
Většina projektů nasazení AI selže ne proto, že týmy vybraly nesprávný model, ale proto, že si nikdo po třech měsících nepamatuje, proč jej vybraly nebo jak replikovat nastavení, přičemž 46 % projektů AI je zrušeno mezi fází ověření koncepce a širokým nasazením.
Tato příručka vás provede používáním Hugging Face pro nasazení AI – od výběru a testování modelů až po správu procesu nasazení – aby váš tým mohl dodávat rychleji, aniž by došlo ke ztrátě důležitých rozhodnutí ve vláknech Slacku a roztříštěných tabulkách.
Co je Hugging Face?
Hugging Face je open-source platforma a komunitní centrum, které poskytuje předem vycvičené modely AI, datové sady a nástroje pro vytváření a nasazování aplikací strojového učení.
Představte si to jako obrovskou digitální knihovnu, kde najdete hotové modely AI, místo abyste trávili měsíce a vynakládali značné prostředky na jejich vytváření od nuly.
Je určen pro inženýry strojového učení a datové vědce, ale jeho nástroje stále častěji využívají i mezioborové týmy zabývající se produkty, designem a inženýrstvím k integraci AI do svých pracovních postupů.
Věděli jste, že: 63 % organizací nemá správné postupy pro správu dat pro AI. To často vede k zastavení projektů a plýtvání zdroji.
Hlavní výzvou pro mnoho týmů je samotná složitost nasazení AI. Tento proces zahrnuje výběr správného modelu z tisíců možností, správu základní infrastruktury, verzování experimentů a zajištění souladu mezi technickými a netechnickými zúčastněnými stranami.
Hugging Face to zjednodušuje díky Model Hub, centrálnímu úložišti s více než 2 miliony modelů. Knihovna transformátorů platformy je klíčem k odemčení těchto modelů, který vám umožní je načíst a používat pomocí několika řádků kódu Python.
I s těmito výkonnými nástroji však nasazení AI zůstává výzvou v oblasti projektového řízení, která vyžaduje pečlivé sledování výběru modelu, testování a zavádění, aby byl zajištěn úspěch.
📮ClickUp Insight: 92 % znalostních pracovníků riskuje ztrátu důležitých rozhodnutí roztroušených v chatu, e-mailech a tabulkách. Bez jednotného systému pro zaznamenávání a sledování rozhodnutí se důležité obchodní informace ztrácejí v digitálním šumu.
Díky funkcím správy úkolů ClickUp se o to už nikdy nebudete muset starat. Vytvářejte úkoly z chatu, komentářů k úkolům, dokumentů a e-mailů jediným kliknutím!
📚 Přečtěte si také: Nejlepší alternativy Hugging Face pro LLM, NLP a AI pracovní postupy
Modely Hugging Face, které můžete nasadit
Procházení platformy Hugging Face Hub může být na začátku trochu matoucí. S ohledem na stovky tisíc modelů je klíčové porozumět hlavním kategoriím, abyste našli ten správný model pro svůj projekt. Modely se pohybují od malých, efektivních variant určených pro jeden účel až po rozsáhlé modely pro všeobecné použití, které zvládají komplexní úvahy.
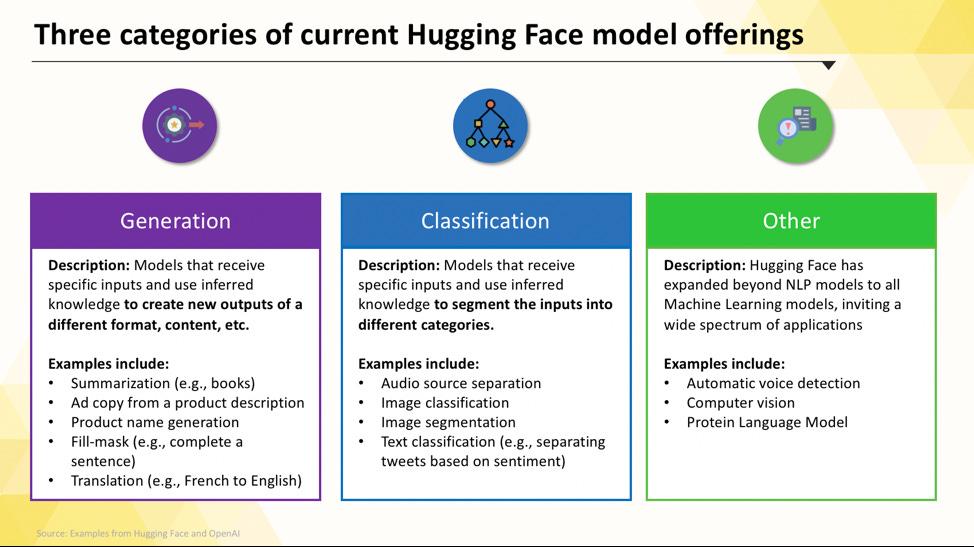
Jazykové modely pro konkrétní úkoly
Když váš tým potřebuje vyřešit jeden konkrétní, jasně definovaný problém, často nepotřebujete rozsáhlý model pro všeobecné použití. Čas a náklady na provoz takového modelu mohou být neúnosné, zejména pokud by lépe fungoval menší, specializovanější nástroj AI. Právě v takových případech přicházejí na řadu modely určené pro konkrétní úkoly.
Jedná se o modely, které byly vycvičeny a optimalizovány pro jednu konkrétní funkci. Vzhledem k tomu, že jsou specializované, jsou obvykle menší, rychlejší a efektivnější z hlediska využití zdrojů než jejich větší protějšky.
Díky tomu jsou ideální pro produkční prostředí, kde jsou důležitými faktory rychlost a náklady. Mnohé z nich lze dokonce spustit na standardním hardwaru CPU, takže jsou dostupné i bez drahých GPU.
Mezi běžné typy modelů pro konkrétní úkoly patří:
- Klasifikace textu: Použijte tuto funkci k rozdělení textu do předem definovaných kategorií, například k roztřídění zákaznické zpětné vazby do kategorií „pozitivní“ nebo „negativní“ nebo k označení ticketů podpory podle tématu.
- Analýza sentimentu: Pomáhá vám určit emocionální tón textu, což je užitečné pro sledování značky na sociálních médiích.
- Rozpoznávání pojmenovaných entit: Extrahujte z dokumentů konkrétní entity, jako jsou osoby, místa a organizace, a pomozte tak strukturovat nestrukturovaná data.
- Shrnutí: Zkrácení dlouhých článků nebo zpráv do stručných shrnutí, čímž ušetříte svému týmu drahocenný čas na čtení.
- Překlad: Automaticky převádějte text z jednoho jazyka do druhého.
📚 Přečtěte si také: Jak používat Hugging Face pro shrnování textu
Velké jazykové modely
Někdy váš projekt vyžaduje více než jen jednoduchou klasifikaci nebo shrnutí. Možná budete potřebovat AI, která dokáže generovat kreativní marketingové texty, psát kód nebo odpovídat na složité otázky uživatelů konverzačním způsobem. V těchto scénářích se pravděpodobně obrátíte na velký jazykový model (LLM).
LLM jsou modely s miliardami parametrů, které jsou trénovány na obrovském množství textů a dat z internetu. Toto rozsáhlé trénování jim umožňuje porozumět nuancím, kontextu a složitému uvažování. Mezi populární open-source LLM dostupné na Hugging Face patří modely z rodin Llama, Mistral a Falcon.
Nevýhodou této výkonnosti je značná spotřeba výpočetních zdrojů. Nasazení těchto modelů téměř vždy vyžaduje výkonné grafické procesory s velkou pamětí (VRAM).
Aby byly přístupnější, můžete použít techniky jako kvantizace, která snižuje velikost modelu za malou cenu v oblasti výkonu, což umožňuje jeho spuštění na méně výkonném hardwaru.
📚 Přečtěte si také: Co jsou agenti LLM v AI a jak fungují?
Modely pro převod textu na obraz a multimodální modely
Vaše data nejsou vždy jen text. Váš tým možná potřebuje generovat obrázky pro marketingovou kampaň, přepsat zvukový záznam ze schůzky nebo porozumět obsahu videa. Právě v těchto případech jsou nezbytné multimodální modely, které jsou navrženy tak, aby fungovaly s různými typy dat.
Nejoblíbenějším typem multimodálního modelu je model text-to-image, který generuje obrázky z textového popisu. Modely jako Stable Diffusion používají techniku zvanou difúze k vytváření úžasných vizuálů z jednoduchých podnětů. Možnosti však sahají daleko za hranice generování obrázků.
Mezi další běžné multimodální modely, které můžete nasadit z Hugging Face, patří:
- Popisky obrázků: Automaticky generujte popisný text k obrázkům, což je skvělé pro přístupnost a správu obsahu.
- Rozpoznávání řeči: Převádějte mluvený zvuk na psaný text pomocí modelů, jako je Whisper od OpenAI.
- Vizuální zodpovídání otázek: Zeptejte se na obrázek a získejte textovou odpověď, například „Jakou barvu má auto na této fotografii?“
Stejně jako LLM jsou i tyto modely výpočetně náročné a pro efektivní provoz obvykle vyžadují GPU.
📚 Přečtěte si také: Více než 50 podnětů pro AI obrázky k vytvoření úžasných vizuálů
Chcete-li vidět, jak se tyto různé typy modelů AI promítají do praktických obchodních aplikací, podívejte se na tento přehled reálných případů použití AI v různých odvětvích a funkcích.
Jaká je úroveň vyspělosti AI ve vaší organizaci?
Náš průzkum mezi 316 odborníky odhalil, že skutečná transformace AI vyžaduje více než jen přijetí funkcí AI. Vyplňte hodnocení vyspělosti AI a zjistěte, kde se vaše organizace nachází a co můžete udělat pro zlepšení svého skóre.
Jak nastavit Hugging Face pro nasazení AI
Než budete moci nasadit svůj první model, musíte správně nastavit své místní prostředí a účet Hugging Face. Častým zdrojem frustrace pro týmy je, když mají různí členové nesourodá nastavení, což vede k klasickému problému „na mém počítači to funguje“. Pokud si uděláte pár minut čas na standardizaci tohoto procesu, ušetříte si později hodiny strávené řešením problémů.
- Vytvořte si účet Hugging Face a vygenerujte přístupový token. Nejprve se zaregistrujte a vytvořte si bezplatný účet na webových stránkách Hugging Face. Po přihlášení přejděte do svého profilu, klikněte na „Nastavení“ a poté přejděte na kartu „Přístupové tokeny“. Vygenerujte nový token s alespoň oprávněním „číst“; budete jej potřebovat ke stažení modelů.
- Nainstalujte potřebné knihovny Pythonu. Otevřete terminál a nainstalujte základní knihovny, které budete potřebovat. Dvě nezbytné knihovny jsou transformers a huggingface_hub. Můžete je nainstalovat pomocí pip: pip install transformers huggingface_hub
- Nakonfigurujte ověřování. Chcete-li použít svůj přístupový token, můžete se přihlásit buď přes příkazový řádek spuštěním příkazu huggingface-cli login a vložením svého tokenu po zobrazení výzvy, nebo jej můžete nastavit jako proměnnou prostředí ve svém systému. Přihlášení přes příkazový řádek je často nejjednodušší způsob, jak začít.
- Ověřte nastavení. Nejlepší způsob, jak ověřit, že vše funguje, je spustit jednoduchý kód. Zkuste načíst základní model pomocí funkce pipeline z knihovny transformers. Pokud běží bez chyb, jste připraveni začít.
Mějte na paměti, že některé modely na Hubu jsou „uzamčené“, což znamená, že předtím, než k nim získáte přístup pomocí svého tokenu, musíte souhlasit s licenčními podmínkami na stránce modelu.
Nezapomeňte také, že sledování toho, kdo má jaká oprávnění a jaké konfigurace prostředí se používají, je samo o sobě úkolem projektového managementu, který se stává čím dál důležitějším s tím, jak váš tým roste.
🌟 Pokud integrujete modely Hugging Face do širších softwarových systémů, šablona pro integraci softwaru ClickUp vám pomůže vizualizovat pracovní postupy a sledovat vícestupňové technické integrace.
Šablona vám poskytuje snadno použitelný systém, ve kterém můžete:
- Vizualizujte propojení mezi různými softwarovými řešeními
- Vytvářejte úkoly a přiřazujte je členům týmu pro hladší spolupráci.
- Organizujte všechny úkoly související s integrací na jednom místě.
Možnosti nasazení modelů Hugging Face
Jakmile otestujete model lokálně, vyvstane další otázka: kde bude umístěn? Nasazení modelu do produkčního prostředí, kde jej mohou používat i ostatní, je kritickým krokem, ale možnosti mohou být matoucí. Výběr nesprávné cesty může vést k pomalému výkonu, vysokým nákladům nebo neschopnosti zvládnout uživatelský provoz.
Vaše volba bude záviset na vašich konkrétních potřebách, jako je očekávaný provoz, rozpočet a to, zda vytváříte rychlý prototyp nebo škálovatelnou aplikaci připravenou k produkci.
Hugging Face Spaces
Pokud potřebujete rychle vytvořit demo nebo interní nástroj, Hugging Face Spaces je často tou nejlepší volbou. Spaces je bezplatná platforma pro hostování aplikací strojového učení a je ideální pro vytváření prototypů, které můžete sdílet se svým týmem nebo zainteresovanými stranami.
Uživatelské rozhraní své aplikace můžete vytvořit pomocí populárních frameworků, jako jsou Gradio nebo Streamlit, které usnadňují vytváření interaktivních ukázek pomocí několika řádků kódu v jazyce Python.
Vytvoření prostoru je stejně jednoduché jako výběr preferovaného SDK, připojení repozitáře Git s vaším kódem a výběr hardwaru. Spaces nabízí bezplatnou úroveň CPU pro základní aplikace, ale pro náročnější modely můžete upgradovat na placený hardware GPU.
Mějte na paměti omezení:
- Není určeno pro API s vysokým provozem: Spaces je určeno pro demonstrace, nikoli pro obsluhu tisíců souběžných požadavků API.
- Studené spuštění: Pokud je váš prostor neaktivní, může „usnout“, aby šetřil zdroje, což způsobí zpoždění pro prvního uživatele, který k němu znovu přistoupí.
- Pracovní postup založený na Git: Veškerý kód vaší aplikace je spravován prostřednictvím repozitáře Git, který je skvělý pro správu verzí.
Hugging Face Inference API
Pokud potřebujete integrovat model do stávající aplikace, pravděpodobně budete chtít použít API. Hugging Face Inference API vám umožňuje spouštět modely, aniž byste museli sami spravovat jakoukoli základní infrastrukturu. Stačí odeslat HTTP požadavek s vašimi daty a obdržíte zpět předpověď.
Tento přístup je ideální, pokud se nechcete zabývat servery, škálováním nebo údržbou. Hugging Face nabízí pro tuto službu dvě hlavní úrovně:
- Bezplatné API pro inferenci: Jedná se o sdílenou infrastrukturu s omezenou rychlostí, která je ideální pro vývoj a testování. Je perfektní pro případy s nízkým provozem nebo když teprve začínáte.
- Inference Endpoints: Pro produkční aplikace budete chtít použít Inference Endpoints. Jedná se o placenou službu, která vám poskytuje vyhrazenou infrastrukturu s automatickým škálováním a zajišťuje, že vaše aplikace bude rychlá a spolehlivá i při velkém zatížení.
Použití API zahrnuje odeslání JSON payloadu na koncovou URL modelu s vaším autentizačním tokenem v hlavičce požadavku.
Nasazení cloudové platformy
Pro týmy, které již mají významnou přítomnost u hlavních poskytovatelů cloudových služeb, jako jsou Amazon Web Services (AWS), Google Cloud Platform (GCP) nebo Microsoft Azure, může být nasazení u těchto poskytovatelů nejlogičtější volbou. Tento přístup vám poskytuje největší kontrolu a umožňuje integrovat model s vašimi stávajícími cloudovými službami a bezpečnostními protokoly.
Obecný pracovní postup zahrnuje „kontejnerizaci“ vašeho modelu a jeho závislostí pomocí Dockeru a následné nasazení tohoto kontejneru do cloudové výpočetní služby. Každý poskytovatel cloudových služeb má služby a integrace, které tento proces zjednodušují:
- AWS SageMaker: Nabízí nativní integraci pro trénování a nasazování modelů Hugging Face.
- Google Cloud Vertex AI: Umožňuje nasazovat modely z Hubu do spravovaných koncových bodů.
- Azure Machine Learning: Poskytuje nástroje pro import a poskytování modelů Hugging Face.
Ačkoli tato metoda vyžaduje více nastavení a odborných znalostí v oblasti DevOps, je často nejlepší volbou pro rozsáhlá nasazení na podnikové úrovni, kde potřebujete plnou kontrolu nad prostředím.
📚 Přečtěte si také: Automatizace pracovních postupů: Automatizujte pracovní postupy a zvyšte produktivitu
Jak spustit modely Hugging Face pro inferenci
Při použití Hugging Face pro nasazení AI je „spuštění inference“ procesem, při kterém se váš trénovaný model používá k předpovídání nových, dosud neznámých dat. Je to okamžik, kdy váš model vykonává práci, pro kterou jste jej nasadili. Správné provedení tohoto kroku je klíčové pro vytvoření responzivní a efektivní aplikace.
Největší frustrací pro týmy je psaní inferenčního kódu, který je pomalý nebo neefektivní, což může vést ke špatné uživatelské zkušenosti a vysokým provozním nákladům. Naštěstí knihovna transformers nabízí několik způsobů, jak spustit inferenci, z nichž každý má své vlastní kompromisy mezi jednoduchostí a kontrolou.
- Pipeline API: Jedná se o nejjednodušší a nejběžnější způsob, jak začít. Funkce pipeline() abstrahuje většinu složitosti a za vás se postará o předzpracování dat, předávání modelů a následné zpracování. U mnoha standardních úkolů, jako je analýza sentimentu, můžete získat predikci pomocí jediného řádku kódu.
- AutoModel + AutoTokenizer: Pokud potřebujete větší kontrolu nad procesem inferenční analýzy, můžete přímo použít třídy AutoModel a AutoTokenizer. To vám umožní ručně nastavit, jak bude váš text tokenizován a jak bude surový výstup modelu převeden na předpověď srozumitelnou pro člověka. Tento přístup je užitečný, když pracujete s vlastní úlohou nebo potřebujete implementovat specifickou logiku předběžného nebo následného zpracování.
- Hromadné zpracování: Pro maximalizaci efektivity, zejména na GPU, byste měli zpracovávat vstupy hromadně, nikoli jeden po druhém. Odeslání hromadných vstupů přes model v jediném předním průchodu je výrazně rychlejší než odesílání každého vstupu jednotlivě.
Sledování výkonu vašeho inferenčního kódu je klíčovou součástí životního cyklu nasazení. Sledování metrik, jako je latence (jak dlouho trvá predikce) a propustnost (kolik predikcí můžete provést za sekundu), vyžaduje koordinaci a jasnou dokumentaci, zejména když různí členové týmu experimentují s novými verzemi modelů.
📚 Přečtěte si také: Nejlepší nástroje pro spolupráci týmů v oblasti AI
Příklad krok za krokem: Nasazení modelu Hugging Face
Projdeme si kompletní příklad nasazení jednoduchého modelu analýzy sentimentu. Postupováním podle těchto kroků se dostanete od výběru modelu až k funkčnímu, testovatelnému koncovému bodu.
- Vyberte si model: Přejděte na Hugging Face Hub a pomocí filtrů vlevo vyhledejte modely, které provádějí „klasifikaci textu“. Dobrým výchozím bodem je distilbert-base-uncased-finetuned-sst-2-english. Přečtěte si jeho modelovou kartu, abyste pochopili jeho výkon a způsob použití.
- Nainstalujte závislosti: Ve svém lokálním prostředí Python se ujistěte, že máte nainstalovány potřebné knihovny. Pro tento model budete potřebovat pouze transformátory a torch. Spusťte pip install transformers torch
- Testujte lokálně: Před nasazením se vždy ujistěte, že model na vašem počítači funguje podle očekávání. Napište malý skript v jazyce Python, který načte model pomocí pipeline, a otestujte jej na vzorové větě. Například: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") následovaný classifier("ClickUp je nejlepší platforma pro produktivitu!")
- Vytvoření nasazení: V tomto příkladu použijeme Hugging Face Spaces pro rychlé a snadné nasazení. Vytvořte nový prostor, vyberte Gradio SDK a vytvořte soubor app.py, který načte váš model a definuje jednoduché rozhraní Gradio pro interakci s ním.
- Ověření nasazení: Jakmile je váš Space spuštěn, můžete jej otestovat pomocí interaktivního rozhraní. Můžete také odeslat přímý požadavek API na koncový bod Space a získat odpověď JSON, která potvrdí, že program funguje správně.
Po provedení těchto kroků budete mít funkční model. Další fáze projektu bude zahrnovat sledování jeho využití, plánování aktualizací a případně škálování infrastruktury, pokud se stane populárním.
Pro týmy, které řídí komplexní projekty nasazení AI s více fázemi – od přípravy dat až po nasazení do produkce – poskytuje komplexní strukturu pokročilá šablona pro řízení softwarových projektů od ClickUp.
Tato šablona pomáhá týmům:
- Spravujte projekty s více milníky, úkoly, zdroji a závislostmi.
- Vizualizujte průběh projektu pomocí Ganttových diagramů a časových os.
- Spolupracujte hladce se svými kolegy a zajistěte úspěšné dokončení projektu.
Časté problémy při nasazení Hugging Face a jak je vyřešit
I s jasným plánem se při nasazení pravděpodobně setkáte s několika překážkami. Zírání na tajemnou chybovou zprávu může být neuvěřitelně frustrující a může zastavit pokrok vašeho týmu. Zde jsou některé z nejčastějších problémů a způsoby, jak je vyřešit. 🛠️
🚨Problém: „Model vyžaduje ověření“
- Příčina: Pokoušíte se přistupovat k „uzavřenému“ modelu, který vyžaduje, abyste přijali jeho licenční podmínky.
- Řešení: Přejděte na stránku modelu v Hubu, přečtěte si licenční smlouvu a přijměte ji. Ujistěte se, že přístupový token, který používáte, má oprávnění „číst“.
🚨Problém: „CUDA nemá dostatek paměti“
- Příčina: Model, který se pokoušíte načíst, je příliš velký pro paměť vašeho GPU (VRAM).
- Řešení: Nejrychlejším řešením je použít menší verzi modelu nebo kvantizovanou verzi. Můžete také zkusit snížit velikost dávky během inferenčního procesu.
🚨Problém: „chyba trust_remote_code”
- Příčina: Některé modely na Hubu vyžadují ke spuštění vlastní kód a z bezpečnostních důvodů jej knihovna ve výchozím nastavení neprovede.
- Řešení: Tuto situaci můžete obejít přidáním trust_remote_code=True při načítání modelu. Vždy byste však měli nejprve zkontrolovat zdrojový kód, abyste se ujistili, že je bezpečný.
🚨Problém: „Nesoulad tokenizátoru”
- Příčina: Tokenizér, který používáte, není přesně ten, se kterým byl model trénován, což vede k nesprávným vstupům a špatnému výkonu.
- Řešení: Tokenizér vždy načtěte ze stejného kontrolního bodu modelu jako samotný model. Například AutoTokenizer. from_pretrained("název modelu")
🚨Problém: „Překročen limit rychlosti“
- Příčina: V krátkém časovém období jste odeslali příliš mnoho požadavků na bezplatné rozhraní API Inference.
- Řešení: Pro produkční použití proveďte upgrade na vyhrazený inferenční koncový bod. Pro vývoj můžete implementovat ukládání do mezipaměti, abyste se vyhnuli opakovanému odesílání stejných požadavků.
Je velmi důležité sledovat, která řešení fungují pro které problémy. Bez centrálního místa, kde by se tyto poznatky dokumentovaly, týmy často řeší stejný problém znovu a znovu.
📮 ClickUp Insight: 1 ze 4 zaměstnanců používá čtyři nebo více nástrojů pouze k vytvoření kontextu v práci. Klíčový detail může být skrytý v e-mailu, rozvedený ve vlákně Slacku a zdokumentovaný v samostatném nástroji, což nutí týmy ztrácet čas hledáním informací místo toho, aby se věnovaly práci.
ClickUp sjednocuje celý váš pracovní postup do jedné jednotné platformy. Díky funkcím jako ClickUp Email Project Management, ClickUp Chat, ClickUp Docs a ClickUp Brain zůstává vše propojené, synchronizované a okamžitě přístupné. Rozlučte se s „prací kolem práce“ a získejte zpět svůj produktivní čas.
💫 Skutečné výsledky: Týmy mohou díky ClickUp ušetřit více než 5 hodin týdně, což představuje více než 250 hodin ročně na osobu, a to díky eliminaci zastaralých procesů správy znalostí. Představte si, co by váš tým mohl vytvořit s extra týdnem produktivity každý čtvrtrok!
Jak spravovat projekty nasazení AI v ClickUp
Použití Hugging Face pro nasazení AI usnadňuje balení, hostování a poskytování modelů, ale neodstraňuje koordinační náklady spojené s nasazením v reálném světě. Týmy stále musí sledovat, které modely se testují, sjednotit konfigurace, dokumentovat rozhodnutí a udržovat všechny – od inženýrů ML po produktové a provozní pracovníky – na stejné vlně.
Když váš technický tým testuje různé modely, váš produktový tým definuje požadavky a zainteresované strany žádají o aktualizace, informace se rozptýlí po Slacku, e-mailech, tabulkách a různých dokumentech.
Toto rozptýlení práce – fragmentace pracovních činností mezi více nesouvislými nástroji, které spolu nekomunikují – vytváří zmatek a zpomaluje všechny.
Právě zde hraje klíčovou roli ClickUp, první konvergovaný pracovní prostor pro AI na světě, který spojuje projektové řízení, dokumentaci a týmovou komunikaci do jediného pracovního prostoru.
Tato konvergence je obzvláště cenná pro projekty nasazení AI, kde technické a netechnické zainteresované strany potřebují sdílenou viditelnost, aniž by musely používat pět různých nástrojů.
Místo rozptýlení aktualizací mezi lístky, dokumenty a chatovými vlákny mohou týmy spravovat celý životní cyklus nasazení na jednom místě.
Zde je několik způsobů, jak ClickUp může podpořit váš projekt nasazení AI:
- Jasné vlastnictví a sledování v průběhu celého životního cyklu modelu: Použijte ClickUp Tasks ke sledování modelů Hugging Face během hodnocení, testování, přípravy a výroby, s přizpůsobenými stavy, vlastníky a blokátory viditelnými pro celý tým.
- Centralizovaná, živá dokumentace nasazení: Udržujte runbooky nasazení, konfigurace prostředí a průvodce řešením problémů v ClickUp Docs, aby se dokumentace vyvíjela společně s vašimi modely a zůstala snadno vyhledatelná a referenční. Protože jsou dokumenty propojeny s úkoly, vaše dokumentace je přímo u práce, ke které se vztahuje.
- Spolupráce v kontextu bez rozptýlení práce: Udržujte diskuse, rozhodnutí a aktualizace přímo spojené s úkoly a dokumenty, čímž snížíte závislost na roztříštěných vláknech Slacku, e-mailech a nesouvislých projektových nástrojích.
- Komplexní přehled o průběhu nasazení: Sledujte proces nasazení, včas identifikujte rizika a vyvažujte kapacitu týmu pomocí dashboardů ClickUp, které zobrazují průběh a úzká místa v reálném čase.
- Rychlejší zapracování a vyhledávání rozhodnutí díky integrované AI: Použijte ClickUp Brain k shrnutí dlouhých dokumentů o nasazení, získání relevantních poznatků z minulých nasazení a pomoci novým členům týmu se rychle zapracovat, aniž by museli prohledávat historický kontext.
📚 Přečtěte si také: Jak automatizovat procesy pomocí AI pro rychlejší a chytřejší pracovní postupy
Spravujte svůj projekt nasazení AI hladce v ClickUp
Úspěšné nasazení Hugging Face závisí na pevných technických základech a jasném, organizovaném řízení projektu. Technické výzvy jsou sice řešitelné, ale často jsou to právě problémy s koordinací a komunikací, které vedou k neúspěchu projektů.
Díky vytvoření jasného pracovního postupu na jedné platformě může váš tým dodávat rychleji a vyhnout se frustraci z rozptýlení kontextu – kdy týmy ztrácejí hodiny hledáním informací, přepínáním mezi aplikacemi a opakováním aktualizací na více platformách.
ClickUp, aplikace pro vše, co souvisí s prací, sjednocuje správu projektů, dokumentaci a komunikaci týmu na jednom místě, aby vám poskytla jediný zdroj informací pro celý životní cyklus nasazení AI.
Spojte své projekty nasazení AI a eliminujte chaos v nástrojích. Začněte ještě dnes zdarma s ClickUp.
Často kladené otázky (FAQ)
Ano, Hugging Face poskytuje velkorysou bezplatnou úroveň, která zahrnuje přístup k Model Hub, CPU poháněné Spaces pro dema a Inference API s omezenou rychlostí pro testování. Pro produkční potřeby vyžadující vyhrazený hardware nebo vyšší limity jsou k dispozici placené plány.
Spaces je navržen pro hostování interaktivních aplikací s vizuálním front-endem, což jej činí ideálním pro demonstrace a interní nástroje. Inference API poskytuje programový přístup k modelům, což vám umožňuje integrovat je do vašich aplikací pomocí jednoduchých HTTP požadavků.
Rozhodně. Prostřednictvím interaktivních ukázek hostovaných na Hugging Face Spaces mohou i členové týmu bez technických znalostí experimentovat s modely a poskytovat k nim zpětnou vazbu, aniž by museli napsat jediný řádek kódu.
Hlavními omezeními bezplatné verze jsou omezení rychlosti API Inference, použití sdíleného hardwaru CPU pro Spaces, které může být pomalé, a „studené starty“, kdy neaktivní aplikace potřebují chvíli na to, aby se probudily. /