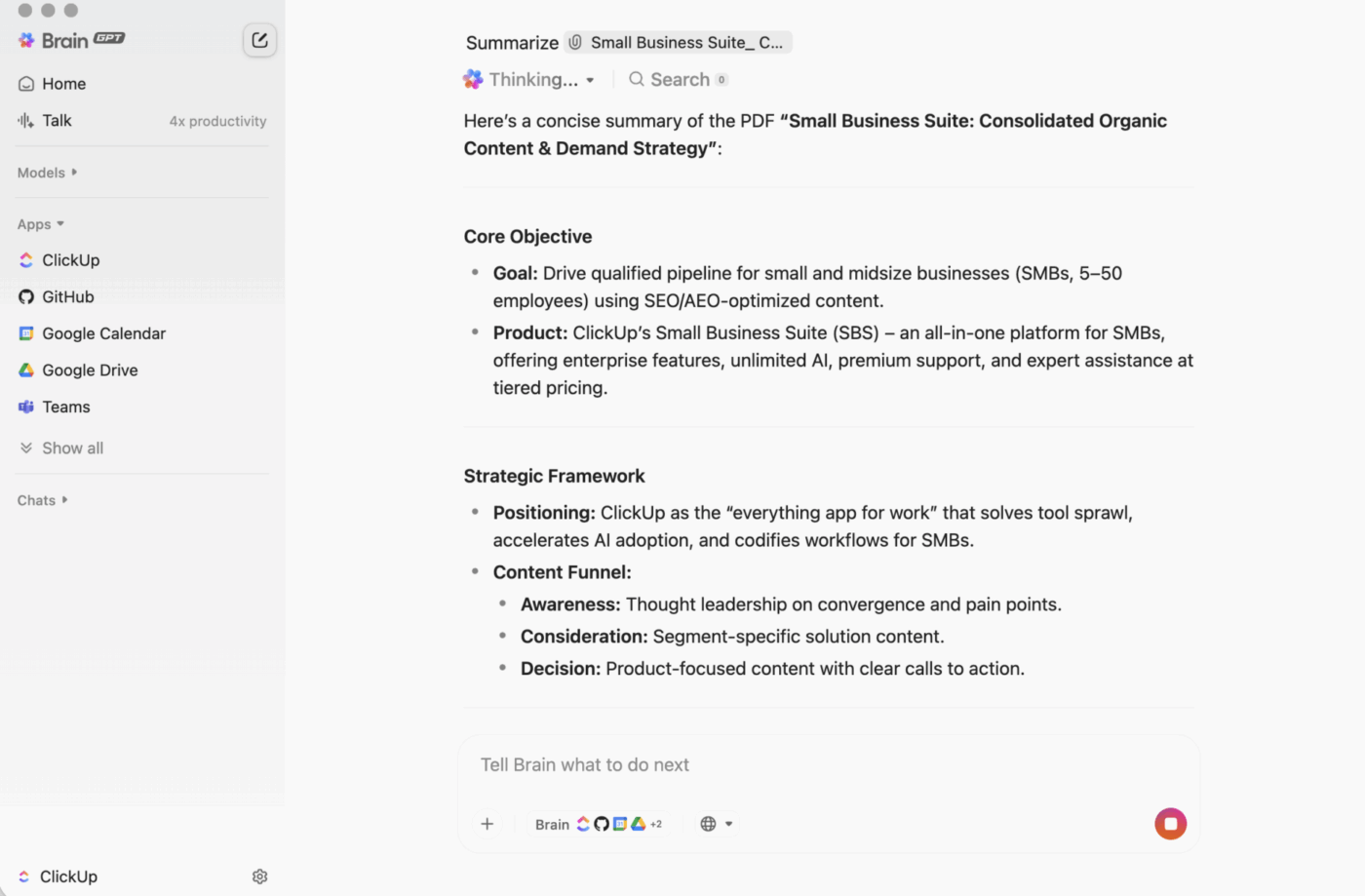
Írhat (vagy használhatja a beszéd-szöveggé funkciót) a következőkre:
- Összefoglalja egy hosszú feladatleírást, kommentárszálat vagy dokumentumot.
- Kövesse nyomon olyan kérdésekkel, mint „Mi a következő lépés?” vagy „Ki a felelős ezért?”.
- Tegye az összefoglalót cselekvéssé úgy, hogy belőle feladatokat hoz létre, tulajdonosokkal és határidőkkel.
Mivel a ClickUp Brain a munkaterületén belül működik, az eredmény élő kontextuson alapul: feladatleírások, megjegyzések, alfeladatok, kapcsolódó dokumentumok és a projekt felépítése. Nem kell szöveget beillesztenie egy külön eszközbe, és remélnie, hogy semmi fontos nem marad ki.
Miért jobb ez a legtöbb csapat számára, mint a kódalapú összefoglalási munkafolyamat?
A fejlesztők által létrehozott munkafolyamatok hatékony összefoglalókat tudnak generálni. A probléma akkor jelentkezik, amikor valakinek át kell másolnia a kimenetet a munka helyszínére, majd feladatokká kell alakítania, és végül nyomon kell követnie a végrehajtást.
A ClickUp Brain bezárja ezt a kört:
Nincs szükség kódolásraA csapat bármely tagja összefoglalhat egy dokumentumot, egy feladat szálat vagy egy rendezetlen kommentárkészletet anélkül, hogy bármit is telepítenie vagy kódot írnia kellene.
Kontextust figyelembe vevő összefoglalók A ClickUp Brain tartalmazhatja azokat a részeket, amelyeket az emberek általában elfelejtenek: a megjegyzésekben elrejtett döntéseket, a válaszokban említett akadályokat, a „kész” jelentését megváltoztató alfeladatokat.
Az összefoglalók ott vannak, ahol a munka is Felzárkózhat egy feladatba, hozzáadhat egy összefoglalót a ClickUp Docs tetejére, vagy gyorsan összefoglalhat egy beszélgetést anélkül, hogy létrehozna egy újabb „összefoglaló dokumentumot”, amelyet senki sem olvas el.
Kevesebb eszközNincs szükség külön szkriptekre, Jupyter notebookokra, API-kulcsokra vagy olyan munkafolyamatra, amelyet csak egy ember ért. A dokumentumok, feladatok és összefoglalások mind ugyanabban a rendszerben maradnak.
Ez a konvergált munkaterület gyakorlati előnye: az összefoglalás, a cselekvés és az együttműködés egyszerre történik, ahelyett, hogy utólag összeraknák őket.
Ez a konvergált munkaterület gyakorlati előnye: az összefoglalás, a cselekvés és az együttműködés egyszerre történik, ahelyett, hogy utólag összeraknák őket.
Hogyan működik ez a valós életben?
Íme néhány általános minta, amelyet a csapatok használnak:
- Összefoglaljon egy kommentárszálat: nyisson meg egy hosszú vitát tartalmazó feladatot, kattintson az AI opcióra, és kapjon egy gyors összefoglalót arról, mi változott és mi a fontos.
- Összefoglaljon egy dokumentumot: nyissa meg a ClickUp Doc alkalmazást, és az „Ask AI” funkcióval készítsen összefoglalót az oldalról, hogy mindenki gyorsan eligazodhasson benne.
- Cselekvési tételek kivonása: vegye az összefoglalót, és azonnal alakítsa át a következő lépéseket feladatokká, kijelölt felelősökkel és határidőkkel, hogy a lendület ne vesszen el az átadás során.
| Képesség | Hugging Face (kódalapú) | ClickUp Brain |
|---|---|---|
| Beállítás szükséges | Python környezet, könyvtárak, kódolás | Nincs, beépített |
| Kontextustudatosság | Csak szöveg (amit átad) | Teljes munkaterületi kontextus (feladatok, dokumentumok, megjegyzések, alfeladatok) |
| Munkafolyamat-integráció | Kézi export/import | Natív: az összefoglalók feladatokká és frissítéseké válhatnak |
| Szükséges technikai ismeretek | Fejlesztői szint | A csapat bármely tagja |
| Karbantartás | Folyamatos modell- és kódkarbantartás | Automatikus frissítések |
Az összefoglalásoktól a végrehajtásig a Super Agents segítségével
Az összefoglalók hasznosak. A nehéz rész az, hogy biztosítsuk, hogy azok következetesen cselekvéssé váljanak, különösen akkor, ha a mennyiség növekszik.
Itt jönnek képbe a ClickUp Super Agents . Ők felhasználhatják az összefoglalt információkat, és ugyanazon a munkaterületen belül, kiváltó események és feltételek alapján előrevihetik a munkát.
A Super Agents segítségével a csapatok:
- Összefoglalja a változásokat egy ütemterv szerint (heti projektösszefoglaló, napi állapotjelentések)
- Cselekvési tételek kivonása és tulajdonosok automatikus hozzárendelése
- Jelölje meg a leállt munkákat (felülvizsgálatban ragadt feladatok, megválaszolatlan szálak, lejárt következő lépések)
- Tartsa magas szinten a vezetőség láthatóságát manuális jelentések nélkül
Ahelyett, hogy az összefoglaló statikus szövegként maradna, az ügynökök segítik, hogy az összefoglaló tervvé váljon, a terv pedig előrelépéssé.
Összefoglalás, amely ott történik, ahol a munka zajlik
A Hugging Face Transformers kiválóan alkalmas, ha egyedi alkalmazásra, testreszabott folyamatra vagy a modell viselkedésének teljes ellenőrzésére van szükség.
De a legtöbb csapat számára a nagyobb probléma nem az, hogy „Összefoglalhatjuk ezt?”, hanem az, hogy „Összefoglalhatjuk ezt, és azonnal munkává alakíthatjuk, tulajdonosokkal, határidőkkel és láthatósággal?”
Ha a célja a csapat termelékenysége és a gyors végrehajtás, a ClickUp Brain kontextusban nyújt összefoglalókat, pontosan ott, ahol a munka folyik, egyértelmű útmutatással a „itt van a lényeg” és a „ezek a következő lépéseink” között.
Készen áll arra, hogy kihagyja a beállítást, és elkezdje összefoglalni a munkáját ott, ahol az ténylegesen zajlik? Kezdje el ingyenesen a ClickUp használatát, és hagyja, hogy a Brain végezze el a nehéz munkát.