
Většina vývojářů, kteří vytvářejí skript pro sumarizaci Hugging Face, naráží na stejný problém: shrnutí funguje perfektně v jejich terminálu. Ale málokdy se propojí se skutečnou prací, kterou má podporovat.
Tento průvodce vás provede vytvořením textového sumarizátoru pomocí knihovny Hugging Face Transformers a poté vám ukáže, proč i bezchybná implementace může způsobit více problémů, než kolik jich vyřeší, když váš tým potřebuje shrnutí, která skutečně souvisejí s úkoly, projekty a rozhodnutími.
Co je to shrnutí textu?
Týmy se topí v informacích. Čelíte dlouhým dokumentům, nekonečným zápisům z jednání, obsáhlým výzkumným pracím a čtvrtletním zprávám, jejichž ruční zpracování trvá hodiny. Toto neustálé přetížení informacemi zpomaluje rozhodování a snižuje produktivitu.
Shrnutí textu je proces, při kterém se pomocí zpracování přirozeného jazyka (NLP) zhušťuje obsah do krátké, souvislé verze, která zachovává nejdůležitější informace. Představte si to jako okamžitý souhrn pro jakýkoli dokument. Tato technologie shrnutí NLP obecně používá jeden ze dvou přístupů:
Extraktivní shrnutí: Tato metoda funguje tak, že identifikuje a vytáhne nejdůležitější věty přímo ze zdrojového textu. Je to jako mít zvýrazňovač, který za vás automaticky vybere klíčové body. Konečné shrnutí je sbírkou původních vět.
Abstraktivní shrnutí: Tato pokročilejší metoda generuje zcela nové věty, aby zachytila základní význam zdrojového textu. Parafrázuje informace, což vede k plynulejšímu a lidštějšímu shrnutí, podobně jako když člověk vysvětluje dlouhý příběh vlastními slovy.
Výsledky tohoto nástroje vidíte všude. Používá se ke zhuštění poznámek z jednání do akčních bodů, k destilaci zpětné vazby od zákazníků do trendů a k vytvoření rychlého přehledu projektové dokumentace. Cíl je vždy stejný: získat podstatné informace, aniž byste museli číst každé slovo.
📮 ClickUp Insight: Průměrný profesionál stráví více než 30 minut denně hledáním informací souvisejících s prací. To je více než 120 hodin ročně ztracených prohledáváním e-mailů, vláken Slacku a roztroušených souborů. Inteligentní asistent AI zabudovaný do vašeho pracovního prostoru to může změnit. ClickUp Brain poskytuje okamžité informace a odpovědi tím, že během několika sekund vyhledá správné dokumenty, konverzace a podrobnosti úkolů, takže můžete přestat hledat a začít pracovat.
💫 Skutečné výsledky: Týmy jako QubicaAMF ušetřily díky ClickUp více než 5 hodin týdně, což představuje přes 250 hodin ročně na osobu, a to díky odstranění zastaralých procesů správy znalostí.
Proč používat Hugging Face pro shrnování textu?
Vytvoření vlastního modelu shrnutí textu od nuly je obrovský úkol. Vyžaduje obrovské datové soubory pro trénování, výkonné a drahé výpočetní zdroje a tým odborníků na strojové učení. Tato vysoká vstupní bariéra brání většině technických a produktových týmů v tom, aby vůbec začaly.
Hugging Face je platforma, která tento problém řeší. Jedná se o open-source komunitu a platformu pro datovou vědu, která vám poskytuje přístup k tisícům předem vycvičených modelů, čímž efektivně demokratizuje shrnování LLM pro vývojáře. Místo toho, abyste začínali od nuly, můžete začít s výkonným modelem, který je již z 99 % hotový.
Zde je důvod, proč se tolik vývojářů obrací na Hugging Face: 🛠️
Přístup k předem vycvičeným modelům: Hugging Face Hub je obrovské úložiště více než 2 milionů veřejných modelů vycvičených společnostmi jako Google, Meta a OpenAI. Tyto nejmodernější kontrolní body si můžete stáhnout a použít pro své vlastní projekty.
Zjednodušené rozhraní API: Funkce pipeline je rozhraní API na vysoké úrovni, které zpracovává všechny složité kroky, jako je předzpracování textu, modelová inference a formátování výstupu, pomocí několika řádků kódu.
Rozmanitost modelů: Nejste omezeni na jednu možnost. Můžete si vybrat z široké škály architektur, jako jsou BART, T5 a Pegasus, z nichž každá má jiné silné stránky, velikost a výkonnostní charakteristiky.
Flexibilita frameworku: Knihovna Transformers bezproblémově spolupracuje s dvěma nejpopulárnějšími frameworky pro hluboké učení, PyTorch a TensorFlow. Můžete použít ten, se kterým je váš tým již obeznámen.
Podpora komunity: Díky rozsáhlé dokumentaci, oficiálním kurzům a aktivní komunitě vývojářů je snadné najít návody a získat pomoc, když narazíte na problémy.
Ačkoli je Hugging Face pro vývojáře neuvěřitelně výkonný nástroj, je důležité si uvědomit, že se jedná o řešení založené na kódu. Jeho implementace a údržba vyžaduje technické znalosti. To není vždy vhodné pro netechnické týmy, které potřebují pouze shrnovat svou práci.
🧐 Věděli jste? Knihovna Hugging Face Transformers umožnila široké použití nejmodernějších modelů NLP pomocí několika řádků kódu, a proto prototypy shrnutí často začínají právě zde.
Co jsou transformátory Hugging Face?
Rozhodli jste se tedy použít Hugging Face, ale jaká technologie vlastně stojí za tímto nástrojem? Jádrem technologie je architektura zvaná Transformer. Když byla představena v článku z roku 2017 s názvem „Attention Is All You Need“ (Pozornost je vše, co potřebujete), zcela změnila oblast NLP.
Před vznikem modelů Transformers měly modely potíže s porozuměním kontextu dlouhých vět. Klíčovou inovací modelu Transformer je mechanismus pozornosti, který modelu umožňuje při zpracování konkrétního slova zvážit význam různých slov ve vstupním textu. To mu pomáhá zachytit dlouhodobé závislosti a porozumět kontextu, což je pro vytváření souvislých shrnutí zásadní.
Knihovna Hugging Face Transformers je balíček Pythonu, který vám neuvěřitelně usnadní používání těchto složitých modelů. Nepotřebujete doktorát z strojového učení. Knihovna za vás odvede těžkou práci.
Tři základní komponenty, které potřebujete znát
- Tokenizátory: Modely nerozumí slovům, rozumí číslům. Tokenizátor vezme váš vstupní text a převede jej na sekvenci číselných tokenů – proces zvaný tokenizace –, kterou model dokáže zpracovat.
- Modely: Jedná se o předem vycvičené neuronové sítě. Pro shrnování se obvykle používají modely typu sekvence-sekvence se strukturou kodér-dekodér. Kodér čte vstupní text a vytváří jeho numerické znázornění, které dekodér používá k generování shrnutí.
- Pipelines: Toto je nejjednodušší způsob použití modelu. Pipeline spojuje předem vycvičený model s odpovídajícím tokenizérem a za vás zpracovává všechny kroky předběžného zpracování vstupu a následného zpracování výstupu.
Dva z nejpopulárnějších modelů pro shrnování jsou BART a T5. BART (Bidirectional and Auto-Regressive Transformer) je obzvláště dobrý v abstraktním shrnování a vytváří shrnutí, která se čtou velmi přirozeně. T5 (Text-to-Text Transfer Transformer) je univerzální model, který rámuje každou úlohu NLP jako problém text-to-text, což z něj dělá výkonný všestranný nástroj.
🎥 Podívejte se na toto video, kde najdete srovnání nejlepších AI PDF shrnovačů, a zjistěte, které nástroje poskytují nejrychlejší a nejpřesnější shrnutí bez ztráty kontextu.
Jak vytvořit textový sumarizátor s Hugging Face
Jste připraveni vytvořit si vlastní příklad sumarizátoru? Potřebujete pouze základní znalosti jazyka Python, editor kódu, jako je VS Code, a připojení k internetu. Celý proces trvá pouze čtyři kroky. Funkční sumarizátor budete mít hotový během několika minut.
Krok 1: Nainstalujte potřebné knihovny
Nejprve je třeba nainstalovat potřebné knihovny. Hlavní z nich je transformers. Budete také potřebovat framework pro hluboké učení, jako je PyTorch nebo TensorFlow. V tomto příkladu použijeme PyTorch.
Otevřete terminál nebo příkazový řádek a spusťte následující příkaz:

Některé modely, jako například T5, také vyžadují knihovnu sentencepiece pro svůj tokenizér. Je dobré ji také nainstalovat.

💡 Tip pro profesionály: Před instalací těchto balíčků vytvořte virtuální prostředí Python. Tím izolujete závislosti svého projektu a zabráníte konfliktům s jinými projekty ve vašem počítači.
Krok 2: Načtěte model a tokenizátor
Nejjednodušší způsob, jak začít, je použít funkci pipeline. Ta automaticky zajistí načtení správného modelu a tokenizátoru pro úkol shrnutí.
Ve svém skriptu v Pythonu importujte pipeline a inicializujte jej takto:

Zde specifikujeme dvě věci:
Úkol: Řekneme pipeline, že chceme provést „sumarizaci”.
Model: Z Hugging Face Hub vybereme konkrétní předem vycvičený model checkpoint. facebook/bart-large-cnn je oblíbená volba, která byla vycvičena na novinových článcích a dobře funguje pro obecné shrnování. Pro rychlejší testování můžete použít menší model, jako je t5-small.
Při prvním spuštění tohoto kódu se stáhnou váhy modelu z Hubu, což může trvat několik minut. Poté se model uloží do mezipaměti vašeho lokálního počítače pro okamžité načtení.
Krok 3: Vytvořte funkci shrnutí
Aby byl váš kód čistý a znovu použitelný, je nejlepší zabalit logiku shrnutí do funkce. To také usnadňuje experimentování s různými parametry.
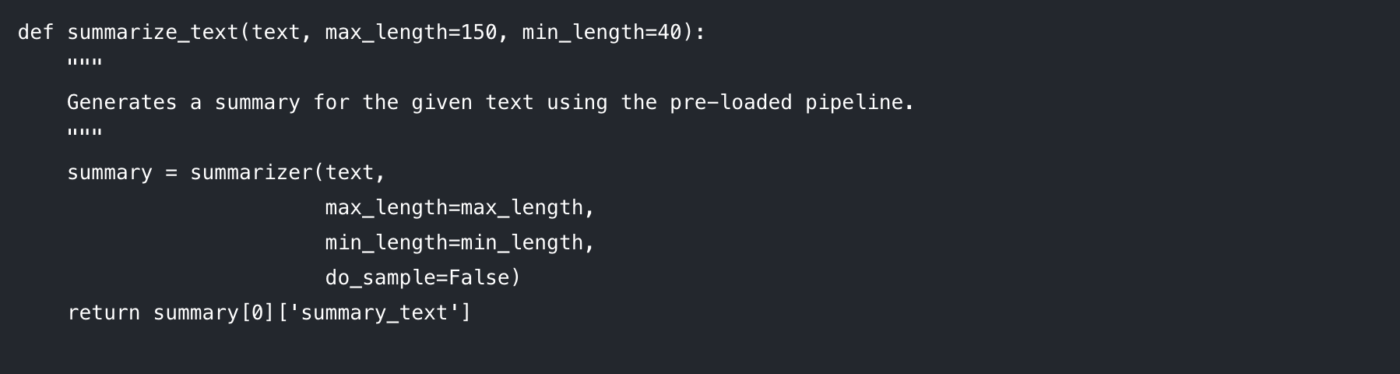
Rozebřeme si parametry, které můžete ovládat:
max_length: Nastavuje maximální počet tokenů (zhruba slov) pro výstupní shrnutí.
min_length: Nastavuje minimální počet tokenů, aby model nevytvářel příliš krátké nebo prázdné shrnutí.
do_sample: Pokud je nastaveno na False, model používá deterministickou metodu (jako beam search) k vygenerování nejpravděpodobnějšího shrnutí. Nastavení na True zavádí náhodnost, která může produkovat kreativnější, ale méně předvídatelné výsledky.
Nastavení těchto parametrů je klíčem k dosažení požadované kvality výstupu.
Krok 4: Vytvořte své shrnutí
A teď ta zábavná část. Předávejte svůj text funkci a vytiskněte výsledek. 🤩

Na konzoli by se měla zobrazit zkrácená verze článku. Pokud narazíte na problémy, zde je několik rychlých řešení:
Vstupní text je příliš dlouhý: Model může vyhodit chybu, pokud váš vstup překročí maximální délku (často 512 nebo 1024 tokenů). Přidejte truncation=True do volání summarizer(), aby se dlouhé vstupy automaticky zkrátily.
Shrnutí je příliš obecné: Zkuste zvýšit parametr num_beams (např. num_beams=4). Díky tomu model důkladněji vyhledá lepší shrnutí, ale může být o něco pomalejší.
Tento přístup založený na kódu je fantastický pro vývojáře, kteří vytvářejí vlastní aplikace. Ale co se stane, když to potřebujete integrovat do každodenní práce týmu? Tam se začínají projevovat omezení.
Omezení Hugging Face pro shrnování textu
Hugging Face je skvělou volbou, pokud chcete flexibilitu a kontrolu. Jakmile jej však zkusíte použít pro skutečné týmové pracovní postupy (nejen pro demo notebook), rychle se objeví několik předvídatelných problémů.
Limity tokenů a problémy s dlouhými dokumenty
Většina modelů shrnutí má pevně stanovenou maximální délku vstupu. Například facebook/bart-large-cnn je nakonfigurován s max_position_embeddings = 1024. To znamená, že delší dokumenty často vyžadují zkrácení nebo rozdělení na části.
Pokud potřebujete pouze rychlý základ, můžete v pipeline povolit zkrácení a pokračovat dál. Pokud však potřebujete věrné shrnutí dlouhých dokumentů, obvykle skončíte tím, že vytvoříte logiku rozdělení na části a poté provedete druhý průchod, „shrnutí shrnutí“, abyste výsledky spojili dohromady. To je navíc technicky náročné a snadno může dojít k nekonzistentním výstupům.
Riziko halucinace (a ověřovací daň)
Abstraktivní modely mohou někdy halucinovat a generovat text, který zní věrohodně, ale je fakticky nesprávný. Pro použití v podnikání to představuje problém: každý souhrn je třeba ručně ověřit. V tom okamžiku ve skutečnosti nešetříte čas, pouze přesouváte práci do jiné části procesu.
Nedostatek kontextového povědomí
Model Hugging Face zná pouze text, který mu zadáte. Nerozumí cílům vašeho projektu, osobám, které se na něm podílejí, ani tomu, jak souvisí jeden dokument s druhým, protože postrádá kontextovou inteligenci moderních systémů. Nedokáže vám říct, zda shrnutí z hovoru se zákazníkem odporuje dokumentu s požadavky projektu, protože funguje izolovaně.
Integrační režie (problém „poslední míle“)
Vytvoření shrnutí je obvykle snadná část. Skutečný problém nastává až poté.
Kam se shrnutí dostane? Kdo ho uvidí? Jak se promění v akční úkol? Jak ho propojíte s prací, která ho vyvolala?
Řešení této „poslední míle“ znamená vytvoření vlastních integrací a spojovacího kódu. To zvyšuje práci vývojářů a často vytváří neohrabaný pracovní postup pro všechny ostatní.
Technická překážka a průběžná údržba
Přístup založený na Pythonu je většinou přístupný lidem, kteří umí programovat. To vytváří praktickou překážku pro marketingové, prodejní a provozní týmy, což znamená, že jeho přijetí zůstává omezené.
Součástí je také průběžná údržba: správa závislostí, aktualizace knihoven a zajištění funkčnosti všeho v souvislosti s vývojem API a modelů. Co začíná jako rychlý úspěch, se může tiše proměnit v další systém, o který je třeba se starat.
📮 ClickUp Insight: 42 % přerušení práce pochází z přeskakování mezi platformami, správy e-mailů a přecházení mezi schůzkami. Co kdybyste mohli tyto nákladné přerušení eliminovat? ClickUp sjednocuje vaše pracovní postupy (a chat) pod jednou efektivní platformou. Spouštějte a spravujte své úkoly z chatu, dokumentů, tabulek a dalších míst, zatímco funkce založené na umělé inteligenci udržují kontext propojený, prohledávatelný a spravovatelný.
Větší problém: Rozptýlení kontextu
I když váš skript pro vytváření shrnutí funguje perfektně, váš tým může stále ztrácet čas, protože výstup není propojen s místem, kde se práce skutečně odehrává.
To je kontextová roztříštěnost, kdy týmy ztrácejí hodiny hledáním informací, přepínáním mezi aplikacemi a hledáním souborů na nesouvislých platformách.
Právě zde konvergovaný pracovní prostor mění pravidla hry. Namísto generování shrnutí na jednom místě a snahy o jejich pozdější „převedení do práce“ konvergovaný systém udržuje projekty, dokumenty a konverzace pohromadě, přičemž ClickUp Brain je zabudován jako inteligentní vrstva. Vaše shrnutí zůstávají propojena s úkoly a dokumenty, takže další krok je zřejmý a předání je okamžité.
Shrnutí, které se promění v akci s ClickUp
Skript pro vytváření shrnutí může fungovat perfektně, ale přesto může vašemu týmu zkomplikovat práci jedním nepříjemným způsobem: shrnutí nakonec skončí někde mimo pracovní prostředí.
Tato mezera vytváří rozptýlený kontext, kdy jsou informace roztříštěny mezi dokumenty, chatovými vlákny, úkoly a „rychlými poznámkami“ v nástrojích, které nejsou propojeny. Lidé tráví více času hledáním shrnutí než jeho používáním. Skutečným vítězstvím není jen vytvoření shrnutí. Je to udržení tohoto shrnutí spojené s rozhodnutími, vlastníky a dalšími kroky, kde se práce skutečně odehrává.
To je to, co ClickUp Brain dělá jinak. Shrnuje úkoly, dokumenty a konverzace uvnitř stejného pracovního prostoru, kde se nacházejí vaše projekty, takže váš tým může něco pochopit a jednat podle toho, aniž by musel přecházet mezi různými nástroji.

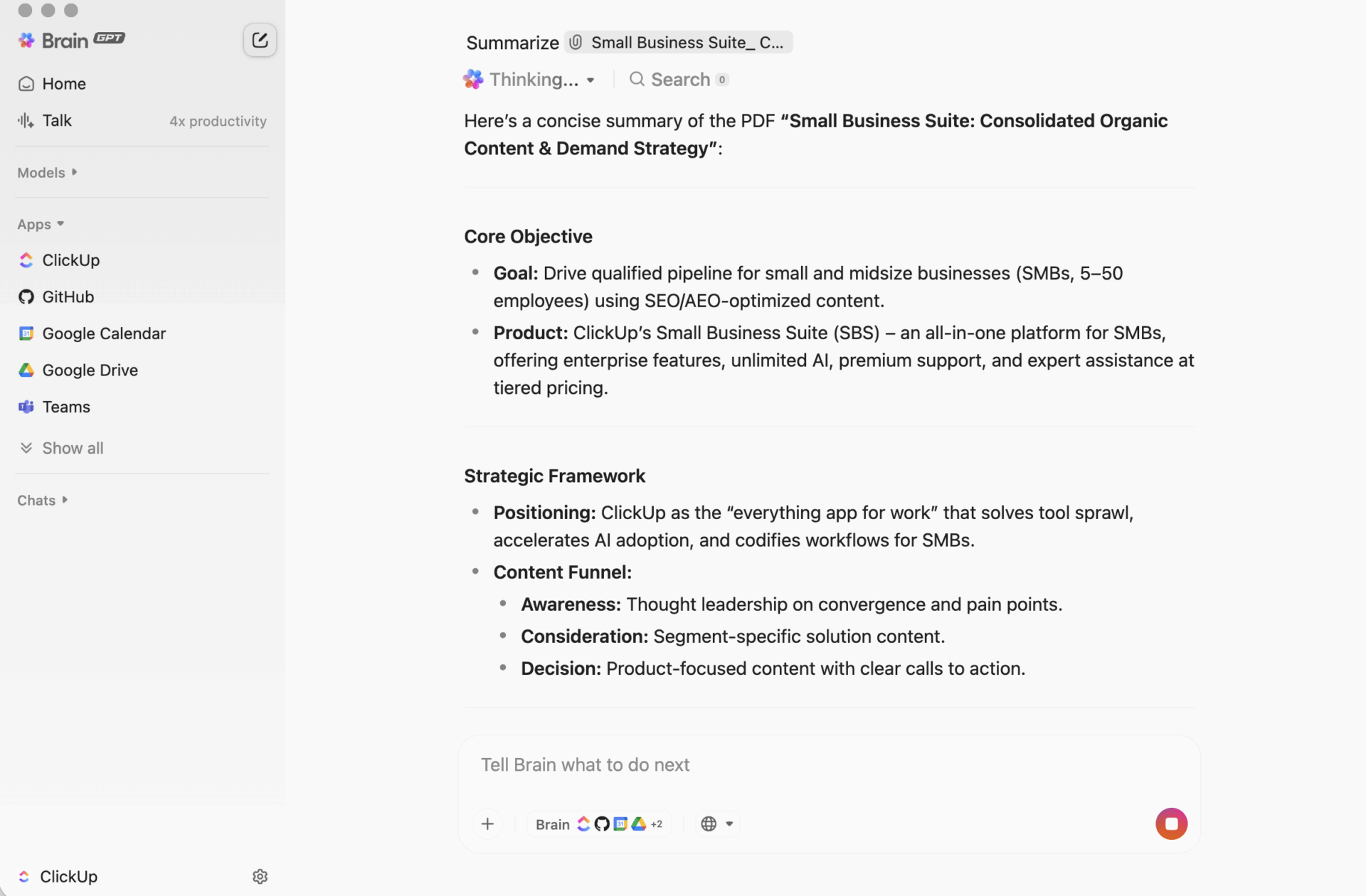
ClickUp BrainGPT: komunikujte se shrnutími pomocí přirozeného jazyka
Na počítači je BrainGPT konverzačním rozhraním pro ClickUp Brain. Místo otevírání skriptů, notebooků nebo externích nástrojů AI může váš tým požádat o to, co potřebuje, v běžném jazyce, přímo v ClickUp.
Můžete psát (nebo použít funkci převodu řeči na text) a:
- Shrňte dlouhý popis úkolu, vlákno komentářů nebo dokument.
- Navazujte otázkami jako „Jaké jsou další kroky?“ nebo „Kdo za to odpovídá?“
- Proměňte shrnutí v akci tím, že z něj vytvoříte úkoly s vlastníky a termíny splnění.
Protože ClickUp Brain pracuje uvnitř vašeho pracovního prostoru, výstup je založen na živém kontextu: popisy úkolů, komentáře, podúkoly, propojené dokumenty a struktura projektu. Nevkládáte text do samostatného nástroje a nedoufáte, že vám neunikne nic důležitého.
Proč je to pro většinu týmů lepší než workflow založené na kódování
Workflow vytvořený vývojáři může generovat silné shrnutí. Potíže se objeví až poté, když někdo musí výstup zkopírovat na místo, kde se práce odehrává, poté jej převést na úkoly a následně sledovat jejich plnění.
ClickUp Brain tuto smyčku uzavírá:
Není třeba žádné programováníKdokoli z týmu může shrnout dokument, vlákno úkolů nebo chaotickou sadu komentářů, aniž by musel cokoli instalovat nebo psát kód.
Shrnutí s ohledem na kontextClickUp Brain může zahrnovat části, na které lidé obvykle zapomínají: rozhodnutí skrytá v komentářích, překážky zmíněné v odpovědích, dílčí úkoly, které mění význam slova „hotovo“.
Shrnutí jsou tam, kde se odehrává práceMůžete se seznámit s úkolem, přidat shrnutí v horní části ClickUp Docs nebo rychle shrnout diskusi, aniž byste museli vytvářet další „shrnující dokument“, který nikdo nečte.
Méně nástrojůNepotřebujete samostatné skripty, notebooky Jupyter, klíče API ani pracovní postup, kterému rozumí pouze jedna osoba. Vaše dokumenty, úkoly a shrnutí zůstávají ve stejném systému.
To je praktická výhoda konvergovaného pracovního prostoru: shrnutí, akce a spolupráce probíhají společně, místo aby byly spojovány až dodatečně.
To je praktická výhoda konvergovaného pracovního prostoru: shrnutí, akce a spolupráce probíhají společně, místo aby byly spojovány až dodatečně.
Jak to funguje v praxi
Zde je několik běžných vzorů, které týmy používají:
- Shrňte vlákno komentářů: otevřete úkol s dlouhou diskuzí, klikněte na možnost AI a získejte rychlý přehled toho, co se změnilo a co je důležité.
- Shrňte dokument: otevřete dokument ClickUp a pomocí funkce „Ask AI“ vygenerujte shrnutí stránky, aby se v ní každý rychle zorientoval.
- Extrahujte akční položky: vezměte shrnutí a okamžitě převedete další kroky na úkoly s přiřazenými osobami a termíny, aby se při předávání neztratila dynamika.
| Schopnosti | Hugging Face (založený na kódu) | ClickUp Brain |
|---|---|---|
| Nutná konfigurace | Prostředí Python, knihovny, kódování | Žádné, vestavěné |
| Vnímání kontextu | Pouze text (to, co zadáte) | Úplný kontext pracovního prostoru (úkoly, dokumenty, komentáře, podúkoly) |
| Integrace pracovního postupu | Ruční export/import | Nativní: shrnutí se mohou stát úkoly a aktualizacemi |
| Potřebné technické dovednosti | Úroveň vývojáře | Kdokoli z týmu |
| Údržba | Průběžná údržba modelu a kódu | Automatické aktualizace |
Od shrnutí k realizaci s Super Agents
Shrnutí jsou užitečná. Těžké je zajistit, aby se důsledně promítala do následných kroků, zejména když se jejich objem zvyšuje.
A právě zde přicházejí na řadu ClickUp Super Agents . Mohou využívat shrnuté informace a posouvat práci vpřed na základě spouštěčů a podmínek, a to vše v rámci stejného pracovního prostoru.
Díky Super Agents mohou týmy:
- Shrňte změny podle plánu (týdenní rekapitulace projektu, denní souhrny stavu)
- Extrahujte akční položky a přiřazujte jim vlastníky automaticky
- Označte pozastavenou práci (úkoly uvízlé v revizi, nezodpovězené vlákna, zpožděné další kroky)
- Udržujte vysokou viditelnost vedení bez ručního vykazování
Místo toho, aby shrnutí zůstalo statickým textem, agenti pomáhají zajistit, že se shrnutí stane plánem a plán se stane pokrokem.
Shrnutí, které žije tam, kde se pracuje
Hugging Face Transformers jsou skvělé, když potřebujete vlastní aplikaci, pipeline na míru nebo plnou kontrolu nad chováním modelu.
Pro většinu týmů však není největším problémem otázka „Můžeme to shrnout?“, ale „Můžeme to shrnout a okamžitě to proměnit v práci s vlastníky, termíny a viditelností?“
Pokud je vaším cílem produktivita týmu a rychlé provedení, ClickUp Brain vám poskytne shrnutí v kontextu, přímo tam, kde se práce odehrává, s jasnou cestou od „zde je podstata“ k „zde je to, co budeme dělat dál“.
Jste připraveni přeskočit nastavení a začít vytvářet shrnutí tam, kde se vaše práce skutečně odehrává? Začněte zdarma s ClickUp a nechte Brain, aby se postaral o těžkou práci.